下载掌阅APP,畅读海量书库
立即打开



如第1章所述,像DistilBERT这样的模型被预训练用于预测文本序列中的掩码单词。然而,这些语言模型不能直接用于文本分类,我们需要稍微修改它们。为了理解需要做哪些修改,我们来看一下基于编码器的模型(如DistilBERT)的架构,如图2-4所示。
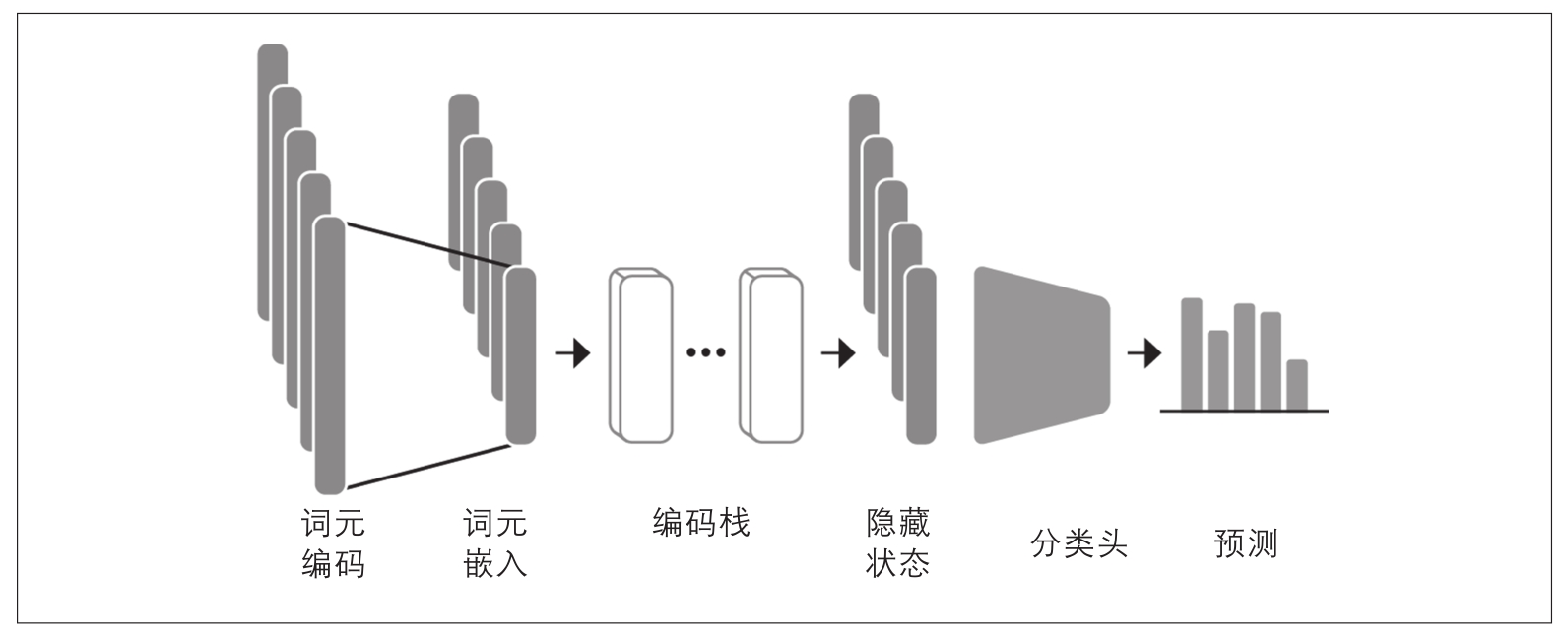
图2-4:使用基于编码器的Transformer进行序列分类的架构。它由模型的预训练主体和自定义分类头组合而成
首先,文本会被词元化并表示为称为词元编码的独热向量。词元编码的维度由词元分析器词表的大小决定,通常包括两万到二十万个唯一性词元。接下来,这些词元编码会被转换为词元嵌入,即存在于低维空间中的向量。然后,这些词元嵌入会通过编码器块层传递,以产生每个输入词元的隐藏状态。对于语言建模的预训练目标 [6] ,每个隐藏状态都被馈送到一个层,该层预测掩码输入词元。对于分类任务,我们将语言建模层替换为分类层。
 实际上,PyTorch在实现中跳过了为词元编码创建独热向量的步骤,因为将矩阵与独热向量相乘等同于从矩阵中选择一列。这可以通过直接从矩阵中获取词元ID对应的列来完成。当我们使用nn.Embedding类时,我们将在第3章中看到这一点。
实际上,PyTorch在实现中跳过了为词元编码创建独热向量的步骤,因为将矩阵与独热向量相乘等同于从矩阵中选择一列。这可以通过直接从矩阵中获取词元ID对应的列来完成。当我们使用nn.Embedding类时,我们将在第3章中看到这一点。
我们有以下两种选择来基于Twitter数据集进行模型训练:
特征提取
我们将隐藏状态用作特征,只需训练分类器,而无须修改预训练模型。
微调
我们对整个模型进行端到端的训练,这样还会更新预训练模型的参数。
接下来我们将讲述基于DistilBERT的以上两种选择,以及这两种选择的权衡取舍。
使用Transformer作为特征提取器相当简单。如图2-5所示,我们在训练期间冻结主体的权重,并将隐藏状态用作分类器的特征。这种方法的优点是,我们可以快速训练一个小型或浅层模型。这样的模型可以是神经分类层或不依赖于梯度的方法,例如随机森林。这种方法特别适用于没有GPU的场景,因为隐藏状态只需要预计算一次。
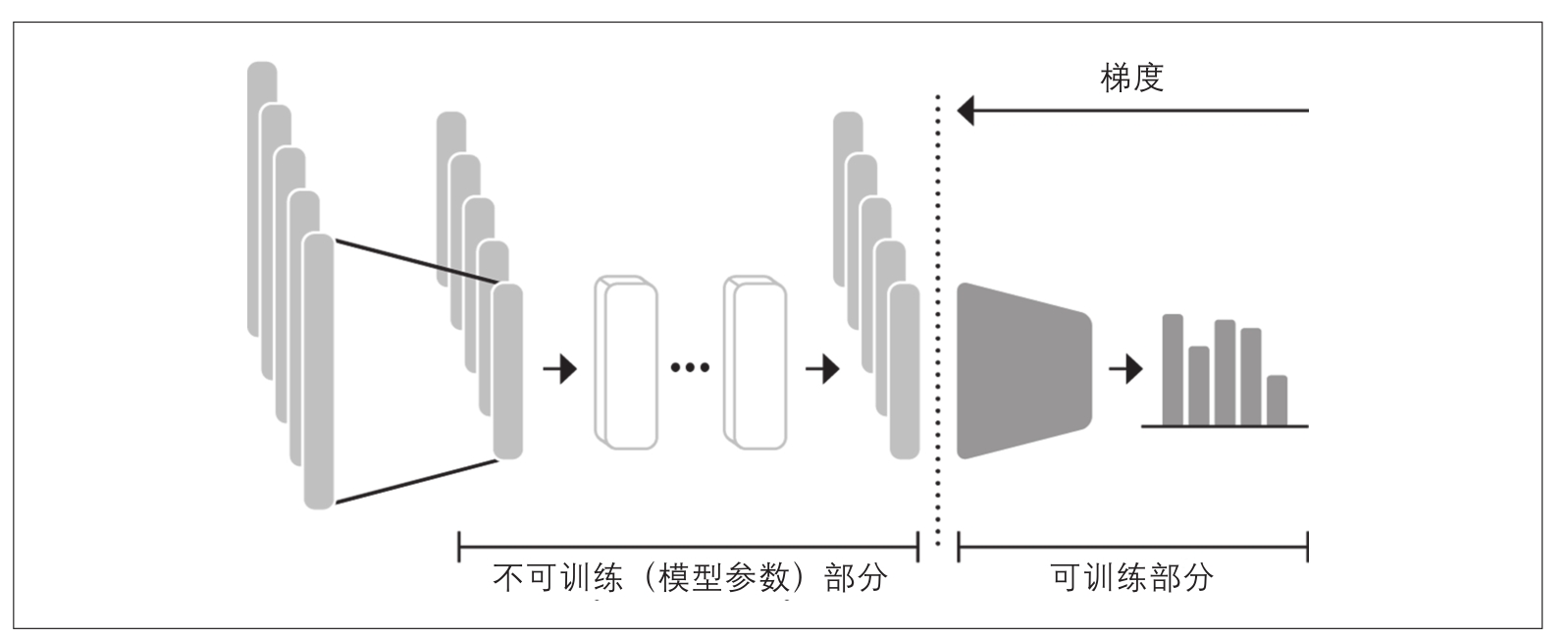
图2-5:在基于特征的方法中,DistilBERT模型是冻结的,只提供用于分类器的特征
加载预训练模型
我们将使用Hugging Face Transformers库中另一个很方便的自动类AutoModel。与AutoTokenizer类似,AutoModel具有from_pretrained()方法,可用于加载预训练模型的权重。现在我们使用该方法来加载DistilBERT checkpoint:

这里我们使用PyTorch来检查GPU是否可用(即代码torch.cuda.is available()),然后将PyTorch的nn.Module.to()方法与模型加载器链接起来(即代码to(device))。这确保了如果有GPU,模型将在GPU上运行。如果没有,模型将在CPU上运行,不过这样可能会慢很多。
AutoModel类将词元编码转换为嵌入向量,然后将它们馈送到编码器栈中以返回隐藏状态。我们看一下如何从语料库中提取这些状态。
虽然本书中的代码大多用PyTorch编写,但Hugging Face Transformers库可以与TensorFlow和JAX紧密协作。这意味着你只需要改变一些代码即可在你最喜欢的深度学习框架中加载预训练模型!例如,我们可以使用TFAutoModel类在TensorFlow中加载DistilBERT:

当模型仅在一个框架中发布,而你想在另一个框架中使用时,这种互操作性特别有用。例如,在第4章中我们会遇到XLM-RoBERTa模型( https://oreil.ly/OUMvG ),它只有PyTorch权重,因此如果你尝试像之前一样在TensorFlow中加载它:

你将会得到一个错误。在这种情况下,你可以将from_pt=True参数传给TfAutoModel.from pretrained()函数,库将自动为你下载并转换PyTorch权重:

你可以看到,在Hugging Face Transformers库中切换框架非常简单!在大多数情况下,你只需要在类名前添加TF前缀即可获得相应的TensorFlow2.0类。同理,如果要加载PyTorch的权重,你只需要将tf替换成pt字符串即可(例如在接下来的部分中),pt是PyTorch的简称,就像tf代表TensorFlow一样。
提取最终隐藏状态
作为预热,我们检索一个字符串的最终隐藏状态。我们需要做的第一件事是对字符串进行编码并将词元转换为PyTorch张量。可以通过向词元分析器提供return_tensors=”pt”参数来实现。具体如下:

我们可以看到,生成的张量形状为[batch size,n_tokens]。现在我们已经将编码作为张量获取,最后一步是将它们放置在与模型相同的设备上,并按以下方式传输入:

这里我们使用了torch.no_grad()上下文管理器来禁用梯度的自动计算。这对推理很有用,因为它减少了计算的内存占用。根据模型配置,输出可以包含多个对象,例如隐藏状态、损失或注意力,这些对象以类似于Python中的namedtuple的形式排列。在我们的示例中,模型输出是一个BaseModelOutput实例,并且包含了其属性名,我们可以通过这些属性名来获取其详情。我们看到,我们的模型只有一个属性,即last_hidden_state(最终隐藏状态),然后我们通过以下代码查看一下它的形状:

我们可以看到,隐藏状态张量的形状为[batch_size,n_tokens,hidden_dim]。换句话说,对于每个输入词元,都会返回一个768维向量。对于分类任务,通常惯例是只使用与[CLS]词元关联的隐藏状态作为输入特征。由于此词元出现在每个序列的开头,我们可以通过简单地索引outputs.last_hidden_state来提取它,如下所示:

现在我们知道如何针对单个字符串获取最终隐藏状态。我们通过创建一个新的hidden_state列来对整个数据集执行相同的操作,以存储所有这些向量。就像我们在词元分析器中所做的那样,我们将使用DatasetDict的map()方法一次性提取所有隐藏状态。我们需要做的第一件事是将先前的步骤封装在一个处理函数中:

这个函数和我们之前的逻辑的唯一不同在于最后一步,即将最终的隐藏状态作为NumPy数组放回CPU。当我们使用批量输入时,map()方法要求处理函数返回Python或NumPy对象。
由于我们的模型期望输入张量,下一步需要将input_ids和attention_mask列转换为torch格式,具体如下:

然后我们可以一次性提取所有分割的隐藏状态:
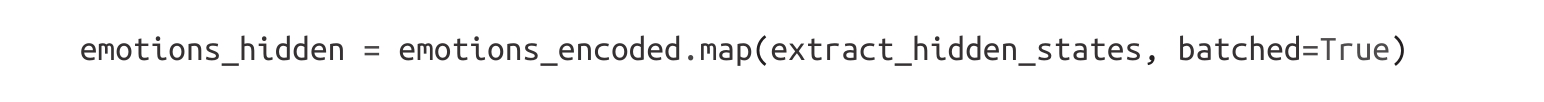
请注意,这里我们没有设置batch_size=None,这意味着使用了默认的batch_size=1000。正如预期的那样,应用extract_hidden_states()函数将一个新的hidden_state列添加到我们的数据集中。

现在我们已经得到了与每个推文相关联的隐藏状态,下一步是基于它们训练一个分类器。为了做到这一点,我们需要一个特征矩阵,我们来看一下。
创建特征矩阵
现在,经过预处理的数据集包含了我们需要训练分类器的所有信息。我们将使用隐藏状态作为输入特征,标注作为目标。我们可以很容易地按照以下方式创建对应的数组,以Scikit-learn格式为基础:

在对隐藏状态进行模型训练之前,进行快速检查以确保它们提供了我们想要分类的情感的有用表示是一个良好的实践。接下来,我们将看到可视化特征提供了一种快速的方法来实现这一点。
可视化训练集
由于在768维度中可视化隐藏状态是个艰难的任务,因此我们将使用强大的UMAP算法将向量投影到2D平面上 [7] 。由于UMAP在特征缩放到[0,1]区间内时效果最佳,因此我们将首先应用一个MinMaxScaler,然后使用umap-learn库的UMAP实现来缩放隐藏状态:

结果是一个数组,该数组具有相同的训练样本数量,但只有2个特征,而不是我们最初使用的768个特征!我们进一步探究压缩后的数据,并分别绘制每个类别的点密度图:

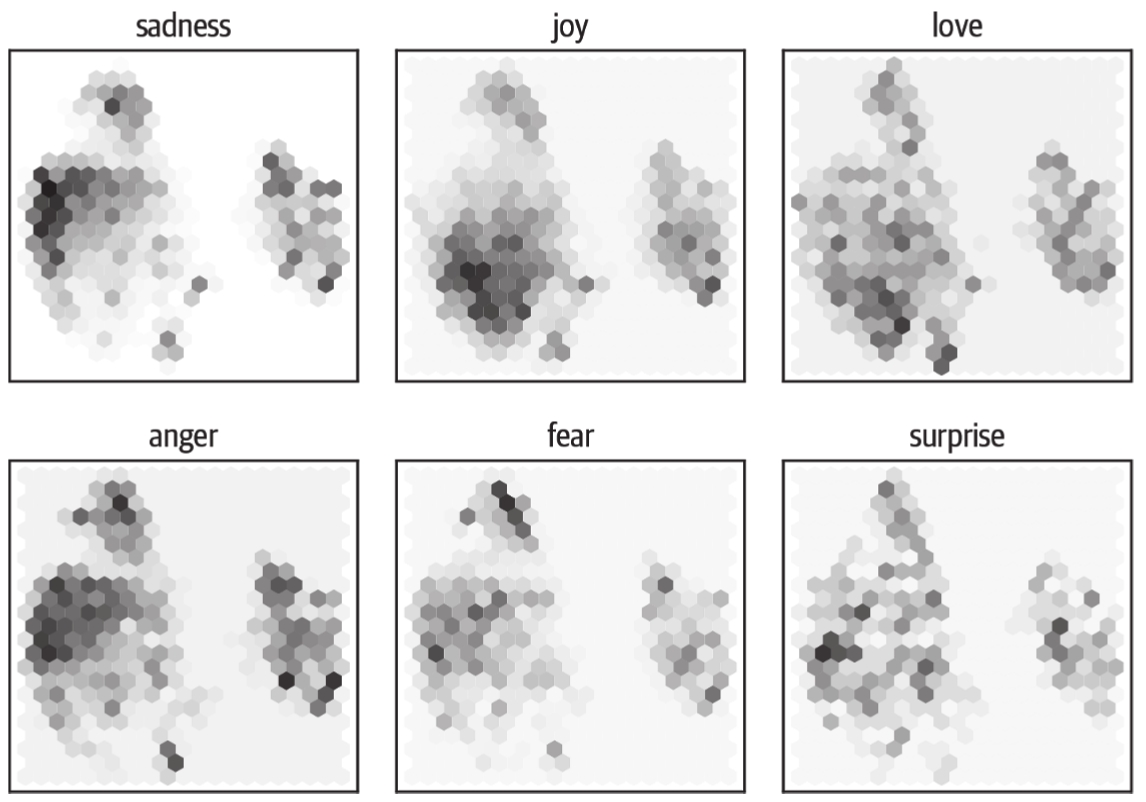
 这些只是投影到较低维空间的结果。某些类别重叠并不意味着它们在原始空间中不能区分。相反,如果它们在投影空间中是可区分的,那么它们在原始空间中也将是可区分的。
这些只是投影到较低维空间的结果。某些类别重叠并不意味着它们在原始空间中不能区分。相反,如果它们在投影空间中是可区分的,那么它们在原始空间中也将是可区分的。
从这个图中,我们可以看到一些明显的模式:负面情感,如悲伤(sadness)、愤怒(anger)和恐惧(fear),都占据着类似的区域,但分布略有不同。另外,喜悦(joy)和爱情(love)与负面情感明显分开,并且也共享一个相似的空间。最后,惊奇(surprise)分散在整个图中。虽然我们可能希望有些区分,但这并不是肯定的,因为该模型并没有被训练去区分这些情感。它只是通过猜测文本中被掩码的单词来隐式地学习它们。
现在我们已经对数据集的特征有了一些了解,接下来我们来到最后一步,基于数据集训练模型!
训练一个简单的分类器
我们已经看到,不同情感的隐藏状态是不同的,尽管其中一些情感并没有明显的界限。现在让我们使用这些隐藏状态来训练一个逻辑回归模型(使用Scikit-learn)。训练这样一个简单的模型速度很快,而且不需要GPU:

从准确率上看,我们的模型似乎只比随机模型稍微好一点,但由于我们处理的是一个不平衡的多分类数据集,它实际上会显著地表现更好。我们可以通过将其与简单基准进行比较来检查我们的模型是否良好。在Scikit-learn中,有一个DummyClassifier可以用于构建具有简单启发式的分类器,例如始终选择多数类或始终选择随机类。在这种情况下,表现最佳的启发式是始终选择最常见的类,这会产生约35%的准确率:

因此,使用DistilBERT嵌入的简单分类器明显优于我们的基线。我们可以通过查看分类器的混淆矩阵来进一步研究模型的性能,该矩阵告诉我们真实标注和预测标注之间的关系:

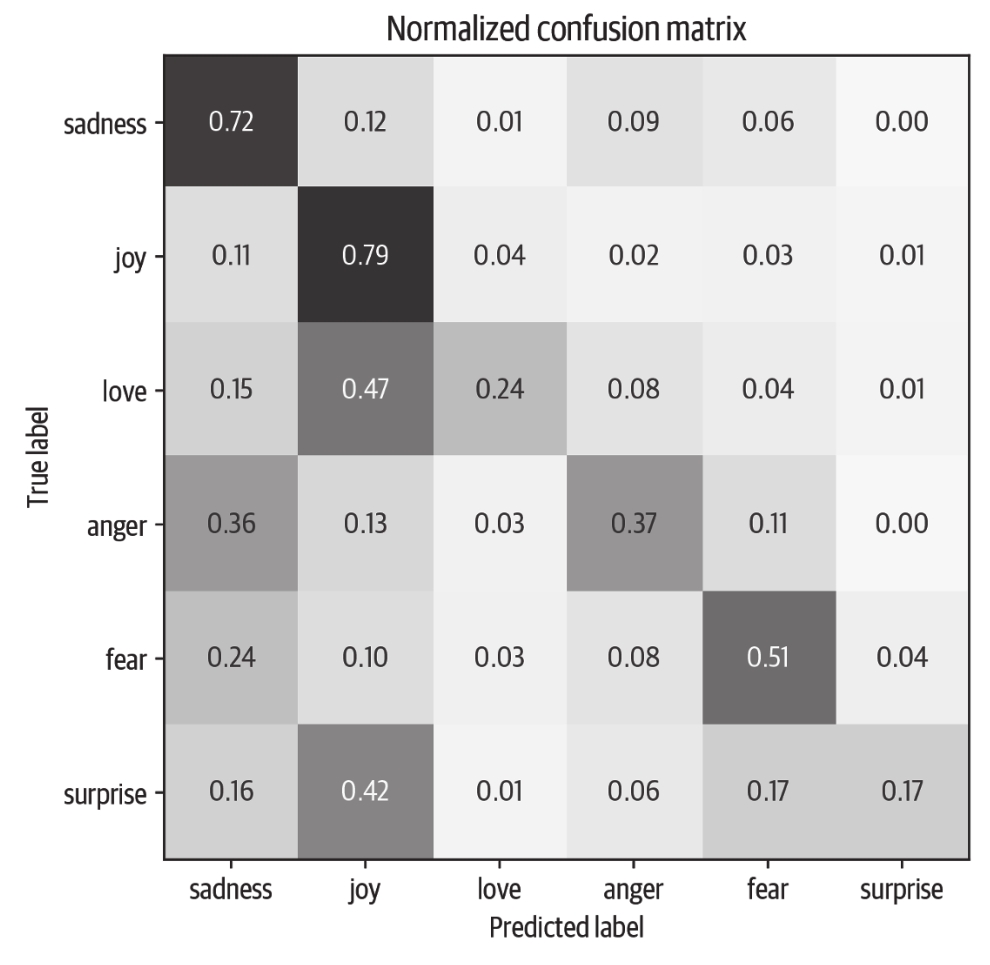
这里我们可以看到,anger和fear最常与sadness混淆,这与我们可视化嵌入时所观察到的一致。此外,love和surprise经常与joy混淆。
接下来我们将探究微调方法,这种方法可以带来更好的分类效果。但是,重要的是要注意,微调需要更多的计算资源,比如GPU,而你的组织可能没有GPU。在这种情况下,基于特征的方法可以是传统机器学习和深度学习之间的一个很好的折中方案。
现在我们探讨如何进行端到端的Transformer模型微调。在使用微调方法时,我们不使用隐藏状态作为固定特征,而是如图2-6所示那样进行训练。这要求分类头是可微的,这就是为什么这种方法通常使用神经网络进行分类。
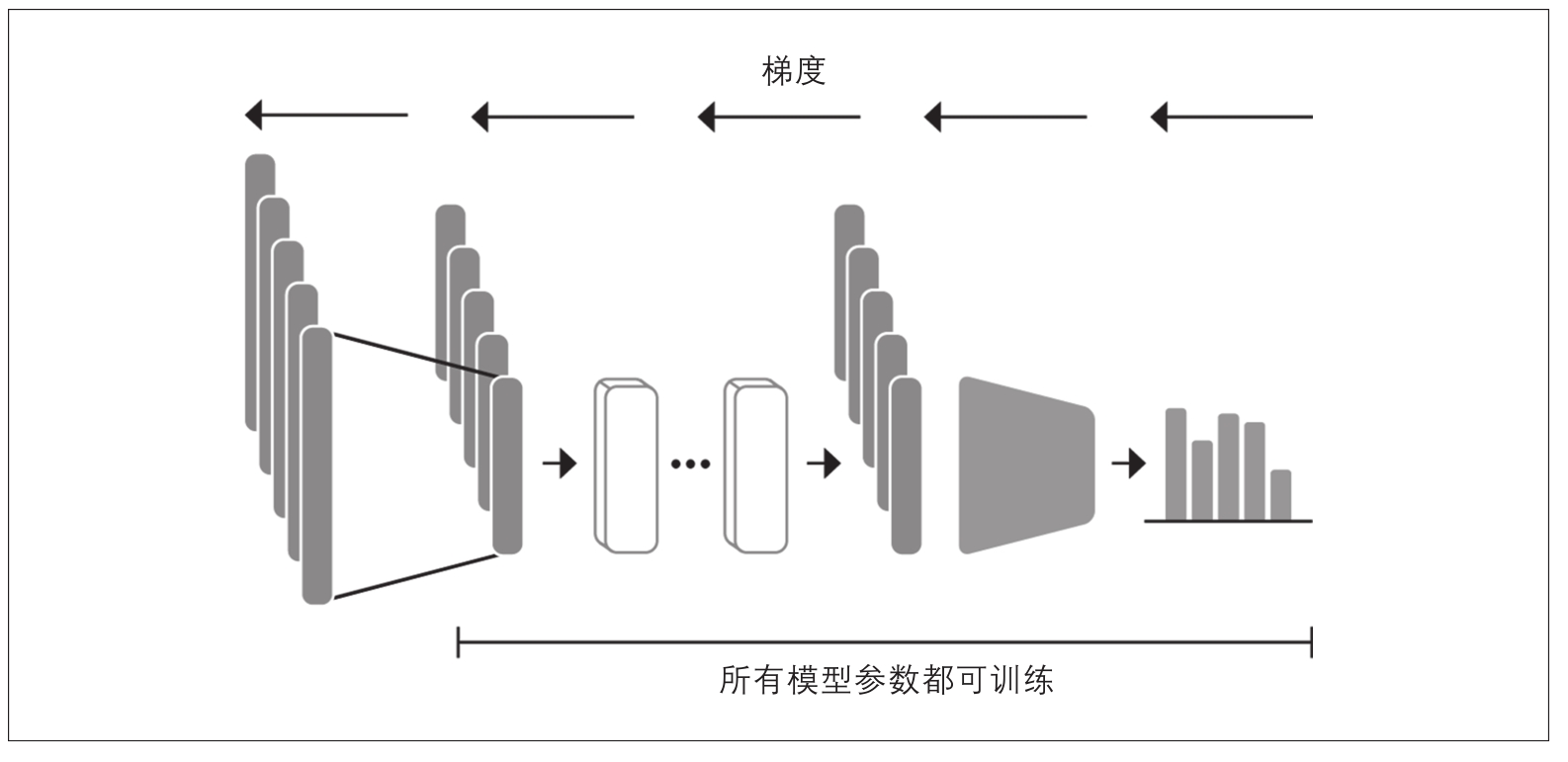
图2-6:在使用微调方法时,整个DistilBERT模型以及分类头一起进行训练
训练用作分类模型输入的隐藏状态将有助于我们避免使用可能不适合分类任务的数据的问题。相反,初始隐藏状态在训练过程中适配,以降低模型损失并提高其性能。
我们将使用Hugging Face Transformers库中的Trainer API简化训练循环。让我们看一下设置它所需的步骤!
加载预训练模型
我们要做的第一件事是使用我们在基于特征的方法中一样的DistilBERT预训练模型。唯一的细微修改是我们使用AutoModelForSequenceClassification模型而不是AutoModel。区别在于AutoModelForSequenceClassification模型在预训练模型输出的顶部有一个分类头,可以很容易地与基础模型一起训练。我们只需要指定模型需要预测的标注数量(在我们的情况下为6个),因为这决定了分类头输出的数量:

你会看到一个警告,说明模型的某些部分是随机初始化的。这是正常的,因为分类头还没有被训练。接下来的步骤是定义我们将用于评估模型在微调期间的性能的指标。
定义性能指标
为了在训练期间监控指标,我们需要为Trainer定义一个compute_metrics()函数。该函数接收一个EvalPrediction对象(这是一个具有predictions和label_ids属性的命名元组),并需要返回一个将每个指标名称映射到其值的字典。对于我们的应用,我们将计算模型的F1分数和准确率:

有了数据集和度量指标后,在定义Trainer类之前,我们只需要处理最后两件事情:
1.登录我们的Hugging Face Hub账户。从而让我们能够将我们的微调模型推送到Hub上,并与社区分享它。
2.定义训练运行的所有超参数。
接下来我们将解决这些步骤。
训练模型
如果你使用Jupyter notebook,你可以使用下面的辅助函数来登录到Hub:

然后会显示一个小部件,你可以在其中输入你的用户名和密码,或具有写入权限的访问令牌。你可以在Hub文档中找到有关如何创建访问令牌的详细信息( https://oreil.ly/IRkN1 )。如果你使用命令行终端,则可以通过运行以下命令登录:

我们将使用TrainingArguments类来定义训练参数。此类存储了大量信息,从而为训练和评估提供细粒度的控制。最重要的参数是output_dir,它是存储训练过程中所有工件的位置。以下是TrainingArguments的完整示例:

这里我们还设置了批量大小、学习率和迭代轮数,并指定在训练运行结束时加载最佳模型。所有组件都齐全了,我们可以使用Trainer实例化和微调我们的模型:
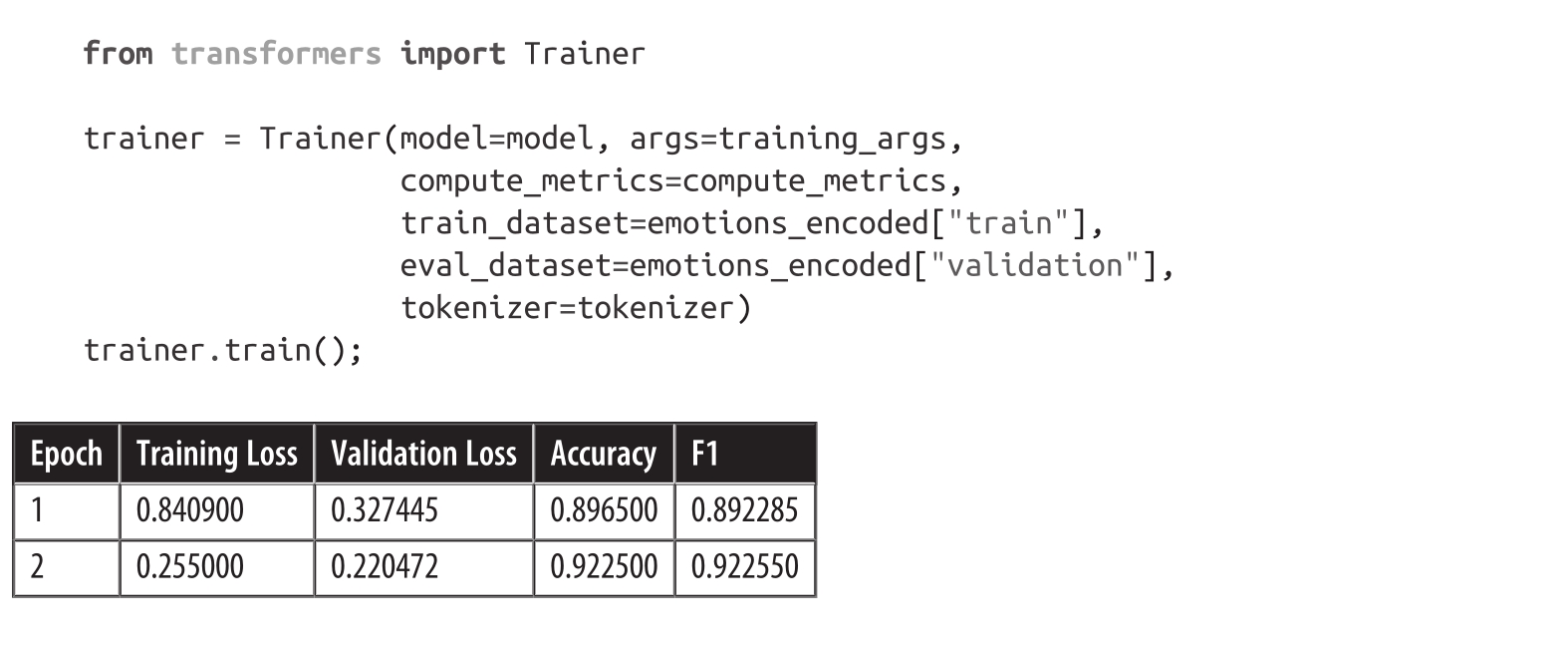
我们可以看到我们的模型在验证集上的F1分数约为92%,这比基于特征的方法有了显著的提升!
我们可以通过计算混淆矩阵来更详细地查看训练指标。为了可视化混淆矩阵,我们首先需要获取验证集上的预测结果。Trainer类的predict()方法返回了几个有用的对象,我们可以用它们进行评估:

predict()方法的输出是一个PredictionOutput对象,它包含了predictions和label_ids的数组,以及我们传给训练器的度量指标。我们可以通过以下方式访问验证集上的度量指标:

它还包含了每个类别的原始预测值。我们可以使用np.argmax()进行贪婪解码预测,然后会得到预测标注,并且结果格式与前面的基于特征的方法相同,以便我们进行比较:

我们可以基于这个预测结果再次绘制混淆矩阵:

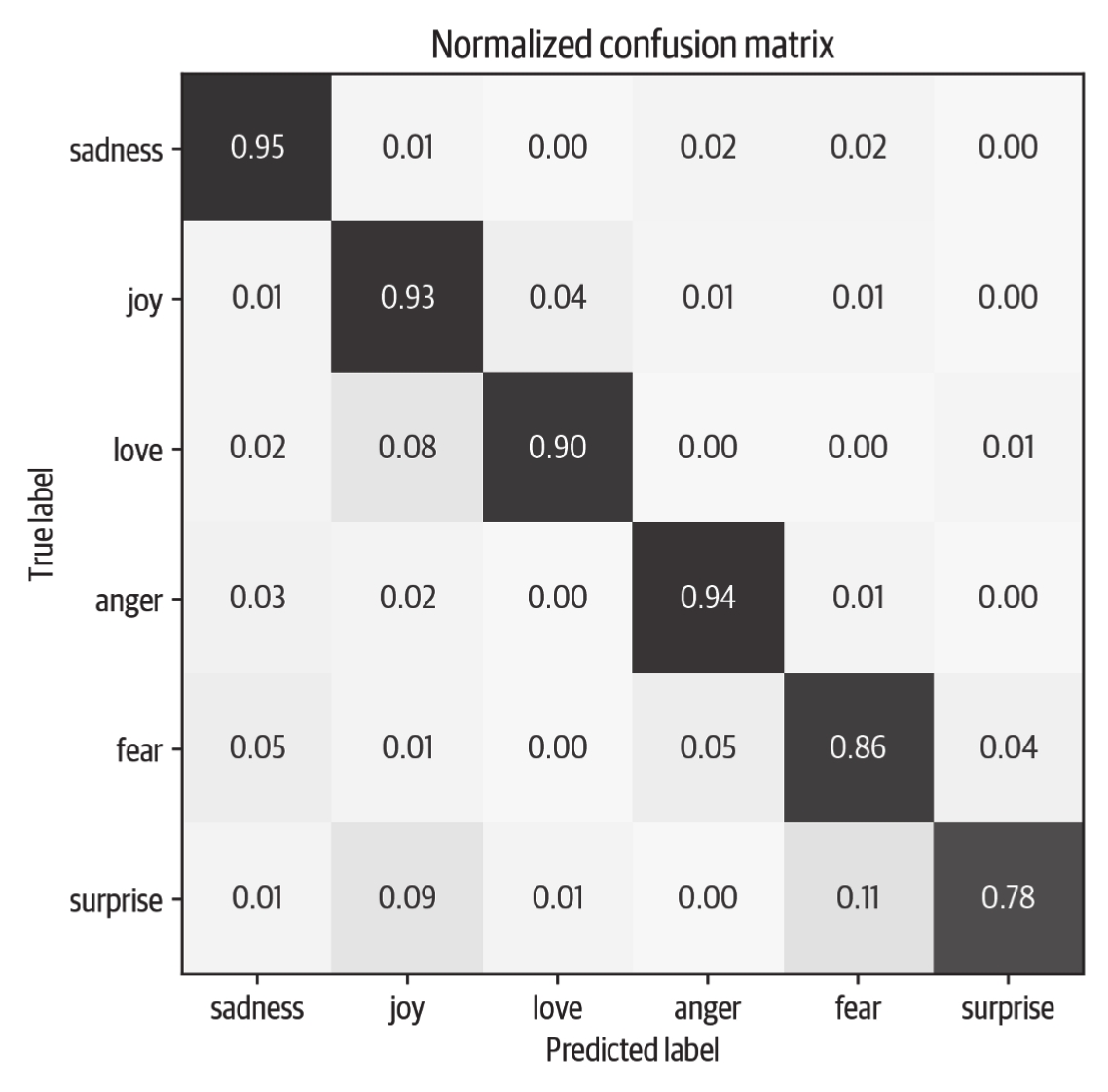
可见,与前面的基于特征的方法相比,微调方法的结果更接近于理想的对角线混淆矩阵。love类别仍然经常与joy混淆,这点逻辑上也讲得过去。surprise也经常被错误地识别为joy,或者与fear混淆。总体而言,模型的性能似乎非常不错,但在我们结束之前,让我们深入了解模型可能会犯的错误的类型。
如果你使用的是TensorFlow,那么还可以使用Keras API微调模型。其与PyTorch API的主要区别在于,没有Trainer类,因为Keras模型已经提供了内置的fit()方法。为了了解具体是如何工作的,这里我们将加载DistilBERT模型的TensorFlow版本:

接下来,我们将把数据集转换为tf.data.Dataset格式。因为我们已经填充了词元化输入,所以我们可以通过将to_tf_dataset()方法应用于emotions_encoded轻松完成此转换:

在这里,我们还对训练集进行了随机化,定义了它和验证集的批量大小。最后要做的是编译和训练模型:
误差分析
在继续之前,我们应该更深入地研究一下模型的预测。一个简单而又强大的技巧是按模型损失对验证样本进行排序。当我们在前向传递期间传递标注时,会自动计算并返回损失。以下是返回损失以及预测标注的函数:

我们可以再次使用map()方法将此函数应用到所有样本中以获得损失:

最后,我们创建一个包含文本、损失、预测标注、真实标注的DataFrame:

现在我们可以轻松地根据损失升序或降序对emotions_encoded进行排序。此操作的目的是检测以下内容之一:
错误的标注
任何对数据进行标注的过程都有可能出错。数据标注者可能会犯错误或者存在分歧,而从其他特征推断的标注也有可能是错误的。如果自动标注数据很容易,那么就不存在人工标注数据这项工作了。因此,有些样本被错误标注是很正常的。通过这种方法,我们可以快速找到并纠正它们。
数据集的特性
在现实世界中,数据集往往有一定的杂乱。当输入为文字时,输入中的特殊字符或字符串可能会对模型的预测产生重大影响。检查模型最弱的预测可以帮助识别这样的特征,清理数据或注入类似的样本可以使模型更健壮。
让我们先看一下损失最高的数据样本:
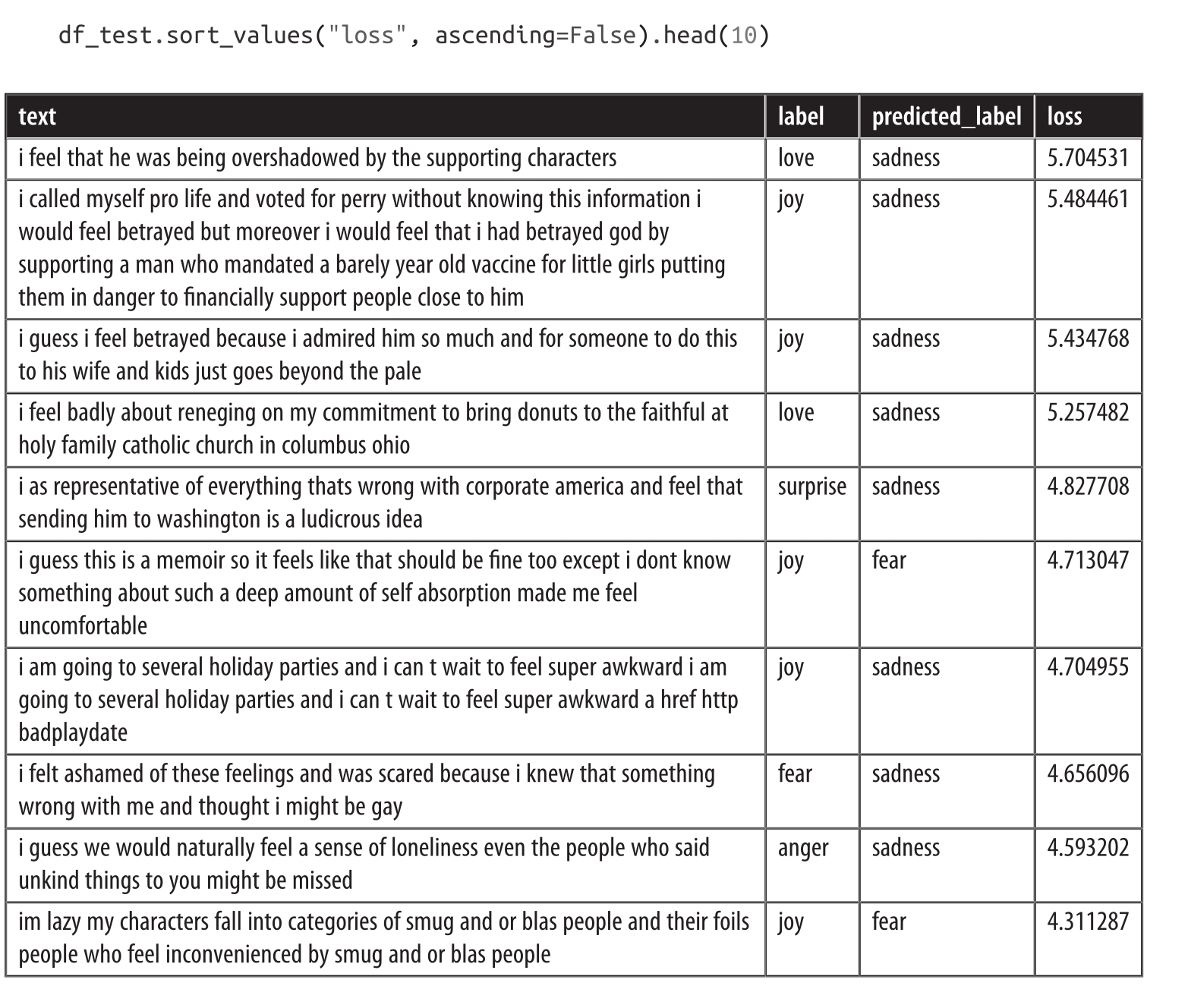
我们可以清楚地看到模型对某些标注进行了错误的预测。另外,似乎有相当多的样本没有明确的类,这可能是被错误标注的或需要一个新类。特别是,joy似乎被多次标注错误。通过这些信息,我们可以改进数据集,这通常可以带来与增加数据或使用更大的模型一样大的(或更大的)性能提升!
当查看具有最低损失的样本时,我们观察到模型在预测sadness类时最有信心。深度学习模型非常擅长找到和利用短路来进行预测。因此,值得花时间查看模型最有信心的样本,以便我们可以确信模型不会错误地利用文本的某些特征。所以,让我们也看一下损失最小的预测:


(续)
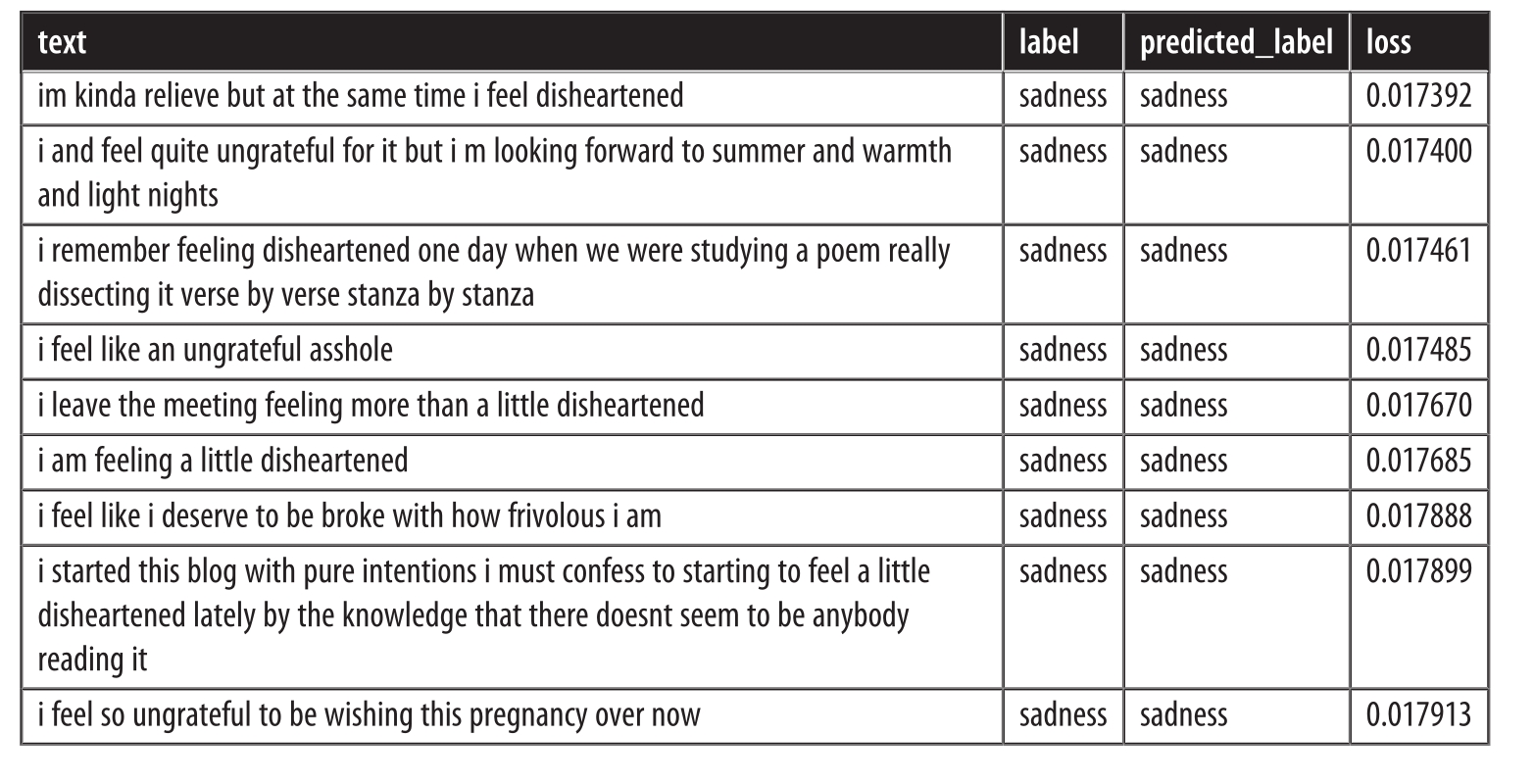
通过上面操作,我们可以看到joy有时会误标注,而模型对预测sadness标注最有信心。通过这些信息,我们可以有针对性地改进我们的数据集,并且还要关注模型最有信心的类别。
在使用训练好的模型之前的最后一步是将其保存以备后续使用。接下来我们将向你展示如何使用Hugging Face Transformers库来完成这个任务。
储存和共享模型
NLP社区通过共享预训练和微调模型获益匪浅,每个人都可以通过Hugging Face Hub与他人共享自己的模型。任何社区生成的模型都可以像我们下载DistilBERT模型一样从Hub中下载。我们可以通过使用Trainer API非常简单地保存和共享模型:

我们也可以使用微调模型来对新的推文进行预测。由于我们已将模型推到了Hub上,因此现在我们可以通过pipeline()函数来使用它,就像在第1章中所做的那样。首先,让我们加载pipeline:

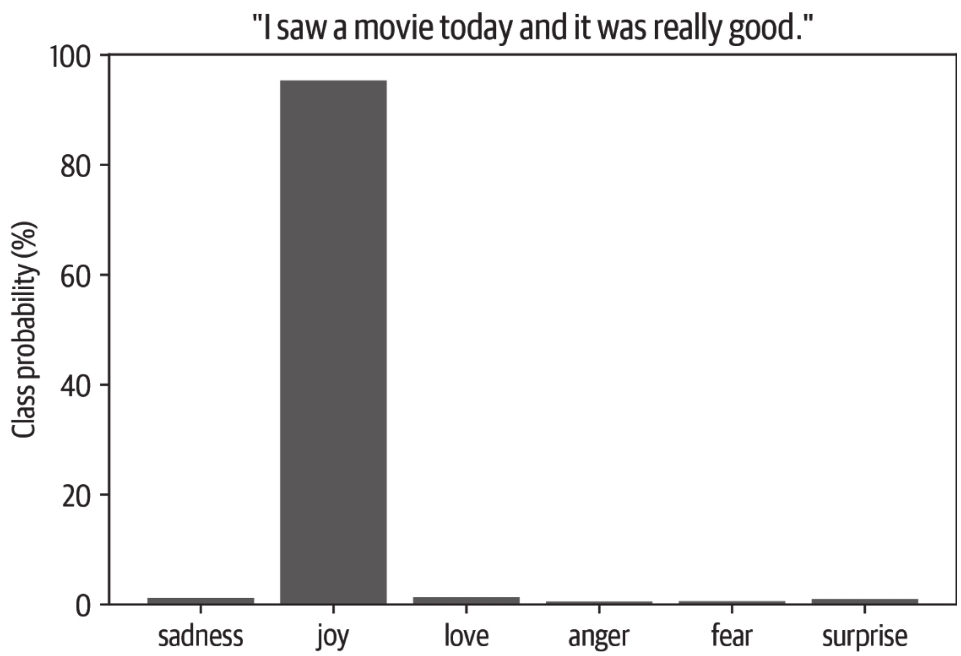
然后用一条样本推文来测试pipeline:

最后,我们可以用条形图绘制每个类别的概率。很明显,模型估计最可能的类是joy,这对于给定的推文似乎是合理的: