
下载掌阅APP,畅读海量书库
立即打开



UltraScale+架构的时钟资源通过分布在时钟布线和时钟分配资源上的专用全局时钟来管理时钟需求。
时钟管理单元(Clock Management Tile,CMT)提供时钟频率合成、去偏移和抖动过滤功能。在设计时钟功能时,不推荐使用诸如本地布线之类的非时钟资源。
图 1.37 给出了 UltraScale+架构系列 FPGA 内的时钟结构。UltraScale+架构的 FPGA 内部被细分为列和行的分段时钟区(Clock Region,CR)。与之前架构的FPGA有所不同,CR排布在瓦片(Tile)中,但不是跨越器件宽度的一半。CR 包含 CLB、DSP 切片、BRAM、互联和相关的时钟。CR的高度是60个CLB、24个DSP切片和12个BRAM,其中心具有水平时钟脊(Horizontal Clock Spine,HCS)。HCS 包含水平布线和分配资源、叶子时钟缓冲区、时钟网络互联及时钟网络的根。时钟缓冲区直接驱动到 HCS。每组(Bank)有 52个I/O 和 4 个与 CR 间距匹配的千兆位收发器(Gigabit Transceiver,GT)。核心列包含配置、系统监控器(SYSMON)和PCIe块。
与 I/O 列相邻的是具有 CMT、全局时钟缓冲区、全局时钟复用结构和 I/O 逻辑管理功能的物理层(Physical Layer,PHY)块。时钟通过 HCS 到 CR 与 I/O 的独立时钟布线和时钟分配资源来驱动垂直和水平连接。
水平布线和分配通道(Track)水平驱动进入 CR;垂直布线和分配通道驱动垂直相邻的CR。通道在水平方向和垂直方向上的 CR 边界是可分割的。这允许创建器件宽度的全局时钟或者可变大小的本地时钟。
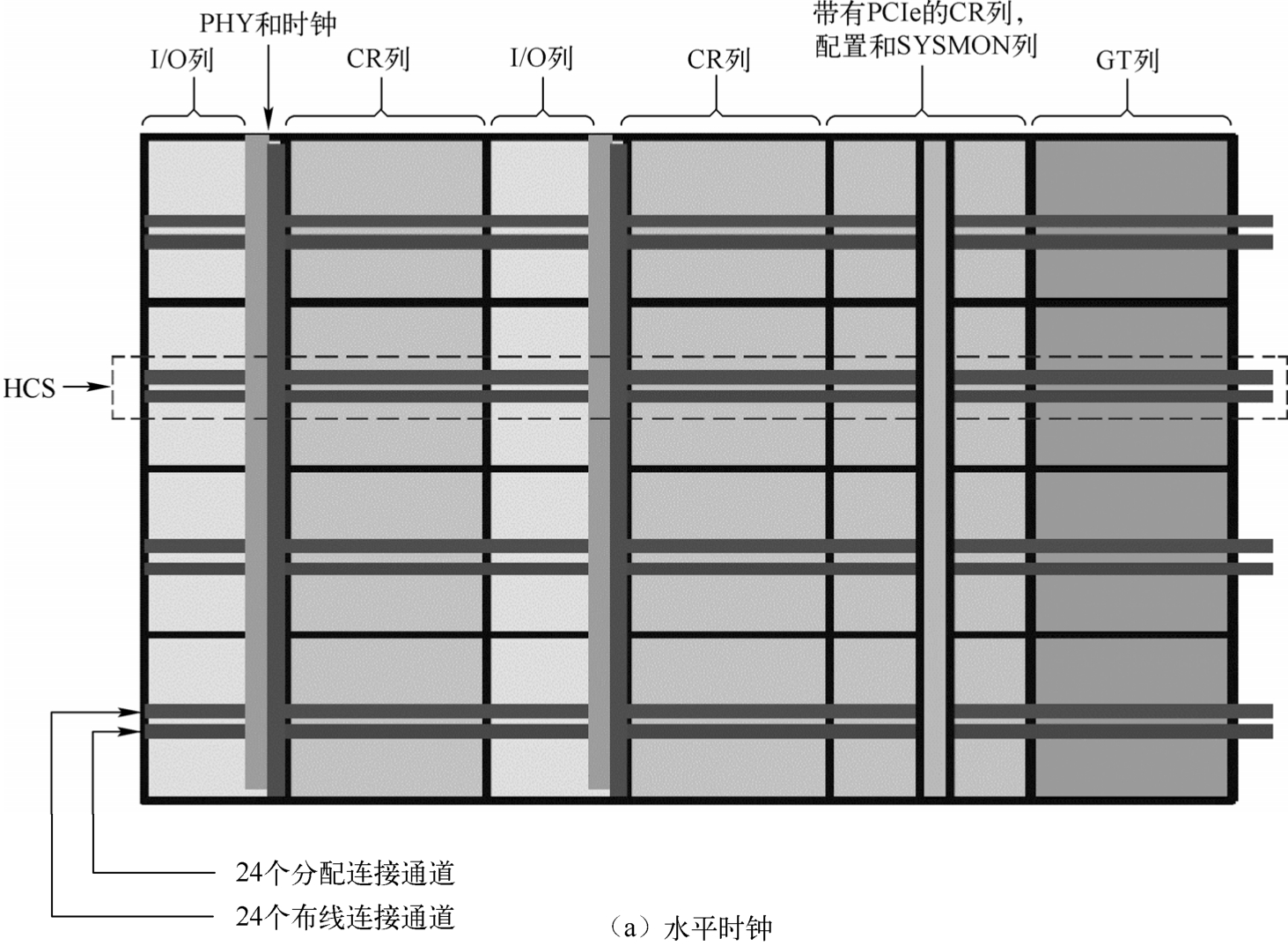
图1.37 UltraScale+架构系列FPGA内的时钟结构
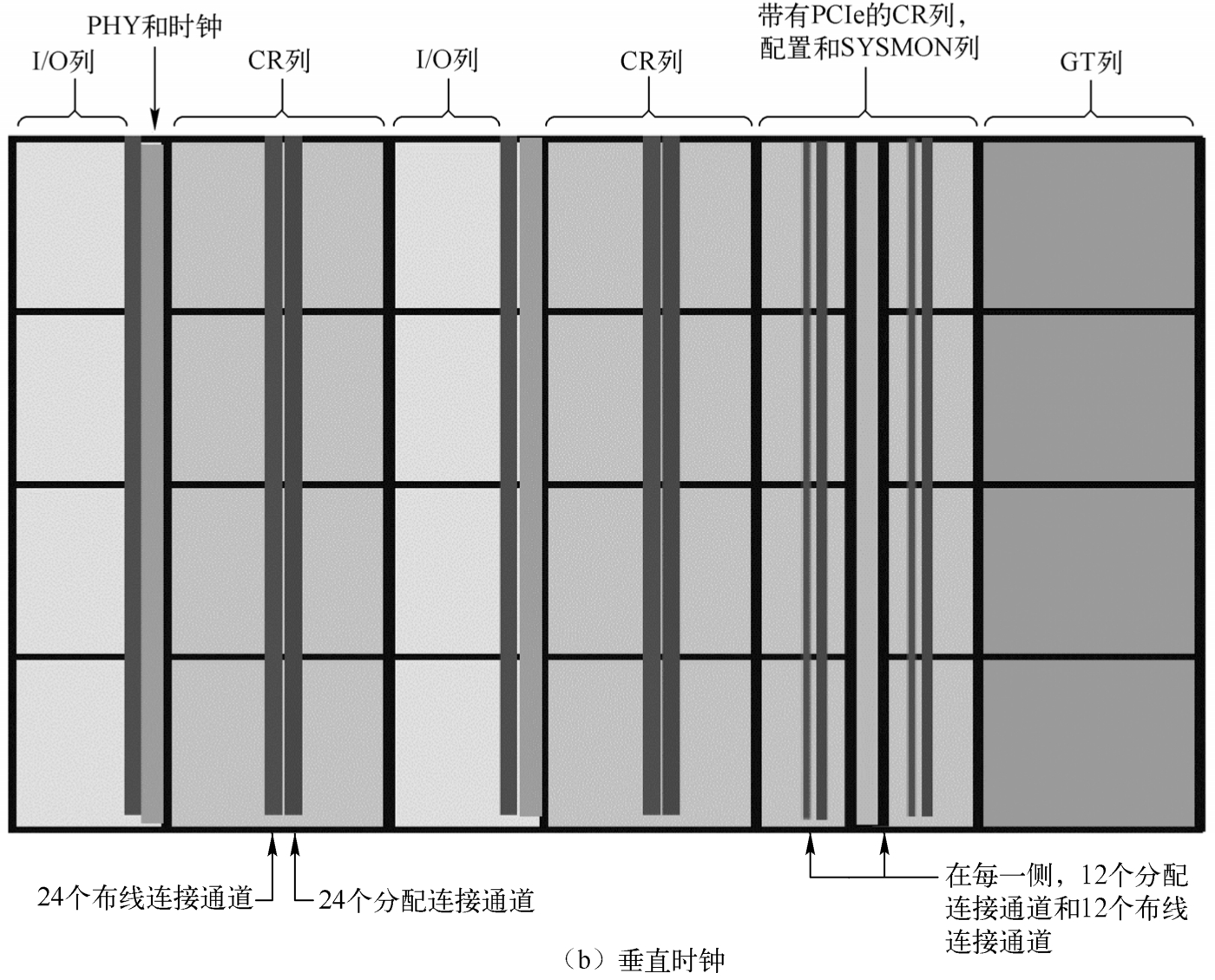
图1.37 UltraScale+架构系列FPGA内的时钟结构(续)
分配通道驱动器件上同步元件的时钟。分配通道由布线通道或直接由 PHY 中的时钟结构驱动。I/O由PHY时钟直接驱动和/或相邻PHY通过布线通道驱动。
每个 I/O 组都包含全局时钟输入引脚,用于将用户时钟带到器件时钟管理和布线资源上。全局时钟输入将用户时钟带到:
(1)PHY中与同一组相邻的时钟缓冲区;
(2)PHY中与同一组相邻的CMT。
每个器件都有 3 个全局时钟缓冲区,包括 BUFGTRL、BUFGCE 和 BUFGCE_DIV。此外,还有一个本地 BUFCE_LEAF 时钟缓冲区,用于将叶时钟从水平分配驱动到器件中的各个块。BUFGTRL 具有 BUFGMUX、BUFGMUX1、BUFGCE_1 类型的衍生软件表示。BUFGCE 用于无毛刺的时钟门控,并具有软件衍生 BUFG (时钟使能绑定为高电平的BUFGCE)。全局时钟缓冲区通过 HCS 行将布线和分配通道驱动到器件逻辑。每个 HCS 行中有 24个布线和 24个分配通道。此外,还有一个 BUFG_GT,它生成用于驱动 GT时钟的分频时钟。时钟缓冲区:可用作时钟使能电路,以全局、本地或 CR 内使能或禁止时钟,用于细粒度的功率控制;可作为无毛刺的多路选择器,用于在两个时钟源之间进行选择或切换掉出现故障的时钟源;通常由 CMT 驱动,消除了时钟分配延迟,以及相对另一时钟调整时钟延迟。
每个器件都有一个CMT,作为每个I/O组旁边PHY的一部分。CMT由一个MMCM和两个 PLL 构成。MMCM 用于宽频率范围的频率合成的基本块,并且用作外部或内部时钟的抖动过滤器,以及在宽范围的其他功能中的去偏移时钟。PLL的主要目的是向PHY I/O提供时钟,但也可以以有限的方式对器件的其他资源提供时钟。器件时钟输入连接允许多个资源向MMCM和PLL提供参考时钟。
MMCM 在任何一个方向上都具有无限精细的相移能力,并且可以用于动态相移模式。MMCM 在一个输出路径中的反馈路径中也有一个分数计数器,从而实现频率合成能力的进一步粒度。
LogiCORE IP时钟向导(LogiCORE IP Clocking Wizard)可用于帮助我们利用MMCM和PLL在UltraScale+架构设计中创建时钟网络。图形用户界面(Graphics User Interface,GUI)用于搜集时钟网络参数。时钟向导可选择适当的CMT资源并优化配置CMT资源和相关的时钟布线资源。
思考与练习1-10: 使用 Vivado 2013.1 打开前面给出的任意一个工程,这些设计使用UltraScale+架构的Kintex系列FPGA器件,该器件的具体型号为xcku5p-ffva676-1-i。在Device视图中,查看该器件的内部结构,并回答下面的问题:
(1)CR的高度包含________个CLB,指出其具体位置;
(2)包含________个DSP,指出其具体位置;
(3)包含________个BRAM,指出其具体位置;
(4)包含________个I/O,指出其具体位置。
基于 UltraScale+架构的 FPGA 有多个时钟布线资源来支持各种时钟方案和要求,包括高扇出、短传播延迟和极低偏斜。为了最好地利用时钟布线资源,设计者必须了解如何将用户时钟从印刷电路板(Printed Circuit Board,PCB)获取到 UltraScale+架构的 FPGA,决定哪些时钟布线资源是最佳的,然后通过利用适当的 I/O 和时钟缓冲区来访问这些时钟布线资源。
外部全局用户时钟必须通过称为全局时钟(Global Clock,GC)输入的差分时钟引脚对引入UltraScale+架构的FPGA。每组有4个GC引脚对,它们可以直接访问与同一I/O组相邻的CMT中的全局时钟缓冲区、MMCM 和 PLL。UltraScale+架构的 FPGA 的每个 HD I/O 组中有一个HDGC引脚。HD I/O组只是UltraScale+架构FPGA的一部分。由于HD I/O组旁边没有XIPHY和CMT,因此HDGC引脚只能直接驱动BUFGCE(BUFG),而不能驱动MMCM/PLL。因此,连接到 HDGC 引脚的时钟只能通过 BUFGCE 连接到 MMCM/PLL。若要避免出现设计规则检查(Design Rule Check,DRC)错误,需要设计下面的属性:

GC 输入提供对内部全球和区域时钟资源的专用高速访问。GC 输入使用专用布线,并且必须用于时钟输入,其中各种时钟功能的时序是强制性的。带有本地互联的通用 I/O 不应用于时钟信号。
每个I/O组位于单个时钟区域中,并且包含52个I/O引脚。在每个I/O列中的每个I/O组中的52个I/O引脚中,有4个全局时钟输入引脚对(总计8个引脚)。每个全局时钟输入:可以连接到PCB上的差分或单端时钟;可以针对任何I/O标准进行配置,包括差分I/O标准;有一个P端(主)和一个N端(从)。
如果单端时钟输入必须分配给GC输入引脚对的P端,则N端不能用作另一个单端时钟引脚,它只能用作用户 I/O。如果 GC 输入不用作时钟,则可以用作常规 I/O。当用作常规 I/O时,全局时钟输入引脚可以配置为任何单端或差分I/O标准。GC输入可以连接到与其所在组相邻的PHY。
字节通道时钟(DBC 和 QBC)输入引脚对是专用的时钟输入,直接驱动源同步的时钟到I/O 块的比特切片。在存储器应用中,这些称为 DQS。当不用于 I/O 字节时钟时,这些引脚具有其他功能,如通用I/O。
全局时钟是专门设计用于到达器件中各种资源的所有时钟输入的专用互联网络。这些网络被设计为具有低偏斜和低占空比失真、低功耗和改进的抖动容限。
1)时钟结构
基本器件架构由 CR 块构成。在 UltraScale+架构 FPGA 内,CR 以瓦片的形式进行组织,从而构成列和行。每个CR包含切片(CLB)、DSP和BRAM块。每个CR中的切片、DSP和BRAM 块的混合可以不同,但是在垂直方向上堆叠时总是相同的,从而为整个器件构建这些资源的列。I/O 和 GT 列与 CR 列一起插入。此外,还有一列包含配置逻辑、SYSMON 和 PCIe块。HCS包含水平布线和分配通道,以及水平/垂直布线和分配之间的叶时钟缓冲区与时钟网络互联。
布线和分配垂直通道连接到一列中的所有 CR,而垂直布线跨越整个 I/O 列。如图 1.37 所示,有24条水平布线和24条分配通道,以及24条垂直布线和24条分配通道。时钟布线资源的目的是将时钟从全局时钟缓冲区布线到中心点,从该中心点经由分配资源将时钟连接到负载。时钟网络的这个中心点在 UltraScale+架构中被称为时钟根。根可以在 FPGA 中的任何 CR中,根从该 CR 经由时钟分配资源布线到负载。这种架构优化了时钟偏移。布线和分配资源可以连接到相邻CR,也可以根据需要在CR的边界断开连接(隔离)。
时钟可以通过以下两种方式从其来源进行分配:
(1)首先时钟可以进入布线通道,将时钟带到 CR 中的中心点,而无须进入任何负载。然后时钟可以单向驱动分配通道,时钟网络从中扇出。以这种方式,时钟缓冲区可以驱动到 CR中的特定点,时钟缓冲区从该特定点垂直地行进,然后在分配通道上水平地行进,以驱动时钟点。如果需要,通过该 CR 和相邻 CR 中具有时钟使能(CE)的叶时钟来驱动时钟点。分配通道不能驱动布线通道。该分配方案用于将所有负载的根移动到特定位置,以改善局部偏斜。此外,布线和分配通道都可以分段方式驱动到水平或垂直相邻的 CR 中。布线通道可以驱动相邻CR 中的布线通道和分配通道,而分配通道可以驱动邻近 CR 中的其他水平分配通道。CR 边界分割允许通过重复使用时钟通道来构建真正全局的、器件范围的时钟网络或更多可变大小的本地时钟网络。
(2)时钟缓冲区直接驱动到分配通道上,并以这种方式分配时钟,这就减少了时钟插入延迟。XIPHY BITSLICE中的4个字节中的每一个都有6个从HCS到其全局时钟引脚的连接。因此,只有6个BUFG可以驱动I/O组任意一半中的BITSLICE时钟引脚(最多六个时钟可以驱动I/O组的任意一半)。
时钟区域时钟的内部结构如图1.38所示。
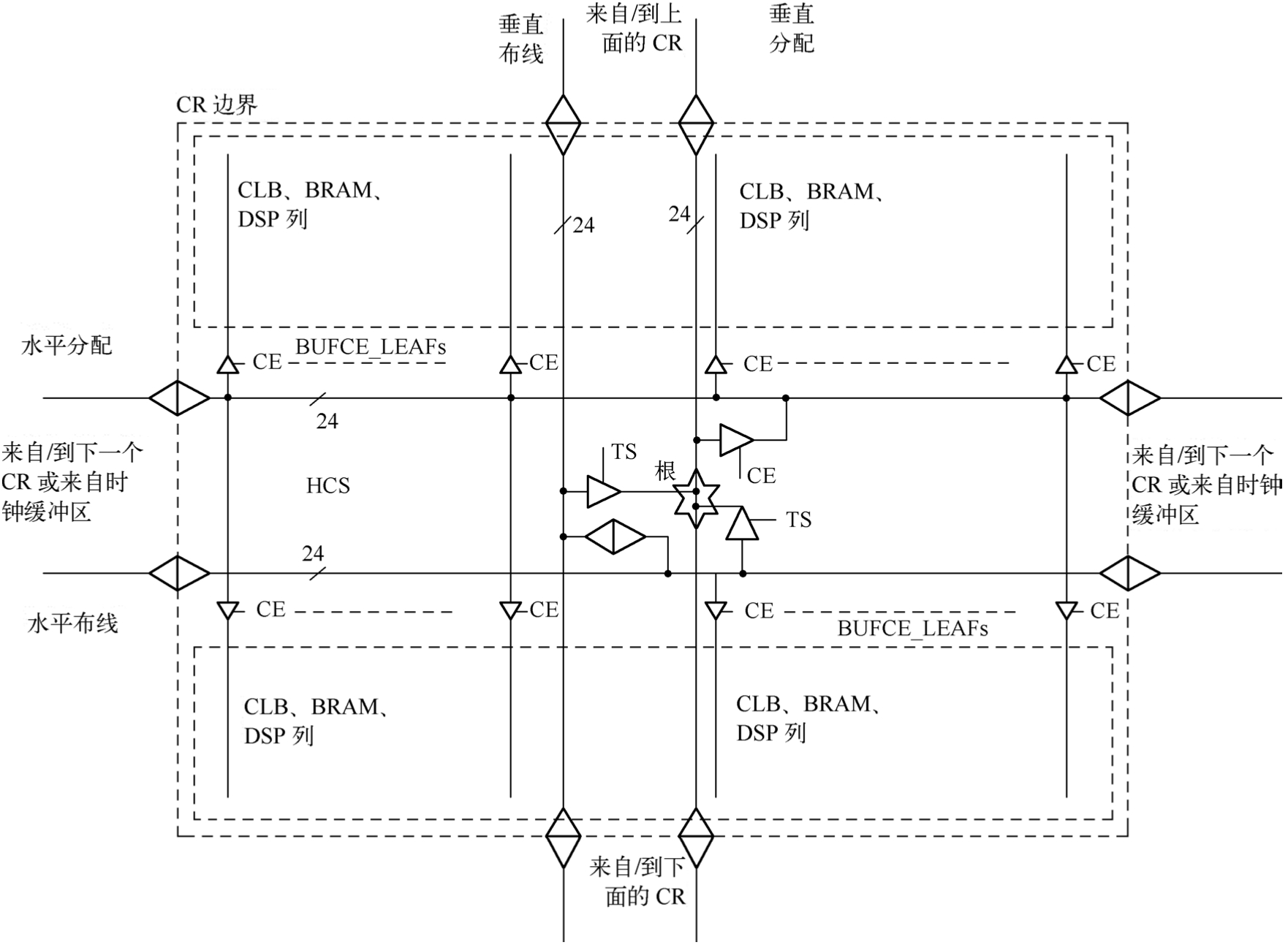
图1.38 时钟区域时钟的内部结构
2)时钟缓冲区
PHY 全局时钟包含若干组 BUFGCTRL、BUFGCE 和 BUFGCE_DIV,如图 1.39 所示。每组都可以由来自相邻组的4个GC引脚、MMCM、同一PHY中的PLL及互联来驱动。时钟缓冲区用于驱动整个芯片内的布线和分配资源。每个PHY包含24个BUFGCE、8个BUFGCTRL和4个BUFGCE_DIV。但是,在同一时刻,只使用其中的24个。
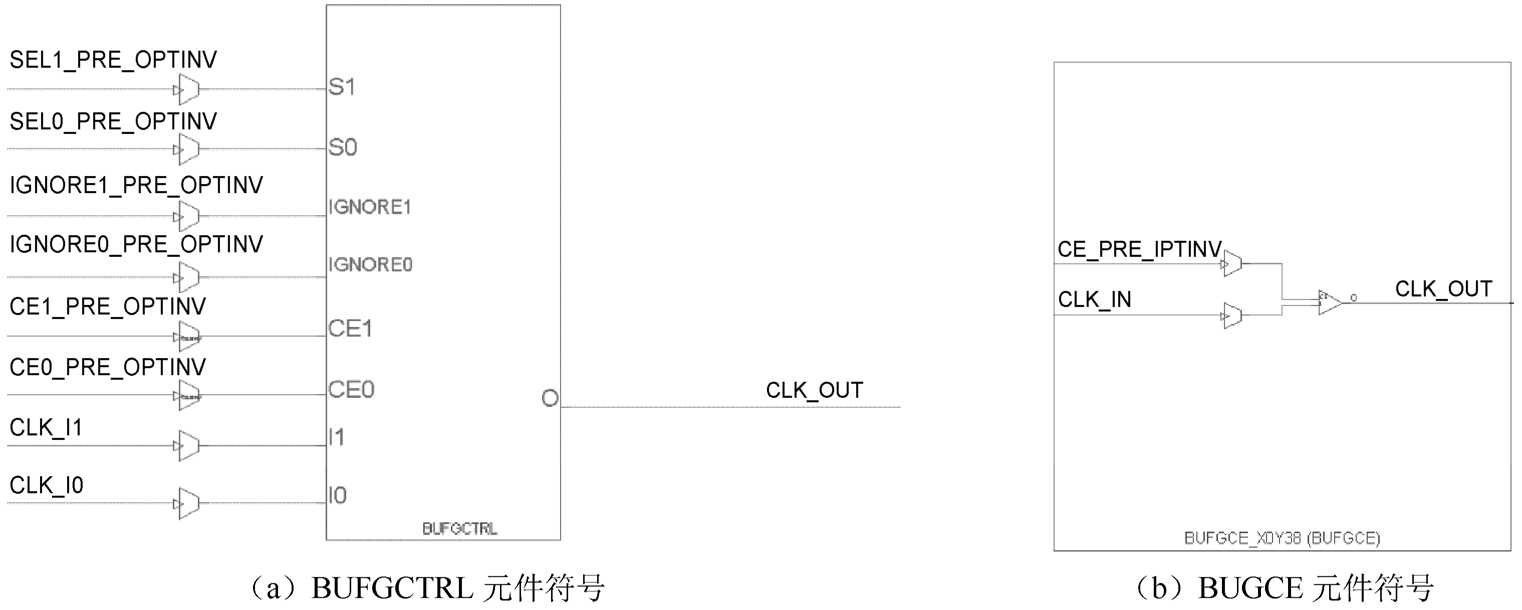
图1.39 3种不同时钟元件符号
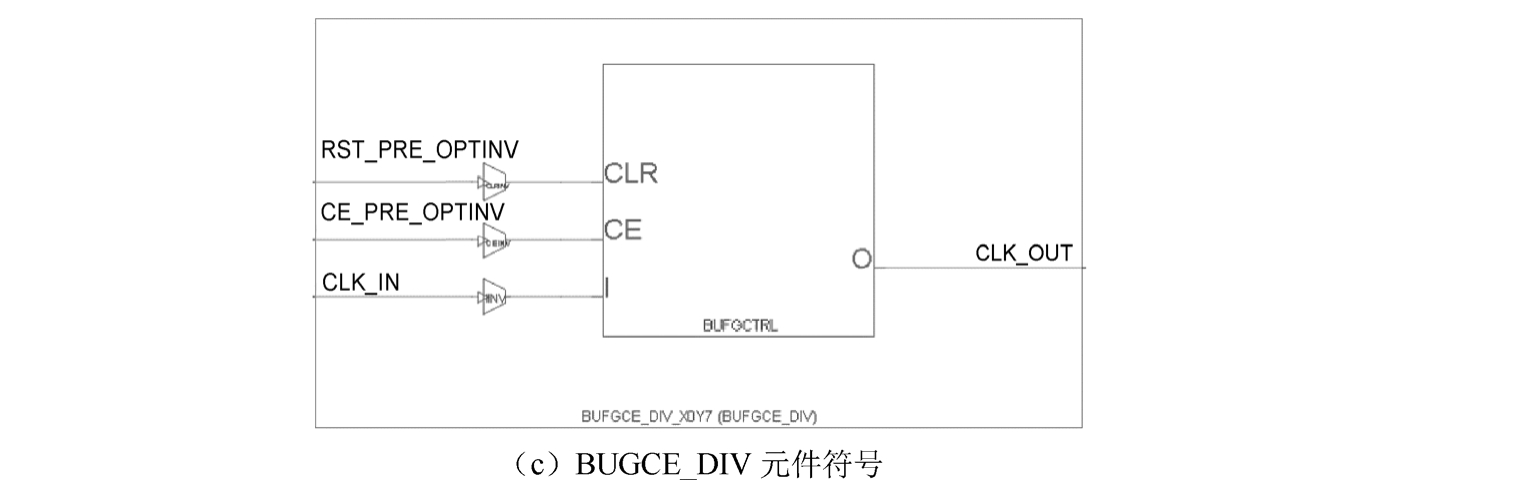
图1.39 3种不同时钟元件符号(续)
对于BUFGCTRL元件,选择输入时钟I0或I1,取决于“选择”对(S0和CE0,或S1和CE1)是否设置为逻辑“1”(高电平)。如果 S 或 CE 有一个不为逻辑“1”(高电平),则未选择所需要的输入时钟I0或I1。
对于BUFGCE元件,它是一个时钟缓冲区,具有一个时钟输入、一个时钟输出及一条时钟使能信号线。这个缓冲区提供了无毛刺的时钟门控。BUFGCE 可直接驱动布线资源,并且是具有单个门控输入的时钟缓冲区。当 CE 为逻辑“0”(低电平)时(非活动),其端口 CLK_OUT输出为逻辑“0”(低电平)。当 CE 为逻辑“1”(高电平)时,来自 CLK_IN 的输入送到CLK_OUT输出。
对于 BUFGCE_DIV 元件,它是一个时钟缓冲区,具有一个时钟输入(I)、一个时钟输出(O)、一个清除输入(CLR)和一个时钟使能(CE)输入。BUFGCE_DIV可以直接驱动布线和分配资源,是一个具有单个门控输入和复位的时钟缓冲区。当 CLR 为逻辑“1”(高电平)时(活动),其端口O的输出为逻辑“0”(低电平)。当CE为逻辑“1”(高电平)时,其端口I的输入传送到端口O输出。CE与时钟同步以实现无毛刺运行。BUFGCE_DIV元件可以将输入时钟除以1~8。
思考与练习1-11: 使用 Vivado 2013.1 打开前面给出的任意一个工程,这些设计使用UltraScale+架构的Kintex系列FPGA器件,该器件的具体型号为xcku5p-ffva676-1-i。在Device视图中,查看该器件的内部结构,计算每个PHY包含:
(1)____个BUFGCE;
(2)____个BUFGCTRL;
(3)____个BUFGCE_DIV。
注: 建议仅允许 Vivado 布线器将所有全局时钟缓冲区分配到特定位置。每个CR包含24个BUFGCE、8个 BUFGTRL 和 4 个 BUFGCE_DIV。这些时钟缓冲区共享 24 个布线通道,因此可能发生冲突,从而导致不可改变的设计。如果设计要求多个全局时钟缓冲区处于某个 CR 中,则建议将 clock_REGION 属性添加到这些缓冲区,而不是特定的LOCATION属性。
在时钟结构中,BUFGCTRL 多路复用器和其衍生物可以级联到相邻的时钟缓冲区,有效地创建了一个由 8个BUFGMUX构成的环(BUFGCTRL多路复用器)。
如图 1.40 所示,BUFCE_LEAF 是带有 CE 的时钟缓冲区,用于叶驱动离开水平 HCS 行。该缓冲区是用单个门控输入驱动各个块的时间点的时钟缓冲区。当 CE 为逻辑“0”(低电平)时(非活动),端口 O 的输出为逻辑“0”(低电平)。当 CE 为逻辑“1”(高电平)时(活动),端口 I 的输入传输到端口O输出。
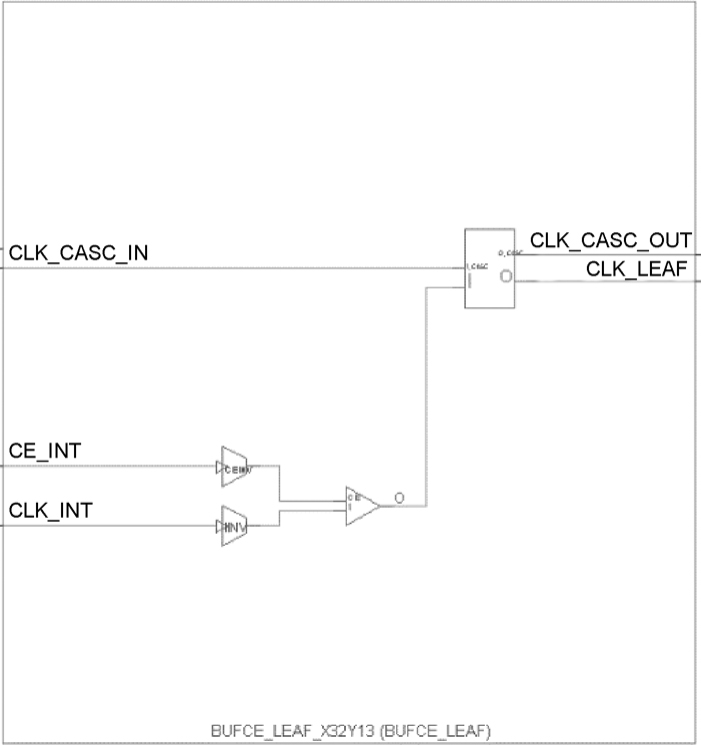
图1.40 BUFCE_LEAF元件符号
注: FPGA开发者不能尝试通过Vivado 2023.1访问BUFCE_LEAF元件。
思考与练习1-12: 使用 Vivado 2013.1 打开前面给出的任意一个工程,这些设计使用UltraScale+架构的Kintex系列FPGA器件,该器件的具体型号为xcku5p-ffva676-1-i。在Device视图中,定位到其中一个CR,在该CR中间的一行,定义并放大HCS,查看BUFCE_LEAF元件,以及该元件与CR内逻辑资源的连接关系。
图1.41给出了BUFG_GT和BUFG_GT_SYNC元件符号。BUFG_GT由RFSoC器件中的千兆收发器(Gigabit Transceiver,GT)和ADC/DAC块驱动。只有GT、ADC和DAC可以驱动 BUFG_GT。BUFG_GT 是一个时钟缓冲区,具有一个时钟输入(I)、一个时钟输出(O)、一个带有CLR屏蔽输入(CLRMASK)的清除输入、一个带有CE屏蔽输入(CEMASK)的时钟使能(CE)输入和一个3位分频输入(DIV[2:0])。
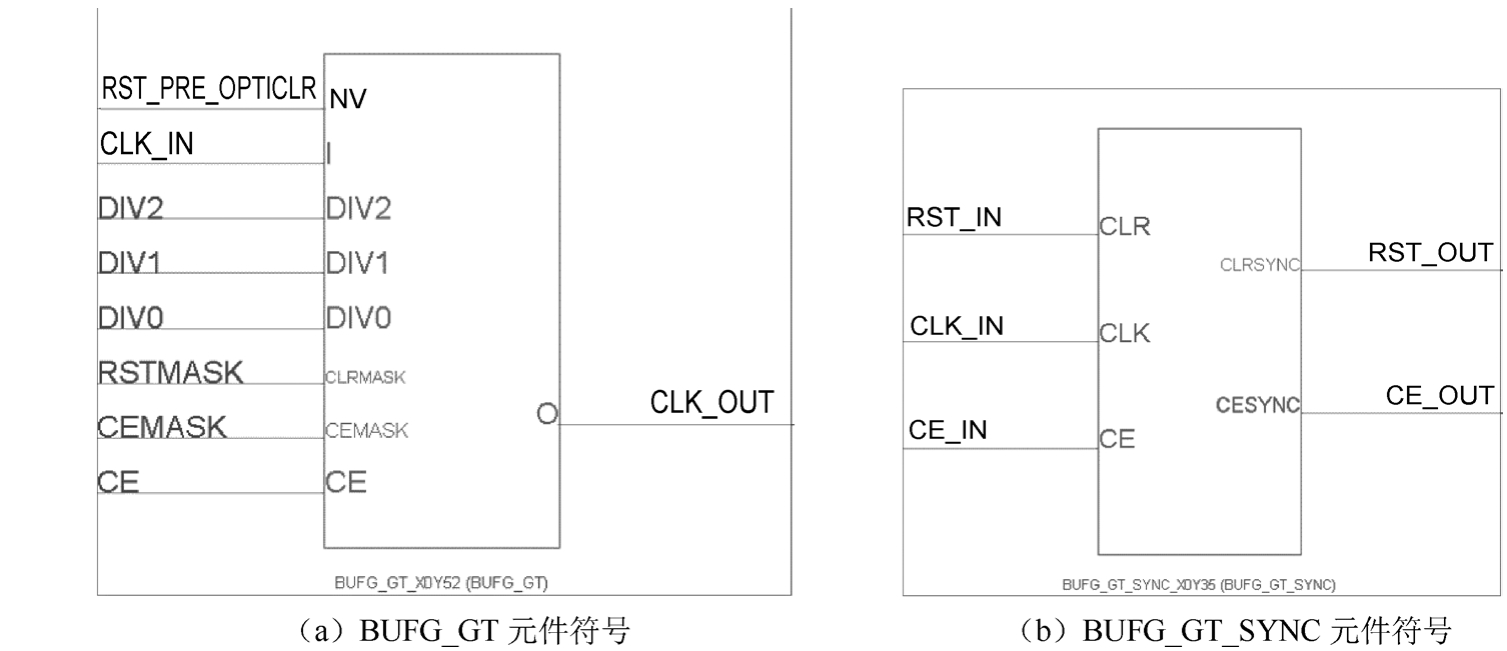
图1.41 BUFG_GT和BUFG_GT_SYNC元件符号
BUFG_GT_SYNC 是用于 BUFG_GT 的同步器电路。如果在设计中没有 BUFG_GT_SYNC原语,则Vivado工具自动插入它。BUFG_GT_SYNC可以直接驱动布线和分配资源,并且是具有单个门控输入和复位的时钟缓冲区。当 CE 无效(逻辑“0”,低电平)时,输出停止在当前的状态,逻辑“1”(高电平)或逻辑“0”(低电平)。当 CE 为逻辑“1”(高电平)时,端口 I的输入传输到端口O输出。CE的边沿和CLR的无效都自动与时钟同步,以实现无毛刺的操作。Vivado工具不支持CE引脚的时序,因此无法实现确定性的延迟。CLR是对BUFG_GT的异步复位确认和同步复位非确认。同步器有两级,但 CLR 引脚没有分配建立/保持时序弧。因此,延迟是不确定的。BUFG_GT 也可以将输入时钟分频 1~8。DIV[2:0]值是实际分频值减去 1 (3'b000 对应于 1,3'b111 对应于 8)。当缓冲区处于复位状态时,必须改变分频值(DIV 输入)、CEMASK 和 CLRMASK。当 CE 无效或复位有效时,可以更改输入时钟。然而,对于控制信号存在最小有效/无效时间。
注: (1)在RFSoC器件中,ADC和DAC瓦片(Tile)取代了MPSoC器件中的GTH收发器。因此,ADC 和 DAC 利用现有的BUFG_GT 时钟缓冲区来驱动器件中的全局时钟树,然后从FPGA逻辑资源结构中返回ADC和DAC瓦片。但是,当连接到ADC/DAC时钟时,不能使用DIV功能。因此,BUFG_GT的功能更像是一个带有CE和CLR的简单全局时钟缓冲区。
(2)对于Zynq UltraScale+中的器件和Kintex Ultrascale+系列(XCKU9P及以上)中选定的器件,将时钟根与BUFG_GT驱动器(X0列)分配在同一区域可能会导致不可布线的情况,并阻止来自到达负载的输出时钟,它们布局在Zynq UltraScale+器件PS右侧或Kintex UltraScale+的Y0、Y1和Y2行的空PL区域。为了避免这个问题,用户需要将根时钟分配到右侧的一个时钟域,在这种情况下是X1列。
UltraScale器件的每个GT Quad有24个BUFG_GT和10个BUFG_GT_SYNC。UltraScale+器件的每个GT Quad也有24个BUFG_GT,但是它们有14个BUFG_GT_SYNC。在Quad中的任何GT输出时钟都可以复用到任何一个BUFG_GT。在UltraScale器件中,有10个CE和CLR引脚,它们对应于10个BUFG_GT_SYNC,可以驱动24个BUFG_GT。在UltraScale+器件中,有 14 个 CE 和 CLR 引脚,它们对应于 14 个 BUFG_GT_SYNC,可以驱动 24 个BUFG_GT。每个BUFG_GT缓冲区都具有CE和CLR(24)的单独屏蔽码。由同一时钟源驱动的所有BUFG_GT必须具有公共的CE和CLR信号。在这种情况下,不允许将CE和CLR连接到常量信号,但可以设置屏蔽码以提供相同的功能。连接到同一输入时钟的 BUFG_GT 的输出时钟在退出复位(CLR)或 CE 有效时彼此同步(相位对准)。单独的屏蔽引脚可用于控制 24组中的BUFG_GT 响应CE 和CLR,并因此互相同步或保持其之前的相位和分频值。这些时钟缓冲区位于HCS中,并且由GT输出时钟直接驱动。它们的目的是通过布线和分配资源直接驱动CR中的硬核模块和逻辑。GT没有到其他时钟资源的其他连接和专用连接。然而,它们可以通过BUFG_GT和时钟布线资源连接到CMT。
BUFG_PS 是一个简单的时钟缓冲区,具有一个时钟输入(I)和一个时钟输出(O)。该时钟缓冲区是Zynq UltraScale+MPSoC处理器系统(Processing System,PS)的资源,并为从处理器到 PL 的时钟提供对可编程逻辑(Programmable Logic,PL)时钟布线资源的访问。最多18个PS时钟可以驱动BUFG_PS。该时钟缓冲区位于PS旁边。
UltraScale 结构的每个 I/O 组包含一个 CMT,每个 CMT 包含一个混合模式的时钟管理器(Mixed-Mode Clock Manager,MMCM)和两个相位锁相环(Phase Lock Loop,PLL),其主要用于为I/O生成时钟。但是,它也包含了用于内部结构的MMCM的一些功能集。
时钟输入连接允许多个资源向 MMCM 提供参考时钟。输出计数器(分频器)的个数为 8个,其中一些能够驱动反相时钟信号(180°相移)。MMCM 在任何一个方向上都具有无限的相移能力,并且可以用于动态相移模式。精细相移的分辨率取决于压控振荡器(Voltage Controlled Oscillator,VCO)的频率。CLKFBOUT和CLKOUT0分数分频功能以1/8(0.125)的增量提供,以支持更大的时钟频率合成能力。
基于 UltraScale 架构的器件具备扩频(Spread Spectrum,SS)功能。如果不使用 MMCM扩频特性,外部输入时钟上的扩频将不会被过滤掉,从而传输到输出时钟。
基于 UltraScale 架构的 FPGA 中,每个 I/O 组包含一个CMT。MMCM 用于宽范围频率的合成,也可用作内部或者外部时钟的抖动过滤器。
输入多路复用器从全局时钟 I/O、时钟布线或分配资源中选择参考时钟与反馈时钟。每个时钟输入都有一个可编程的计数器分频器(D)。相位频率检测器(Phase Frequency Detector,PFD)比较输入(参考)时钟和反馈时钟的上升沿的相位与频率。如果保持最小的高/低脉冲,则占空比是辅助的。PFD 用于生成与两个时钟之间的相位和频率成比例的信号,该信号驱动电荷泵(Charge Pump,CP)和环路滤波器(Loop Filter,LF)以产生到VCO的参考电压。PFD产生到 CP 和 LF 的向上或向下信号,以确定 VCO 应该在更高或更低频率下工作。当 VCO 以过高的频率工作时,PFD 激活下降信号,控制电压降低,从而降低 VCO 的工作频率。当 VCO在过低的频率下工作时,向上信号会增加电压。VCO产生8个输出相位和一个用于精细相移的可变相位,可以选择每个输出相位作为输出计数器的参考时钟。每个计数器都可以针对给定的开发人员设计进行独立编程。还提供了一个特殊的计数器 M,该计数器控制 MMCM 的反馈时钟,允许宽范围的频率合成。
除整数分频输出计数器外,MMCM 还为 CLKOUT0 和 CLKFBOUT 添加了一个小数计数器。MMCM的内部结构如图1.42所示。
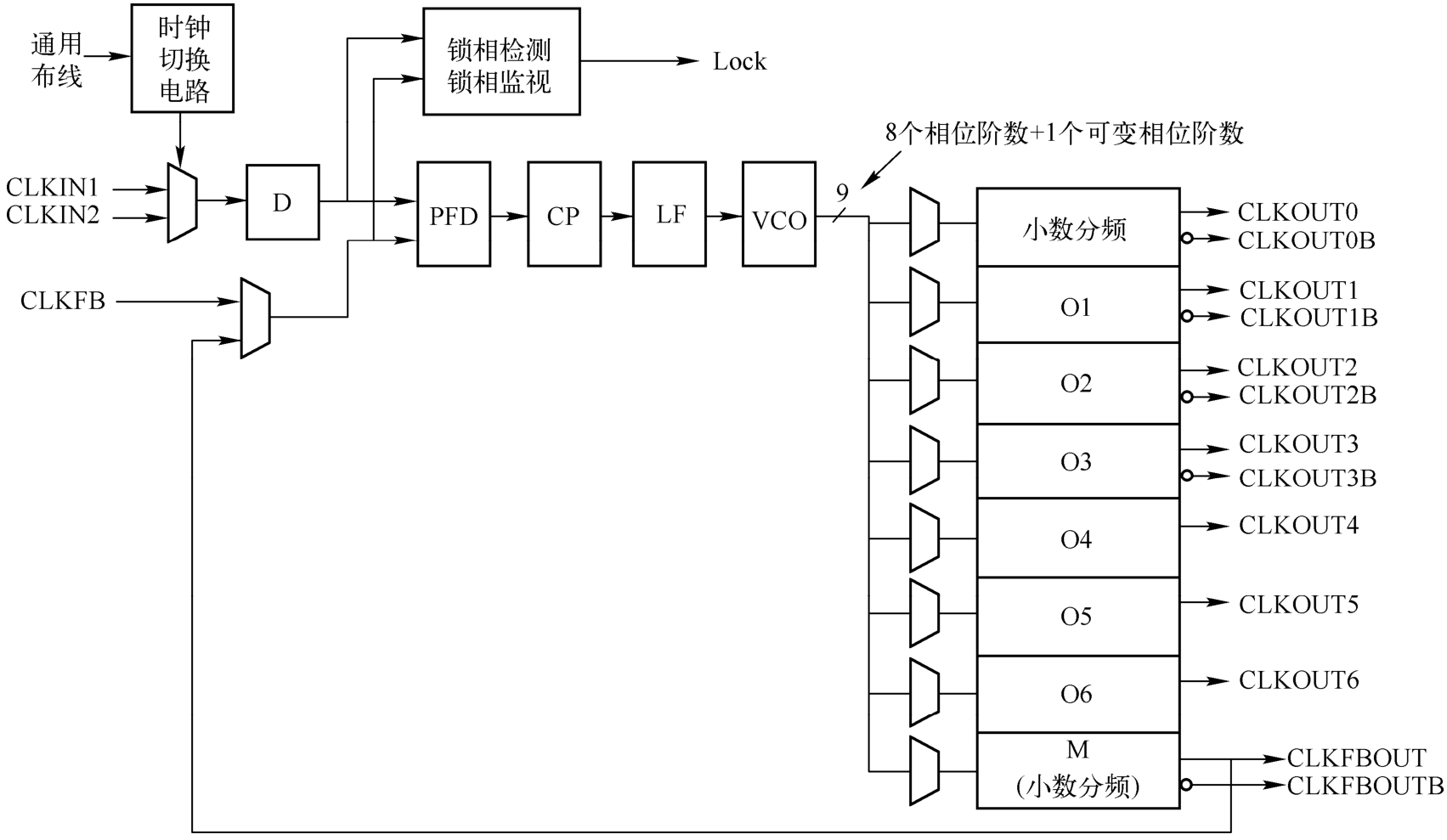
图1.42 MMCM的内部结构
UltraScale/UltraScale+架构 FPGA 的 MMCM 原语如图 1.43 所示。其中,MMCME4_B ASE/MMCME3_BASE 提供了对一个单独的 MMCM 的最频繁使用特征的访问。时钟去偏移、频率合成、粗略相移和占空比编程可用于 MMCME4_BASE/MMCME3_BASE。MMCME4_ADV/MMCME3_ADV 提供了对 MMCME4_BASE/MMCME3_BASE 功能的访问,可用作时钟切换、访问动态重配置端口(Dynamic Reconfiguration Port,DRP)和动态精细相移的额外端口。
每个CMT有两个PLL,它们为PHY逻辑和I/O提供时钟。此外,它们可以用作宽频率范围的频率合成器,用作抖动过滤器,并提供基本的相移能力和占空比编程。PLL 在输出数量上与 MMCM 不同,不能对时钟网络进行去偏斜,并且不具有高级相移能力,乘法器和输入除法器具有较小的值范围,并且不具备MMCM的许多其他高级功能。
UltraScale/UltraScale+架构FPGA的PLL原语如图1.44所示。对于UltraScale+器件,其原语带有 E4而不是 E3。PLLE4_ADV与PLLE3_ADV相同,PLLE4_BASE与 PLLE3_BASE相同。
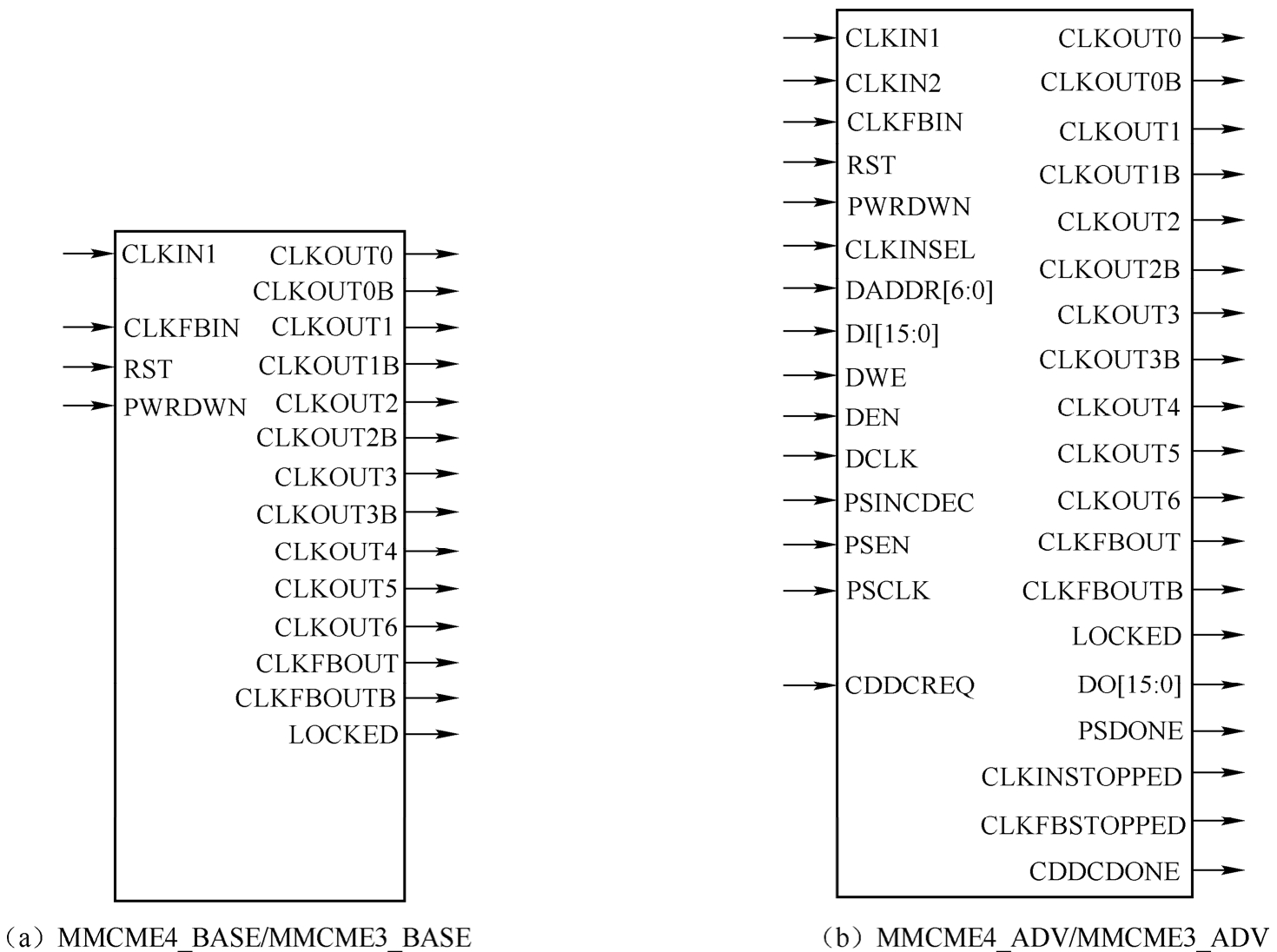
图1.43 UltraScale/UltraScale+架构FPGA的MMCM原语
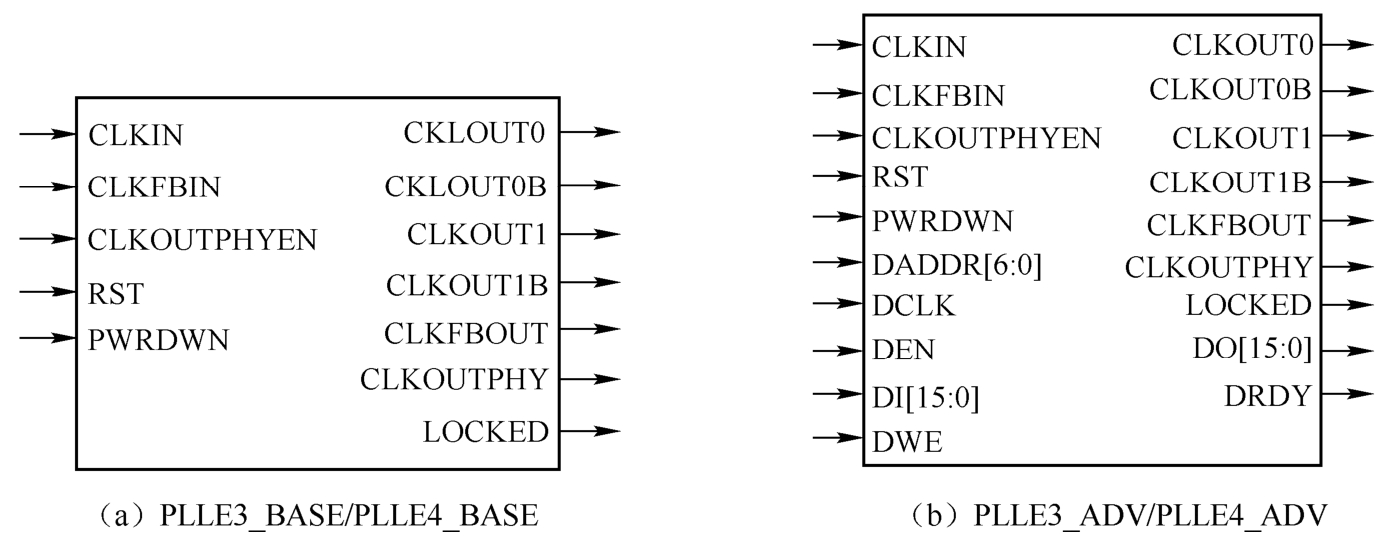
图1.44 UltraScale/UltraScale+架构FPGA的PLL原语
PLLE3_BASE/PLLE4_BASE 提供了对独立 PLL 最常用功能的访问,可用于时钟去偏移、频率合成和占空比编程。PLLE3_ADV/PLLE4_ADV 提供了对所有 PLLE3_BASE/PLLE4_BASE功能的访问,可用作访问DRP的额外端口。
使用Clocking Wizard调用MMCM原语的Verilog HDL和VHDL描述如代码清单1-22和代码清单1-23所示。在该设计中,MMCM的输入时钟频率为100MHz,输出时钟频率为166MHz。
代码清单1-22 使用Clocking Wizard调用MMCM原语的Verilog HDL描述例子

注: 读者进入本书提供的\vivado_example\mmcm_verilog 资源目录中,用Vivado 2023.1 打开名字为project1.xprj的工程文件。
代码清单1-23 使用Clocking Wizard调用MMCM原语的VHDL描述例子

注: 读者进入本书提供的\vivado_example\mmcm_vhdl 资源目录中,用 Vivado 2023.1 打开名字为project1.xprj的工程文件。
使用Vivado 2023.1对该设计进行综合后的结果如图1.45所示
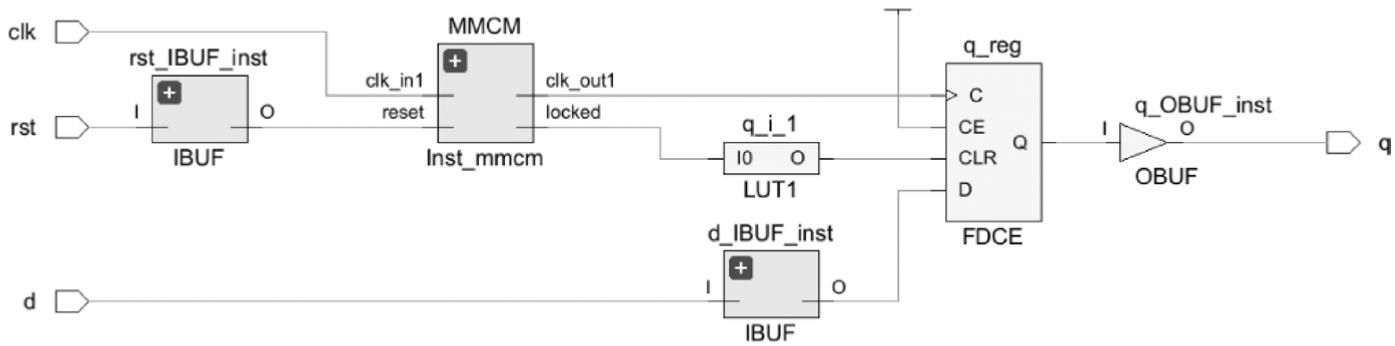
图1.45 使用Vivado 2023.1对该设计进行综合后的结果
思考与练习1-13: 在Vivado 2013.1中打开图1.45,在Schematic视图中,单击MMCM元件符号中的“+”按钮,查看MMCM原语MMCME4_ADV的元件符号和内部连接关系。
使用Vivado 2023.1对该设计进行布局布线后的结果如图1.46所示。

图1.46 使用Vivado 2023.1对该设计进行布局布线后的结果
思考与练习1-14: 在Vivado 2023.1中打开如图1.46所示布局布线后的Device视图,仔细查看该设计的布局和布线,尤其是查看该设计中所使用MMCM的位置,以及该设计中时钟的布线。