
下载掌阅APP,畅读海量书库
立即打开



在正式讲解文本特征表示方法之前,我们将简单介绍语料是什么,如何处理语料以及如何构建语料库,之后再循序渐进地介绍NLP中的文本特征表示方法。
语料是NLP任务的数据来源,所有带有文字描述性的文本都可以看作语料。一个文本可以由一个或多个句子组成,其中每一个句子都可以称为语料。
语料库是存放在计算机里的原始语料文本或经过加工后带有语言学信息标注的语料文本。为了方便理解,可以将语料库看作一个数据库,我们可以从语料库中提取语言数据,并对其进行分析、处理。
实际上,语料库有三个特征:一是语料库中存放的是真实出现过的语言材料;二是语料库是以计算机为载体承载语言知识的基础资源;三是真实语料需要经过分析、处理和加工才能成为有用的资源。在人工智能的发展过程中,我们经常使用的语料库有中文分词语料库、词性标注语料库、命名实体识别语料库、句法分析语料库、情感分析语料库等。
原始文本无法直接用于模型的训练,需要经过一系列的预处理,才能符合模型输入的要求。语料预处理的方法主要包括语料清洗、分词、词性标注、去停用词等,接下来依次展开介绍。
1.语料清洗
语料清洗即保留原始语料中有用的数据,删除噪声数据。在实际的应用场景中,特殊字符、不可见字符或者格式不正确的字符都不利于后续模型的训练。常见的清洗方式有人工去重、对齐、删除、标注等。
以下面的文本为例,该文本中不仅包含中文字符,还包含标点符号等非常规字符,这些字符对于我们来说都是没有意义的信息,需要对其进行清洗。

对于上述情况,可以使用正则表达式对文本进行清洗,具体的Python实现代码为:

清洗后的结果为:

除了需要清洗上述提到的各种形式的符号外,噪声数据还包括重复的文本、错误、缺失、异常等,这些都属于语料清洗的范畴。只有数据清洗得干净,才能为模型的训练扫清障碍。
2.分词
分词是指将连续的自然语言文本切分成具有完整性和语义合理性的词汇序列的过程,而词是语义最基本的单元。分词是文本分类、情感分析、信息检索等众多自然语言处理任务的基础。常用的分词方法可分为基于规则和基于统计两种,其中基于统计的分词方法的样本来自标准的语料库。
例如这个句子:小明住在朝阳区。我们期望语料库统计后的分词结果是“小明/住在/朝阳/区”,而不是“小明/住在/朝/阳区”。那么如何做到这一点呢?
基于统计的分词方法,我们可以借助条件概率分布来解决这个问题。对于一个新的句子,我们可以通过计算各种分词方法对应的联合分布概率,找到最大概率对应的分词方法,即最优分词。
到目前为止,研究者已经开发出许多分词实用小工具,如表1-1所示。如果对分词没有特殊需求,可以直接使用这些分词工具。如果想要语料中的一些特定词不分开,可以设置自定义词典。
表1-1 分词工具总览
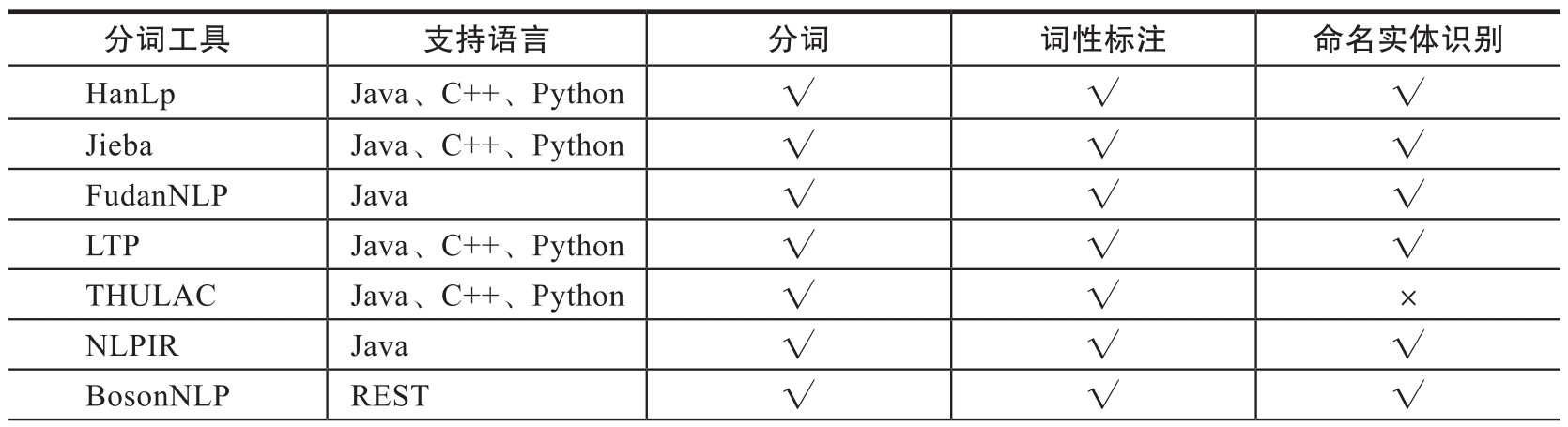
(续)

3.词性标注
词性标注是指为分词结束后的每个词标注正确词性,即确定每个词是名词、动词、形容词或其他词性的过程。
词性标注有两个作用。一是消除歧义。一些词在不同语境下或使用不同用法时表达的含义不同,比如在“这只狗狗的名字叫开心”和“我今天很开心”这两个句子中,“开心”就代表了不同的含义。我们可以通过词性标注对有歧义的词进行区分。二是强化基于单词的特征。机器学习模型可以提取一个词很多方面的信息,如果一个词已经标注了词性,那么使用该词作为特征就能提供更精准的信息。还是以上句为例,原始文本为“这只狗狗的名字叫开心”和“我今天很开心”,单词在文本中出现的次数为[(这,1),(只,1),(狗狗,1),(的,1),(名字,1),(叫,1),(开心,2),(我,1),(今天,1),(很,1)],带标注的单词在文本中出现的次数为[(这_r, 1),(只_d, 1),(狗狗_n, 1),(的_uj, 1),(名字_n, 1),(叫_v, 1),(开心_n, 1),(我_r, 1),(今天_t, 1),(很_zg, 1),(开心_v, 1)],其中r表示代词,d表示副词,n表示名词,uj表示结构助词,v表示动词,t表示时间词,zg表示状态词。在这个案例中,如果不进行词性标注,两个“开心”会被看作同义词,其词频被错误识别为2,这会为后续的语义分析引入误差。此外,词性标注还具有标准化、词形还原和移除停用词的作用。
常用的词性标注方法可分为基于规则和基于统计两种,如最大熵词性标注、隐含马尔可夫模型(Hidden Markov Model, HMM)词性标注等。
4.去停用词
人类在接收信息时,都会下意识地过滤掉无效的信息,筛选有用的信息。对于NLP来说,去停用词就是一种类比人类过滤信息的操作。那什么是停用词呢?停用词实际上是一些对文本内容无关紧要的词。
在一篇文章中,无论中文还是英文,通常会包含一些起到连接作用的连词、虚词、语气词等词语。这些词语并不是关键信息,比如“的”“吧”“啊”“uh”“yeah”“the”“a”等,对文本分析没有太多实质性的帮助。删除这些词并不会对我们任务的训练产生负面影响,反而会在一定程度上让数据集的变小,较少训练时间。
但是,停用词的去除对我们的训练任务来说并不总是有益的。比如我们正在训练一个可以用于情感分析任务的模型,训练影评为“The movie was not good at all.”,情感类别是负面;对该影评进行去停用词操作后变为“movie good”。我们可以清楚地看到这部电影的原始评论是负面的,然而在去掉停用词后,评论变成正向的了。对于该任务来说,去停用词操作是有问题的。
因此,在对NLP任务的语料进行预处理时,我们应该谨慎地决定是否进行去停用词操作,该去除哪类停用词。目前常用的停用词表有中文停用词表cn_stopwords.txt,哈工大停用词表hit_stopwords.txt,百度停用词表baidu_stopwords.txt和四川大学机器智能实验室停用词表scu_stopwords.txt。对于英文数据来说,我们可以借助常用的删除英文停用词的库,如自然语言工具包(NLTK)、SpaCy、Gensim、Scikit-Learn。
5.词频统计
词频统计即统计分词后文本中词语的出现次数,也就是该词语出现的频率,目的是找出对文本影响最大的词汇,这是文本挖掘中常用的手段。统计词频可以帮助我们了解文章的重点内容,辅助后续模型的构建。比如我们可以统计《红楼梦》中词频在前10的词语,结果如表1-2所示。
表1-2 《红楼梦》的词频统计
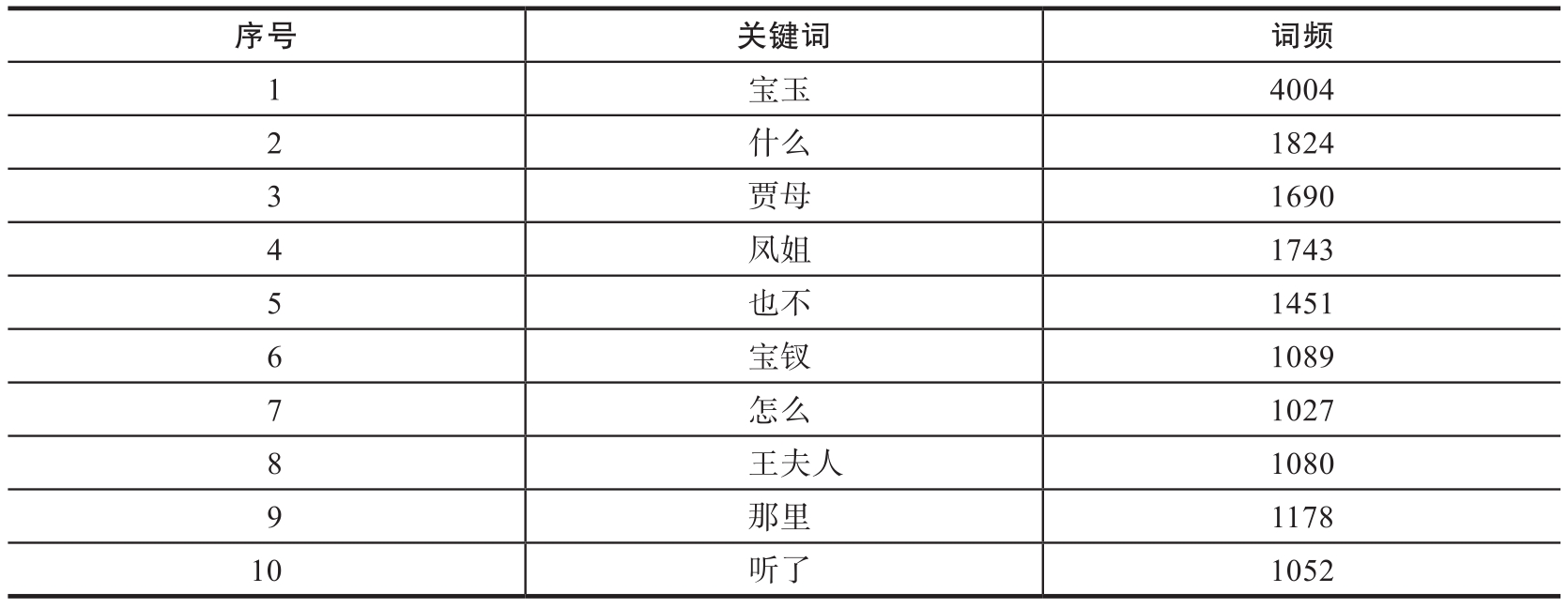
从表1-2中,我们可以清楚地发现,在《红楼梦》中曹雪芹对宝玉、贾母、凤姐、宝钗、王夫人等人物描述的篇幅最多,这几个人物也是《红楼梦》中的关键人物。通过词频的统计结果,我们可以很容易地掌握文本中的一些关键信息。