
下载掌阅APP,畅读海量书库
立即打开



从第一颗FPGA产生至今,FPGA已有30多年的历史,虽内部结构愈加丰富,但万变不离其宗——可编程逻辑单元、可编程I/O单元和布线资源构成了FPGA内部三大主要资源,如图1.1所示。
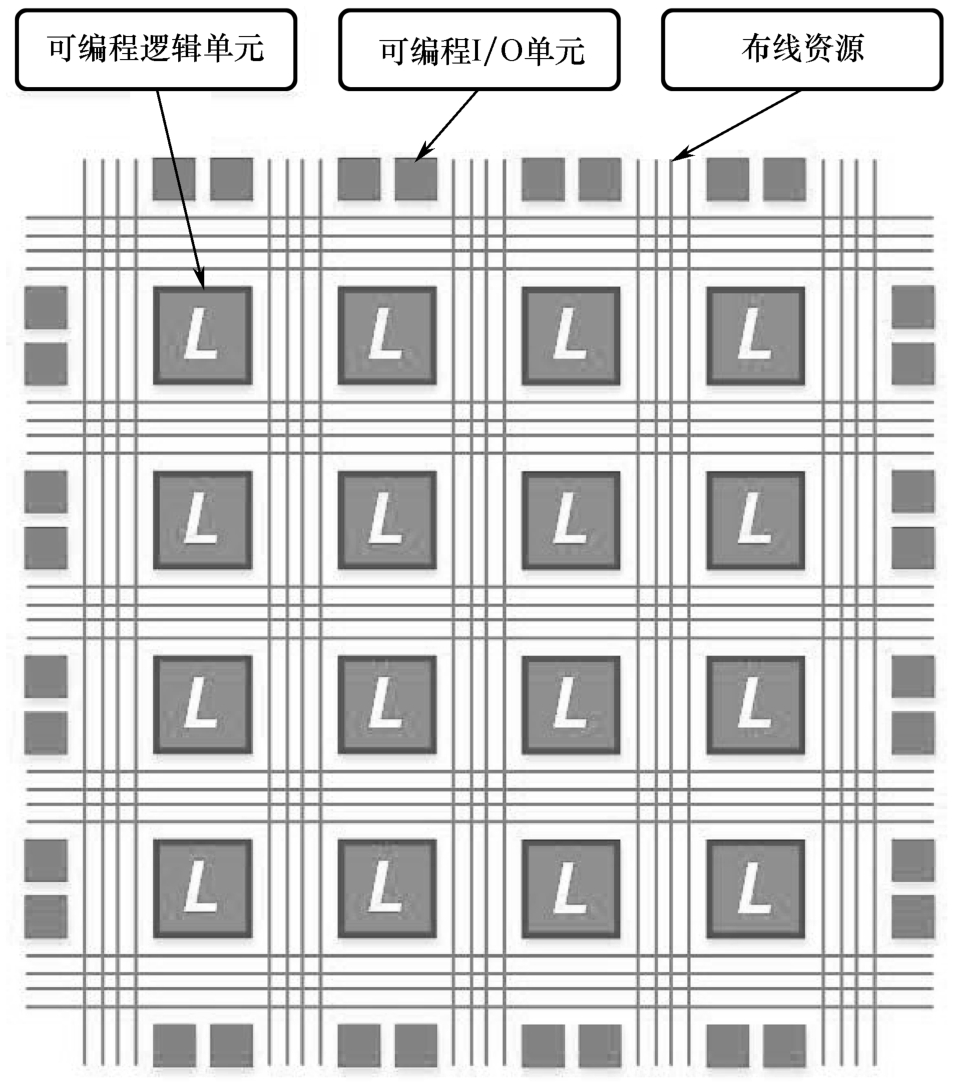
图1.1 FPGA内部结构
作为FPGA的主流厂商,在28nm工艺节点上,Xilinx推出了7系列FPGA,依然采用ASMBL(Advanced Silicon Modular Block)架构,如图1.2所示。在该架构中,每类资源以列形式存在,列的个数决定了该资源的数量,从而可以满足不同应用领域的需求。
CLB [1] 在FPGA中最为丰富,由两个SLICE构成。由于SLICE有SLICEL(L:Logic)和SLICEM(M:Memory)之分,因此CLB可分为CLBLL和CLBLM两类,如图1.3所示,图中箭头为进位链。
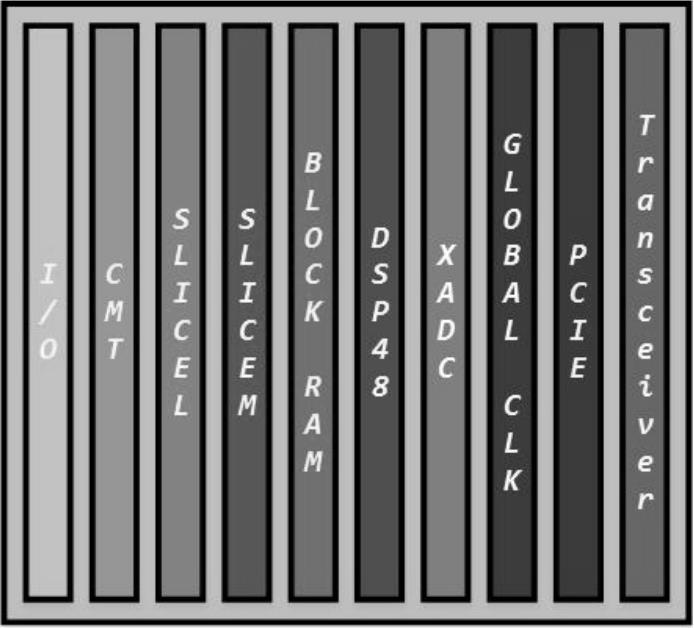
图1.2 ASMBL架构
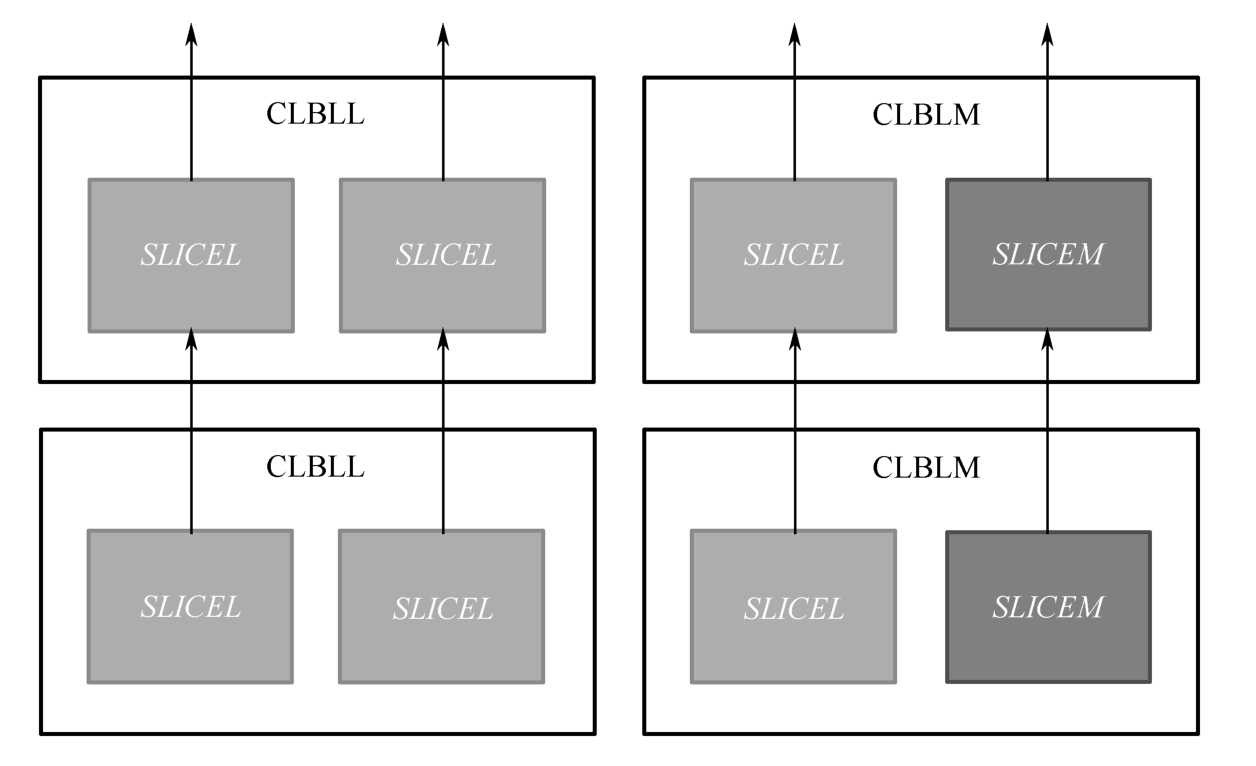
图1.3 Xilinx 7系列FPGA CLB和SLICE的关系
SLICEL和SLICEM内部都包含4个6输入查找表(LUT6)、3个数据选择器(MUX)、1个进位链(Carry Chain)和8个触发器(Flip-Flop),如图1.4所示。尽管如此,二者的结构仍略有不同,正是这种结构上的差异导致了LUT6功能的不同。
LUT6内部结构如图1.5所示。LUT6基本功能如表1.1所示,该表也体现了SLICEL和SLICEM的区别。
用作逻辑函数发生器时,查找表就扮演着真值表的角色,真值表的内容可在Vivado中查看。例如,实现!a&!b时Vivado显示的查找表的内容如图1.6所示。
结合图1.5可知,LUT6可满足以下情形的逻辑运算:
(1)任意6输入布尔表达式,此时运算结果均由O6输出;
(2)两个共享输入端口的5输入布尔表达式,此时A6=1,运算结果分别由O6和O5输出;
(3)一个 x 输入布尔表达式和一个 y 输入布尔表达式,只要满足 x + y ≤5,此时A6=1,运算结果分别由O6和O5输出。
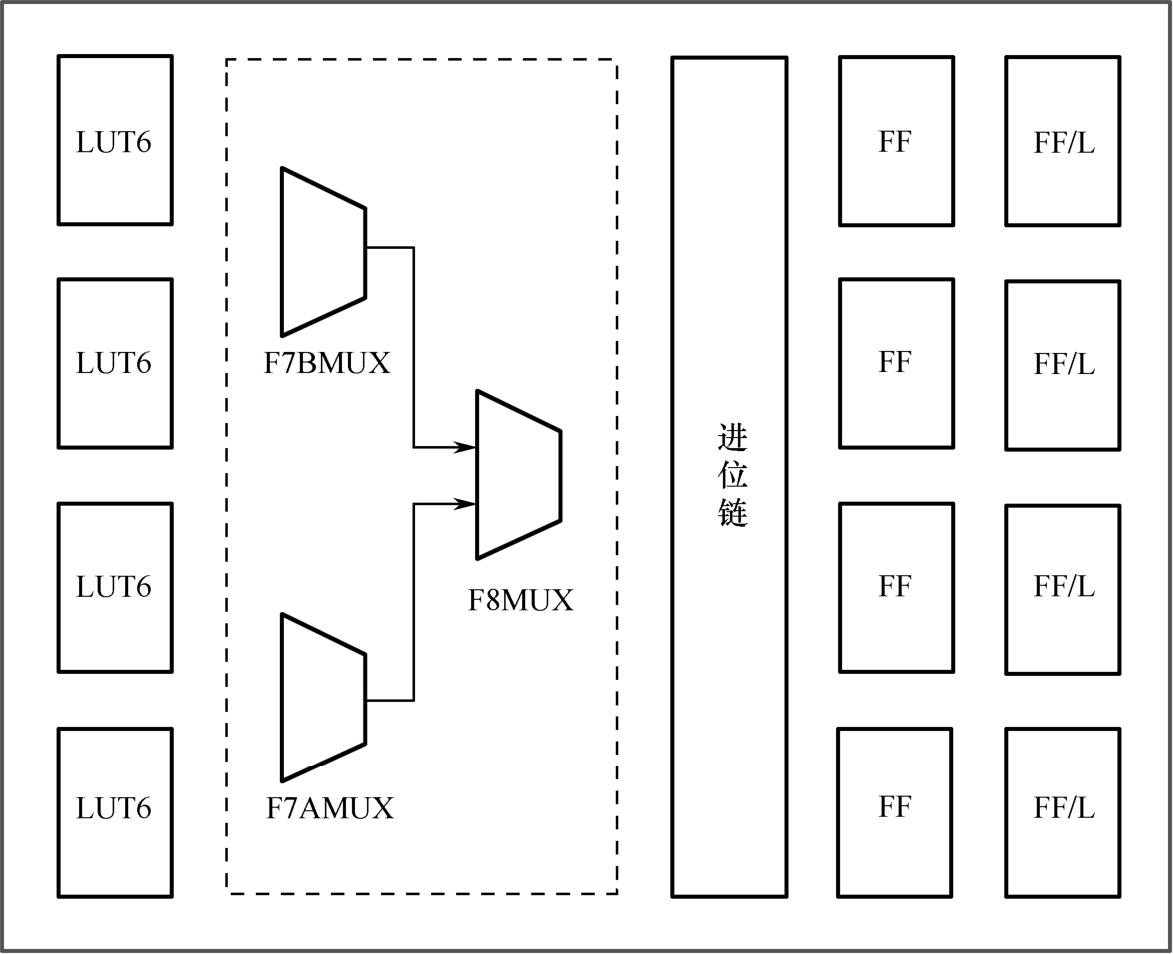
图1.4 SLICE内部资源
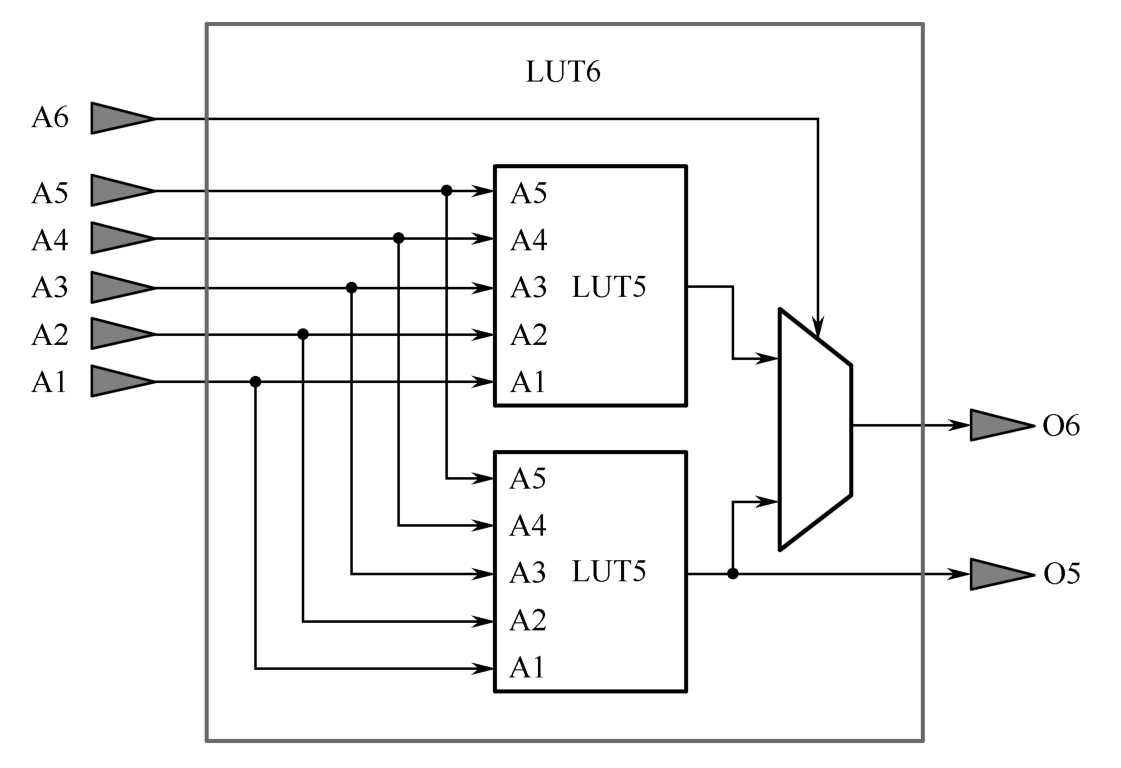
图1.5 LUT6内部结构
表1.1 LUT6基本功能

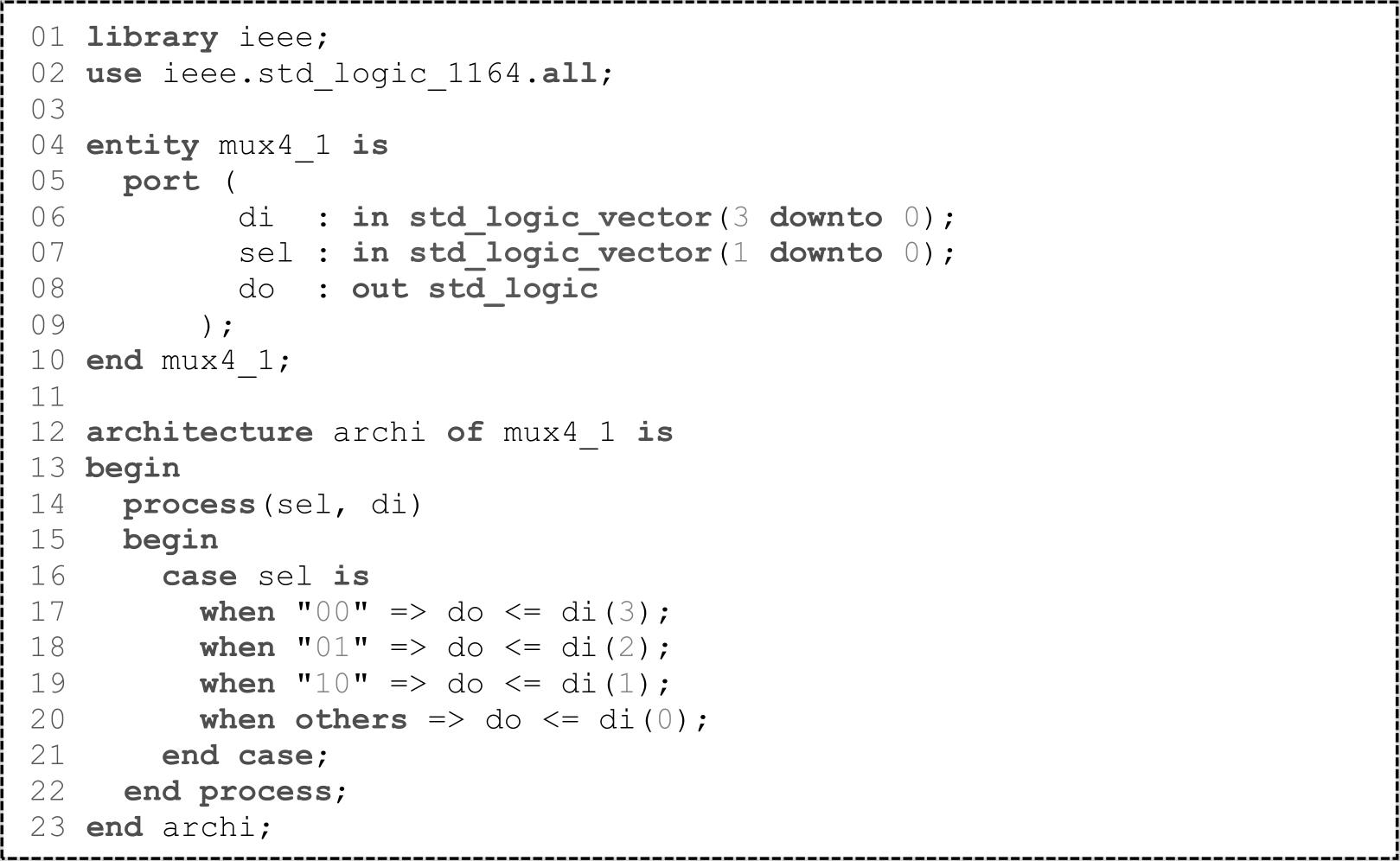
对于第二种情形,默认情况下Vivado会把这两个布尔表达式放在一个LUT6中实现;对于第三种情形,当这两个布尔表达式有共享端口时,默认情况下Vivado会把这两个布尔表达式放在一个LUT6中实现,否则Vivado会把这两个布尔表达式分别放在两个LUT6中。因此,对于VHDL代码1.1,f1和f3会被放在一个LUT6中,f2会单独占用一个LUT6,整个设计会占用两个LUT6。
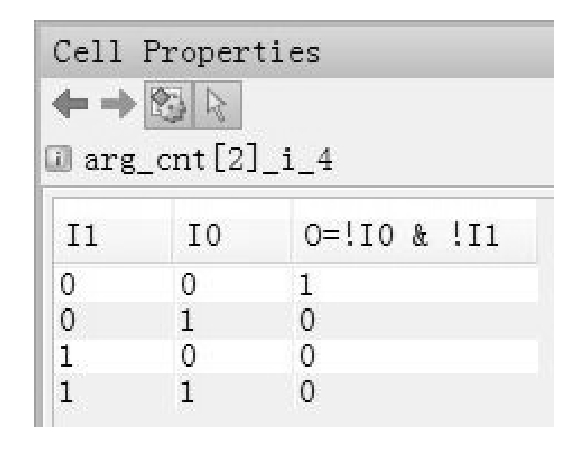
图1.6 实现!a&!b时Vivado显示的查找表的内容

查找表还可用作ROM(Read-Only Memory),每个SLICE中的LUT6可配置为64×1(占用1个LUT6,64代表ROM深度,1代表ROM宽度)、128×1(占用2个LUT6)和256×1(占用4个LUT6)的ROM。
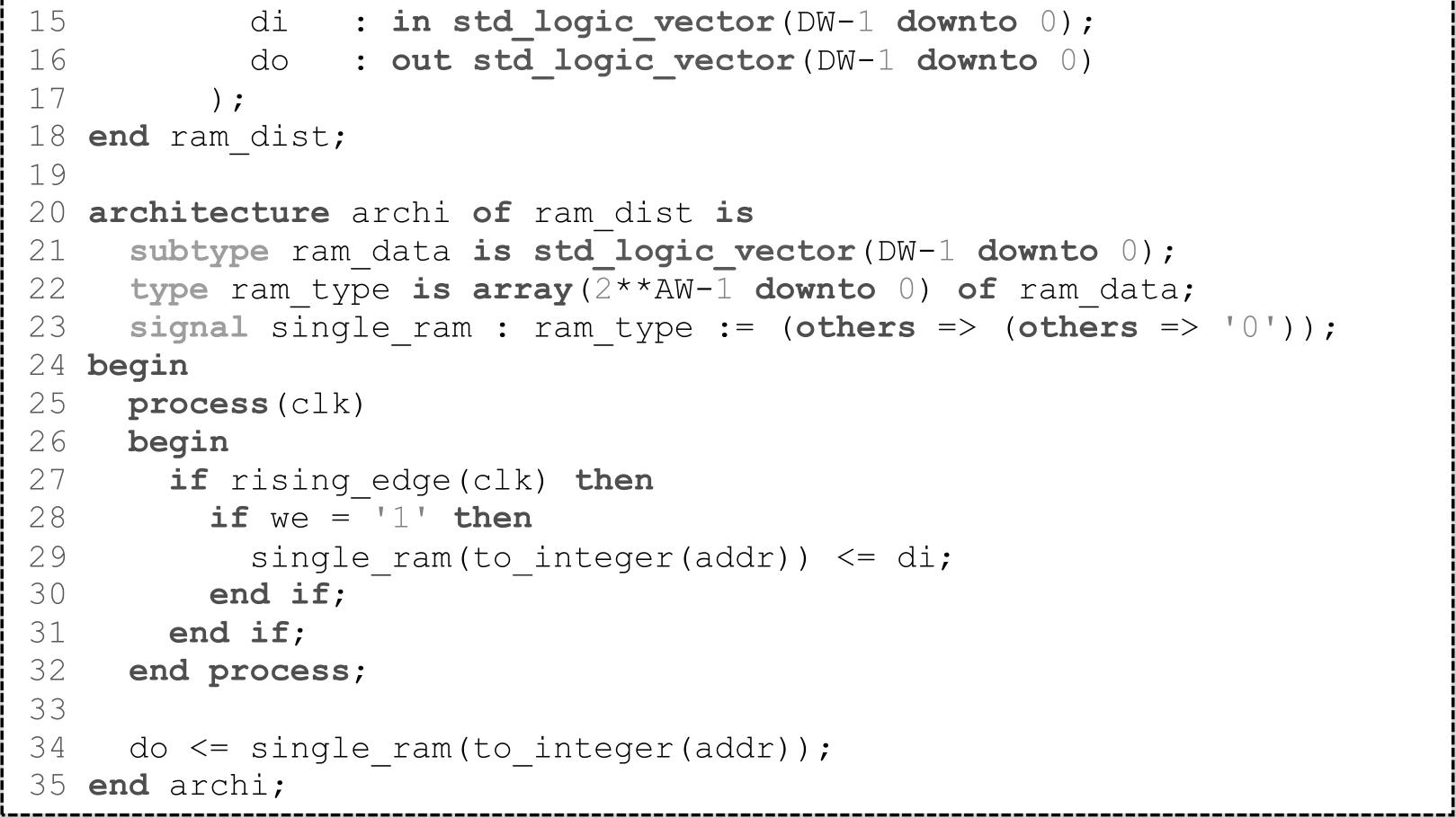
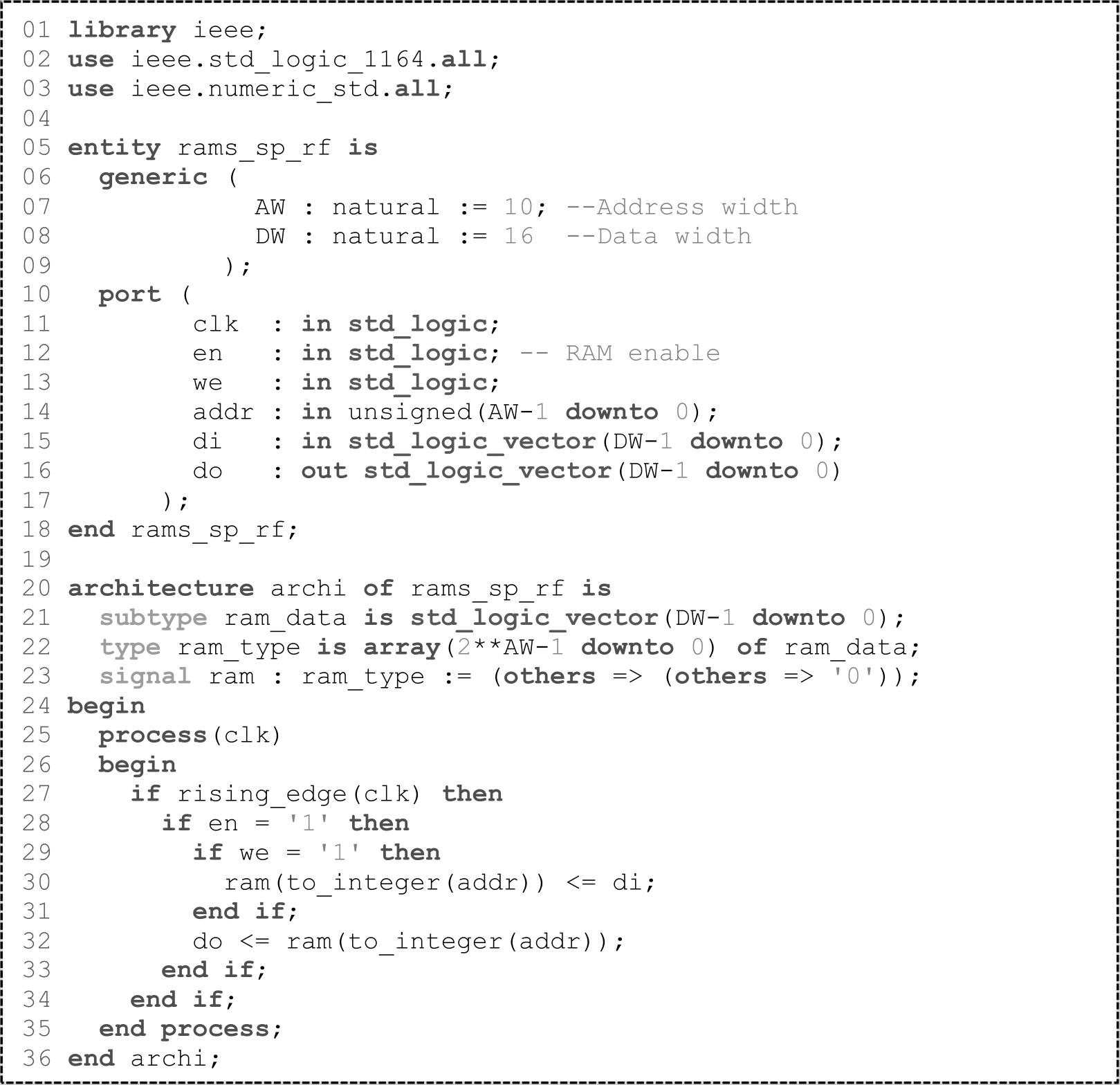
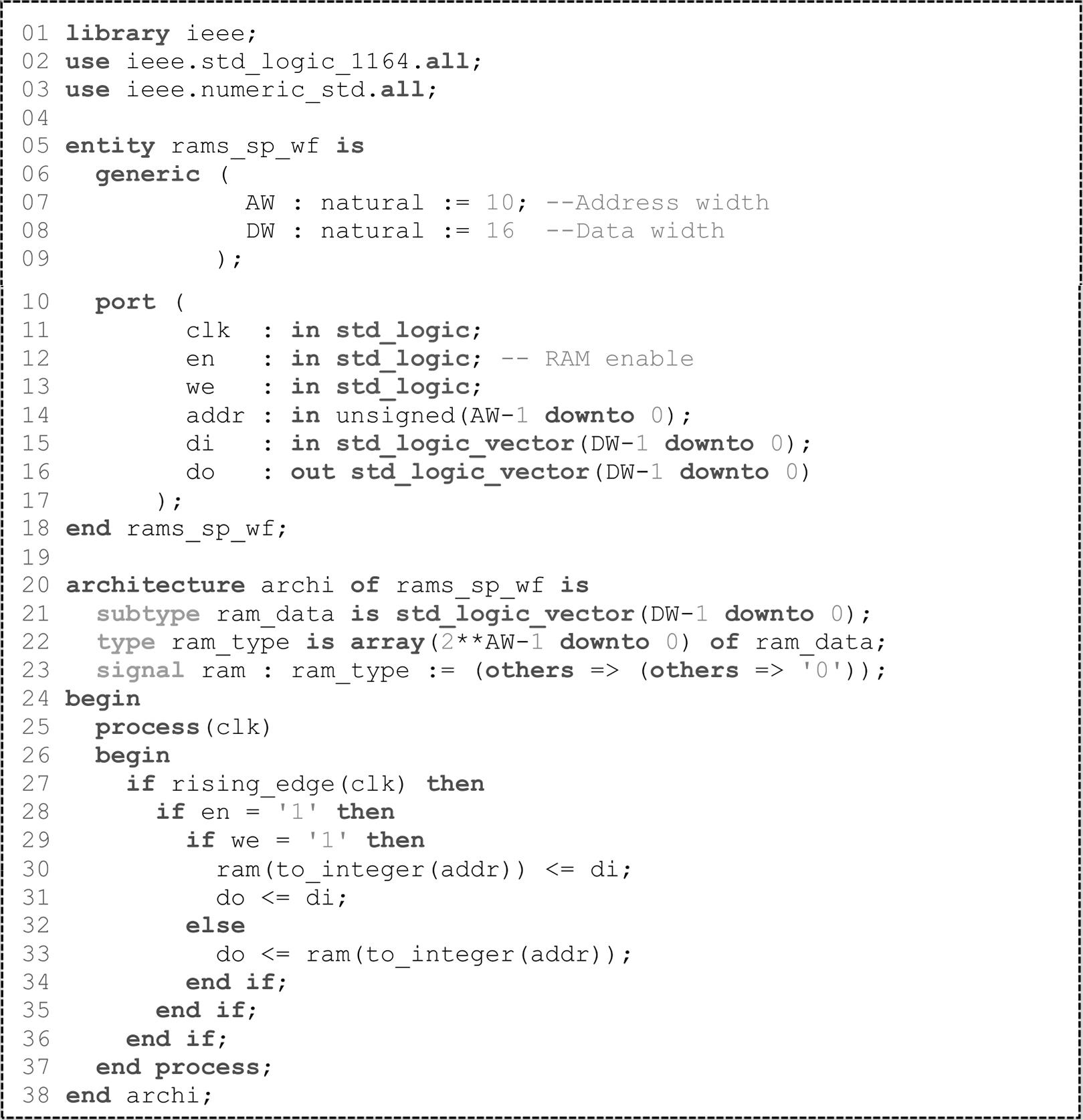
SLICEM中的查找表可配置为RAM(Random Access Memory),称为分布式RAM。其中,RAM的写操作为同步,读操作为异步,与时钟信号无关。如果需要实现同步读操作,则要占用额外的触发器,虽增加了一个时钟的Latency(延迟),但提升了系统的性能。一个LUT6可配置为64×1的RAM,当RAM的深度大于64时,会占用额外的MUX(F7AMUX、F7BMUX和F8MUX)。VHDL代码1.2实现的是单端口RAM,会占用16个LUT6。对于分布式存储单元(RAM和ROM),Vivado提供了相应的IP:Distributed Memory Generator。

SLICEM中的查找表还可配置为移位寄存器,每个LUT6可实现深度为32的移位寄存器,且同一个SLICEM中的LUT6可级联实现128深度的移位寄存器。移位寄存器采用VHDL描述时如VHDL代码1.3所示,当DEPTH=4时,功能描述如图1.7所示。
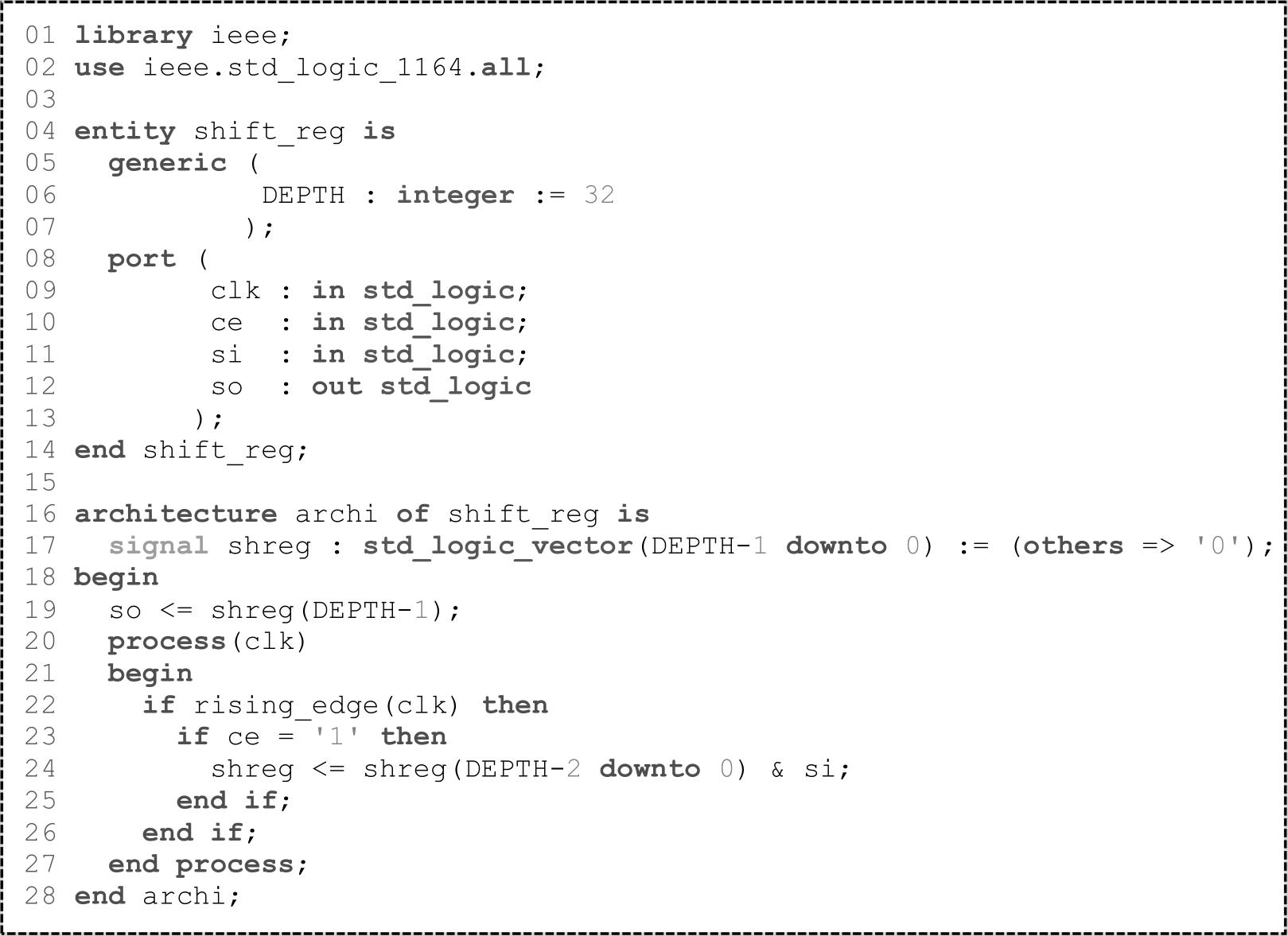
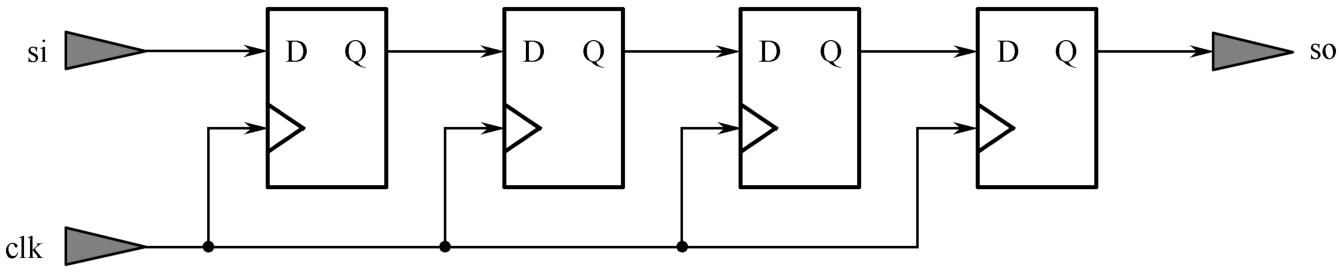
图1.7 移位寄存器功能描述
此外,动态移位寄存器也可采用SLICEM中的查找表实现,相应的代码如VHDL代码1.4所示。若DEPTH=4,则功能描述如图1.8所示。移位寄存器的典型应用是延迟补偿和同步FIFO。需要注意的是,这里的移位寄存器均没有复位端,是因为LUT6本身不支持复位。一旦代码描述中使用了复位,则无论是同步复位还是异步复位,都会导致移位寄存器采用触发器级联的方式实现。
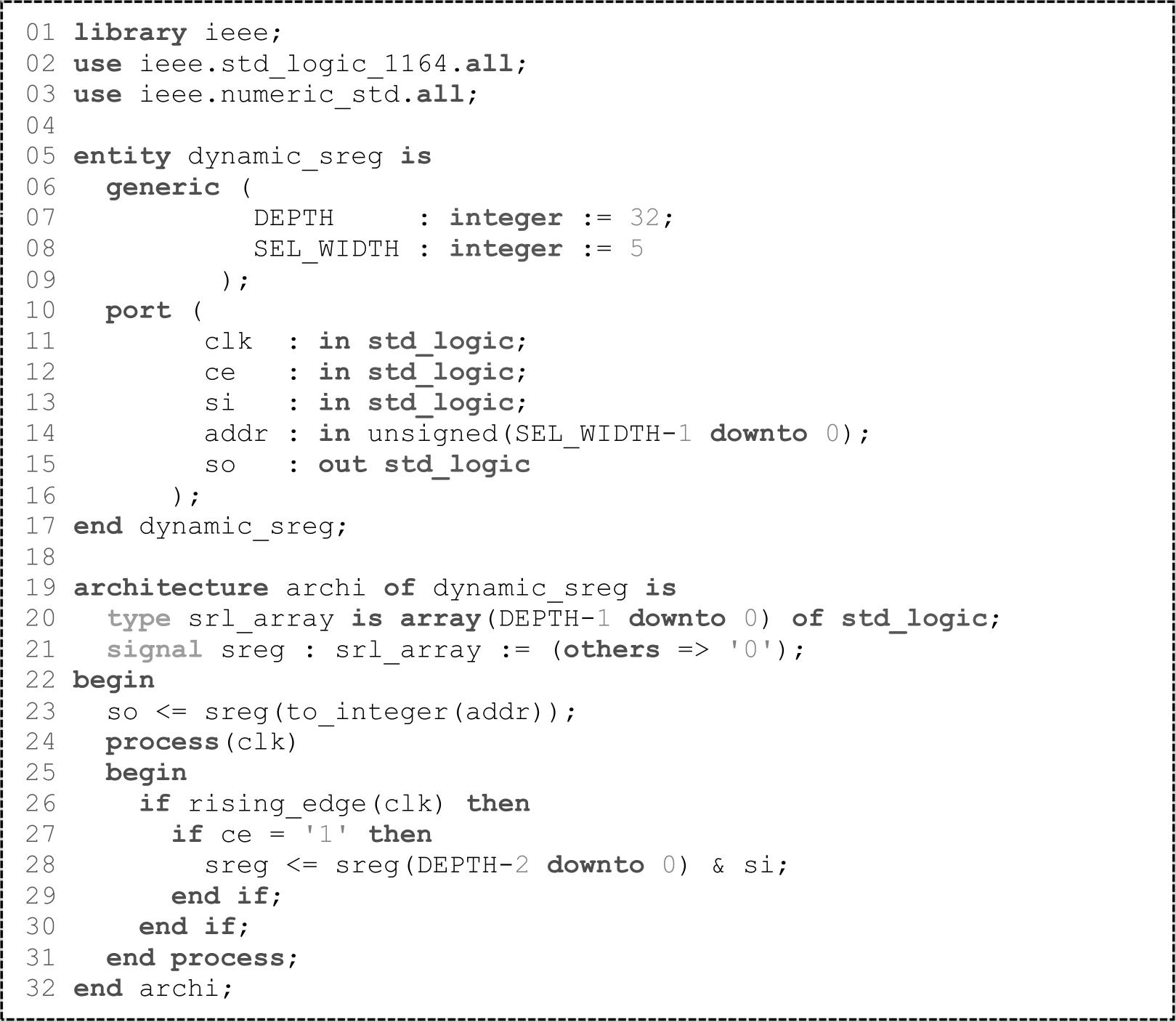
基于LUT6的移位寄存器除使用HDL代码描述方式外,还可采用原语(Primitive,SRL16E或SRLC32E)或在Vivado中直接调用IP:RAM-based Shift Register。
SLICE中的三个MUX(Multiplexer:F7AMUX、F7BMUX和F8MUX)可以和LUT6联合共同实现更大的MUX。事实上,一个LUT6可实现4选1的MUX。一个4选1的MUX如VHDL代码1.5所示,用布尔表达式可表示为
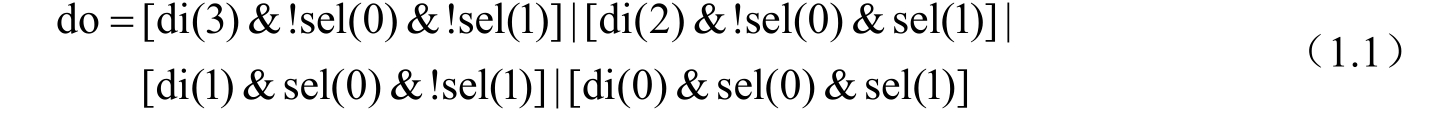
式中,“&”表示“与运算”;“!”表示“取反运算”;“|”表示“或运算”。显然,式(1.1)是一个6输入布尔表达式,故占用一个LUT6。
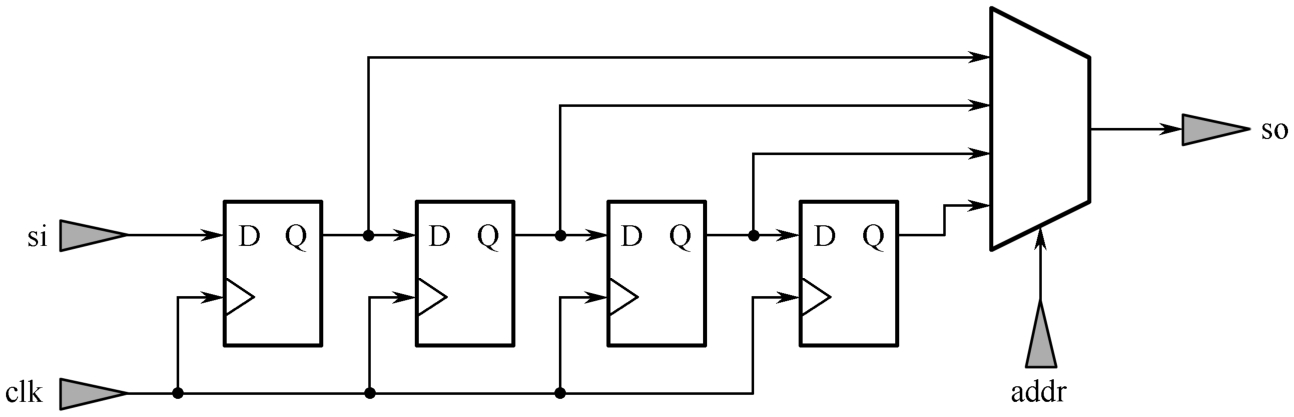
图1.8 动态移位寄存器功能描述
SLICE中F7MUX(F7AMUX和F7BMUX)的输入数据来自相邻的两个LUT6的O6端口。由于一个F7MUX和相邻的两个LUT6可实现一个8选1的MUX,因此一个SLICE可实现两个8选1的MUX。由于4个LUT6、F7AMUX、F7BMUX和F8MUX可实现一个16选1的MUX,因此一个SLICE可实现一个16选1的MUX。
SLICE中的进位链用于实现加法和减法运算。进位链中包含2输入异或门。这是因为异或运算是加法运算中必不可少的运算。以一位全加器为例:输入端是被加数 A 、加数 B 及较低位的进位 C I N ;输出端是本位和 S 及向较高位的进位 C O UT 。输出与输入的逻辑关系可表示为
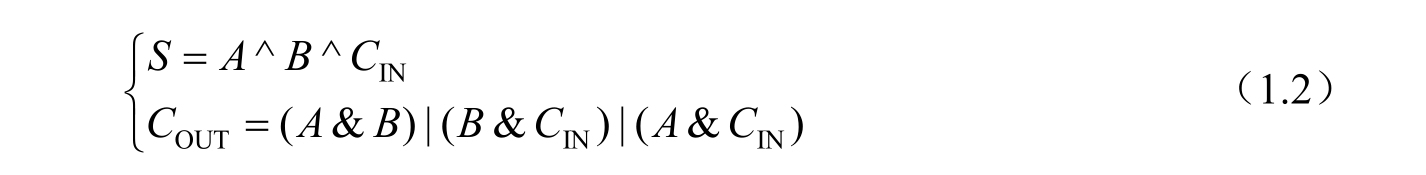
每个SLICE中有8个触发器。这8个触发器可分为两大类,其中4个只能配置为边沿敏感的D触发器(图1.4中标记为FF),而另外4个既可以配置为边沿敏感的D触发器,又可以配置为电平敏感的锁存器(图1.4中标记为FF/L)。但是当后者被配置为锁存器时,前者将无法使用。当这8个触发器用作D触发器时,它们的控制端口包括使能端CE、置位/复位端S/R和时钟端CLK是对应共享的。{CE,S/R,CLK}称为触发器的控制集。显然,在具体设计时,控制集种类越少越好,这样可以提高触发器的利用率。S/R端口可配置为同步/异步置位或同步/异步复位,且高有效,因此可形成4种D触发器,如表1.2所示。可见,触发器无法实现复位和置位并存的情形。另外,当使用低有效置位或复位时,会占用额外的查找表资源以实现极性翻转。
表1.2 4种D触发器

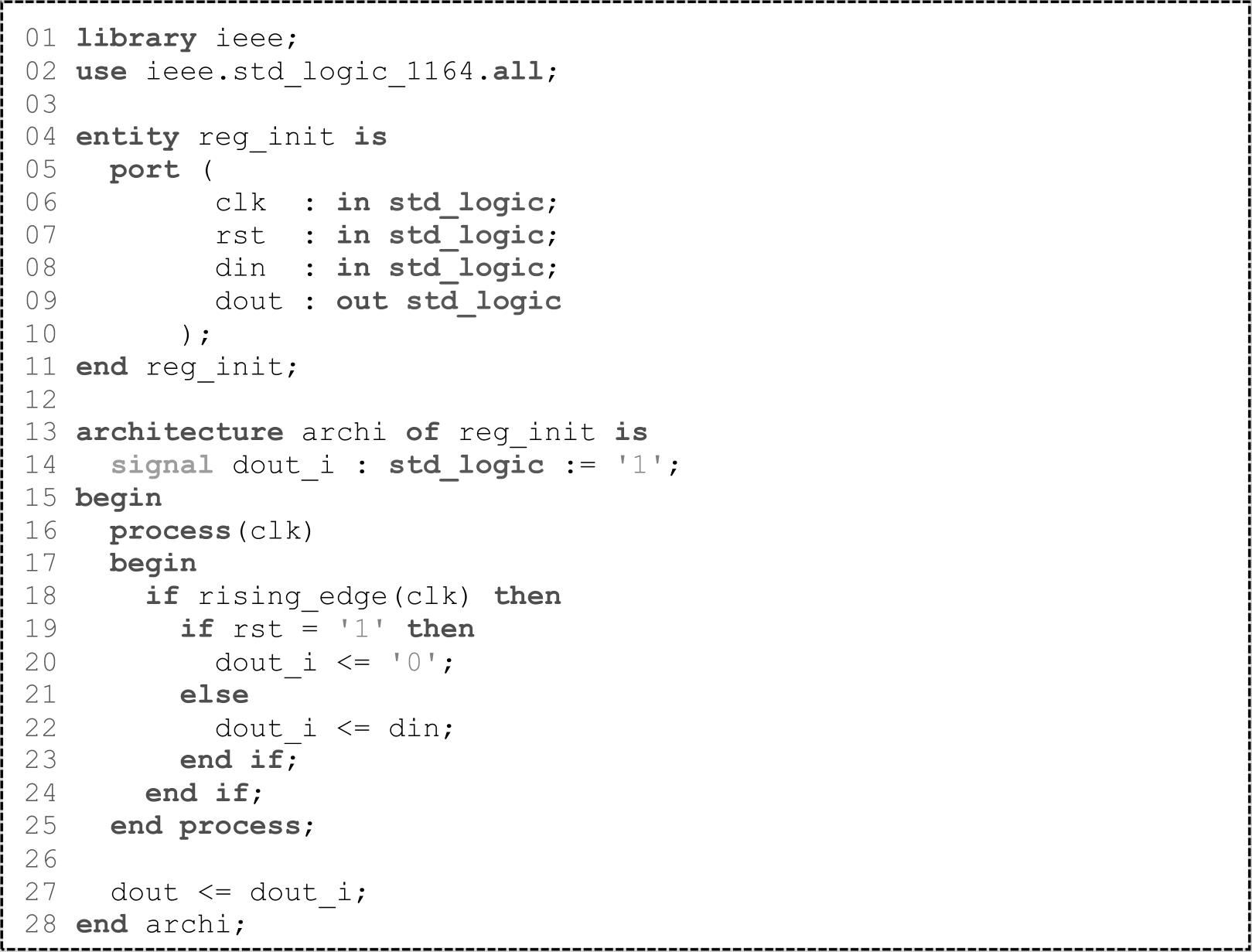
此外,还可以设定触发器的初始值,如VHDL代码1.6第14行所示。初始值不仅在仿真时起作用,在综合后的网表中也可以看到。
每个BRAM [2] 大小均为36KB(RAMB36E1),由两个独立的18KB BRAM(RAMB18E1)构成,因此一个36KB的BRAM可配置为4种情形,如图1.9所示。由于两个18KB的BRAM无法共享其中的FIFO Logic(用于生成FIFO控制信号,包括读/写地址等),因此无法将一个36KB的BRAM当作两个18KB的Built-in FIFO(使用固有的FIFO Logic)来使用。
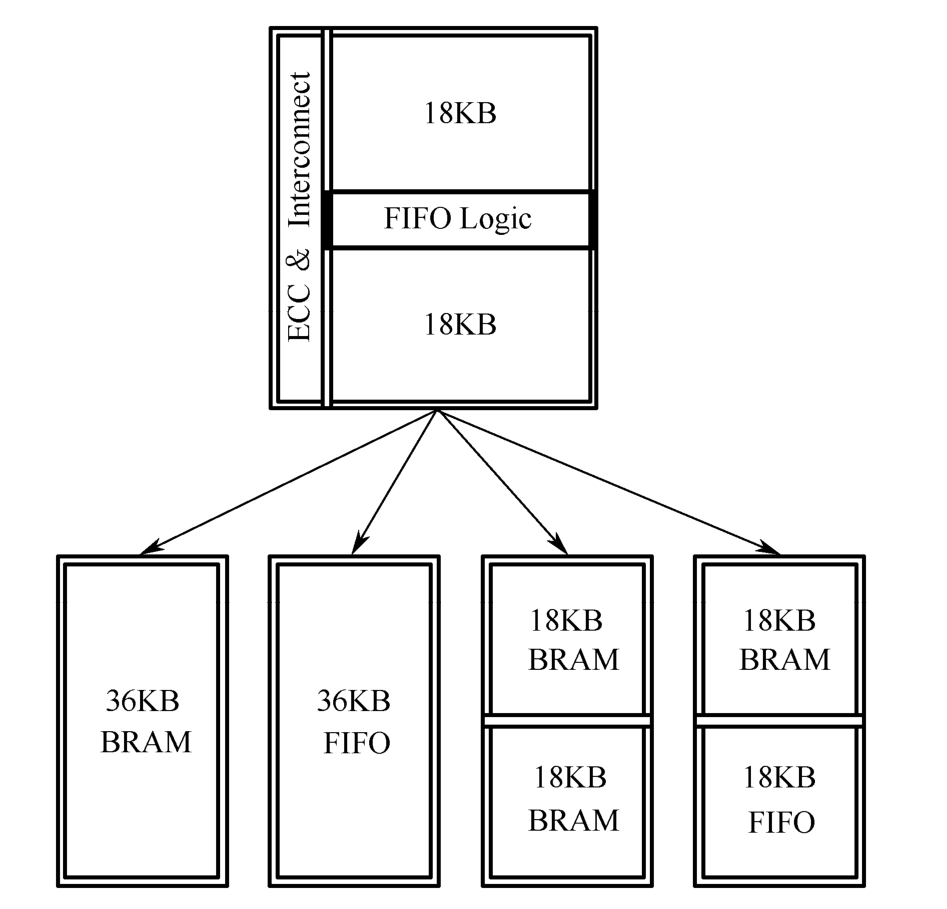
图1.9 36KB BRAM的4种应用情形
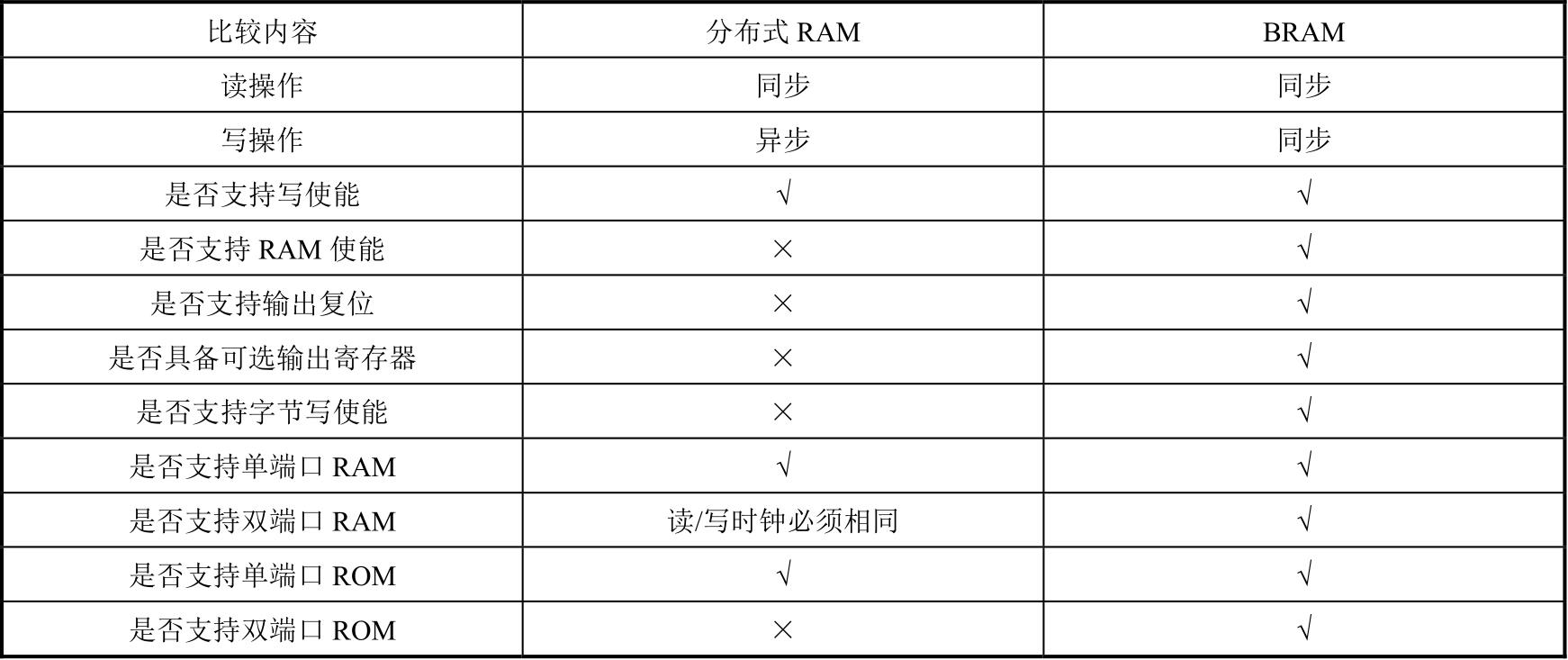
BRAM与查找表构成的分布式RAM的差异如表1.3所示。尽管BRAM可支持更多功能,但这并不表明BRAM在任何场合都具有优势。对于一些小规模的数据存储,分布式RAM可获得与BRAM相媲美,甚至比BRAM更好的性能(从功耗和速度两方面比较)。
表1.3 BRAM与分布式RAM的差异
BRAM配置为RAM时有三种工作模式:读优先(Read First,Read-Before-Write Mode)、写优先(Write First,Transparent Mode)和保持模式(No Change Mode)。这三种模式体现了当对RAM中同一地址同时进行读操作和写操作时的不同。从HDL代码角度来看,以单端口BRAM为例,VHDL代码1.7为读优先模式,VHDL代码1.8为写优先模式,VHDL代码1.9为保持模式。代码中第23行将RAM初始化为全0值,第28行的en为RAM使能信号,第29行的we为写使能信号;di为输入数据端口,do为输出数据端口。


对VHDL代码1.7~VHDL代码1.9进行仿真,仿真结果如图1.10所示。图中,do_rf为读优先模式输出结果,do_wf为写优先模式输出结果,do_nc为保持模式输出结果。从图中可以看到,当同时对RAM中的同一地址进行读/写时,读优先模式将读出该地址内的原有数据,写优先模式将读出当前向该地址写入的数据,保持模式则保持之前读出的数据不变。
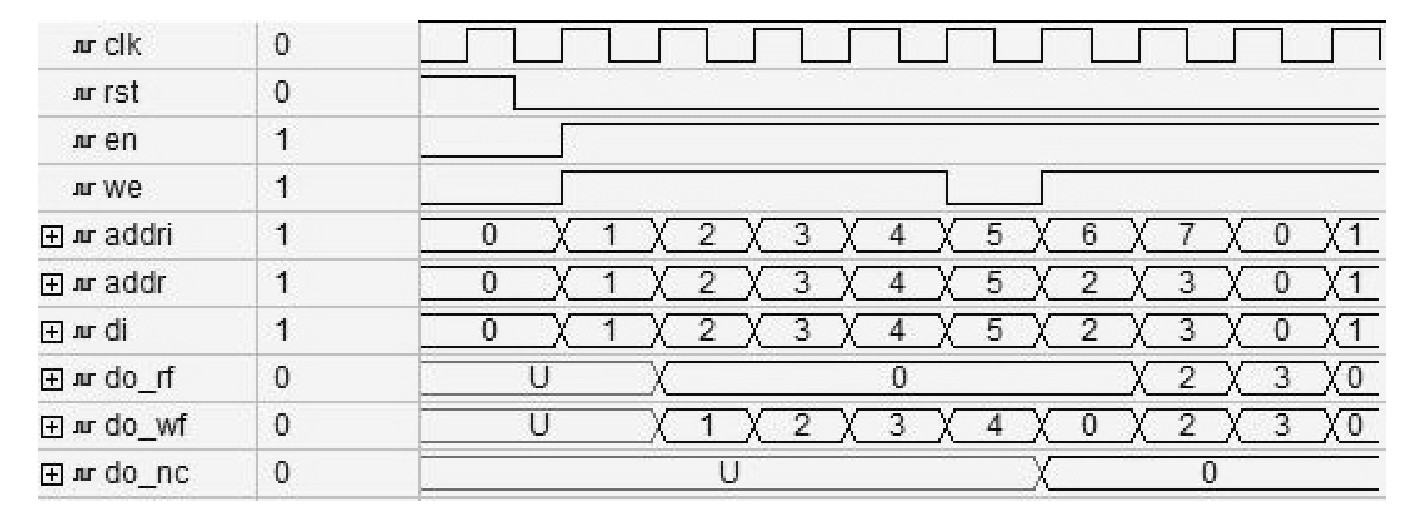
图1.10 BRAM三种工作模式仿真结果
用作RAM时,BRAM还支持字节使能,具体功能如VHDL代码1.10所示。从代码第30~33行可以看到,每一位写使能对应1字节(实际上就是字节使能信号),当写使能有效时,将其对应的字节写入RAM中。


对VHDL代码1.10取CW=8,NB_COL=2,相应的仿真结果如图1.11所示。从图中可以看出,当we=1即we(0)='1'时,将“CB”写入1号地址的低8位;当we=2即we(1)='1'时,将“22”写入1号地址的高8位;当we=3即we(1)='1'且we(0)='1'时,将“33EE”写入1号地址。这在RAM的输出端do处得到了验证。

图1.11 BRAM字节写使能仿真结果
BRAM的RAM使能信号、内部锁存器同步复位信号RSTRAM和内部触发器同步复位信号RSTREG,既可配置为高有效,也可配置为低有效,而不会占用查找表资源。尽管如此,从代码风格的角度而言,采用7系列FPGA设计时,复位信号和使能信号均统一为高有效。这是因为其内部的触发器无论是复位还是使能均只支持高有效。
Vivado提供了IP:Block Memory Generator,用于将BRAM配置为RAM或ROM。在该IP中对RAM的输出提供了两个可选输出寄存器,即图1.12中的Primitives Output Register和Core Output Register。其中,前者位于BRAM内部,后者为CLB中的触发器。需要注意的是,在这里,这两个触发器只支持同步高有效复位。这两个触发器可大大降低时钟到输出的延迟。UltraFast设计方法学建议在高速设计中,这两个触发器都使用,尽管这会使读操作的Latency增大为3个时钟周期。
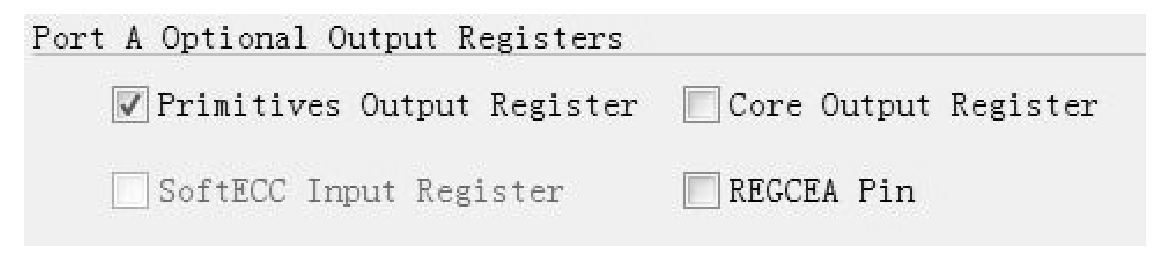
图1.12 BRAM输出可选寄存器
BRAM还可以配置为FIFO(同步FIFO或异步FIFO),同时提供了专用的FIFO Logic用于生成FIFO的控制信号(如读/写地址)和状态信号(如空/满标记信号)。使用专用FIFO Logic的FIFO称为Built-in FIFO。Vivado提供了IP:FIFO Generator,既可以将BRAM配置为Built-in FIFO,也可以采用CLB资源生成FIFO控制逻辑结合BRAM构成FIFO。
对于7系列FPGA内部未使用的18KB BRAM,Vivado通过Power Gating技术不会对其进行初始化,从而可有效降低功耗。
7系列FPGA中的运算单元为DSP48E1 [3] ,它不仅可以实现逻辑运算,如与、或、异或,也可以实现算术运算,如加法、乘法、乘累加等。其对外端口如图1.13所示,端口描述如表1.4所示。表中,Fix_W_F表示有符号定点数,字长为W,小数部分字长为F;UFix_W_F表示无符号定点数,字长为W,小数部分字长为F。DSP48E1支持25×18(被乘数和乘数位宽分别为25bit和18bit)的有符号数乘法和24×17的无符号数乘法(端口A用作乘法输入端口时,尽管为30bit,但其高5位为符号位的扩展)。
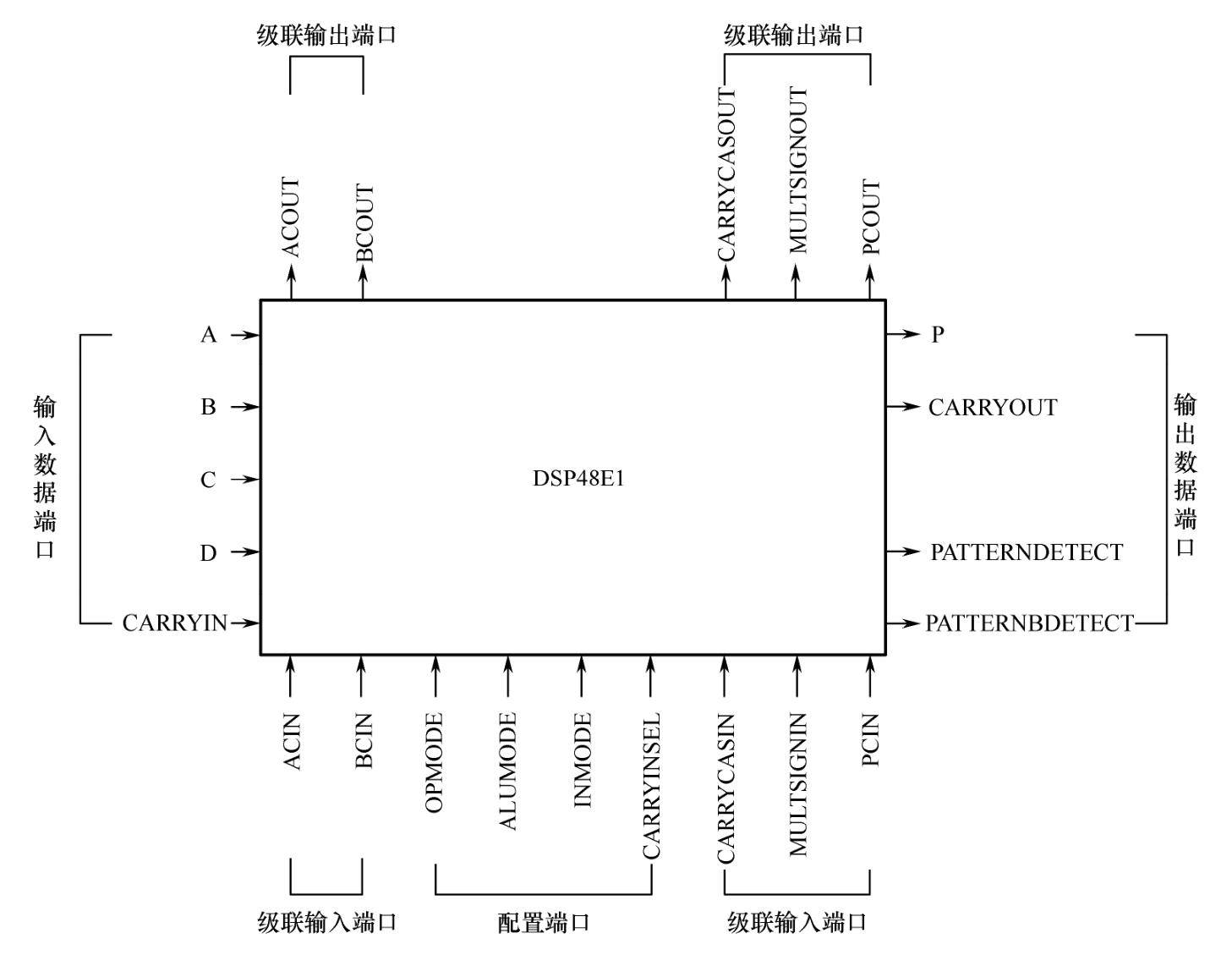
图1.13 DSP48E1对外端口
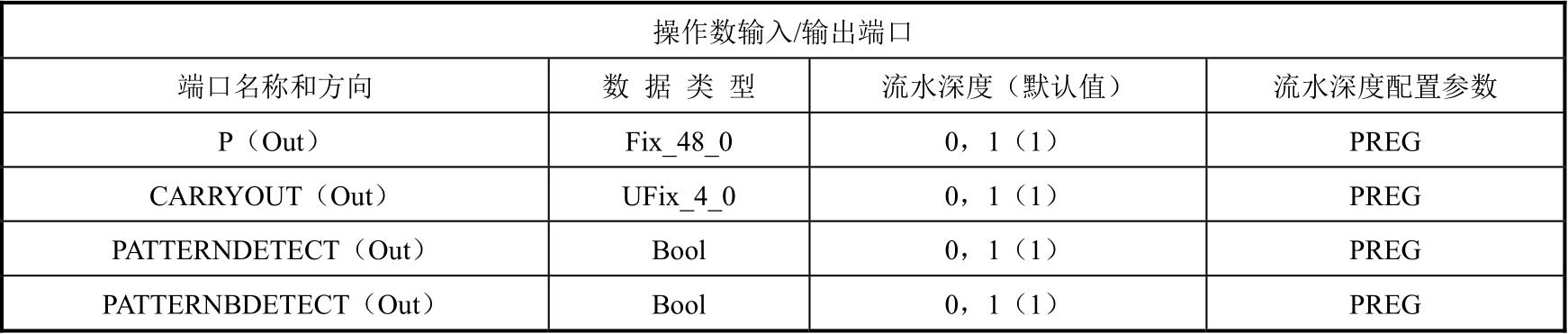
表1.4 DSP48E1对外端口描述
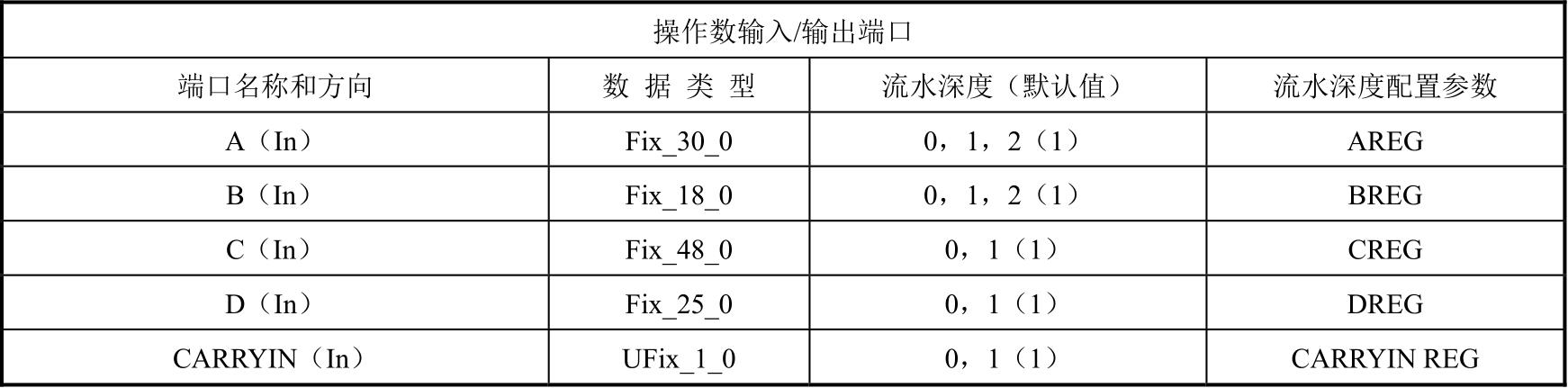
(续表)
DSP48E1的简化结构如图1.14所示。图中,D表示D触发器。构成DSP48E1的核心部分为预加器、乘法器和算术逻辑单元(ALU,用于实现逻辑运算和算术运算,具体功能由ALUMODE控制)。其中,ALU的输入数据由OPMODE控制X MUX、Y MUX和Z MUX(图中以XYZ MUX表示)来决定。
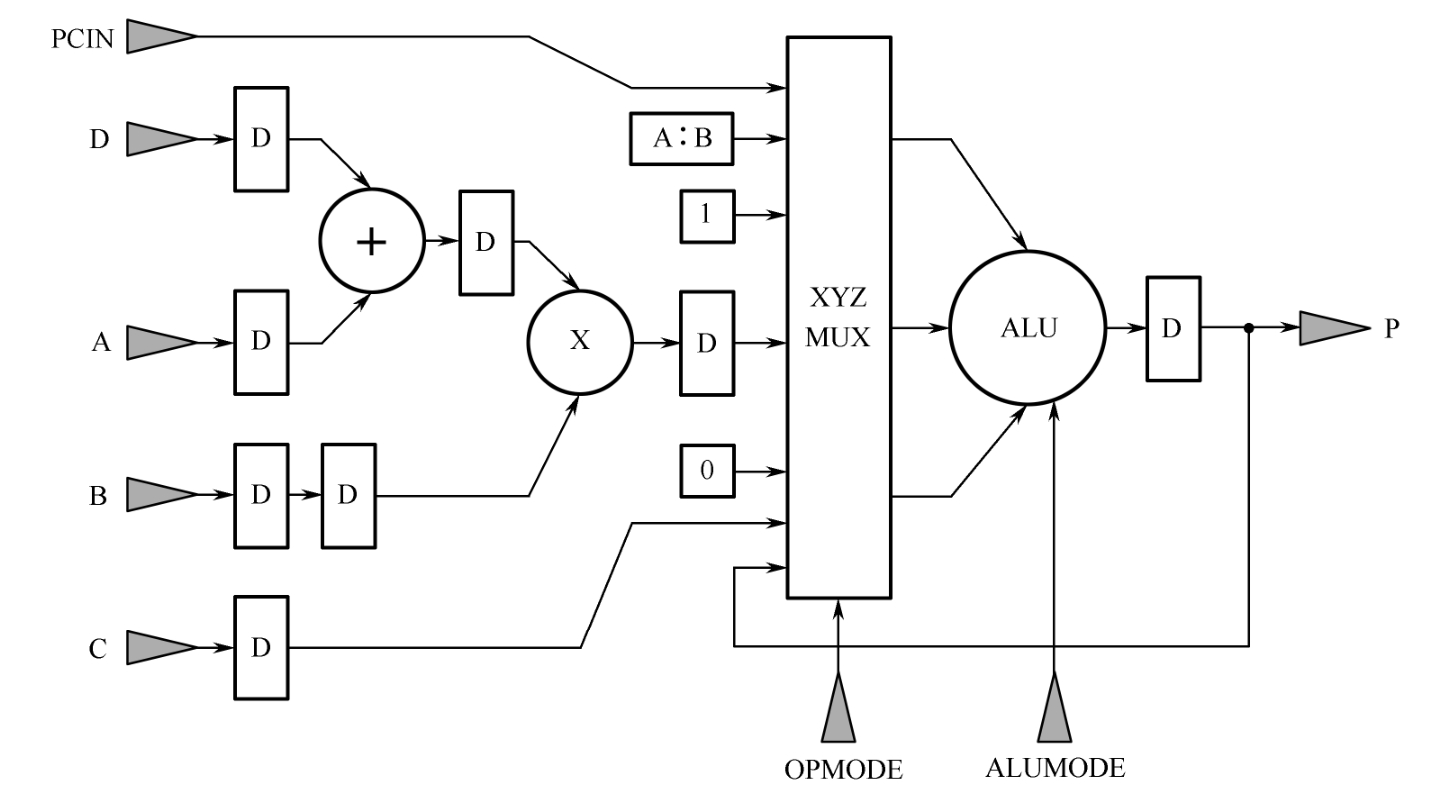
图1.14 DSP48E1的简化结构
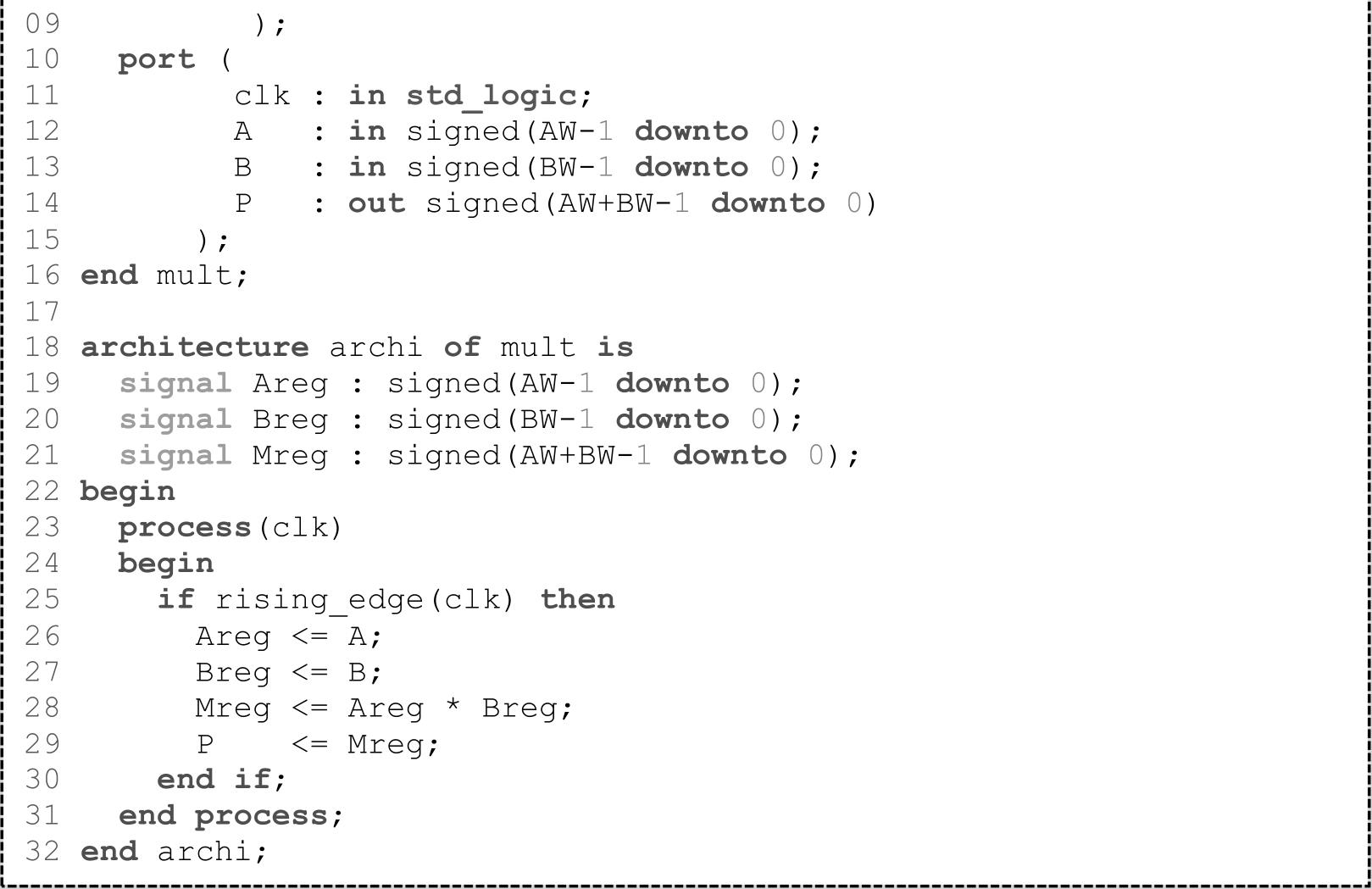
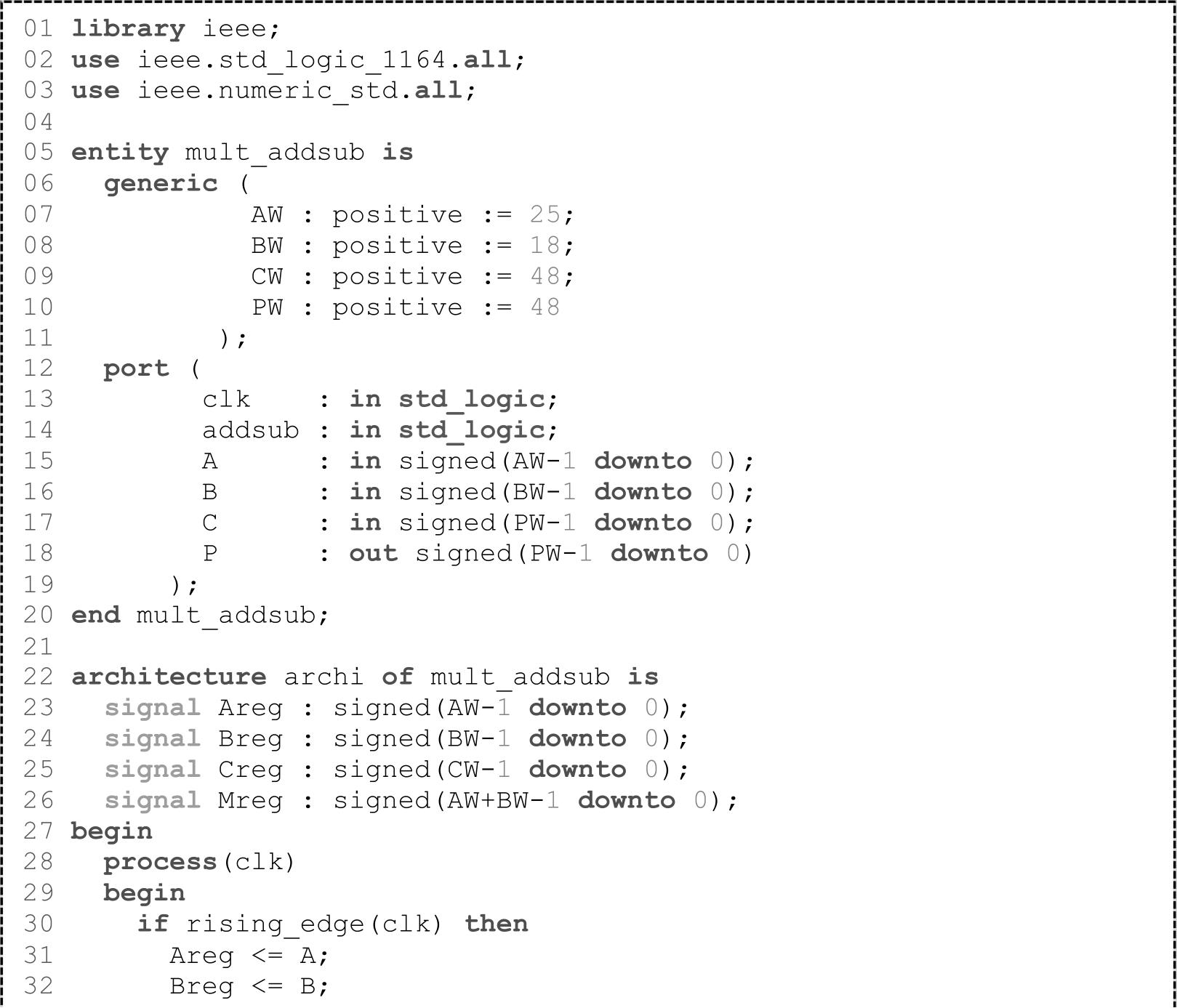
在默认情况下,对于乘法(VHDL代码1.11)、乘加/乘减(VHDL代码1.12)、乘累加(VHDL代码1.13)和预加相乘运算(VHDL代码1.14),Vivado都会将其映射为DSP48E1。VHDL代码1.11~VHDL代码1.14都只占用了一个DSP48E1,代码中的寄存器都使用了DSP48E1内部的寄存器。需要注意的是,DSP48E1内部寄存器只支持同步复位,不支持异步复位。为了获得最高性能,在采用DSP48E1实现上述与乘法相关的运算时,需要三级流水(输入数据寄存、乘法器输出数据寄存和ALU输出数据寄存)。




为了便于直接使用DSP48E1,Vivado提供了IP:DSP48 Macro。
UltraScale系列FPGA依然采用ASMBL架构,与7系列FPGA在内部结构上虽有很多相似之处,但仍有差异。就CLB [4] 而言,UltraScale FPGA的每个CLB均由一个SLICEL或一个SLICEM构成,这相当于7系列FPGA中SLICE去掉了边界。CLB包含8个6输入查找表、7个MUX、1个进位链和16个触发器,如图1.15所示。
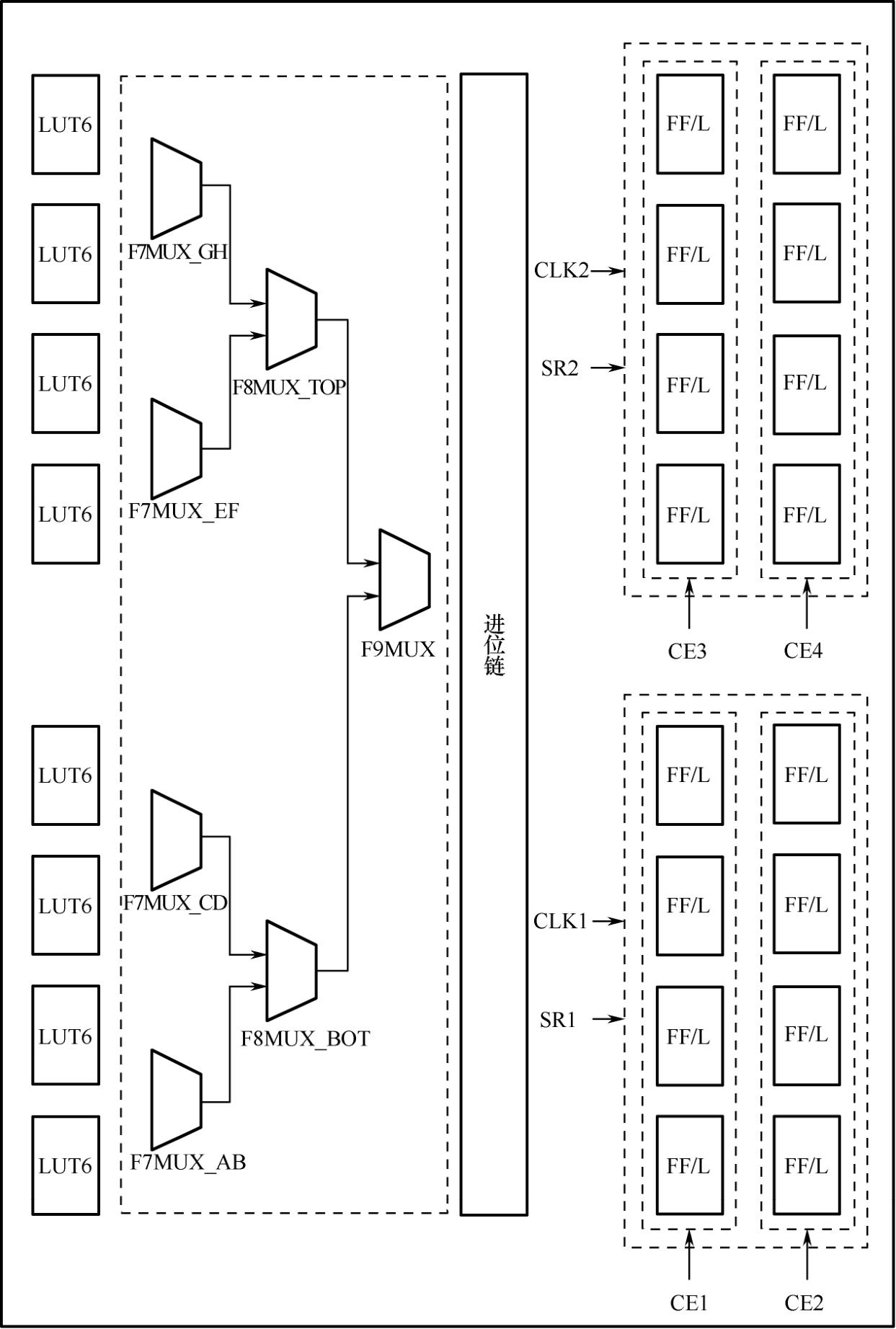
图1.15 UltraScale FPGA CLB内部资源
查找表的功能因SLICEL与SLICEM的不同而改变,这与7系列FPGA保持一致。SLICEM中的8个LUT6可级联实现深度为256的移位寄存器,用作分布式RAM时可存储512bit数据。与7系列FPGA相比,UltraScale CLB中多了一个F9MUX,使32选1的MUX可在一个CLB中实现(32选1的MUX需要占用8个LUT6)。
变化较大的是触发器,UltraScale CLB中的16个触发器均可配置为边沿敏感的D触发器或电平敏感的锁存器。CLB顶部和底部各8个一组。若该组中有一个触发器被配置为锁存器,那么其余的触发器只能当作锁存器使用。当用作边沿敏感的D触发器时,顶部的8个共享一个时钟端口和一个置位/复位端口(既支持高有效又支持低有效,而不会占用额外的逻辑资源),底部的8个共享一个时钟端口和一个置位/复位端口。顶部的8个分为两组,每组有独立的使能信号,底部的8个也是如此,从而使一个CLB中的16个触发器可以有2个时钟信号、2个置位/复位信号和4个使能信号,控制集的个数增加,对提高CLB的利用率非常有利。
此外,UltraScale中的触发器复位/置位信号既支持高有效又支持低有效。因此,VHDL代码1.15所描述的异步低有效D触发器若在UltraScale FPGA中,将直接映射为FDCE,如图1.16所示;若在7系列FPGA中,则会占用一个查找表以实现极性翻转,如图1.17所示。这体现了代码风格的一个原则,即HDL代码要与FPGA内部结构相匹配。
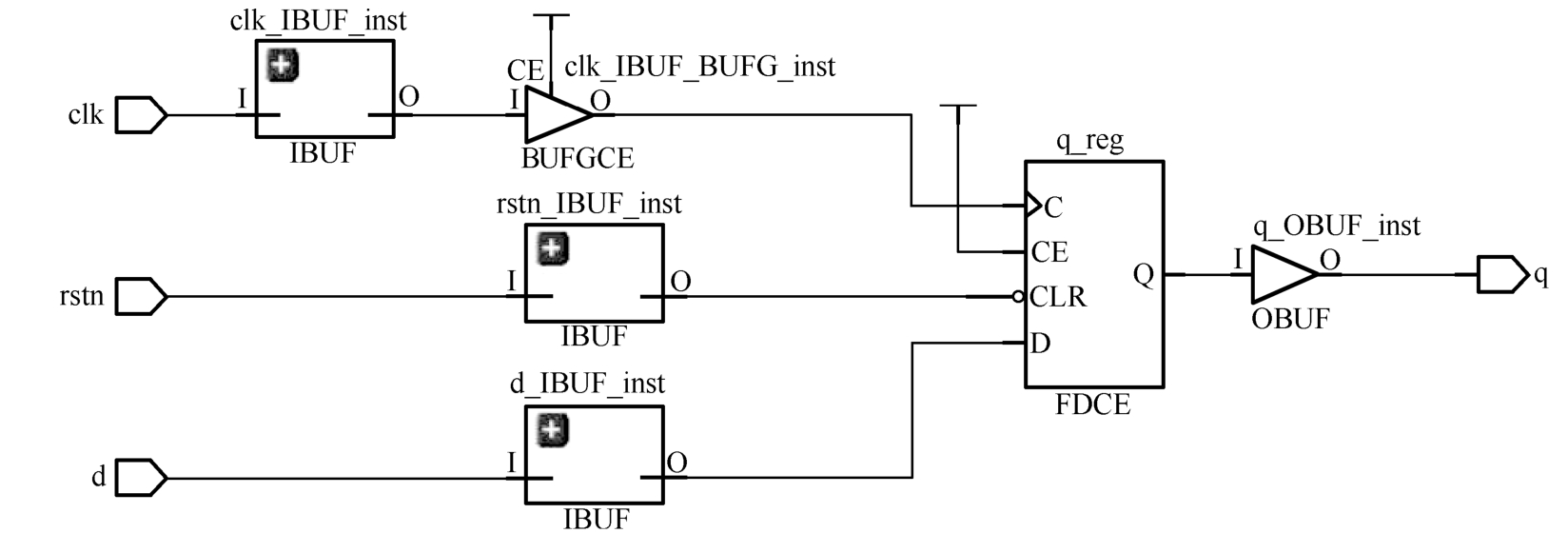
图1.16 异步低有效D触发器在UltraScale FPGA中的实现方式
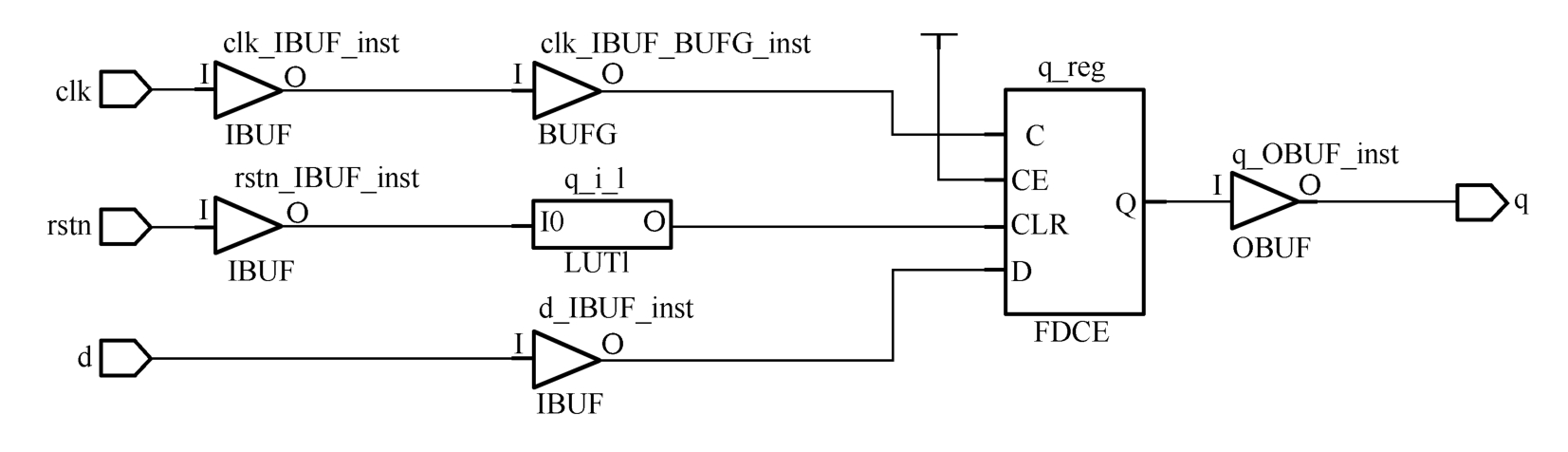
图1.17 异步低有效D触发器在7系列 FPGA中的实现方式
UltraScale中的BRAM为第二代BRAM(RAMB36E2,RAMB18E2),与7系列FPGA相比有两个不同之处 [5] 。
(1)UltraScale的每列BRAM有专用的级联走线。这对于构造更大的存储空间非常有利:BRAM的级联不需要使用CLB资源,同时还可以避免布线拥塞并且降低功耗。这种级联的使用也非常简单,只要存储空间需要至少两个RAMB36E2就有可能需要级联,Vivado会自动完成级联。
(2)为进一步降低动态功耗,每个RAMB18E2和RAMB36E2都提供了端口SLEEP。当RAM使能信号无效时,即在某段时间内对RAM不执行任何操作,即可将该RAM设置为睡眠模式(SLEEP=1)。在此模式下,RAM内的数据将保持不变。当再次对RAM进行操作时,需要先将RAM唤醒,这需要占用两个时钟周期。
UltraScale中的运算单元为DSP48E2 [6] ,其简化结构如图1.18所示。与DSP48E1相比,增加了3个MUX,其中两个如图中虚线框所示,另一个为W MUX(图中以WXYZ MUX表示4个MUX,即W MUX、X MUX、Y MUX和Z MUX)。从该图可以看出,DSP48E2很容易实现(A+D) 2 或(B+D) 2 。
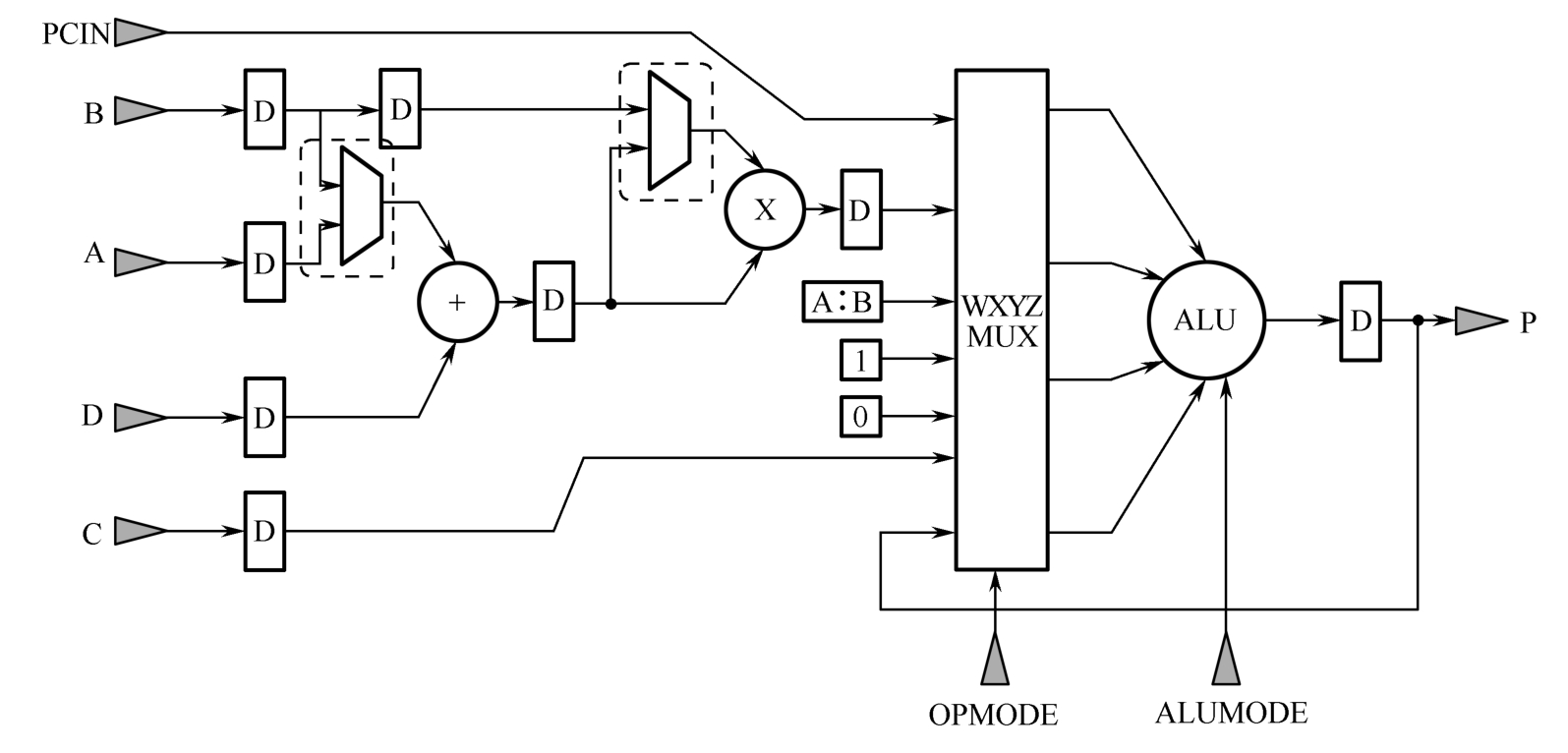
图1.18 DSP48E2简化结构
此外,DSP48E2中的预加器为27bit,乘法器可实现27×18的有符号数乘法运算和26×17的无符号数乘法运算。
采用VHDL描述平方运算如VHDL代码1.16所示,该代码可完全映射到DSP48E2中而不会占用额外资源。但若采用7系列FPGA则除了占用一个DSP48E1外,还会占用16个查找表和32个触发器。
