
下载掌阅APP,畅读海量书库
立即打开



机器学习可以分成三大类别,即监督式学习、非监督式学习和强化学习。在监督式学习中,除了给出数据,还要给出标签。根据标签,又可以分成分类学习和回归学习两种。处理离散变量往往使用分类模型,处理连续变量往往使用回归模型。本章主要介绍一个在历史上具有里程碑作用的分类学习模型。
机器学习的第一个分类的模型在历史上称为感知机模型。感知机模型是一个监督式分类学习模型。分类问题的标签就是离散的,有时可以简单到两个取值,如{0,1},当然更多的离散标签也是可以的。在实际应用中这种做法很常见。例如,客户的精准画像可以分成若干种;信用卡的申请者可以被分成同意或者拒绝;在金融市场的预测中,市场的下一个阶段可以分成涨或跌。在上述例子中,我们需要给出预测的都是两种或者若干种分类。
为了能够做到这样离散分类,需要对被分类的主体进行来自数据上的刻画。刻画一个主体,可以用一个实数来刻画,这个实数就是一个维度或者一个特征。用一个维度或者特征刻画主体太过简单。为了从更多侧面来描述主体,就需要提取更多特征。这样每个数据就是由这些特征组成的。每个数据都是下面的向量
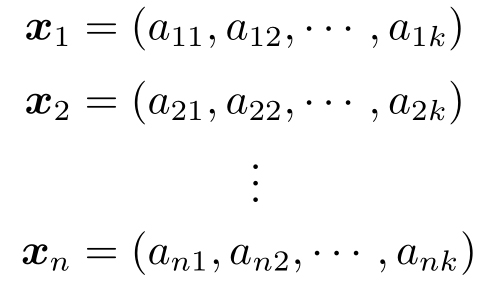
每一个数据都对应于
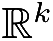 空间中的一个点
空间中的一个点
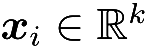 ,i
=1,2,···
,n
。每个数据具有的分量可以称为特征,所以上述数据就有
k
个特征。除了给出数据,还要给出标签。对应于每一个数据,都有一个标签
y
i
,其中
y
i
∈{-1,1}。这就是一个典型的二分类的机器学习问题。
,i
=1,2,···
,n
。每个数据具有的分量可以称为特征,所以上述数据就有
k
个特征。除了给出数据,还要给出标签。对应于每一个数据,都有一个标签
y
i
,其中
y
i
∈{-1,1}。这就是一个典型的二分类的机器学习问题。
现在的问题就是寻找
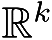 空间中的这组点的位置和对应分类产生的对应关系。感知机模型就是为了解决这个问题而产生的。
空间中的这组点的位置和对应分类产生的对应关系。感知机模型就是为了解决这个问题而产生的。