
下载掌阅APP,畅读海量书库
立即打开



英语语言能力测试的基本原则也称为英语语言能力测试评价标准,它是指导英语语言能力测试的最基本、最基础的准则,是我们在进行英语语言能力测试设计过程中必须遵循的规范、规则与基本精神。
巴克曼(Bachman,1996)认为,设计与评价英语测试最重要的总体性原则是实用性(usefulness)原则,而实用性原则是一个含义丰富的概念,可以进行分解性理解,即实用性包括以下几个方面。
(1)效度。
(2)信度。
(3)真实性。
(4)互动性。
(5)考试后效作用。
(6)可操作性。
海宁(Henning,2001)认为,设计一个合适的测试,不仅需要明确测试的目的和种类,而且需要遵循一定的标准,这些标准包括以下几个方面。
(1)效度。
(2)难易度。
(3)信度。
(4)可操作性。
(5)相关性。
(6)可复制性。
(7)可解释性。
我国学者王振亚(2009)认为,决定英语语言能力测试质量的高低最重要的三个因素包括以下几个方面。
(1)效度。
(2)信度。
(3)实用性。
一般认为,学者们对英语语言能力测试应当遵循的原则的内容概括不一,可能源于两个原因:其一,有关英语语言能力测试应当遵循的基本原则还没有形成统一的认识,学者们各自有自己的见解;其二,基本原则本身是一个宽泛的概念,至于什么是“基本”这一认识,本身就存在发挥的空间。
但是上述理解仍有一定合理性,只是没有认识到问题的本质。事实上,这些不同的概括在本质上是没有太大区别的,其原因有二:第一,差别只是用语的差别,其内容并没有实质的不同,比如巴克曼讲的互动性,与海宁讲的相关性并没有太大的差异;其二,我国学者的概括似乎与国外学者差异较大,但是,实际上,这里存在翻译上的表达误解,王振亚先生所讲的实用性就是海宁所讲的可复制性。至于为什么只有三点,则在于著文的侧重点的不同。
综合以上分析,我们认为,英语语言能力测试的基本原则包括:效度;信度;真实性;互动性;考试后效作用;可操作性。现我们分别进行论述。
效度(validity)又称有效性,海宁(1987)认为,所谓效度是指一套测试或测试内容达到其预期测试意图的程度。休斯(Hughes,1989)强调,一个测试的好坏,要看它是否做到了它能够精确地测试它所想要测试的内容。韦尔(Weir,1990)也认为,效度就是能够达到测试设计者所希望测试的内容。
如何正确理解效度的概念。比如测试者想通过测试,考查学生的口语流利程度,他设计了下面的测试题目:
Please write in general your study of spoken English.
请简要写出你学习英语口语的状况。
这样的测试题目,是否能够考查出被测试者的英语口语的流利程度呢?答案是显而易见的,无论被测试者在作答这个题目时,表现的多突出,还是表现得很差,都与口语没有任何关系。通过写作的题目来测试口语的流利程度是不可能达到目的的。
在这个例子中,测试者测试的目的是考查学生的英语口语的流利程度,而设计的题目则是写作,在此情况下,不能实现测试目的,即不能达到测试者所希望测试的内容。我们说,这样的测试的效度较低。
相反,如果测试者想考查学生的口语流利程度,他设计了下面的测试题目:
Please tell us in general your study of spoken English.
请告诉我们你学习英语口语的状况。
这样的测试题目,是否能够考查出被测试者的英语口语的流利程度呢?答案也是显而易见的,测试者在口头叙述他学习英语口语的状况时,必然表现出他的英语口语运用能力,测试者可以通过被测试者的现场表现,直接发觉被测试者的英语口语的流利程度。通过这样的题目来测试口语的流利程度是可以达到目的的。
这个例子与上面的例子在测试目的上是相同的,而设计的题目则是口头叙述的方式,在此情况下,实现了测试的目的,即达到测试者所希望测试的内容。也就是说,这样的测试的效度较高。
效度只是一个相对的概念。效度只有高低之分,而没有绝对有效或绝对无效。正如巴克曼所说的,“It is important for test developers and users to realize that test validation is an on-going process and that the interpretation we make of test scores can never be considered absolutely valid.”(Bachman,1996)
关于效度的重要性问题,刘润清(2000)曾指出,效度的高低是衡量英语语言能力测试最重要的指标,或者说是英语语言能力测试的基本出发点。一项效度很低的英语语言能力测试是毫无意义的。
效度如此重要,英语语言能力测试专家为更细致地分析效度的含义,将其分为表面效度、结构效度、内容效度、尺度关联效度几个方面。
表面效度(face validity)又称卷面效度。英格拉姆(Ingram,1977)认为,所谓表面效度指的是surface credibility or public acceptability(表面可信度或公众的可接受性)。也就是说,如果一项测试看上去测试了预定的测试内容,那么这项测试就具有表面效度。
可以看到,表面效度所涉及的是应试者的主观判断。也正因为如此,表面效度似乎不是一个科学的概念。有些语言学家甚至不将其列入效度之内。
但是,表面效度有其存在的必要性。奥尔德森(Alderson,1995)认为,如果被测试者认为一项测试的表面效度较高,就可能在测试中发挥应有的水平,这有利于提高测试测试的客观性。
那么,如何获取表面效度呢?斯伯尔斯基(Spolsky,1998)曾对此做过论述:
“To obtain statistically analyzable data about attitudes and behaviors,a common technique is the questionnaire Questionnaires are particularly useful in gathering data…and used to study attitudes in language study.”
也就是说,表面效度可以通过开座谈会或填“问答卷(questionnaire)”方式获取。但是,由于表面效度是一种主观的判断,因而这种问答卷的准确度就受到诸多因素的制约,准确度随之表现出不固定性。
结构(construct),指的是心理结构,在英语语言能力测试中,结构指的是被测试的一种能力或技能(马振亚,2009)。例如,我们通常所说的阅读能力、写作能力等。
休斯(1989)认为,如果一项测试表明能够测量某个理论能力结构,它就具有结构效度(construct validity)。也就是说,如果我们认为写作能力是由一定的语言表达技巧构成的,而我们又能够证明一项测试通过考查语言表达技巧测试了写作能力,那么这个测试就具有结构效度。
上述观点是传统的看法,当代语言学家在批判传统观点dev基础上,提出新的见解。巴克曼和帕尔默(Bachman &Palmer,1996)在《英语语言能力测试实践》一书中对结构效度进行了论述:
“Construct validity pertains to the meaningfulness and appropriateness of the interpretations that we make Oil the basis of test scores…We need to demonstrate,or justify,the validity of the interpretations we make of the test scores,and not simply assert or argue that they are valid.…The term construct validity is therefore used to refer to the extent to which we can interpret a given test score as an indicator of the ability(ies),or construct(s),we want to measure.”
从上述论断可以看出,结构效度不仅仅指测试能够测量某个理论能力结构的特征,它还具有更深层次的意思:比如,被测试的语言能力是否能通过对测试结果的解释得到体现;根据测试结果做出的解释是否合理,是否有意义。
另外,考试结构效度的证明对测试本身的意义在于,根据巴克曼(1996)的观点,考试结构效度证明的目的是确定考试解释的意义合适性。
那么如何确定测试的结构效度呢?奥尔德森(1995)认为,可以通过两类方法来确定考试的结构效度:定性与定量。所谓定性方法是由专家依据相应的理论确定考试的结构效度。定量的方法则包括试卷内部各项目之间的相关分析、考试成绩与考生特征之间的关系的分析以及因素分析等。
内容效度具有以下两层含义。
(1)海宁认为(198),内容效度(content validity)指测试内容是否具有代表性(representative)和充分性(comprehensive),即测试内容测试题目取样的代表性如何,覆盖面怎样。内容效度还有另一层含义,即测试考查的内容是否反映测试的目的,能否达到测试的效果。
关于内容效度的第一层含义,其理论根源在于,语言能力的外在形式纷繁复杂,很难一一考到。只能从中抽取一部分作为样本来测,这个样本的代表性如何,直接影响考试效度的高低。也就是说,如要保持测试内容的高效度,样本必须全面地、充分地体现要考查的内容。换句话说,试卷中是否有足够的题目去体现所要考的各方面内容显得十分重要。
(2)关于内容效度的第二层含义,麦克纳马拉(McNamara,2000)在论及此问题的时候,曾举过一个经典的例子:航空公司需要在一个特殊的航线上招聘能够用英语交流的乘务员,应聘者必须参加一个英语测试。这个测试的内容如果包括了航班工作过程所需要的英语内容,通过测试的应聘者就能够应付工作中的英语交流。如果测试的内容与航班工作过程所需要的英语有很多不同,那么试卷的内容就不能够反映测试目标,测试就缺少内容效度。
下面我们再举一个例子。
请阅读下面的文字,这是个阅读理解题目,还是一个语法题目?
Modern airplanes have two black boxes:a voice recorder,which tracks pilots.conversations,and a flight-data recorder,which monitors fuel levels,engine noises and other operating functions that help investigators reconstruct the aircraft' final moments.Placed in an insulated case and surrounded by a quarter-inch-thick panels of stainless steel,the boxes can withstand massive force and temperatures up to 2,000 ℉.
What is the subject of“engine noises”?
A.Modern airplanes
B.Two black boxes
C'A voice recorder
D'A flight-data recorder
如果认为该题目是阅读理解题目,那么它的内容效度就比较低,甚至可以说没有内容效度。原因很简单,无论被测试者作答正误,都不能测试出他的阅读理解能力;如果该题目是语法题目,那么,它的内容效度就比较高,能够考查出被测试者的语法识别能力。
那么,测试者如何确保内容的高效度呢?如何保证测试内容的高效度呢?王晓军(2006)认为,需要做到以下三点。
(1)测试内容要符合测试目标。命题前要根据考试大纲、教学内容和教学目标拟订好测试内容,制订详细明确的考试细目表,然后按这个细目表去编制具体的试题。
(2)考试内容要适合测试对象,题目不能太难或太易。
(3)试题编制好后,要请有经验的教师或专家审定,保证测试内容的全面、合理。
尺度关联效度(criterion-related validity)包括预见效度(predictive validity)和共时效度(concurrent validity)。休斯(1989)认为,尺度关联效度主要指的是本测试与某一个“独立并且相当可靠的学生能力测量工具”之间的关联程度。“可靠的能力测量工具”就是这里的“尺度”。
杨钟琳(1992)认为,这个“尺度”可以是信度、效度,已经经过检验的正式考试或地区性的会考,也可以是责任心强并富有教学经验而又熟悉教学对象的任课教师,根据自己的记录、观察给学生打出的分数或名次排队。
那么,如何具体地理解尺度关联效度呢?我们举例来加以说明:
我们将标准测试A作为“尺度”,自行设计测试B,然后以标准测试A作为“尺度”来检验自己设计并定命测试B。具体的做法是,首先通过具体做法是标准测试A进行测试,然后使用测试B进行测试,进而对两次测试的结果进行尺度关联比较,根据比较的结果对
对测试B进行修订,产生测试B’。然后比较测试B’的成绩与标准测试A的成绩的关联关系。如果相差较大,则说明相关性小,如果差别不大,则说明相关性大。
前面已经讲到,尺度关联效度包括共时效度和预见效度,下面分别阐述。
1.共时效度
对于,共时效度(concurrent validity),奥尔德森(1995)认为,比较同时或时间相隔很近的情况下同一批被测试者的两次测试结果的关联程度。如果关联程度较高,则说明两次测试具有共时效度,否则,如果关联程度较低,则说明本次测试缺乏共时性。奥尔德森进一步指出,关联程度可以用效度相关系数(validity coefficient)表示,效度相关系数的取值在 0.5 ~ 0.7 之间。
仍然以上文的例子为例:
我们自行设计的测试B,将标准测试A作为“尺度”,然后让同一批学生在时间间隔较短的两个时间段(比如上午与下午)先后作答两项测试题,进而比较两组的成绩,如果他们之间表现出较高的一致性,就表明测试B具有较高的共时效度,反之,则说明测试B缺乏共时效度。
共时效度经常被用于将新设计好的测试题与已经发展成熟或标准化的测试相比较,从而确定新测试的效度。
2.预见效度
预见效度(predictive validity)与共时效度的相同之处是,都是建立在两次测试结果的分析之上,但是,与共时效度不同的是,两次测试的间隔时间较长。
奥尔德森(1995)认为,预见效度主要是通过比较被测试者目前成绩与未来成绩的比较来显示测试B是否能够预测被测试者未来学绩。我们说某项测试有预见效度,就是说这项测试能比较正确地预见到考生以后的语言能力的发展。
萧春麟,刘清华(2001)也对关联系数进行了探讨,指出两份试卷的统计效度可用关联系数(0 ~ 1)表示。1 表示完全相关;0 表示完全无关。0.9 以上为关系非常密切,0.7 ~ 0.9 为关系密切,0.4 ~ 0.7 为关系一般,0.2 ~ 0.4 为略有关系,0.2 以下表示几乎没有关系。事实上,不大可能出现系数为 1 或 0 的试卷。
艾伦·戴维斯(Alan Davies,1998)认为,信度(reliability)是指对测试事先所做的判断与测试结果之间的一致性;休斯(1989)更通俗地表述了信度,认为信度是考试分数的一致性(consistency of test scores)。换句话说,用同一份试卷对同组考生施考两次以上,如果他们各次的考分基本一致,或者虽有变化,但变化不大,那就说明该测试有较高的信度。信度包括考试信度(test reliability)和评分者信度(Scorer Reliability)。
一般认为,可用使用三种方法确定考试信度,分别是重复测试法(test-retest method)、平行卷测试法(parallel-form method)和对半分析法(split-half method),下面我们分别进行介绍。
1.重复测试法
重复测试法是指让同一组学生重复作答同一份试卷来确定试卷信度的方法。它的基本规则是,如果两次测试的分数较一致,则该试卷信度较高。
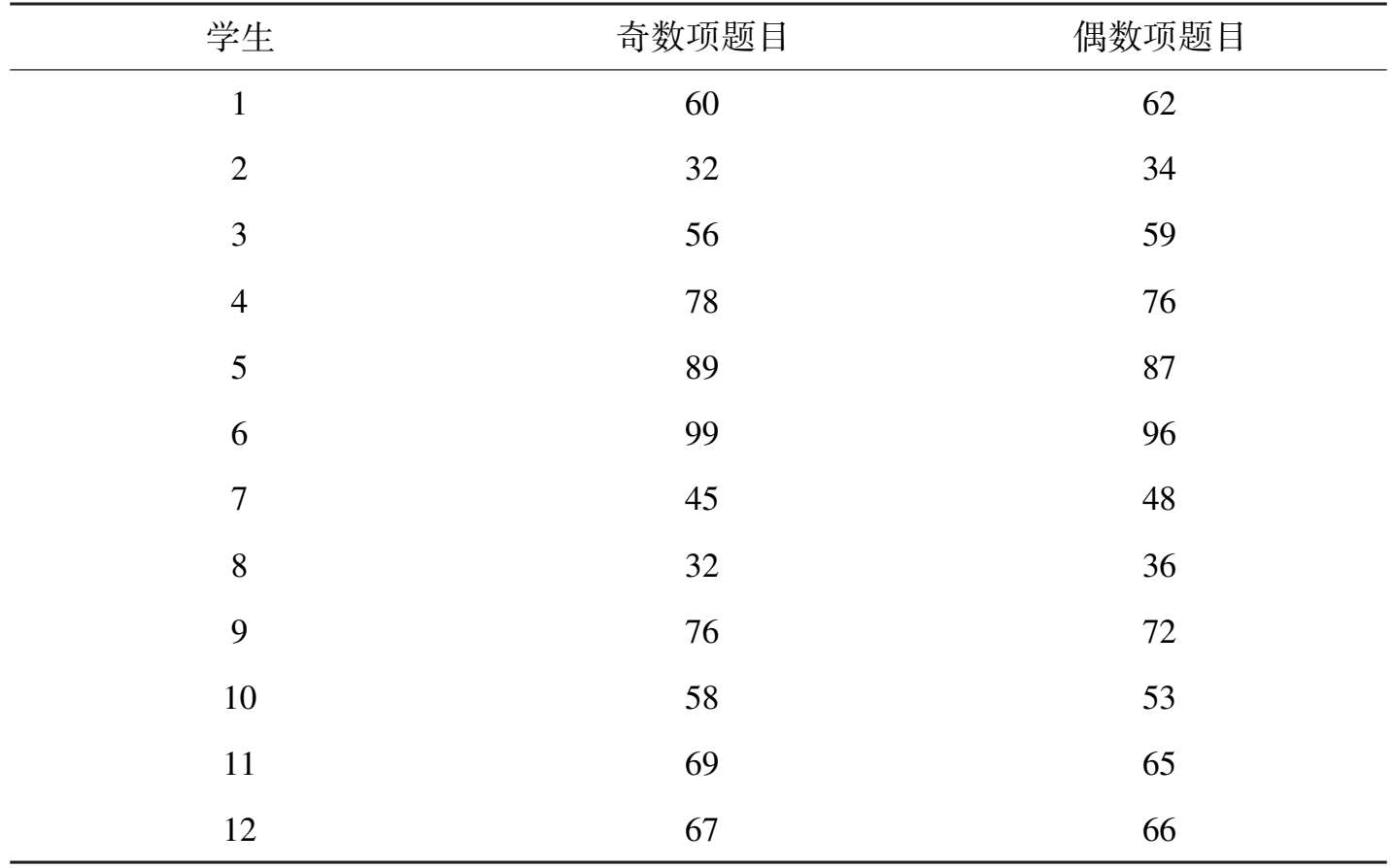
我们举例来说明。假定我们采用同一张试卷A,满分 100 分,分别在周一上午、周五上午(我们假定时间间隔因素的影响较小),让同一组(共 12 名学生)作答,其得分统计如表 3-1 所示。
表 3-1 某试卷A得分统计表
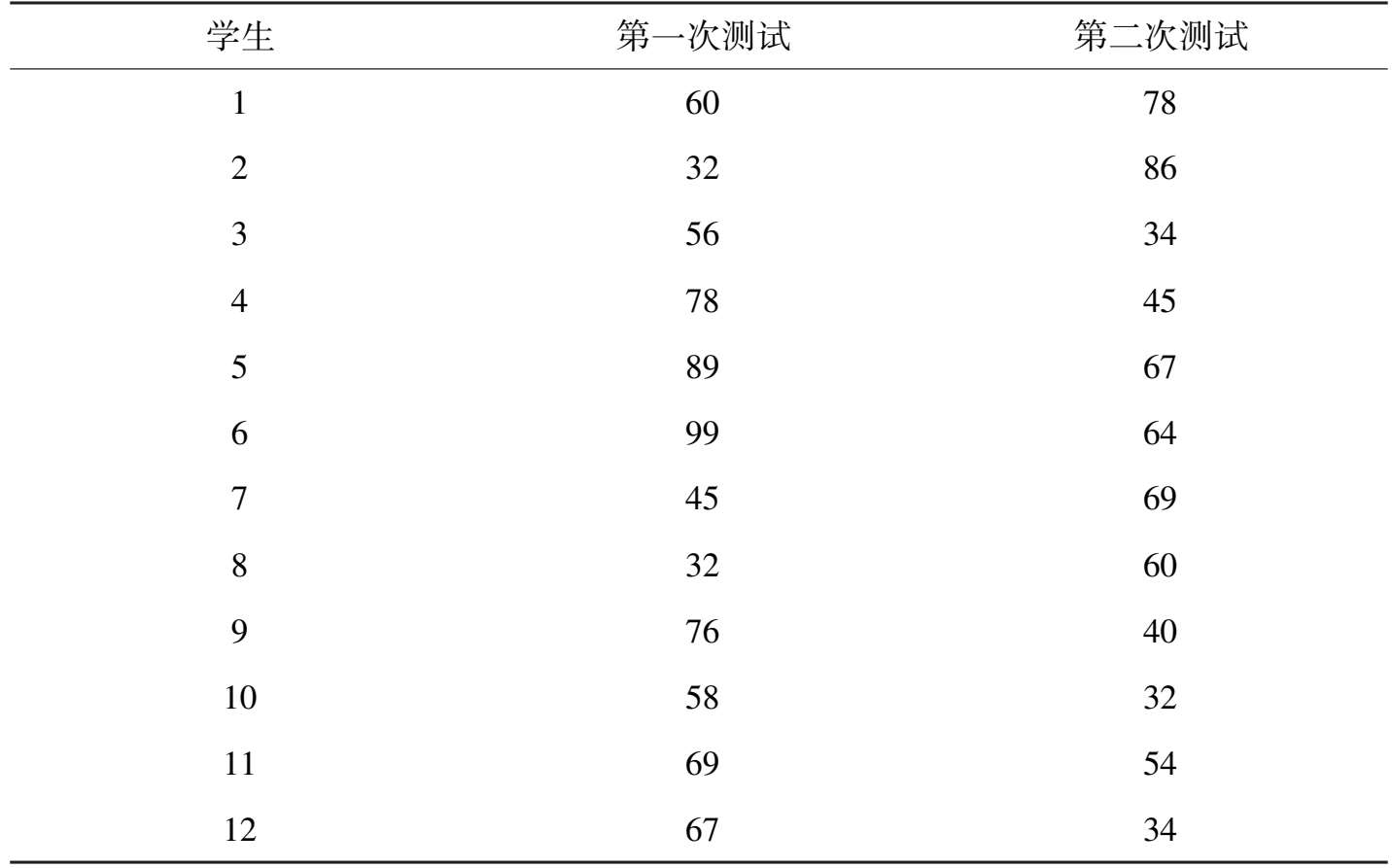
从上表中可以看出,考生在两次考试中的成绩差别较大。说明试卷A的信度较低。这是对信度的单独判断。
我们再来看另外一个例子,假定我们采用同一张试卷B,满分 100 分,分别在周一上午、周五上午(我们假定时间间隔因素的影响较小)让同一组(共 12 名学生)作答,其得分统计如表 3-2 所示。
表 3-2 某试卷B得分统计表

从上表中可以看出,考生在两次考试中的成绩差别不大。说明试卷B的信度较高。这也是对试卷B的信度的单独判断。
如果我们将上述两表合并起来进行比较,可以得出的结论是:试卷B较试卷A的信度高。这对我们选择试卷有一定的指导意义。
关于重复测试法,以下两点需要格外注意。
(1)该方法的准确性受时间间隔的影响较大。比如时间间隔的长短,如果时间较短,则学生可能记题、第一次测试后可能搜集答案;如果时间过长,则学生可能学习新知识,同时可能忘记一些在第一次测试时能够记忆的知识。
(2)心理因素的介入使得重复性测试方法在逻辑上存在障碍。我们知道,人的心理状态,包括生理状况、心理状况以及身心健康等都影响一个特定人在测试中的正常发挥。甚至,自然环境的变化都会影响到一个人的心情或精神状态,进而影响他在测试中的发挥。比如,如果我们第一次测试是在周一举行,而周一天气凉爽,比较舒服,学生A心情舒畅,在测试中发挥较好,甚至超常发挥;而第二次测试的周三,是一个炎热的天气,气温高、天气闷,学生A心情比较烦躁,在测试中没有发挥应有的水平。这样必然影响重复测试方法的准确性。
当然,测试者可以通过一定的技巧来减轻这些影响。例如,控制相隔时间内学生的学习内容,以保证学生在前后两次测试时学习进展(至少对于测试本身)是相一致的;可以通过一定的方法减轻记忆力因素的影响,比如调整选项的顺序等。
2.平行卷测试法
平行卷测试法。戴维斯(1998)认为,为了观察测试的信度,最有效的方法是编制一套测试的副本,通过样本来观察测试的结果。一次信度很高的测试,其两次测试的情况应是高度吻合的。在现实操作中,我们通常使用AB卷的形式,即设计一套形式和内容与原试题平行的试题,让同一组学生在连续时间内或时间间隔极短时间内分别作答这两套试卷,然后根据测试的结果,确定两次测试的相关性。如果两次测试的结果一致性较高,则我们说A卷(我们假定副本为B卷)信度较高,反之,则A卷信度较低。
我们举例来说明这个问题。假定我们采用试卷A、试卷B(二者为预先设计好的平行试卷),满分 100 分,分别在周一上午、周一下午(假定时间间隔因素的影响较小),让同一组(共 12 名学生)作答,其得分统计分别如表 3-3 和 3-4 所示。
表 3-3 某试卷A得分统计表
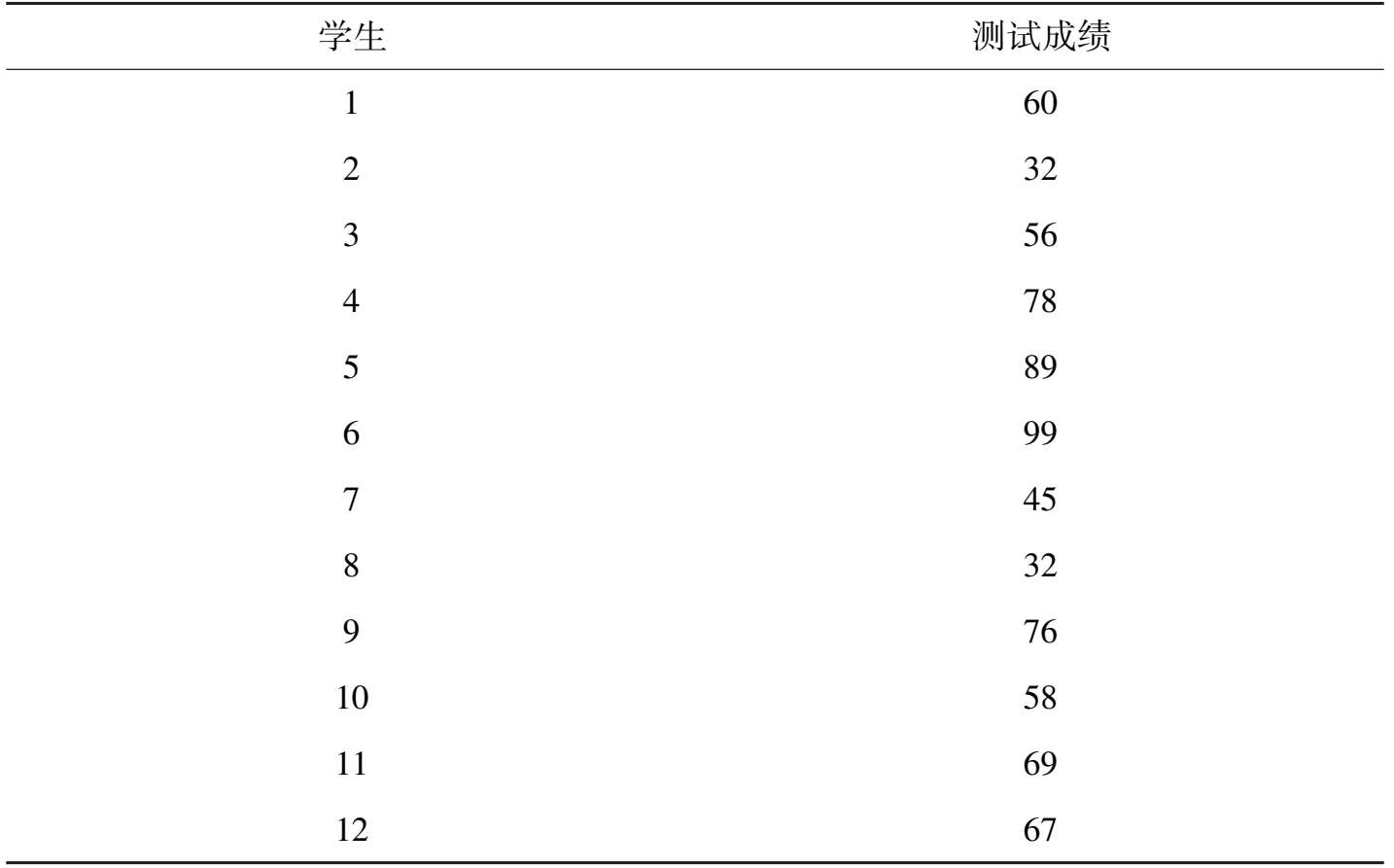
表 3-4 某试卷B得分统计表
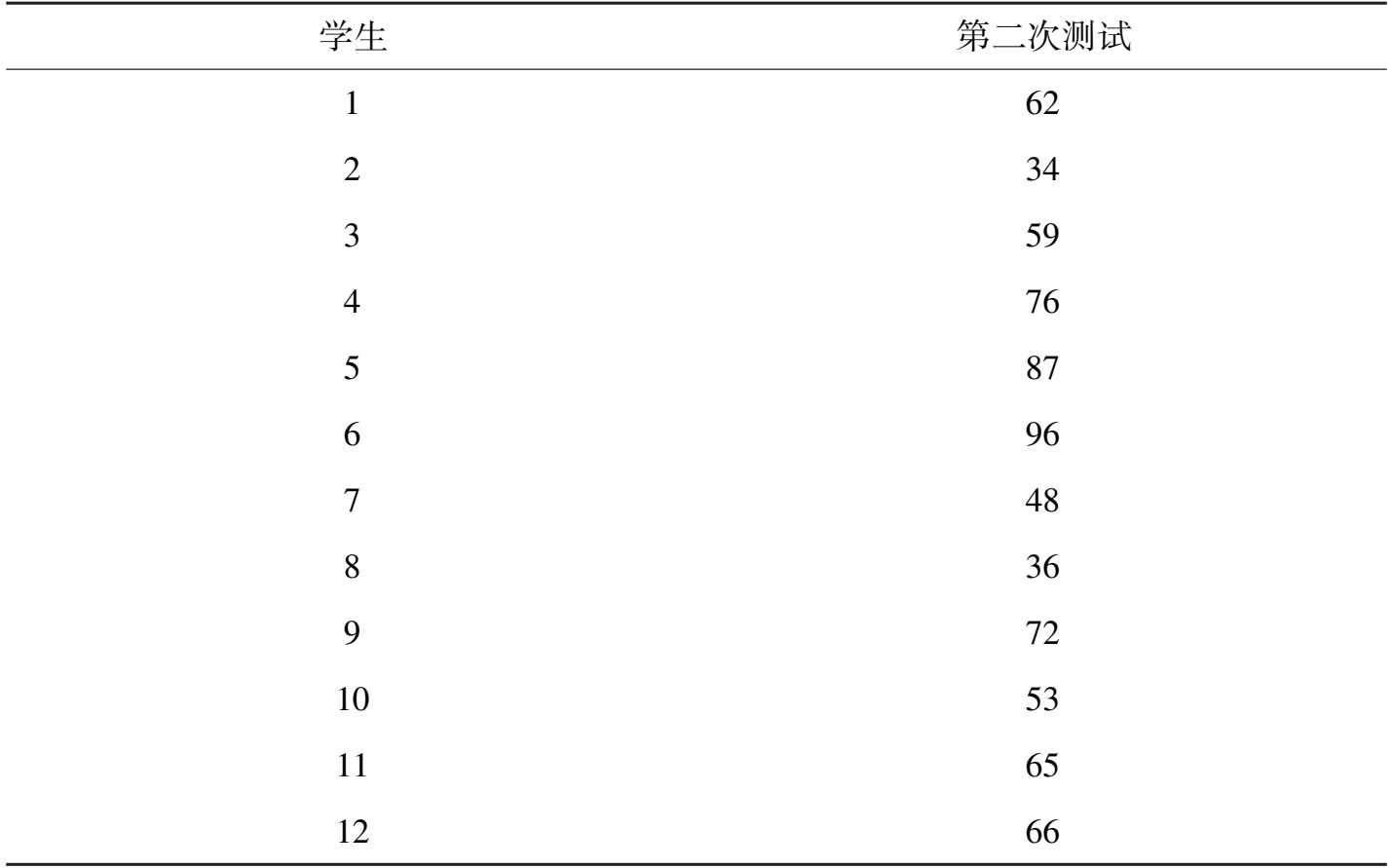
从统计结果中可以看到,考生的AB卷得分的差别较小,趋于一致性,因而,我们得出结论:试卷A的信度较高。
平行卷测试法较重复测试法更准确,但是它的困难之处在于,A、B卷如何制作才能确保完全相同。重复测试法是使用相同的试卷,因而不存在这个问题,但是平行卷测试使用两份具体内容不同,但是测试实质相同的试卷,因而对如何制作要求就较高。就如同戴维斯(1998)所说的那样,“从语言的角度来看,人们却很难保证一次测试的内容与另一次测试的内容,是完全相等的。”
我们不妨拿下面的例子来说明这个问题:
(1)杰克逊在听音乐。杰克逊在听什么?回答:……。
(2)杰克逊在听新闻。杰克逊在听什么?回答:……。
即使是在这样的平行项目中,音乐与新闻的不同,就足以给考生带来困扰。那么,在更加复杂的平行试卷测试中,隐含的信息如此丰富,考生所遇到的麻烦会更大。如果考生不能很顺利地绕过这些麻烦,那么平行试卷就不那么平行了。
3.对半分析法
对半分析法。戴维斯(1998)认为,可以只进行一次测试,但在具体操作时使它看起来像有两次测试,两份试卷,并希望测试的结果是一致的。这种测试,就是把一次测试分为两次来进行,而两部分测试是相关联的,然后用相关联的测试情况来体现试卷的信度。
实际操作中的做法是,将一份试卷内的题目按奇偶数进行排列,这样就形成一分为二的局面,即奇数题目一半,偶数题目一半。然后通过分析两个相对独立且相应的部分得分分数的比较获得整份试卷的信度(Hughes1989:33)。两个部分分数的一致性越高,试卷的信度也就越高。反之,则较低。
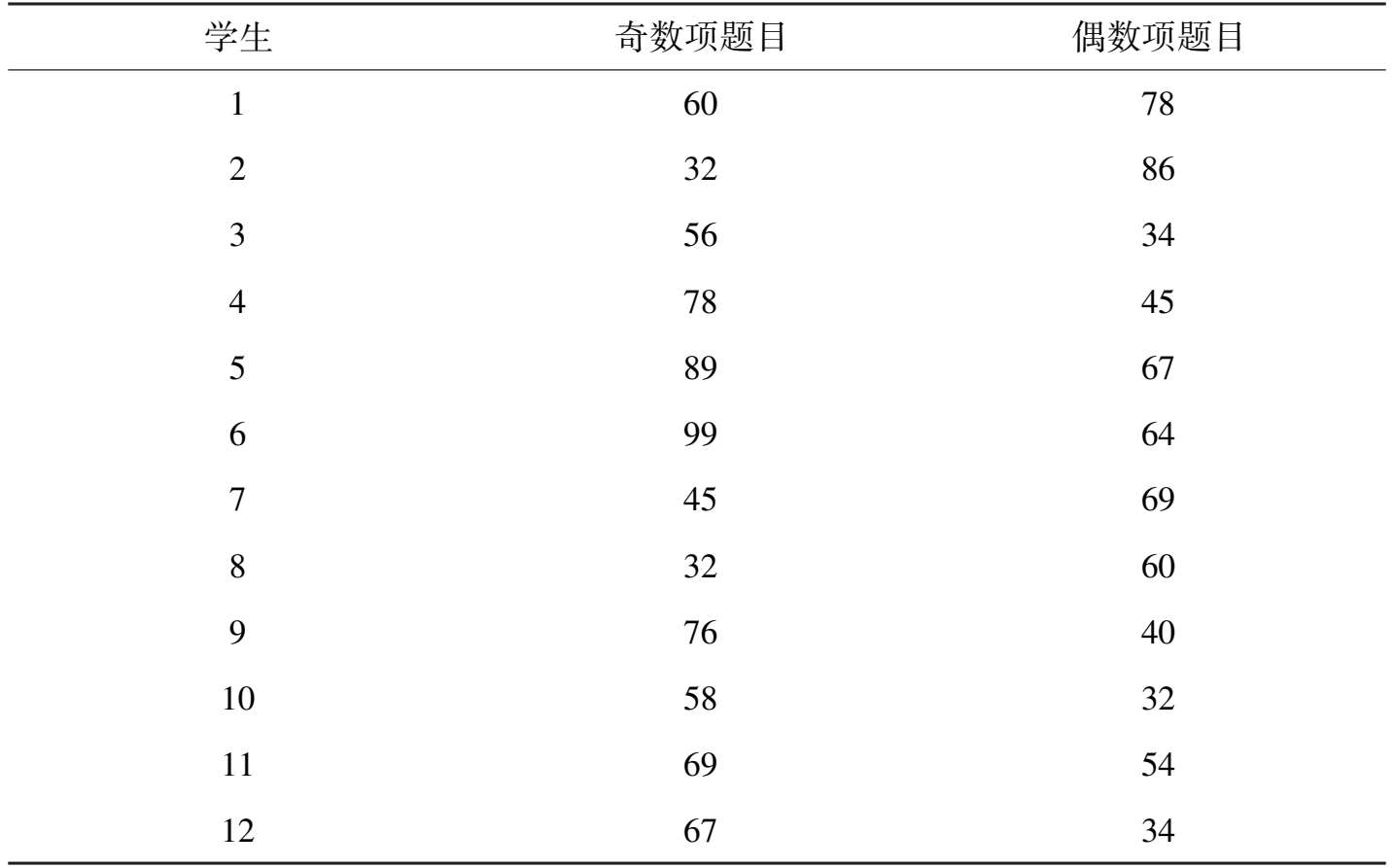
我们仍然举例来说明这个问题。假定我们采用试卷A(假定为预先设计好的适合用于对半分析的试卷),满分 100 分,一共 100 道题目,每道题目 1 分;奇、偶题目分别为 50 道,在周一上午,让一组(共 12 名)学生作答。如果得分统计如表3-5 所示,那么从表格中的统计数据可以看到,同一学生奇数项的得分与偶数项的得分差别较大,则我们说,试卷A的信度较低。
表 3-5 某试卷A得分统计表
如果统计结果如表 3-6 所示,那么从表格中的统计数据可以看到,同一学生奇数项的得分与偶数项的得分差别不大,趋于一致性,则我们说,试卷A的信度较高。
表 3-6 某试卷A得分统计表
但是,问题在于,很难有一个行之有效的方法将一份试卷恰如其分地分为两个部分。如何解决这个问题,是正确运用对半分析法的关键所在。
信度是可以加以量化的,这是测量学发展的结果。信度量化的指标就是信度系数。信度系数是指两次或多次测试结果之间的关联度。相关程度越高,信度系数越大,因而信度也越大。
客观性题目的信度系数可达到l;主观性题目的信度系数受阅卷人员主观因素的影响,因而信度系数相对低一些。
下面我们分别讲述重复性测试法、平行卷测试法以及对半分析法涉及的信度系数公式。
(1)在重复性测试法中,重测信度也称稳定性系数,是指用同一个测验,对同一组被试前后施测两次,对两次测验分数求得的相关系数。其计算公式一般采用皮尔逊积差相关公式的变式:
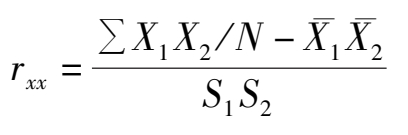
式中X
1
、X
2
为同一被试的两次测验分数,
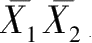 为全体被试两次测验的平均数,S1、S2 为两次测验的标准差,N为被试人数。
为全体被试两次测验的平均数,S1、S2 为两次测验的标准差,N为被试人数。
(2)在平行卷测试法中,复本信度(Alternate Form Reliability)也称等值性系数(Coefficient of Equivalence),是指用两个平行(等值)的测验对同一组被试施测,得到两组测验分数,求得的这两组测验分数的相关系数。计算方法与再测法是一样的。
(3)在对半分析法中,分半信度(Split-half reliability)是指将测验题目分成等值的两半,分半求出量表题目的总分,再计算两部分总分的相关系数。
这里存在一个校正的过程,采用的公式为Spearman-Brown Formula:
r
xx
=
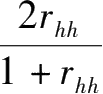 公式中,r
hh
是两半测验分数的相关系数,r
xx
为整个测验的信度估计值。
公式中,r
hh
是两半测验分数的相关系数,r
xx
为整个测验的信度估计值。
对半分析实际上是对测验内部一致性的一个粗略估计。但对于同一个测验分半的方法是很多的,而且用不同的分半方法求出的分半信度都不一样,因此分半信度不是最好的内部一致性的估计。为了弥补分半法的不足,可以采用其他的方法。常见的是Kuder Richardson Formula。
库德(Kuder)、理查逊(Richardson)针对分半分析法的不足,提出以项目统计量为转移,利用项目统计量来计算信度。称为K-R 20 公式:
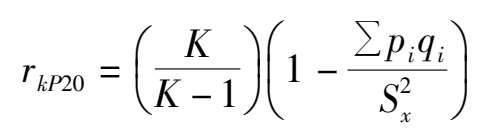
式中k表示构成测验的题目数,
p
i
为通过第i题的人数比例,
q
i
为未通过第i题的人数比例,
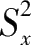 为测验总分的变异数。
为测验总分的变异数。
当测验项目难度接近时可以采用库德-理查逊提出的一种简便公式,称为K-R 21 公式:
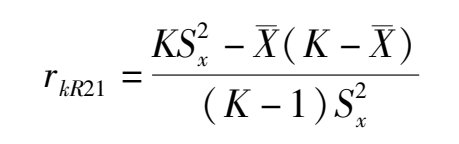
式中k表示构成测验的题目数,
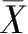 为测验总分的平均数,
为测验总分的平均数,
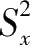 为测验总分的变异数。
为测验总分的变异数。
但是,库德-理查逊公式只适用于两级记分的测验,而对多级记分的测验,则可以采用克伦巴赫(Cronbach)的α系数,克伦巴赫的α系数对两级记分的测验也是适用的。其计算公式为:
α
=
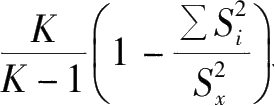 式中,K为测验的题目数,
式中,K为测验的题目数,
 为某一测验题目分数的变异数,
为某一测验题目分数的变异数,
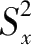 为测验总分的变异数。
为测验总分的变异数。
评分者信度是指随机抽取部分试卷,由两个或多个评分者独立按评分标准打分,然后求其间的相关,所得的相关系数。
希顿(Heaton,1988)认为,评分者信度包含以下两层含义。
(1)不同的评卷人在相同的时间内评卷,评阅分数大致相同。
(2)同—个评卷人在不同的时间内评卷,分数也大致相同。
武尊民(2011)认为,评分者信度包括评分员信度和评分员自身信度。其中,评分员信度是不同评分员是否对评分标准有相同的理解与掌握尺度;而评分者自身信度,王振亚(2009)认为评分人内部(intra—rater reliability)信度,则是指同一评分员对评分标准的掌握是否稳定可靠。
评分者信度可以进行量化计算,下面我们根据评分者人数的多少介绍其计算公式。
1.评分者为两个人时
若是连续变量的评分,且分布是正态,则可用计算机直接计算皮尔逊积差相关系数。若是等级评定或虽是等距或等比的数据,但分布非正态,则计算斯皮尔曼等级相关,斯皮尔曼等级相关公式:
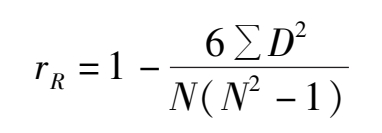
式中D为各对偶等级之差,. D 2 是各D平方之和,N为等级数目。
2.评分者为多个时
采用肯德尔和谐系数(Kendall coefficient of concordance)来估计信度系数。
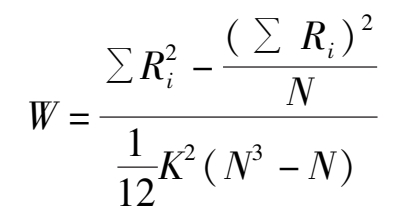
式中,W为和谐系数,K为评分者人数,N为被评对象数,R i 为每一对象被评的等级之和。
影响信度的因素有很多。刘润清(2000)曾对此作过生动的描述:
影响信度的因素很多。例如,举行测验的时间和环境。早晨举行的测验可能比晚正进行的测验得分高一些。在安静、舒适的环境进行的测验可能比在又脏又乱又吵的环境进行的测验得分高一些。需要使用录音机的测试,分数变化会更大:录音是否清楚,耳机工作是否正常,周围有没有噪音等。学生中的个人因素也很重要:情绪高诋,是否疲倦,有无头痛发烧等。不过,最主要的因素有两条。一是题目的覆盖面是否够大,是否有代表性,项目是否均匀……与此有关的另一个因素是评分。如果不同评卷人会得出不同的分数,或者同一评卷人两次评阅中可得出不同的分数,那么这套试题的信度也就较差。
从上文的描述中可以看出,影响信度的因素主要包括三个:测试自身、考生以及评卷人。因而,我们提高测试信度也应当从这三个方面进行。
1.从测试自身方面提高测试信度
(1)应当有足够量的题目。试卷只有保证有足够量的题目,才能保证考试行为的样本覆盖面足够宽。但是这并不是说题目越多越好。而应当考虑考试的时间,合理设计出题目的数量。
(2)题目的那难易度应当适中。题目过难还是过易都会严重影响测试的区分度,进而影响测试的信度。海宁(2001)曾经指出,“A test should never be selected or developed without due consideration of the abilities and other characteristics of the intended examinees。”因而,我们在设计试卷时,一定做到有的放矢,合理估计学生的水平。
(3)题目的区分度应当明显。一般的规律是,试题的区分度越高,则信度越高。没有区分度的题目一般与过难与过易相关联。
(4)题目的设计应当明确,设问应当准确清晰,不能由歧义;作答要求应当简明扼要;试卷本身的打印应当清晰,排版正确,适合学生阅读。
2.从考生方面提高测试信度
(1)考生应当事先对考试哪门科目、考试的大致范围有所了解,这有利于其做好心理准备,以便在考试中能够正常发挥。
(2)考生应具备必要的考试技巧,这是参加测试的基础。试想,一个发挥再好的考生,如果对时间把握不准,导致答题卡填涂不完,则必然影响测试的结果。
(3)考试过程中,考生应当具备排除一些非正常因素的干涉。比如,窗外知了的鸣叫;屋外下雨的声响等。
3.从评卷人方面提高测试信度
休斯(1989)认为,要保证较高的评卷信度,应当注意以下几个方面。
(1)尽量使用评分标准客观的试题。
(2)尽量对考生行为做直接对比。
(3)提供详尽的答案。
(4)培训评分员。
(5)统一评分标准。
(6)糊名制。
(7)多人独立评分制。
从实践中看,休斯提出的以上d这些措施基本上已经被广泛使用。例如,提供详尽的答案,同一评分标准等。
客观地讲,真实性(authenticity)原则并不是英语语言能力测试与生俱来的原则,而是英语语言能力测试发展到重交际能力考查阶段所产生的原则。从这个意义上讲,真实性原则是一个“新生”的原则。
什么是英语语言能力测试的真实性原则呢?或者说如何理解“真实”的含义呢?自 20 世纪 80 年代以来,英语语言能力测试学界从未停止对此问题的探讨。
曾经有一段时间,人们认为真实性等同于直接性(directness),即测试不经过任何中介而得以测量被测试者的特定语言能力。这种认识的偏见之处在于,没有明确类似语言能力这样的人的心理结构是不能直接被测试或考查的。
一部分英语语言能力测试专家认为,真实性就是英语语言能力测试环境与现实生活的相似程度。与现实生活的相似程度。但是,现实生活的复杂性,使得任何精心设计的测试都不能达到相似的程度,更不用说相同。
另外一种观点将真实性和测试的表面效度(face validity)等同起来,但是,我们已经讲到测试的表面效度是评估者的主观判断。将真实性等同于表面效度无疑是不正确的,也是不可取的。

Spolsky(1985)summed up this issue as follows:“In sum,the criterion of authenticity raises important pragmatic questions in language testing.Lack of authenticity in the material used in a test raises issues about the generalizability of results.”
巴克曼和帕尔默(1996)认为,真实性指某一英语语言能力测试任务与实际语言运用任务在特征方面的对应程度,即一致程度。并指出应当从以下两个方面理解真实性的含义。这两个方面为具体介绍如下。
1.情景真实性
情景真实性(situational authenticity)。所谓情景真实性,就是指测试的内容应当与现实生活中真实使用的情景相类似。也就是说,我们设计的测试任务必须与将来目的语使用的情景特征相一致。
举例来说,假定我们设计的测试是考查被测试者的英语导游从业资格能力。因为参加英语导游从业资格考试的人员在其工作中应当具有与游客用英语面对面交流的能力,我们在设计测试时,在其中的口语测试中设置考生之间就某一景点介绍进行面对面交流的环节,那么该口试就具有很强的情景真实性。
2.交际真实性
交际真实性(communicative authenticity)指的是被测试者在完成某一测试任务中,其语言能力参与测试的程度。它揭示的是被测试者与测试任务之间的交际关系。强调“真实性不一定反映在语言运用实景中,而是应该体现在考试是否真正测试了构成语言能力的那些特征”(邹申,2000)。
巴克曼和帕尔默(1996)进一步提出了提高英语语言能力测试交际真实性的四项措施。
(1)提出要求。在设计考题时可以具体说明考生只有使用何种策略才能完成该任务。
(2)提供机会。即给考生提供充足的时间、必要的信息和工具等。
(3)考试任务要得当。任务太难,会影响考生策略的应用。
(4)考试任务要有趣味性。通过提高考试任务的情景真实性可以提高考试任务的趣味性。
正是对上述观点的不同坚持,产生了当今英语语言能力测试界在测试真实性问题上的两大派系。一派只坚持情景真实性;另一派只坚持交际真实性。
与真实性原则相类似,互动性(interactiveness)原则也不是与生俱来的原则,而是近年来随着重交际、重参与、重互动的教学方式的发展在英语语言能力测试领域的客观要求或需求。
武尊民(2011)认为,交互性指考生在完成试题时,个人的语言知识、元认知策略、专业知识以及情感因素互相作用的程度。
巴克曼和帕尔默认为,交互性指被试者在完成一件测试任务(test task)时所涉及的个人特征类型(individual characteristics)及程度。 [1]
与英语语言能力测试最有关的个人特征主要有语言能力(language ability)、话题知识(topical knowledge)以及情感图式(affective schemata)。其中,语言能力又包括语言知识(language knowledge)、策略能力(strategic competence)或称元认知策略(meta cognitive strategies)。三者之间的关系如图 3-1 所示。
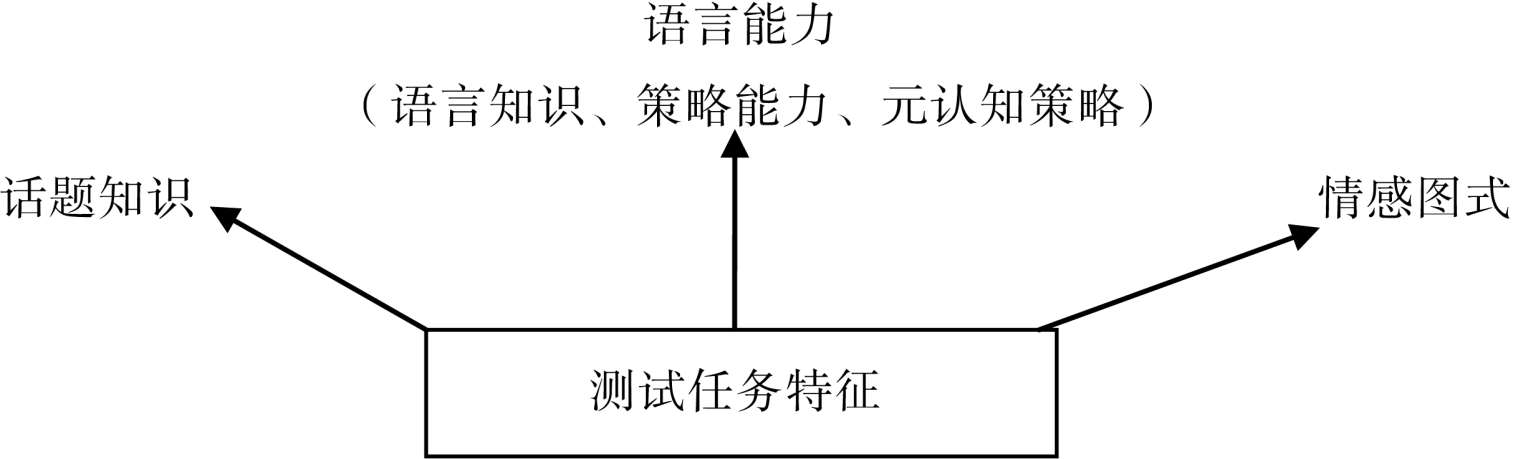
图 3-1 语言能力、话题知识、情感图式的关系示意图
(资料来源:阎少云,2001)
一般的规则是,考生参与程度越高,考试的相互性也就越强。
举例来说,试比较下面两道题目的交互性的强弱:
第一道题目:
Directions:
You will hear three pieces of recorded material.Before listening to each one,you will have time to read the questions related to it.While listening,answer each question by choosing A,B,C or D .After listening,you have time to check your answers .you will hear each piece once only.(10 points)
questions 11—13 are based on the following talk about napping,you now have 15 seconds to read.
1.Children under five have abundant energy partly because they_____________.
A.sleep in three distinct parts
B.sleep in one long block.
C.have many five—minute naps
D.take one or two naps daily.
2.According to the speaker,the sleep pattern of a baby is determined by____________.
A.its genes
B.its habit
C.its mental state
D.its physical condition
3.The talk suggests that,if you feel sleepy through the day。you should____________.
A.take some refreshment.
B.go to bed early
C.have a long rest
D.give in to sleep.
答案:1.D;2.A;3.D
(资料来源:2003 年全国硕士研究生英语测试题)
第二道题目:
Directions:
You will hear three sentences,please write down the word(s)that is suitable to the bracket.
1.Children under five have abundant energy partly because they take one or two________________.daily
2.According to the speaker,the sleep pattern of a baby is determined by its ______________.
3.The talk suggests that,if you feel sleepy through the day。you should to sleep.
答案:1:naps;2:genes;3:give in
通过比较以上两个题目,我们可以看到,第一个题目对听力能力的要求较高,不仅需要考生听懂短文,而且要辨别选项之间的异同,需要考生对短文有较高的把握;而第二个题目,并不要求考生对短文有什么了解,而只要对三句话中空白处的词语听清楚就可以完成测试任务。我们可以得出的结论如下:第一道题目得分交互性较高;而第二道题的交互性较低。
此外,影响考试的交互性的因素还包括测试的目的与用途,不同的测试目的与用途在一定程度上决定了交互性的高低。
对于测试的冲击力,有的学者称之为测试的后效作用(washback effect)(邹申,2000),或者英语语言能力测试的“回波效应”、反拨效应,是指“英语语言能力测试对教与学所产生的影响”(Hughes,1989)。
但是,也有的学者对这些概念加以区分,比如巴克曼和帕尔默(1996)认为英语语言能力测试界原来所说的“回波效应”应当放在测试冲击力的框架内来讨论。特纳(Turner,2001)也认为在普通教育中最好使用“冲击力”而不是“回波效应”。
在这里我们认为,这些概念在本质上是等同的,对其进行区分没有太大的意义,“回波效应”本身的含义完全可以涵盖冲击力,至少对其进行合理的扩大解释就能实现这个目的。同样地,“反拨效应”的含义也完全能够扩展到冲击力的范围。在这种情况下,对他们进行区分,就显得没有太大的必要了。
因而,我们在此不对诸概念加以区分,但所要把握的是:测试具有反作用,这个反作用可能是积极的,也可能是消极的。
巴克曼和帕尔默(1996)将测试的冲击力分为两个层面:宏观与微观。
宏观方面的反作用指的是测试对整个社会教育制度甚至整个社会的影响。这种影响主要表现在以下几个方面。
(1)测试对社会教育制度、政策,对教育改革的影响。
(2)测试对国家考试制度的影响。
(3)测试对国家考试制度的影响。
(4)测试对学校教育的影响。例如,学校教学的计划、内容,教学的改革等的影响。
(5)测试对人们价值观、人生观的影响。
(6)测试对职业类型、门槛等的影响。
微观方面的反作用是指测试对受到测试影响的群体的影响。这种影响主要表现在以下两个方面。
(1)测试对考生的影响。
(2)测试对教师的影响。
这里需要强调的是,无论是宏观方面,还是微观方面,这里的影响都包括积极影响与消极影响两个方面。
我们在测试设计的过程中需要遵循的原则就是,积极冲击力的最大化,消极冲击力的最小化。
可操作性(practicality)又称可行性。这一原则是由英语语言能力测试的兴之所决定的。我们知道,英语语言能力测试从本质上说是一种工具性的科学。我们设计的测试如果没有可操作性,那么就完全违背了英语语言能力测试的工具性特征。
巴克曼和帕尔默认为,考试的可操作性是控制考试质量和操作实施的因素。
武尊民(2011)指出,为某一目标而设置的考试在充分考虑到效度和信度问题后,还要考虑到可行性问题。并指出,考试可行性问题的决定因素主要包括以下两个。
(1)时间问题。包括考试试卷的设计、编写、考试实施、阅卷以及报告分数等。
(2)财政问题。包括人力资源,即命题人员、监考人员、考务人员、阅卷人员;物质资源,即考试器材、考试场地等。
[1] Lyle F.Bachman.Adrian S.Palmer. Language Testing in Practice .Shanghai:Shanghai Foreign Language Education Press,2000