
下载掌阅APP,畅读海量书库
立即打开



通过上一节的学习可知,urlopen()方法能够发送一个最基本的网络请求,但这并不是一个完整的网络请求。如果要构建一个完整的网络请求,还需要在请求中添加如Headers、Cookie及代理IP地址等内容,这样才能更好地模拟一个浏览器所发送的网络请求。Request类则可以构建一个有多种功能的请求对象,其语法格式如下:

参数说明:
☑ url:需要访问网站的URL完整地址。
☑ data:该参数默认为None,通过该参数确认请求方式,如果是None,则表示请求方式为GET,否则请求方式为POST。在发送POST请求时,参数data需要以字典类型的数据作为参数值,并且需要将字典类型的参数值转换为字节类型的数据才可以实现POST请求。
☑ headers:设置请求头部信息,该参数为字典类型。添加请求头信息最常见的用法就是修改User-Agent来伪装成浏览器,例如headers={'User-Agent':'Mozilla/5.0(Windows NT 10.0;WOW64)Ap-pleWebKit/537.36(KHTML,like Gecko)Chrome/83.0.4103.61 Safari/537.36'},表示伪装成谷歌浏览器进行网络请求。
☑ origin_req_host:用于设置请求方的host名称或者IP地址。
☑ unverifiable:用于设置网页是否需要验证,默认是False。
☑ method:用于设置请求方式,如GET、POST等,默认为GET请求。
设置请求头参数是为了模拟浏览器向网页后台发送网络请求,这样可以绕过服务器的反爬措施。使用urlopen()方法发送网络请求时,其本身并没有设置请求头参数,所以向https://www.httpbin.org/post请求测试地址发送请求时,返回的信息中headers将显示如图2.4所示的默认值。
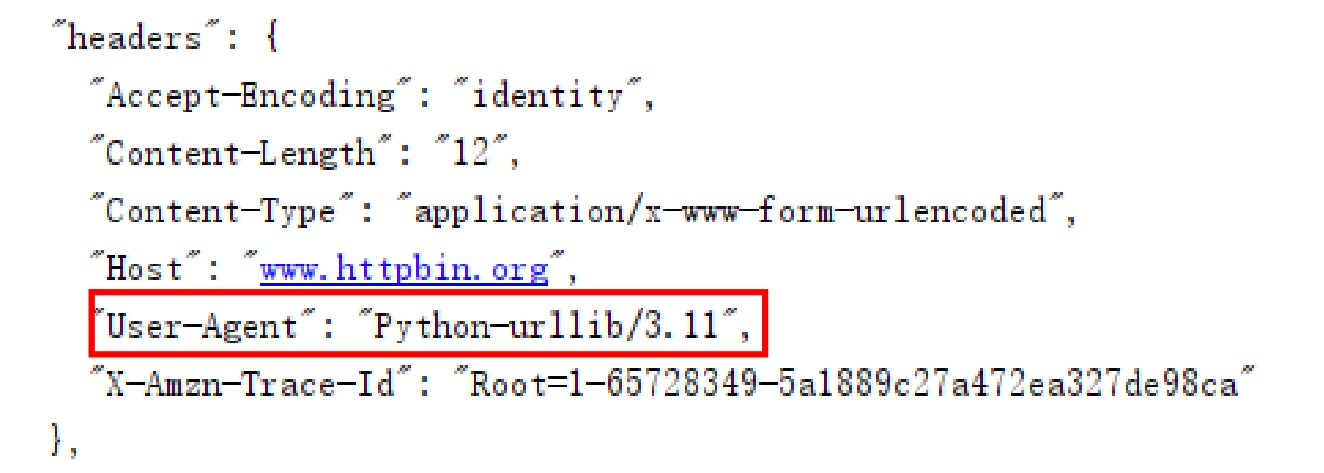
图2.4 headers默认值
所以在设置请求头信息前,需要在浏览器中找到一个有效的请求头信息。以谷歌浏览器为例,首先按下“F12”键打开“开发者工具”,然后选择“Network”,接着在浏览器地址栏中打开任意一个网页(如https://www.python.org/),在请求列表中选择一项请求信息,最后在“Headers”选项中找到请求头信息。具体步骤如图2.5所示。
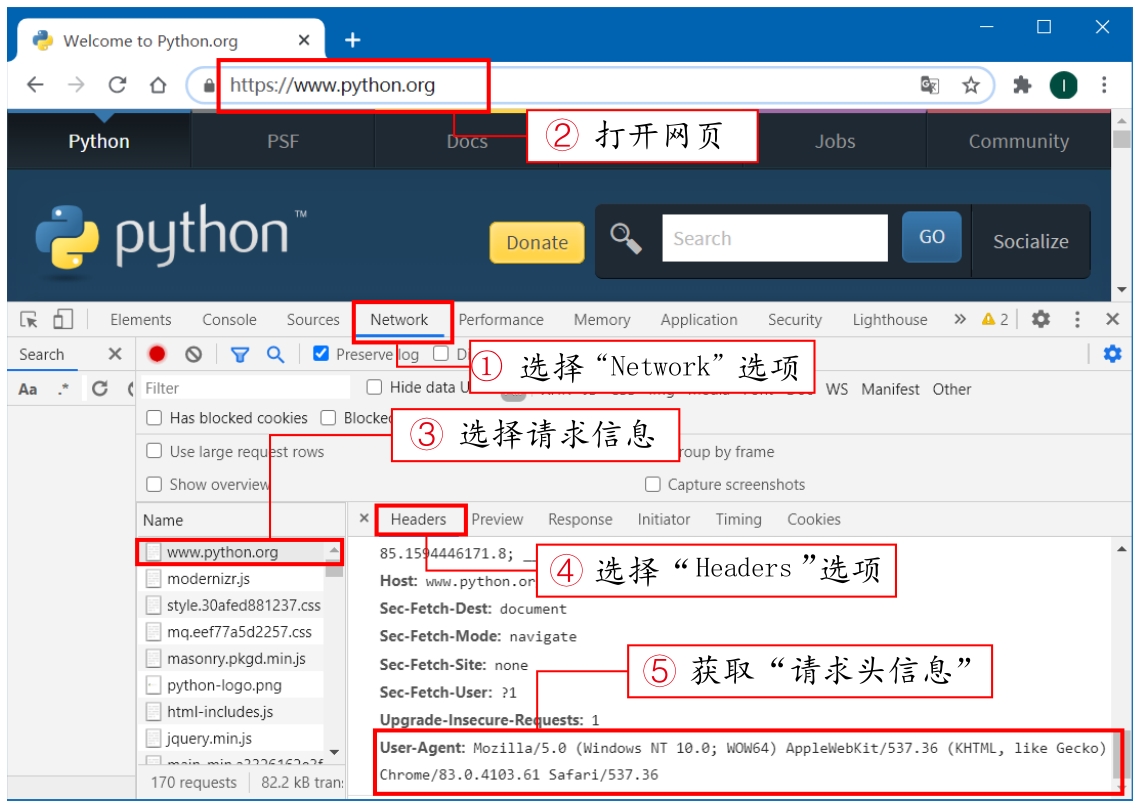
图2.5 获取请求头信息
(实例位置:资源包\Code\02\04)
如果需要设置请求头信息,首先通过Request类构造一个带有headers请求头信息的Request对象,然后为urlopen()方法传入Request对象,再进行网络请求的发送。示例代码如下:
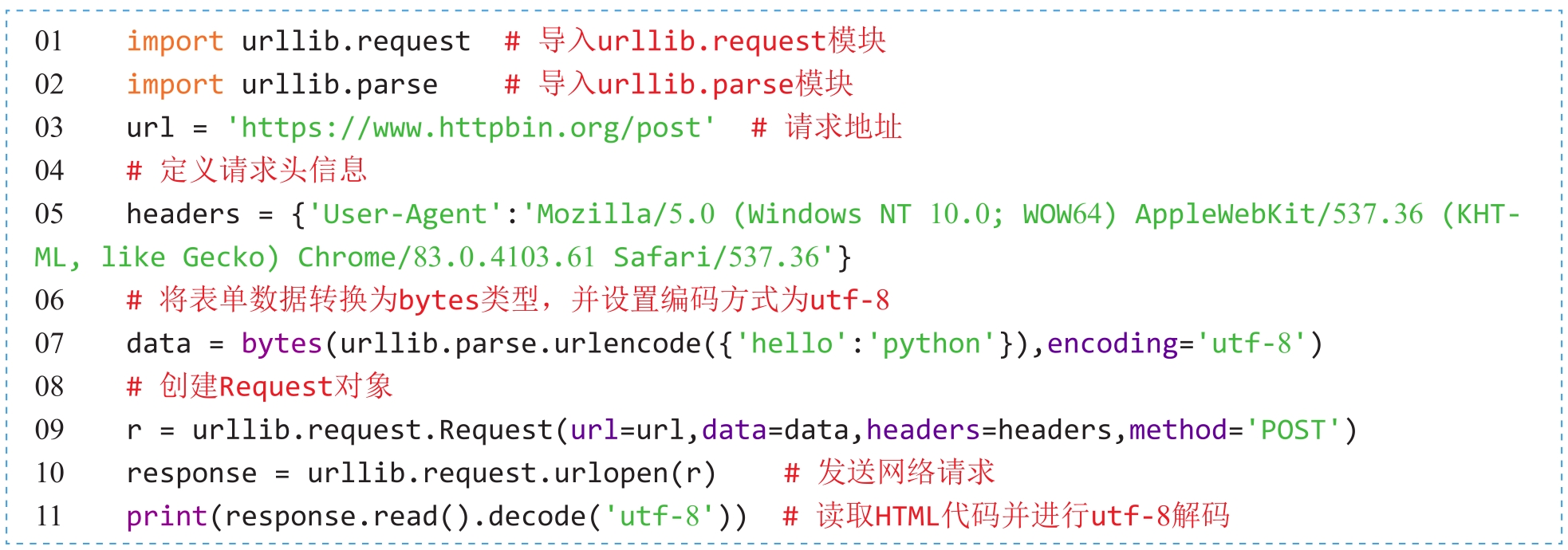
程序运行后,返回的headers信息如图2.6所示。

图2.6 设置请求头的运行结果
从实例2.4中并没有直观地看出设置请求头的好处,接下来以请求“百度”为例,测试设置请求头的绝对优势。在没有设置请求头的情况下直接使用urlopen()方法向https://www.baidu.com/地址发送网络请求,将返回如图2.7所示的HTML代码。

图2.7 未设置请求头所返回的HTML代码
首先创建具有请求头信息的Request对象,然后使用urlopen()方法向“百度”地址发送一个GET请求。关键代码如下:

程序运行以后,将返回“某度”正常的HTML代码,如图2.8所示。
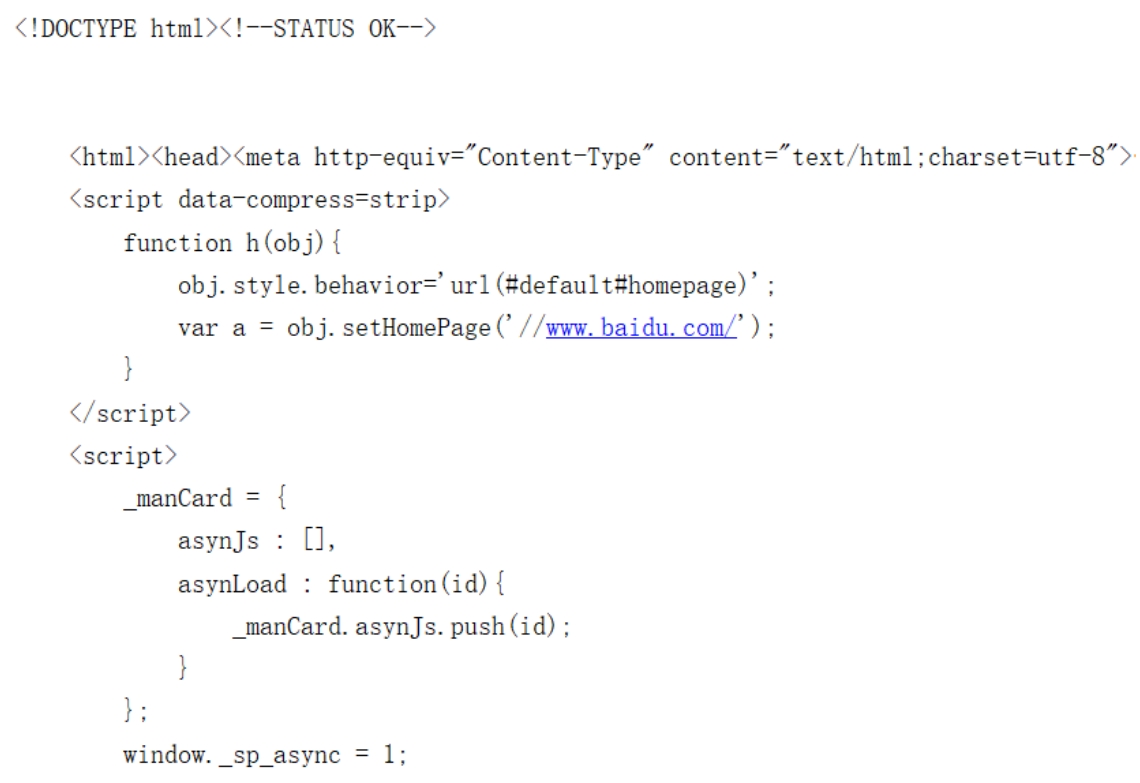
图2.8 设置请求头所返回的HTML代码
Cookie是服务器向客户端返回响应数据时所留下的标记,当客户端再次访问服务器时,将携带这个标记。一般登录一个页面时,在登录成功后,会在浏览器的Cookie中保留一些信息;当浏览器再次访问时会携带Cookie中的信息,经过服务器核对后,便可以确认当前用户已经登录过,此时可以直接将登录后的数据返回。
在使用爬虫获取网页登录后的数据时,除了使用模拟登录,还可以获取登录后的Cookie,然后利用这个Cookie再次发送请求时,就能以登录用户的身份获取数据。下面以获取图2.9中登录后的用户名信息为例,具体实现步骤如下。
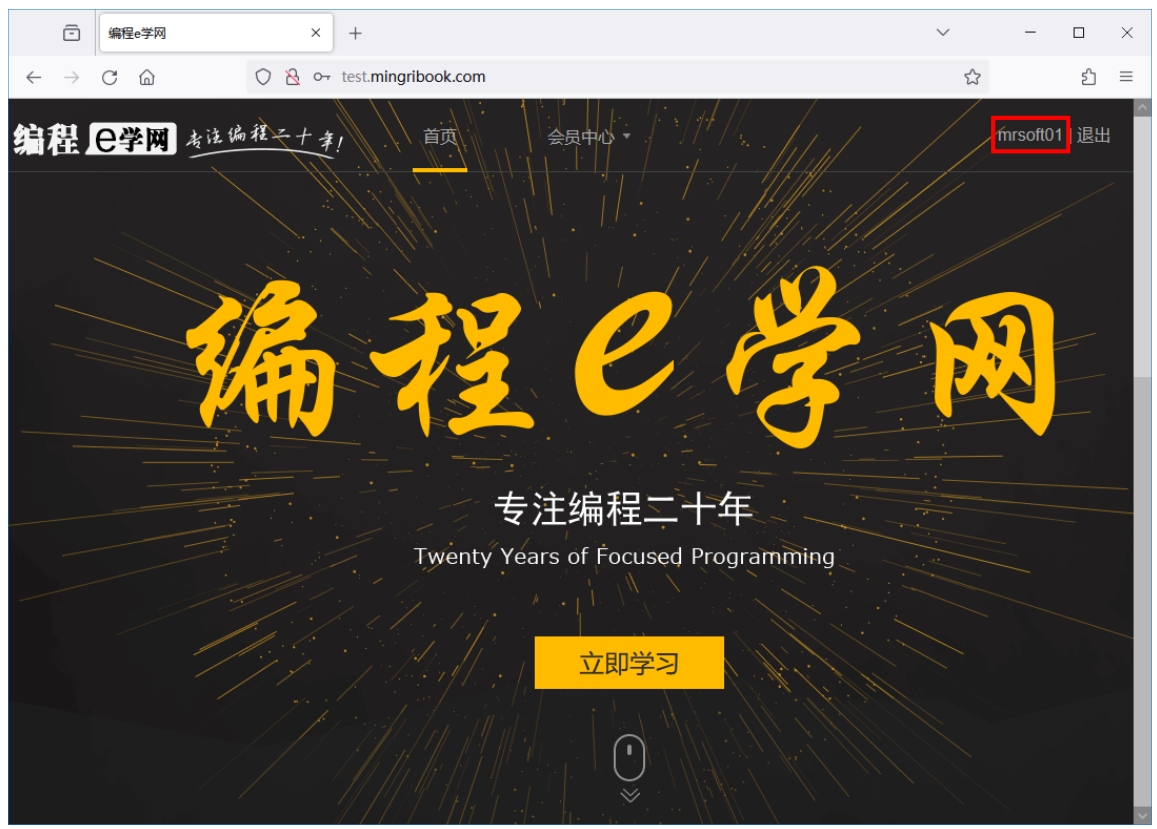
图2.9 登录后的用户名信息
1.模拟登录
(实例位置:资源包\Code\02\05)
在实现爬虫的模拟登录时,首选需要获取登录验证的请求地址,然后通过POST请求的方式将正确的用户名与密码发送至登录验证的后台地址。
(1)在火狐浏览器中打开网页后,单击网页右上角的“登录”按钮,此时将弹出如图2.10所示的登录窗口。
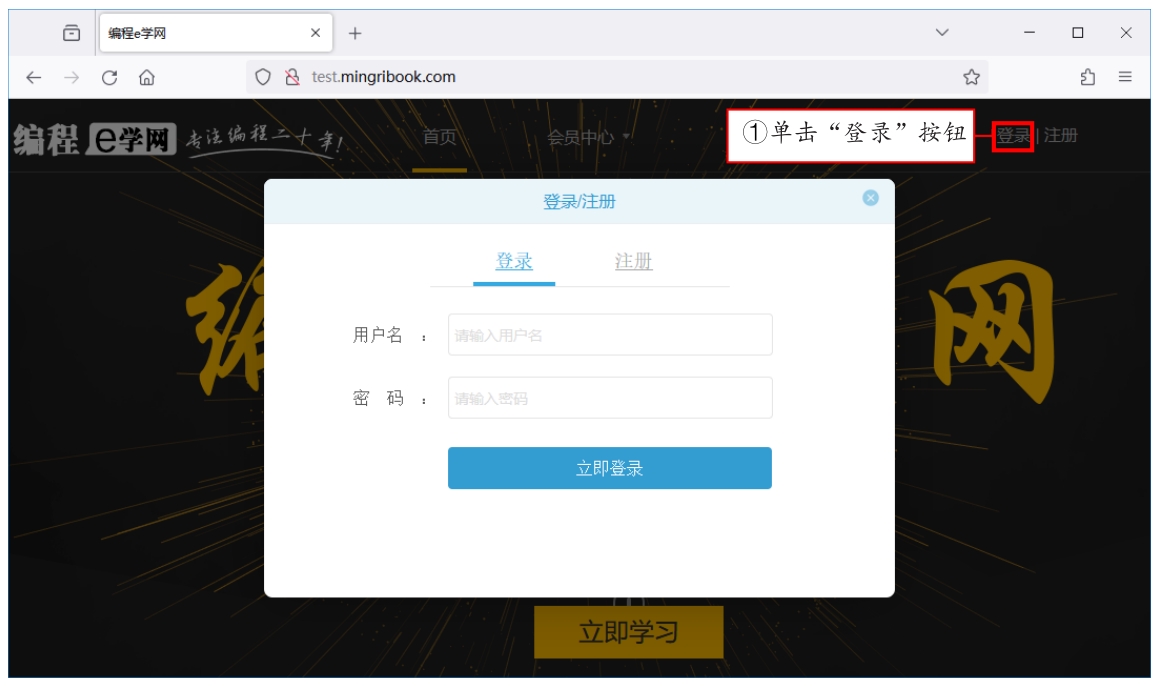
图2.10 登录窗口
(2)按下“F12”键,打开“开发者工具”,接着单击顶部工具栏中的“网络”,再单击右侧的设置按钮,勾选“持续记录”,如图2.11所示。
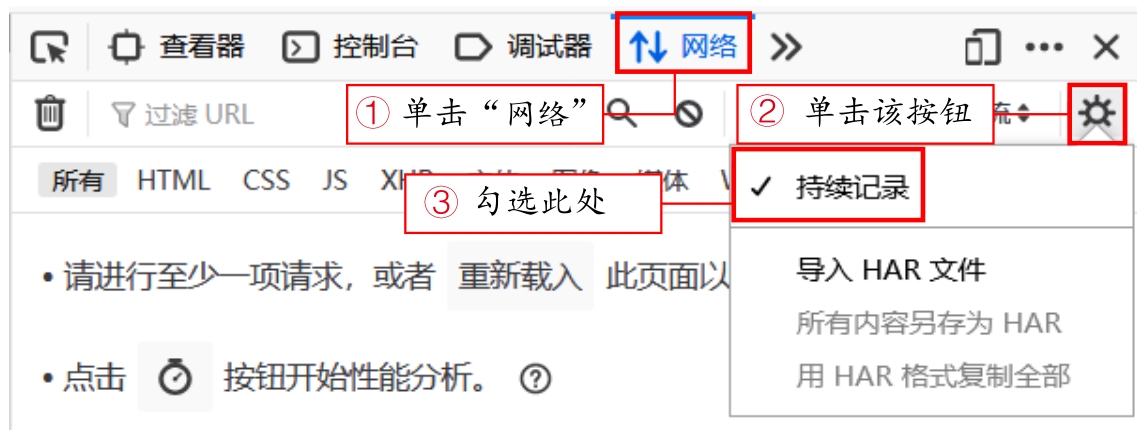
图2.11 设置网络持续记录
(3)在登录窗口中,首先输入正确的用户名与密码,然后单击“立即登录”按钮,接着在“开发者工具”的网络请求列表中找到文件名为“chklogin.html”的网络请求信息,如图2.12所示。
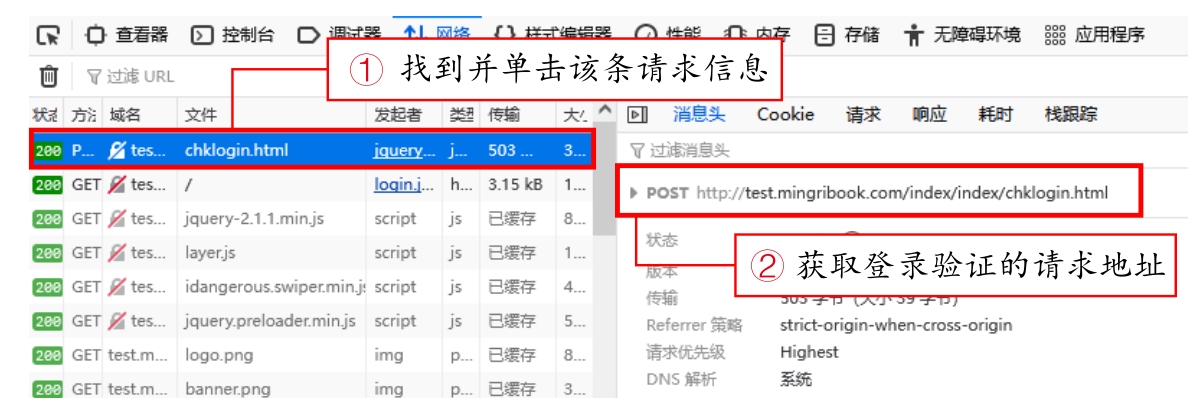
图2.12 找到文件名为“chklogin.html”的网络请求信息
该步骤中的用户名与密码,可以提前在网页的注册页面中进行注册。
(4)在图2.12中已经找到了登录验证的请求地址,接着在“登录验证请求地址”的上方单击“请求”选项,获取登录验证请求所需要的表单数据,如图2.13所示。

图2.13 查看表单数据
(5)获取了网页登录验证的请求地址与表单数据后,可通过urllib.request子模块中的POST请求方式,实现网页的模拟登录。代码如下:

程序运行结果如下:

2.获取Cookie
(实例位置:资源包\Code\02\06)
上一节已经成功地通过爬虫实现了网页的模拟登录,接下来需要实现在模拟登录的过程中获取登录成功所生成的Cookie信息。在获取Cookie信息时,首先需要创建一个CookieJar对象,然后生成Cookie处理器,接着创建opener对象,再通过opener.open()发送登录请求,登录成功后获取Cookie内容。代码如下:


程序运行结果如下:

(实例位置:资源包\Code\02\07)
除了简单地获取登录后的Cookie信息,还可以将Cookie信息保存成指定的文件格式,下次登录请求时直接读取文件中的Cookie信息即可。如果需要将Cookie信息保存为LWP格式的Cookie文件,则需要先创建LWPCookieJar对象,再通过cookie.save()方法将Cookie信息保存成文件。代码如下:
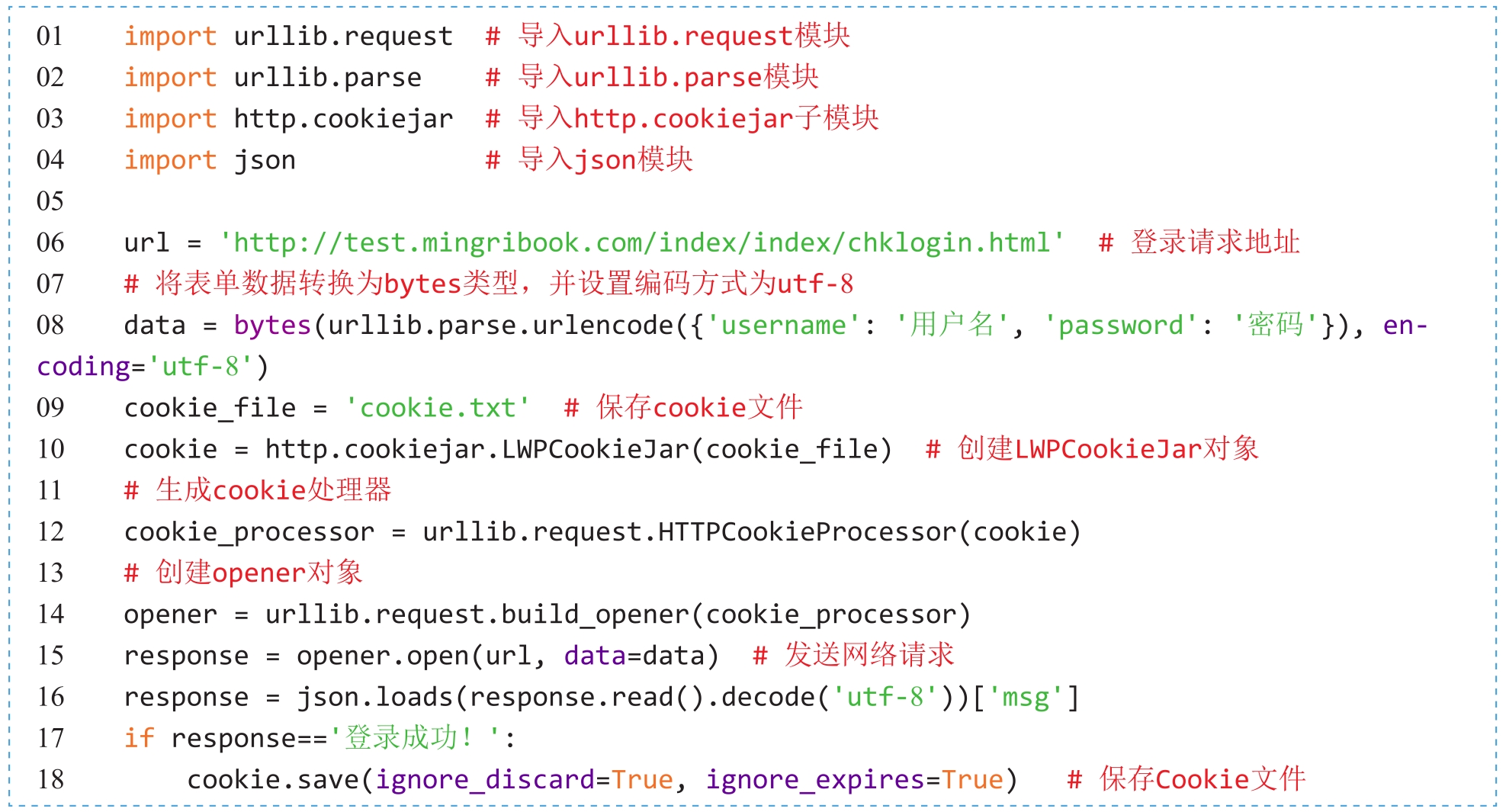
程序运行完成以后,将自动生成一个cookie.txt文件,文件内容如图2.14所示。
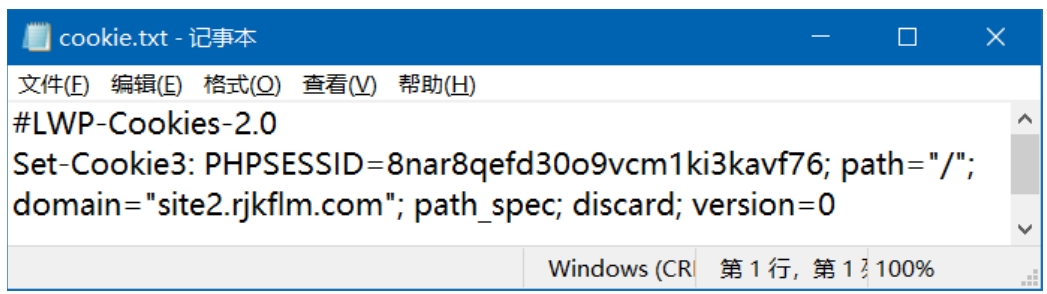
图2.14 cookie.txt文件内容
3.使用Cookie
有了Cookie文件,接下来需要调用cookie.load()方法来读取本地的Cookie文件,然后再次向登录后的页面发送请求。由“模拟登录”一节中的“网络请求列表”可以看出,登录验证的请求通过后将自动向登录后的页面地址再次发送请求,如图2.15所示。
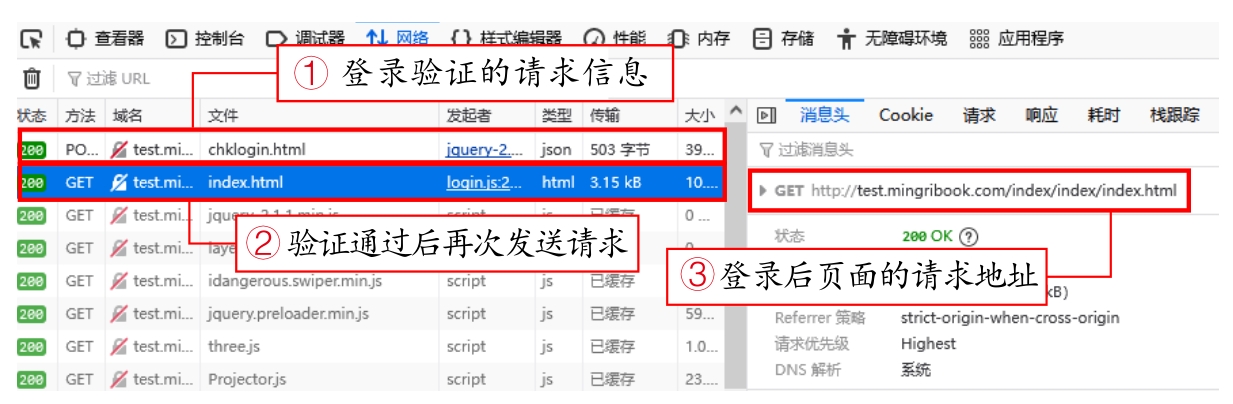
图2.15 获取再次发送的请求地址
(实例位置:资源包\Code\02\08)
获取登录后页面的请求地址之后,接下来只需要使用cookie.txt文件中的Cookie信息发送请求,便可以获取登录后页面中的用户名信息。代码如下:
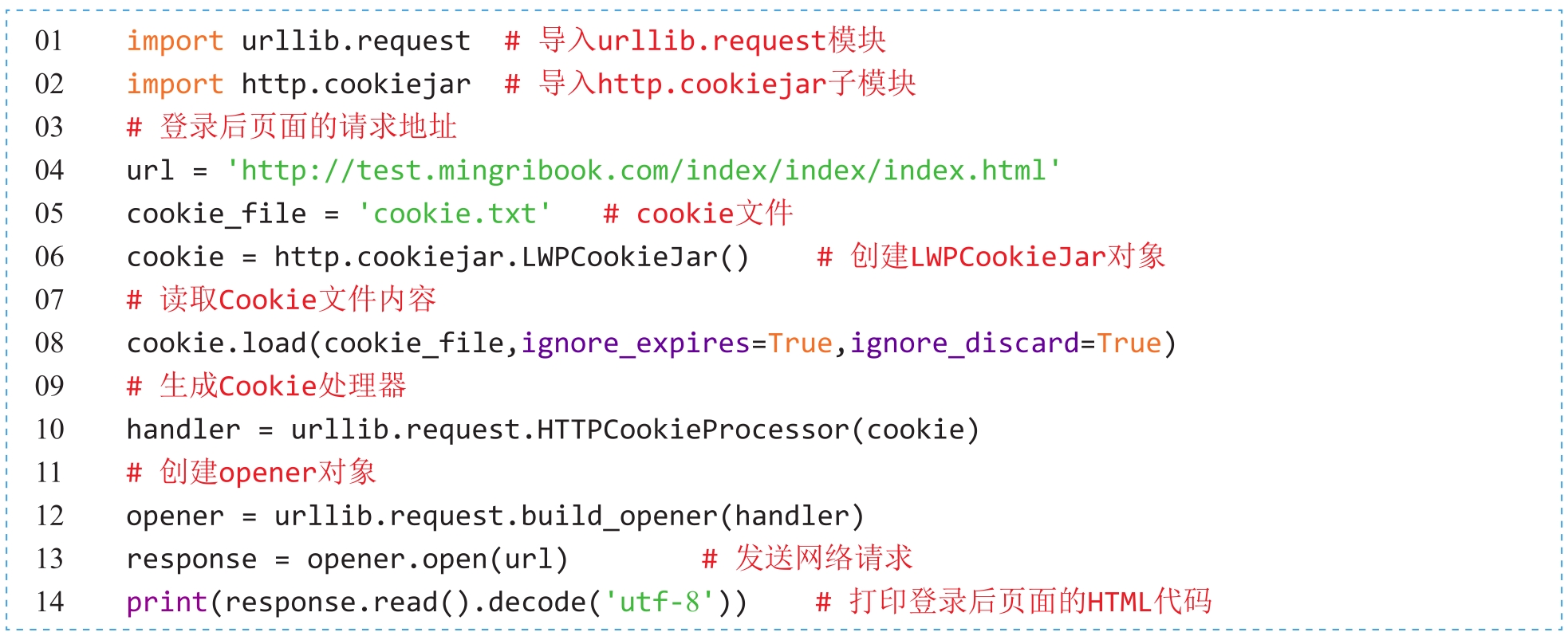
程序运行完成后,在控制台中搜索自己注册的用户名,将自动定位登录后显示用户名信息所对应的HTML代码标签,如图2.16所示。
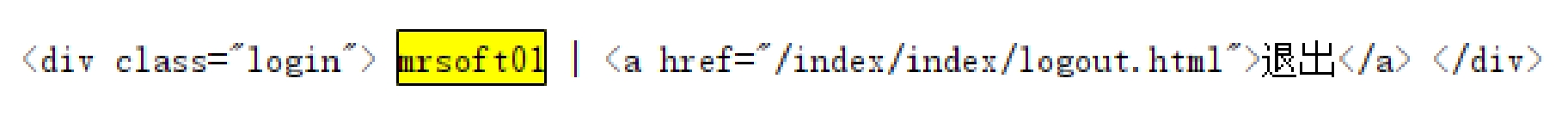
图2.16 用户名信息所对应的HTML代码标签
反爬虫技术有很多,其中最为常见的就是通过客户端的IP地址判断当前请求是否为爬虫。因为如果在短时间内同一个IP地址访问了后台服务器的大量数据,那么服务器会将该客户端视为爬虫。当服务器发现爬虫在访问数据时,就会对当前客户端所使用的IP地址进行临时或永久禁用,这样使用已经禁用的IP地址是无法获取后台数据的。
解决这样的反爬虫技术就需要对网络请求设置代理IP地址,最好是每发送一次请求就设置一个新的代理IP地址,让后台服务器永远都无法知道是谁在获取它的数据资源。
(实例位置:资源包\Code\02\09)
使用urllib模块设置代理IP地址是比较简单的,首先需要创建ProxyHandler对象,其参数为字典类型的代理IP地址,键名为协议类型(如HTTP或者HTTPS),值为代理链接。然后利用ProxyHan-dler对象与build_opener()方法构建一个新的opener对象,最后发送网络请求即可。代码如下:

程序运行结果如图2.17所示。
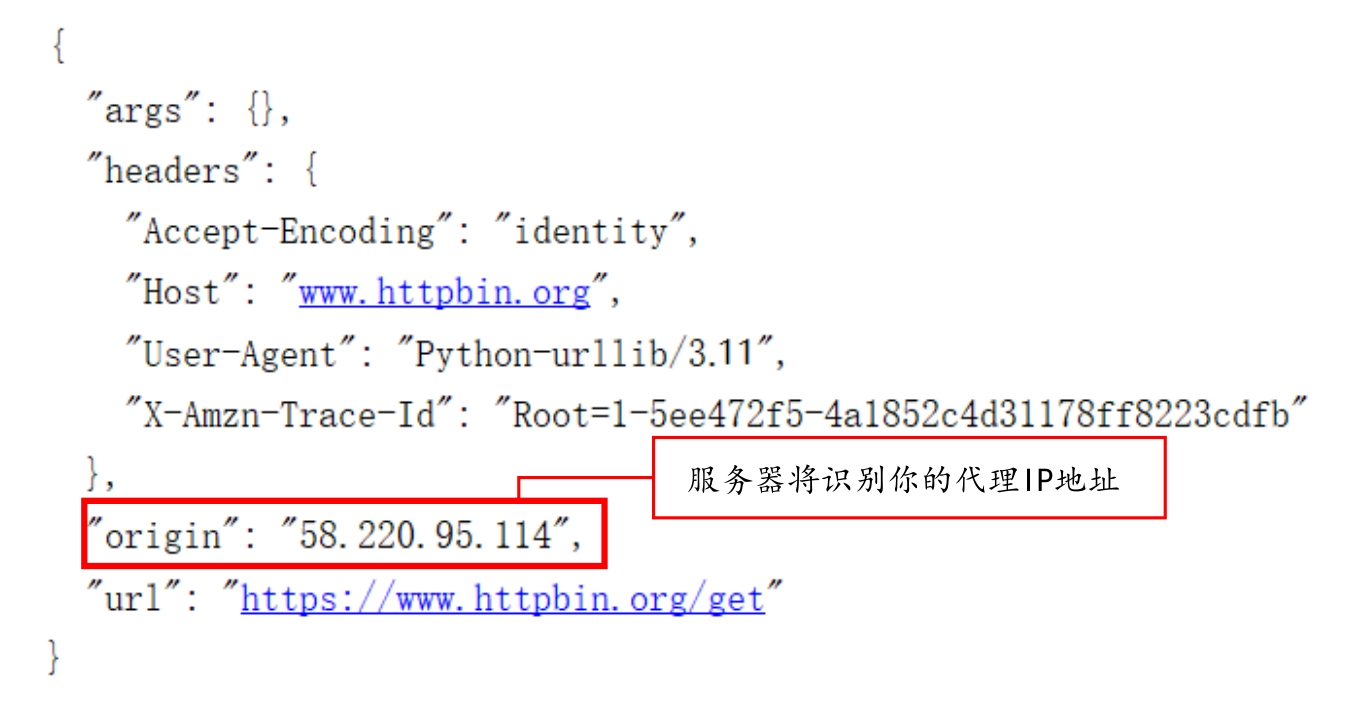
图2.17 返回服务器所识别的代理IP地址
免费代理存活的时间比较短,如果失效,读者可以自己上网查找正确有效的代理IP地址。或者参考3.3.2节与3.3.3节来获取免费有效的代理IP地址。