
下载掌阅APP,畅读海量书库
立即打开



正如我们看到的,序对是一种基本“粘合剂”,我们可以用它构造复合数据对象。图2.2展示了以图的形式表示序对的标准方式,其中的序对通过pair(1, 2)产生。在这种称为 盒子和指针表示法 的表示中,每个复合对象用一个指向盒子的 指针 表示。表示一个序对的盒子包括两个部分,其左边部分包含该序对的head,右边部分里包含相应的tail。
我们已经看到,pair不仅可以用于组合数值,也可以用于组合序对(你在做练习2.2和练习2.3时已经——或者说应该——熟悉这一事实)。作为这种情况的推论,序对是一种通用的砌块,我们可以利用它构造所有种类的数据结构。图2.3显示的是组合数值1、2、3、4的两种不同方法。
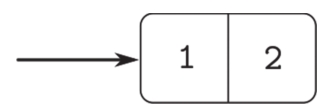
图2.2 pair(1, 2)的盒子和指针表示
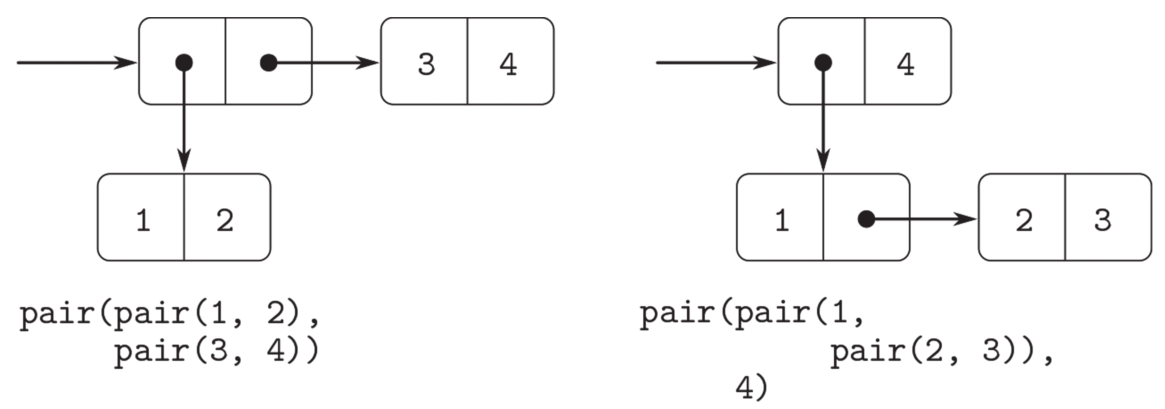
图2.3 用序对组合数值1、2、3、4的两种不同方式
可以建立元素本身也是序对的序对,这是表结构能作为表示工具的根本。我们把这种能力称为pair的
闭包性质
。一般而言,如果某种组合数据对象的操作满足闭包性质,通过用它组合数据对象得到的结果,就还能用这个操作再组合
 。闭包性质是任何组合功能的威力的关键,因为这使我们能建立
层次性
的结构——这种结构由一些部分构成,而其中部分又可能由一些部分构成,而且可以如此继续下去。
。闭包性质是任何组合功能的威力的关键,因为这使我们能建立
层次性
的结构——这种结构由一些部分构成,而其中部分又可能由一些部分构成,而且可以如此继续下去。
在第1章的开始,我们处理函数问题时就用到了闭包性质,因为除了最简单的程序外,所有程序都依赖一个事实:一个组合式的成员本身还可以是组合式。在这一节里,我们要着手研究复合数据具有闭包性质的一些后果。我们要描述一些方便使用的技术,如用序对表示序列和树。我们还要给出一种能生动地展示闭包性质的图形语言。
用序对可以构造出许多非常有用的结构,其中一类就是序列,它们是一批数据对象的有序汇集。显然,用序对表示序列的方式很多,最直接的方式如图2.4所示:序列1、2、3、4用一个序对的链条表示,其中每个序对的head对应链中一个项,tail则是链中的下一个序对。最后一个序对的tail标记序列结束,在盒子指针图中用一条对角线表示,在JavaScript的程序里用基本值 null 。整个序列可以通过嵌套的pair操作构造出来:


图2.4 将序列1, 2, 3, 4表示为序对的链
通过嵌套的pair应用构造出的这种序对的序列称为
表
。为了更方便地构造这种表,我们的JavaScript环境提供了一个基本操作list
。上面序列也可以通过list(1, 2, 3, 4)生成。一般说:

等价于
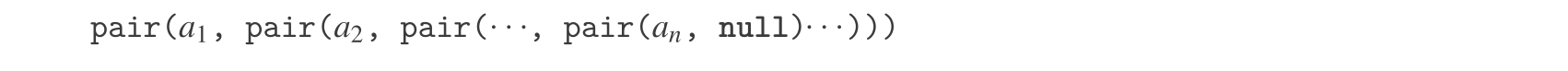
我们的解释器用一种文本形式打印盒子-指针图,我们称其为 盒子记法 。pair(1, 2)的结果将打印为[1, 2]。图2.4里的数据对象打印为[1, [2, [3, [4, null ]]]]:

我们可以认为head选取表中的第一项,tail选取表中除去第一项之后剩下的所有项形成的子表。嵌套地应用head和tail,就能取出表里的第二、第三以及后面的各项。构造函数pair用于构造与原表类似的表,但前面增加了一项:

值
null
用于表示序对链结束,也可以看作是不包含任何元素的序列,即所谓的
空表
。
盒子记法有时比较难看明白。在本书中,如果我们想说明一个数据结构具有表的特征,将会使用另一种 表记法 。只要可行,在表示数据结构时,我们将用函数list的应用来表示其求值能得到的结果。例如,对于用盒子记法描述的结构:
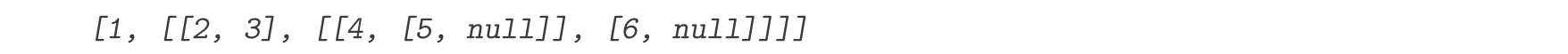
采用表记法,我们将其写成
:

表操作
用序对将元素的序列表示为表后,随之而来的一种常用程序设计技术,就是通过对表反复向下求tail的方式完成对表的操作。例如,函数list_ref以一个表和一个数 n 为实参,返回表里的第 n 个项(人们习惯令表元素编号从0开始)。计算list_ref的方法如下:
●对 n =0,list_ref应该返回表的head。
●否则,list_ref返回表的tail部分的第( n -1)项。

我们经常需要通过反复向下求tail的方式扫过整个表,为了支持这类操作,我们的JavaScript环境里有一个基本操作is_null,它检查自己的参数是否为空表。函数length返回表中项数,其声明很好地说明了这种典型应用模式:

函数length实现了一种简单的递归方案,其中的归约步骤是:
●任意表的length就是该表的tail的length加一。
顺序地反复这样应用,直至到达基础情况:
●空表的length是0。
我们也可以用迭代的风格计算length:

另一种常用的程序设计技术,是在对一个表向下求tail的过程中,通过不断用pair在前面加入元素的方式构造一个作为结果的表。函数append就是这样做的,这个函数以两个表为参数,组合起它们的元素,做成一个新表:

append也通过一种递归方案实现。要append两个表list1和list2,按如下方式做:
●如果list1是空表,结果就是list2。
●否则,首先做出list1的tail和list2的append,然后再把list1的head通过pair加到结果的前面:

练习2.17 请声明一个函数last_pair,对给定的(非空)表,它返回只包含表中最后一个元素的表:

练习2.18 请声明一个函数reverse,它以一个表为参数,返回的表包含的元素与参数表一样,但它们排列的顺序与参数表相反:

练习2.19 现在重新考虑1.2.2节的兑换零钱方式的计数程序。如果很容易改变程序里用的兑换币种,那当然就更好了。譬如说,我们就也能计算一英镑的不同兑换方式数。在写前面的程序时,有关币种的知识散布在不同地方:一部分出现在函数first_denomination里,另一部分出现在函数count_change里(它知道有5种美元硬币)。如果我们能用一个表来提供可用于兑换的硬币,那就更好了。
我们希望重写函数cc,令其第二个参数是一个可用硬币的币值表,而不是一个表示可用硬币种类的整数。然后我们就可以针对每种货币定义一个表:

这样,我们就可以用如下的方式调用cc:

为了做到这些,我们需要对程序cc做一些修改。它仍然具有同样的形式,但将以不同的方式访问自己的第二个参数,如下面所示:

请基于表结构的基本操作声明函数first_denomination、except_first_denomination和no_more。表coin_values的排列顺序会影响cc给出的回答吗?为什么会或不会?
练习2.20 由于存在高阶函数,允许函数有多个参数的功能已不再是严格必需的,只允许一个参数就足够了。如果我们有一个函数(例如plus)自然情况下它应该有两个参数。我们可以写出该函数的一个变体,一次只送给它一个参数。该变体对第一个参数的应用返回一个函数,该函数随后可以应用于第二个参数。对多个参数就这样做下去。这种技术称为curry 化 ,该名字出自美国数学与逻辑学家Haskell Brooks Curry,在一些程序设计语言里被广泛使用,如Haskell和OCalm。下面是在JavaScript里plus的curry化版本:

请写一个函数brooks,它的第一个参数是需要curry化的函数,第二个参数是一个实参的表,经过curry化的函数应该按给定顺序,一个个地应用于这些实际参数。例如,brooks的如下应用应该等价于plus_curried(3)(4):

做好了函数brooks,我们也可以carry化函数brooks自身!请写一个函数carried_brooks,它可以按下面的方式应用:

有了这个carried_brooks,下面两个语句的求值结果是什么?

对表的映射
有一个操作特别有用,那就是把某个变换应用于一个表里的所有元素,得到由所有结果构成的表。举例说,下面的函数按给定的因子,对一个表里的所有元素做缩放:

我们可以把这一极具普适性的想法抽象出来,提取其中的公共模式,将其表述为一个高阶函数,就像1.3节里那样。这个高阶函数称为map,它以一个函数和一个表为参数,返回把这个函数应用于表中各个元素得到的结果构成的表。


现在我们可以基于map给出scale_list的一个新声明:

函数map是一种非常重要的结构,因为它不仅代表了一种公共模式,而且建立了一种处理表的高层抽象。在scale_list原来的声明里,程序的递归结构把人的注意力吸引到对表中元素的逐个处理过程。基于map声明的scale_list则抑制了这种细节层面的事务,强调从元素表到结果表的一个缩放变换。这两种定义形式之间的差异,并不在于计算机会执行不同的计算过程(其实不会),而在于我们对这个过程的不同思考方式。从作用上看,map帮助我们建立起一层抽象屏障,把实现表变换的函数,与如何提取和组合表中元素的细节隔离开。与图2.1展示的屏障类似,这种抽象也提供了新的灵活性,它使我们有可能在保持从序列到序列的变换操作框架的同时,改变序列实现的低层细节。2.2.3节将把序列的这种使用方式扩展为一种组织程序的框架。
练习2.21 函数square_list以一个数值表为参数,返回每个数的平方构成的表:

下面是square_list的两个不同声明,请填充其中空缺的表达式以完成它们:

练习2.22 Louis Reasoner试图重写练习2.21中的第一个square_list函数,希望使它能生成一个迭代计算过程:

不幸的是,在这样声明的square_list生成的结果表里,元素的顺序正好与我们需要的顺序相反。为什么?
Louis又试着修正其程序,交换了pair的参数:

但还是不行。请解释为什么。
练习2.23 函数for_each与map类似,它也以一个函数和一个元素表为参数,但是它并不返回结果的表,只是把这个函数从左到右逐个应用于表中元素,并且把函数应用返回的值都丢掉。for_each通常用于那些执行某些动作的函数,如打印等。请看下面的例子:

调用函数for_each的返回值(上面没有显示)可以是任何东西,例如逻辑值真。请给出一个for_each的实现。
用表作为序列的表示方式,可以自然推广到元素本身也是序列的序列。例如,我们可以认为对象[[1, [2, null ]], [3, [4, null ]]是通过以下方式构造的:

这是一个包含三个项的表,其中的第一项本身又是表[1, [2, null ]]。图2.5用序对形式展示了这个结构。
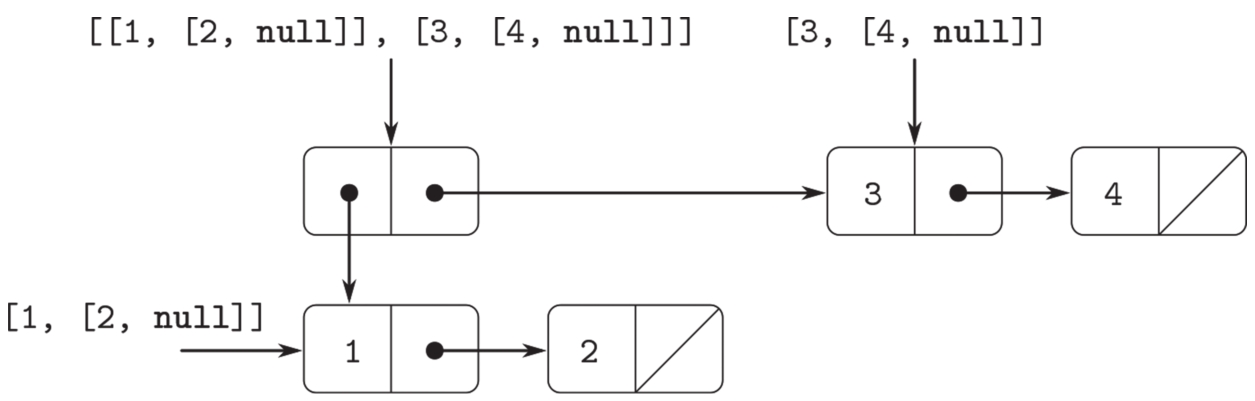
图2.5 由pair(list(1, 2), list(3, 4))构造的结构
为了理解这种元素本身也是序列的序列,我们可以把它们看作 树 。序列里的元素就是树的分支,自身也是序列的元素就形成树中的子树。图2.6显示了把图2.5中结构看作树的情况。
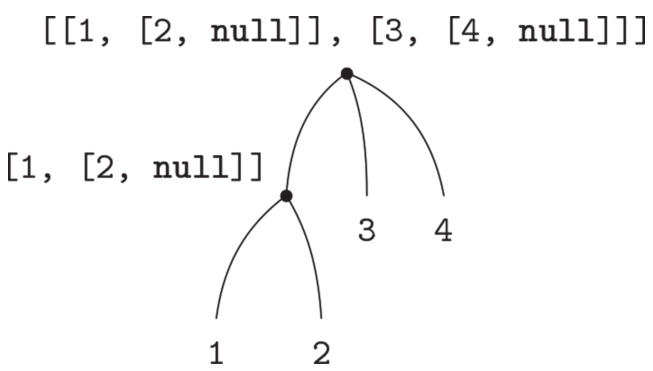
图2.6 把图2.5中的表结构看作树
递归是处理树结构的一种非常自然的工具,因为我们常常可以把对树的操作归结为对其分支的操作,再归结为对分支的分支的操作,并如此下去,直至到达了树的叶子。作为例子,请比较一下2.2.1节的length函数和下面的count_leaves函数,该函数统计一棵树中树叶的总数:

要实现函数count_leaves,我们先回忆一下计算length的递归方案:
●表x的length是x的tail的length加一。
●空表的length是0。
count_leaves的递归方案与此类似,对空表的值也一样:
●空表的count_leaves是0。
但是在递归步骤中,当我们去掉一个表的head时,就必须注意这个head本身也可能是树,其树叶也需要考虑。这样,正确的归约步骤应该是:
●对树x的count_leaves的结果,应该是x的head的count_leaves与x的tail的count_leaves之和。
最后,考虑head是实际树叶的情况,这是我们需要考虑的另一种基本情况:
●树叶的count_leaves是1。
为了支持人们描述对树结构的递归处理,我们的JavaScript环境提供了一个基本谓词is_pair,它检查其参数是否为序对。下面是完整函数的声明
:

练习2.24 假定我们需要求值表达式list(1, list(2, list(3, 4))),请给出解释器打印的结果,画出对应的盒子指针结构,并把它解释为一棵树(参看图2.6)。
练习2.25 请给出能从下面各个表里取出7的head和tail组合:


练习2.26 假设x和y定义为如下的两个表:

解释器对下面各个表达式将打印出什么结果?

练习2.27 请修改你在练习2.18做的reverse函数,做一个deep_reverse函数。它以一个表为参数,返回另一个表作为值。结果表中的元素反转,所有的子树也反转。例如:

练习2.28 请写一个函数fringe,它以一个树(表示为一个表)为参数,返回一个表,该表里的元素就是这棵树的所有树叶,按从左到右的顺序排列。例如:

练习2.29 一个二叉活动体由两个分支组成,一个是左分支,另一个是右分支。每个分支是一根长度确定的杆,杆上或者吊一个重量,或者吊着另一个二叉活动体。我们可以用复合数据对象表示这种二叉活动体,或者基于两个分支构造它们(例如用list):

一个分支可以基于一个length(它应该是一个数)加上一个structure构造出来,这个structure或者是一个数(表示一个简单重量),或者是另一个活动体:

a.请写出相应的选择函数left_branch和right_branch,它们分别返回参数活动体的两个分支。还有branch_length和branch_structure,它们返回参数分支的两个成分。
b.基于你的选择函数声明一个函数total_weight,它返回参数活动体的总重量。
c.一个活动体称为是平衡的,如果其左分支的力矩等于其右分支的力矩(也就是说,如果其左杆的长度乘以吊在杆上的重量,等于这个活动体右边的这种乘积),而且其每个分支上吊着的子活动体也都平衡。请设计一个函数,它检查一个二叉活动体是否平衡。
d.假定我们改变活动体的表示,采用下面的构造方式:

你需要对自己的程序做多少修改,才能把它改为使用这种新表示?
对树的映射
map是处理序列的一种功能强大的抽象,类似地,结合map与递归,就是处理树的一种功能强大的抽象。例如,我们可以定义与2.2.1节的scale_list类似的函数scale_tree,其参数是一个数值因子和一棵叶子都是数值的树。它返回一棵形状相同的树,但树中的每个数值都乘以这个因子。对scale_tree的递归方案也与count_leaves的类似:

实现scale_tree的另一种方法是把树看成子树的序列,对它使用map。我们对这种序列做映射,顺序地对各棵子树逐个缩放,并返回结果的表。对于基础情况,也就是当被处理的树是树叶时,就直接用因子去乘它:

对树的许多操作可以采用类似的方式,通过序列操作和递归的组合实现。
练习2.30 请声明一个函数square_tree,它与练习2.21中的函数square_list类似,也就是说,它应该具有下面的行为:

请以两种方式声明square_tree,直接做(也就是说不用高阶函数),以及用map和递归。
练习2.31 请把你对练习2.30的解答进一步抽象为一个函数tree_map,使它能支持我们采用下面的形式声明square_tree:
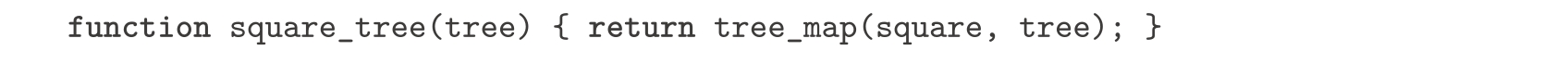
练习2.32 我们可以用元素互不相同的表来表示集合,因此一个集合的所有子集可以表示为一个表的表。比如说,假定集合为list(1, 2, 3),其所有子集的集合就是

请完成下面的函数声明,该函数生成一个集合的所有子集的集合。请解释它为什么能完成这项工作。

在处理复合数据时,我们一直强调数据抽象如何使人能设计出不受数据表示的细节纠缠的程序;如何使程序能保持良好的弹性,能应用于不同的具体表示。在这一节,我们要介绍处理数据结构的另一威力强大的设计原理——使用 约定的接口 。
在1.3节,我们看到了如何通过把程序的抽象实现为高阶函数,清晰地刻画数值数据处理中的一些公共模式。能把类似的操作做好,使它们能很好地在复合数据上工作,深度依赖于我们操控数据结构的方式。举个例子,考虑下面这个函数,它与2.2.2节中count_leaves函数类似,以一棵树为参数,计算树中值为奇数的叶子的平方和:

从表面上看,上面这个函数与下面的函数很不一样。下面的函数要求构造斐波那契数列Fib( k )中所有偶数的表,其中的 k 小于等于某个给定整数 n :

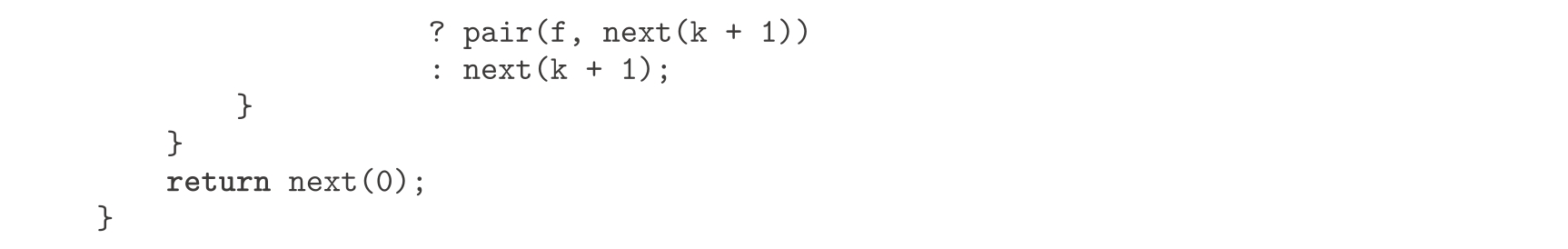
虽然这两个函数在结构上差异巨大,但是对两个计算的抽象描述却能揭示出它们之间极强的相似性。第一个程序:
●枚举一棵树的树叶;
●过滤它们,选出其中的奇数;
●对选出的每一个数求平方;
●用+累积得到的结果,从0开始。
而第二个:
●枚举从0到 n 的整数;
●对每个整数计算相应的斐波那契数;
●过滤它们,选出其中的偶数;
●用pair累积得到的结果,从空表开始。
信号处理工程师可能发现,把这种处理过程描述为流过一些级联的处理步骤的信号,每一步实现程序方案中一个部分也是很自然的,如图2.7所示。对sum_odd_squares,我们从一个 枚举器 开始,它生成由给定树的所有树叶组成的“信号”。这个信号流过一个 过滤器 ,删去所有非奇数的数。得到的信号再通过一个 映射 ,这是一个“转换装置”,它把square函数应用于每个元素。这一映射的输出被送入一个 累积器 ,该装置用+把得到的所有元素组合起来,以初始值0作为开始。函数even_fibs的工作过程与此类似。
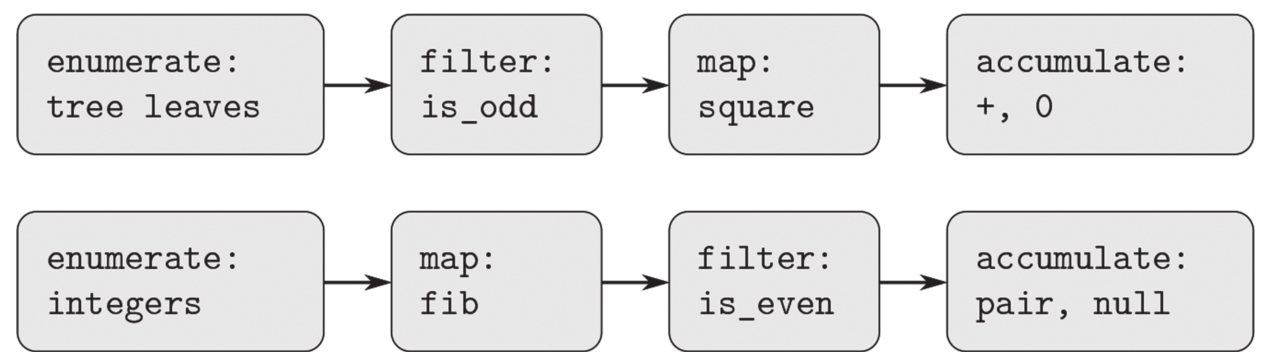
图2.7 函数sum_odd_squares(上)和even_fibs(下)的信号流程揭示出这两个程序之间的共性
不幸的是,上面两个函数声明并没有表现出这种信号流结构。譬如说,如果仔细考察函数sum_odd_squares,可以发现其中的枚举工作部分通过检查is_null和is_pair实现,部分通过函数的树形递归结构实现。类似地,在这些检查中还可以看到一部分累积工作,另一部分由递归中使用的加法完成。一般说,在这两个函数里,没有一个部分正好对应于信号流描述中的某个元素。我们的两个函数用不同的方式分解各自的计算,把枚举工作散布到程序中各处,并把它与映射、过滤器和累积器混在一起。如果我们能重新组织这两个程序,使信号流结构明显表现在写出的函数里,应该能大大提高结果代码的清晰性。
序列操作
要使程序的组织更清晰地反映上面的信号流结构,关键是集中关注处理过程中从一个步骤流向下一步骤的“信号”。如果我们用表来表示这些信号,就可以用表操作实现每个步骤的处理。举例说,我们可以用2.2.1节的map函数实现信号流图中的映射步骤:

过滤一个序列,也就是选出其中满足某给定谓词的元素,可以通过下面的方式完成:

例如,

累积工作可以如下实现:

现在再实现上面的信号流图,剩下的工作也就是枚举出需要处理的数据序列。对于even_fibs,我们需要生成给定区间里所有整数的序列。该序列可以如下生成:

要枚举一棵树的所有树叶,则可以用
:


现在我们已经可以像前面的信号流图那样重新构造sum_odd_squares和even_fibs了。对于sum_odd_squares,我们需要枚举一棵树的树叶序列,过滤它,只留下序列中的奇数,求出每个元素的平方,最后把得到的结果加起来:

对于even_fibs,我们需要枚举出从0到 n 的所有整数,对每个整数生成相应的斐波那契数,通过过滤只留下其中的偶数,最后把结果积累在一个表里:

把程序表示为一个操作序列,其价值在于能帮助我们做好程序的模块化,也就是说,得到由一些相对独立的片段构造起来的设计。我们还能通过提供标准的部件库,让其中部件都支持以灵活方式互连的约定接口,进一步推动模块化的设计。
在工程设计领域,模块化构造是一种控制复杂性的威力强大的策略。举例说,在真实的信号处理应用中,设计者通常总是从标准化的过滤器和变换器族中选一些东西,通过级联的方式构造出需要的系统。类似地,序列操作也形成了一个标准程序元素的库,可以通过混合和匹配的方式使用。例如,如果另一个程序要求构造前 n +1个斐波那契数的平方的表,我们就可以利用取自函数sum_odd_squares和even_fibs的片段:

我们也可以重新安排这些片段,用它们产生一个序列中所有奇整数的平方之乘积:

我们还可以用序列操作的方式,形式化常规的数据处理应用。假设有一个人事记录序列,我们希望找出其中薪水最高的程序员的工资额。假定我们有选择函数salary返回记录中的工资数额,另有谓词is_programmer检查记录是否程序员,那么就可以写:

这些例子给我们的启示是:许多工作都可以用序列操作的方式表述
。
以表实现的序列作为约定接口,使我们可以组合各种处理模块。进一步说,以序列作为统一的表示结构,也使我们能把程序对数据结构的依赖限制到不多的几个序列操作上。通过修改这些操作,就能在保持程序的整体设计不变的前提下,在序列的不同表示之间转换。3.5节还将继续探索这方面的能力,那里将把序列处理的范型推广到无穷序列。
练习2.33 下面是一些把基本表操作看作累积的声明,请填充空缺的表达式,完成它们:

练习2.34 对一个给定的 x 的多项式,求出其在某个 x 处的值也可以形式化为一种累积。假设需要求下面多项式的值:
a n x n + a n -1 x n -1 +…+ a 1 x + a 0
采用著名的Horner 规则 的计算过程具有如下的结构:
(…( a n x + a n -1 ) x +…+ a 1 ) x + a 0
换句话说,我们从 a n 开始,将其乘以 x ,再加上 a n -1 ,再乘以 x ,如此下去,直到处理完 a 0 [3] 。请填充下面的程序模板,做出一个使用Horner规则求多项式的值的函数。假定多项式的系数安排在一个序列里,从 a 0 直至 a n 。

例如,为了计算1+3 x +5 x 3 + x 5 在 x =2的值,你需要求值:
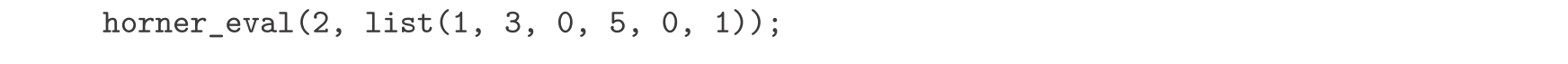
练习2.35 请把2.2.2节的count_leaves重新声明为一个累积:
练习2.36 函数accumulate_n与accumulate类似,但是其第三个参数是一个序列的序列,我们还假定其中每个小序列的元素个数相同。这个函数应该用指定的累积过程组合起每个序列里的第一个元素,而后再组合每个序列的第二个元素,并如此做下去。它返回以得到的所有结果为元素的序列。例如,如果s是包含4个序列的序列
那么accumulate_n(plus, 0, s)的值就应该是序列list(22, 26, 30)。请填充下面accumulate_n声明中缺失的表达式:

练习2.37 假设我们把向量 v =( v i )表示为数的序列,把矩阵 m =( m ij )表示为向量(矩阵行)的序列。例如,矩阵:
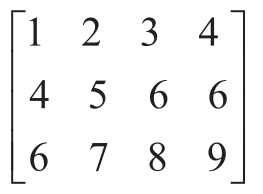
可以用下面的序列表示:

有了这种表示,我们就可以利用序列操作,简洁地描述各种基本的矩阵与向量运算了。例如如下的这些运算(任何有关矩阵代数的书里都有说明):
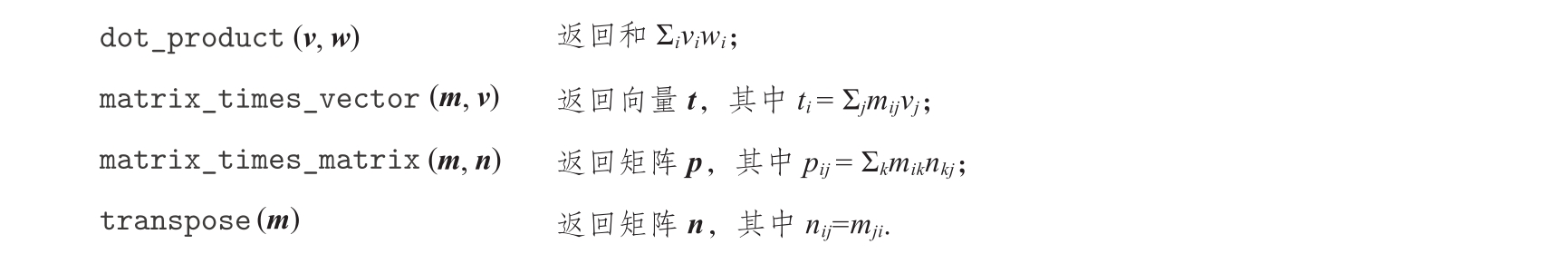
其中的点积(dot product)函数可以如下声明
:

请填充下面函数声明里空缺的表达式,使所定义的函数能完成另外那些矩阵运算的计算(函数accumulate_n在练习2.36中定义)。

练习2.38 函数accumulate也被称为fold_right,因为它把序列里的第一个元素组合到右边所有元素的组合结果上。与之对应的也有一个fold_left,它与fold_right类似,但却是按相反的方向组合元素:

下面各个表达式的值是什么?

为保证fold_right和fold_left对任何序列都产生同样结果,函数op应该满足什么性质?
练习2.39 请基于练习2.38的fold_right和fold_left完成下面两个有关函数reverse(练习2.18)的声明:

嵌套的映射
我们可以扩充序列范型,把通常用嵌套循环描述的许多计算也包括进来
。考虑下面的问题:给定一个自然数
n
,要求找出所有不同的有序对
i
和
j
,其中1≤
j
<
i
≤
n
,使得
i
+
j
是素数。例如,假定
n
是6,满足条件的序对就是:
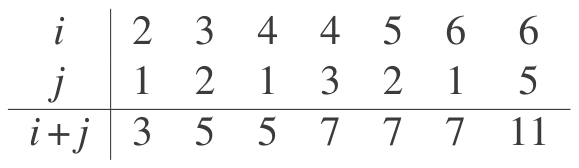
组织这一计算有一种很自然的方法:生成所有小于等于 n 的正整数的有序序对,过滤选出和为素数的序对,最后对通过了过滤的每个序对( i , j )生成一个三元组( i , j , i + j )。
生成这种序对的序列的一种方法如下:对每个整数 i ≤ n ,枚举出所有的整数 j < i ,并对每一对 i 和 j 生成一个序对( i , j )。按序列操作的说法,这是对序列enumerate_interval(1, n)做一次映射。对序列里的每个 i ,我们都对序列enumerate_interval(1, i-1)做映射。对后一序列中的每个 j ,我们生成序对list(i, j),这样就对每个 i 得到了一个序对的序列。把针对所有 i 的序列组合起来(用append累积),就得到了所需的序对序列 [4] 。

在这类程序里,经常需要在做映射之后再把结果用append累积,我们可以把这整个工作独立出来,定义为一个独立的函数:

现在考虑过滤这个序对的序列,找出序对中两个数之和是素数的序对。应该对序列里的每个元素调用过滤谓词。由于谓词的参数是序对,而操作中必须提取出序对里两个整数,这样,作用到序列中每个元素上的谓词就应该是:

最后还要生成结果的序列,为此只需要把下面的函数映射到过滤后留下的序对上。对每个序对里的两个元素,该函数生成包含了它们的和的三元组:

把所有这三个步骤组合到一起,就得到了完整的函数:

嵌套的映射不仅能用于枚举所需的区间,也能用于生成其他序列。假设现在我们希望生成一个集合
S
的所有排列,也就是说,生成这一集合中元素的所有可能的排序序列。例如,{1, 2, 3}的排列是{1, 2, 3}, {1, 3, 2}, {2, 1, 3}, {2,3,1}, {3,1,2}和{3, 2, 1}。下面是生成
S
的所有排列的序列的一种方案:对
S
里的每个
x
,递归地生成
S-x
的所有排列的序列
[5]
,而后把
x
加到每个序列的前面。这样就能对
S
里的每个
x
,生成了
S
的所有以
x
开头的排列。把对每个
x
生成的序列组合到一起,就得到了
S
的所有排列
。

请注意这里的策略:我们把生成 S 的所有排列的问题,归结为生成元素少于 S 的集合的排列的问题。终极情况是遇到空表,它表示无元素的集合,此时生成的就是list(null),这是一个只包含一个元素的序列,该元素是一个无元素的集合。在permutations函数里使用的remove函数返回除去指定项之外的所有元素,它可以简单地用一个过滤器描述:
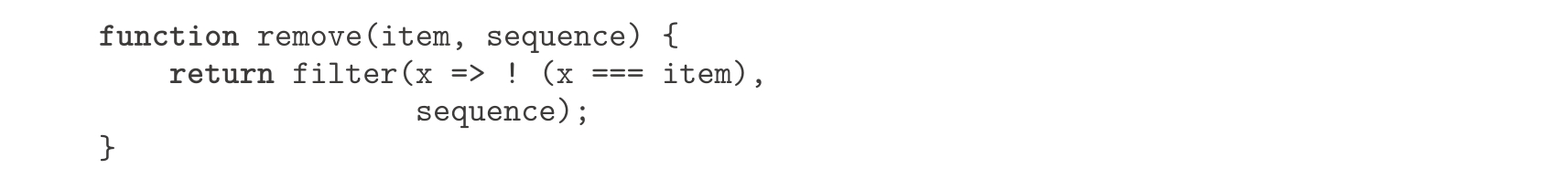
练习2.40 请写一个函数unique_pairs,给它一个整数参数 n ,它产生所有序对( i , j )的序列,其中1≤ j < i ≤ n 。请用unique_pairs简化上面prime_sum_pairs的定义。
练习2.41 请写一个函数,它能生成所有小于等于给定整数 n 的正的相异整数 i 、 j 和 k 的有序三元组,其中每个三元组的三个元之和都等于给定的整数 s 。
练习2.42 “八皇后谜题”问怎样把八个皇后摆在国际象棋盘上,使得没有一个皇后能攻击另一个(也就是说,任意两个皇后都不在同一行、同一列,或者同一斜线上)。该谜题的一个解如图2.8所示。解决这个谜题的一种方法是按一个方向考虑棋盘,每次在一列中放入一个皇后。如果现在已经放好了 k -1个皇后,第 k 个皇后就必须放在不会攻击任何已在棋盘上的皇后的位置。我们可以递归地描述这一处理过程:假定我们已经生成了在棋盘前 k -1列放 k -1个皇后的所有可能方法,现在对其中的每种方法,生成把下一皇后放在第 k 列中每一行的扩充集合。然后过滤它们,只留下使第 k 列的皇后与其他皇后相安无事的扩充。这样就生成了 k 个皇后放在前 k 列的所有安全序列。继续这一过程就能得到该谜题的所有解,而不是一个解。
我们把这个解法实现为一个函数queens,令它返回在 n × n 的棋盘上放好 n 个皇后的所有解的序列。函数queens有一个内部函数queen_cols,它返回在棋盘的前 k 列中放好皇后的所有位置的序列。

图2.8 八皇后谜题的一个解

在这个函数里,参数rest_of_queens是在前 k -1列放置 k -1个皇后的一种方式,new_row是在第 k 列放置皇后时考虑的行编号。要完成这个程序,我们需要设计一种棋盘位置集合的表示方法;还要实现函数adjoin_position,其功能是把一个新的行列位置加入一个位置集合;还有empty_board表示空的位置集合。你还需要写一个函数is_safe,它确定在一个位置集合中,位于第 k 列的皇后相对于其他列的皇后是安全的。(请注意,我们只需检查新皇后是否安全——其他皇后都已经保证相安无事了。)
练习2.43 Louis Reasoner做练习2.42时遇到了麻烦,他的queens函数看起来能行,但却运行得极慢(Louis居然无法忍耐到它解出6×6棋盘的问题)。Louis请Eva Lu Ator帮忙时,她指出他在flatmap里交换了嵌套映射的顺序,把它写成了:

请解释,为什么这样交换顺序会使程序运行得非常慢。请估算,用Louis的程序去解决八皇后问题大约需要多少时间,假定练习2.42中的程序需用时间 T 求解这一谜题。
本节要讨论一种用于生成图形的简单语言,它展示了数据抽象和闭包的威力,并以一种非常本质的方式使用了高阶函数。这个语言的设计就是为了方便地做出类似图2.9中所示例的模式的图形,它们都是由某些元素变形或改变大小的重复出现构成
。在这个语言里,被组合的数据元素都将用函数表示,而不是用表结构表示。就像pair满足闭包性质,使我们能构造任意复杂的表结构一样,这个语言里的操作也满足闭包性质,使我们很容易构造任意复杂的模式。

图2.9 利用这个图形语言生成的一些设计
图形语言
我们在1.1节开始研究程序设计时,就特别强调,在描述一种语言时,把注意力集中到语言的基本原语、组合方法和抽象方法的重要性。现在的工作也按同一套路展开。
我们准备研究的这个图形语言的优美之处,部分在于这个语言里只有一类元素,称为 画家 (painter)。一个画家能画出一张图,这种图可以变形或者改变大小,以便正好放到指定的平行四边形框架里。举例说,有一个称为wave的基本画家,它能画出图2.10所示的折线图,而图的实际形状依赖于具体的框架;图2.10里的四个图都是由同一画家wave生成的,但这些图是相对于四个不同的框架。画家也可以更精妙。基本画家rogers能画出MIT的创始人William Barton Rogers的画像,如图2.11所示 [6] 。图2.11里的四个图是相对于与图2.10中wave形象同样的四个框架画出的。
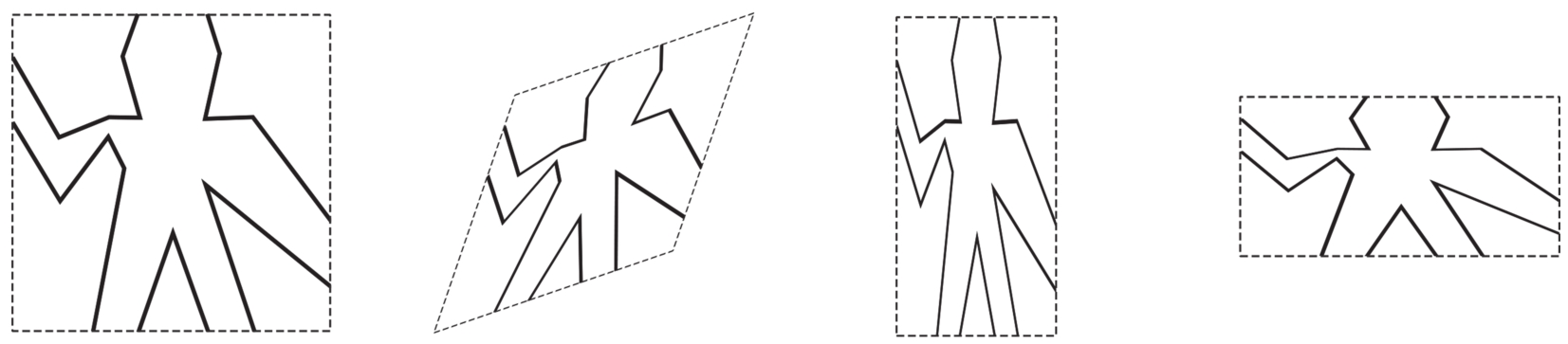
图2.10 由画家wave相对于4个不同框架生成的图像。相应的框架用点线表示,它们并不是图像的组成部分

图2.11 William Barton Rogers(MIT的创始人和第一任校长)的图像,依据与图2.10中同样的4个框架画出(原始图片经过MIT博物馆的允许重印)
为了组合各种图像,我们用一些可以从给定的画家构造新画家的操作。例如,操作beside从两个画家出发,产生一个新的复合画家,它把第一个画家的图像画在框架的左边一半,把第二个画家的图像画在框架的右边一半。与此类似,below从两个画家出发产生一个复合画家,把第一个画家的图像画在第二个画家的图像之下。有些操作把一个画家转换为另一新画家。例如,flip_vert从一个画家出发,生成一个把原画家所画的图上下颠倒画出的画家,而flip_horiz生成的画家把原画家的图左右反转后画出。
图2.12说明了从wave出发,经过两步做出名为wave4的画家的方法:
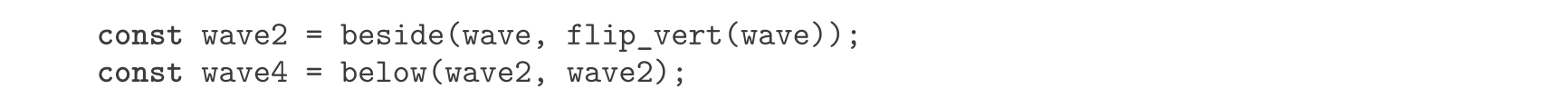
在通过这种方法构造复杂的图像时,我们利用了一个事实,在这个语言的组合操作下画家是封闭的:两个画家的beside或below得到的还是画家,因此可以被用作元素去构造更复杂的画家。就像用pair可以构造各种表结构一样,数据在组合方法下的闭包性质非常重要,因为这使我们能用不多的几个操作构造出各种复杂的结构。
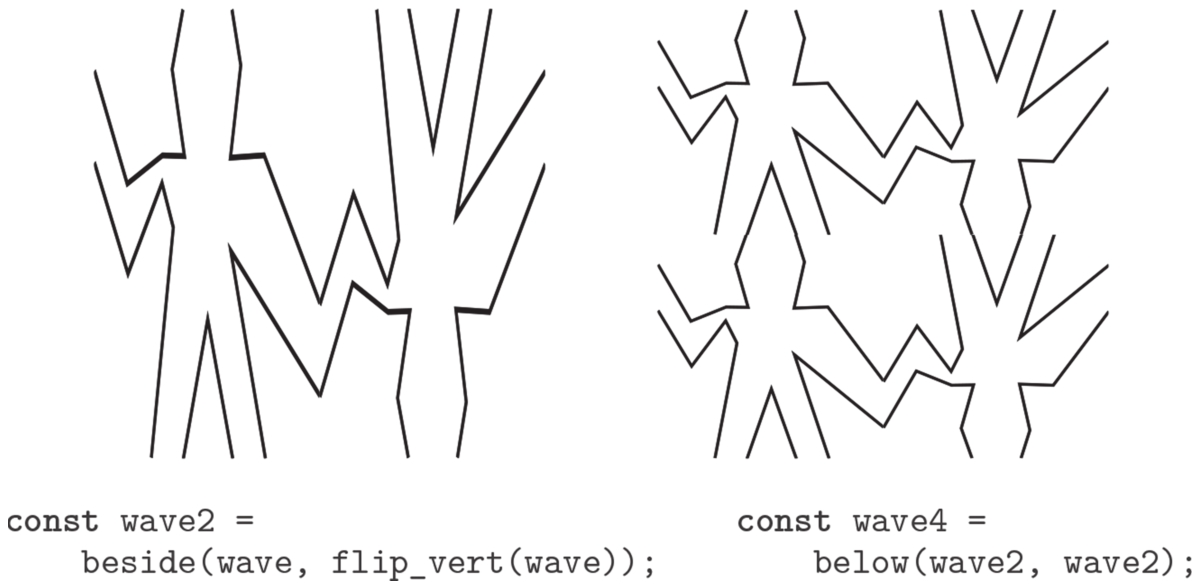
图2.12 从图2.10的画家wave出发,建立起一个复杂的图像
在我们能组合画家之后,就会希望能抽象出组合画家的典型模式,把对画家的操作实现为JavaScript函数。这也意味着我们在图形语言里不需要任何特殊的抽象机制。因为组合的方法就是常规的JavaScript函数,这样,我们就自动地能对画家做原来可以对函数做的所有事情。例如,我们可以把wave4中的模式抽象出来:

并把wave4重新声明为这种模式的实例:

我们也可以定义递归操作。下面就是一个这样的操作,它在图形的右边做分割和分支,就像图2.13和图2.14里显示的那样:

通过同时在图中向上和向右分支,我们可以得到出一种平衡的模式(见练习2.44,以及图2.13和图2.14):


通过把corner_split的4个拷贝适当地组合起来,我们就可以得到一种称为square_limit的模式,把这个函数应用于wave和rogers的效果见图2.9:

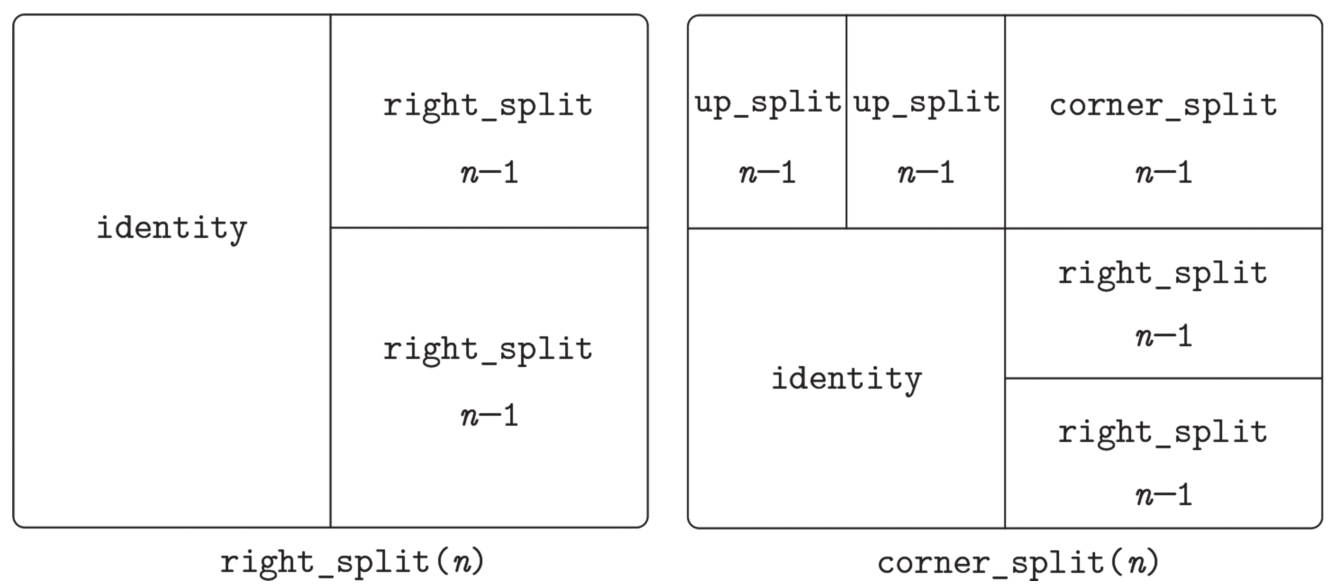
图2.13 right_split和corner_split的递归方案

图2.14 把递归操作right_split和corner_split应用于画家wave和rogers。图2.9显示的就是组合起4个corner_split图形生成的对称的square_limit图形
练习2.44 请声明corner_split里使用的函数up_split,它与right_split类似,但是其中交换了below和beside的角色。
高阶操作
除了可以抽象出组合画家的模式外,我们也可以在高阶上工作,抽象出画家的各种组合操作的模式。也就是说,我们可以把画家操作看成需要操控的元素,去描述组合这些元素的方法——写一些函数,它们以画家操作为实际参数,创建新的画家操作。
举例说,flipped_pairs和square_limit都是把一个画家的四个拷贝安排在一个正方形的模式中,它们之间的不同只在这些拷贝的旋转角度。抽象这种画家组合模式的一种方法是定义如下函数,它基于四个单参数的画家操作,生成一个新的画家操作,在这个操作里用四个参数操作变换给定的画家,然后把得到的结果放入一个正方形里 [7] 。tl、tr、bl和br分别是应用于左上角、右上角、左下角和右下角的四个拷贝的变换:

操作flipped_pairs可以基于square_of_four重新定义如下 [8] :

而square_limit可以描述为
:

练习2.45 函数right_split和up_split可以表述为某种广义划分操作的实例。请声明一个函数split,使它具有如下的性质,求值:

能生成函数right_split和up_split,其行为与前面声明的函数一样。
框架
在说明如何实现画家及其组合方法之前,我们需要先考虑框架的问题。一个框架可以用三个向量描述:一个基准向量和两个角向量。基准向量描述框架基准点相对于平面上某个绝对基准点的偏移量,角向量描述框架的角点相对于框架基准点的偏移量。如果两个角向量正交,这个框架就是矩形,否则它就是一般的平行四边形。
图2.15显示了一个框架和它的三个相关向量。根据数据抽象原理,我们现在无须严格地说明框架的具体表示方法,只需要说明存在一个构造函数make_frame,它能从三个向量出发构造出一个框架。对应的选择函数是origin_frame、edge1_frame和edge2_frame(见练习2.47)。
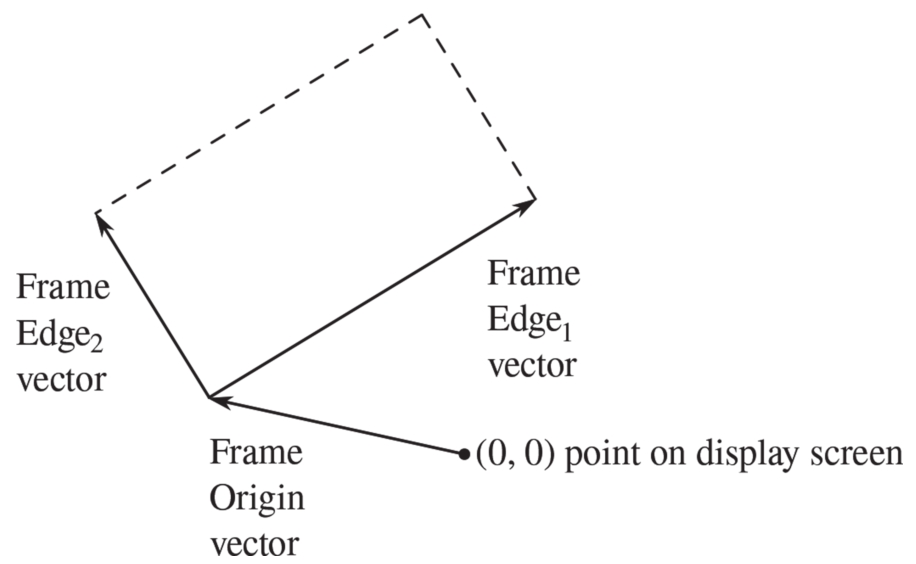
图2.15 框架由三个向量描述,包括一个基准向量和两个角向量
我们将用单位正方形(0≤ x , y ≤1)里的坐标描述图像的位置。对于每个框架,我们要为它关联一个 框架坐标映射 ,利用这个映射实现相关图像的位移和伸缩,使之适配于这个框架。这个映射的功能就是把单位正方形变换到相应的框架,也就是把向量 v =( x , y )映射到下面的向量和:
Origin(Frame)+ x ·Edge 1 (Frame)+ y ·Edge 2 (Frame)
例如,点(0, 0)将映射到给定框架的原点,(1, 1)映射到与原点对角的那个点,而(0.5, 0.5)映射到给定框架的中心点。我们可以通过下面函数建立框架的坐标映射
:

注意,把frame_coord_map应用于一个框架将返回一个函数,送给这个函数一个向量,它返回另一个向量。如果参数向量位于单位正方形里,结果向量就位于相应框架里。例如:
返回的向量与下面向量相同:

练习2.46 从原点出发到某个点的二维向量 v ,可以用由 x 坐标和 y 坐标构成的序对表示。请为这种向量实现一个数据抽象:给出其构造函数make_vect以及对应的选择函数xcor_vect和ycor_vect。基于你的构造函数和选择函数,实现函数add_vect、sub_vect和scale_vect,使它们能完成向量加法、向量减法和向量的缩放。
( x 1 , y 1 )+( x 2 , y 2 )=( x 1 + x 2 , y 1 + y 2 )
( x 1 , y 1 )-( x 2 , y 2 )=( x 1 -x 2 , y 1 -y 2 )
s ·( s , y )=( sx , sy )
练习2.47 下面是框架的两个可能的构造函数:

请为每个构造函数提供合适的选择函数,构造出框架的相应实现。
画家
画家用函数表示。给画家一个框架作为实际参数,它就能通过适当的位移和伸缩,画出一幅与这个框架匹配的图像。也就是说,如果p是画家而f是框架,以f为实际参数调用p,就能在f里生成p表示的那个图像。
基本画家的实现细节依赖特定图形系统的各种特性和被画图像的种类。例如,假定有一个函数draw_line,它能在屏幕上两个给定点之间画一条直线,我们就可以利用它定义一个根据线段表参数画折线图的画家,例如图2.10的wave画家
:

线段用相对于单位正方形的坐标给出。对于表中的每个线段,这个画家用框架坐标映射对线段的端点做变换,然后在变换得到的两个端点之间画一条直线。
用函数表示画家,在这个图形语言里建立了一条强有力的抽象屏障,使我们可以基于各种图形能力,创建和混用各种类型的基本画家。任何函数,只要它以一个框架为参数,能画出一些可以伸缩后适配这个框架的图形,就可以用作画家
。
练习2.48 平面上的一条直线段可以用一对向量表示——一个从原点到线段起点的向量,一个从原点到线段终点的向量。请用你在练习2.46做的向量表示定义一种线段表示,其中用到构造函数make_segment以及选择函数start_segment和end_segment。
练习2.49 利用segments_to_painter定义下面的基本画家:
a.画出给定框架边界的画家。
b.通过连接框架两对角点,画出一个大叉子的画家。
c.通过连接框架各边的中点画出一个菱形的画家。
d.画家wave。
画家的变换和组合
对画家的操作(例如flip_vert或beside)就是创建新画家。这个新画家将针对根据参数框架做出的新框架去调用原来的参数画家。举个例子,flip_vert在反转一个画家时完全不知道它如何工作,只要知道如何倒置一个框架就足够了。这个操作产生的画家就是使用原来的画家,但要求它在倒置的框架里工作。
对画家的操作都基于函数transform_painter,该函数以一个画家和有关如何变换框架和生成新画家的信息作为参数。用一个框架调用变换后的画家时,我们将变换这个框架,然后用变换后的框架去调用原来那个画家。transform_painter的参数是描述新框架各个角的几个点(用向量表示)。在做针对框架的映射时,第一个点描述新框架的原点,另外两个点描述新框架的两个边向量的终点。这样,位于单位正方形里的参数,描述的就是一个包含在原框架里的框架。

从下面的函数声明里可以看到如何纵向翻转一个画家:

利用transform_painter很容易定义各种新变换。例如,我们可以声明一个画家,它把自己的图像收缩到给定框架的右上角的四分之一区域里:

另一个变换把图像逆时针旋转90°
:

或者把图像向中心收缩
:

框架变换也是定义两个或更多画家的组合的关键。例如,beside函数以两个画家为参数,分别把它们变换为在参数框架的左半边和右半边画图,这样就产生出一个新的复合画家。当我们给了这个画家一个框架后,它首先调用变换后的第一个画家在框架的左半边画图,然后调用变换后的第二个画家在框架的右半边画图:

从这个例子里可以看到,画家数据抽象,特别是把画家表示为函数,使beside的实现非常简单。这个beside函数完全不需要了解其成分画家的任何细节,只需要知道这些画家能在指定的框架里画一些东西就足够了。
练习2.50 请声明变换flip_horiz,它能横向地反转画家。再声明两个变换,它们分别把画家按逆时针方向旋转180°和270°。
练习2.51 请声明对画家的below操作。函数below以两个画家为参数。below生成的画家针对给定的框架,要求其第一个参数画家在框架的下半部画图,第二个参数画家在框架的上半部画图。请按两种方式声明below:第一个用类似上面beside函数的方式直接声明,另一个则通过调用beside和适当的旋转(来自练习2.50)完成工作。
强健设计的语言层次
上面的图形语言里运用了我们在前面介绍的函数抽象和数据抽象的一些关键思想。这里的基本数据抽象(画家)的实现采用了函数式表示,这种做法使得该语言能以统一的方式处理各种本质上不同的画图功能。这种组合方法也满足闭包性质,使我们很容易构造各种复杂的设计。最后,所有能用于做函数抽象的工具,都可以用作组合画家的抽象工具。
我们还对语言和程序的设计方面的另一关键思想(即 分层设计 的方法)取得了一点初步认识。该思想说,复杂系统的构造应该通过一系列层次,为描述这些层次需要使用一系列的语言。每个层的构造都是组合起一些作为该层的基本元素的部件,这样构造出的部件又作为下一层的基本元素。在分层设计的每一层,所用语言都要提供一些基本元素、一些组合手段,以及对本层中的细节做抽象的手段。
在复杂系统的工程中,这种分层的设计方法被广泛使用。例如,在计算机工程里,电阻和晶体管被组合起来(用模拟电路的语言)构成一些部件(如与门、或门等),作为数字电路设计语言
中的基本元素。这些部件又被组合起来,构造处理器、总线和存储系统等,它们再组合起来构成计算机,这时使用的是适合描述计算机体系结构的语言。计算机又被组合起来构成分布式系统,采用适合描述网络互联的语言。还可以这样做下去。
作为分层设计的一个小例子,我们的图形语言用了一些基本元素(基本画家),它们描述点和直线,或提供rogers之类的图像。前面关于这一图形语言的说明,集中关注基本元素的组合,使用如beside和below一类的几何组合手段。我们也在更高的层面上工作,以beside和below作为基本元素,在一个包含square_of_four一类操作的语言里处理它们,这些操作关注的是把几何组合手段组合起来的各种常见模式。
分层设计能帮助我们把程序做得更 强健 ,也就是说,在规范发生微小改变时,我们更有可能只需对程序做相应的微小修改。例如,假定我们希望改变图2.9所示的基于wave的图像,我们可以在最低的层次上工作,修改wave元素的细节表现;也可以在中间层次工作,改变corner_split里重复使用wave的方式;还可以在最高层次工作,修改square_limit对图形各个角上的4个副本的安排。一般说,分层结构中的每个层次都为描述系统的特征提供了一套不同的词汇,以及不同种类的修改系统的能力。
练习2.52 请在上面说的各层次上工作,修改图2.9所示的基于wave的正方极限(square limit)图形。特别是:
a.给练习2.49的基本wave画家加入某些线段(例如,加一个笑脸)。
b.修改corner_split的构造模式(例如,只用up_split和right_split的图像的各一个副本,而不是两个)。
c.修改square_limit,换一种使用square_of_four的方式,以另一种不同模式组合各个角区(例如,你可以让最大的Rogers先生从正方形的每个角向外看)。