
下载掌阅APP,畅读海量书库
立即打开



在上一节中,我们了解了如何使用std::regex_match()来验证字符串的内容是否匹配特定的格式。而标准库提供了另一种称为std::regex_search()的算法,它针对字符串的任意部分匹配正则表达式,而不是像regex_match()那样只匹配整个字符串。但是,这个函数不允许我们搜索输入字符串中出现的所有正则表达式,为此我们需要使用库中可用的一个迭代器类。
在本节中,我们将学习如何使用正则表达式解析字符串的内容。因此,我们将考虑如何解析包含name=value的文本文件的问题。每一行都定义格式为name=value这样的键值对,但是以#开头的行表示注释,我们必须忽略这样的行。举例如下:

在查看实现细节之前,我们来考虑一些先决条件。
有关C++11支持正则表达式的相关知识,请参阅2.9节。若想继续阅读本节内容,你需要具备正则表达式的基本知识。
在下面的例子中,text变量的定义如下:

这样做的唯一目的是简化代码片段,尽管在实际示例中,可能要从文件或其他源中读取文本。
为了搜索正则表达式在字符串中出现的次数,应该执行以下操作:
❍ 包含头文件<regex>和<string>以及命名空间std::string_literals(C++14标准字符串可以使用的用户自定义字面量):

❍ 使用原始字符串字面量来指定正则表达式,以避免转义反斜杠(因为这可能时常发生)。以下正则表达式可验证前面提到的文件格式:
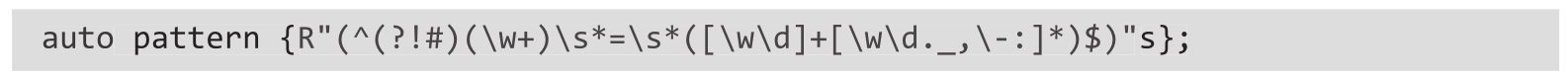
❍ 创建std::regex或std::wregex对象(具体取决于所使用的字符集)来封装正则表达式:

❍ 要查找正则表达式第一次匹配的文本,可以使用通用算法std::regex_search()(示例1):

❍ 要查找正则表达式匹配的所有文本,可以使用迭代器std::regex_iterator(示例2):

❍ 要遍历匹配的所有子表达式,可以使用迭代器std::regex_token_iterator(示例3):


一个简单的正则表达式可以解析之前输入的文本,如下所示:

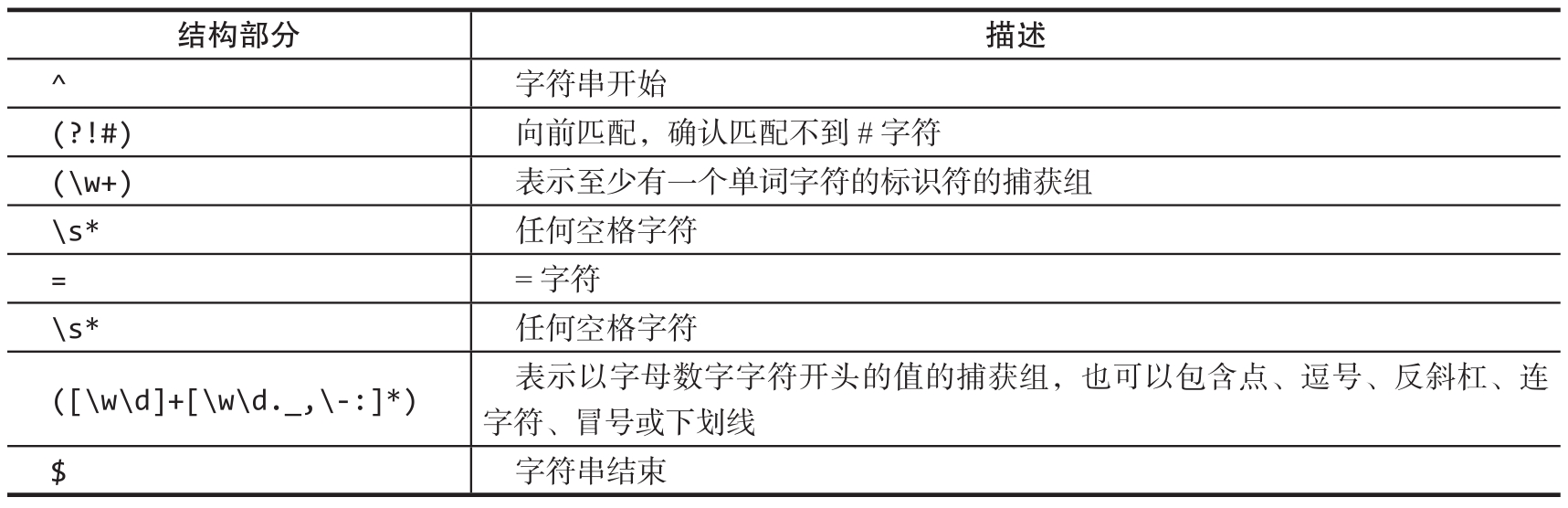
这个正则表达式应该忽略所有以#开头的行,对于那些不以#开头的,需要匹配名称和名称后面的等号,以及一个可以由字母数字字符和其他字符(如下划线、点、逗号等)组成的值。该正则表达式的确切描述如表2.3所示。
表2.3
我们可以使用std::regex_search()在输入文本的任何位置搜索匹配项。这个算法有几个重载版本,但一般而言它们的工作方式基本相同。必须要给定处理的字符范围、包含输出结果的std::match_results对象和正则表达式std::basic_regex对象以及匹配标志(定义了完成搜索的方式)。如果找到匹配项,函数返回true,否则返回false。
在上一节的示例1中(参见第4行),match是std::smatch(std::match_results的别名)的一个实例,它以string::const_iterator作为模板类型。如果找到匹配项,该对象以序列的形式包含所有匹配子表达式的匹配信息。索引0处的子匹配项始终匹配整个字符串;索引1处的子匹配项是该序列匹配的第一个子表达式;索引2处的子匹配项是该序列匹配的第二个子表达式,以此类推。因为正则表达式中有两个捕获组(它们是子表达式),如果匹配成功,std::match_results将有3个子匹配项。表示名称的标识符的索引为1,等号后面的值的索引为2。因此,这段代码只打印图2.4所示的内容。

图2.4 示例1的输出
std::regex_search()算法不能遍历一段文本中所有可能的匹配项,因此,我们需要使用迭代器,于是就有了std::regex_iterator。它不仅可以遍历所有匹配项,还允许访问匹配的所有子匹配项。
迭代器实际上会在构造和自增时调用std::regex_search()算法,并且会记住调用产生的std::match_results。默认构造函数创建一个迭代器,该迭代器指向序列的结尾,可用于测试匹配循环何时应该停止。
在上一节的示例2中(参见列表的第5项),我们首先创建一个序列end迭代器,然后开始遍历所有可能的匹配项。当它被构造时,它将调用std::regex_match(),如果找到了匹配项,就可以通过当前迭代器访问其结果。此过程一直继续下去,直到找不到匹配项(即到达序列结尾)。这段代码将会打印图2.5所示的输出结果。
std::regex_iterator的替代选择是std::regex_token_iterator,它与std::regex_iterator的工作方式类似。事实上,它在内部包含了一个允许我们从匹配项访问特定子表达式的迭代器,这从上一节的示例3中可以看到(见列表第6项)。我们首先要创建序列的end迭代器,然后遍历匹配项,直到到达序列结尾。在我们使用的构造函数中,因为没有指定要通过迭代器访问的子表达式的索引,所以使用默认值0,这也意味着该程序将打印所有匹配项,如图2.6所示。
如果只想访问第一个子表达式(在我们的例子中这意味着名称),所要做的就是在token迭代器的构造函数中指定子表达式的索引,如下所示:

这一次,我们得到的输出只包含名称,如图2.7所示。

图2.5 示例2的输出

图2.6 示例3的输出

图2.7 只包含名称的输出
token迭代器的一个有趣之处在于,如果子表达式的索引为-1,它可以返回字符串中不匹配的部分,在这种情况下,它返回一个std::match_results对象,该对象保存最后一个匹配项的位置和序列结尾之间的字符序列:


这个程序将输出图2.8所示的内容。

图2.8 包含空行的输出
请注意,输出中的空行对应于空项。
❍ 阅读2.9节,以了解C++库对正则表达式的支持。
❍ 阅读2.11节,以了解如何在文本中对一个模式进行多项匹配。