
下载掌阅APP,畅读海量书库
立即打开



不同的存储场景需要选择不同的数据库,不同的设计目标也使得每个数据库背后的方案选型、面临的问题不尽相同。例如有些组件设计之初就定位为关系数据库,而有些组件则定位为NoSQL数据库,随着技术的发展又诞生了NewSQL数据库。本节将对互联网中涉及存储数据的常用存储组件进行分类,并介绍它们的适用场景和设计目标。
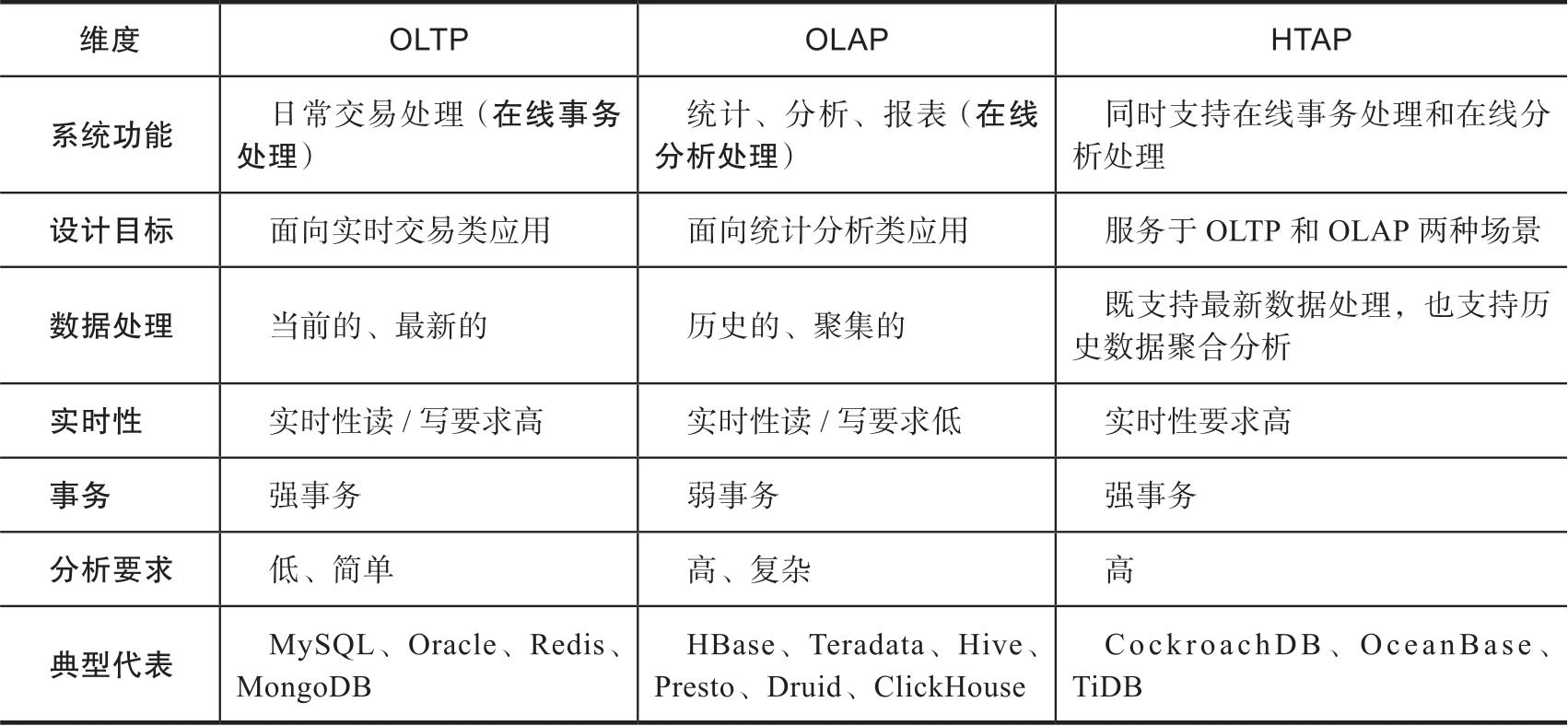
OLTP(在线事务处理)数据库的主要功能是处理用户的在线实时请求,直接为用户提供服务。因此,这类数据库通常对处理请求的时延要求比较高,正常情况下绝大部分请求会在毫秒级完成。OLTP数据库很多,除了大家最熟悉的关系数据库(如MySQL、Oracle)外,还有Redis、MongoDB等非关系数据库。
OLAP(在线分析处理)数据库的主要功能是对数据或者任务进行离线处理,不直接为用户提供服务。OLAP系统对请求的处理通常比OLTP慢得多,一般为秒级、分钟级甚至小时级,通常在数据统计、报表分析、数据聚合分析等场景使用。这类数据库的典型代表有HBase、Teradata、Hive、Presto、Druid、ClickHouse等。互联网企业往往都需要使用OLTP和OLAP,因此为了满足这两类需求,通常结合多个系统一起开发使用。这样的做法当然是可行的,而且多数企业采用的也是这种方式。
随着互联网技术的发展,需要存储的数据量呈爆炸式增长,这种模式带来的存储成本问题成为新的矛盾点,人们开始探索是否有一种数据库能将OLTP和OLAP这两类应用合二为一。于是,一种新的解决方案出现了,那就是下面要介绍的HTAP(混合事务分析处理)数据库。
HTAP在设计时就充分考虑了对OLTP和OLAP两种场景的需求,通过在系统内部实现上进行更好的兼容,为上层应用程序使用提供了统一的服务。在处理上述两种场景时,底层可以使用同一套数据库来完成。这类数据库既可以处理在线事务,又可以进行在线分析。可以认为HTAP=OLTP+OLAP。HTAP的主要代表有TiDB、OceanBase、CockroachDB等。
HTAP数据库有它的优点,但是也间接带来了很大的挑战。只使用HTAP数据库就可以完成在线事务处理和在线分析处理这两类需求,这对用户而言无疑是一种好的选择,因为底层采用同一套系统存储数据,在存储资源和成本上有很大的优势。但随之而来的是系统复杂性的增加,这类数据库的复杂度相比纯OLTP数据库和纯OLAP数据库高很多,软件开发难度也大很多。
OLTP、OLAP与HTAP之间不同维度的对比见表1-1。
表1-1 OLTP、OLAP与HTAP之间不同维度的对比
关系数据库、NoSQL数据库、NewSQL数据库这三者是现如今讨论很多的一组概念,其实要搞明白它们之间的区别,就不得不回到数据库的发展历程上来审视它们产生的背景和动机。数据库的发展历程如图1-1所示。
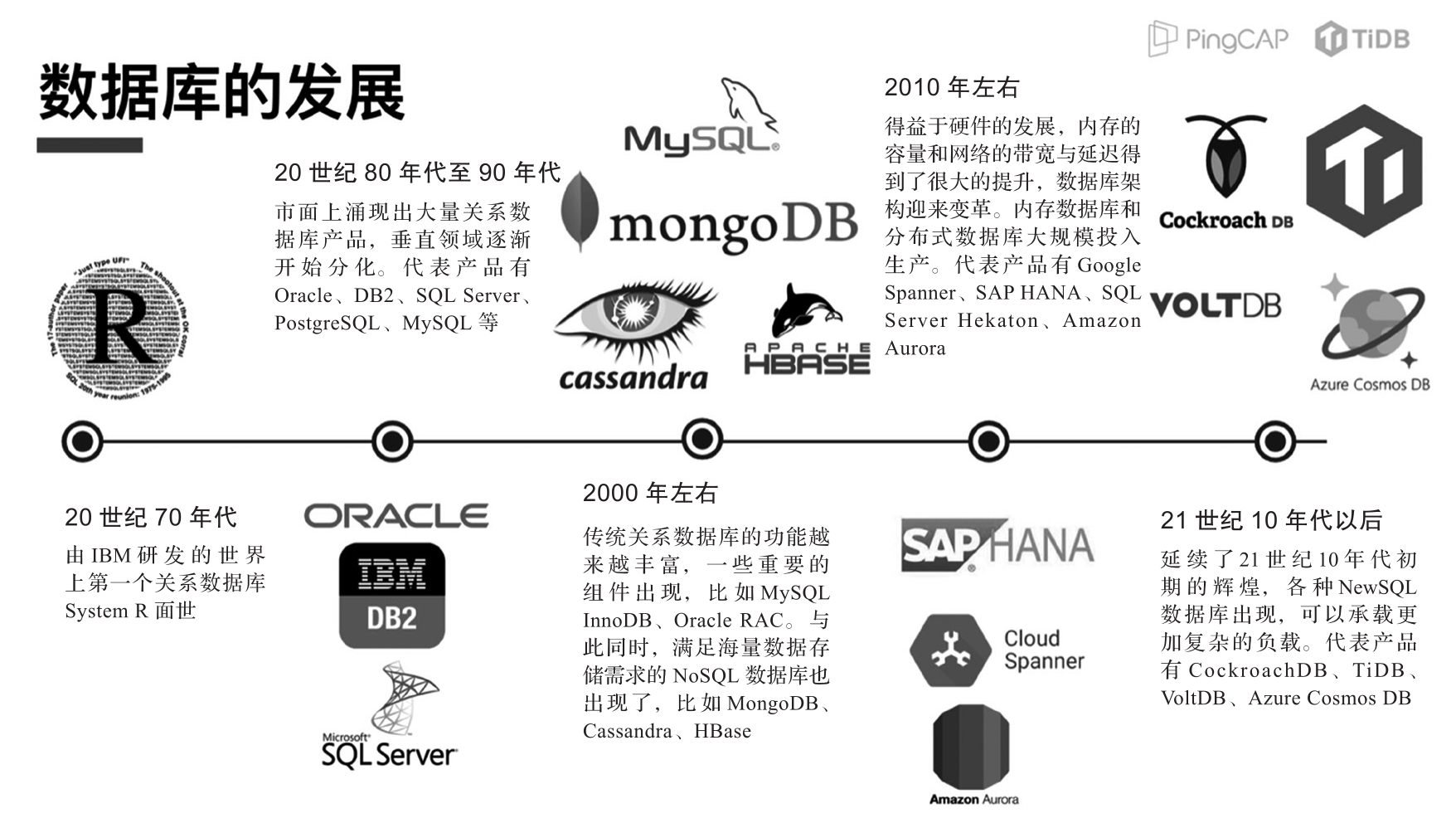
图1-1 数据库的发展历程
1.关系数据库
关系数据库也称为SQL数据库(为描述方便,后面简称为SQL数据库)。最早的数据库可以追溯至20世纪70年代IBM研发的第一个SQL数据库System R,这也是最早的SQL数据库。再后来,20世纪80年代至90年代涌现出大量的SQL数据库产品,例如Oracle、DB2、SQL Server、PostgreSQL、MySQL等。
SQL数据库按照以“行”为单位的二维表格存储数据,这种方式最符合现实世界中的实体,同时通过事务的支持为数据的一致性提供了非常好的保证。这既是SQL数据库的优势,也是它的缺陷。在面对海量数据存储、高并发访问的场景下,SQL数据库的扩展性和性能会受到限制。随着互联网的飞速发展,到2000年左右,存储海量数据、高并发处理读/写的需求变得非常强烈,这对SQL数据库提出了巨大的挑战。为了解决这个问题,出现了支持数据可扩展性、最终一致性的NoSQL数据库。因此,NoSQL数据库可以看作基于SQL数据库的缺陷而诞生的一种新产品。
2.NoSQL数据库
NoSQL组件普遍选择牺牲复杂SQL的支持及ACID事务功能,以换取弹性扩展能力和更高的读/写性能。这类系统主要存储半结构化或非结构化数据。根据存储的数据种类,NoSQL数据库主要分为文档数据库(Document-based Database)、键值数据库(Key Value Database)、图数据库(Graph-based Database)、时序数据库(Time Series Database)、列式存储(Column-based Store)及多模数据库(Multi-model Database)。
(1)文档数据库
文档数据库以文档作为基本的单元进行操作。这里的文档并不是传统意义上的“文档”,它所指的是一条数据记录,类似关系数据库中的一行数据。这个记录是可以进行自我描述的,主要的形式有JSON、XML、HTML等,文档数据库中存储的每个文档可以具有完全不同的结构。从广义上来看,文档数据库也是一种KV数据库,只不过它和键值数据库的区别在于它的值是文档。此外,文档数据库还可以通过文档内容构建复杂索引。这类数据库除了MongoDB外,还有CouchDB、OrientDB等。这类数据库通常很容易和关系数据库进行数据转换。文档数据库非常适用于爬虫、物流、游戏、物联网等场景,存储一些数据模型无法确定的数据。
(2)键值数据库
键值数据库也就是一般意义上的KV数据库,它提供的功能和数据结构中的哈希(Hash)表类似。通常添加或更新数据时调用Put(k,v)接口,而在检索和删除时都只需要传入k即可。一般用Get(k)接口来获取数据,用Delete(k)接口来删除数据。这类数据库最为常用的是Redis,此外还有Riak、Amazon DynamoDB等。这类数据库的主要特点是读/写性能超高,系统内部可以支持弹性扩展,主要适用于对性能要求比较高的单点读/写场景,例如推荐系统,用于存储用户或物品特征、用户对内容的互动信息(点赞数、收藏数)等。
(3)图数据库
图数据库是一种使用图数据结构进行语义查询的数据库。图是一组点和边的集合,“点”表示实体,“边”表示实体间的关系,图数据库通过点和边来存储数据。鉴于它采用独特的图数据结构组织数据,类似于现实世界中的人际关系、交通网络,因此这类数据库比较适用于社交网络、数据挖掘等场景。这类数据库的主要代表有Neo4j、Dgraph、TigerGraph等。
(4)时序数据库
时序数据库又称为时间序列数据库,它是用来存储和管理时间序列数据的专业数据库,具备写多读少、海量数据持续高并发写入、数据冷热分离等特点。此外,这类数据库可以基于时间区间进行数据聚合分析和灵活检索。它被广泛应用在物联网、金融、工业制造、软硬件兼容系统等高频度、高密度、动态实时采集场景下。时序数据库的热门产品有InfluxDB、KDB+、Amazon Timestream和TimescaleDB等。
(5)列式存储
列式存储一般也指宽列式数据库,这类数据库一般采用列族数据模型存储数据。和关系数据库类似,列式存储也由多行数据构成,每行数据包含多个列族,每个列族又会对应多列。不同的行可以具有不同数量的列族。同一列族的数据存储在一起。简单来看这类数据库和关系数据库差不多,但实际上在数据存储上存在很大的差别。
传统的关系数据库中数据是按照行来组织的,多个列构成的一行数据在存储时会按照特定的行格式进行扁平化组织,然后写入文件中。当检索一行中的某列数据时需要读取整行数据,再返回该列的数据。这对每次总是使用整行中的多列信息的场景来说非常高效。而在一些统计分析场景中,往往需要对海量数据中的某列或者某几列数据进行频繁的读取和聚合。在这样的模式下,关系数据库的处理方式就变得不太高效了,而列式存储的优势可以得到充分发挥。列式存储中的数据按照列组织后,同一类型的稀疏数据有时候可以采用一些手段(例如位图编码)进行压缩以节约空间。列式存储主要适用于OLAP场景,典型的产品有HBase、ClickHouse、Cassandra、BigTable等。
(6)多模数据库
多模数据库是下一代新型数据库,它与传统的支持单一数据模型的数据库不同。这类数据库是在一套系统内支持多种不同数据模型的数据库。这些数据模型可包括传统的关系模型、NoSQL数据模型(文档模型、键值模型、图模型等)。多模数据库的主要特性之一是通常支持一种或者多种查询语言,可以以灵活的方式访问多种不同的数据模型,甚至跨越模型进行join等操作。这类数据库使得对数据的存储、组织、查询变得比以往的数据库更加灵活和便捷。目前有些关系数据库和NoSQL数据库正在通过扩展对其他数据模型的支持来转变为多模数据库。多模数据库的典型代表有MongoDB(支持文档、图等模型)、Oracle(支持关系表、XML、文档等模型)、OrientDB(支持文档、图、键值等模型)、ArangoDB(支持文档、图、键值等模型)等。
目前,不同的多模数据库通过不同的底层架构来实现多模型数据的管理。多模数据库的总体实现有两种方式:一种方式是在原生存储引擎存储主数据模型,然后扩展实现其他数据模型,例如某些产品用文档来实现主存储,然后使用文档之间的关系实现图模型;另一种方式是在所有数据模型上层增加一个中间层来集成所有操作,这样每种数据模型都需要有对应的处理模块。
结合上述对各种NoSQL数据库的介绍,将它们对应存储的数据结构进行汇总,如图1-2所示。
虽然NoSQL数据库克服了关系数据库存储的缺陷,但它无法完全代替关系数据库。在NoSQL数据库出现后的一段时间内,互联网软件的构建基本上都是结合二者来提供服务的,在不同的场景下选择不同的数据库进行数据存储。虽然这样的合作方式很好,但是在这样的模式下,一个用户可能会因为场景的不同而存储多份相同的数据到不同的数据库中,在用户量级和存储数据量很小的情况下没什么问题,一旦量级发生变化就会引发新的问题。
3.NewSQL数据库
随着存储数据量的不断增加,资源的浪费和成本的上升不容忽视,工业界和学术界都在寻找更好的解决方案。直到2010年左右,诞生了NewSQL数据库(也称为分布式数据库)。它的出发点是结合关系数据库的事务一致性,又具备NoSQL数据库的扩展性及访问性能。这无疑给系统的设计及实现带来了更大的挑战,NewSQL数据库不仅要考虑单机环境下高效存储的问题,还需要考虑多机情况下数据复制、一致性、容灾、分布式事务等问题。目前,NewSQL数据库的典型代表有TiDB、OceanBase、CockroachDB等。
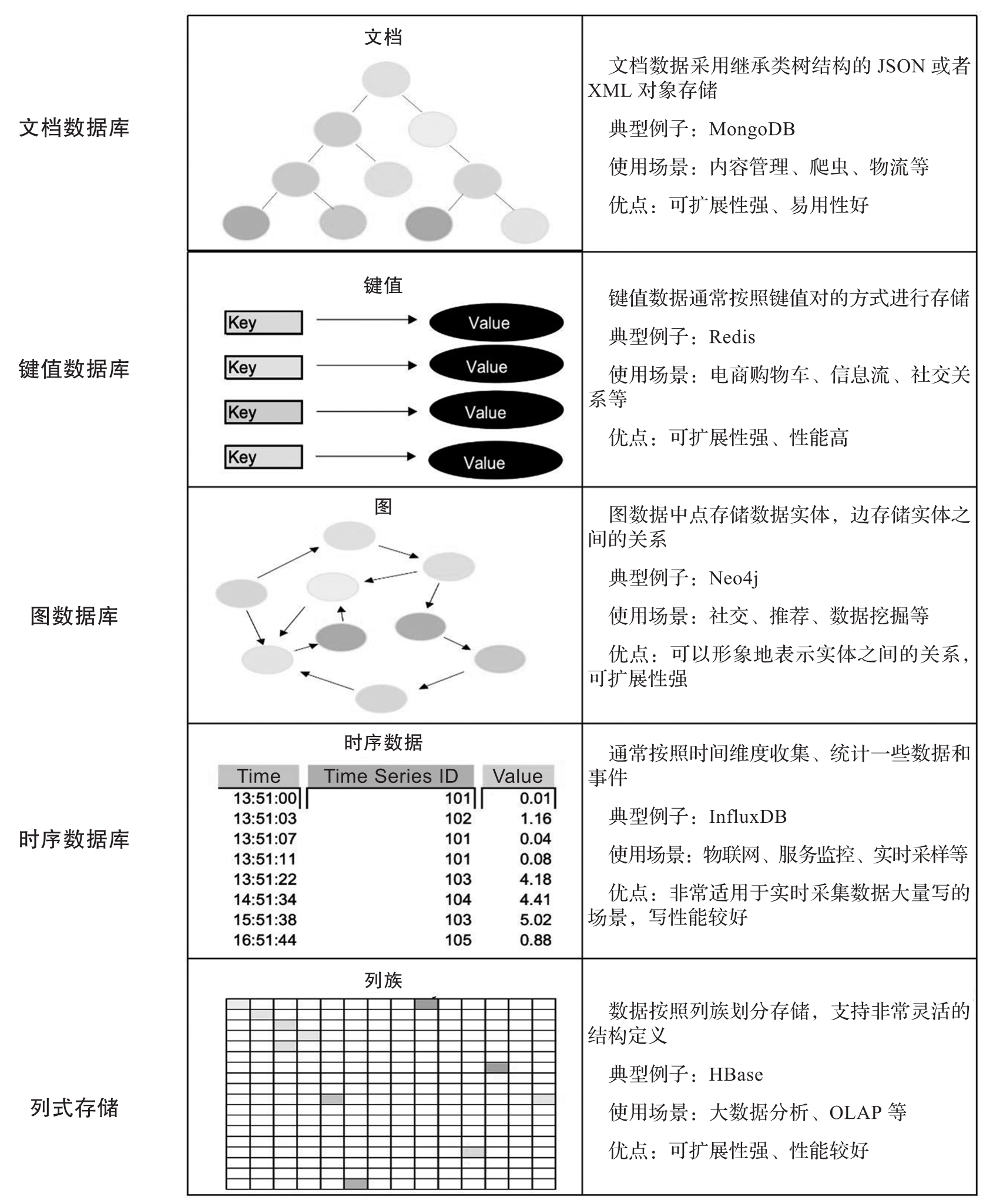
图1-2 NoSQL数据存储类型
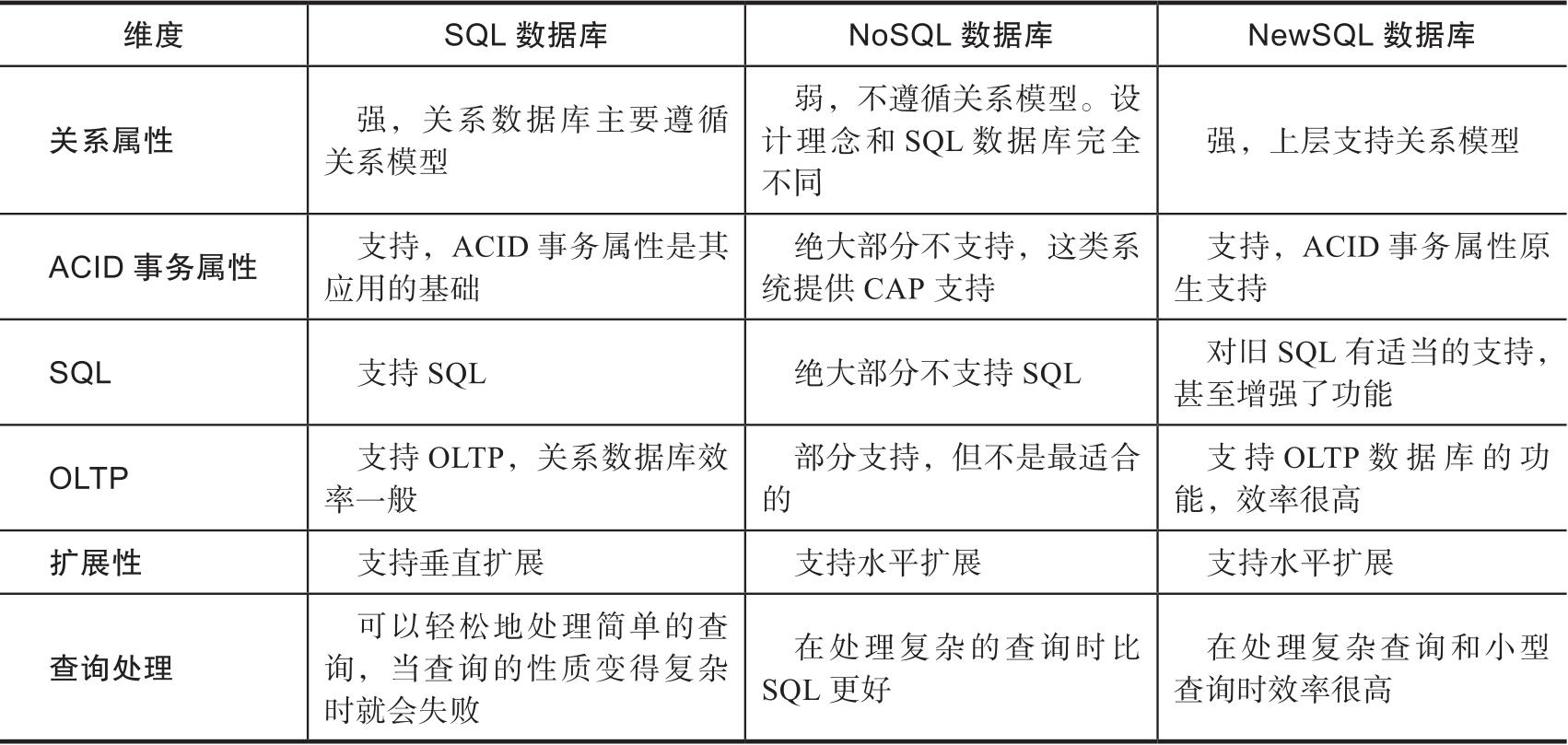
从数据库的发展历程可以看到,每种类型数据库的产生都是为了解决特定场景下的问题,这也是计算机软件发展的一个永恒不变的规律。SQL数据库、NoSQL数据库、NewSQL数据库不同维度的对比见表1-2。
表1-2 SQL数据库、NoSQL数据库、NewSQL数据库对比
如果以组件的类型是关系数据库还是非关系数据库,并结合服务的场景是OLTP还是OLAP来对业界的各种存储组件进行划分的话,可以得到图1-3所示的结果。关系数据库中既有为OLTP设计的,也有为OLAP设计的,同时还有新兴发展起来兼容二者的HTAP数据库。这些系统都有各自适用的业务场景,在实际方案选型时需要结合具体场景灵活选择合适的数据库。
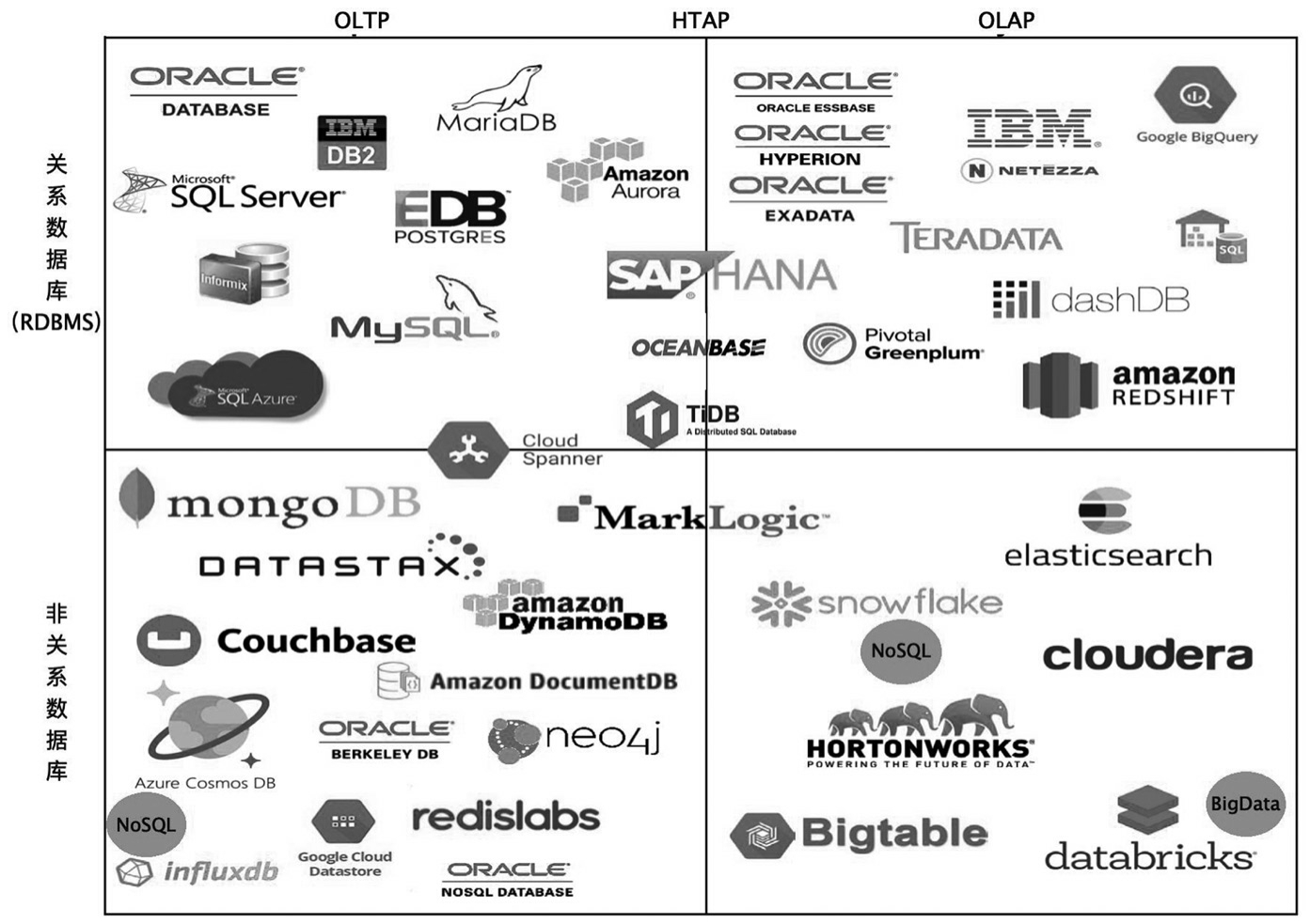
图1-3 存储组件的分类
在计算机发展的几十年里,计算机的整体结构依然没有太大的变化,计算机中充当存储介质的主要有内存、磁盘两类。内存的访问速度要比磁盘快几个量级,但是内存的容量比磁盘要小很多。一般对磁盘进行访问时,首先会从磁盘文件加载数据到内存中,然后响应用户。内存和磁盘的各维度对比如图1-4所示。

图1-4 内存和磁盘对比
结合前面的介绍,在大部分系统设计时,通常会选择一种主要存储介质来存储数据,另一种存储介质则作为辅助使用。在目前的各种存储组件中,根据每个存储组件存储数据的主要介质,可将其分为两类:内存型组件和磁盘型组件。
1.内存型组件
内存型组件的典型特点是读/写性能高、访问速度快。其缺点在于,保存的数据量受限于当前机器的内存容量,并且当机器宕机或发生突发情况断电后,保存在内存中的数据会全部丢失。例如,Redis是大家较熟悉也较常用的一个内存型存储组件。Redis主要采用内存存储数据,而磁盘则用于做辅助的持久化存储。RabbitMQ也主要采用内存存储消息,同时支持将消息持久化到磁盘。
对采用内存存储数据的方案而言,难点之一在于如何在不降低访问效率的情况下,充分利用有限的内存空间来存储尽可能多的数据。这个过程少不了对数据结构的选型、优化,以及对数据过期、数据淘汰等方案的选择。同时,绝大多数的内存型组件在保证单机功能完备的情况下,都会优先考虑对存储的数据进行分片,并构建集群系统对外提供服务,以解决单机内存容量这一限制。另一个难点在于,内存型组件如何保证在机器发生故障的情况下,数据尽可能少丢失。针对这类问题,业界经典的解决方案是快照+广泛意义的WAL(Write Ahead Log)日志,其典型代表有很多,比如Redis。
2.磁盘型组件
和内存型组件不同,磁盘型组件的特点是单机磁盘存储的数据量非常大,要远大于内存型组件。同时,在机器宕机或者发生突发情况断电的情况下不会出现数据丢失(排除极端情况)。然而,磁盘型组件,尤其是典型的HDD(机械磁盘),由于先天性的磁盘结构,其访问数据的速度比内存慢得多。同时,在相同的磁盘结构下,对磁盘的访问方式决定了磁盘访问的耗时。磁盘顺序访问要远远快于磁盘随机访问。磁盘型组件有关系数据库、NoSQL数据库等,例如MySQL、Oracle、MongoDB等数据库主要采用磁盘组织数据,以合理利用内存提升性能。而像RocketMQ、Kafka、Pulsar消息队列,也是主要将数据存储在磁盘,通过内存来提升系统的性能。
对采用磁盘存储数据的方案而言,难点之一在于如何根据系统要解决的特定场景进行合理的磁盘布局。在读多写少的情况下,采用B+树方式存储数据;在写多读少的情况下,采用LSM这类方案处理。另一个难点在于如何减少对磁盘的频繁访问。有几种解决思路:①采用Mmap进行内存映射,提升读性能;②采用缓存机制缓存经常访问的数据;③采用巧妙的数据结构布局,充分利用磁盘预读特性,以保证系统性能。
总的来说,针对写磁盘的优化,可采用顺序写提升性能,或采用异步写提升性能(异步写磁盘时需要结合WAL日志保证数据的持久化,事实上WAL日志也主要采用顺序写磁盘的特性)。针对读磁盘的优化,一方面是缓存经常访问的热点数据或者尽可能利用磁盘预读能力来降低访问磁盘的开销,另一方面是采用操作系统提供的Mmap内存映射等功能来加快读的过程。
上述存储方案上的权衡在关系数据库、NoSQL数据库和NewSQL数据库中都可以看到。抛开数据库不谈,这些存储方案的选择对于消息队列等中间件选型也是通用的。
互联网的存储组件可以根据读请求和写请求的比例分为三类:读多写少组件、写多读少组件和读多写多组件。读少写少的场景基本上属于小型系统,业务量低、数据量少,任何一种存储组件都可以用于这类场景,此处不进行讨论。本小节重点讨论读多写少和写多读少这两类组件。
如何理解此处的读和写的比例呢?这里给出一个定性描述,虽然不太严谨但容易理解:读多写少还是写多读少的主要判定条件首先是针对同一个系统而言,这样讨论读/写请求的量级才是有意义的。此外,还有一个前提,这类系统往往是磁盘型组件,因为对内存型组件而言,所有操作都是在内存中进行的,内存的读/写都很快,读/写操作基本上性能差距不是很大。例如,关系数据库MySQL就属于读多写少组件;而HBase、Cassandra这类组件则可以处理海量数据的写入,属于写多读少。
《数据密集型应用系统设计》中有一句话,即从最基本的层面看,存储组件只做两件事情:向它插入数据时,它就保存数据;之后查询时,它就应该返回之前写入的那些数据。
不管是单机系统还是分布式系统,它们都作为一个统一的系统对外提供服务。它们对外暴露给用户使用的接口不尽相同,有些是HTTP接口,有些则是SQL语言,有些甚至是可直接调用的SDK接口。但这些组件回归到单机节点上时,本质上都逃不出数据的读/写。数据的读/写又称为数据的检索与存储,而数据的检索与存储有一个专业的名词——存储引擎。这也是本书要阐述的核心内容。
本书重点讲解单机节点上基于磁盘型存储组件的存储引擎的设计原理。掌握了基于磁盘的存储引擎的设计原理后,内存型存储引擎也就不在话下了。因为对内存型存储引擎而言,只不过是去掉了磁盘这一层,存储引擎的其他内容是可以复用的。同时,在掌握了单机存储引擎的内部原理和设计思想后,上层可以构建各种各样的单机存储组件(关系数据库、NoSQL数据库、NewSQL数据库、消息队列等)。在此基础上,再结合分布式系统的数据复制、分区、共识等技术,即可构建各式各样的分布式存储组件。
下一节将讲述存储引擎的整体架构和内部的一些通用技术。限于篇幅,本书不涉及分布式系统的相关技术,对分布式技术感兴趣的读者可以自行查阅其他资料。