
下载掌阅APP,畅读海量书库
立即打开



Airflow是Airbnb的Workflow开源项目,2016年3月进入Apache Software Foundation 孵化,2019年1月正式成为其顶级项目。Airflow是由Python编写的任务管理、调度、监控工作流平台。
按照官网说法,Airflow 是一个编排、调度和监控工作流的平台。Airflow 将Workflow编排为任务组成的DAG,调度器在一组Worker上按照指定的依赖关系执行任务。同时,Airflow 提供了丰富的命令行工具和简单易用的用户界面以便用户查看和操作,同时提供了监控和报警系统。
正如之前所提到的,一个调度平台具有几个核心要素:调度时间规则、调度作业依赖关系。由于不同作业可以按照某种规则归为一类,那么基于作业的粒度往往会抽象出类似组的逻辑概念,即该组下面的作业被调度的时间相同,但是执行的具体时间由组内部不同作业的依赖关系确定。
同时,由于Airflow是一个纯调度系统,不提供具体的数据抽取逻辑,因此需要适配不同的作业类型,以满足不同的数据抽取场景。
在Airflow中主要有任务(Task),操作单元(Operator),DAG(Directed Acyclic Graph,有向无环图)、触发规则(Trigger Rule)这四种基础概念。
1)任务是Airflow中最小的执行单元,包含了具体的ETL作业。
2)操作单元是Airflow的DAG封装执行逻辑的基本单元。每个任务都需要包含一个操作单元,通过对其扩展或者自定义,可以使Airflow调度不同类型的ETL作业。例如执行一个命令行的命令,需要使用BashOperator;而基于EmailOperator则可以创建一个邮件发送的任务。当然,除去这些默认的操作单元以外,Airflow还可以自定义操作器。
3)DAG可以将所有需要运行的任务按照依赖关系组织起来,描述的是所有任务执行的顺序,包含构成了系统中调度任务之间的依赖关系。
Tips Airflow中并没有直接提供DAG之间的执行依赖关系,所以往往需要在被依赖的DAG设置一个标志位,然后在依赖的DAG内设置一个作业轮询改状态位。
4)触发规则是Airflow中每个具体的DAG执行的规则,它主要通过配置Crontab来配置每个具体的任务执行,单个任务的执行无法直接配置,如果想配置具体某个任务的执行时间,则只能单独实现调度逻辑。
由于每个DAG都会在触发规则(或者手动触发)下执行,因此每个具体的任务执行会形成具体的任务实例(Task Instance),用来记录任务每一次具体的执行状态以及结果,例如running(运行中)、success(成功)、failed(失败)、skipped(跳过)、up for retry(当前任务执行失败并准备重试)等。具体的DAG执行界面以及状态如图4-3所示。
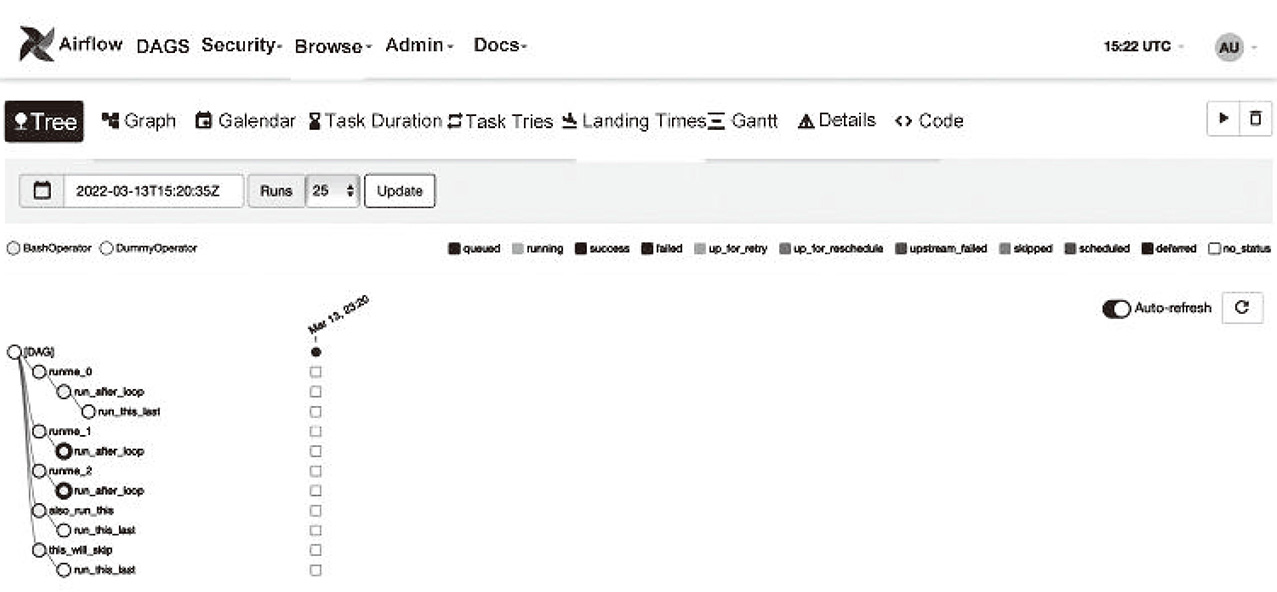
图4-3 具体的DAG执行界面以及状态
在介绍完Airflow的基础概念之后,我们来看一下Airflow架构。
Airflow作为开源的调度框架,不仅支持单机部署、分布式部署,而且提供横向扩展的能力来保证调度任务可以及时地执行。在4.2.1节,我们从业务的角度介绍了Airflow中一些基础的概念。现在我们从技术的角度来描述下Airflow的核心组件。
在Airflow中,主要存在如下5种不同类型的组件,分别是调度器(Scheduler)、执行器(Executor)、DAG 目录(Dag Directory)、Web服务器(Webserver)以及元数据(Metadata)库。
1)调度器,主要处理触发规则(Trigger Rule)以及被调度的工作流(Workflow)之间的关系,它的背后有一个子进程每隔一分钟监控DAG目录下的文件以及触发(Trigger)信息,一旦当前存在任务或者DAG满足执行依赖的情况,调度器会触发任务实例。它是Airflow启动后一直运行的服务。
2)执行器,主要负责执行任务实例,即调度器产生任务实例,然后执行器负责执行具体的任务实例。需要注意的是,Airflow同一时刻只有一个执行器可以存在。而执行器主要有两种执行模式,第一种是本地(locally)模式,存在于调度器中;第二种是远程(remote)模式,通过Worker池实现,这部分我们在后续会详细介绍。
3)DAG目录,主要存放与DAG相关的关键路径,用于被调度器或者执行器扫描。
4)Web服务器,提供一个Web界面,方便用户查看、触发或者调试相关DAG以及任务等。
5)元数据库,主要是存放调度器、执行器以及Web网站的状态数据,Airflow默认安装时采用SQLite作为元数据库,但是在实际生产环境种一般采用关系型数据库作为元数据库,例如MySQL以及PostgresSQL 等。
Airflow通用架构图如图4-4所示。
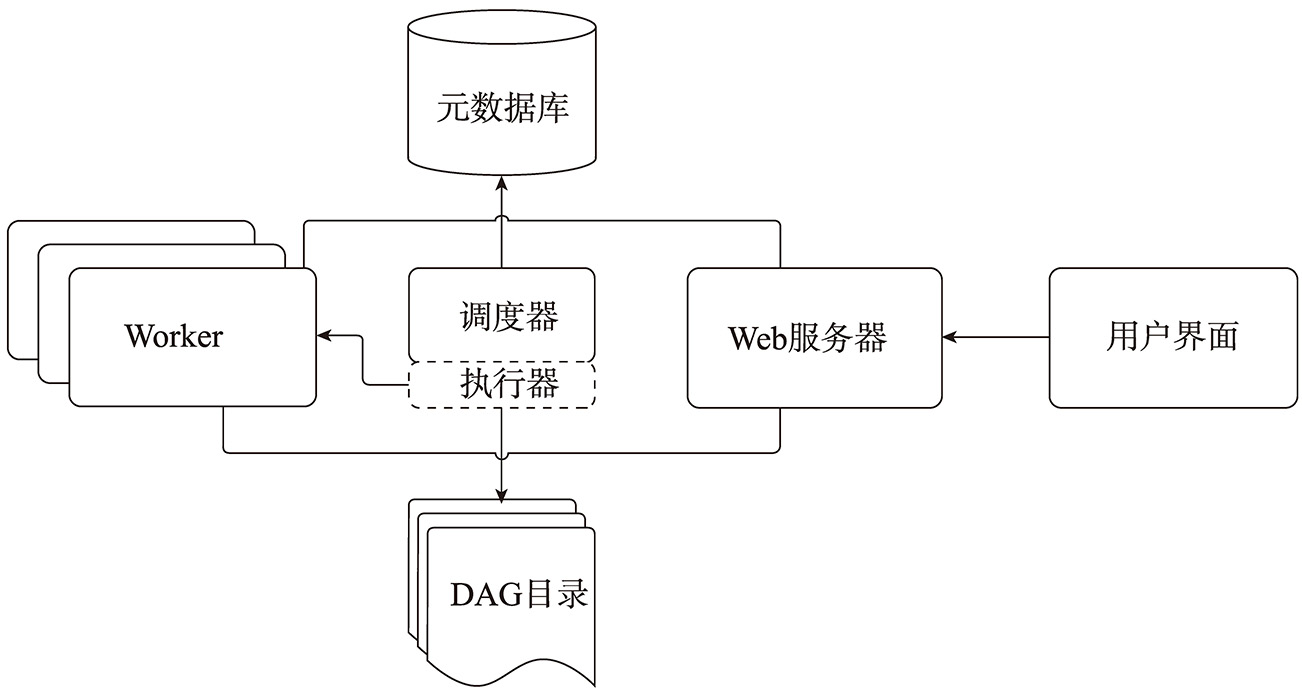
图4-4 Airflow通用架构图
在介绍完技术层面的基础架构后,下面介绍在单机模式以及分布式模式下部署Airflow的区别。
在单机模式的情况下,执行器在调度器进程内部负责具体的任务执行,这个时候执行器主要以本地模式运行。在这种模式下,执行器主要分为3种不同的类型:Debug执行器、本地执行器以及顺序执行器。
其中Airflow默认使用的是顺序执行器,这是因为Airflow安装时默认采用SQLite作为元数据库,此时这种执行器一次只能执行一个任务实例。在实际使用中,一般会替换背后的元数据库,采用本地执行器,这个时候Airflow就可以并发执行任务实例了。
当整个系统DAG或者Task相对较多的时候,企业往往会采用分布式模式部署Airflow。这个过程中Airflow将会采用远程模式进行任务的执行。同时为了保证任务执行状态的一致性,Airflow引入了消息中间件来同步状态。
对于远程模式,Airflow提供4种不同类型的执行器,分别是:Celery 执行器、CeleryKubernete执行器、Dask 执行器、Kubernetes执行器。从这4种不同的执行器中可以看出,CeleryKubernetes执行器以及Kubernetes 执行器主要用于容器环境中。
在大多数分布式部署中采用的是Celery 执行器,这种执行器需要启动一个Celery的后台进程,该进程主要依赖RabbitMQ或者Redis等具有消息队列功能的软件。在这种部署方式下,调度器产生的任务执行信息会首先推送到Celery中,然后由后台的Worker(执行器)通过消息队列进行执行。
Airflow作为一款开源的基于Python的纯调度框架,它并未提供任何数据抽取能力,只基于配置的调度规则执行具体的ETL作业,然而Airflow本身基于单点Scheduler(无论是单机部署还是分布式部署)架构,Scheduler可能成为瓶颈。
其次由于Airflow中作业的依赖关系是在DAG中通过函数之间的调用关系定义完成的,如果前期没有维护好依赖作业,随着调度作业逐步增多并且依赖关系更加复杂,会给后期梳理调度以及数据表之间的依赖关系带来巨大的不便。这部分是使用部署Airflow前期就需要考虑的问题。
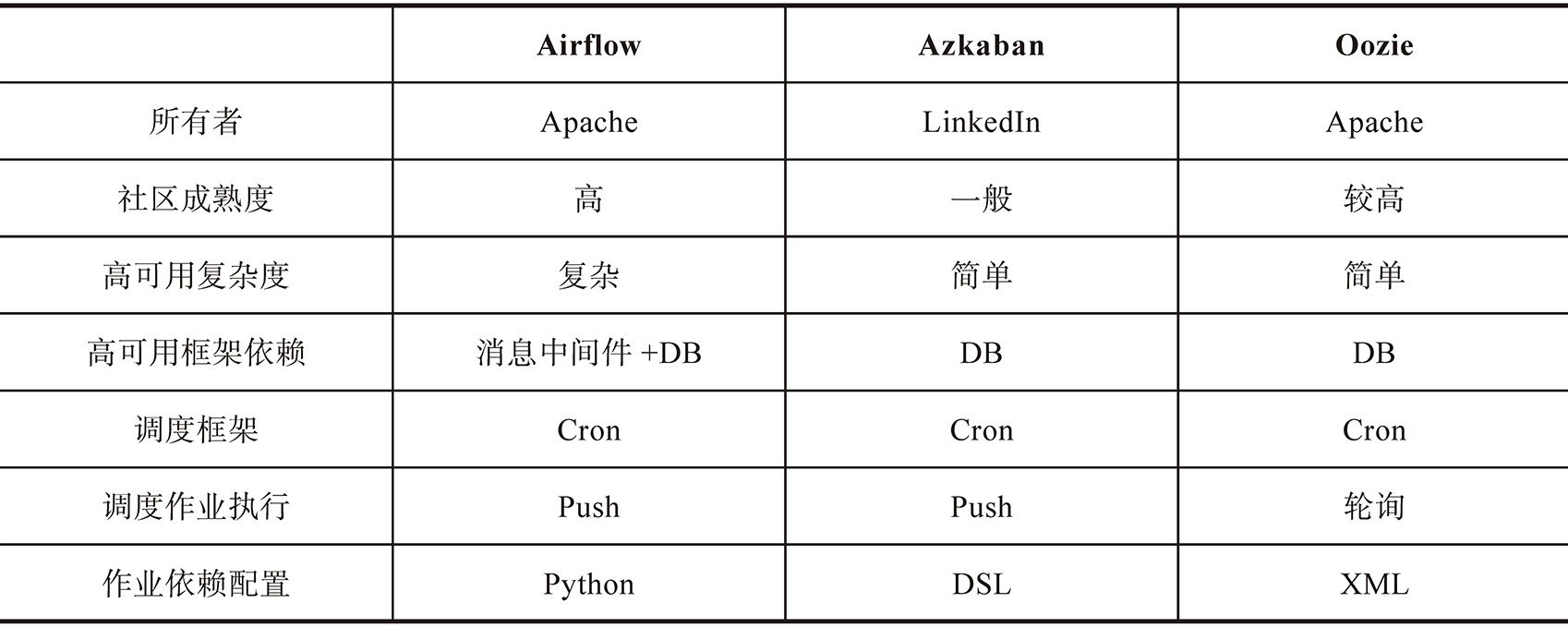
接下来主要从所有者、社区成熟度、高可用复杂度、高可用框架依赖、调度框架、调度作业执行、作业依赖配置等方面对市面上的调度框架进行对比,如表4-1所示。
表4-1 不同类型调度平台对比
作为一款开箱即用的调度框架,Airflow提供了较为完善的调度功能,但是它并未提供数据抽取的能力。接下来介绍一款开源的数据抽取工具。