
下载掌阅APP,畅读海量书库
立即打开



在CTF比赛中,常常采用编码分析题目作为“签到题”。通过设置签到题,可以让参赛队伍熟悉flag格式,增强选手的参与感。而且,几乎所有队伍都可以解出签到题,从而避免零分的出现。虽然这类题目比较简单,但如果基础知识掌握得不牢固,也不容易快速解出。
常见的编码是网络安全的基础知识,几乎在CTF比赛的各类赛题中都会用到,这也是我们把这部分知识放到本书开始来介绍的原因。即使读者不参加CTF比赛,也应该熟悉这部分内容。 本节的重点和难点在于快速识别各种编码以及熟练掌握对应的解码方法 。
本节推荐两个离线解码工具,可以大幅提升学习、比赛和日常工作中的解码效率。
1)Koczkatamas解码工具包,下载地址为https://github.com/koczkatamas/koczkatamas.github.io。
2)CyberChef解码工具包,下载地址为https://github.com/gchq/CyberChef。
Koczkatamas工具包使用方便,但是只能处理标准的编码,对于变形编码和自定义编码就无能为力了。CyberChef工具包功能强大,不仅可以对常见的编码进行解码,还能够对常见的加密算法解密,同时实现多种编码的组合使用。
本节主要以Koczkatamas工具包为例,说明各种编码的解码方法。下载koczkatamas-master.zip文件后,将其解压,双击index.html即可使用。推荐使用Chrome或者Firefox浏览器,用其他浏览器打开可能会报错。第一次运行时,需要在弹窗中选择允许浏览器执行JavaScript代码。
Koczkatamas工具包的主界面如图1.1.1所示。
在第一行(ASCII)输入任意字符串,下面的编码都会随之变化。如果不变化,则说明工具不能使用,建议使用本书自带的离线版工具。DEC表示字符ASCII码的十进制形式,HEX表示字符ASCII码的十六进制形式,OCT表示字符ASCII码的八进制形式。
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)编码(简称ASCII码)是基于拉丁字母的一套计算机编码方案,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,等同于国际标准ISO/IEC 646。

图1.1.1 Koczkatamas工具包的主界面
在计算机中,所有数据都要使用二进制数表示。字母、数字以及一些常用符号(*、#、@等)也要通过二进制数表示,不同的二进制数表示不同的符号。为了约定字符(符号)和二进制数之间的对应关系(也就是编码),美国的标准化组织制定了ASCII码,规定了常用符号用哪些二进制数来表示。
ASCII码的最初构想是用7位(也称为比特,bit)表示一个字符(符号),因此一共可以表示128(0~127)个字符。在后来的使用过程中,人们倾向于用一个字节表示一个字符,一个字节是8位,所以将ASCII码扩展为8位,扩展后的ASCII码可以表示256个字符。标准ASCII码也称为基础ASCII码,使用7位二进制数(剩下的1位二进制数为0)来表示所有大写和小写字母、数字、标点符号,以及在美式英语中使用的特殊控制字符。
CTF比赛中ASCII码的考点
在CTF比赛中,主要考查控制字符(不可打印字符)和可打印字符的范围。控制字符(不可打印字符)的范围是0~31和127,十六进制对应的范围是0x00~0x1F和0x7F;可打印字符的范围是32~126,十六进制对应的范围是0x00~0x7E。
在CTF比赛中遇到可打印字符范围内的字节时,要考虑到将其转化为对应字符。ASCII码的解码方法是:在Koczkatamas工具包中,根据进制把要转换的字符串复制到DEC、HEX或者OCT行,在第一行(ASCII)即可看到对应的字符。
【例题】ascii.txt
【题目来源】 原创。
【题目描述】 找到flag。
【解题思路】 字符串中有数字和字母,字母范围不超过F,推测该字符串表示十六进制数。 在十六进制中,两个字符表示一个字节 ,即两个字符“66”表示一个字节,查ASCII表可知0x66对应字母f。同理,将其余字符按照ASCII码解码,可得到flag{hello_ASCII_666},或者直接将该字符串复制到Koczkatamas工具包的HEX行,即可在第一行(ASCII)看到解码后的字符串。
在扩展的ASCII码中,每个字符用一个字节表示,在不考虑正负号的情况下,一个字节可以表示的范围是0~255(0x00~0xFF),其中0~31以及127~255都是不可打印字符。当传输这些不可打印字符时,很可能出现字符丢失或者转义错误的情况。为了有效地传输和显示这些信息,就 需要把不可打印字符转换为可打印字符 ,Base64编码就是这样一种转换方案。
可以看出,Base64编码本身并不具有加密性和保密性,无法作为加密算法使用 (切记!!!) 。因此, 不要将敏感明文内容进行Base64编码后传输 ,也不建议把Base64编码读作“Base64加密”。
Base64编码使用64个可见字符表示所有数据。其编码原理是把原始数据按 3个字节为一组进行分割 ,再将每组的3个8比特数据切分为4个6比特数据,然后根据Base64编码的标准索引表将6比特数据转换为对应的字符。Base64编码的标准索引表如表1.1.1所示。
注意: Base64编码的标准索引表的字符顺序是大写字母、小写字母、数字、加号和斜杠(/),等号(=)并不在索引表中。
表1.1.1 Base64编码的标准索引表
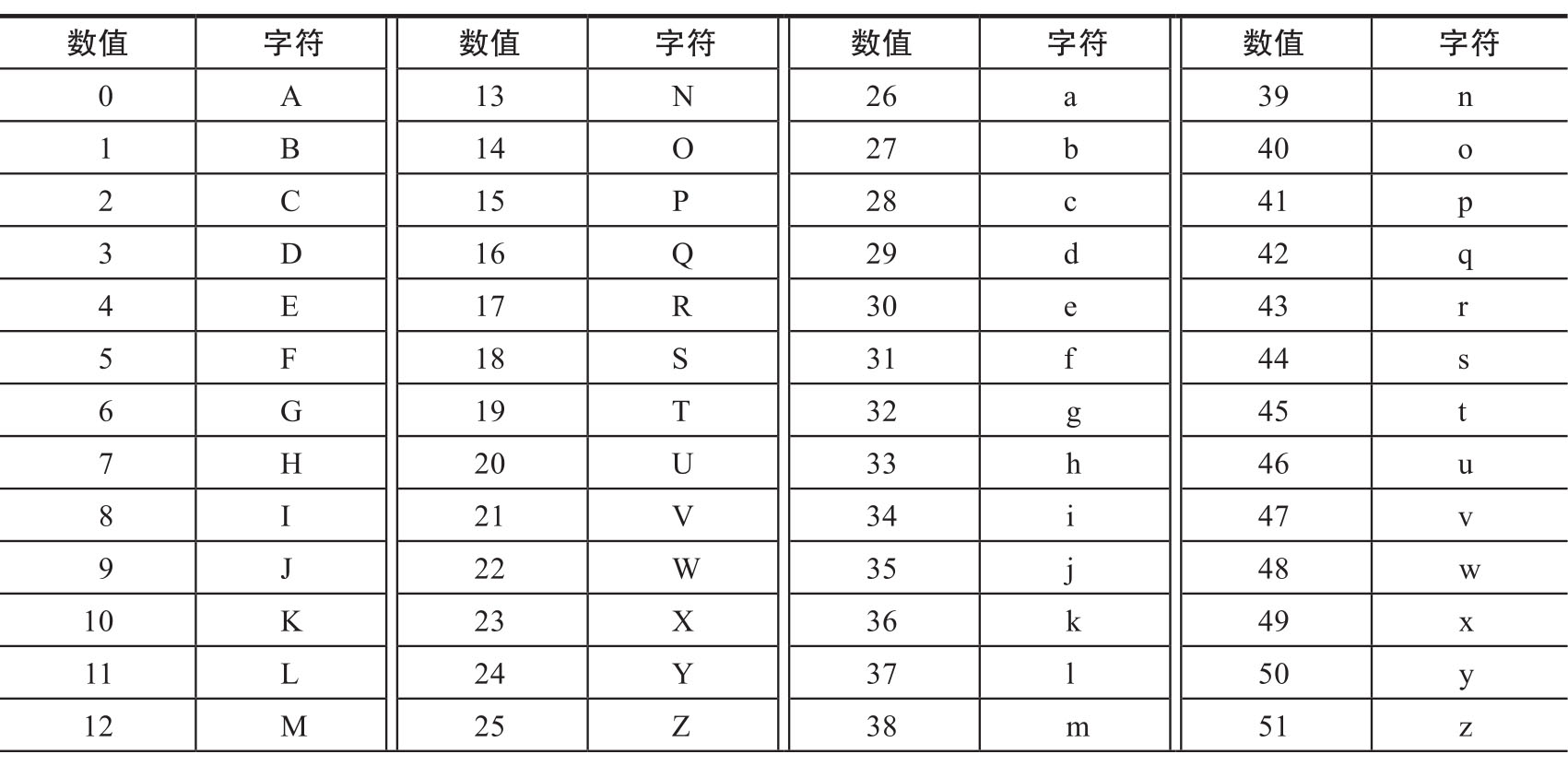
(续)

我们以字符串“fla”为例,展示Base64的编码过程。编码步骤如下所示:

经过上述步骤,字符串“fla”被编码为“Zmxh”。( 这个结果要求背诵并默写! )
但是,在实际转换过程中,原始数据的长度不一定恰好能被3整除,按3字节为一组进行分组后,最后一组会出现只有1字节或2字节的情况。这种情况下,一般默认填充0,使最后一组的长度也达到3字节。下面给出了一个例子。
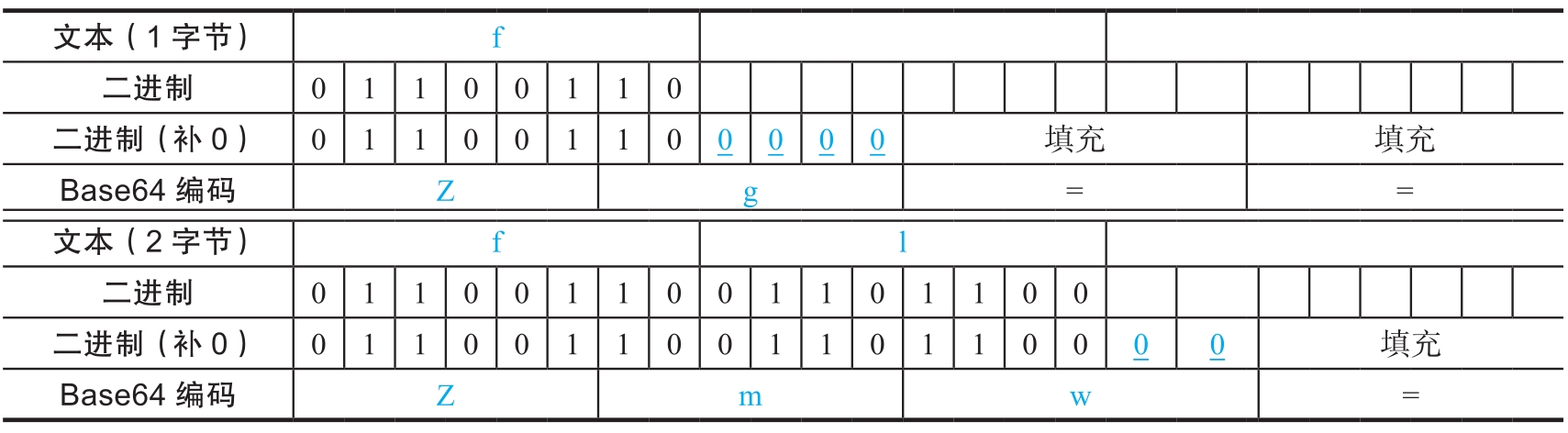
其中,“=”表示填充,如果填充4比特的0,编码后就有2个等号;如果只填充2比特的0,编码后有1个等号;如果没有填充0,就不会有等号。所以, 在Base64编码后的字符串中,最多只有2个等号。
对“fla”进行Base64编码后的结果是“Zmxh”,这个结果需要大家牢记。在很多CTF比赛中,flag的提交格式都是“flag{}”,如果发现“Zmxh”,那么很可能就找到了正确的flag。
Base64的解码过程和编码过程类似,首先查Base64编码的标准索引表,将信息转换为二进制数据,根据等号数量确定丢弃的比特的范围(即上例中的带有下划线的部分,2个等号意味着丢弃4比特信息;1个等号意味着丢弃2比特信息),再以8比特为一组恢复出原始数据。在Koczkatamas工具包中将Base64字符串复制到B64行,即可在第一行(ASCII)看到解码后的内容。
Base64编码的“奇特”考点
在CTF比赛中,有时会考查一个称为“Base64信息隐藏”的知识点。下面给出一个例子。
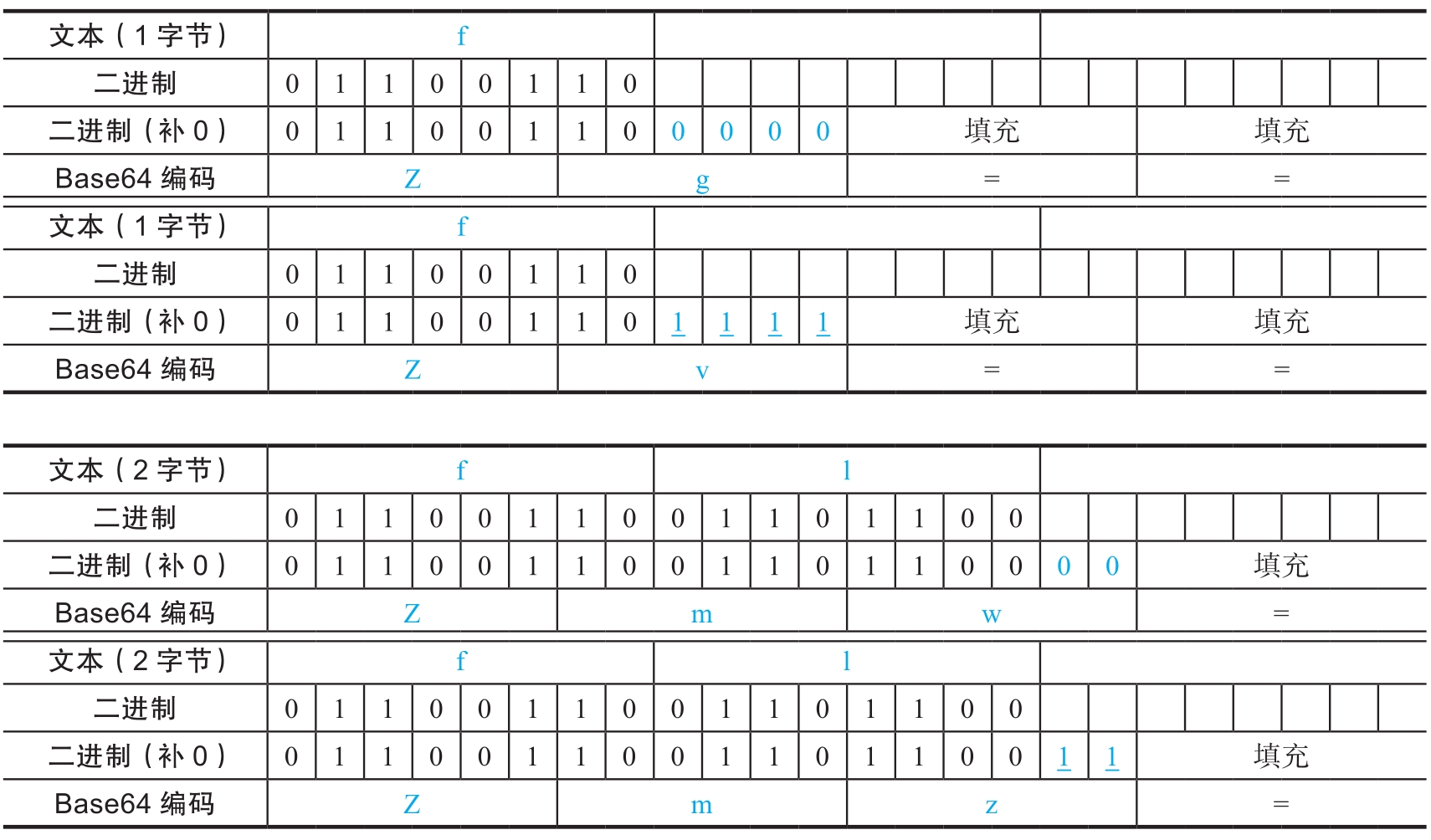
不难发现,不同的Base64编码的字符串在解码后对应同一个字符串。出现这种情况的原因是默认情况下会填充比特0,但在实践中完全可以填充其他比特值。在解码时,会先丢弃下划线部分填充的比特,再恢复出原始数据,下划线部分填充任意数据都不会影响Base64的解码结果。因此,只要是有等号的Base64编码的字符串都可以隐藏信息,其隐藏的规律是: 1个等号可以隐藏2比特信息,2个等号可以隐藏4比特信息 。
【例题】b64steg.txt
【题目来源】 攻防世界。
【题目描述】 找到flag。
【解题思路】 仔细分析字符串,可以判断是Base64编码后的结果。对于带“=”的字符串,例如第2行(IHdyaXRpbmcgaGlkZGVuIG1lc3NhZ2VzIGluIHN1Y2ggYSB3YXkgdGhhdCBubyBvbmV=),解码后得到:writing hidden messages in such a way that no one。
将解码后的结果再次进行Base64编码,得到IHdyaXRpbmcgaGlkZGVuIG1lc3NhZ2Vz IGluIHN1Y2ggYSB3YXkgdGhhdCBubyBvbmU=。不难发现,对于同样的明文字符串,进行Base64编码后,“=”前的字符不一样,说明原字符串中存在Base64信息隐藏。
对于Base64信息隐藏的考点,我们提供一个较为通用的提取脚本b64steg.py,可利用该脚本提取出隐藏的内容。该脚本的使用方法是:python2 b64steg.pyb64steg.txt。最后得到flag{Base_sixty_four_point_five}。
Base32编码与Base64编码类似,它使用32个可见字符表示所有数据。其编码原理是把原始数据按每 5字节分为一组 ,将每组的5个8比特数据切分为8个5比特数据,然后根据Base32编码的标准索引表将5比特数据转换为对应的字符。填充仍然用“=”表示。Base32编码的标准索引表如表1.1.2所示。
表1.1.2 Base32编码的标准索引表
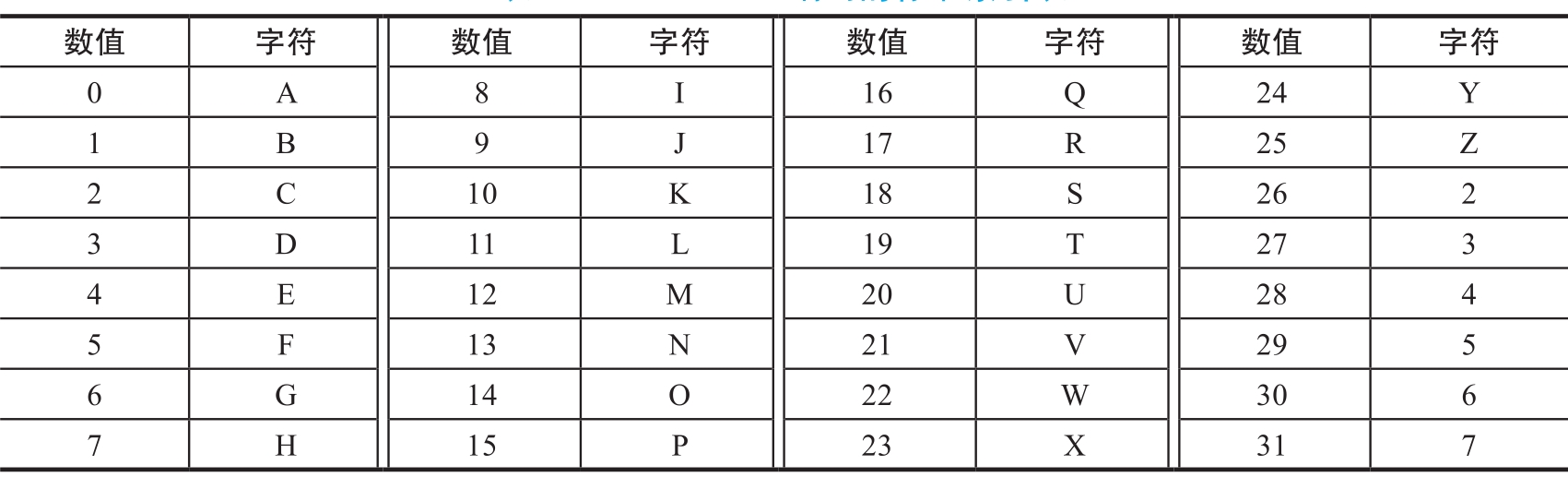
Base32的编码过程如下:

Base32的解码过程为:首先查Base32编码的标准索引表,将信息转换为二进制数据。然后,根据等号数量确定丢弃比特的范围(即上表中的下划线部分),再按照8比特一组恢复出原始数据。在Koczkatamas工具包中,将Base32字符串复制到B32行,即可在第一行(ASCII)看到解码后的内容。
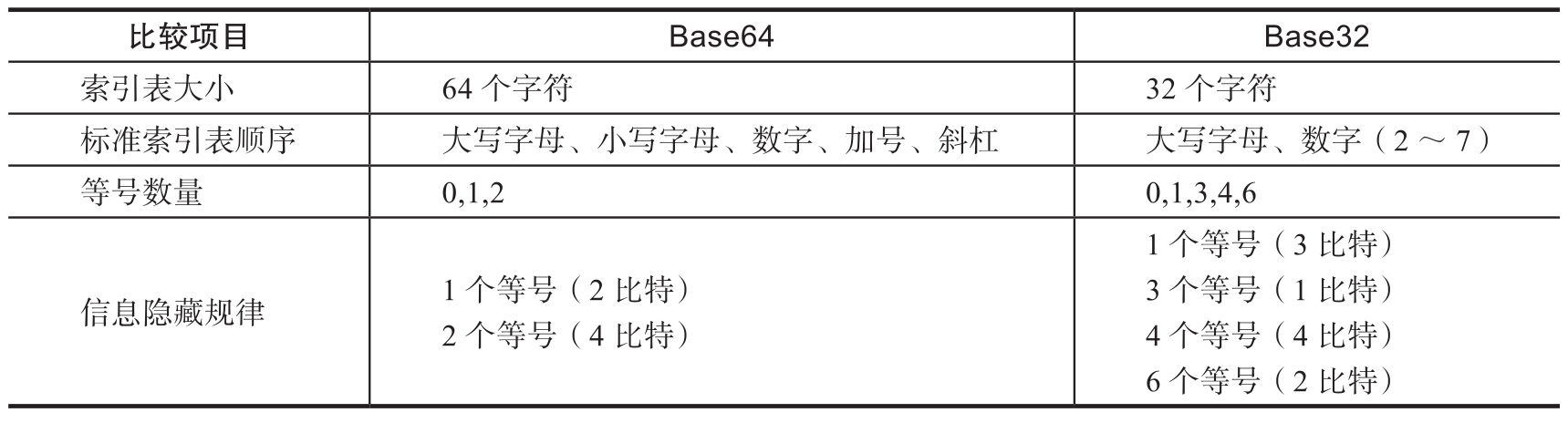
Base32编码也可以实现信息隐藏,其原理和Base64编码的一样。这里我们直接提供其隐藏信息的结果。 Base64编码和Base32编码的比较如表1.1.3所示 。
表1.1.3 Base64编码和Base32编码的比较
Base16编码使用16个可见字符表示所有数据。其编码原理是把原始数据每个字节分为一组,将每组的8比特数据切分为2个4比特数据,然后根据Base16标准索引表(如表1.1.4所示)将4比特数据转换为对应的字符,即每个字节可以转换为2个字符表示。
表1.1.4 Base16标准索引表

可以发现,Base16编码本质上是输出每个字节的十六进制表示,这种编码经常用在MD5、SHA1、SHA256、SHA512、SHA3等哈希算法的输出结果中。例如,“21232f297a57a5a743894a0e4a801fc3”是一个字符串的MD5值,根据Base16编码的原理, 2个字符表示一个字节 ,所以该MD5值共有16字节。标准Base16编码也称为HEX编码或者十六进制编码。
Base16的解码方法是:在Koczkatamas工具包中将字符串复制到HEX行,即可在第一行(ASCII)看到解码后的内容。如果需要将Base16解码成文件,可以使用CyberChef中的From Hex,如图1.1.2所示,再单击“Save output to file”按钮,即可保存为文件。
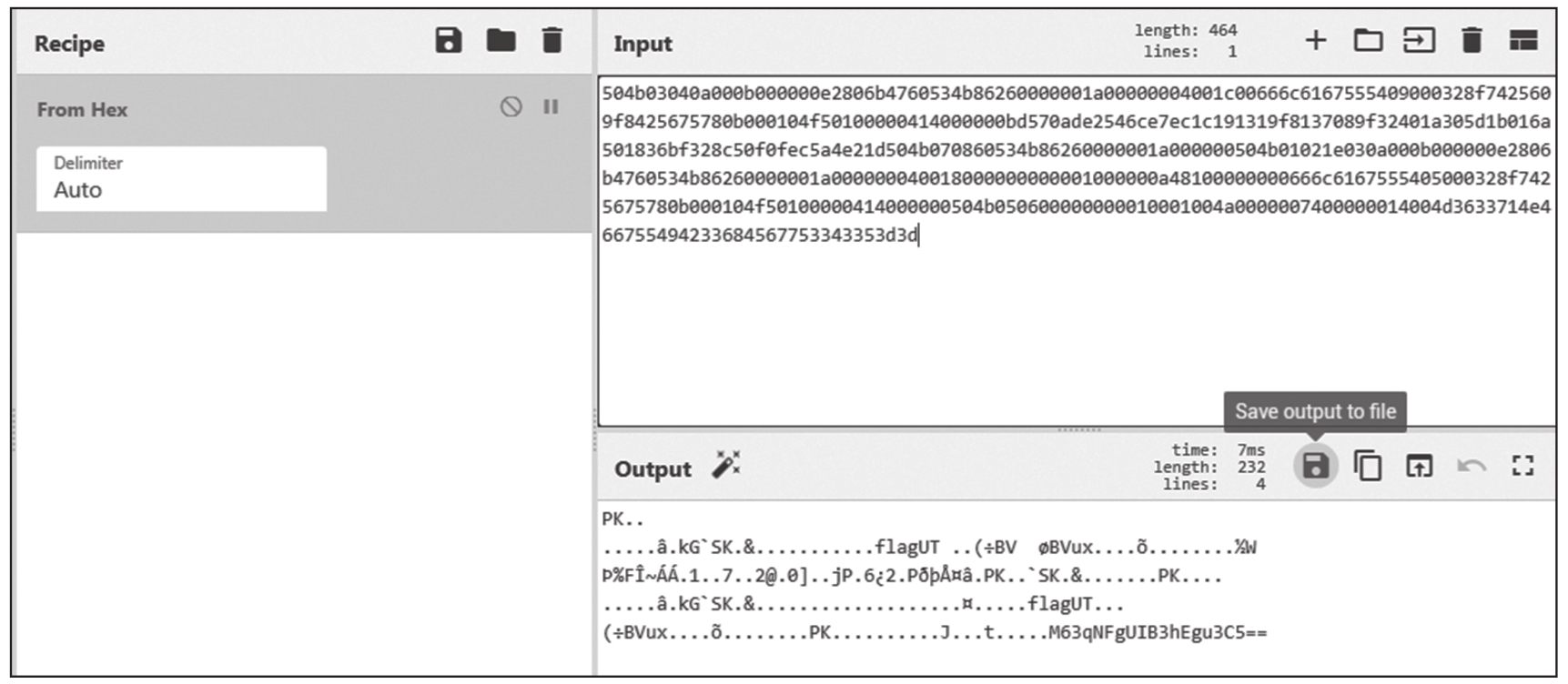
图1.1.2 使用CyberChef解码Base16
所有Base编码产生的原因都是想把不可打印字符转换为可打印字符,区别在于转换时的方法和索引表略有不同。接下来将简单介绍Base58、Base62和Base85的编码原理,这些编码都可以在CyberChef工具包中实现解码。
1.Base58编码
Base58是一种独特的编码方式。其编码原理是:Base58的标准索引表中去掉了容易产生歧义的字符,如0(零)和O(大写字母O)、I(大写的字母I)和l(小写的字母L),以及影响双击选择的字符,如/和+。所以,Base58的标准索引表中正好有58个字符(包括9个数字、24个大写字母、25个小写字母),又因为58不是2的整次幂,因此没有采用Base64编码中的方法进行转换,而是采用辗转相除法实现原始数据和索引表中地址的转换,本质是转换为五十八进制。
2.Base62编码
假设我们现在是一位网页开发者,开发需求是在URL中传输数据,需要把不可打印字符转换为可打印字符再传输。我们马上想到采用Base64编码,但是Base64标准索引表中的“+”和“/”在URL地址中有特殊的含义(在URL中,“+”表示空格,“/”表示分隔目录和子目录)。此时有两种解决方案:①替换“+”和“/”,例如,对于commons-codec中的Base64.encodeBase64URLSafeString(),用“-”和“_”分别替换“+”和“/”;②采用一种新的编码传输,也就是Base62编码。目前,各社交网站的短URL地址基本上都采用这种编码。其编码原理是:Base62的标准索引表有62个字符,顺序为:数字0~9、大写字母A~Z、小写字母a~z,这种编码也是采用辗转相除法实现原始数据和索引表地址的转换,其本质是转为六十二进制。
3.Base85编码
Base85是在Base64的基础上进一步压缩数据。Base85主要应用在PDF文档以及Git使用的二进制文件的补丁中。其编码原理为:用5个字符来表示4个字节。Base85还可以细分为标准型、ZeroMQ(Z85)和RFC1924三种。
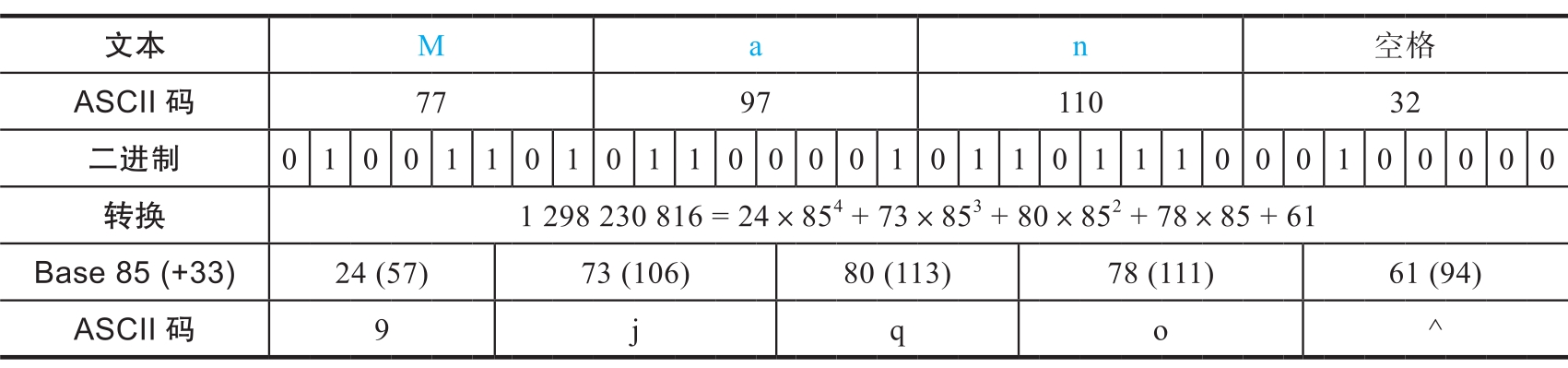
(1)标准型
标准型也被称为Standard或者ASCII85,其索引表的字符集为ASCII码的“!”到“u”,共85个字符,用“z”表示0x00000000,“y”表示0x20202020。下面给出一个例子。
(2)ZeroMQ(Z85)
Z85是现有的ASCII85编码机制的一个派生版本,具有更好的可用性,特别适合在源代码中使用(https://rfc.zeromq.org/spec/32/)。其索引表如下:

(3)RFC1924
RFC1924是针对IPv6地址的一种编码方式。原始IPv6地址需要32字节表示,经过这种方式编码,仅用20字节就可以表示一个IPv6地址(https://tools.ietf.org/html/rfc1924)。其索引表如下:

这三种格式都可以在开头和结尾添加“<~”和“~>”符号,并且在CyberChef工具包中可以手动选择不同格式后再进行解码。
解题技巧
如果遇到像Base64编码的字符串(特点是有大写字母、小写字母以及数字),但是经Base64解码后不是明文,那么可以在CyberChef工具包中用Base62、Base85、Base58等解码工具都尝试一遍。
Shellcode是一段利用软件漏洞而执行的代码,本质是十六进制的机器码,因攻击者可以通过其获得系统shell而得名。针对字符串,也可以采用Shellcode编码,其格式是在每个字符ASCII码的十六进制表示前加“\x”。
Shellcode编码后的字符串特征是 每个字节前面都有“\x”。 Shellcode编码的解码方法和Base16编码完全相同,在Koczkatamas工具包中直接把字符串复制到HEX行,不必删除“\x”,即可在第一行(ASCII)看到解码后的内容。下面看一个例子。
编码前 :The quick brown fox jumps over the lazy dog
编码后 :\x54\x68\x65\x20\x71\x75\x69\x63\x6b\x20\x62\x72\x6f\x77\x6e\x20\x66\x6f\x78\x20\x6a\x75\x6d\x70\x73\x20\x6f\x76\x65\x72\x20\x74\x68\x65\x20\x6c\x61\x7a\x79\x20\x64\x6f\x67
Quoted-printable表示“可打印字符引用”,该编码常用在电子邮件中,如Content-Transfer-Encoding:quoted-printable,它是多用途互联网邮件扩展(Multipurpose Internet Mail Extensions, MIME)的常见一种表示方法。其编码原理为:任何一个字节都可编码为3个字符:等号后跟随两个十六进制数表示该字节的数值。例如,ASCII码换页符(十六进制值为0x0C)可以表示为“=0C”,等号本身(十六进制值为0x3D)可以表示为“=3D”。
除了可打印ASCII字符与换行符以外,所有字符必须表示为这种格式。 这意味着一般CTF比赛中的flag不会采用Quoted-printable编码,因为flag一般为字母和数字,采用这种编码后和原字符串相比没有任何变化。但是,在邮件取证或者邮件流量分析的题目中,会看到这种编码。Quoted-printable编码最显著的特征是每个字节前面都有“=”,利用在线网页http://web.chacuo.net/charsetquotedprintable和CyberChef可以实现编码和解码功能。
下面给出一个在Unicode字符集下的例子。
编码前 :敏捷的棕色狐狸跳过了懒惰的狗
编码后 :=E6=95=8F=E6=8D=B7=E7=9A=84=E6=A3=95=E8=89=B2=E7=8B=90=E7=8B=B8=E8=B7=B3=E8=BF=87=E4=BA=86=E6=87=92=E6=83=B0=E7=9A=84=E7=8B=97
UUencode是“UNIX-to-UNIX encoding”的简称,是在UNIX系统下将二进制数据通过UUCP邮件系统传输的一种编码方式,常用于电子邮件中的档案传送以及Usenet新闻组和BBS的帖文,等等。近年来已逐渐被MIME取代。
UUencode的编码原理为:将输入数据按每3字节为一个单位进行编码,如果最后剩下的数据少于3字节,则用零补齐到3字节。3字节共有24比特,以6比特为单位分为4个组,每组数值在十进制下的范围是0~63,将每个数加上32,产生的结果刚好落在ASCII字符集中可打印字符(32~95)的范围内。输出时,每60个字符为独立的一行,每行的开头会加上长度字符。除了最后一行之外,长度字符都应该是“M”(32+45=77),最后一行的长度字符为32+剩下的字节数目对应的ASCII字符。如果一个6比特组转换后为0,那么会被转换为0x60而不是0x20。
下面给出一个例子。
编码前 :The quick brown fox jumps over the lazy dog
编码后 :M5&AE('%U:6-K(&)R;W=N(&9O>"!J=6UP<R!O=F5R('1H92!L87IY(&1O9P"
UUencode编码后的字符串的特征是:所有字符看起来像乱码,但都是可打印字符;如果有多行,那么除了最后一行,都以“M”开头。UUencode可以使用在线工具http://web.chacuo.net/charsetuuencode实现解码。
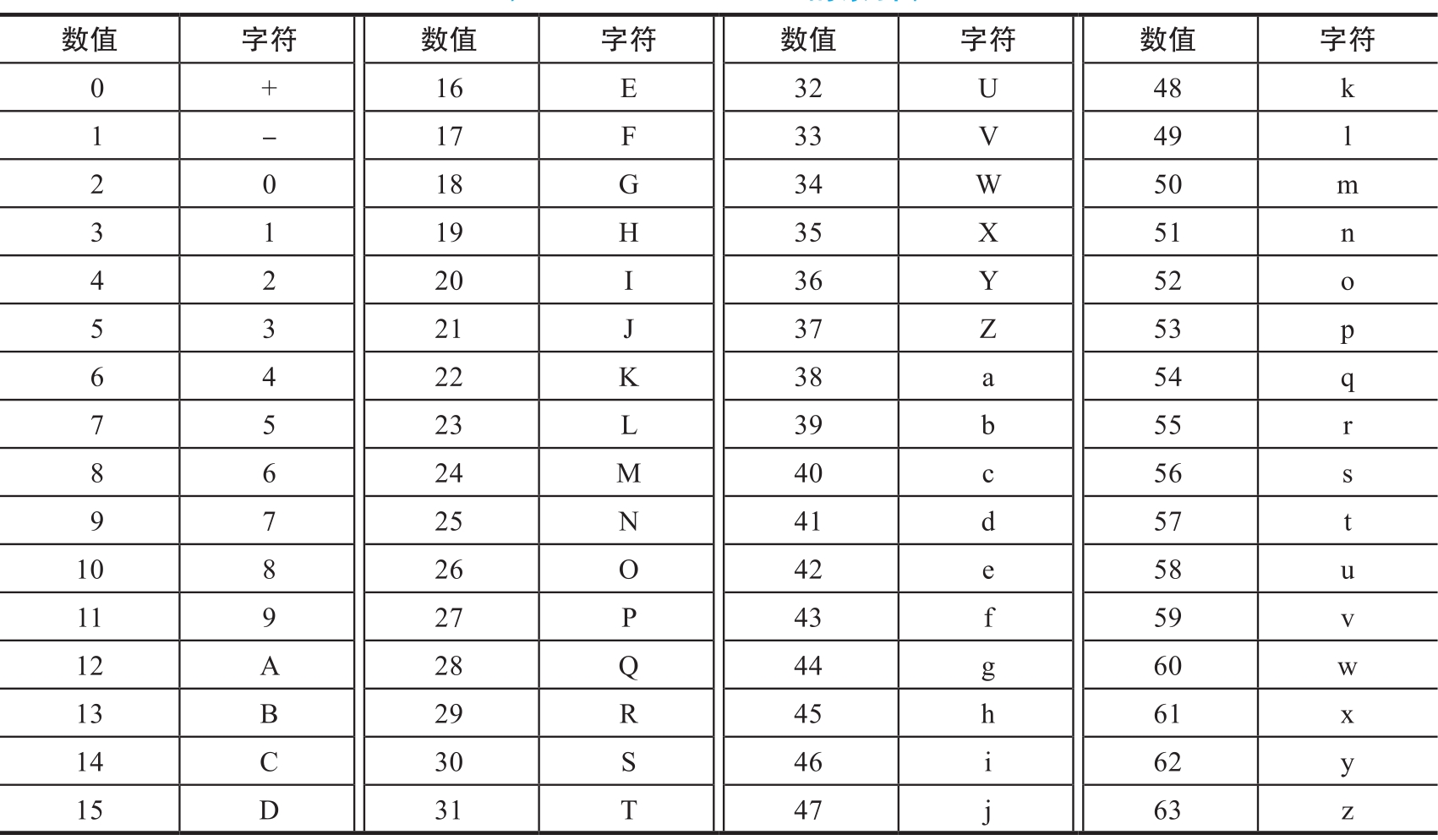
XXencode的编码原理和Base64完全相同,只是转换时的索引表不同,可以看作变形的Base64。XXencode的索引表如表1.1.5所示。
表1.1.5 XXencode的索引表
XXencode编码输出时的格式和UUencode相似,每60个字符为独立的一行,每行的开头会加上长度字符,除了最后一行之外,长度字符都应该是“h”(索引表中第45位),最后一行的长度字符为字节数在索引表中位置所代表字符。编码时默认填充比特0,填充的字符和具体的工具有关,在线XXencode解码网站http://web.chacuo.net/charsetxxencode用索引表的第一个字符作为填充。
下面给出一个例子。
编码前 :The quick brown fox jumps over the lazy dog
编码后 :hJ4VZ653pOKBf647mPrRi64NjS0-eRKpkQm-jRaJm65FcNG-gMLdt64FjNk++
URL编码也称为百分号编码。URL地址规定,常用数字、字母可以直接使用,特殊用户字符(/,:@等)也可以直接使用,剩下的字符必须通过%xx编码处理。其编码方法很简单,就是在每个字节ASCII码的十六进制字符前面加“%”,如字符空格编码后的结果是%20。具体解码方法为:在Koczkatamas工具包中直接把字符串复制到URL行,即可在第一行(ASCII)看到解码后的内容。
【例题】url.txt
【题目描述】 找到flag。
【解题思路】 先对URL解码,得到字符串alf{gyrctprgopai_y_ssae}y。flag的格式是flag{},根据这个提示,与解码后的字符串比较,发现如下规律:5个字符一组,前3个字符逆序,后2个字符逆序。最后得到flag{cryptograpy_is_easy}。
摩斯码一般是指莫尔斯电码,也称作摩斯密码,它是由美国人萨缪尔·莫尔斯在1837年发明的。摩斯码是由 点(.) 和 划(-) 这两种符号组成的信号代码,通过不同的排列顺序来表达不同的英文字母、数字和标点符号。其中,点作为一个基本的信号单位,划的长度相当于3个点的时间长度;在一个字母或数字之内,每个点、划之间的间隔应该是两个点的时间长度;字母(数字)与字母(数字)之间的间隔是7个点的时间长度。摩斯码主要由以下5种代码组成:
❑点(.)。
❑划(-)。
❑每个字符间短的停顿(通常用空格表示停顿)。
❑每个词之间中等的停顿(通常用“/”划分)。
❑句子之间长的停顿。
摩斯码的编码规则如图1.1.3所示。
在CTF比赛中,常用两种符号表示变形的摩斯码,可以先通过替换转换为标准摩斯码,再进一步解码。在Koczkatamas工具包中,首先选中Misc选项卡,再将需要解码的摩斯码字符串复制到MRZ行,即可在第一行(ASCII)看到解码后的内容,如图1.1.4所示。

图1.1.3 摩斯码的编码规则
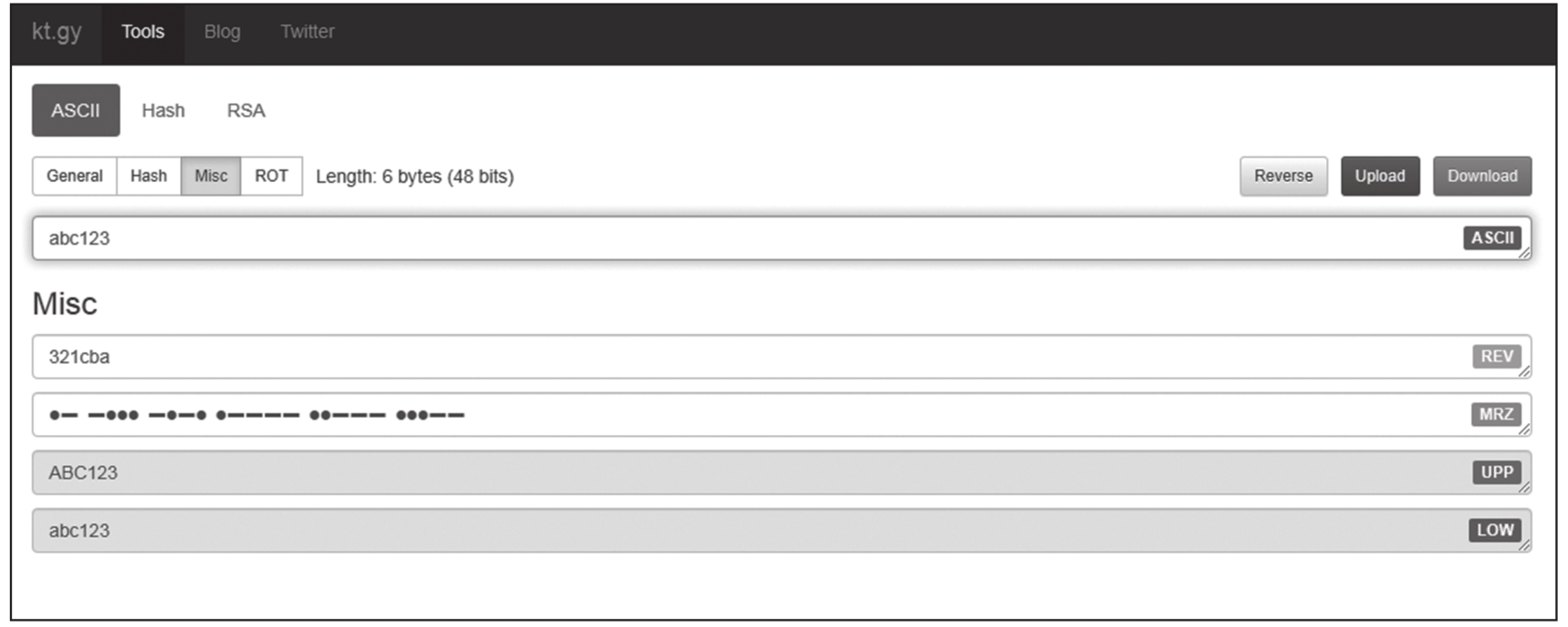
图1.1.4 在Koczkatamas工具包中进行摩斯码解码
【例题】diff_Morse.txt
【题目描述】 找到flag。
【解题思路】 只有Z和X两种符号,以空格分隔,每组长度不定,猜测是摩斯码的变形,因此分别将Z替换成点(.)或划(-),将X替换成划(-)或点(.),然后解码。发现Z替换成点(.)且X替换成划(-)时,解码得到可打印字符串,将字符串逆序,得到flag:IAMFLAGYOUARERIGHT。
JSFuck是一种人类难以阅读的基于JavaScript的编程语言,代码中仅使用“[”“]”“(”“)”“!”和“+”六种字符。理论上,JSFuck的运行不需要依赖浏览器,它也可以在Node.JS上运行。具体的转换原理可以参考官方网站http://www.jsfuck.com。
注意,JSFuck代码和JavaScript代码不是一一对应的关系。一般而言,规范书写的JavaScript代码都能转换成JSFuck代码,但JSFuck代码不一定都能转换成JavaScript代码。在CTF比赛中,JSFuck常用于JavaScript的加密,需要选手运行JSFuck代码或者手工解密,读懂代码内部逻辑。
JSFuck的运行方法如下:打开浏览器,按<F12>键打开调试界面,选择控制台(Console)选项卡,复制代码,按回车键即可显示运行结果。如果浏览器运行报错,可以检查字符串是否复制完整或者换用QQ、360等浏览器。
【例题】Shellcode.txt
【题目来源】 原创。
【题目描述】 找到flag。
【解题思路】 打开文档,发现是JSFuck编码的字符串。由于Chrome和Firefox浏览器的安全机制,我们复制到浏览器的JSFuck代码不能直接运行,因此我们选用360浏览器。运行结果如图1.1.5所示。这里可以发现结果中有Shellcode编码,解码后就得到flag{Nihao_JSf**K}。
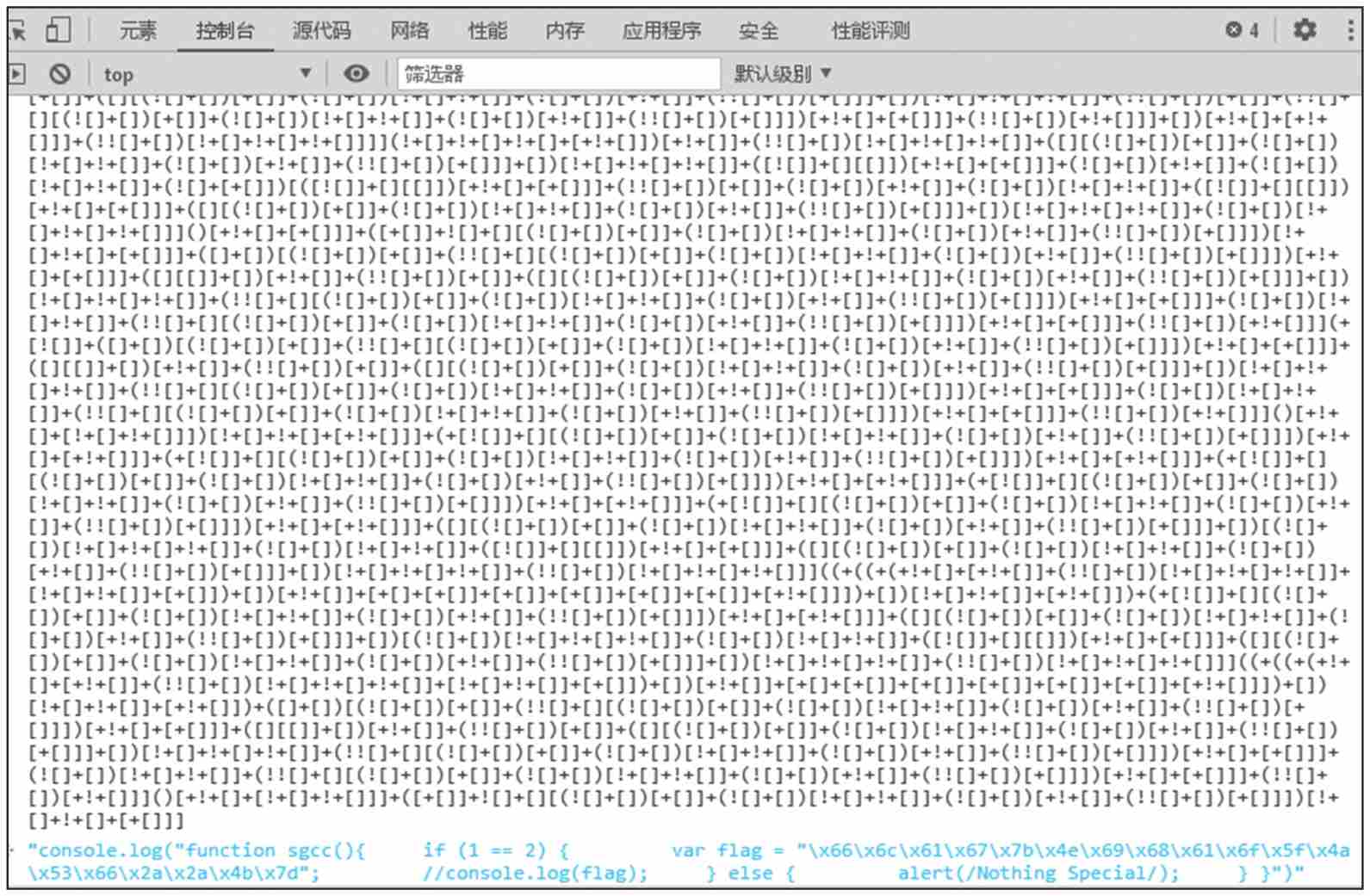
图1.1.5 JSFuck的运行结果
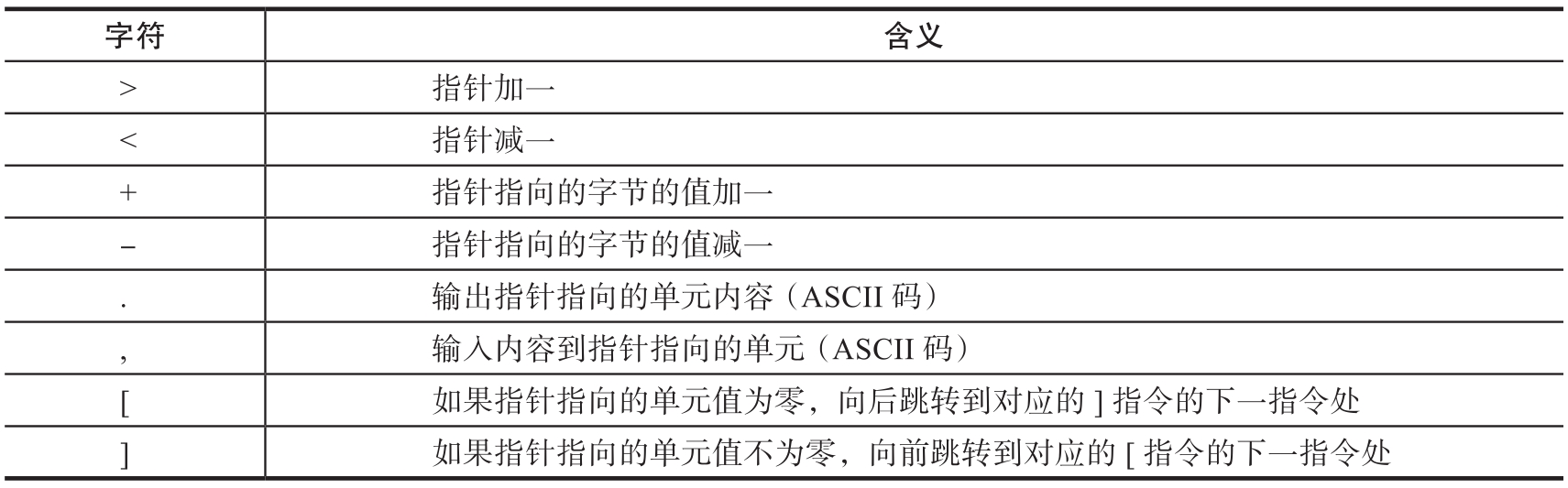
Brainfuck是一种极小化的 程序语言 ,本质上它并不属于编码。它是由Urban Muller于1993年创造的,发明Brainfuck是为了创建一种简单的、可以用最小的编译器来实现的、符合图灵完备思想的编程语言。这也导致Brainfuck代码对非专业人员基本不可读。该语言只有八种符号,所有操作都由这八种符号的组合来完成,见表1.1.6。
表1.1.6 Brainfuck字符的含义
Brainfuck代码可利用在线工具https://www.splitbrain.org/services/ook实现编码和解码。图1.1.6所示是字符串“Hello world”对应的结果。
如果输出结果较为规范,则应该是5个字符为一组,每组以空格分隔,代码开头部分有若干加号,这些可以作为识别Brainfuck代码的明显特征。Brainfuck代码还有变形,分别是Ook!和Short Ook!代码。
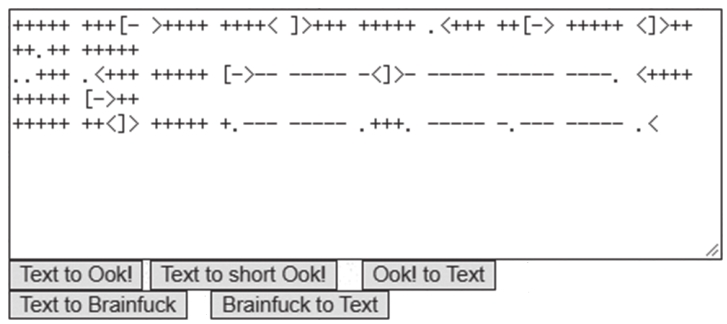
图1.1.6 Brainfuck编码的结果
Ook!是一种由David Morgan-Mar创建的编程语言,它与Brainfuck完全相同,只是指令被改成了其他表示形式。Ook!只包含3种符号:Ook.,Ook!和Ook?,见表1.1.7,这也导致Ook!编码的特征过于明显。
表1.1.7 Ook!编码与Brainfuck编码的对应关系

例如,例题ook_example.txt的Ook!编码为

在https://www.splitbrain.org/services/ook中选择Ook! To Text,得到结果Ook。为了缩短书写时间和避免多次编码,有时会通过删除Ook简化代码,使其成为三元代码,即只有3种符号——点(.)、问号(?)和感叹号(!),如表1.1.8所示。
表1.1.8 Short Ook!与Brainfuck的对应关系

“Hello world”对应的规范化的Short Ook!如下:


其特点也是5个字符为一组,每组以空格分隔,开头有若干个点(.)。
可以使用离线工具https://github.com/jcharra/ook/blob/master/ook.py运行Brainfuck、Ook!和Short Ook!代码,得到运行结果。使用方法为:运行命令python2 ook.py -o/-b xxx.txt,其中-o是对Ook!和Short Ook!解码,-b是对Brainfuck解码。
【例题】txt.txt
【题目来源】 2019年广东省强网杯。
【题目描述】 找到flag。
【解题思路】 将012替换为点、感叹号和问号,首先Short Ook!运行一次,得到Brainfuck代码,再运行一次,得到最终结果:lalala,wo shi mai bao de xiao hang jia.flag{08277716193eda6c592192966e9d6f39}ni neng cai dao ta me?。
虽然我们已经学习了很多种编码,但对于CTF比赛可能远远不够。为了解决编码识别的问题,在Github等网站中可以找到很多开源工具,利用它们可以自动完成编码识别和解码,从而大大提升解题效率。我们推荐两个相关的工具:CyberChef和Ciphey(官方网址为https://github.com/Ciphey/Ciphey)。从实践效果来看,CyberChef能处理大部分编码和压缩,但其智能化程度不高,如果输入涉及密码学知识,还需要依靠人工解密;Ciphey对于大部分古典密码和编码均有非常好的处理效果,其智能化程度更高,但如果输入涉及压缩等操作,可能就无法识别。
【例题】easyencode.txt
【题目描述】 找到flag。
【解题思路】 主要使用CyberChef里面的Magic功能。
为方便初学者学习,我们首先说明CyberChef的使用方法。将CyberChef压缩包解压后,双击CyberChef_v9.21.0.html(推荐使用Chrome浏览器打开),在打开的页面中将看到4个窗口,分别是Operations、Recipe、Input和Output。其中,Operations中包含CyberChef的所有功能,只有将对应的功能模块从Operations拖拽到Recipe中,该功能才能生效。Input窗口存放我们的输入。Recipe中可以同时存在多个模块,并将输入按照从上到下的顺序逐个处理,处理后的结果在Output窗口显示。
因为CyberChef中集成的功能众多,因此可以在Operations的Search窗口中(如图1.1.7所示)查找。输入对应编码(或加密算法)的名称后,在Operations下方会出现对应的功能模块,其中“To”开头的模块表示编码,“From”开头的模块表示解码。

图1.1.7 Search窗口
在Operations中搜索Magic模块,并拖入Recipe中,Magic会检测输入可能采用的编码方式,并显示解码结果。Magic的设置如图1.1.8所示,Depth处可以选择解码的层数,也就是解码几次,其默认值一般是3或4。在浏览器的右下角可看到解码后的结果(如图1.1.9所示):synt{38o2o3pq-rqqr-4895-83p4-n768pqn3732o}。“synt”是一个特征值,希望各位读者牢牢记住,它是“flag”经ROT13处理后的结果,大家可以先记住这个结果。ROT13属于古典密码的范畴,所以在本章中没有讲解,我们将在后续的密码学章节中详细说明。单击图1.1.9左侧框中的字符,相关编码信息将显示在图1.1.10的“Recipe”中。我们在Recipe中添加ROT13的模块,就能看到最终结果:flag{38b2b3cd-edde-4895-83c4-a768cda3732b}。在图1.1.9的右侧,可以看到“Entropy”的值,它表示结果的熵值。如果通过Magic模块得到多个结果,我们要优先选择熵值最小的结果进行分析,因为信息熵的值越小,数据越接近人可以理解的明文信息。
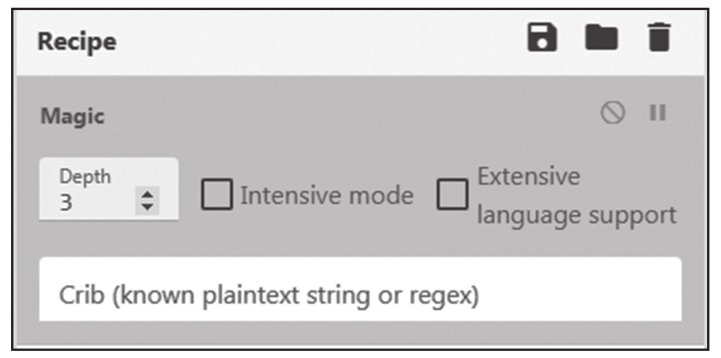
图1.1.8 CyberChef中的Magic配置

图1.1.9 Magic解码结果
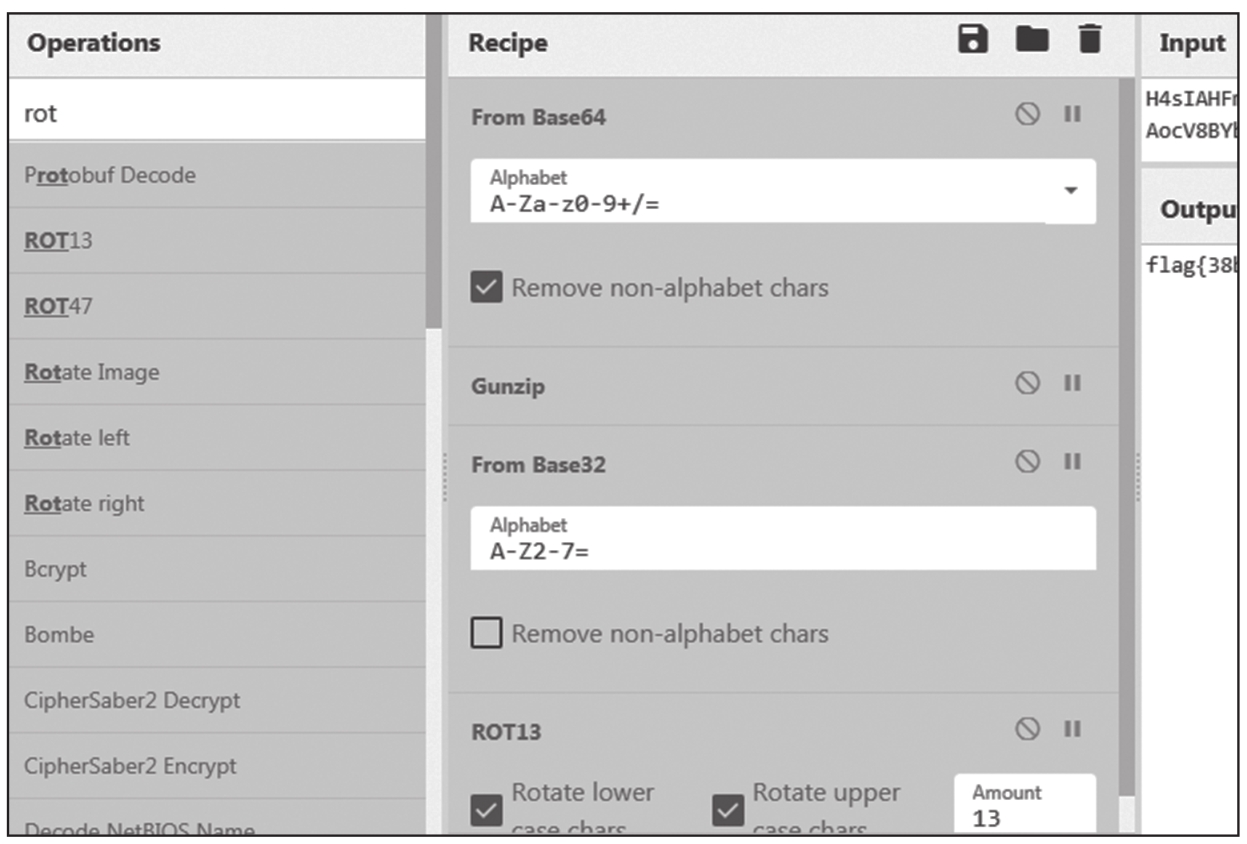
图1.1.10 最终的解码结果
除了Magic模块,CyberChef还有个“魔法棒”功能,如图1.1.11所示。首先,在Recipe中没有选择任何模块,在Input中输入待处理的字符串,即可看到在Output右边出现了一个“魔法棒”,它其实就是CyberChef检测出的输入可能对应的编码或压缩类型。单击“魔法棒”,会在Recipe中自动添加相应的功能模块,并在Output显示处理结果。如果Output中也出现了“魔法棒”,我们可以一直单击,直到它不再出现为止。“魔法棒”给解码工作带来了极大的方便,但有时候它的检测结果是错误的,而且如果输入采用的编码层数过多,“魔法棒”也会失效。
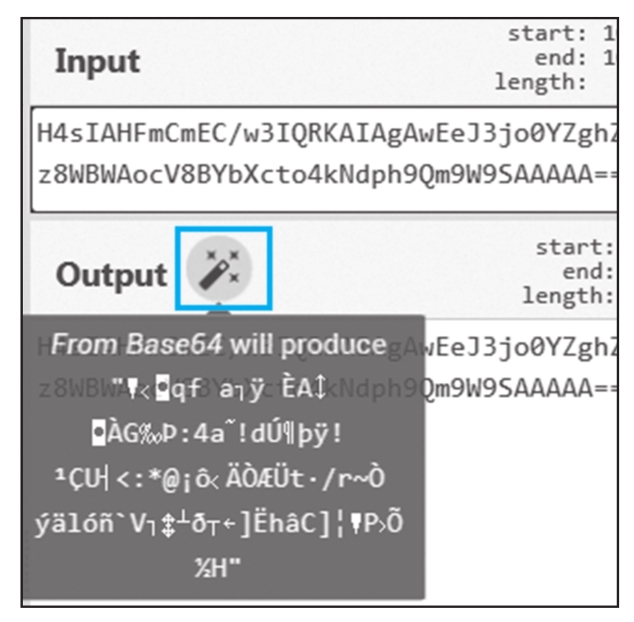
图1.1.11 “魔法棒”功能
【例题】simpleencode.txt
【题目描述】 找到flag。
【解题思路】 题目中的字符串看起来是一个Base64编码的字符串,但将其解码后看不出任何特征,并且使用CyberChef的Magic或“魔法棒”也没有出现任何提示,此时可考虑使用工具Ciphey。根据Ciphey官网的描述,我们可采用Docker的方式进行安装,也可以使用pip安装,这里不再详细介绍安装步骤。本题运行Ciphey的结果如图1.1.12所示,得到flag{Ay7sxCA9wSYrVLC}。可以看到,结果中采用了仿射加密等方式,这是CyberChef中无法自动处理的,但是Ciphey可以自动识别。感兴趣的读者可以用Ciphey对上一个例题(easyencode.txt)进行解码,会发现Ciphey处理失败。这是因为上一个例题采用gunzip压缩,CyberChef对其有较好的识别效果,但Ciphey不能正确处理。因此,在比赛时,大家要灵活使用这两个工具。
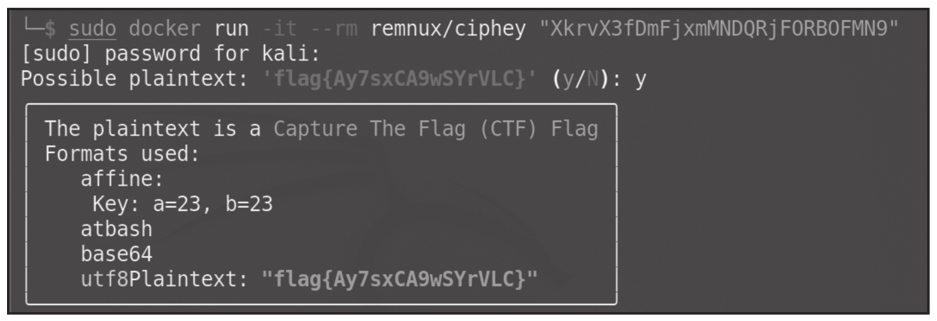
图1.1.12 Ciphey处理结果