
下载掌阅APP,畅读海量书库
立即打开



实际上,存储引擎已经有了几种成熟的可选方案,单机环境内部的存储引擎绝大部分是基于这些成熟的方案进行构建的,所以本节对目前业界主流的存储引擎进行介绍。
业界主流的存储引擎可以根据其适用的场景分为下面两大类。
❑ 基于B+树的存储引擎: B+树存储引擎主要适用于读多写少的场景,最典型的实现就是关系数据库MySQL、Oracle等内部使用的存储引擎,例如InnoDB、MyISAM等。这类存储引擎主要采用B+树这类数据结构维护数据和索引信息。
❑ 基于LSM派系的存储引擎: LSM派系存储引擎属于一大类存储引擎,这类存储引擎主要为大量写而设计,适用于写多读少的场景。LSM派系存储引擎中最典型的就是LSM Tree存储引擎,此外还有LSM Hash、LSM Array等存储引擎。
B+树存储引擎和LSM派系存储引擎开源组件的实现代表如图1-6所示。后续章节会重点介绍二者的设计过程、原理,并配合具体的开源项目源码进行分析。

图1-6 两大类存储引擎开源组件的实现代表
顾名思义,B+树存储引擎内部采用B+树这种数据结构来存储数据。B+树的特点主要有三个:一是它属于多叉树,一个节点内部可以存储多个孩子节点;二是内部存储的数据是有序的,支持顺序遍历维护的数据;三是根据不同类型的节点,内部保存的数据有所不同,根节点、分支节点保存的是数据的索引信息,而叶子节点则保存的是原始数据。第三个特性是其他一般的数据结构所不具备的。
这里只需要记住它的特性即可,这样设计的目的主要是数据读取快,原因会在第4章详细分析。
B+树存储引擎目前的实现主要分为以下两种。
❑ 类InnoDB: 泛指关系数据库中的各种存储引擎实现。
❑ 类BoltDB: 泛指嵌入式场景中的KV类存储引擎实现。
这两类实现的区别主要在于 采用B+树维护的数据是否实时/同步刷盘 。在类InnoDB存储引擎内部,B+树维护的数据不是实时刷盘的。换言之,其内部B+树中的数据是异步刷盘的。这么做是为了保证读/写效率,因为实时落盘的开销是很大的。那它是如何保证数据持久化的呢?答案是在这类异步刷盘的实现中,都是采用预写WAL日志来保证的。
异步刷盘这类组件处理写请求的具体逻辑为:在一次写操作进来后,首先调用WAL模块将数据写入日志文件中存储起来,以保证数据的持久性,当机器宕机或者重启后可以用该日志来恢复数据。当WAL日志写成功后,会更新内存B+树中的数据。
上述操作完成后,就表示一次写入请求完成了,然后就可以响应客户端结果了(此处暂时不考虑主从数据之间的同步过程)。而后台会有单独的线程负责异步刷盘逻辑,它会按照一定的策略将内存中暂存的、已经修改完的脏页数据异步地写入磁盘中。当脏页数据写入磁盘后,对应的WAL日志通常也就没有用处了,此时就可以清理掉了。
通过上述过程可以看到,异步刷盘这类B+树存储引擎的实现过程非常复杂,需要考虑的边界条件非常多,稍有不慎就会导致新的问题。但其带来的好处是系统的写性能会有所提高。这在早期使用机械磁盘存储数据的时代是一种非常主流的设计思路,各大系统也验证了这种做法是可行的。
另外,同步刷盘虽然听上去比较“粗糙”,但是在一些嵌入式的基于B+树的存储引擎上有所应用。BoltDB项目就是这么做的,优点是实现简单、易维护。它在一些请求量不是很大的场景下非常实用,比如用作分布式系统中的WAL日志模块的底层实现或者一些一致性系统的磁盘状态机实现等。它处理写请求的逻辑如下:一个写请求进来后,从磁盘上加载对应节点的数据到内存中,然后开始修改该节点对应的数据。修改完成后就开始将内存中的脏页数据写入磁盘,最后响应上层用户。通常,这种方式会结合Mmap对磁盘文件进行内存映射,以加速访问。注意:这种组件往往配置批量接口进行写操作,这样性能会更佳。
对于B+树存储引擎,会在后面详细解读其原理。
大部分读者或多或少都会听过LevelDB或者RocksDB这两个非常著名的项目,这两个项目就是基于LSM Tree存储引擎构建的。那为什么本小节的标题不是LSM Tree存储引擎而是LSM派系存储引擎呢?接下来为读者解答这个问题。
其实LSM这类组件是为了解决互联网中大量的写场景而出现的,其中最著名的莫过于LSM树了。之所以说LSM是一类组件,主要原因是它的目标是提升大量写场景下的写性能。早期磁盘的随机读/写性能非常低,但是对于需要存储大量数据,并且对数据安全要求非常高的场景,又不得不选择HDD来存储数据,这就出现了难题。选择用磁盘存储就会面临性能问题,而不用磁盘存储又解决不了实际问题。在这样的背景下,人们最终还是选择了用磁盘存储数据。机械磁盘的随机读/写速度确实慢,这一点毋庸置疑,但顺序读/写的性能要远远好于随机读/写。于是人们开始朝着顺序读/写这个方向前进,最终一种新的技术方案就出现了,即LSM类存储引擎。LSM类存储引擎充分利用磁盘的顺序写来保证性能,既保持了持久性又提升了写性能。因此,笔者认为LSM其实是一种思想,它主要表达的是通过顺序写磁盘来解决大量写这类问题。这种思想不仅在数据库这个领域有很多应用,而且在大数据领域使用的消息队列中也有着广泛的应用。
从LSM在内存层中维护的数据是否实时落盘,LSM派系的存储引擎分为以下两类。
❑ 数据同步落盘类: 原生满足数据持久性。
❑ 数据异步落盘类: 数据持久性通过预写WAL日志来保证。
这两类各自有一些项目在使用。数据同步落盘类的LSM存储引擎以LSM Hash模型为主,这种模型的实现中以Bitcask最为出名。Bitcask是NoSQL数据库Riak内部的存储引擎。而数据异步落盘类组件最经典的是LSM Tree模型和LSM Array模型。LSM Tree的典型实现有Google研发的LevelDB,以及Facebook基于LevelDB改进的RocksDB,还有大数据领域的HBase、Cassandra、InfluxDB、ElasticSearch等知名项目。而LSM Array实现的组件有开源项目Moss等。LSM Tree和LSM Array的区别在于,它们在内存中存储数据的数据结构是树类(跳表、红黑树、B树等)结构还是数组结构。
和同步落盘相比较,异步落盘模型虽然复杂一些,但它能为系统提供更强大的功能。例如通过异步落盘可在内存中将数据排好序再落盘,这样原生的数据存储就是有序的,这在有序查询的场景下更为通用。而同步落盘则只能简单地追加写数据,数据的有序访问只能依靠它维护的索引来实现,灵活性相对低一些。
LSM派系的存储引擎的共同点都是充分利用顺序写磁盘进而处理大量写操作的场景,只是LSM Tree在业界用得最为广泛。下面以LSM Tree为例介绍它的基本原理。典型的LSM Tree架构如图1-7所示。
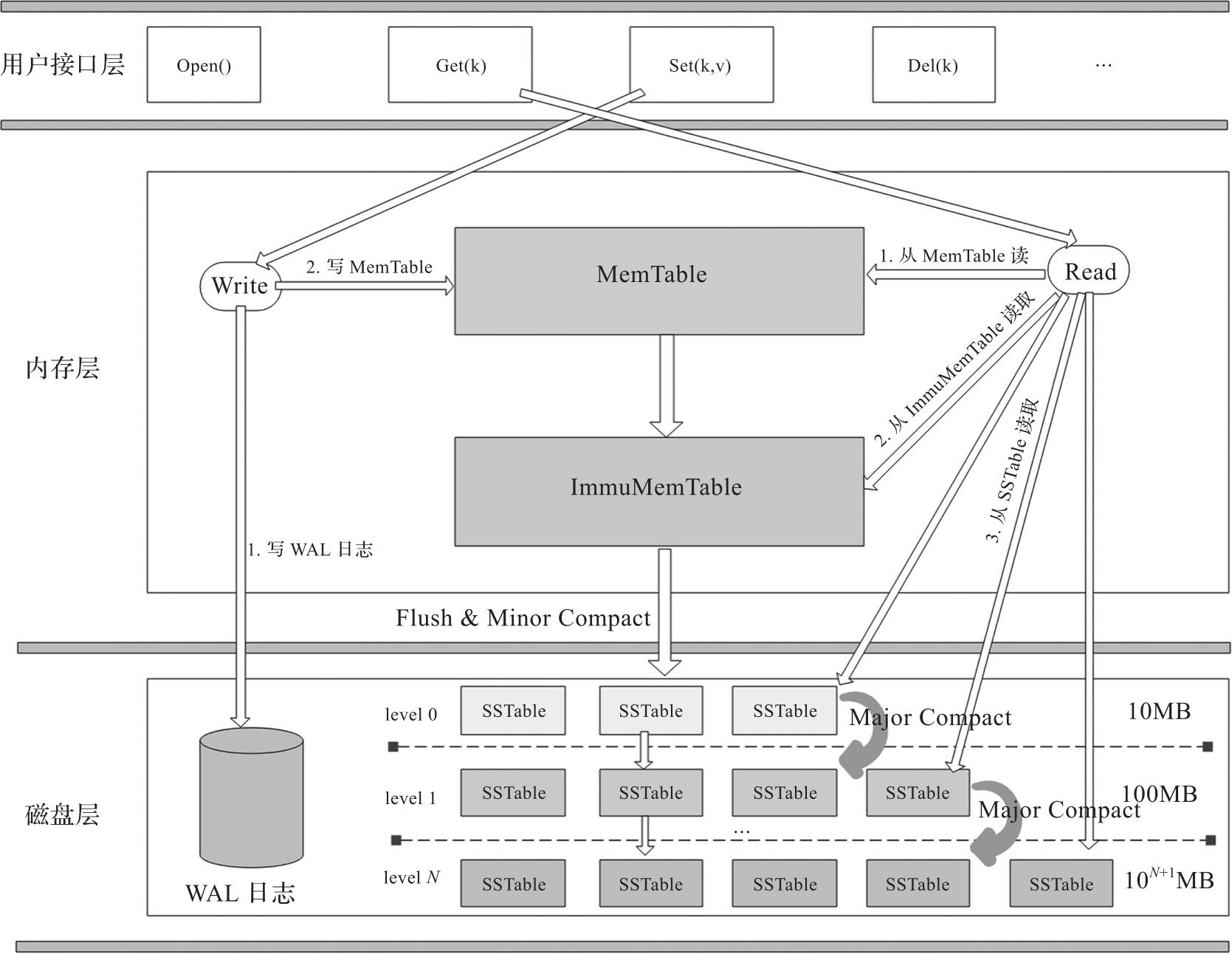
图1-7 LSM Tree架构
以经典的三层架构来介绍LSM Tree。
在内存层中,LSM Tree主要由MemTable和ImmuMemTable构成。二者的区别在于,当MemTable中数据写满(达到设定的最大阈值)后,它就会将当前的MemTable设置成只读,该MemTable就变成了ImmuMemTable。之后重新创建一个新的MemTable来继续处理新的写请求。MemTable是内存中实现的一个有序的数据结构,通常采用红黑树、B树、跳表等数据结构来实现。
磁盘层由多层SSTable(Sorted String Table)文件构成。这些SSTable文件有些是由内存中的ImmuMemTable定期落盘形成的,有些则是在后续过程中压缩数据后生成的。存储在磁盘上的SSTable会定期进行数据的合并,以减少SSTable的数目,提升空间利用率和读性能。有些系统把数据的合并称为数据压缩,本质上是通过合并相同k的数据以减少重复的数据条目。最主要的压缩策略有分层压缩和分级压缩。以分层压缩为例,层数越大,存储的数据越多,数据越旧,层数小的合并后的数据会迁移到下一层级。下面简单介绍一下LSM Tree存储引擎的读/写过程。
对于LSM Tree而言,它处理写操作的主要过程如下:当存储引擎接收到写请求时,首先会将数据记录一份到WAL日志文件中以保证数据的持久性,写完WAL日志后,紧接着它会将该条数据写入内存的MemTable模块中,当数据写入MemTable完成后这一次写操作就完成了,可以响应给客户端了。
对于读请求而言,LSM Tree在处理时的流程如下:在接收到一个读请求后,LSM Tree会首先从内存的MemTable中读取数据,如果没读到再从ImmuMemTable中读取数据,如果还没读取到则会从磁盘的SSTable文件中读取,依次从低层级向高层级读取。一旦读取到数据就停止读取过程,然后返回给客户端。从本质上来说,LSM Tree由于是追加写数据的,因此读取时只需要逆序读取最新的数据即可,也就是说,它的数据读取过程是一个倒序读取的逻辑。把握了这一点就比较好理解了。
此外,LSM Tree系统后台有专门的线程完成一些异步任务。例如,内存层只读的ImmuMemTable中维护的数据会定期被后台线程写入磁盘中形成SSTable文件,这个过程为Minor Compact。再比如,每一层的SSTable数目一般都是有限制的,当超过限制后异步线程会进行层与层之间的数据压缩,这个过程称为Major Compact。压缩是LSM Tree的重点内容,后面会有专门的章节进行详细介绍,此处不再赘述。
本节只是说明LSM Tree是什么以及做什么的,关于LSM Tree为什么由MemTable、ImmuMemTable、SSTable这几部分构成,为什么这样设计,以及压缩方式等核心内容,会在后面详细介绍。