
下载掌阅APP,畅读海量书库
立即打开



前面我们已经了解到KBQA主要由两种技术手段实现,其中语义解析技术指的是将自然语言问题转化为SPARQL语言的技术,简称为NL2SPARQL技术。这里将进一步介绍SPARQL语言以及它在KBQA中的重要性。
SPARQL是一种为RDF数据模型定义的查询语言和数据获取协议。SPARQL可以用于任何以RDF来表示的信息资源,它可以查询和更新RDF数据,非常适用于语义网络和知识图谱的查询与分析。
在KBQA中,SPARQL语言主要用于查询知识图谱中的数据,并根据用户提出的问题返回相应的答案。与NL2SQL中查询表结构的SQL相同,SPARQL在KBQA中的地位同样重要。使用SPARQL可以有效地从知识图谱中获取相关的信息,并且可以通过多种方式对查询结果进行分析和可视化,从而实现高效和精确的问答系统。
我们以2021年CCKS(全国知识图谱与计算语义大会)知识图谱问答竞赛的数据为例来介绍KBQA的任务。例如输入一个自然语言问句,如图1-12所示。
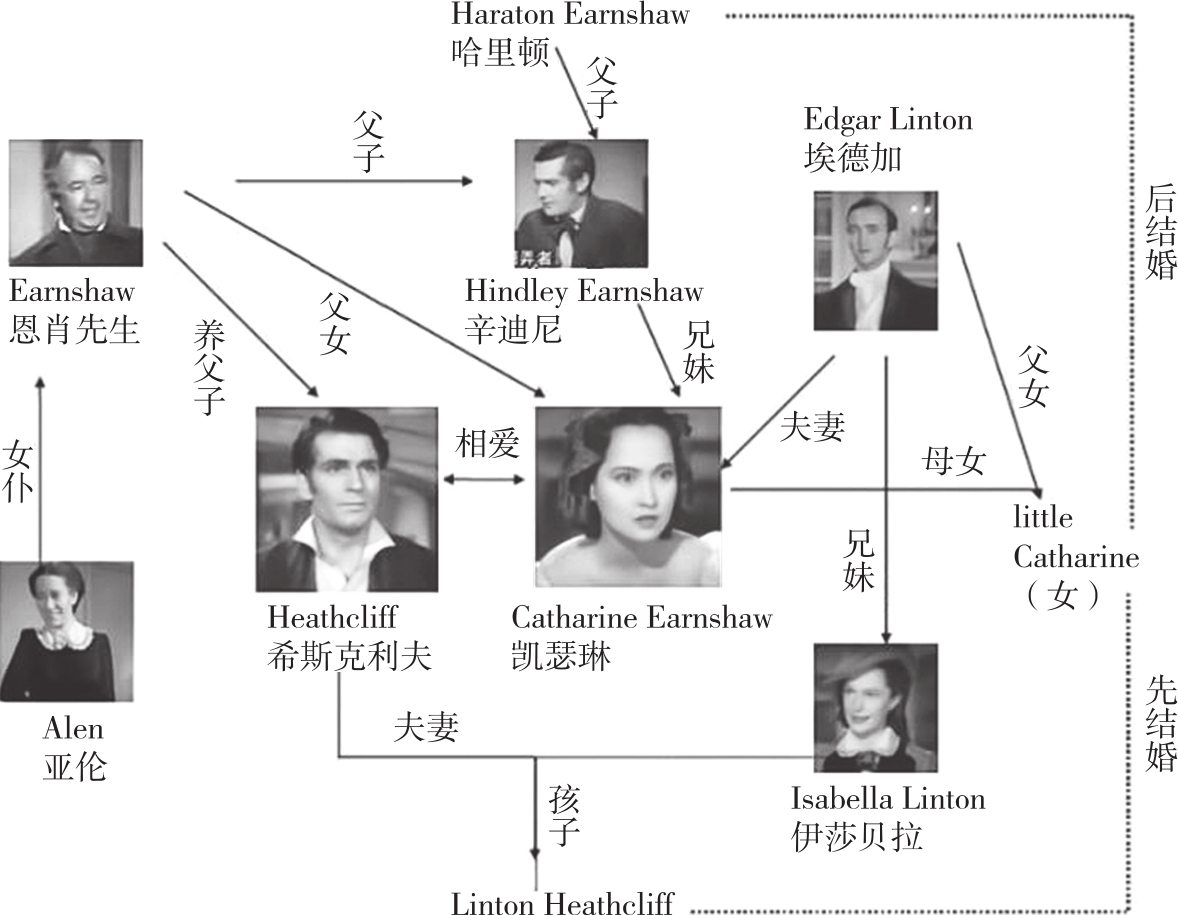
图1-12 《呼啸山庄》的人物关系图
如果输入一个自然语言问句问“希斯克利夫的妻子是谁”,我们需要根据知识图谱中的希斯克利夫节点所在的位置找到对应的边(即夫妻)所连接的节点来得到答案:伊莎贝拉。同样,在CCKS的KBQA赛道训练数据时,如果提问是“莫妮卡·贝鲁奇的代表作是什么?”,我们可以用对应的SPARQL语句来查询:

查询到该问题的答案是《西西里的美丽传说》。
这里简单解释一下上面的SPARQL:“?x”表示一个变量,括号中为一个三元组,“select ?x”表示该查询所返回的就是后面三元组中“?x”所在位置的实体。
当然,以上问题只涉及一个实体和一个关系,实际上SPARQL要解决的问题有很多比这个示例复杂得多,还是以CCKS数据集为例。
问题 :武汉大学出了哪些科学家?
对应的查询语句如下:

答案 :"<郭传杰><张贻明><刘西尧><石正丽><王小村>"。
注意,答案中的括号和引号也是存储在知识图谱中的,所以输出的答案保留了与知识图谱中相同的保存方式。
问题 :凯文·杜兰特得过哪些奖?
对应的查询语句如下:

答案 :""7次全明星(2010-2016)5次NBA最佳阵容(2010-2014)NBA得分王(2010-2012;2014)NBA全明星赛MVP(2012)NBA常规赛MVP(2014)"。
问题 :获得性免疫缺陷综合征涉及哪些症状?
对应的查询语句如下:
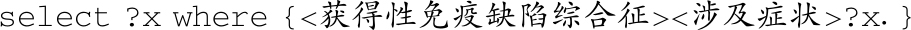
答案 :"<淋巴结肿大><HIV感染><脾肿大><心力衰竭><肾源性水肿><抑郁><心源性呼吸困难><低蛋白血症><不明原因发热><免疫缺陷><高凝状态><右下腹痛伴呕吐>"。
问题 :詹妮弗·安妮斯顿出演了一部1994年上映的美国情景剧,这部美剧共有多少集?
对应的查询语句如下:

答案 :236。
为了便于使用机器学习技术进行建模,需要对问题进行拆解以实现各个击破。根据所涉及的实体个数和查询所要经过的步数,我们将CCKS的数据集中的问题分为如图1-13所示的几个类型。
图1-13中的 E 表示实体, A 表示答案, P 表示关系, M 表示查询路径中要经过的实体节点。
另外,CCKS的KBQA数据集在2021年发布的时候还增加了filter、order等函数。我们根据数据集总结了该任务中出现的一些新类型的SPARQL语句:
1)特殊类型1:含有filter。
问题 :在北京,神玉艺术馆附近5公里的景点都有什么?
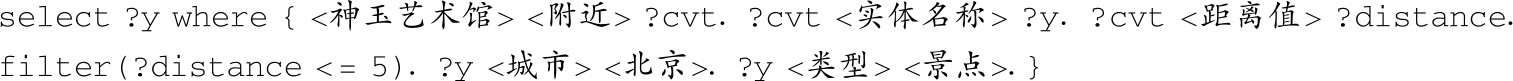
2)特殊类型2:含有count。
问题 :皇冠假日品牌的酒店在天津有几个?
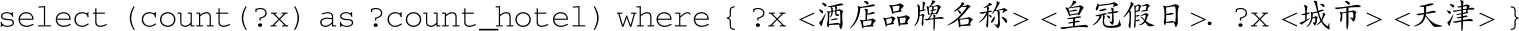
特殊类型3:含有max。
问题 :北京丽晶酒店的最大房型最多可以住几个人?
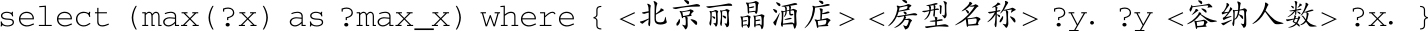
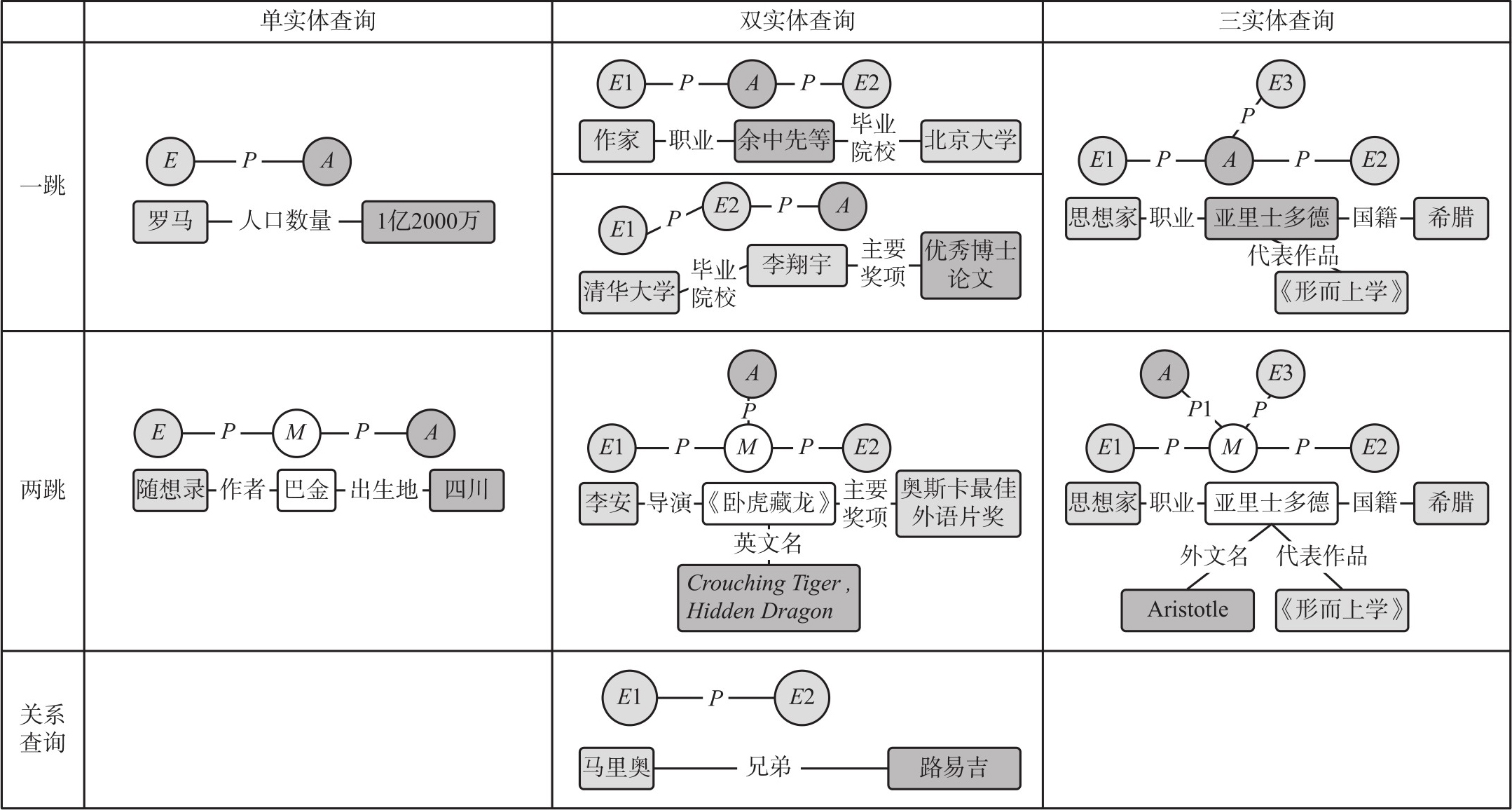
图1-13 实体查询类型
特殊类型4:含有filter和avg。
问题 :景山公园附近5公里的酒店的平均价格是多少?

特殊类型5:含有多个filter。
问题 :景山公园附近2公里且价格低于1000元的北京酒店有哪些?
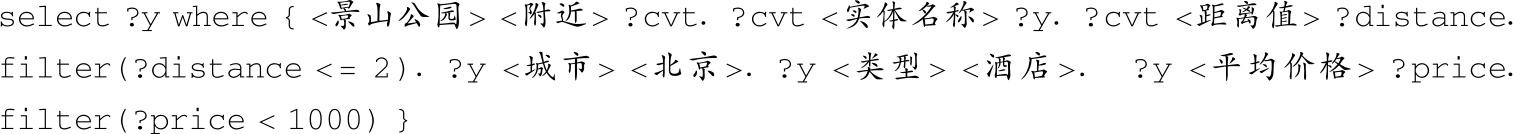
特殊类型6:含有filter和order。
问题 :距离故宫5000米内最便宜的酒店是多少钱?
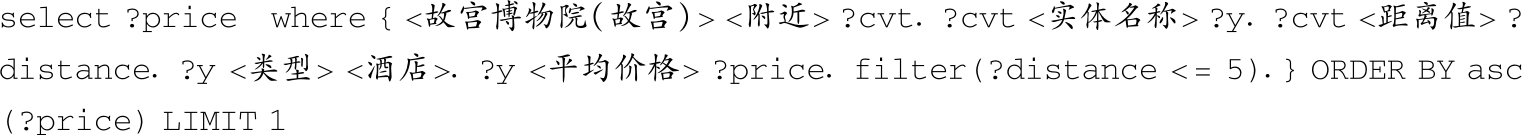
该任务的复杂和难点不仅在于数据集中各种类型的问题和对应的SPARQL语句,还表现在以下几个方面。
1)知识图谱量级巨大。官方给出的知识图谱三元组超过6000万个,实体关系数量都是千万级,关系数超过10万的超级节点多,使得检索和召回复杂度高。
2)知识图谱噪声实体多。知识图谱中有很多无效的实体(没有真实语义但与真正有意义的实体在字符上十分类似),使得定位实体的难度增加。
3)完成CCKS中的KBQA任务需要构建多个复杂的算法任务,并且任务之间的结果相互依赖,从而导致误差扩散且难以定位。
4)自然语言问法变化多。对于同一问题,在自然语言上的句式变化非常多,机器难以理解中文的博大精深。因此,可能会出现训练集训练过的问题因表达方式不同模型不能识别的情况。
研究者提出了一系列方法来完成KBQA任务。主要的方法有3个:排序方法(属于信息检索方法)、从粗到细的方法和生成方法。虽然各种方法的思路不同,但所有的方法基本都采用知识图谱的结构来约束其模型的输出空间。
(1)排序方法
排序方法将KBQA分解为两个子任务:查询候选枚举和语义匹配。查询候选枚举任务是通过直接列出来自知识图谱的真实查询并构建一个查询的候选集合实现的。语义匹配的目标是返回每个问题和候选查询的数据对的匹配分数,通常被建模为机器学习任务。
例如要回答“孙悟空的师父是谁”。第一步要将孙悟空这个实体所涉及的所有关系和关系连接的实体节点都枚举出来,形成一个列表,如表1-4所示。
第二步是将表1-4中的所有路径都和原问题进行语义匹配度计算,系统计算得出第一行中的内容和问题语义表征层面最为接近,从而根据第一行路径查到答案“唐僧”。
表1-4 孙悟空关系列表

(2)从粗到细的方法
从粗到细的方法是首先生成查询的骨架,然后结合知识图谱的信息,将查询的骨架中的实体和关系链接到知识图谱中的真实实体和关系,从而形成真实查询语句得到答案。该方法将语义解析分解为两个阶段。首先,模型只预测一个粗略的查询骨架,它重点关注高级结构(进行粗粒度的解析)。其次,模型通过将查询骨架中的实体和关系解析出来,采用实体链接和关系排序的方式找到其对应的真实实体和关系,并用其替换原骨架中的实体和关系,从而形成真实的查询路径,查到答案。
比如,问题“获得性免疫缺陷综合征涉及哪些症状?”对应的SPARQL语句是:
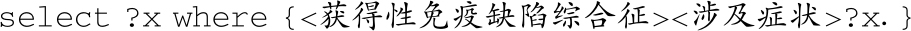
对应的骨架是不包括实体和关系的伪SPARQL语句:
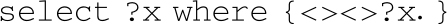
第一步生成了查询骨架之后,通过实体识别模型将原来问题中的实体“获得性免疫缺陷综合征”识别出来并填入SPARQL语句中,然后对主要实体“获得性免疫缺陷综合征”的所有关系进行语义匹配排序,得到关系“涉及症状”,并填入关系所在的位置,得到最终的SPARQL语句查询出答案。
(3)生成方法
生成方法是一种建模字符串到字符串的常用方法,用于解决KBQA任务中的语义解析问题。通常,这种方法通过约束解码的方式对知识图谱进行查询,从而动态地减少搜索空间。由于其灵活性和可伸缩性,生成方法已经成为当前很多语义解析任务的首选,因此有成为KBQA解决方案的趋势。
在使用生成方法时,尤其需要注意解决一个问题,即在生成解码的过程中时刻参考知识图谱的结构和内容,不断地对生成的表达式进行实体、关系、结构上的修正。这一过程需要根据知识图谱的具体情况进行调整和优化,从而提高解析的准确率和效率。
在后续章节中,我们将以CCKS参赛获奖方案为例,介绍这种方法的具体操作。通过实例的展示,我们可以更加深入地理解生成方法,并且了解在实际中如何有效地应用该方法。