
下载掌阅APP,畅读海量书库
立即打开



一个通用的网络爬虫基本工作流程如图1.1所示。
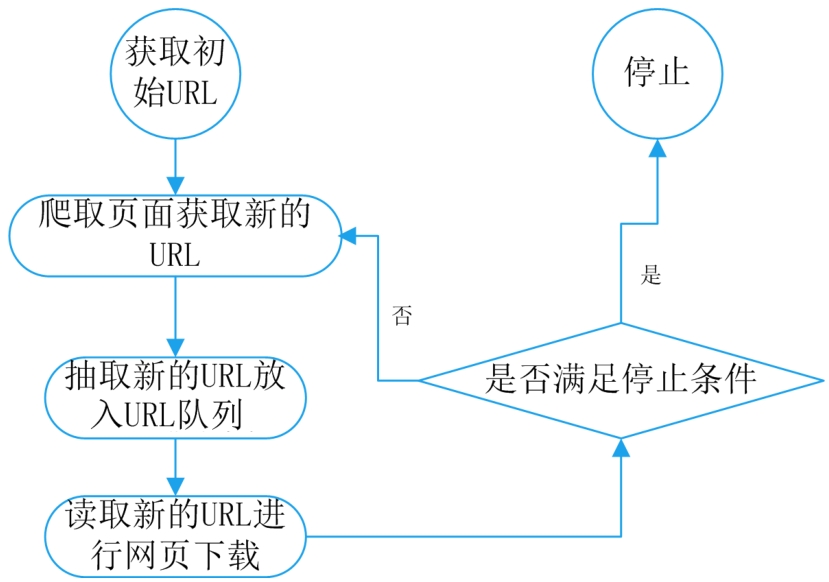
图1.1 通用的网络爬虫基本工作流程
网络爬虫的基本工作流程如下:
(1)获取初始的URL,该URL地址是用户自己制定的初始爬取的网页。
(2)爬取对应URL地址的网页时,获取新的URL地址。
(3)将新的URL地址放入URL队列。
(4)从URL队列中读取新的URL,然后依据新的URL爬取网页,同时从新的网页中获取新的URL地址,重复上述爬取过程。
(5)设置停止条件,如果没有设置停止条件,则爬虫会一直爬取下去,直到无法获取新的URL地址。设置停止条件后,爬虫将会在满足停止条件时停止爬取。