
下载掌阅APP,畅读海量书库
立即打开



数据重构,即对数据变量和记录位置互换。
数据重构,就是选择类型。
一共三种类型:
一是重构变量为记录。如果有几组有联系的纵格数据,要求纵格数据出现在横格记录中,从而组成一个新数据文件。
二是重构记录为变量。如果有几组有联系的数据记录,要求横格数据出现在纵格中,从而形成新的数据文件。
三是转置所有的数据。如果要转置所有的数据,即所有排变成列,或相反。这时可以关闭数据重构对话框,而打开转置对话框。
操作过程 :
要用到数据重构的两个例子
先以简单数据结构为例:一个记录是一个观测量,一个变量占一纵格,一个记录占一横格。要测量一个班所有学生的考试分数,那么所有的成绩要求只能出现在一个纵格里,一格横格一个学生。
一个复杂数据的例子:要分析数据,就是根据某些条件分析变量是如何变化的。这些条件可以是具体的实验处理、人口统计、时间点或是其它。在分析时,这些条件看作是因素。在分析这些因素时,就有了一个复杂的数据结构。信息可处于几个纵栏中(一个栏算一个因素);同理,信息可能处于多排中(一排算一个因素)。在这种情况下,就要用到“重构数据”,形成一个复杂的数据结构。
当下的数据文件和要形成一个什么样的数据结构,决定使用哪一项数据重构规则。
文件的数据是如何排列?可能是处于不同的变量中(几组记录中),也可能处在同一的变量中。
如:几组记录。变量和条件在不同纵格中,下表:
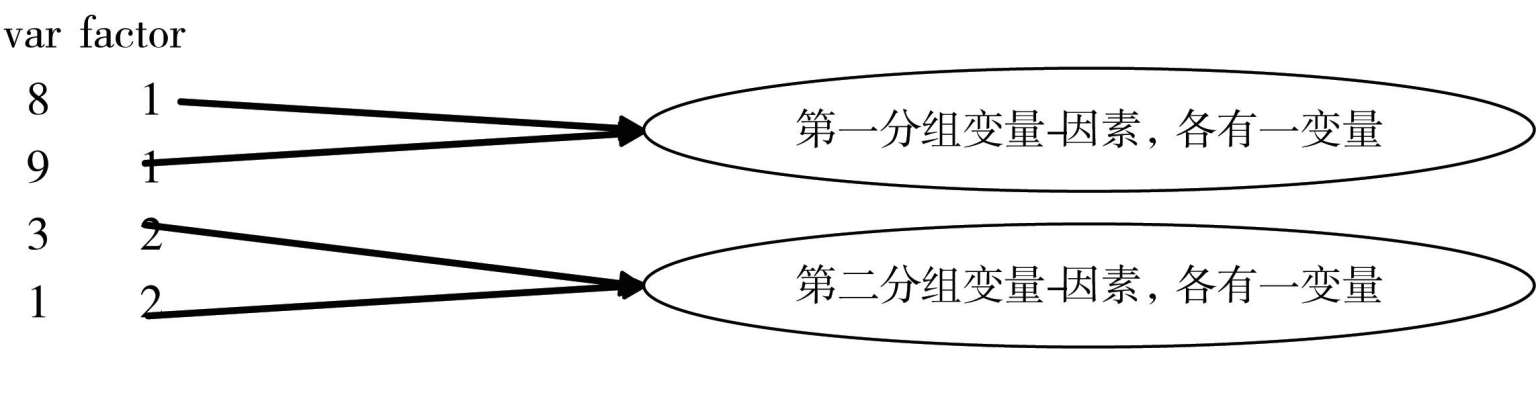
前两排是一组记录,因为数据有联系,有同一水平上的数据。在SPSS分析中因素就是分组变量。
几组纵栏:同一纵栏中有变量和条件。
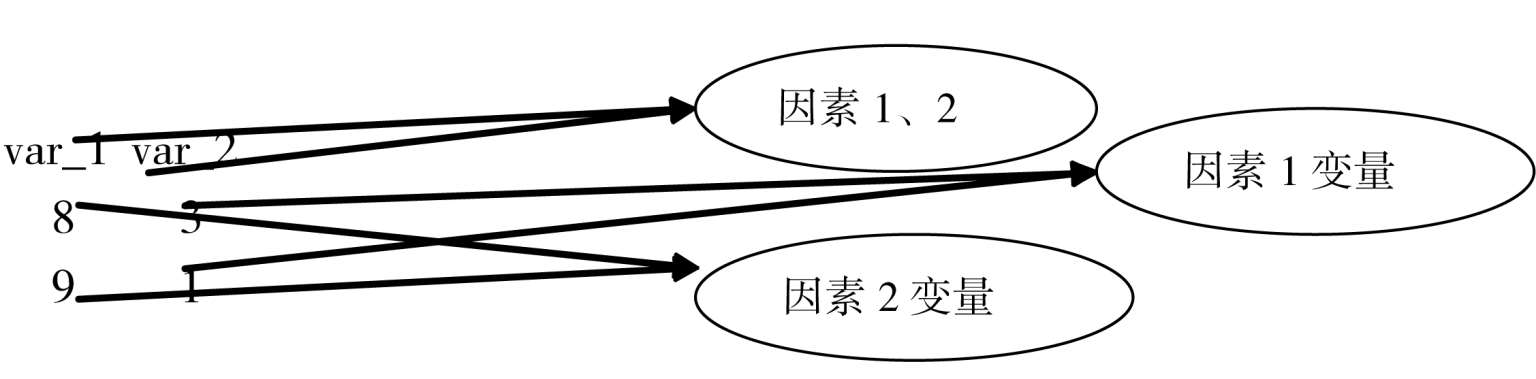
上面两个纵栏是一个变量组,因为两组变量有联系。var_1 代表因素水平 1;var 2_ 代表因素水平 2。在SPSS数据分析中,如果数据结构是这样的话,因素常看作重复测量,新文件中需要什么样的数据结构取决于所使用的分析过程。
需要记录组的分析过程:数据是记录组结构,则要求分类变量。其分析过程有univariate,multivariate,and variance components with General Linear Model,Mixed Models,and OLAP Cubes,独立样本T检验,非参数检验。如果数据是变量组,则用“数据重构”,将变量组转换为记录组。
需要变量组的分析过程:数据是变量组结构,可做重复测量分析。分析过程还有:广义线性重复测量,依赖时间的协变量COX回归分析,配对样本T检验,相关样本非参数检验。如果数据结构是记录组,用“数据重构”,将记录组转换为变量组。
操作步骤 :
调入数据,点击“RECONSTRUCTURE”(数据重构),出现对话框如下:
调入数据,从表中可以看出,这是变量组,如果要求记录组,将作如下数据重构。
操作 1
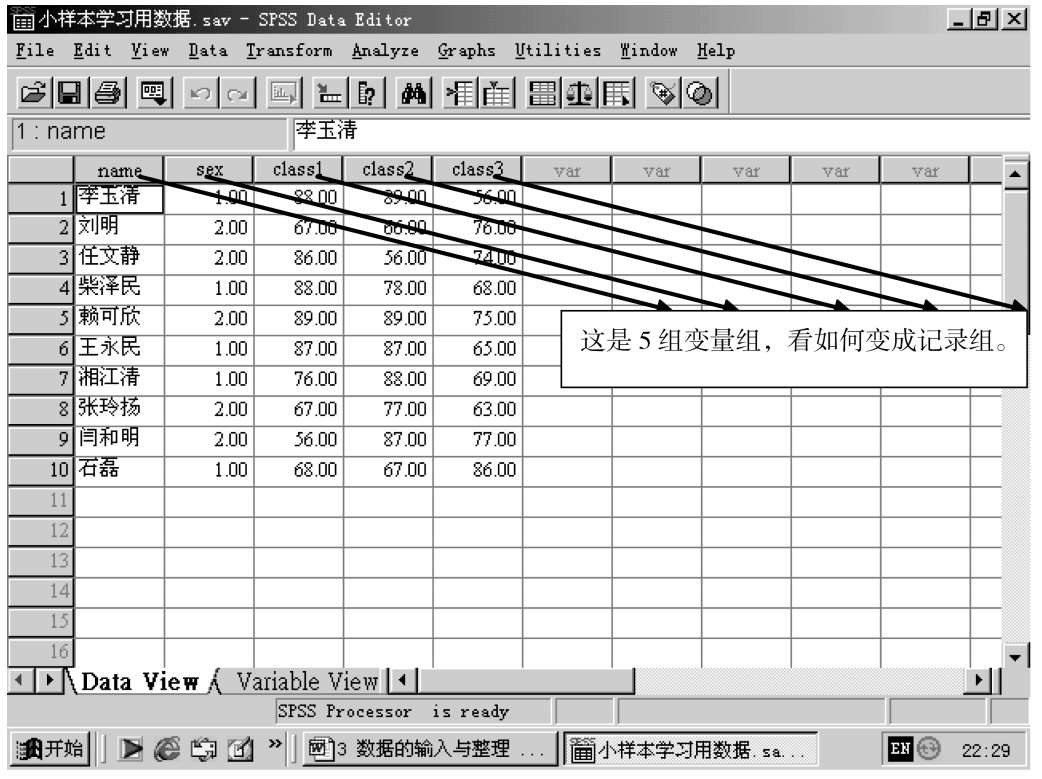
操作 2
点击“数据重构”,出现对话框如下:
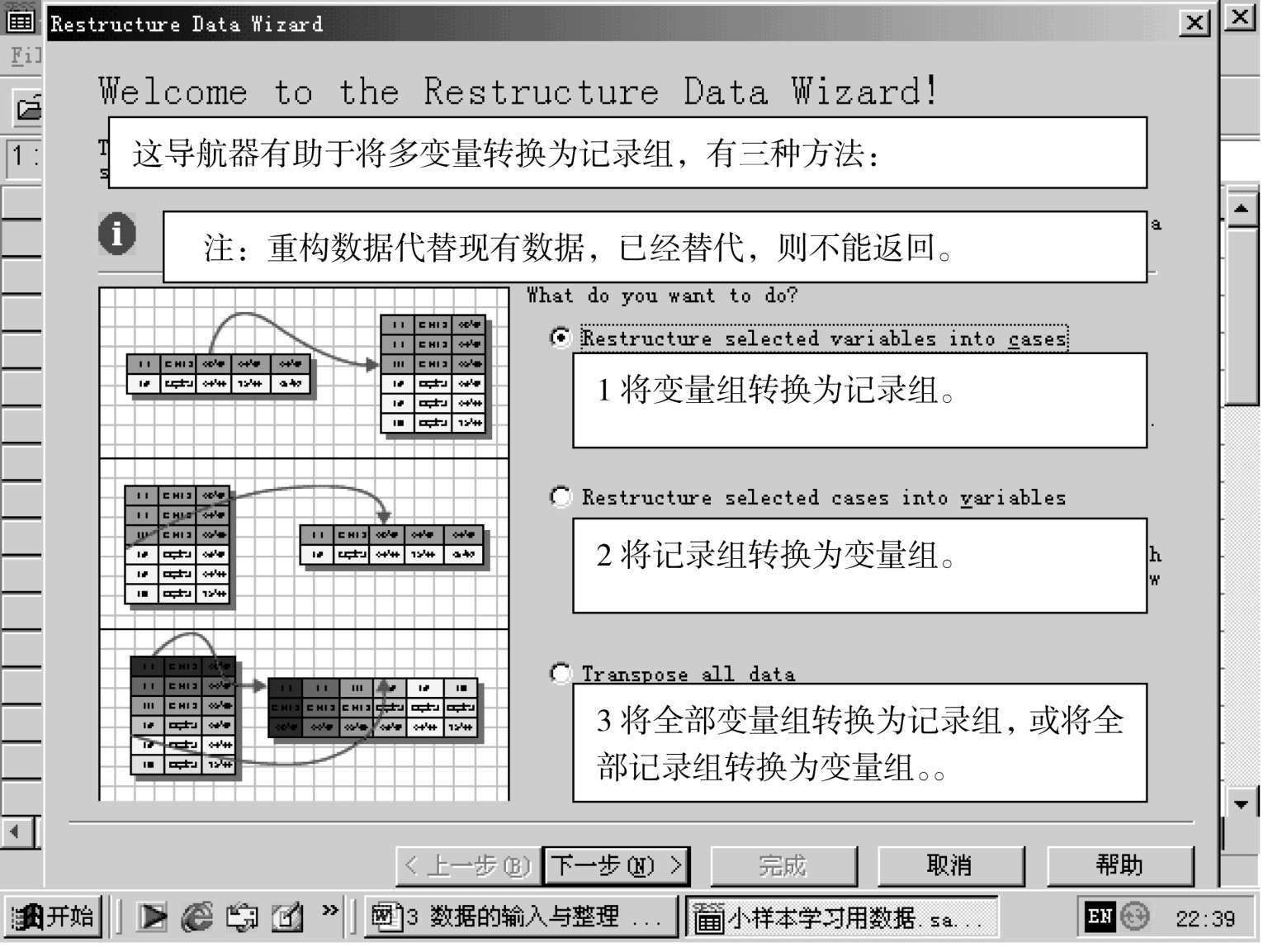
第二步:选择 1 将变量组转换为记录组。按下一步,出现如下对话框:
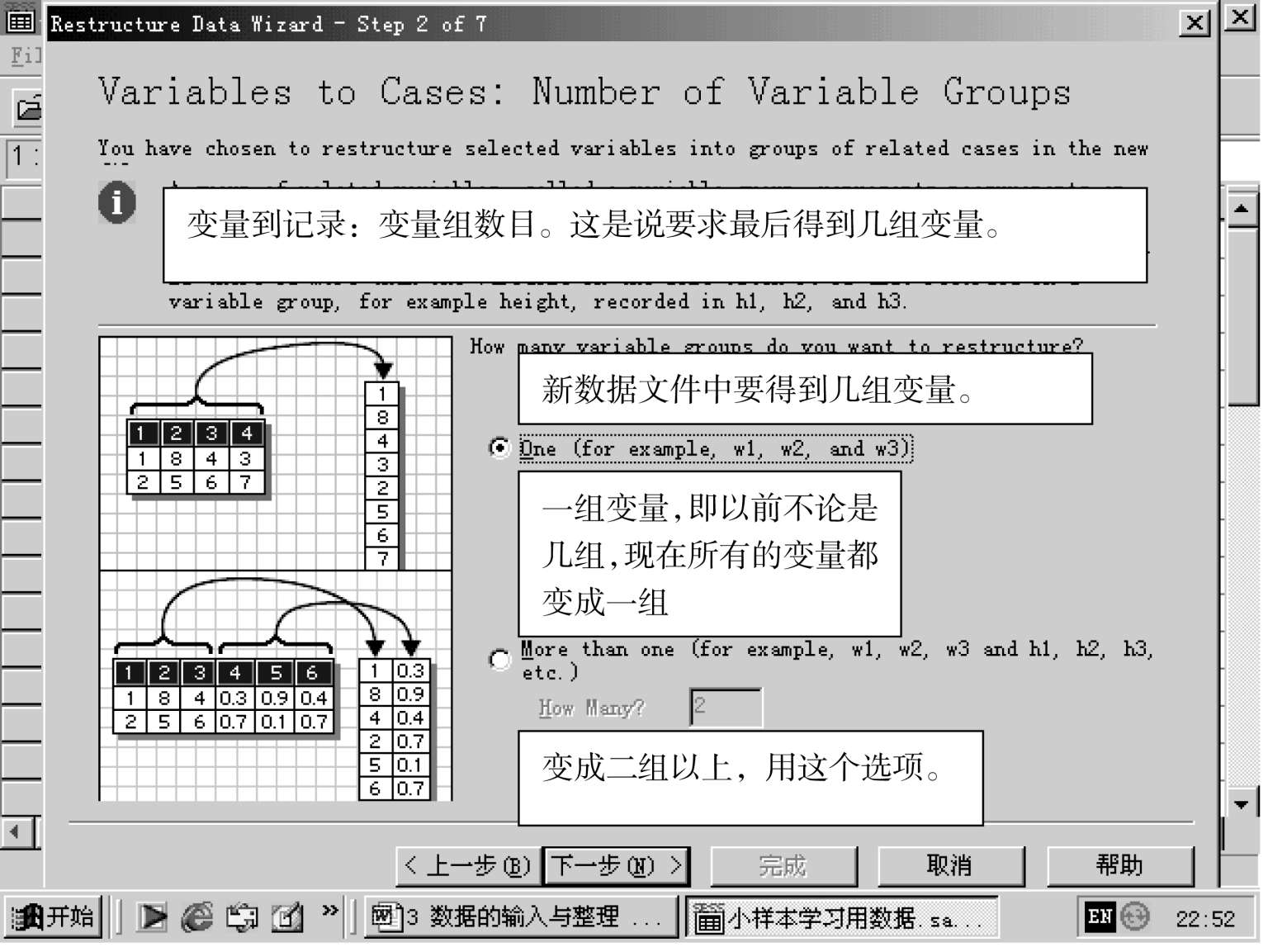
第三步:当选定要得到几组变量(这儿选一组)之后,按下一步,对话框如下:
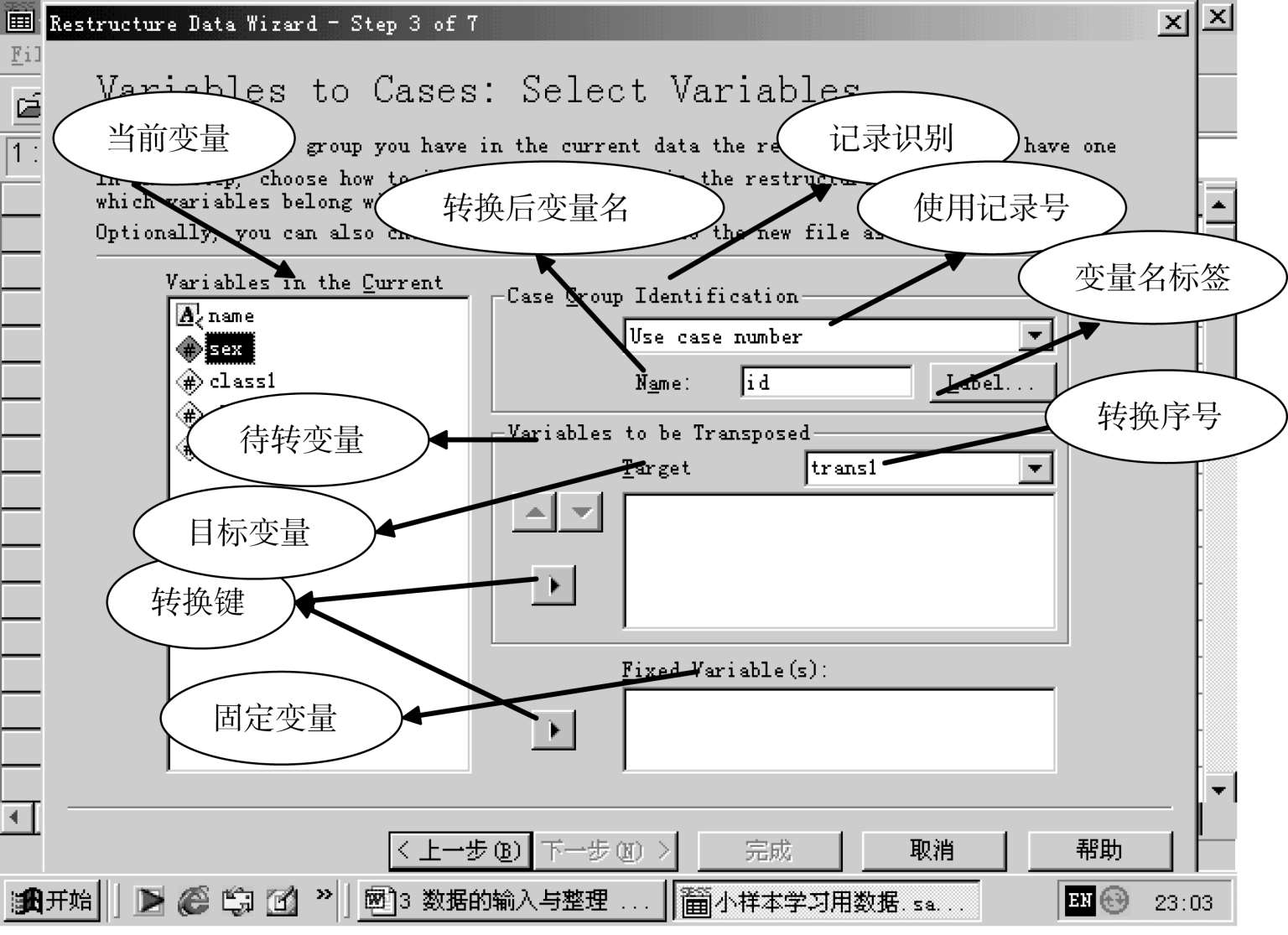
说明:
固定变量是不参与重构的变量。目标变量是要参与重构的变量。将当前变量通过转换键调入固定框和目标变量框。点击下一步。
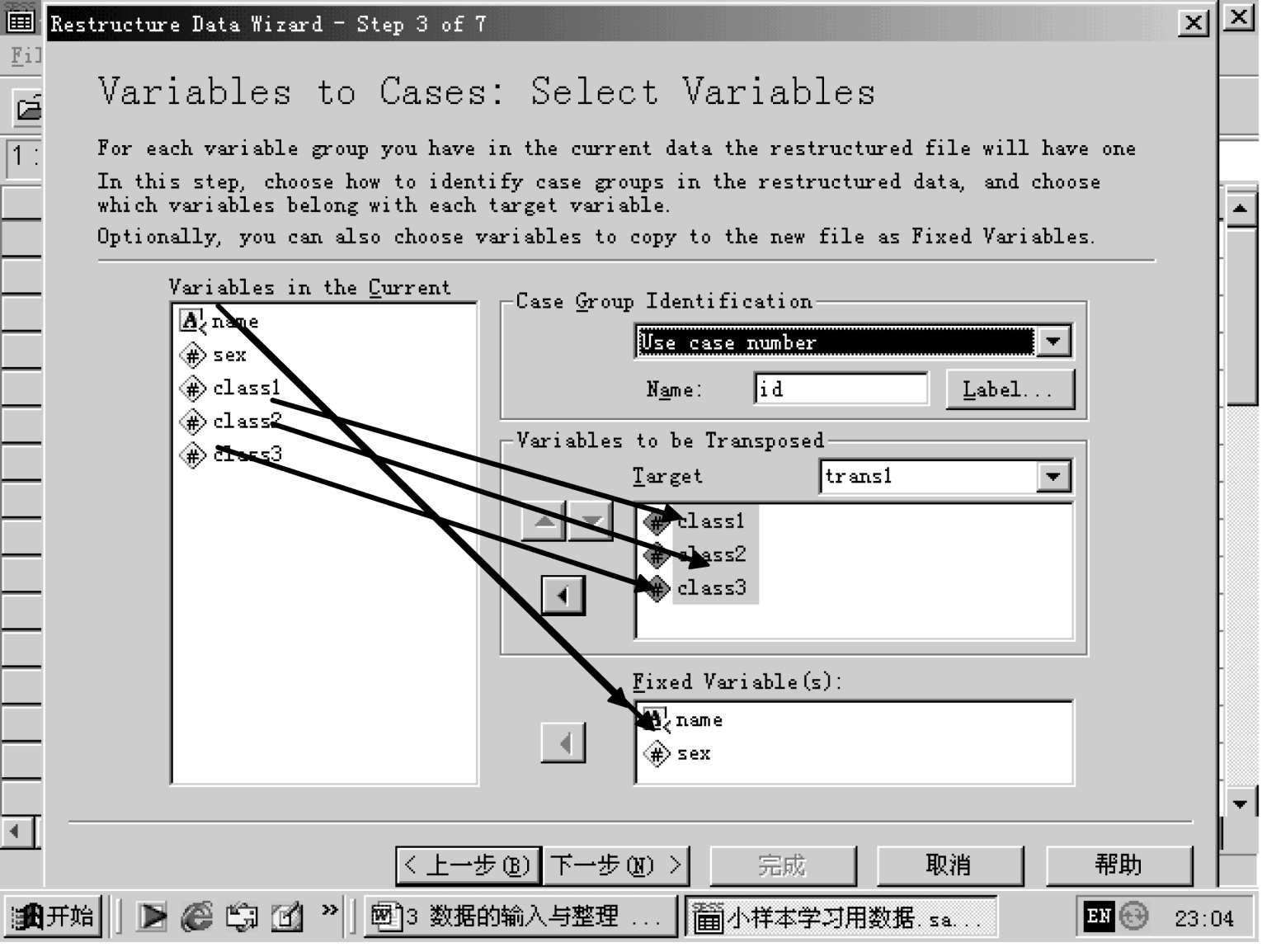
说明:
通过箭头,就能看清转换过程。名称和性别都属于类别变量,调入固定变量框。班级 1、2、3 调入目标框,准备重构。
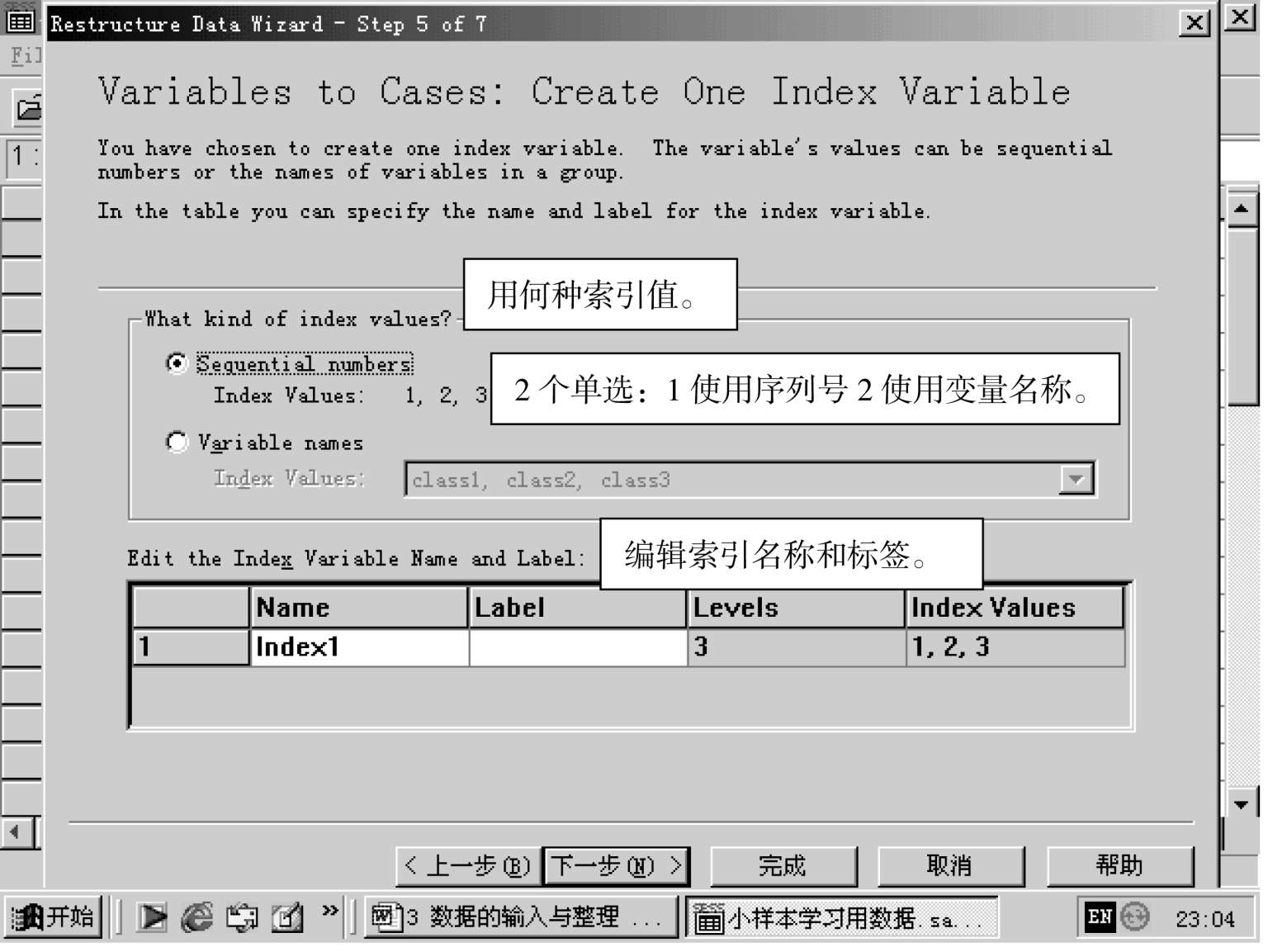
另外,记录组识别下面的复选框有一小尖头,可下拉,里有三个选项:使用记录号,使用变量号,不使用号。重构后的变量名也可以重取,之后的变量名标签,可以打开填写。目标后下拉框,有三种选出项:重构 1,重构 2,重构 3。
当这些选项都确定后,点击下一步:
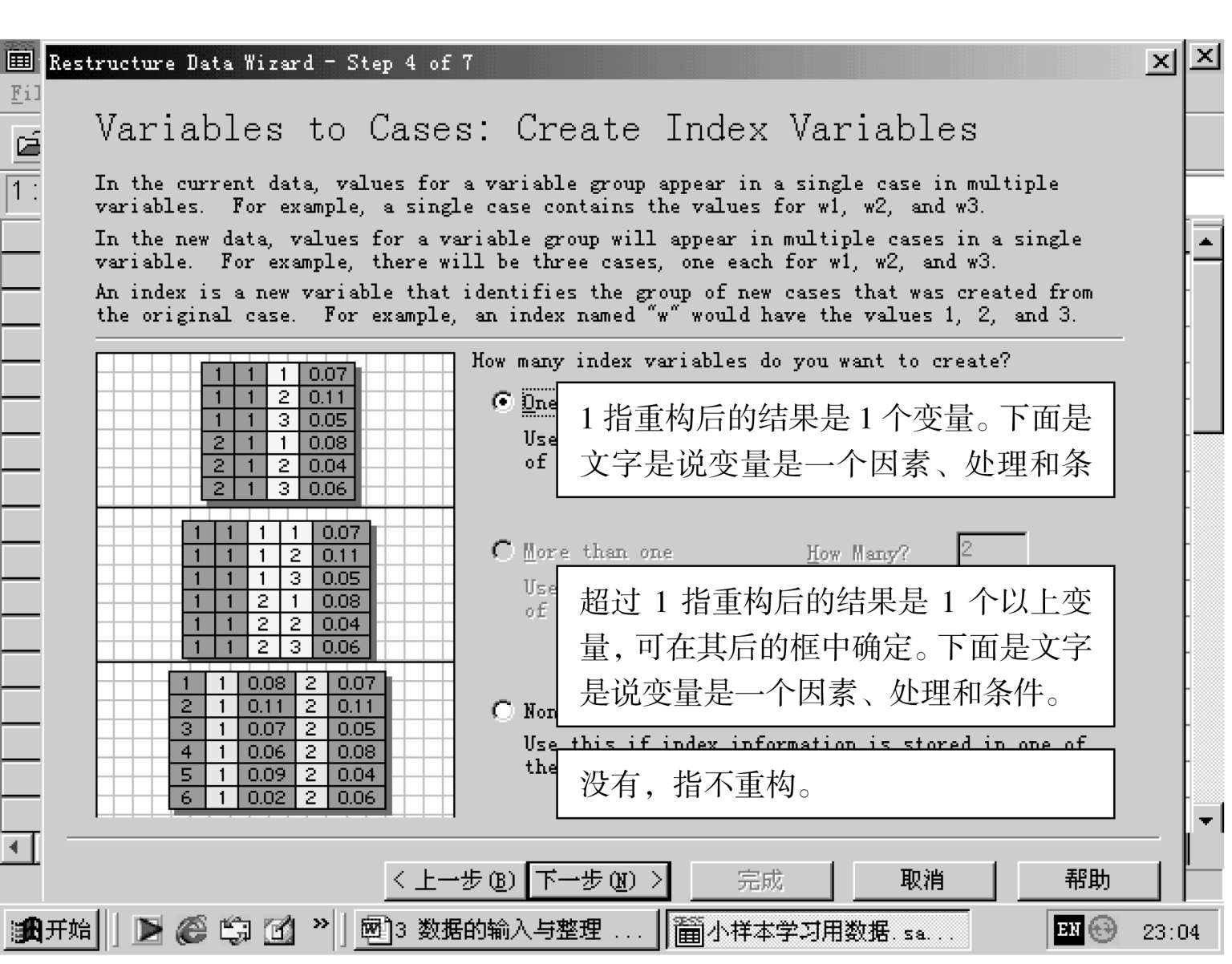
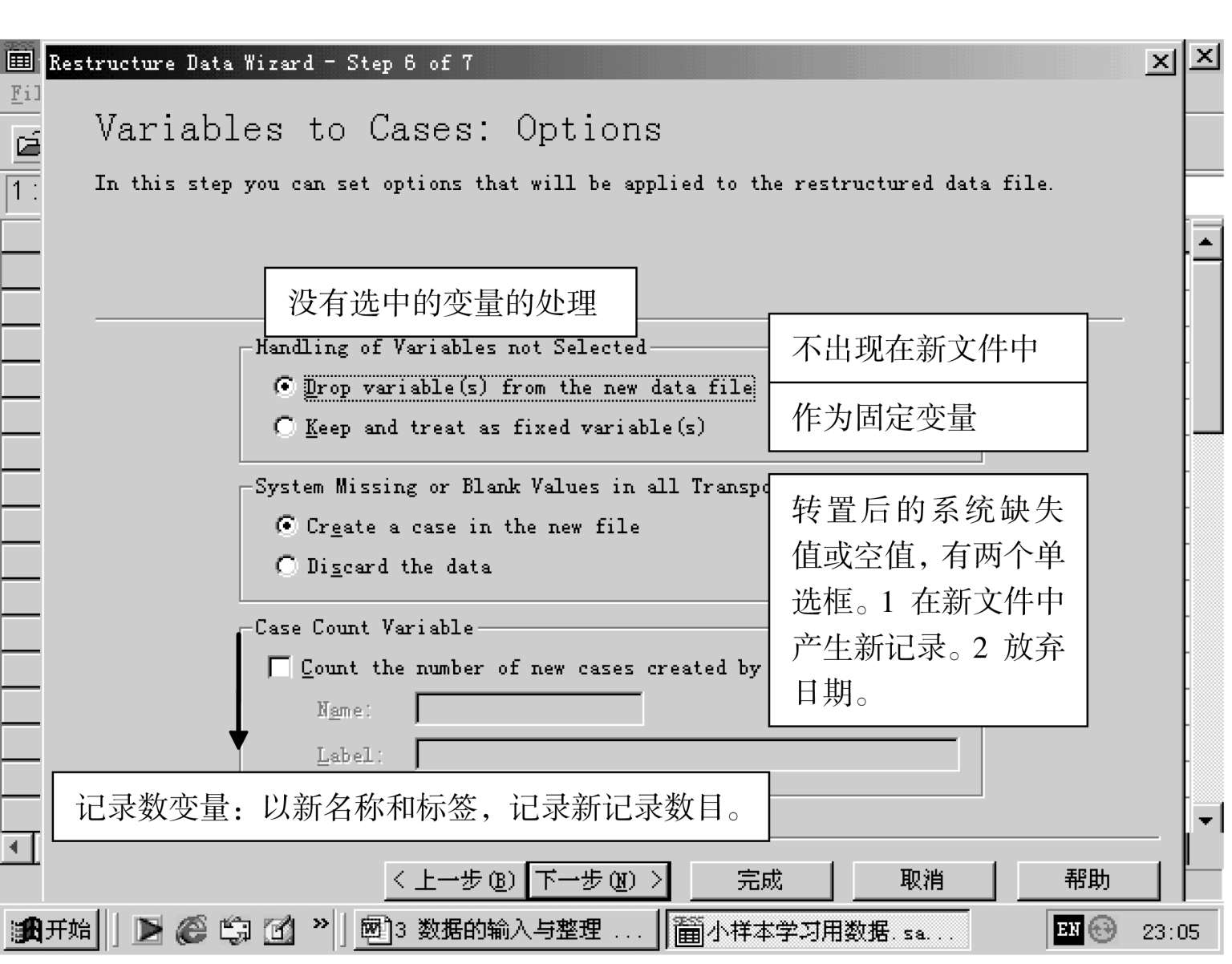
说明:
当选定之后,点击下一步:
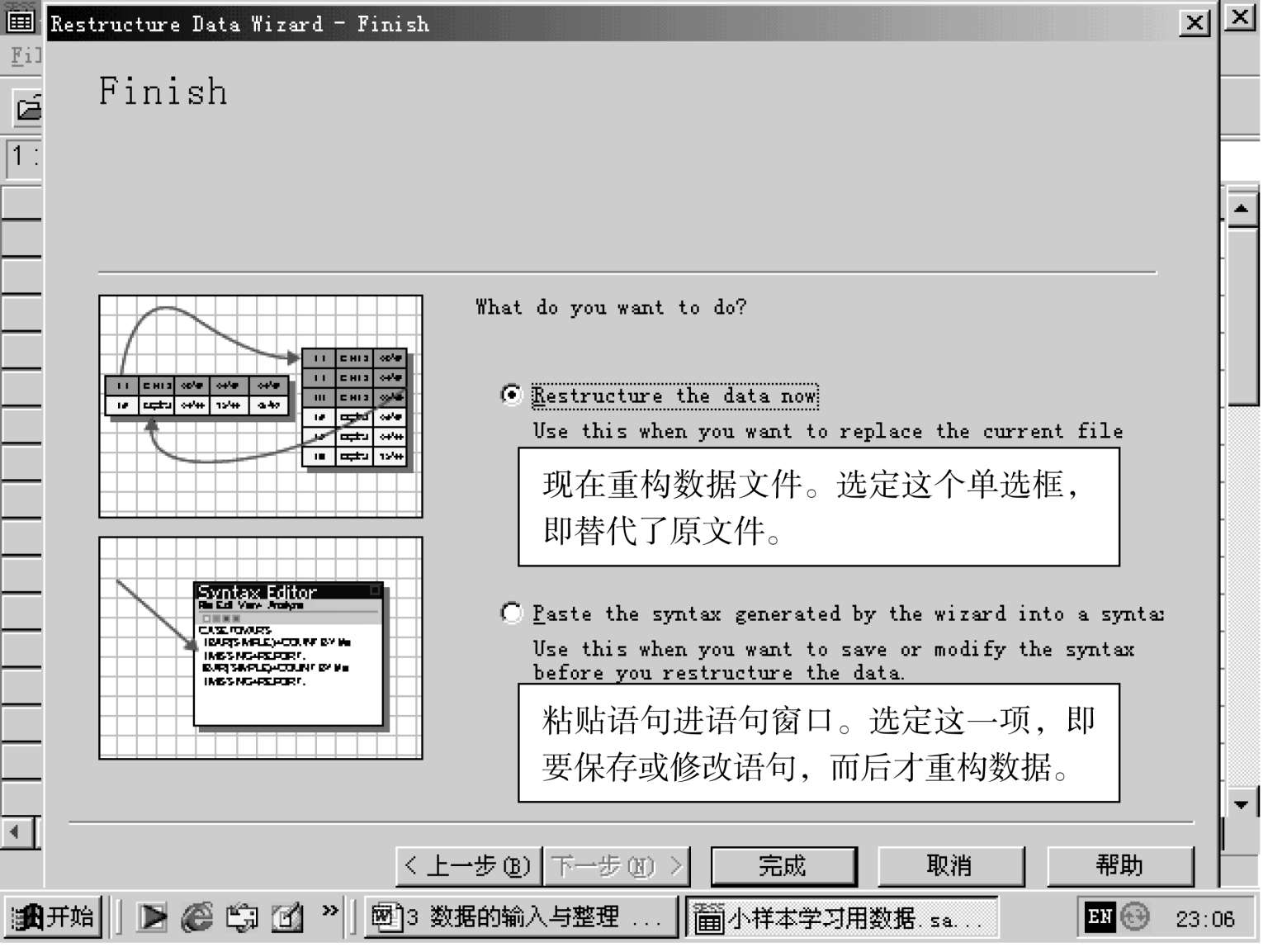
说明:
这一步是结束的步骤,即确定了重构数据后,按下一步,即该出现结果:
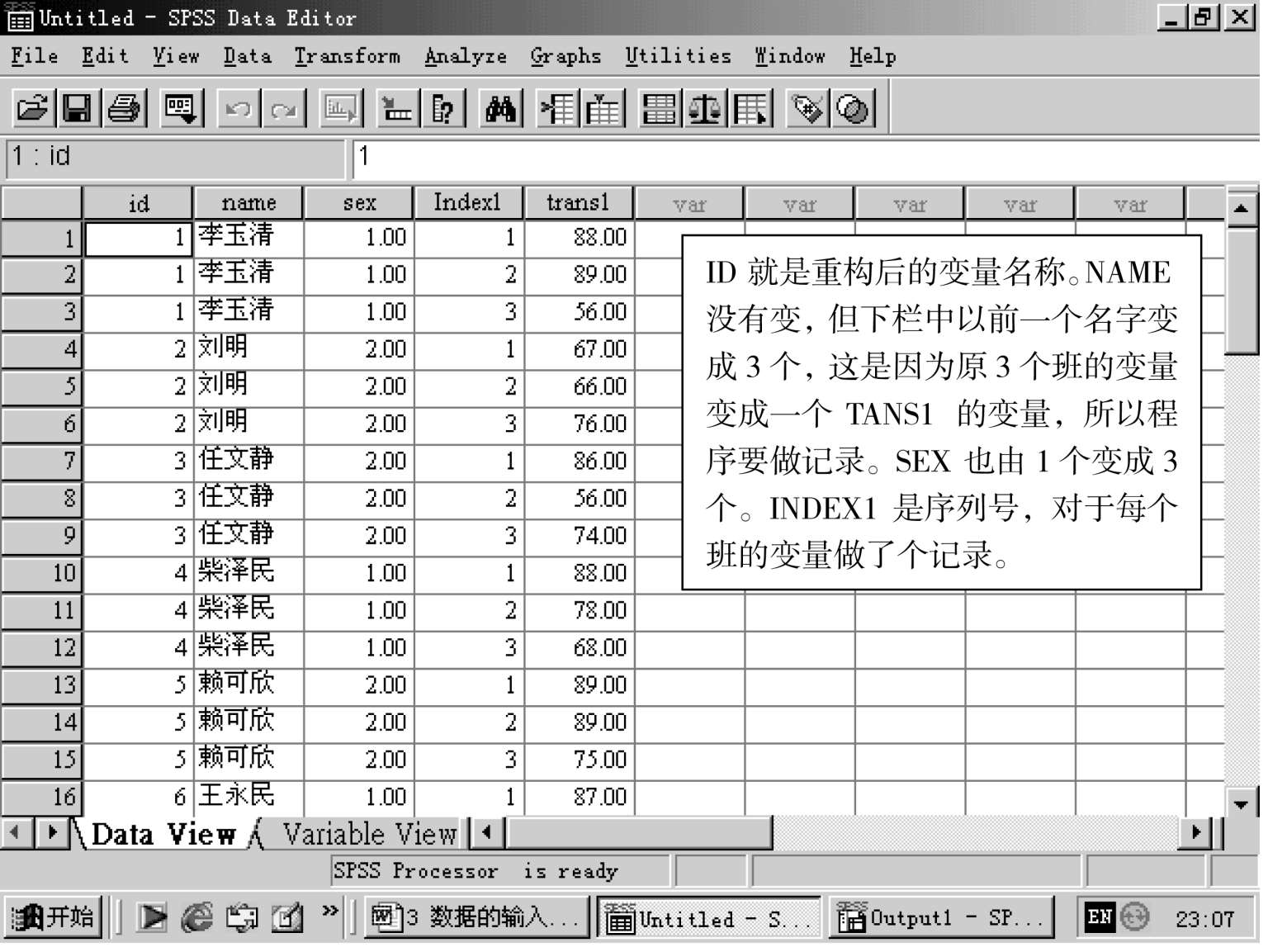
一 、 识别重复值
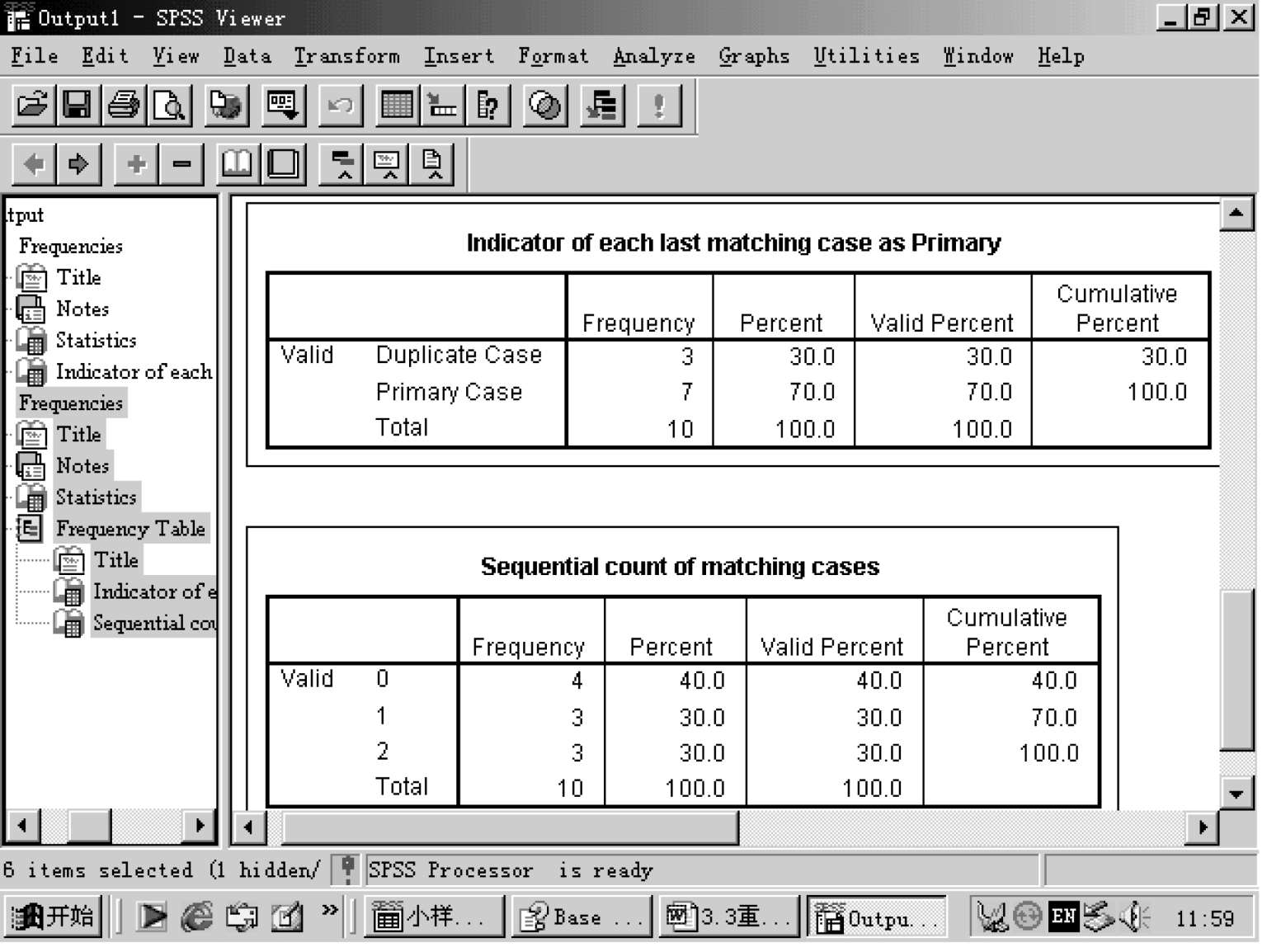
检查数据中是否有重复值,非常重要,否则我们的统计的结果是不可靠的。重复值出现往往是在输入时,有的值可能输入过两次或以上。还有在英语的成绩中,总成绩中有你们的数据,而自已保存中也有本班的数据,可能发生重复值,因此有必要检查,从而取得可靠的结果。
操作过程 :
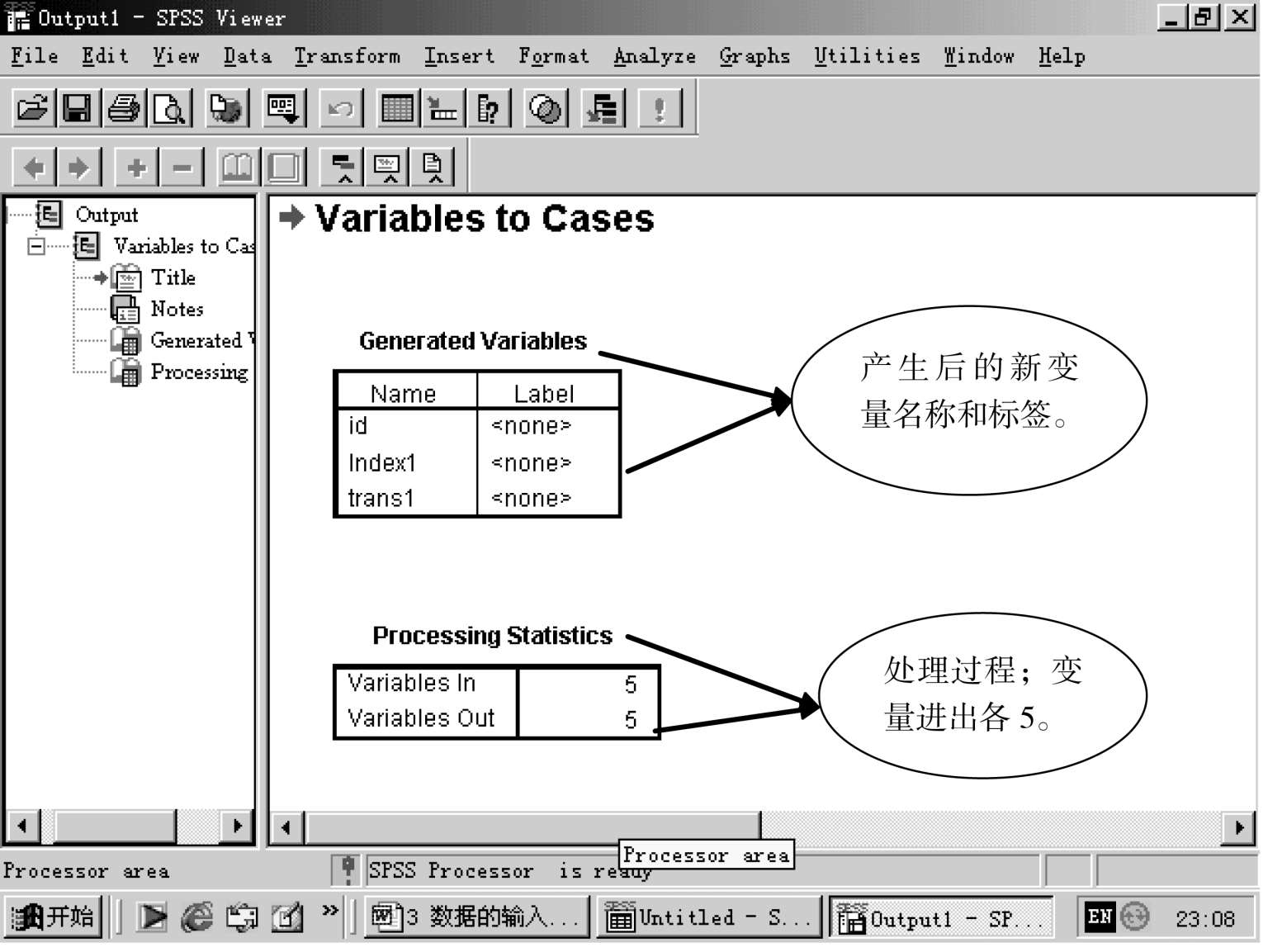
DATA—IDENTIFY DUPLICATE CASES,点击,显示下图
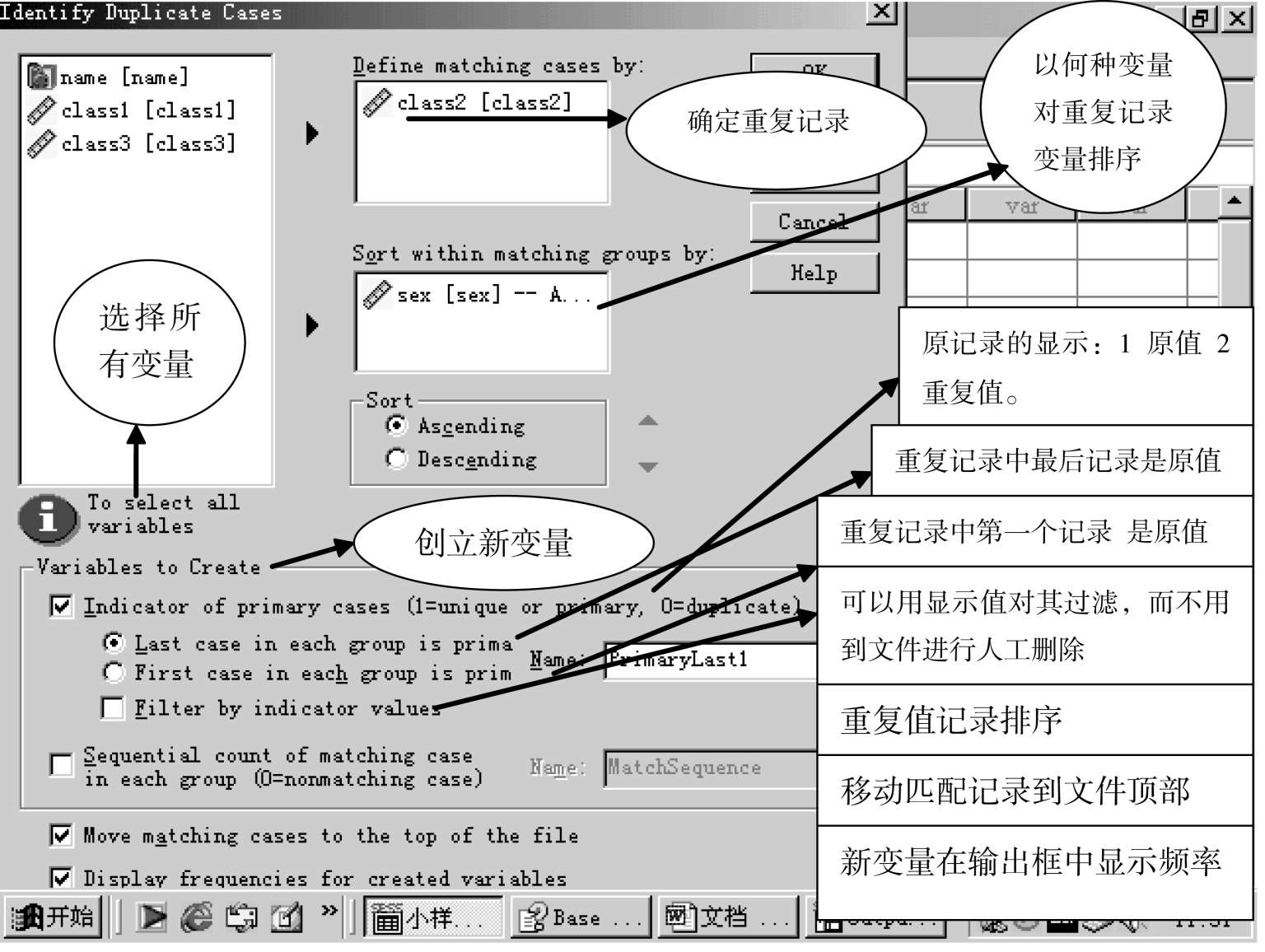
显示检查结果,如图:
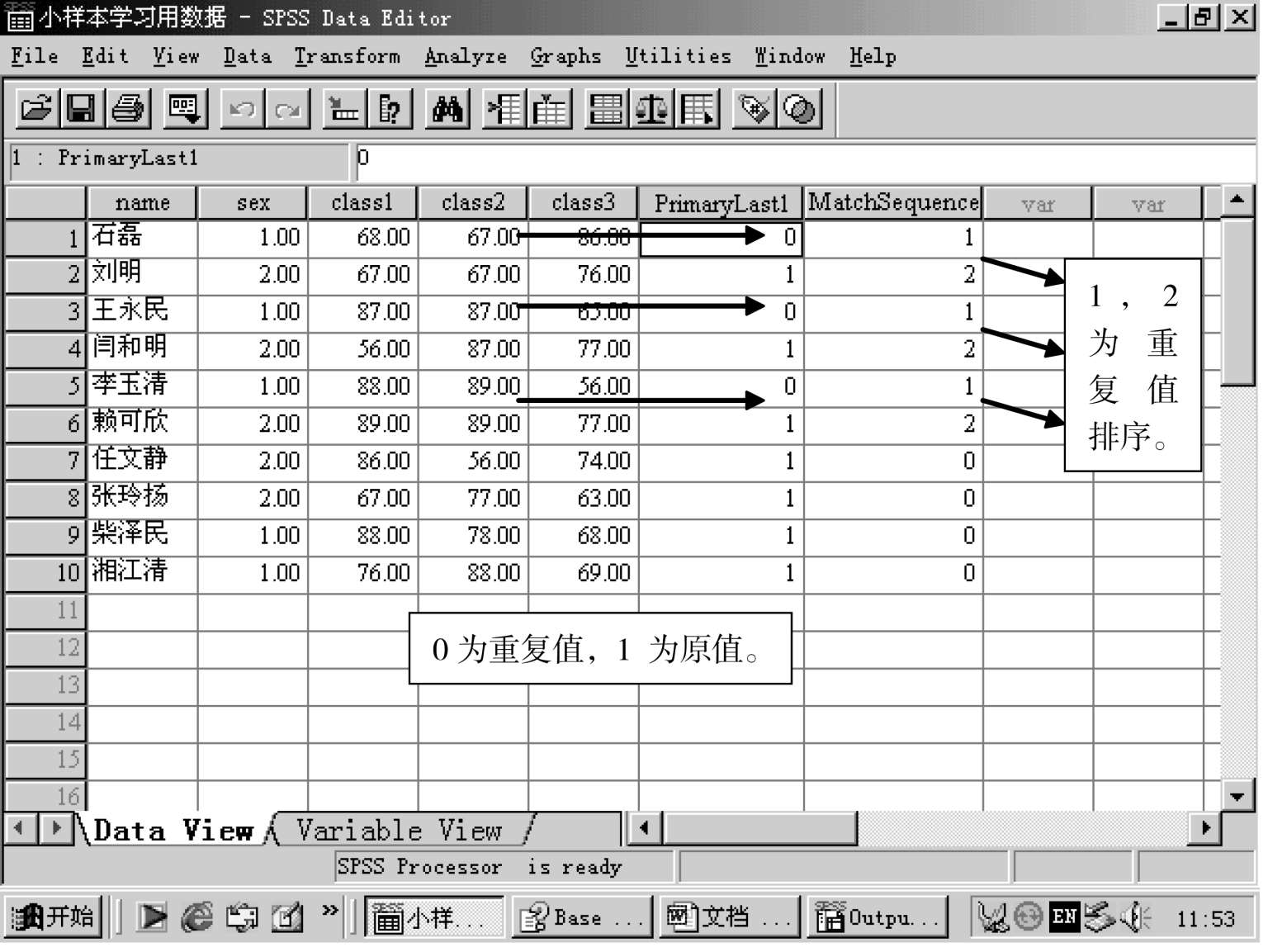
显示输出框:
二 、 识别奇异值
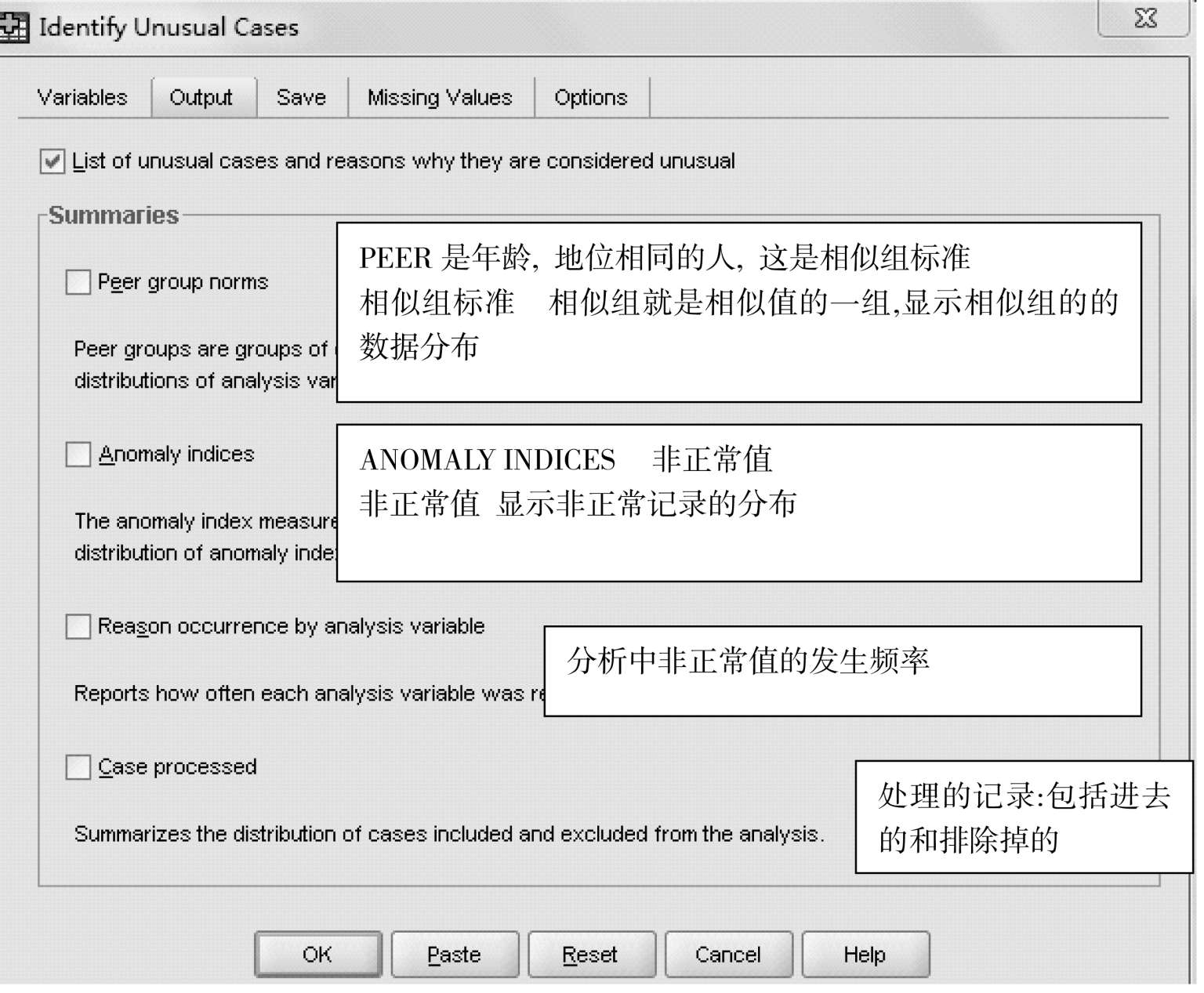
识别奇异值,也是数据准备的一项重要内容。所谓奇异就是特别大的值或特别小的值,显然不是这一类的值,在分析要处理,否则分析结果不可靠。
分析过程 :
CASE—DATA—IDENTIFYUNUSUALCASES
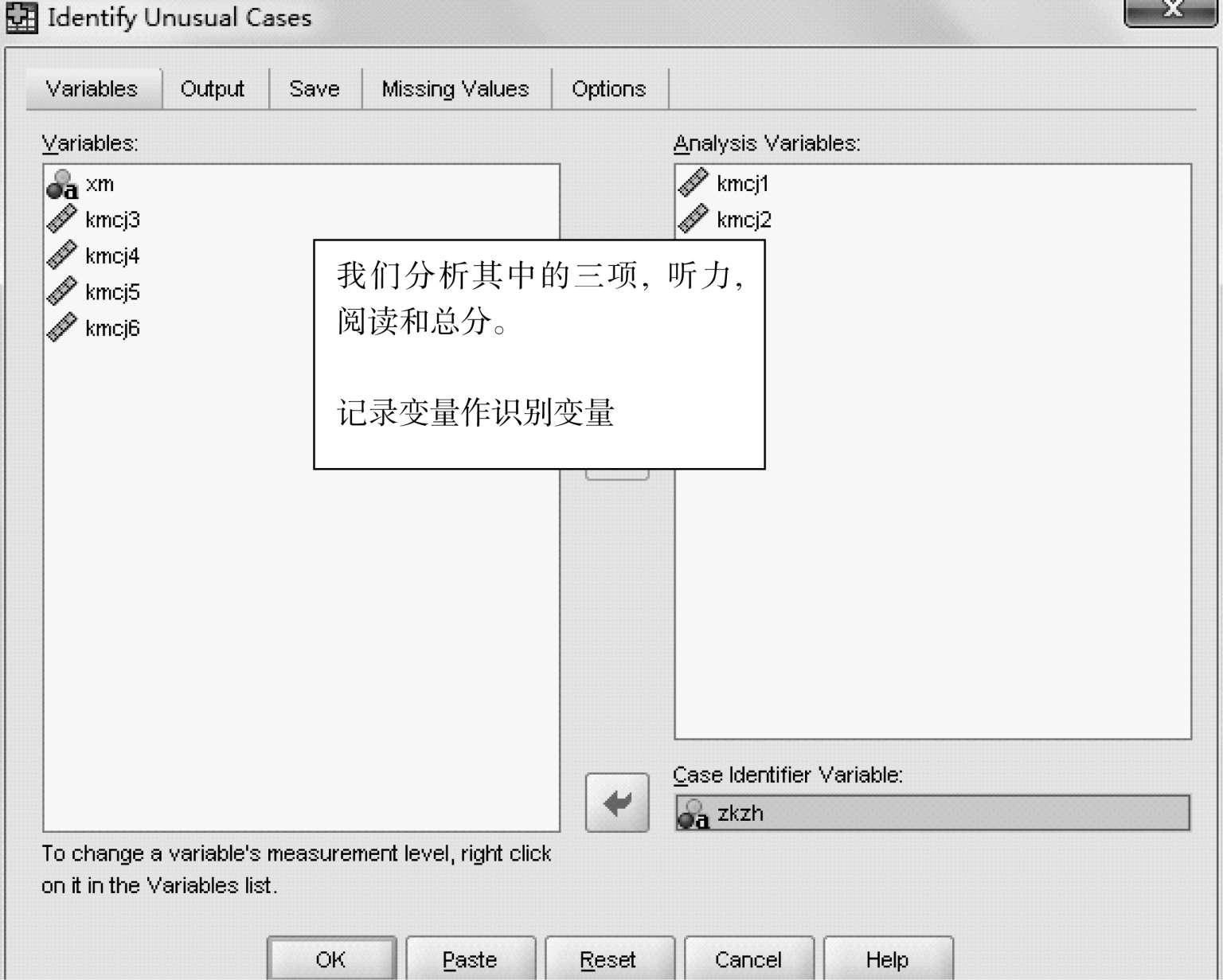
我们利用”大样本数据”,做一个分析:
我们构选上图的全部 5 个小方框,看分析结果:
分析结果 :
Case Processing Summary
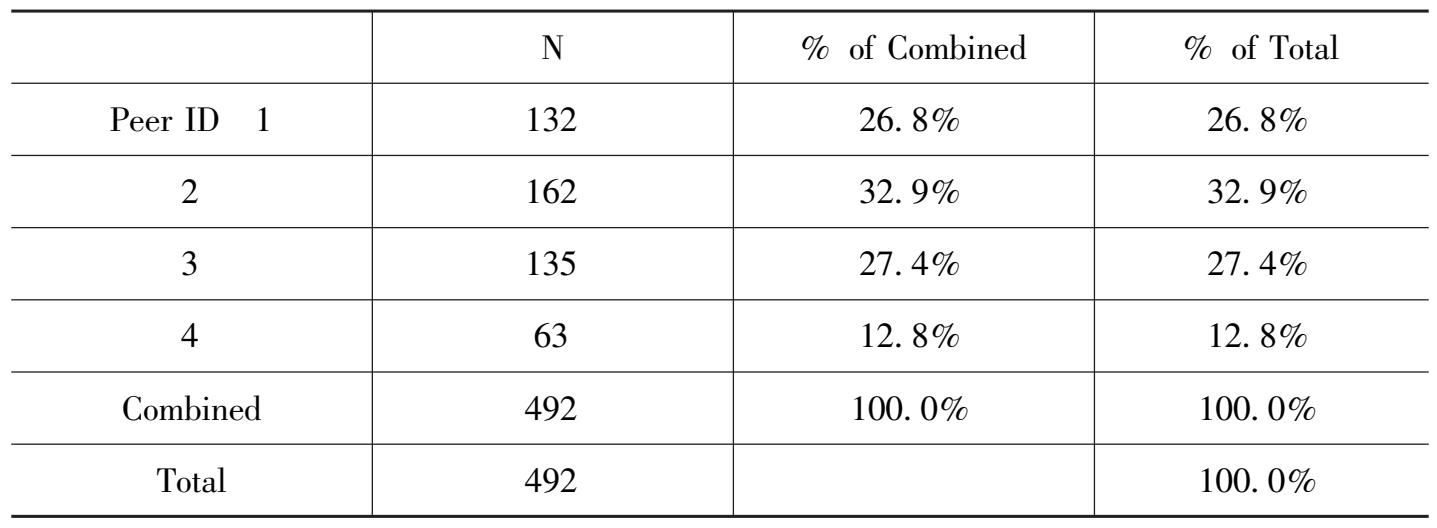
相似组有四组,各有一定的记录,共有 492 个记录。
Reason:1
Anomaly Case Reason List
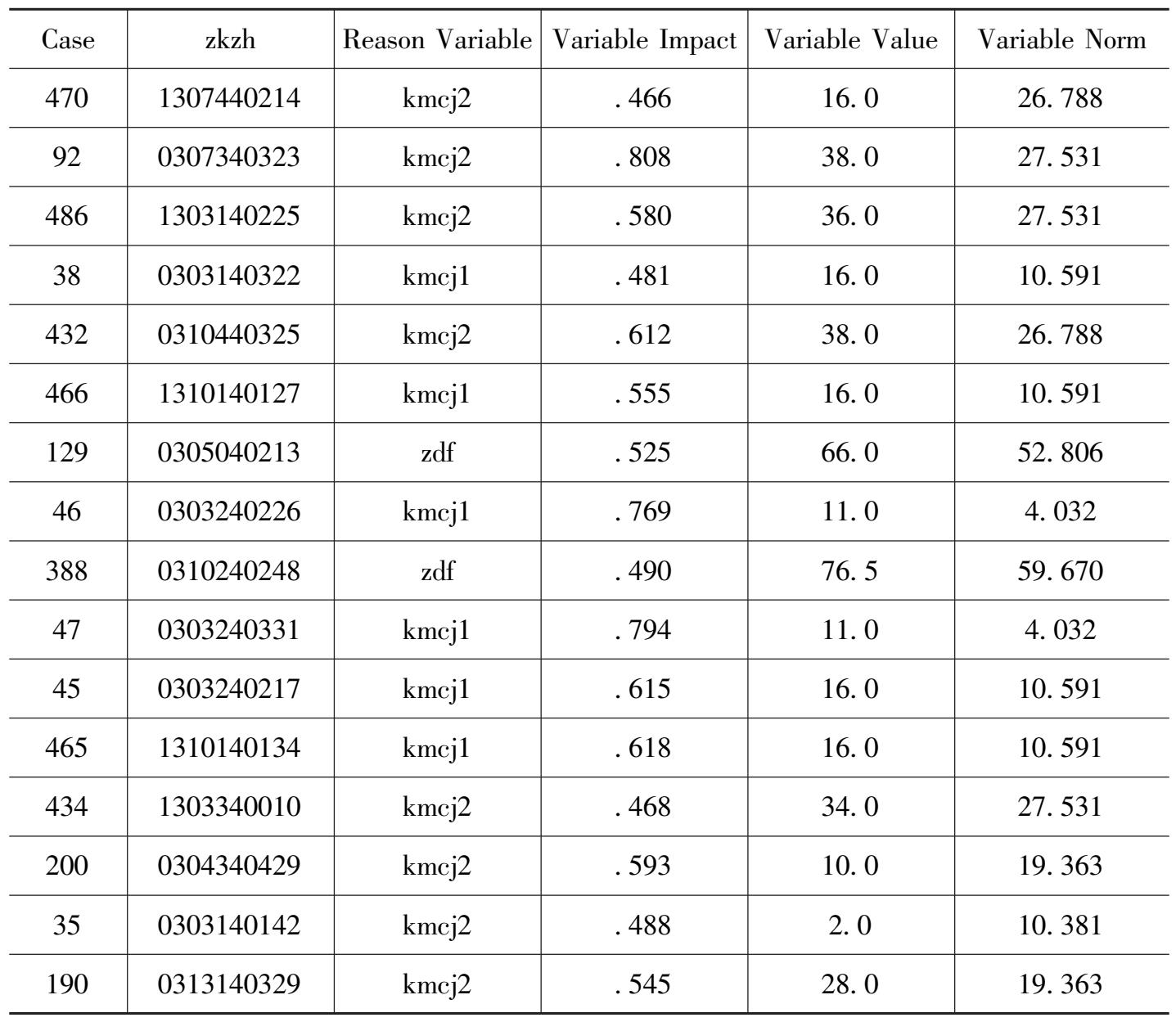
续表
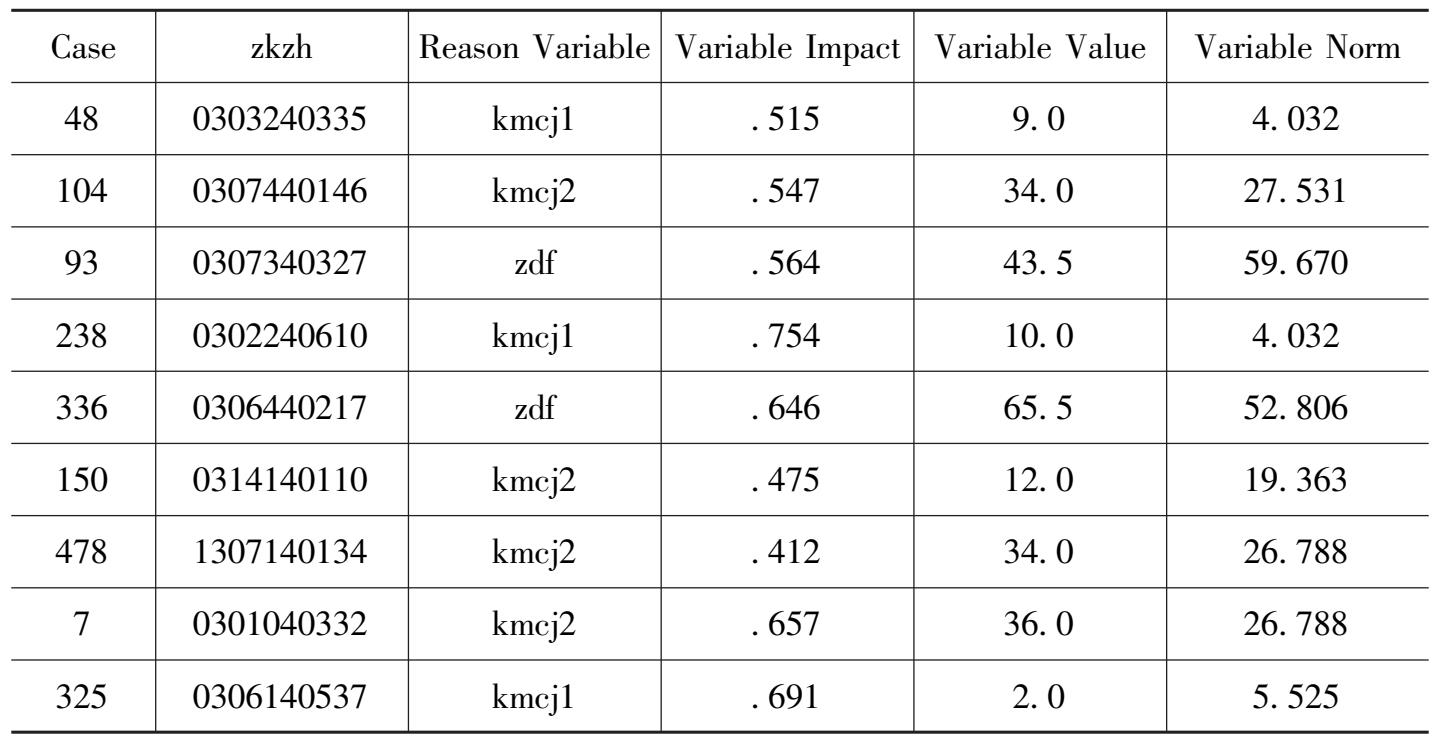
第一列是记录号,第二列是学号,第三列是理由变量,第四列是变量影响,数字越大,影响越大,第五列是具体值,从这里可以看出奇异值。或剔除或修改。第六列是变量标准。