
下载掌阅APP,畅读海量书库
立即打开



随着技术的发展,满足某些特定领域的存储组件逐步被大家使用,例如低并发大规模数据分析场景的ClickHouse、搜索领域的Elasticsearch以及实现Exactly-Once的实时计算框架Flink,这些组件满足了我们某些特定场景的查询需求,例如利用ClickHouse可以在企业中进行灵活报表的构建、利用Elasticsearch可以快速搭建企业搜索引擎以及利用Flink可以搭建企业实时计算应用等。
接下来我们将逐一介绍上述组件。
从名字上就可以知道,ClickHouse(Click Stream,Data WareHouse)主要是从OLAP场景需求出发的,是基于MergeTree存储对数据进行列式存储,同时按向量进行处理从而提高对于CPU的利用率,数据压缩空间大,对于磁盘I/O的资源要求降低,单查询吞吐量高(每台服务器每秒最多数十亿行)。
它主要由7种类型的MergeTree组成,具体的信息如图3-8所示。

图3-8 ClickHouse的7种类型的MergeTree
同时为了保证数据的冗余,ClickHouse提供了Replicated机制,构成了14种MergeTree的变种,满足日常应用的需求。对应的14种存储引擎如图3-9所示。
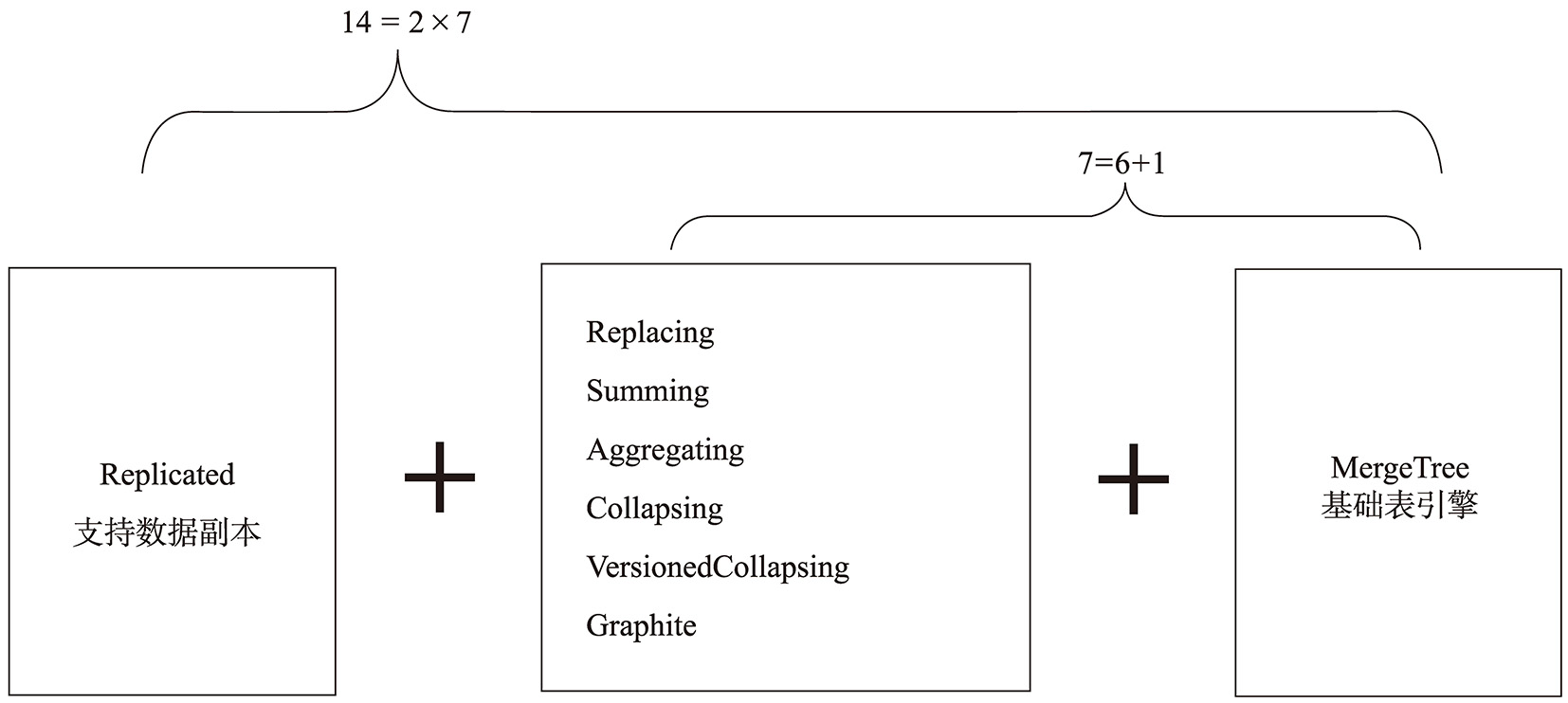
图3-9 ClickHouse的14种存储引擎
此外,由于ClickHouse是以自下而上的方式进行开发的,因此它也提供如下几种基于行、基于组件连接以及基于特殊应用场景的存储引擎,如图3-10所示。

图3-10 ClickHouse的其他存储引擎
由于ClickHouse官方建议QPS值在100左右,因此它并不支持高并发。此外它的跨节点的JOIN连接性能较差(分布式系统中普遍存在的问题),不支持事务。这些潜在的问题是我们在使用ClickHouse时需要考虑的。
Elasticsearch(下文简称ES)是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,是一种流行的企业级搜索引擎,可以协助企业快速实现分布式搜索。
ES从逻辑结构来看主要由三部分构成,依次是索引(Index)、类型(Type)以及文档(Document),分别对应传统关系型数据库中的数据库(Database)、数据表(Table)以及行(Row)。然而Document主要存储的数据类型并不是类似传统关系型数据库中的结构化数据,而是一种JSON 形式的半结构化数据。在ES中数据会被创建倒排索引,用以提高数据整体查询的效率。
由于ES主要是提供搜索的功能,它内部默认嵌套分词器(tokenizer),利用分词器对所存储的数据进行分词处理。分词器可以根据具体的需求进行自定义,例如国内通过整合中文分词器IK满足对于中文检索的需求。