
下载掌阅APP,畅读海量书库
立即打开



在1.1节中,我们亲眼见证了ChatGPT的惊人创造力,能够在几秒内以李白的豪放派风格创作出美妙的诗歌。那么,下面让我们来深入探讨大模型是如何拥有一个跨越多领域、穿越古今的“超级大脑”的。
大模型丰富的知识储备来自其庞大的训练数据集,其中包括互联网上各种各样的文本,从新闻文章到小说、论文以及其他网页内容。各种各样的数据集丰富了大模型对语言和知识的理解,使它能够涵盖多领域。数据集是其获得知识的来源,据统计,ChatGPT的数据集主要采集于以下几个数据源。
(1)BooksCorpus:这是一个包含11,038本英文电子图书的语料库,共有74亿个单词。
(2)WebText:这是一个从互联网上抓取的大规模文本数据集,包括超过8万个网站的文本数据,共有13亿个单词。
(3)Common Crawl:这是一个存档互联网上公开可用的数据集,包括数百亿个网页、网站和其他类型的文本数据。
(4)Wikipedia:这是一个由志愿者编辑的百科全书,包括各种领域的知识和信息,是一个非常有价值的语言资源。
在海量数据的基础上,大模型采用了基于变换器(Transformer)模型的深度神经网络模型,获得了处理长文本和复杂语法的能力,同时保持了上下文的一致性,帮助ChatGPT生成更准确、连贯的文本。模型的本质是一个概率计算的过程,如图1-4所示为一个基础的语言概率模型示意图,以不同的概率和选择策略决定生成的文本。
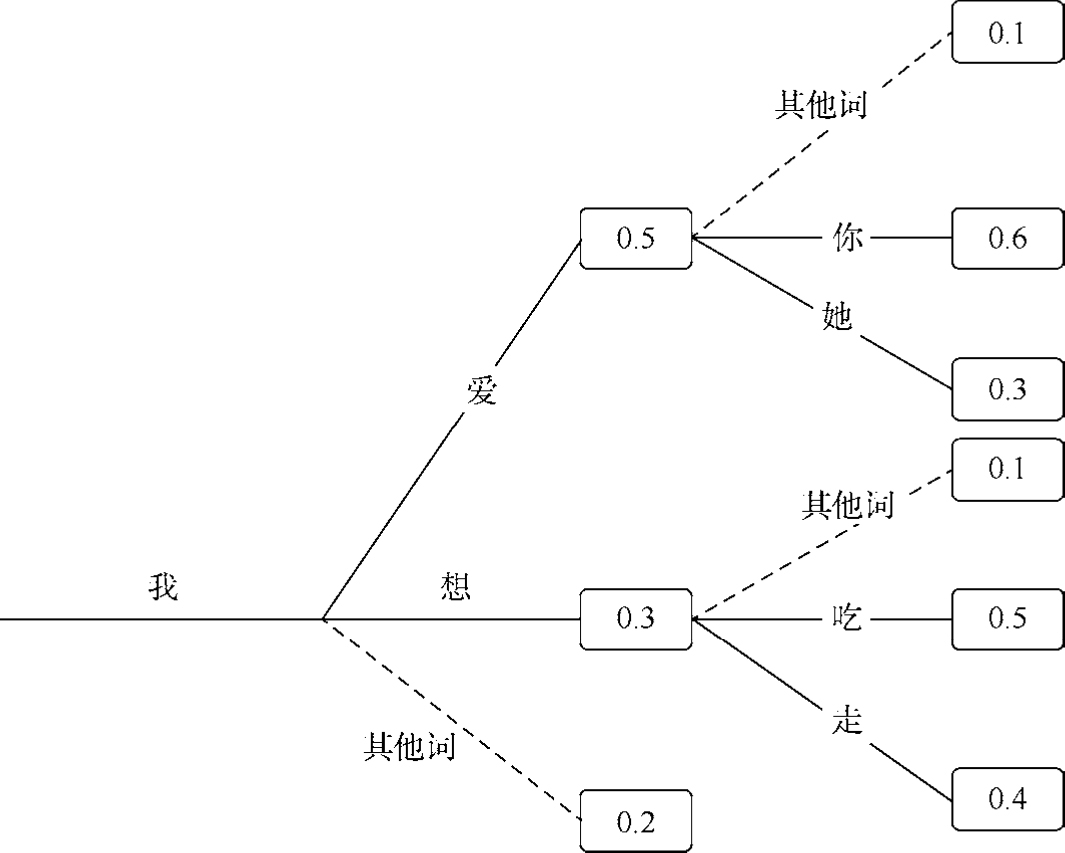
图1-4 语言模型示意图
在本例中,生成不同文本的概率如下。
「我爱你」概率:0.5×0.6=0.3
「我爱她」概率:0.5×0.3=0.15
「我想吃」概率:0.3×0.5=0.15
「我想走」概率:0.4×0.3=0.12
在模型生成文本时,选择“我爱你”,还是“我爱她”,取决于大模型的参数设置,即温度和TOP_P,温度值决定了文本的随机性,较高的温度值会提升返回的随机值,较低的温度值会使模型倾向于返回可能性更高的词语。TOP_P是GPT2版本中引入的一个参数,选择词语时在累积概率>P的词语中进行选择,在概率分布相对均匀的情况下,可选词语会比较多;在分布方差较大的情况下,选择会少一些。
模型的训练包括两个过程,即预训练与有监督微调(SFT)。在预训练阶段,大规模文本数据被收集和准备用于模型的预训练。这个语料库通常包含来自互联网的各种文本,包括网页、社交媒体帖子、新闻文章等。一个大型的神经网络模型在经过构建和预训练之后,通过在上述文本语料库上进行自监督学习。在自监督学习中,模型通过在上下文中预测缺失的单词或标记来学习语言的语法、语义和世界知识。预训练的模型通常由多个Transformer层组成,用于建模文本序列中的依赖关系。这些模型可以包含数亿或数十亿的参数。经过预训练后,模型的参数包含了大量的知识,可以被视为通用的“语言理解”模型,但还需要微调以适应特定的任务。
在微调阶段,模型被进一步训练以适应特定的自然语言处理(Natural Language Processing,NLP)任务。为此,使用特定任务的标记数据集,如文本分类、文本生成、情感分析等。微调阶段通常包括添加额外的神经网络层,这些层根据任务的需求自定义,模型会经过特定任务的数据集的多次训练,逐渐适应该任务。
大模型之所以能够理解人类的复杂任务,在预训练—微调模式的基础上,还有一个关键的技术,即基于人类反馈的强化学习方式(Reinforcement Learning from Human Feedback,RLHF),通俗的表达就是从人类的反馈中学习。听起来感觉好像很容易想到,实际上却经历了不断探索才有所发现,可以说没有RLHF,ChatGPT的通用性远远达不到现在这种程度。微调过程很容易理解,如图1-5所示,经历了三个步骤。
步骤1 有监督微调(Supervised Fine-Tuning,SFT)整个过程是在已标注数据上进行微调训练完成的。这里的数据是指用户在对话框中输入的提示词和对ChatGPT输出内容的回复,帮助大模型增强在特定领域的能力。
步骤2 奖励模型(Reward Model,RM)。当前一步的SFT过程生成输出文本后,标注人员对这些输出结果进行排序。然后每次从输出结果中选取2个来训练这个奖励模型,使模型学习评价效果。这一步骤非常关键,它就是所谓的Human Feedback,用来引导下一步模型的进化方向。
步骤3 强化学习(Reinforcement Learning,RL)在步骤2的RM过程对输出结果评分后,奖励模型将评分回传给模型更新参数,更新模型时会考虑参数每一个词的输出和第一步SFT输出之间的差异性,尽可能使两者相似,这个过程使用的优化策略是图1-5中的近端策略优化(Proximal Policy Optimization,PPO),可以有效缓解强化学习的过度优化。
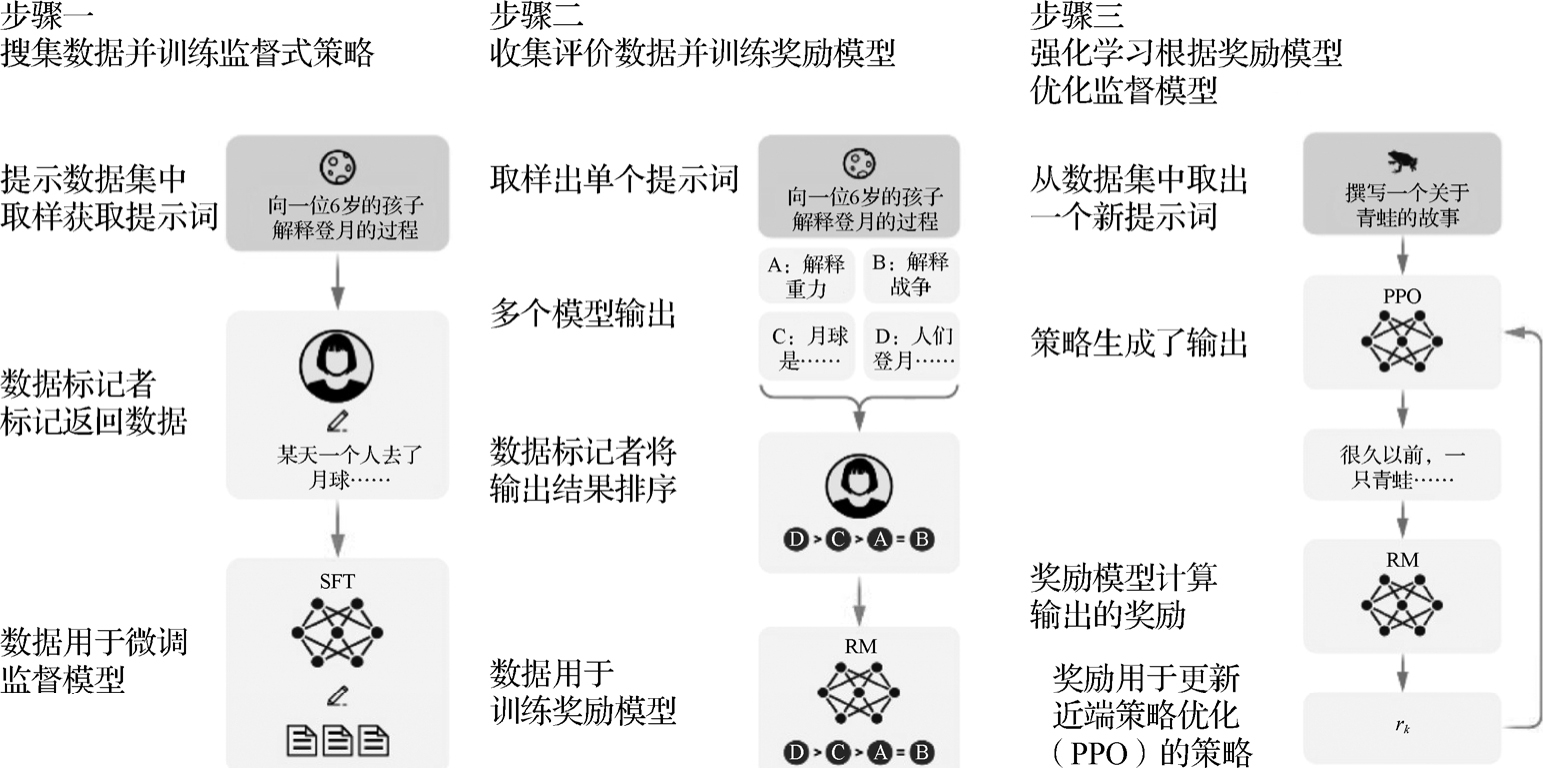
图1-5 微调过程示意图
大模型在训练和计算方面采用了大规模的分布式计算集群和高性能GPU,主要使用了数据并行、流水线并行和张量并行的策略,使得它能够进行大规模的训练和推理,快速响应用户的请求,在几秒内回复用户的复杂任务。
在GPT系列发布后,研发团队不断努力改进其效果,从GPT-1、GPT-2、GPT-3到爆火的GPT-3.5,再到如今的GPT-4和GPT-4 Turbo,一直在修复偏见、妄想、计算不准确等问题,并通过迭代和微调来提高模型的性能和适应性,以确保其更好地满足用户需求。
总而言之,大模型之所以如此强大,是因为它汇聚了大规模的数据、深度的神经网络、不断地学习反馈、强大的计算资源及持续的改进。这个“超级大脑”能够跨越多领域,穿越古今,用以探索、创造和解决各种问题。