
下载掌阅APP,畅读海量书库
立即打开



人体行为识别技术是一种基于人体时空特征实现行为判别的先进技术,旨在理解目标人体的行为信息,是计算机视觉(Computer Vision,CV)领域的关键研究任务之一 [1-2] 。人体行为识别技术在人机交互 [3] 、虚拟现实 [4] 、体育运动分析、机器人技术 [5] 、运动员辅助训练、医疗诊断与监护 [6] 、智能家居系统、异常行为监测、游戏动画等领域具有十分广阔的发展前景与巨大的应用价值。特别是,随着国家安防体系与社会公共安全体系的健全发展,基于人体行为识别的智能监控与安防系统具有极大的社会价值与研究意义 [7] 。
随着深度学习理论在人工智能领域的快速演进,基于计算机视觉的人体行为识别技术逐渐成为人体行为识别领域的热点问题,其涵盖了数字图像处理、机器学习、计算机图像学、模式识别等多个学科。此技术的核心是以视频/图像为研究对象,通过对视频/图像中人体目标的行为进行处理、理解和分析,实现对目标人体行为的智能识别。同时,图像分类、目标检测、语义分割等底层计算机视觉任务的快速突破,使人体行为识别技术取得了瞩目的研究进展。当前,对基于可见光视觉信息的人体行为识别技术已经开展了较广泛的研究,但可见光成像系统较易受环境因素影响,在特殊外场环境(如光照不佳、沙尘、大雾、雨、雪等)下其技术劣势明显。此外,医疗智能监护、犯罪活动等特殊监控应用场景多发生在夜间,基于可见光视觉信息的人体行为识别技术无法满足特殊环境下的应用需求。
红外热成像技术与智能人体行为识别技术的融合对特殊外场环境下人体行为识别技术的革新具有推动作用。红外热成像技术是一种新型的物理研究技术,是红外热成像系统将其视场范围内因温度和发射率不同而产生的红外热辐射空间分布转换为红外热图像的技术。全辐射热像视频系统具有隐蔽性强、抗干扰能力强、对热目标敏感等优势,可以排除烟、雾、尘、雨、雪等能见度较低的恶劣外场环境的影响,更能够在无外部照明系统的情况下实现24小时全天候昼夜连续监测 [8] 。
红外视觉人体行为识别是计算机视觉领域具有挑战性的任务之一。目前,视觉人体行为识别研究多以检测单一异常行为为主 [9-14] ,检测模型的结构性较差,鲁棒性、实用性较低。同时,由于人体动作的高复杂性、环境复杂性、视角不定性等特定干扰因素的影响,使识别精度与识别速度并未达到应用领域的要求。此外,红外视觉下的人体目标存在对比度低、信噪比低、纹理特征匮乏、晕轮效应、灵敏度低等特点,采用传统基于可见光的人体行为识别技术往往无法取得较好的识别效果。因此,红外视觉人体行为识别系统性能的提升依然存在较大的研究空间,现阶段提出一种稳定、可靠、高效的红外视觉人体行为识别模型具有十分重要的研究意义。依据上述研究背景,本节介绍基于红外视觉的人体行为识别研究,研究的主要流程包括数据集的建立、模型构建与训练、检测结果定量分析。
人体行为识别技术的现代科学研究起源于20世纪70年代,瑞典心理学家Johansson G [15] 对人体动作感知问题进行了科学研究,提出了通过人体骨骼关键点描述其运动信息,并对其建模,从而识别人体行为。此后,相关研究人员提出了各种优秀的人体行为识别理论与方法。目前,人类行为的数据表征方式主要有RGB、骨架、深度、点云、事件流、音频、加速、雷达、Wi-Fi信号等。上述数据表征方式来源于不同的传感器信号,依据获取行为信号的传感器类型可以分为:①基于视觉传感器的人体行为识别,即以视觉信息为研究对象实现对人体行为的识别;②基于可穿戴式传感器的人体行为识别 [16-18] ,即通过可穿戴式传感器(如加速度计[19]、陀螺仪、信号接收器、速度计、手机等)获取人体动作信号特征,以实现对目标的行为识别;③基于环境式传感器的人体行为识别 [20] ,即通过压力传感器、声音传感器、振动传感器获取特定检测区域内目标人体的动作变化信号。
由于可穿戴式传感器和环境式传感器存在适用性差、可扩展性低、应用场景局限性大等技术劣势,基于视觉传感器的人体行为识别技术逐渐成为当前人体行为识别领域的重点研究方向。
随着深度学习理论及计算机硬件设备(CPU、GPU)性能的不断提升,基于视觉信息的人体行为识别技术得到了相关研究人员的青睐。基于视觉信息的人体行为识别技术的研究任务是让机器通过学习视频/图像中的表征信息,使其具有类似人类感知外部环境并做出判断的能力。基于视觉信息的人体行为识别技术就是从视觉的角度去分析人体姿态信息,以实现目标行为的定义、运动特征的提取、行为信息表征及行为理解的一种推理技术。
基于视觉信息的人体行为识别技术基于不同的准则有不同的分类方式:基于输入数据类型分为运动影像识别技术和静态图像识别技术;基于目标数量分为单人(Single-Person)人体行为识别技术和多人(Multiple-Person)人体行为识别技术;基于数据的维度分为2D人体行为识别技术和3D人体行为识别技术;基于特征提取方式分为传统识别技术和基于深度学习识别技术。视觉人体行为识别技术理论繁杂,但其技术路线可以概述为底层数据感知、数据预处理、时/空特征提取、特征融合与分类、行为识别5个阶段,如图3-1所示。

图3-1 视觉人体行为识别技术路线
在人体行为识别任务的发展过程中,早期研究学者多依赖手工设计的特征对人体运动信息进行提取并建立表征人体行为的模型,从而实现对人体行为的识别。人体行为特征表征方式可分为全局表征(Holistic Representations)和局部表征(Local Representations) [21] 。其中,全局表征是将人体的动作表征为一个整体,以提取目标人体结构、形状、动作的全局特征来全局分析人体行为。A F Bobick等人 [22] 提出的运动能量图(Motion Energy Image,MEI)和运动历史图(Motion History Image,MHI)方法较经典,首先使用背景剪除法获得人体轮廓,再通过人体轮廓图像的堆叠获得目标在视频上下文的运动表征信息。红外视觉下挥手动作的MEI和MHI如图3-2所示。全局表征虽然提取了动作的时空结构信息,但无法捕捉轮廓内的细节变化特征,存在检测适应性差,对噪声、遮挡、视点等变化敏感的缺点 [23-24] 。
局部表征是基于局部区域特征描述人体行为的方式,主要有时空兴趣点和运动轨迹两种方法。局部特征描述子包括HOG [25] 、HOF [26] 、SIFT [27] 、Harris3D [28] 、Cuboid [29] 、HOG3D [30] 、LBP [31] 、MBH [32] 等。Laptev I [33] 提出了时空兴趣点(Space-Time Interest Points,STIP)算法,使用兴趣点描述行为信息。通过构建STIP检测器,使用Harris3D检测器提取角点特征,形成一个局部描述子来表征人体行为。密集轨迹(Dense Trajectories,DT)算法 [34] 是经典的运动轨迹算法,其利用光流场来获取目标的运动轨迹,并沿着轨迹提取HOG、HOF、MBH 3种局部特征,最后对特征进行编码并训练SVM分类器以实现对目标的行为识别。Wang H等人 [35] 提出了改进的密集轨迹(Improve Dense Trajectories,IDT)算法,利用轨迹的位移矢量进行阈值处理,以消除相机光流带来的影响,从而提升识别精度。

图3-2 红外视觉下挥手动作的MEI和MHI
传统人体行为识别算法极易受物体遮挡、噪声、环境等因素的影响,导致识别结果的泛化能力、鲁棒性、适用性较差,无法应对更复杂的视觉任务。随着深度学习的兴起,卷积神经网络、循环神经网络、图神经网络、图卷积神经网络等深度学习模型在高维度、深层次特征提取方面发挥了重要作用。相较传统手工设计的低维度特征,深度学习算法提取的高维度特征具有更强的鲁棒性和代表性,特征表达能力也更强,获取的目标分类特征可以显著提高人体行为识别的精度。基于深度学习的人体行为识别模型主要有双流网络模型、3D卷积网络模型、时空混合网络模型等。
双流网络模型能对静态图像和光流场的时空特征进行提取。Simonyan K等人 [36] 提出了双流网络(Two-Stream Networks)结构,首先通过空域卷积网络实现对单帧图像空域特征的提取,然后通过时域卷积网络实现对多帧光流信息特征的提取,最后进行特征平均融合实现对动作的识别。双流网络模型框架如图3-3(a)所示。此外,Wang L等人 [37] 提出了时域分段网络(Time Segment Networks,TSN),通过稀疏时间采样和视频监督两种策略对双流网络模型进行了改进。双流网络模型相较单流网络模型其人体行为识别性能有较大的提升。
3D卷积网络模型是在2D卷积网络模型的基础上增加了对视频帧间运动信息的获取,对于连续性动作有较好的识别效果。Baccouche M等人 [38] 利用3D卷积核对视频进行三维卷积运算,以提取运动目标的空域特征和时域特征,提高人体行为识别的精确性和鲁棒性。Tran D等人 [39] 提出了C3D网络模型,其框架如图3-3(b)所示。随后,又在C3D基础上引入了残差网络(Residual Network),构建了Res3D网络 [40] ,进一步提升了网络的检测效率与运算速度。但使用3D卷积网络模型处理时序信号时,模型参数过于庞大且模型不易收敛,可部署性与实用性较差。
时空混合网络模型通常先采用卷积神经网络提取空域特征,再采用序列模型提取时域特征,最后通过特征融合方式实现行为分类,其中CNN-LSTM模型是时空混合网络模型的代表。Donahue J等人 [41] 提出的长期循环神经网络(Long-term Recurrent Convolutional Networks,LRCN)模型就是先通过卷积神经网络提取视觉特征,再通过长短期记忆神经网络提取时域特征,以实现对人体目标的行为识别,其框架如图3-3(c)所示。
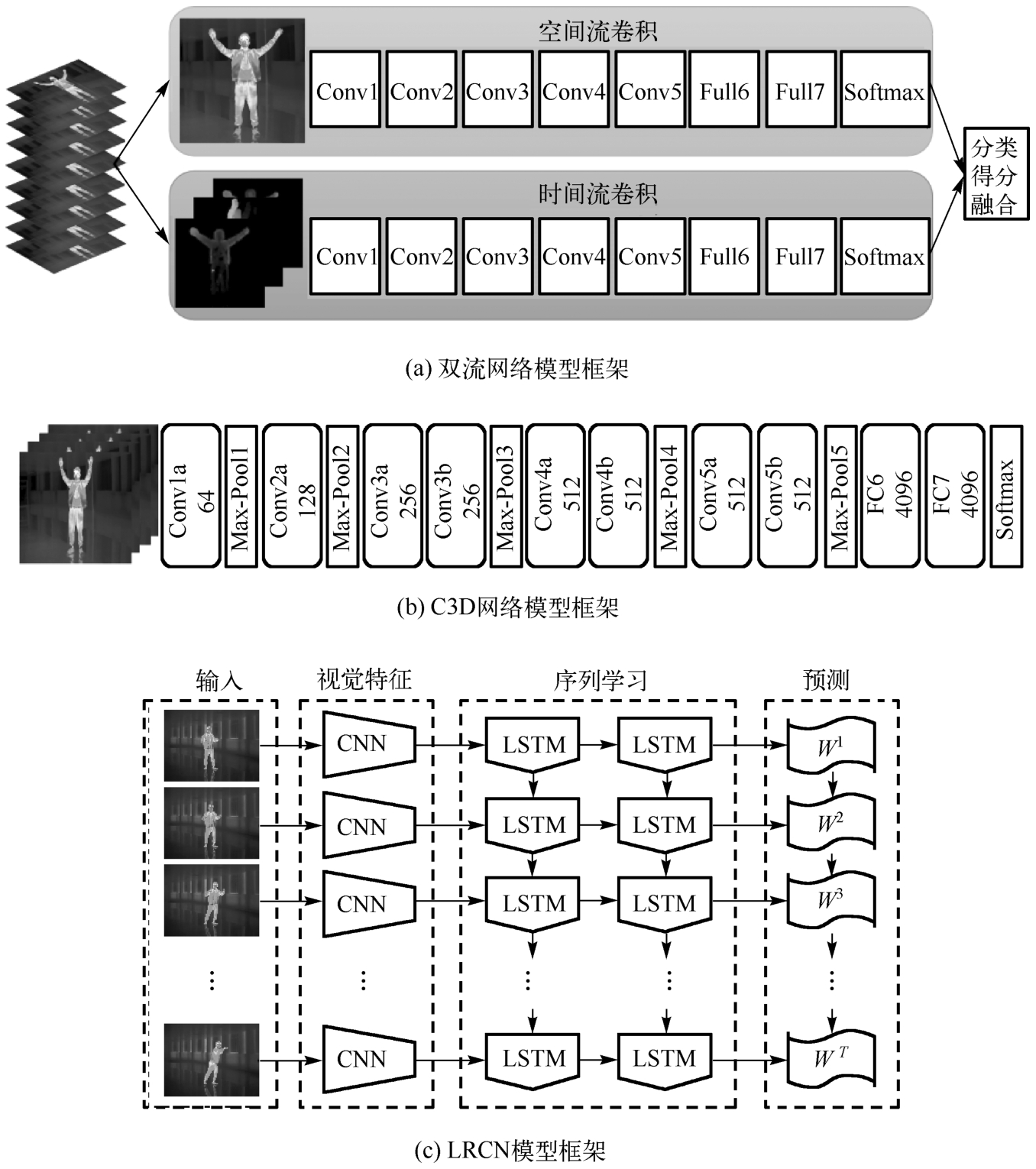
图3-3 人体行为识别相关模型结构
姿态估计是人体行为识别领域的底层计算机视觉任务之一,其核心思想是通过对目标人体的骨骼关键点进行检测,来实现对人体骨骼关键点的精确定位和对人体骨架信息的恢复。基于姿态估计的行为识别技术是当前视觉人体行为识别领域的热点研究方向之一,其以人体骨骼关键点数据作为人体行为的表征数据来实现目标行为的分类,具有可解释性强、鲁棒性强、适用性强、实时性强等优势。依据人体目标数量,人体姿态估计可分为单人姿态估计和多人姿态估计,其中单人姿态估计主要有模型表示和深度学习两种方法,多人姿态估计基于实现方式分为自顶向下(Top-Down)和自底向上(Bottom-Up)两种模式。
基于模型表示的姿态估计方法将人体骨骼关键点检测问题描述为图结构问题,其核心思想是通过手工设计特征提取人体骨骼关键点的位置信息,并通过特定的映射关系来实现图像特征与人体姿态模板的匹配。图结构模型 [42] 包括部件模型和空间模型,部件模型用于表征人体部件的信息,空间模型用于表征人体部件的空间关系。为了解决人体自遮挡问题,Wang J等人 [43] 提出了非树形结构模型;Yang Y等人 [44] 为了解决人体行为复杂的空间约束问题提出了混合部件模型;但人体结构的非刚性使基于模型表示的姿态估计方法的局限性较大。
DeepPose [45] 模型是首个基于深度神经网络的单目标姿态估计模型,将人体姿态估计问题比作人体骨骼关键点的回归问题,采用级联结构,通过多个阶段的模型优化,极大地提升了人体骨骼关键点的定位精度。Tompson J等人 [46] 将深度神经网络和图形模型相结合,通过预测人体骨骼关键点的热图(Heatmap)来实现人体姿态估计。Wei S等人 [47] 提出了卷积姿态机(Convolutional Pose Machines,CPMs),通过热图像的形式建立人体骨骼关键点的空间位置关系,并利用卷积层提取图像空域特征信息,以实现端到端的特征表达。Newell A等人 [48] 引入了堆叠沙漏网络(Stacked Hourglass Networks)模块,通过多级上采样和下采样获取不同尺度下的人体骨骼关键点特征信息及多尺度特征融合策略,对人体骨骼关键点特征提取网络进行了改进,极大地提升了人体骨骼关键点的检测精度。
多人姿态估计有两种模式,其中自顶向下模式可视为人体目标检测和单人姿态估计的组合,先对图像中的目标进行识别,再对每个目标进行人体骨骼关键点检测,以获取多目标的人体骨骼关键点信息。Fang H等人 [49] 提出了AlphaPose模型,即区域多人姿态估计(Regional Multi-person Pose Estimation,RMPE)模型,首先通过对称空间变换网络对人体边界框位置信息进行校正,并与单人姿态估计模型结合,然后通过姿态引导的候选框生成器对单人姿态估计器的训练进行数据增强,最后引入非极大值抑制重复检测问题。但AlphaPose模型基于ResNet50、ResNet101,模型的计算量大、运算速度慢。
自底向上模式先对图像中的所有人体骨骼关键点进行检测,再基于聚类算法或人体结构先验信息实现多目标姿态估计。Pishchulin L等人 [50] 提出的Deepcut模型使用局部检测器获取部件候选集合,通过求解整数线性规划问题(Integer Linear Program,ILP)对候选集合进行非极大值抑制,以实现多目标姿态估计。Cao Z等人 [51] 提出的OpenPose模型采用局部亲和场(Part Affinity Field,PAF)对CPMs得到的任意两个相邻的人体骨骼关键点建立有向场,从而实现人体骨骼关键点的匹配。Sun Ke等人 [52] 提出的HRNet(Hight-Resolution Networks)高分辨率基础网络模型,采用并行连接高分辨率到低分辨率卷积策略来保持高分辨率表示。同时采用多尺度特征融合使高分辨率特征具有更多的语义信息和位置信息,从而获得更大的感受野和更丰富的上下文信息。为了提升对弱小目标姿态估计的精度,Cheng B等人 [53] 提出了Higher HRNet模型,通过对高分辨率特征图进行卷积运算,并利用多分辨率训练和热图像聚合的策略,增加模型的尺度感知能力。Chen Y等人 [54] 采用粗糙到精细的检测策略,提出了级联金字塔网络(Cascaded Pyramid Networks,CPN),设计全局网络并引入特征金字塔结构,以实现高、低层特征的融合,同时通过对全局网络级联修正网络模块的方式,提高模型对困难人体骨骼关键点的定位能力。Feng Zhang等人 [55] 提出了DarkPose模型,通过高斯分布假设的思想改进了人体骨骼关键点坐标的映射方式,实现了更高精度的人体骨骼关键点检测。综上所述,自顶向下模式具有检测精度高、鲁棒性强的特点,在多人姿态估计领域具有一定的优势。自底向上模式的优势在于检测速度快、模型的算力相对简单,计算量不会因为图像中目标数量的增加而显著提高。
姿态估计从技术层面分析属于像素级分类技术,相较图像级、区域级分类技术,其以人体骨骼关键点为研究对象来分析人体动作表征,使人体行为表征更加具体化。国内外学者针对基于姿态估计的人体行为识别问题展开了相关研究。张恒鑫等人 [56] 提出了一种将传统算法与深度学习算法相结合的姿态估计动作识别算法,通过LBP+SVM算法实现对人体目标的识别,并采用OpenPose模型实现对目标骨架的提取,最后使用KNN对人体动作进行分类,检测精度达到了88.93%。于乃功等人 [57] 采用OpenPose模型提取人体骨骼关键点,通过人体质心的下降速度与人体骨骼关键点的空间位置关系进行跌倒检测。陈京荣 [58] 提出了一种基于姿态估计的跌倒人体行为识别算法,利用HRNet对人体骨骼关键点进行提取,并建立新的人体骨骼关键点结构特征,通过构建Bi-LSTM时序网络来实现对跌倒行为的高效识别。Lie W N等人 [59] 通过使用OpenPose模型得到人体骨骼关键点的坐标信息后直接输入LSTM进行跌倒检测。Jeong S等人 [60] 以不同视频帧中人体骨骼关键点坐标之间的距离特征作为LSTM的输入进行跌倒检测。徐劲夫 [61] 在时空图卷积网络模型的基础上,提出了一种利用数据驱动模型调整人体骨骼关键点间联通关系的自适应时空图卷积网络来实现人体行为识别。葛威 [62] 基于自顶向下的人体姿态估计方法实现对人体姿态的估计,并提出了一种基于时空图卷积网络的人体跌倒检测算法。姜皓祖 [63] 通过姿态估计模型实现了对人体骨骼关键点时序信息的提取,并采用卡尔曼滤波对丢失的人体骨骼关键点进行预测,最后采用多个行为分类器来实现对人体行为的分类。
由于红外热成像技术具有全天候、抗干扰等技术优势,因此基于红外视觉下的人体行为识别也成为相关学者的重点研究方向。Han J等人 [64] 利用步态能量图像(Gait Energy Image,GEI)对跑步、慢跑、步行等行为进行识别,但GEI依然属于轮廓剪影方法,无法捕捉局部特征信息。Kitazume M等人 [65] 首先针对红外图像中的动作识别问题,对视频帧进行减背景运算以获取人体目标,然后通过大量的数学运算计算头部和身体的相对位置来识别诸如躺在沙发上、在桌子上睡着的行为。Lee E J等人 [66] 提出了一种基于卷积神经网络的红外图像户外可疑人类的行为识别模型,但该模型的输入是一个只包含人类的剪辑图像,没有任何背景,模型的鲁棒性较差。Akula A等人 [67] 使用红外热像仪采集了6种人体行为数据集,并构建了卷积神经网络以实现图像级红外人体动作分类,对比结果表明,其提出的卷积神经网络算法相较LBP-KNN、HOG-KNN、LBP-SVM、HOG-SVM等行为分类算法检测精度提高了1.52%。徐世文 [68] 提出了一种基于红外静态图像的人体跌倒检测算法,采用CenterNet目标检测网络来实现对目标行为的分类,并与YOLO V3模型对比,验证所提算法的优越性。Javed I等人 [69] 提出了一种融合局部运动特征和全局运动特征的时空混合模型,有效提升了人体行为识别的精度。Ying Zang等人 [70] 提出了一种红外图像人体姿态估计模型LMAnet,引入了通道注意力机制和空间注意力机制,以实现对红外图像中单目标人体的姿态估计。Ganbayar B等人 [71] 针对红外图像中人体目标的空域特征通过生成对抗网络去除目标的晕轮效应,并提出了一种基于时空混合网络的红外人体行为识别模型。杨爽 [72] 以智能视频监控系统为应用背景,采用基于统计模型的分类识别算法对红外目标分割、特征提取和行为分类识别展开了研究。针对区域生长法需要人工交互的问题,对视觉显著性和区域生长法进行改进,利用基于频谱残差的视觉显著性模型确定目标的显著区域,得到显著区域的重心,以重心作为区域生长分割的种子点,以实现对红外人体行为的识别。
深度学习理论及相关模型的发展推动了人体行为识别技术的进步,但红外视觉下的人体行为识别技术依然存在较多的问题与挑战。本节对红外视觉下的人体行为识别研究的主要技术难点及其发展趋势进行概述。
红外视觉下的人体行为识别有以下几个突出问题。
(1)红外数据集来源问题:当前,人体行为识别相关数据集多为可见光数据集,红外数据集极少,缺乏针对特定场景下的公开数据集,无法满足多任务应用场景的需求,制约了红外视觉下的人体行为识别技术的发展。InfAR数据集 [73] 是应用较广泛的红外数据集,其主要针对室外场景,但动作单一、场景简单。因此,建立基于红外视觉的人体行为识别数据集是必要的。
(2)人体行为识别鲁棒性问题:现实监测环境下,外场环境复杂多变、人体尺度变化、人体自遮挡、人群遮挡、拍摄视角等问题都制约了模型性能的提升,容易造成漏检、误检等情况,无法保证检测系统的识别率。人体姿态的非刚性结构、活动的高自由度导致任何一个部位的轻微变化都会产生新的行为特征。
(3)红外视觉下特征提取困难问题:红外视觉下的人体行为识别虽然解决了在特殊外场环境下的检测问题,但红外热图像呈现的是物体表面的热辐射信息,底层数据信息量匮乏。红外热图像具有低分辨率、低信噪比、低对比度的特点,可以获取的空域特征相较可见光图像较少,这对模型进行时空特征提取带来了巨大挑战。因此,模型的建立与识别系统的优化都需要深度理解红外热成像的基本特点与物理基础。
(4)其他问题:基于计算机视觉的人体行为检测技术多以检测异常行为为主,应用场景单一,无法满足计算机视觉领域的多样化、复杂化需求。现阶段人体行为识别技术的研究多为对单人行为识别的研究,对多人行为识别的研究较少,而实际生活中多人复杂场景更多。同时,智能监控系统需要保证实时性,如何有效降低网络模型的计算复杂度,实现实时、快速、高精度的检测也是技术问题之一。
人体行为识别是热点研究方向,基于红外视觉的人体行为识别技术的发展趋势主要有以下几点。
(1)模型轻量化:随着红外物理技术的小型化、移动设备的快速发展,以及社会对移动设备的实时性和便捷性的要求,使人体行为识别技术模型的轻量化成为核心技术发展趋势之一。将人体行为识别算法应用到安全监控等实时性要求高的领域,需要进一步优化模型结构,以实现对模型的移动端部署。
(2)高精度与高速度:模型检测精度与速度的提升是所有计算机视觉领域的核心技术问题。当前,针对更深层次的红外视觉人体行为识别技术仍然存在较大的研究空间。如何提升模型的检测速度和检测效率,保证其在复杂应用背景下的鲁棒性是红外视觉人体行为识别的发展趋势之一。
(3)多模态信息融合:单模态特征与多模态特征相比,忽略了多模态底层行为感知数据的相关性。视频信息不仅包含视觉信息还包含声音等信息,在网络模型中要对视觉与声音等信息进行融合。多模态信息融合可以提高人体行为识别的结果,对人体行为识别技术的发展具有推动作用。