
下载掌阅APP,畅读海量书库
立即打开



随着数据量的增长,对数据的访问开始变得越来越慢。要想从一个充满信息的大的数据表中准确地检索出合适的数据,需要执行更多的内部操作来定位这些数据。
 虽然我们讨论的是与关系数据库有关的数据索引问题,但大部分的基本原理都适用于其他类型的数据库。
虽然我们讨论的是与关系数据库有关的数据索引问题,但大部分的基本原理都适用于其他类型的数据库。
以一种易于搜索的方式巧妙地组织数据,可以大大加快这一定位过程。所以要创建数据库的索引,从而能够通过搜索来快速定位数据。索引的基本原理是创建一个外部的有序数据结构,指向数据库中每条记录的一个或多个字段。这个索引结构总是随着表中数据的变化而保持有序。
例如,有个简单的包含了以下信息的数据表。

在没有索引的情况下,要查询哪个条目的Height(高度)值最大,数据库将需要单独检查每条记录并对其进行排序。这个操作称为 全表扫描 (full table scan)。如果表有数以百万计的行,全表扫描的开销会非常大。
通过为Height字段创建索引,一个始终有序的数据结构将与原表数据保持同步。

因为索引表始终保持有序,所以执行任何与高度有关的查询都很容易。例如,要获取前三名的高度,现在不需要做任何Height字段比对操作,只需从索引表中检索前三条记录。要确定180和170之间的高度也很容易,只需到排好序的列表中的对应位置搜索即可,像二进制搜索一样快。再次强调,如果这个索引表不存在,那么找到这些所需数据的唯一方法是检查原始表中的每一条记录。
请注意,这个索引表并未包含所有的字段。例如,Name(姓名)字段就没有索引。别的字段需要其他索引,同一张表可以有多个索引。
 一个表的主键总是有索引的,因为主键的值必须唯一。
一个表的主键总是有索引的,因为主键的值必须唯一。
索引可以组合,即为两个或更多的字段创建一个索引。这些复合索引根据两个字段的有序组合对数据进行排序,例如,复合索引(Name,Height)能够快速返回姓名以J开头的人的高度。而(Height,Name)的复合索引返回的结果则相反,即高度排序在前,然后才对姓名字段进行排序。
在复合索引中可以只对索引的第一部分进行查询。在本例中,(Height,Name)的索引可用于仅查询高度。
检索信息时用或不用索引,是由数据库自动处理的,对SQL查询的操作方式没有影响。在数据库系统内部,执行查询操作之前会先运行查询分析器(query analyzer)。数据库软件此时会决定如何检索数据,以及使用什么索引,如果有的话。
 查询分析器的执行要快才行,因为确定什么是搜索信息的最佳方式,可能比直接运行查询并返回数据需要更长时间。也就是说,查询分析器有时会出错,导致没有使用最佳组合。在下一条SQL语句之前执行EXPLAIN命令,可显示查询操作是如何被解释和执行的,这样可以了解并调整查询操作,以改善其执行效率。请记住,在同一个查询中使用不同的独立索引是不可行的。有时,数据库无法通过组合两个索引来执行更快的查询,因为数据要与索引文件进行关联,而这可能是一个比较耗资源的操作。
查询分析器的执行要快才行,因为确定什么是搜索信息的最佳方式,可能比直接运行查询并返回数据需要更长时间。也就是说,查询分析器有时会出错,导致没有使用最佳组合。在下一条SQL语句之前执行EXPLAIN命令,可显示查询操作是如何被解释和执行的,这样可以了解并调整查询操作,以改善其执行效率。请记住,在同一个查询中使用不同的独立索引是不可行的。有时,数据库无法通过组合两个索引来执行更快的查询,因为数据要与索引文件进行关联,而这可能是一个比较耗资源的操作。
使用索引后查询速度会大幅提高,特别是对于有数千或数百万行的大表来说。索引是自动使用的,所以也不会给查询操作带来额外的负担。那么,如果索引这么好,为什么不对所有的一切都进行索引?实际上,索引也有一些问题:
❍每个索引都需要额外的存储空间。虽然经过优化,但在一个表中添加大量索引会占用更多的空间,无论是在硬盘上还是在内存中。
❍每当表的内容发生变化时,表中的所有索引都需要更新,以确保索引数据始终保持正确排序。这在写入新的数据时更为明显,如添加记录或索引字段数据更新时。索引是在花更多的时间用于数据写入,和加快数据读取速度两者之间所做的一种权衡。对于写入量大的表来说,仅靠这种权衡可能还不够,维护一个或多个索引可能会适得其反。
❍小型数据表并不能真正从索引中受益。如果行数低于数千,全表扫描和基于索引的搜索之间的性能差异很小。
根据经验,最好是在明确需求之后再尝试创建索引。当发现查询操作执行缓慢时,先分析索引是否会改善情况,然后才去创建索引。
衡量每个索引有效性的一个重要特征是其 基数 (cardinality)。它代表着索引数据字段所包含的不同值的数量。
例如,下面这个表中的高度索引的基数是4,因为表中有四个不同的高度值。
像这样的表的高度索引的基数只有2。

基数小意味着索引质量不高,因为它不能像预期的那样加快搜索速度。索引可以被理解为一个过滤器,它可以减少要搜索的行的数量。如果在应用过滤器之后,数据量没有明显减少,那么索引就无法发挥其作用。让我们用一个极端的例子来体会一下。
假设有一个100万行的表,其索引字段在表的所有记录中都有着相同的值。现在,假设我们对该表做一次查询,在另一个未索引的字段中去找某条记录。即便使用了索引,显然也不会加快这个过程,因为索引会返回表中的每一条记录,如图3-11所示。
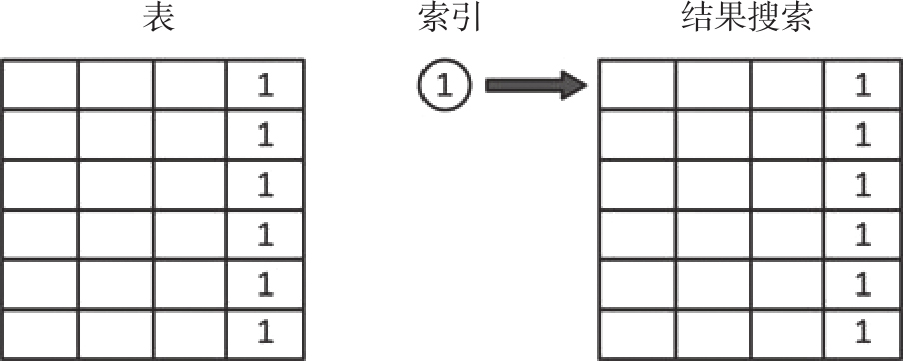
图3-11 使用无用索引时查询会返回每一条记录
现在假设该字段有两种值。此时索引会先返回表中一半的记录,然后在这些记录中检索,如图3-12所示。这样效果要好一点,但是与直接进行全表扫描相比,使用索引需要一定的开销,所以在实践中,这种优势并不明显。
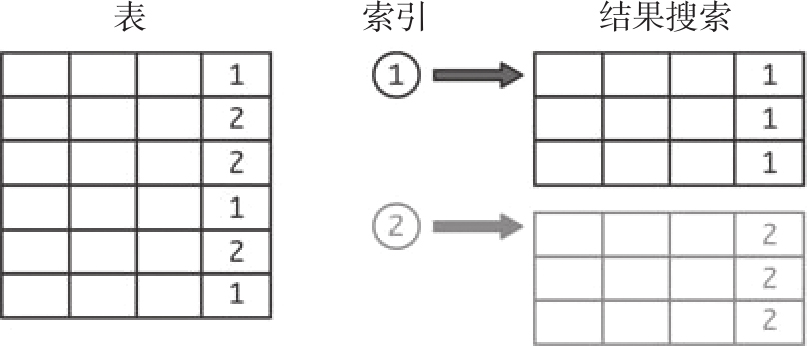
图3-12 使用有两种值的索引时返回的记录
如图3-13所示,当索引的基数增加,即索引字段的值越来越多时,索引就会更加有用。
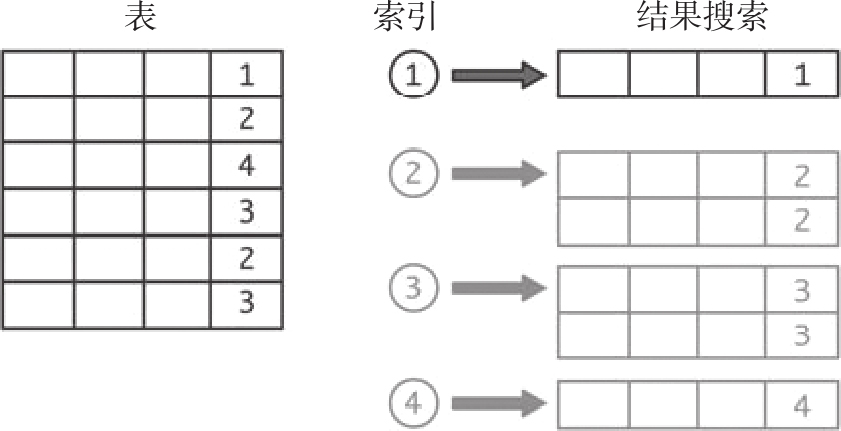
图3-13 使用有四种值的索引时返回的记录
随着基数的增加,数据能更好地进行区分,并趋向于更小的数值分段,从而能极大地加快对目标数据的访问。
 按照一般的经验,应确保索引的基数达到10或者更大。低于这个数值的,就不应作为索引使用。查询分析器会将基数值作为参考因素,看是否使用该索引。
按照一般的经验,应确保索引的基数达到10或者更大。低于这个数值的,就不应作为索引使用。查询分析器会将基数值作为参考因素,看是否使用该索引。
请记住,只存在少量数值的字段,如布尔(Booleans)运算和枚举型(Enums)字段,其基数总是有限的,这使得它们不适合被索引,至少对这些字段本身来说如此。另外,各条记录倾向于不同值的字段,其基数会很大,这种字段是索引的上选。考虑到这个原因,所以主键总是被自动索引。