
下载掌阅APP,畅读海量书库
立即打开



索引指应用程序在查询时,尽量使用数据库索引进行查询。数据库表在创建时也尽量对查询条件的字段建立合适的索引。这里强调一定是合适的索引,如果索引建立不合适,不仅对查询效率没有任何的帮助,反而会使数据库表在插入数据时变得更慢,因为一旦建立了索引,数据在插入时,索引也会自动更新,这样就加大了数据库数据插入时的资源消耗。例如,数据库表中有一个字段为status,而status的取值只有0、1、2三个值,这时候如果对status建立索引,对查询效率没有任何帮助,因为status字段的值只有0、1、2这三个值,取值范围太少,建立索引后根据status去检索时,需要扫描的数据量还是非常大的。
正确使用索引可以很好地提高查询效率,但是如果一个表的数据量非常庞大,比如达到了亿万级别,此时索引查询很慢,并且新数据插入时也很慢,这就需要对数据进行分表或者分库。分库一般指的是一个数据库的存储量已经很大了,查询和插入时I/O消耗非常大,此时就需要将数据库拆分成2个库,以减轻读写时I/O的压力,如图1-7-10所示。
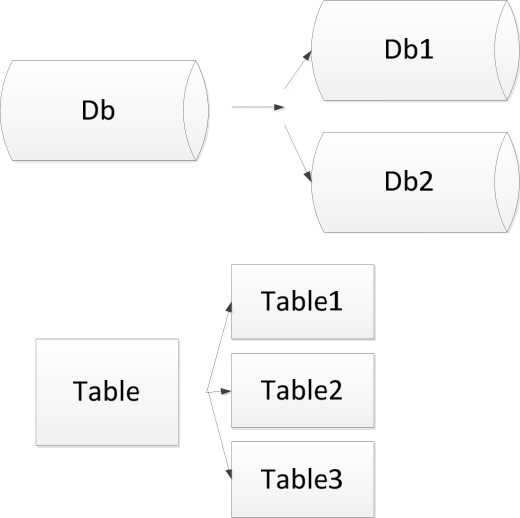
图1-7-10
常见的分库分表方式如下:
· 按照冷热数据分离的方式:一般将查询频率较高的数据称为热数据,查询频率较低或者几乎不被查询的数据称为冷数据。冷热数据分离后,热数据单独存储,这样数据量就会下降,查询的性能自然也就提升了,而且还可以更方便地单独针对热数据进行I/O性能调优。
· 按照时间维度的方式:比如可以按照实时数据和历史数据分库分表,也可以按照年份、月份等时间区间进行分库分表,目的是尽可能地减少每个库表中的数据量。
· 按照一定的算法计算的方式:此种方式一般适用于数据都是热数据的情况,比如数据无法做冷热分离,所有的数据都经常被查询到,而且数据量又非常大,此时就可以根据数据中的某个字段执行算法(注意:这个字段一般是数据查询时的检索条件字段),使得数据插入后能均匀地落到不同的分表中去(由算法决定每条数据进入哪个分表),查询时再根据查询条件字段执行同样的算法,就可以快速定位到是需要到哪个分表中去进行数据查询。
在分库分表后,写入数据时就可以按照如图1-7-11所示的方式进行分布式写入。数据分库分表带来的另一个好处就是:如果在单次查询时需要查询多个分表,那么就可以通过多线程并行的方式去查询每个分表,最后合并每个分表的查询结果即可,这样也可以使得查询的效率更高,如图1-7-12所示。
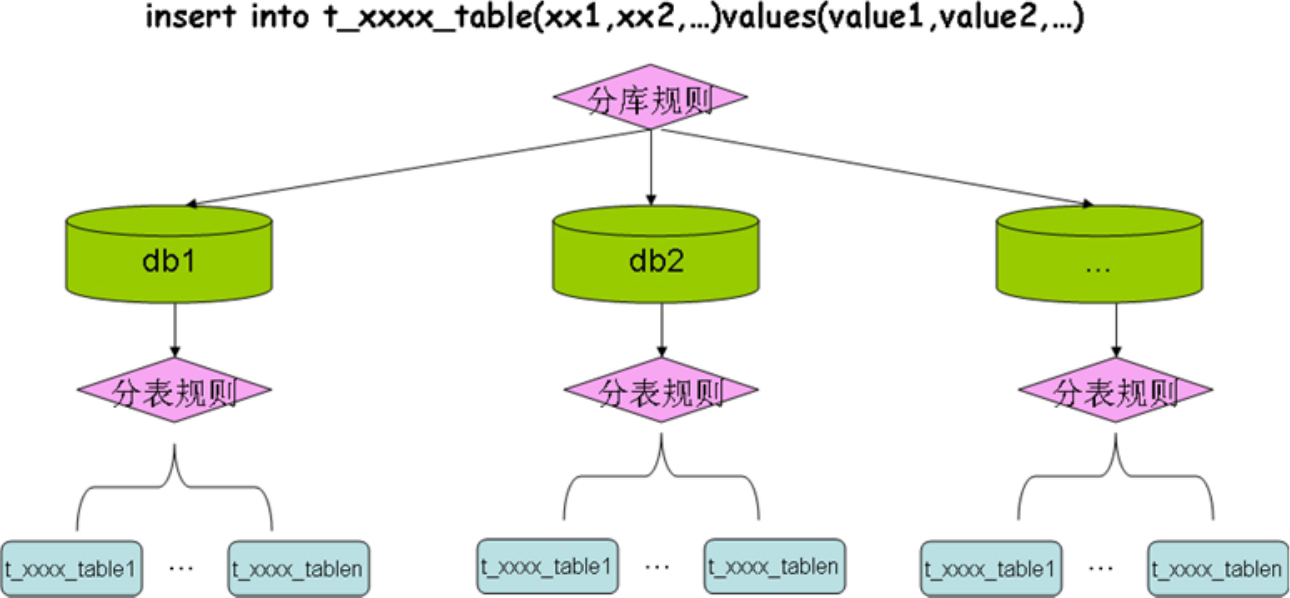
图1-7-11
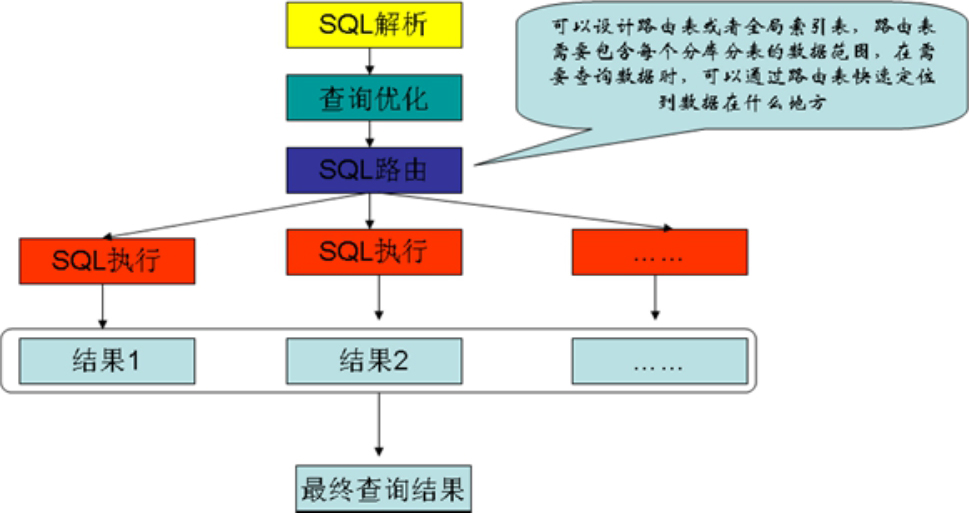
图1-7-12
数据分库分表的关键点如下:
· 合理设计路由表,当需要查询数据时,能快速地定位到需要查询的数据是分布在哪些库的哪些表中,这样就能快速到对应的库和表中去做查询。
· 设计分库时,根据实际业务场景,尽量减少跨库之间的关联查询,因为不同的库的数据一般分布在不同的存储上,如果做关联查询,那么就会涉及大量数据的网络传输,从而影响查询性能。
· 设计分表时,尽可能根据实际业务场景让每个分表的数据分布相对比较均匀。