
下载掌阅APP,畅读海量书库
立即打开



简单来说,数据模型就是对一个数据对象基本组成的描述。我们先来看一下中华古诗网站的数据组成,如图4-1所示。
中华古诗网站的数据对象有五种,包括风格、作者、古诗、译文赏析和名句。根据数据之间的关系,数据模型的创建需要有先后顺序,先是作者与风格,再是古诗,最后是译文赏析与名句。
创建数据模型时,先要分析一个数据对象要包含哪些数据内容。例如,一位古诗作者的数据可能包括姓名、朝代、简介、图片等。我们可以根据需求,只选择其中一部分属性,作为数据模型的组成。当确定了数据模型的组成,就可以编写模型类描述数据模型。
模型类需要写在数据模型模块models.py中。“models.py”文件中预先引入了相应的模块。
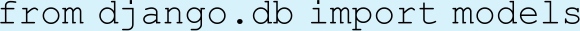
我们要做的是继承Django的models模块中的Model类,编写自定义的模型类。
因为需要使用随书资源中带有测试数据的数据库文件,编写的模型代码务必与文中保持一致。
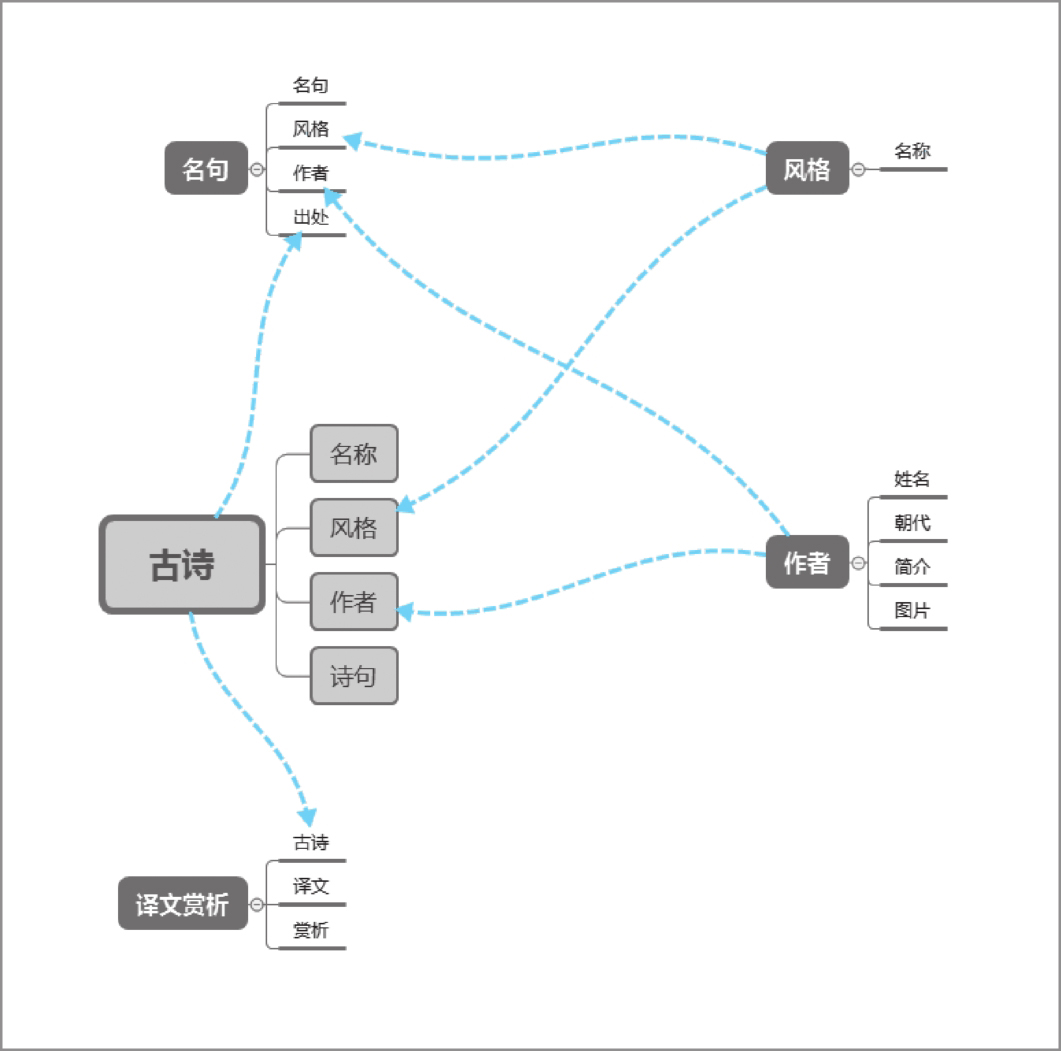
图4-1 中华古诗网站的数据组成


在“作者”类中定义了四个字段。
“姓名”被定义为用于存储少量文本内容的字符字段(CharField),并且根据中国人姓名的特点(未考虑少数民族),将“姓名”字段定义为最多容纳5个文字。
“朝代”同样被定义为字符字段,最大长度为3个字符,并且需要从“朝代选项”中进行选择(choices)。“朝代选项”是一个元组。元组中每一个元素是由两个字符串组成的元组。前一个字符串是存储到数据库中的数据,后一个字符串是显示在网页中的信息。
“简介”被定义为用于存储大量文本内容的文本字段(TextField)。因为有些作者可能没有简介内容,所以设置默认值(default)为“尚无简介。”。
“图片”被定义为图片字段(ImageField),并指定了上传(upload)目录“author_img/”。因为有些作者没有肖像图片,所以允许数据库中这个字段为空值(null),并且允许在前端页面中添加作者信息时将图片信息留空(blank)。
注意,因为需要在上传图片时对图片数据进行处理,需要安装代码库Pillow,否则会导致程序异常。
执行命令: pip install pillow
另外,在同一个“朝代”中不能出现相同“姓名”的作者,需要联合(Together)两个字段进行唯一(Unique)约束。所以,在内部的“Meta”类中,需要设置“unique_together”,为其指定字段元组。

“风格”类比较简单,只有“名称”字段需要定义。因为风格名称必须是唯一的,所以直接设为主键(primary_key),并限制最大字符数量为5个。

“名称”字段定义为字符字段,最大字符数量为64个。
“作者”字段依赖于相应模型类。也就是说,一首古诗的作者对应一条已存在的作者数据记录。所以,需要指定外键(ForeignKey)关系。第一个参数是对应的模型类的名称。第二个参数是关联名称(related_name),指定这个名称的用途是能够让我们通过某一个作者的数据对象快速查询到该作者关联的所有古诗。最后一个参数是指定删除时(on_delete)需要进行级联(CASCADE)删除,即删除某一作者时,同步删除该作者的所有古诗。
“诗句”定义为文本字段,以适应不同长度的诗句内容。诗句内容限定是唯一的(unique)。
“风格”字段定义为多对多字段(ManyToManyField)。因为一首古诗可能包含多种风格,例如古诗《咏柳》包含“春天”和“咏物”的风格。而一种风格也可能包含多首古诗,例如“秋天”风格的古诗有《长安秋望》《枫桥夜泊》《江上》等。所以,需要指定多对多关系。第一个参数是对应的模型类的名称。第二个参数是关联名称,用于查询同一风格的古诗。

“诗句”定义为文本字段,存储一些节选的诗句。诗句内容限定是唯一的。
“风格”字段定义为多对多字段。原因与“古诗”类中同名字段相同。
“作者”定义为外键字段。原因与“古诗”类中同名字段相同。
“出处”定义为外键字段。记录一条名句出自哪一首古诗。

“古诗”定义为一对一字段(OneToOneField)。因为古诗与译文赏析是一一对应关系。不会出现一首古诗对应多个译文赏析,或一个译文赏析对应多首古诗的情况。实际上,“译文赏析”是“古诗”数据的扩展,因为译文赏析只会出现在古诗详情的数据中,所以单独进行数据的存储。当一首古诗被删除时(on_delete),相应的译文赏析也需要清理,所以设定为级联(CAS-CADE)删除。
“译文”和“赏析”都定义为文本字段。因为有些古诗可能没有译文赏析,所以指定默认“default”内容为“尚无译文。”和“尚无赏析。”。
在以上模型类中,我们使用了Django的3种标准字段和3种关系字段。实际上,Django包含标准字段还有很多,具体如下。
AutoField
BigAutoField
BigIntegerField
BinaryField
BooleanField
CharField
DateField
DateTimeField
DecimalField
DurationField
EmailField
FileField
FilePathField
FloatField
GenericIPAddressField
ImageField
IntegerField
JSONField
PositiveBigIntegerField
PositiveIntegerField
PositiveSmallIntegerField
SlugField
SmallAutoField
SmallIntegerField
TextField
TimeField
URLField
UUIDField
这些字段中比较常用的有自增字段(AutoField)、整数字段(IntegerField)、浮点数字段(FloatField)、日期时间字段(DateTimeField)、文件字段(FileField)等。
关于标准字段的用途与使用方法,在Django的官方文档中有详细的介绍。
文档路径:/django-docs-4.1-zh-hans/ref/models/fields.html。
段落标题:字段类型。
绝大部分时候,这些标准字段能够完全满足我们的开发需求。
当完成模型类的编写,我们就可以通过模型类进行数据库中数据表的创建。