
下载掌阅APP,畅读海量书库
立即打开



综合选项的设置对综合结果有着潜在的影响。综合选项窗口如图2.1所示。本节介绍-fla-tten_hierarchy [1] 的含义。
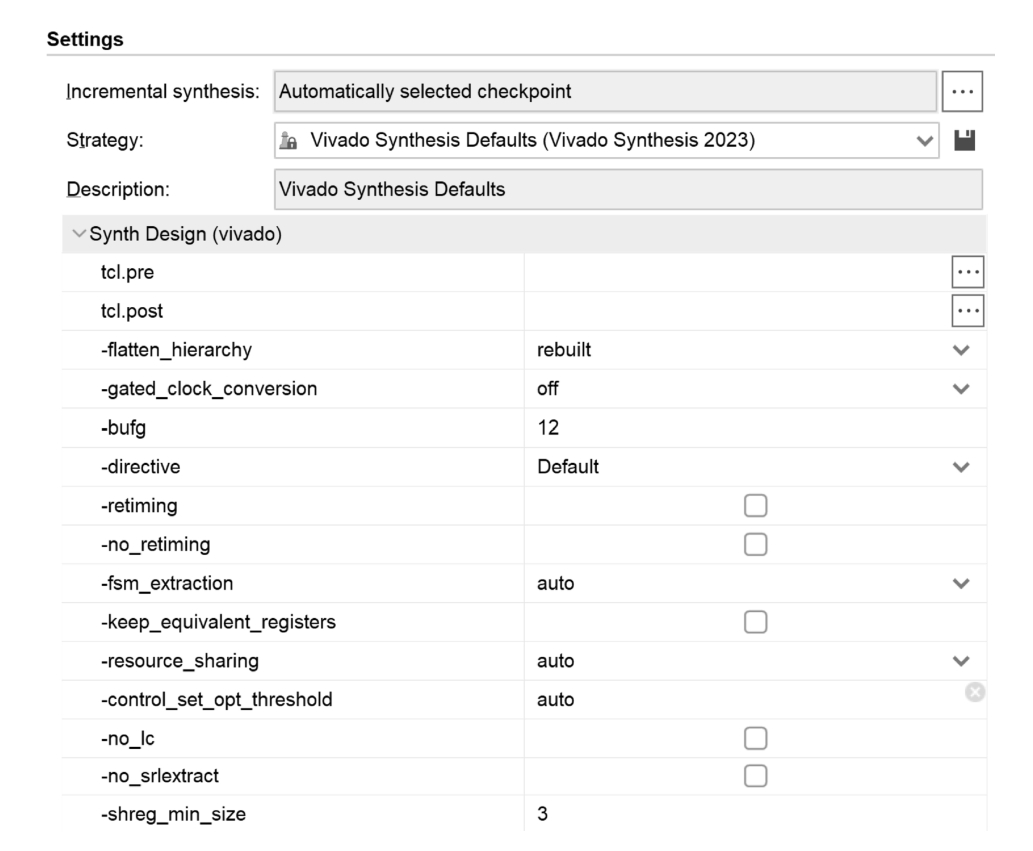
图2.1 综合选项窗口
-flatten_hierarchy有3个可选值,每个值的具体含义如表2.1所示。为了进一步解释,这里以Vivado自带的例子工程Wavegen为例。在其他综合选项保持默认的情形下,创建3个Design runs:synth_1、synth_2和synth_3。三者的区别只是-flatten_hierarchy取值不同。
表2.1 -flatten_hierarchy的3个可选值

原始RTL代码层次如图2.2所示,三者综合后的网表层次如图2.3所示。结合表2.1,不难理解图2.3所示结果。
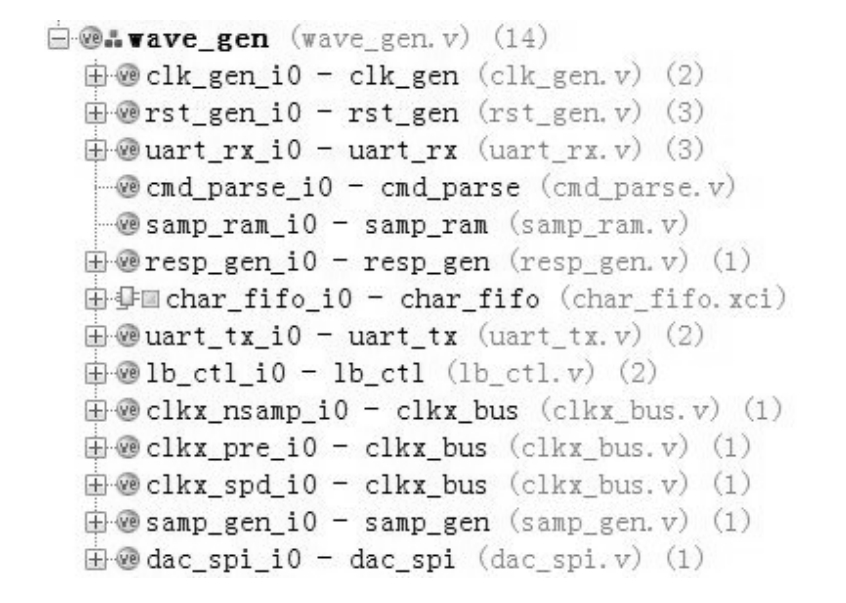
图2.2 原始RTL代码层次
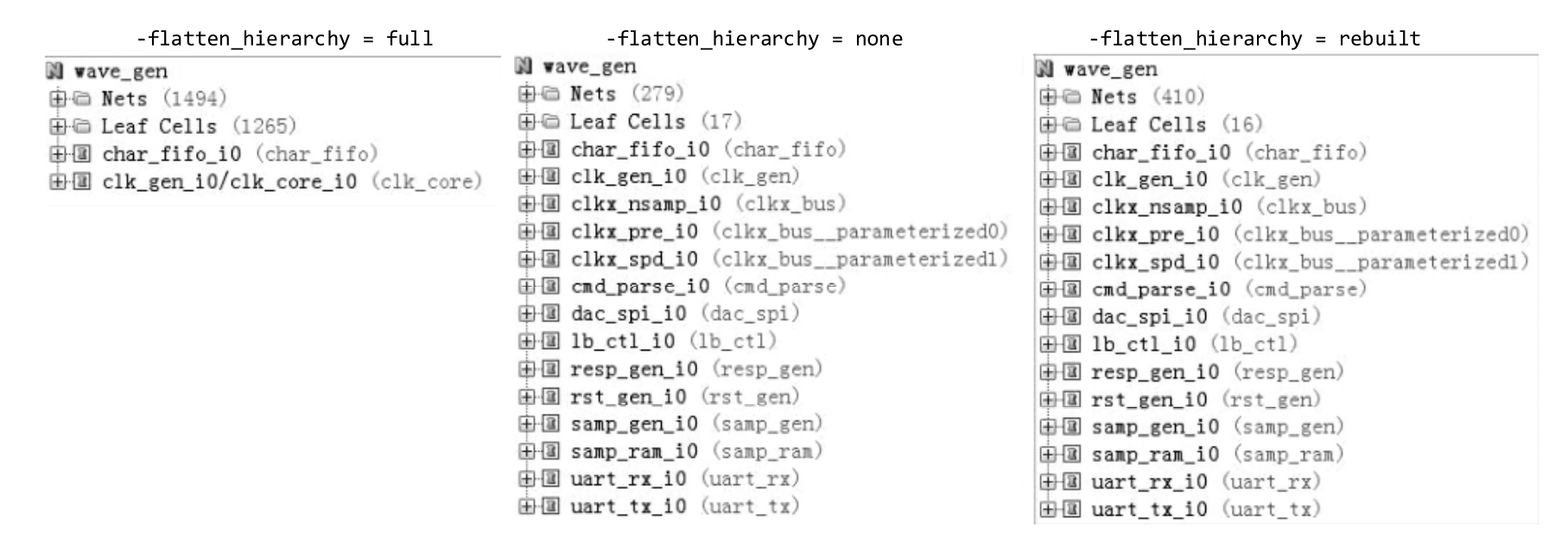
图2.3 -flatten_hierarchy为不同值时综合后的网表层次
从综合后的资源利用率报告来看(如图2.4所示),当-flatten_hierarchy为none时消耗的寄存器最多。
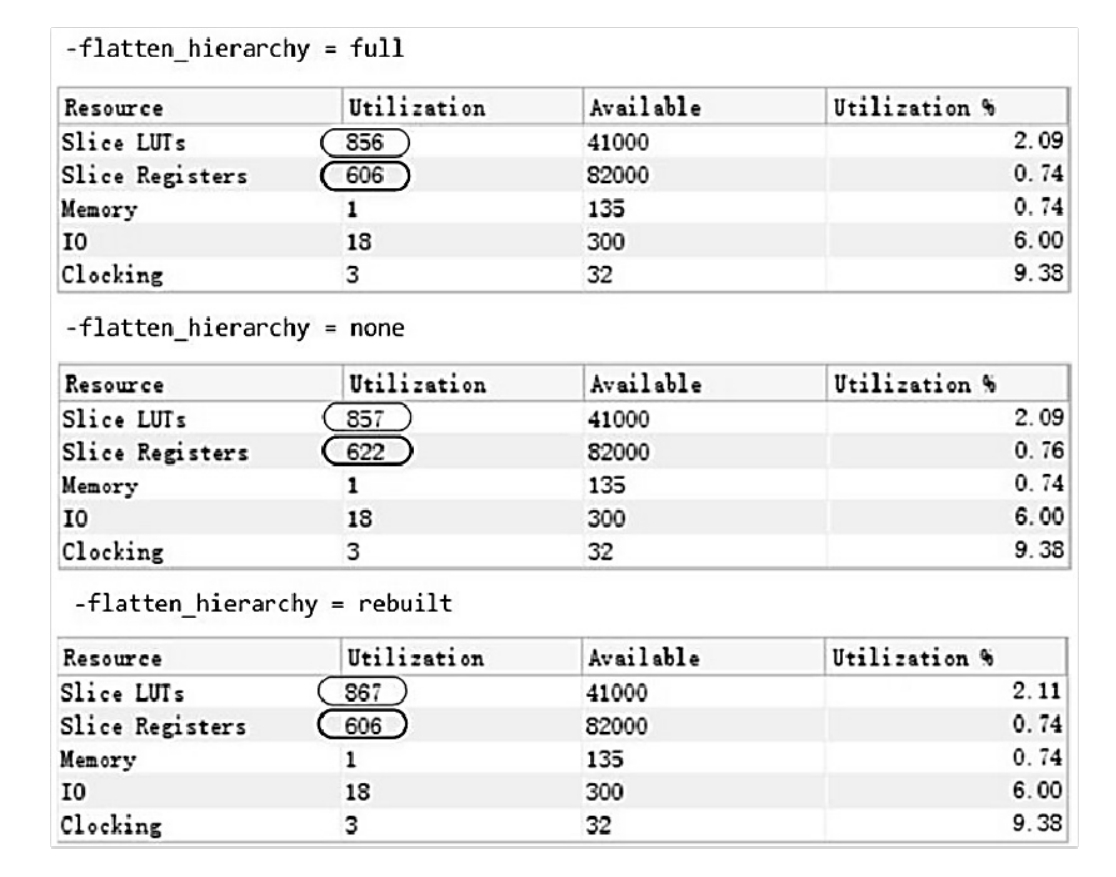
图2.4 -flatten_hierarchy为不同值时的资源利用率
此外,观察uart_rx下的模块meta_harden,其综合结果如图2.5所示。可以看到,meta_harden内部的signal_dst是一个同步复位D触发器。当-flatten_hierarchy为none时,signal_dst端口名保持不变;而当-flatten_hierarchy为rebuilt时,则在原有端口名称后添加_reg作为后缀。这也是Vivado对寄存器命名的一个特征,理解这个特征便于寻找网线(net)。当-flatten_hierarchy为full时,利用get_pins命令则无法找到该引脚,利用get_nets命令尽管可以找到类似名称的网线,但并非uart_rx模块下的网线,如图2.6所示。
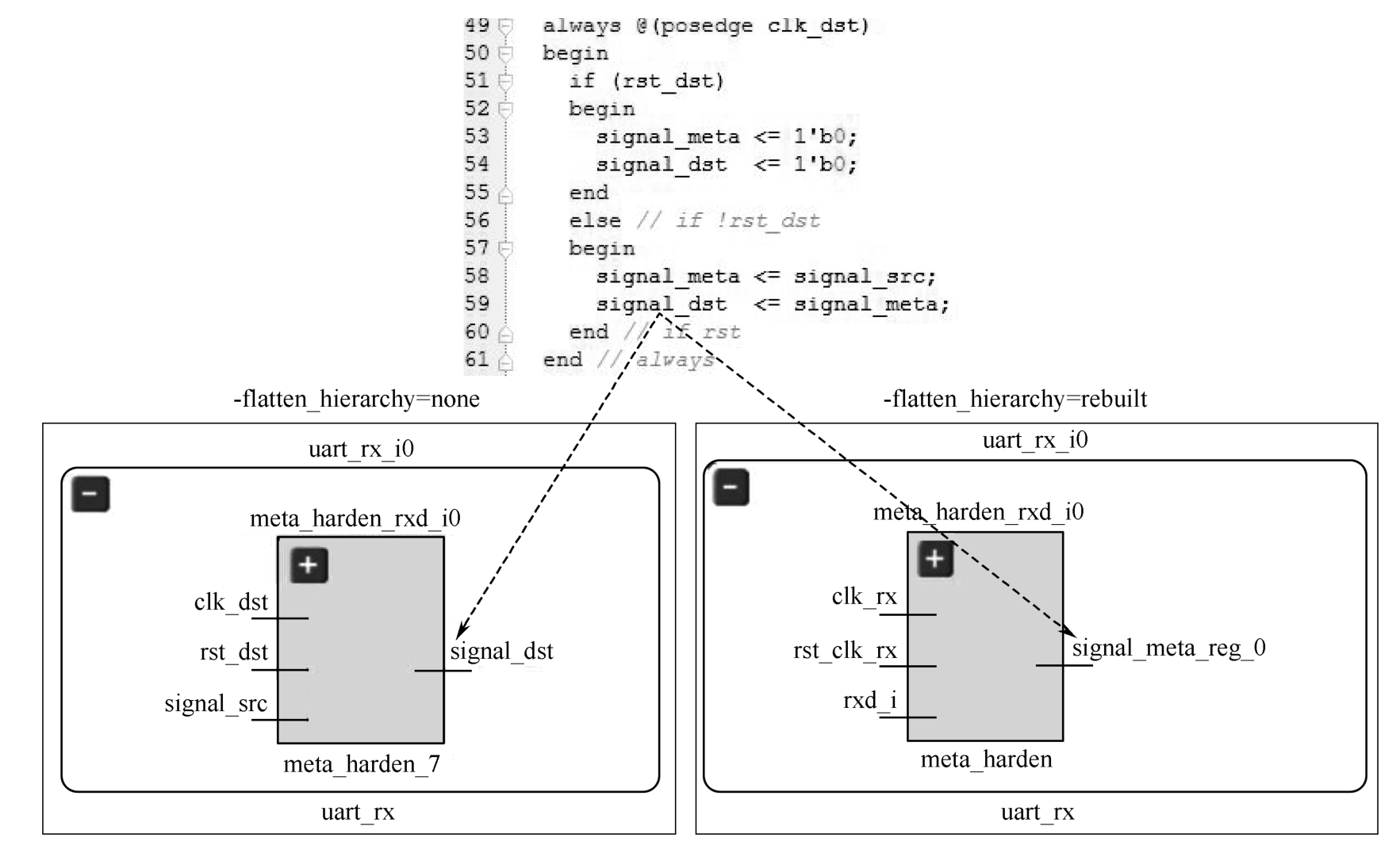
图2.5 -flatten_hierarchy为none和rebuilt时对寄存器输出端口名的影响

图2.6 -flatten_hierarchy为full时对寄存器输出端口名的影响
-flatten_hierarchy是一个全局的综合指导原则,即它对整个工程的所有模块都起作用。如果需要对指定模块的层次化进行管理,就需要用到keep_hierarchy综合属性了。仍以Wavegen工程为例,在uart_rx模块中添加该属性,如图2.7所示。-flatten_hierarchy设定为full,综合前后的层次对比如图2.8所示。可以看到,uart_rx被保留,但其内部依然被打平。
图2.7 添加keep_hierarchy属性
通常情况下,建议将-flatten_hierarchy设定为默认值rebuilt。

图2.8 uart_rx模块综合前后的层次对比
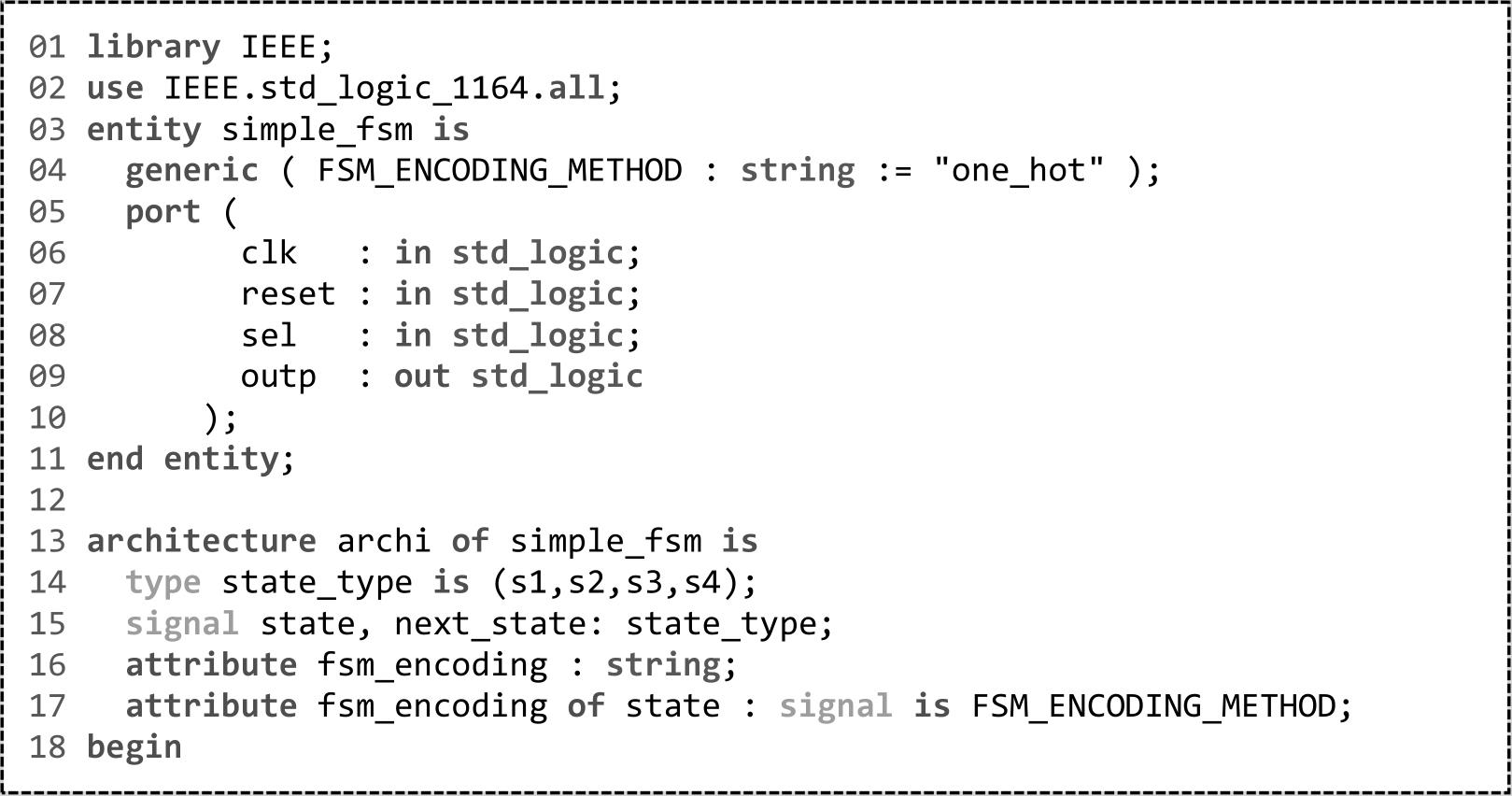
-fsm_extraction用于设定状态机的编码方式,默认值为auto,此时Vivado会自行决定最佳的编码方式。
仍以Vivado自带的例子工程Wavegen为例,该工程的cmd_parse模块中包含一个状态机。当-fsm_extraction为auto时,综合后在log窗口中搜索encoding,结果如图2.9所示,可见此时状态机编码方式为sequential,之所以会显示Previous Encoding,是因为cmd_parse模块本身已经设定了编码方式,如图2.10所示。
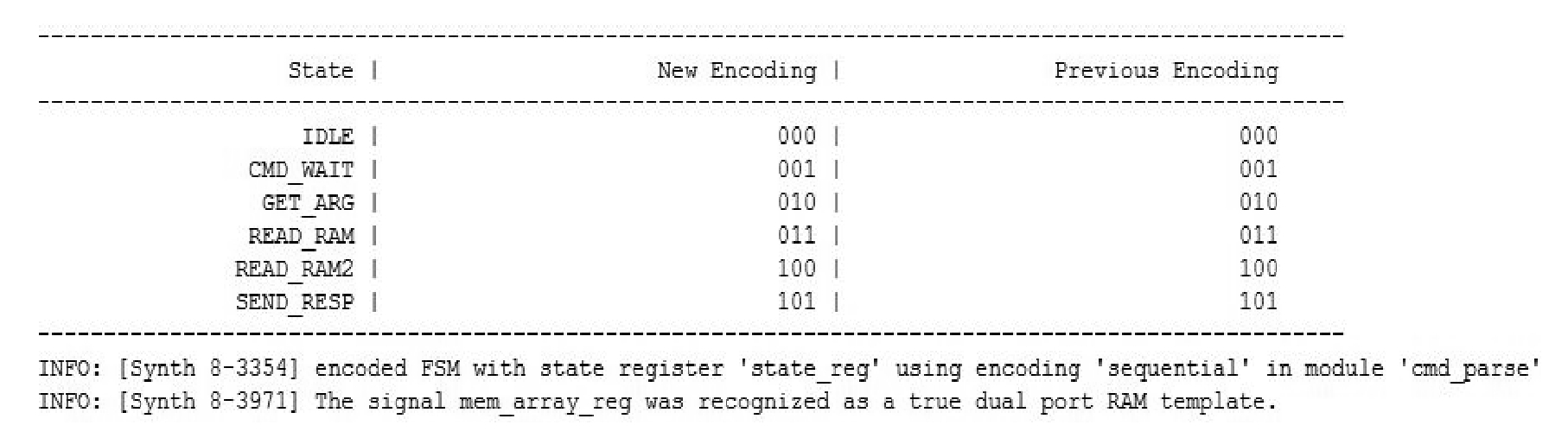
图2.9 -fsm_extraction为auto时状态机的编码方式

图2.10 cmd_parse模块自带的状态机编码方式
但是,当-fsm_extraction设定为one-hot时,综合后的结果如图2.11所示,可见此时-fsm_extraction设定的编码方式高于HDL代码内部定义的编码方式。
与-fsm_extraction具有同样功能的综合属性是fsm_encoding,它可以在HDL代码中针对某个状态机设定编码方式,其优先级高于-fsm_extraction,但是如果代码本身已经定义了编码方式(如图2.10所示),则fsm_encoding设定的编码方式将无效。
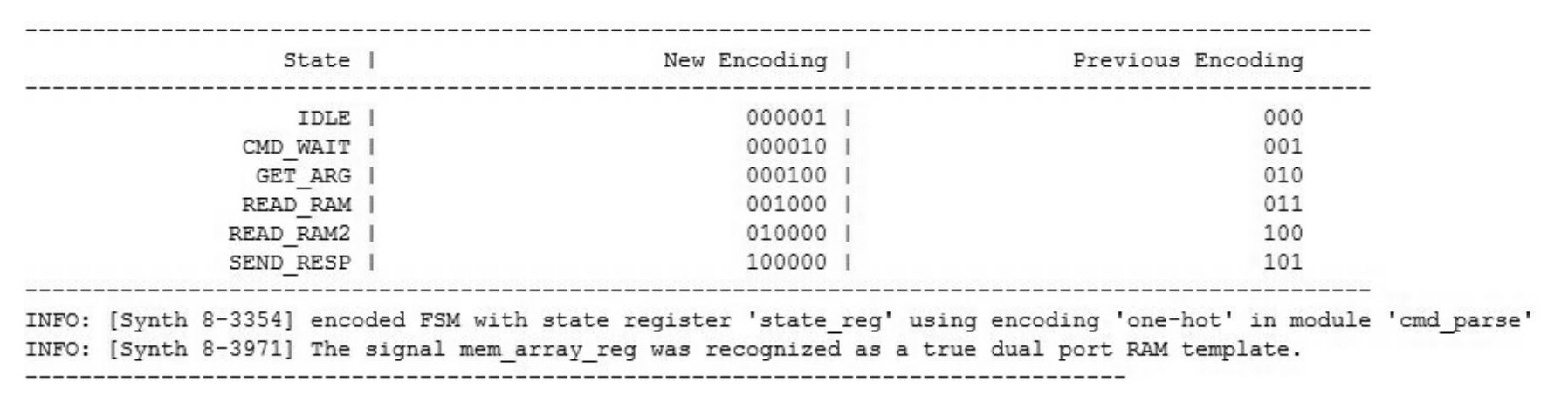
图2.11 -fsm_extraction为one-hot时状态机的编码方式
通常情况下,-fsm_extraction设定为auto即可满足设计需求,如果需要对某个状态机指定编码方式,可以采用VHDL代码2.1所示的方式,通过对fsm_encoding的参数化处理实现代码的高效维护和管理并增强代码的可读性。
所谓等效寄存器(Equivalent Registers),是指具有同源的寄存器,即共享输入数据的寄存器,如VHDL代码2.2中的opa_rx和opa_ry。
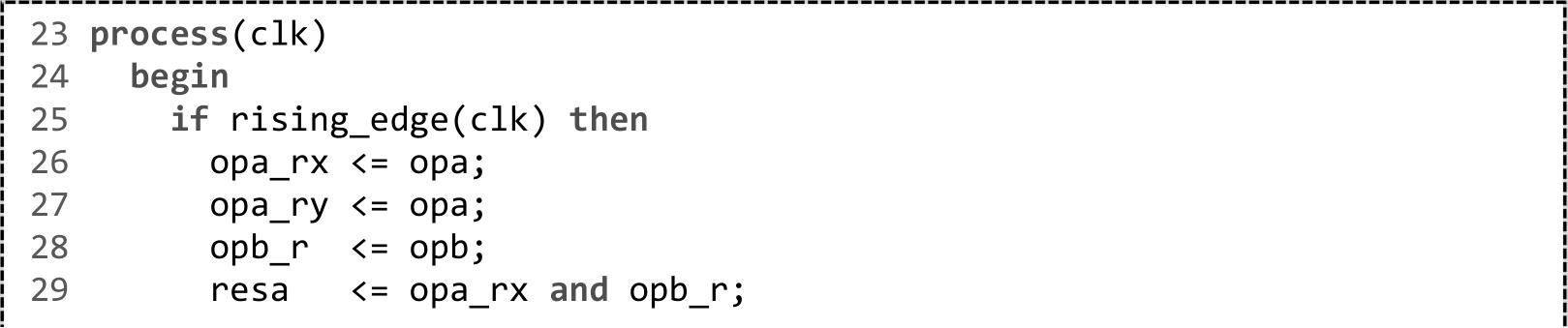

当-keep_equivalent_registers没有被勾选即等效寄存器被合并时,VHDL代码2.2的综合结果如图2.12所示,否则如图2.13所示。从这个例子可以看出,等效寄存器可以有效降低扇出。
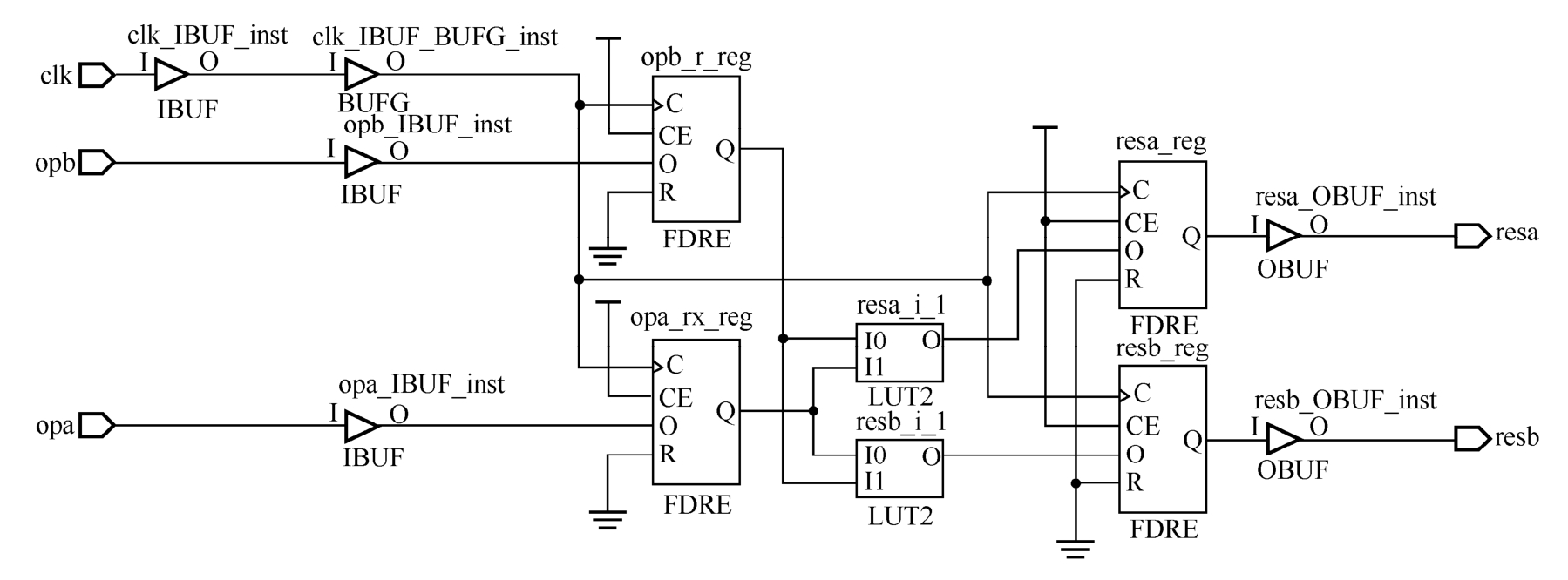
图2.12 -keep_equivalent_registers没有被勾选时的综合结果
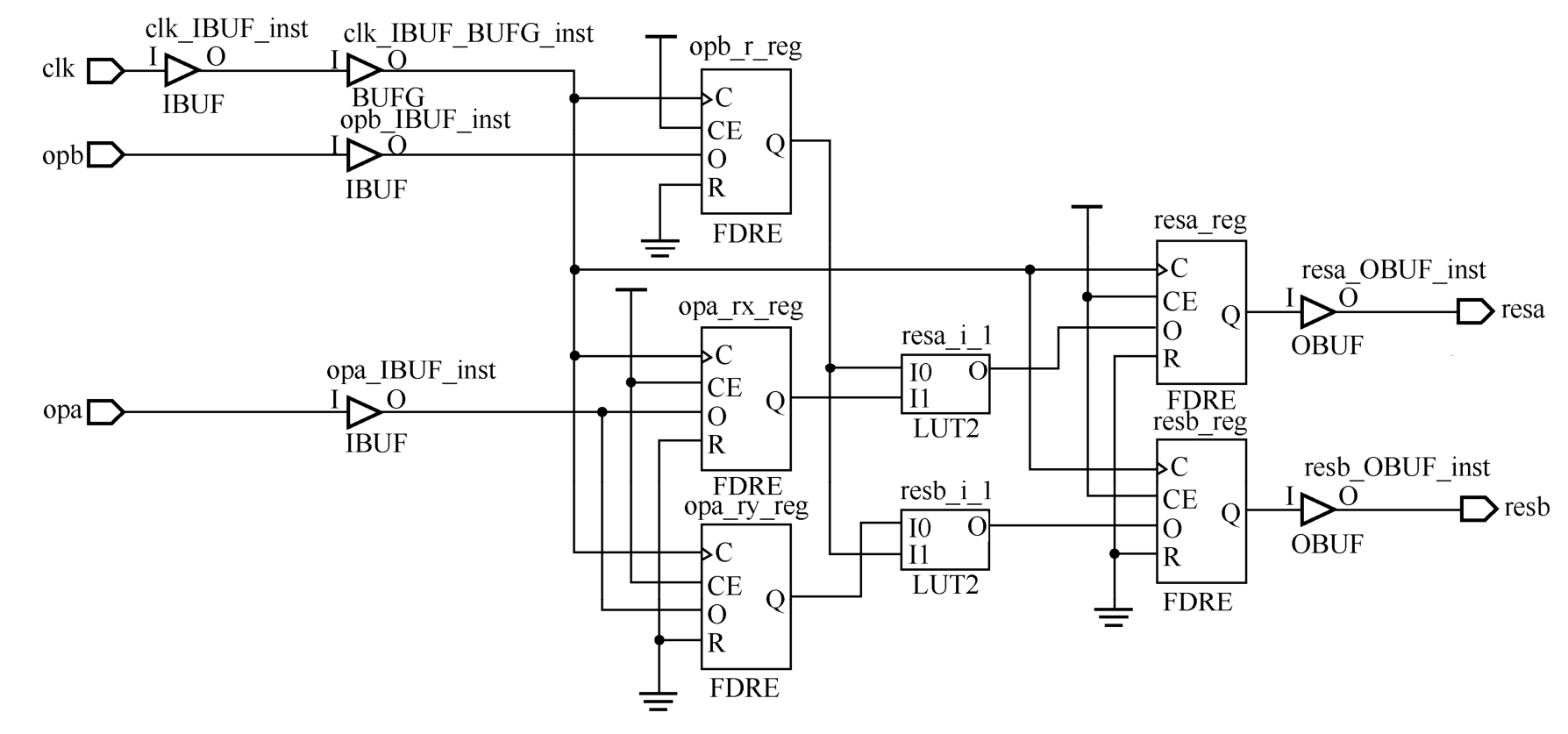
图2.13 -keep_equivalent_registers被勾选时的综合结果
此外,对于等效寄存器还可以通过设置综合属性keep避免其被合并,如VHDL代码2.3所示,这里IS_KEEP为true。


-resource_sharing的作用是对算术运算通过资源共享优化设计资源,它有3个值,即auto、off和on。默认值为auto,此时会根据设计时序需求确定是否进行资源共享。
以加法运算为例,VHDL代码2.4显示了利用资源共享降低资源利用率。代码中resize函数的作用是对操作数进行符号位扩展,防止溢出。-resource_sharing分别为on和off时的资源利用率如图2.14所示,显然,资源共享降低了资源利用率。资源共享的原理如图2.15所示。


图2.14 -resource_sharing分别为on和off时的资源利用率
此外,对于VHDL代码2.5所示的乘法运算也可以通过-resource_sharing控制资源共享。
触发器的控制集由时钟信号、复位/置位信号和使能信号构成,通常只有{clk,set/rst,ce}均相同的触发器才可以被放置在一个SLICE中。但是,对于同步置位、同步复位和同步使能信号,Vivado会根据-control_set_opt_threshold的设置进行优化,其目的是减少控制集的个数。优化的方法如图2.16所示。在优化之前,3个触发器被分别放置在3个SLICE中,而优化后,被放置在一个SLICE中,但此时需占用查找表资源。
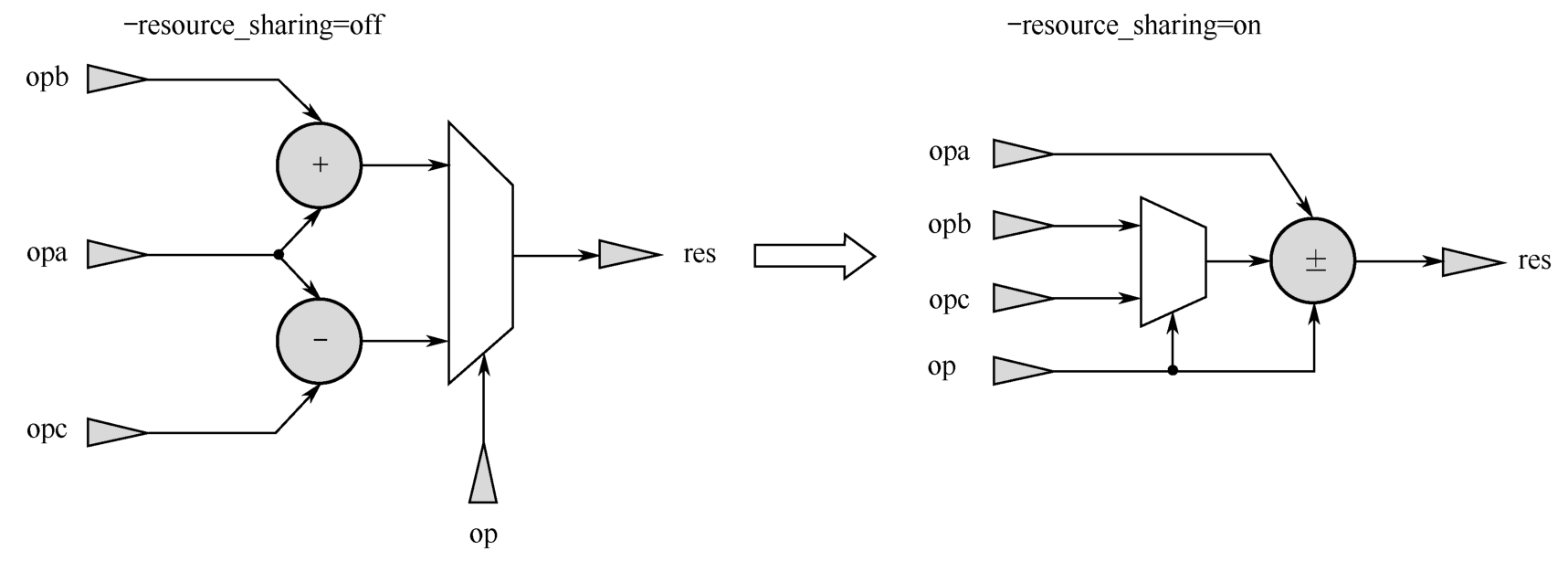
图2.15 资源共享的原理

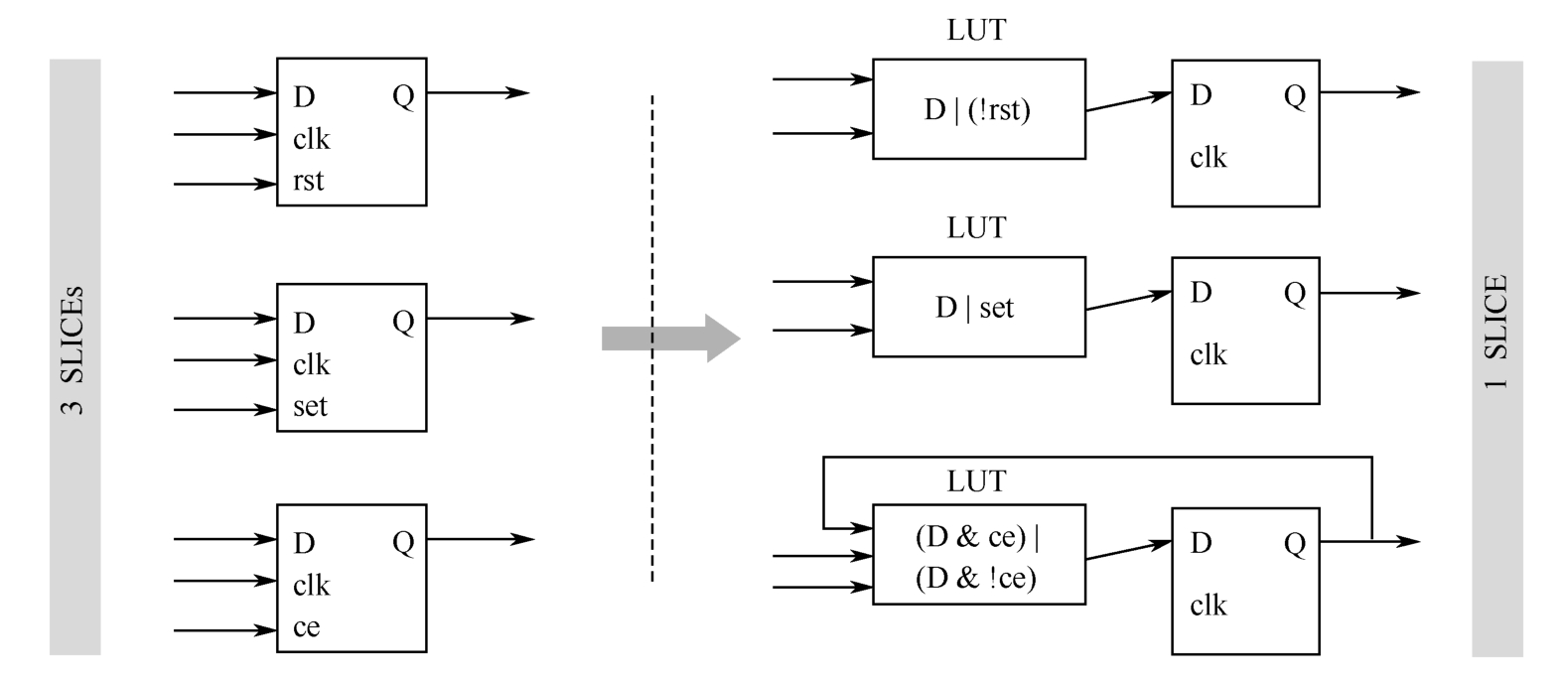
图2.16 控制集优化方法
-control_set_opt_threshold的值为控制信号(不包括时钟)的扇出个数,表明对小于此值的同步信号进行优化。显然,此值越大,被优化的触发器就越多,但占用的查找表也越多。若此值为0,则不进行优化。通常情况下,按默认值auto运行即可。
对于VHDL代码2.6所示的同步复位寄存器,-control_set_opt_threshold取auto和0时的综合结果如图2.17所示。
在设计初期就应尽可能地减少控制集,否则可能会出现触发器消耗不多但SLICE的占用率却很高的情形。

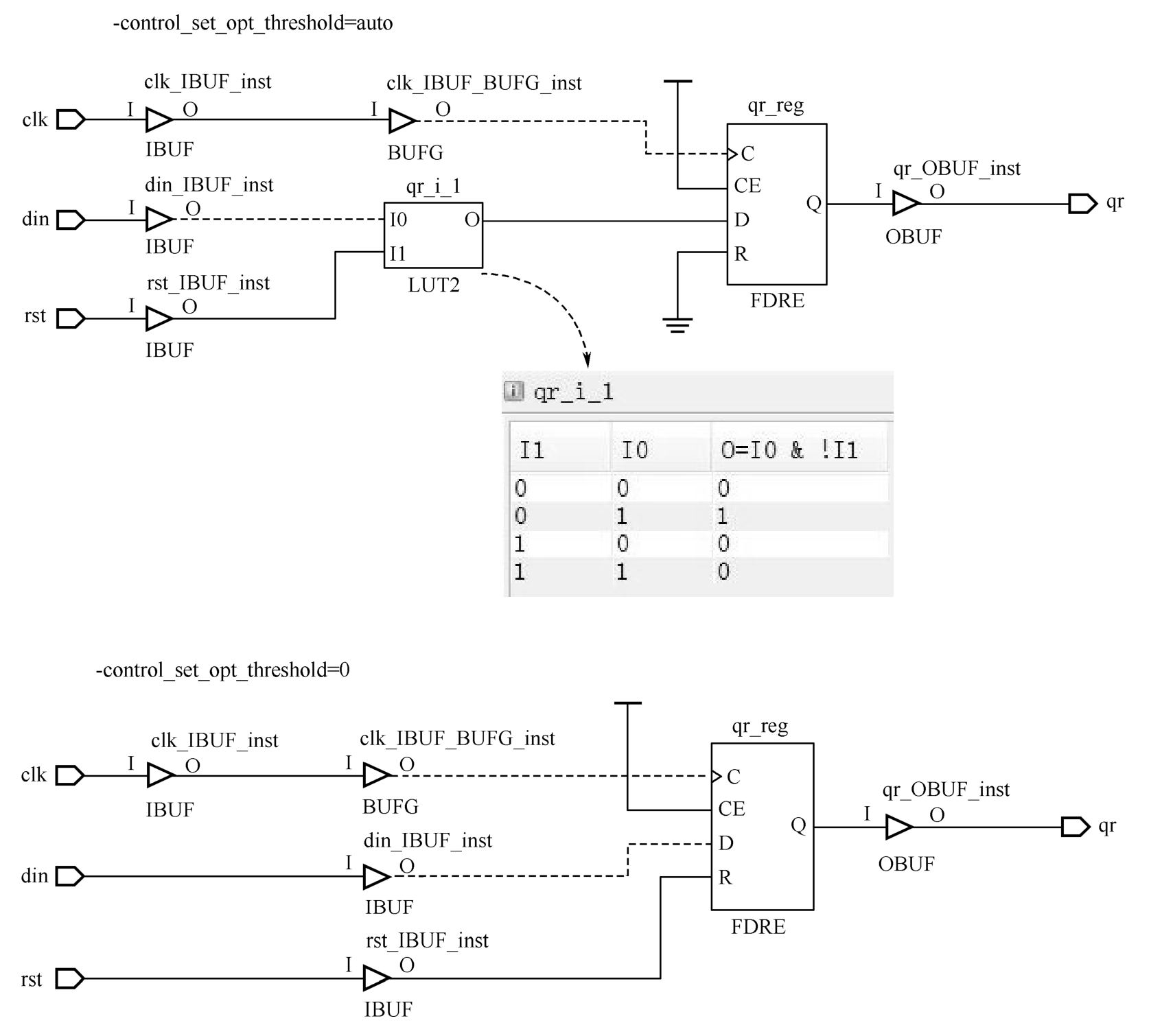
图2.17 -control_set_opt_threshold取auto和0时对同步复位寄存器的影响
在第1章已阐述了Xilinx FPGA内部LUT6的结构,正是这种结构决定了对于一个 x 输入布尔表达式和一个 y 输入布尔表达式,只要满足 x + y ≤5(相同变量只算一次),两个布尔表达式就可以放置在一个LUT6中实现,此时A6=1,运算结果分别由O6和O5输出。
默认情况下,当存在共享变量时,Vivado会自动把这两个布尔表达式放在一个LUT6中实现,称为LUT整合(LUT Combining);否则,仍占用两个LUT6分别实现每个布尔表达式。但是,当-no_lc(No LUT Combining)被勾选时,则不允许出现LUT整合。
如VHDL代码2.7所示,在默认情况下会占用一个LUT6,即采用了LUT整合。在综合后的资源利用率报告中会显示消耗了一个LUT6。在实现后的报告中,选择图2.18中的using O5 and O6可查看整合的LUT6个数。

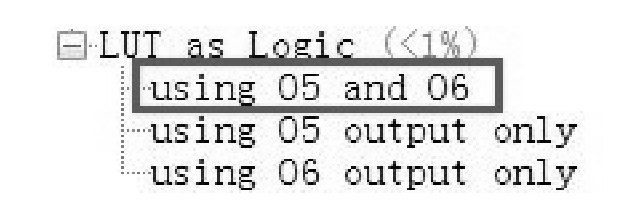
图2.18 在实现后的资源利用率报告中查看整合的LUT6个数
通过LUT整合虽然可以降低LUT的资源消耗率,但是也可能导致布线拥塞。因此,Xilinx建议,当整合的LUT超过LUT总量的15%时,应考虑勾选-no_lc,关掉LUT整合。
在第1章已阐述了SLICEM中的LUT可以用来实现移位寄存器。-shreg_min_size决定了当VHDL代码2.8所示的移位寄存器的深度大于此设定值时,将采用“触发器+SRL+触发器”的方式实现,其中SRL由LUT实现。例如,当DEPTH=5时,综合后的结果如图2.19所示。
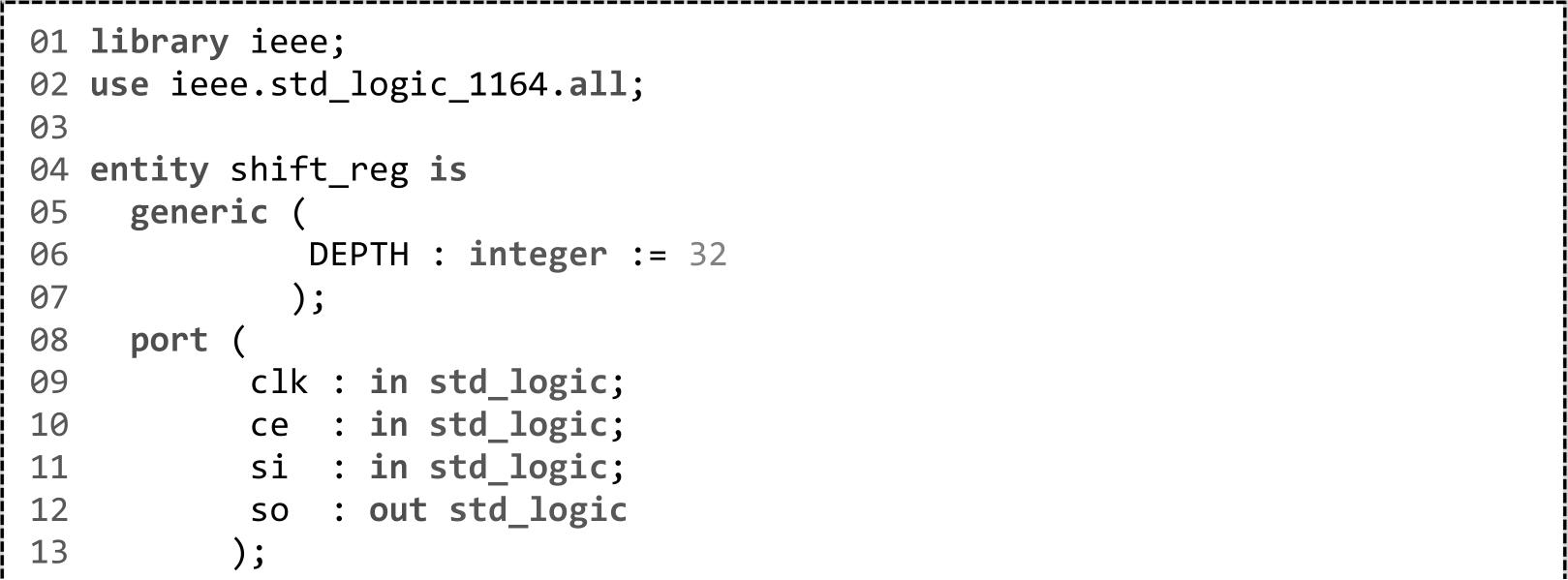

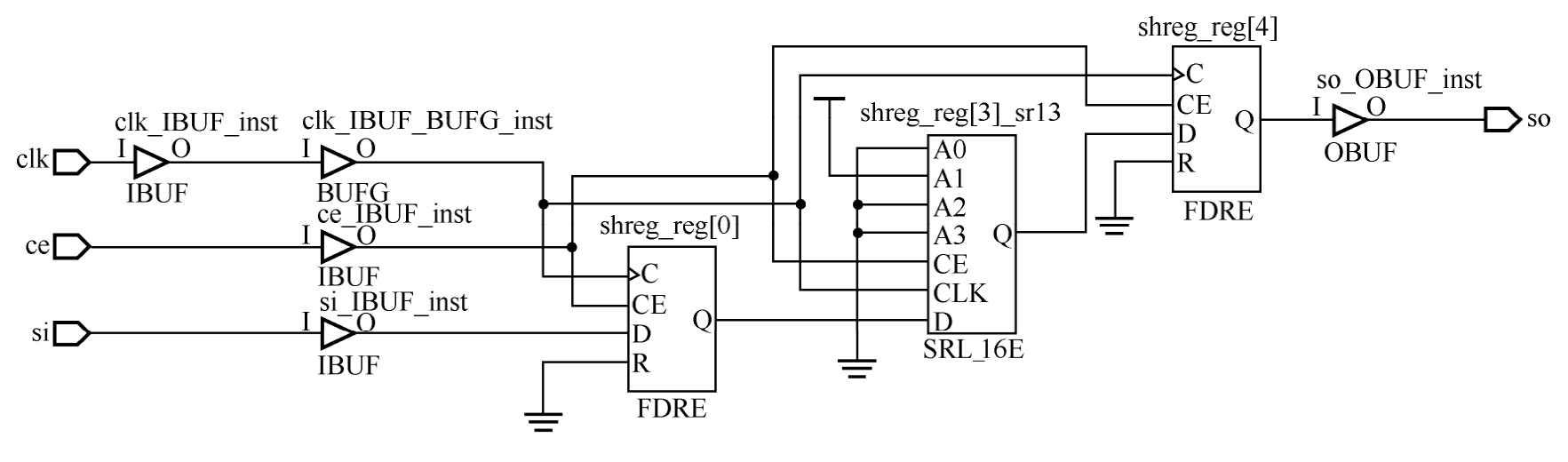
图2.19 深度为5的移位寄存器综合后的结果
在综合属性中,shreg_extract可用于指导综合工具是否将移位寄存器推断为SRL。作为局部的综合指导命令,其优先级高于-shreg_min_size。例如,当-shreg_min_size为3、shreg_extract为no时,对于深度为5的寄存器,综合的结果将是5个寄存器级联。
此外,综合属性srl_style可指导综合工具如何处理移位寄存器。它的6个可取值及对应的综合结果如图2.20所示。srl_style的优先级虽高于-shreg_min_size,低于shreg_extract,但srl_style不必与shreg_extract联合使用。
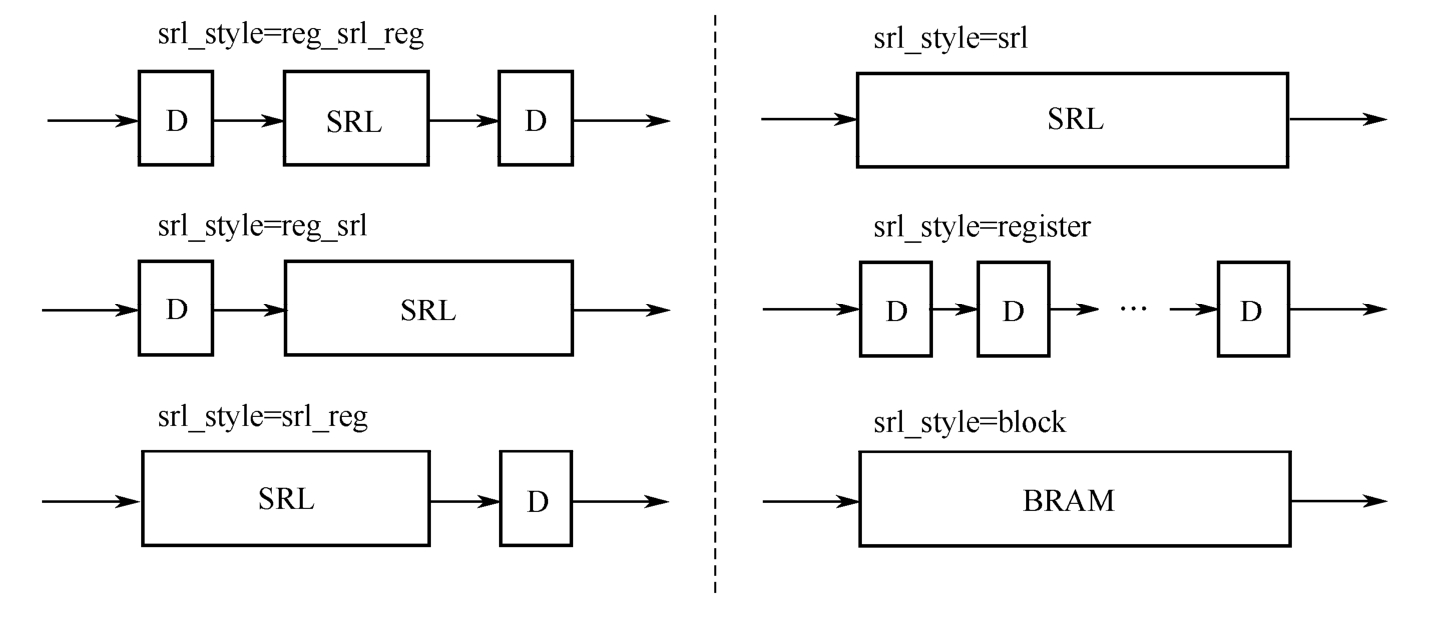
图2.20 srl_style的6个可取值及对应的综合结果
在工程应用中,可将srl_style参数化以提高代码的可读性和可维护性,如VHDL代码2.9所示。
