
下载掌阅APP,畅读海量书库
立即打开



调试内存损坏的真正挑战在于,程序错误时并不能揭示导致错误的有缺陷的代码。通常,程序在有bug的代码做出错误的内存访问时,不会显示任何症状,但是程序中的某个变量意外地被改变为不正确的值。在一些文献中,这被叫作传染。随着程序继续运行,该变量会感染其他变量。这种错误传播最终会发展为严重的失败:程序要么崩溃,要么生成错误的结果。由于导致错误的原因和结果之间的距离很长,崩溃时的变量和执行代码与实际错误往往没有关联,而且在时间和位置方面可能会表现出很多随机性。
图3-1展示了从初始感染变量到最终程序崩溃的典型感染链。水平轴表示程序的执行时间(每个时间事件代表程序状态的变化);纵轴是程序状态,包括一组变量。符号“O”表示变量处于有效状态,“X”表示被感染。在t 0 时刻,程序处于完美状态,所有变量均有效。在t 1 时刻,变量v 4 被感染,但这并不是灾难性的。程序在t 2 、t 3 等时间点向前推进,直到t n 。在t 2 时刻,变量v 3 也被感染。在t 3 时刻,变量v 2 被感染,此时变量v 4 超出了作用域(其“X”被标记为灰色)。当最终被感染的变量v 1 在t n 时刻导致程序失败时,它已经远离初始感染点,即t 1 时刻的变量v 4 。注意,变量v 2 也超出了作用域,而变量v 3 从被感染状态改为有效状态,这是由于程序可能正确地处理了错误的数据,尽管不能回顾性地定位和修复起因。对于工程师来说,要确定第一个被感染的变量v 4 以及相关的有缺陷的代码是非常困难的,因为存在着复杂性和无数种可能导致程序最终失败的情况。
以下示例展示了错误代码损坏内存却没有在犯罪现场留下让我们调查的痕迹。这个简单的程序写入一块已释放的内存,它最终在内存分配函数中崩溃,但这个函数看起来与“罪犯”无关。
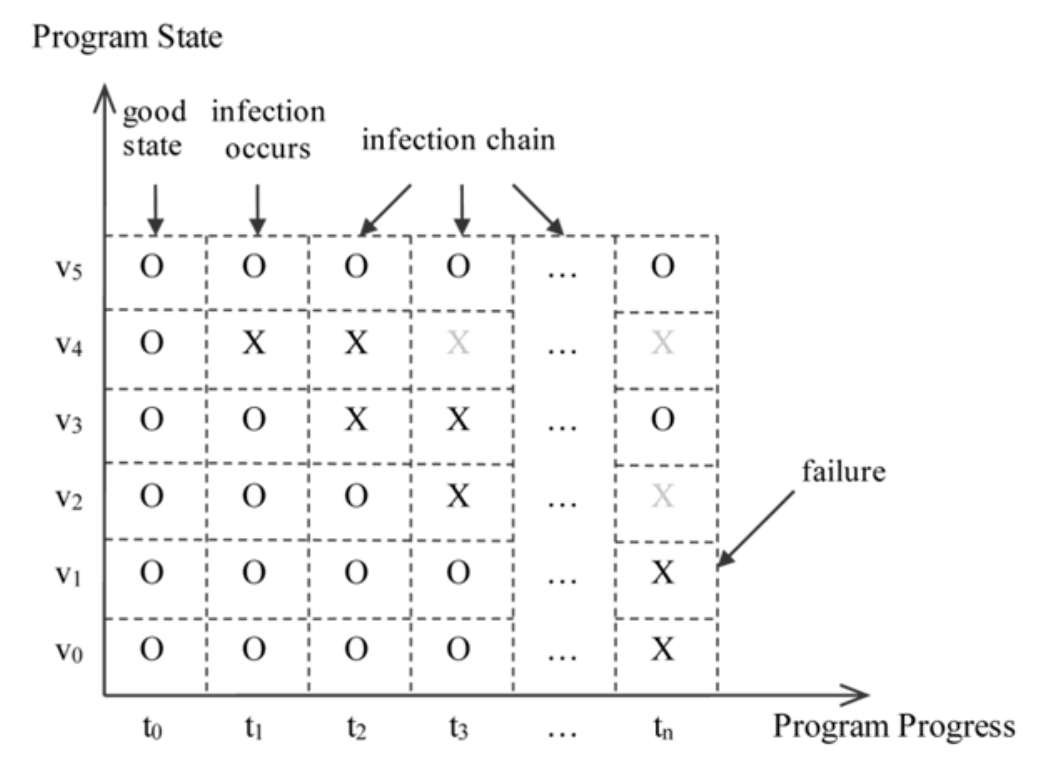
图3-1 内存错误的传播

使用ptmalloc作为默认内存管理器的Linux Red Hat发行版运行这个程序,当程序接收到段错误信号时,我们将会看到如下函数调用栈:该线程正在调用函数Victim,该函数仅仅尝试从堆分配32字节的内存;但是,正如前一节所示,函数AccessFree覆写了一块已释放的内存,因此损坏了堆元数据,更准确地说是用来记录空闲块链表的指针。这个问题直到ptmalloc为了重用空闲块而访问指针时才会出现。

通常在程序失败时,程序的状态不足以得出确定的结论。对于上面的例子,仅仅通过审阅代码就很容易发现bug,但是对于实际应用的复杂程序,这不会是一个有效的方法。面对上万甚至百万行代码,我们往往无从下手,因此调试内存损坏非常困难。
调试内存损坏实际上是从故障点溯源到最初感染的罪魁祸首。这可能非常困难,甚至不可能,即使看似简单的情况也是如此,就像上面的例子一样。但是,我们应该努力发现尽可能多的感染变量,以便更接近有缺陷的代码。这个恢复感染链的分析过程至少需要对程序有深入的了解,需要了解架构特定信息以及使用调试器的经验。
当发现问题时,第一个动作是调查程序的当前状态,这是感染链的终点。分析非常重要,因为它确定了我们需要采取的后续行动。有各种方法和风格来检索和分析失败程序的大量信息。下面将描述一些基本但具体的步骤。每个步骤都是为了缩小搜索范围并为下一步提供指导方向。有些步骤只适用于特定情况,例如只有当感染变量从堆中分配时才需要堆分析。
这是任何调查的起点。可观察到的失败必然是由源代码最后一条语句,或者更准确地说是CPU正在执行的最后一条指令所造成的。在崩溃的情况下这是显然的,但是对于非崩溃性失败,可能就有些困难。崩溃情况可能与信号或者进程接收的异常相结合,这说明了异常退出的原因。例如,最常见的段错误信号或者AV(访问违规)异常意味着程序试图访问不属于进程映射段集合的内存地址,或者访问权限有问题,比如写入只允许读的地址;信号总线错误意味着访问不正确对齐地址的内存;信号非法指令意味着线程当前的程序计数器指向不可执行的指令,这通常是因为程序计数器的值是基于损坏的数据对象计算出来的,比如调用已经释放了的数据对象的虚函数。当程序抛出了异常而没有处理这类异常的代码时,C++运行库实现的默认对未处理异常的操作,通常是先生成一个核心转储文件,然后终止程序。
程序的失败通常与最后一条指令尝试访问的地址有关,而这个地址是通过一个被感染的变量直接或间接计算出来的。如果这个地址就是变量的值,这种情况下直接确定导致程序失败的原因很容易。但有时,这个地址是多个计算步骤包括内存解引用的结果,这就需要仔细检查要评估的复杂表达式。例如,由于指向无效地址(如空指针)而导致的内存访问失败,由于无效的指向对象虚函数表的指针而导致调用对象虚函数失败,由于数据成员未对齐而导致读取对象的数据成员失败,等等。该变量可以是一个传入参数、局部变量、全局变量或由编译器创建的临时对象。我们应该清楚地了解该变量的存储类别、作用域和当前状态。它是否在线程栈上、进程堆上、模块的全局数据段上、寄存器中,还是属于线程特定存储,这对问题的原因有重要影响。在大多数情况下,该变量是一个堆数据对象。我们应该确保底层内存块的大小与该变量的大小匹配,以及确定内存块是正在使用还是空闲。如果它是空闲的,首先我们就不应该访问它。
检查当前线程上下文中的所有其他变量,注意那些可能受感染变量影响的变量,其中一些可能也被感染了。失败线程的上下文包括所有的寄存器值、本地变量、传入参数、被访问的全局变量。通过审阅代码和线程上下文,我们可以更好地梳理感染链。
如果以上步骤没有得出结论,我们应该继续检查受感染变量是不是被多个线程共享,甚至正在被其他线程访问。如果有这种可能,就必须梳理其他线程上下文。如果幸运,我们可以找到在其他线程中的罪魁祸首,当然更可能的是我们没有这样的好运气。即使没有看到其他线程破坏了受感染的变量,通过观察其他线程此刻在做什么,也可以形成一个更丰富的问题背景,最终将有助于我们形成更为现实的问题原因的理论。
如果错误数值来源未知的内存,一个有效的方法是读取受感染区域的内存的数值规律,以便找出它是如何被感染的,以及是由谁感染的。有些内存模式具有显著的特征,可以直接归纳到原因。例如,具有可识别内容的字符串,具有明显特征的众所周知的数据结构,带有调试符号的指令或全局数据对象,指向另一个有效内存地址的指针,等等。
一旦我们以ASCII格式呈现一块内存,就很容易识别其中的字符串,指针则不太明显。然而,我们也有办法将它们与整数、浮点数和其他数据类型区分开来:检查进程的地址映射,内存指针应该落在一个有效的内存段中;数据对象的指针应该对齐在适当的边界上;64位指针有许多位是固定的,要么是0,要么是1,因为实际使用中系统只使用了64位线性虚拟地址的一部分(32位指针则较难识别),例如,Intel x86_64 CPU目前仅使用48位有效地址,其余的16位地址总是0;同样地,AIX/PowerPC的堆地址最大有效位是43位(虚拟地址位),其余21位始终都是0。
示例1:下面来看几个例子。下面代码列表中的内存内容似乎是一个可打印的字符数组。如果将内存打印为字符串,它会变成一个域名。通过进一步搜索代码,可以找到使用该字符串的地方。

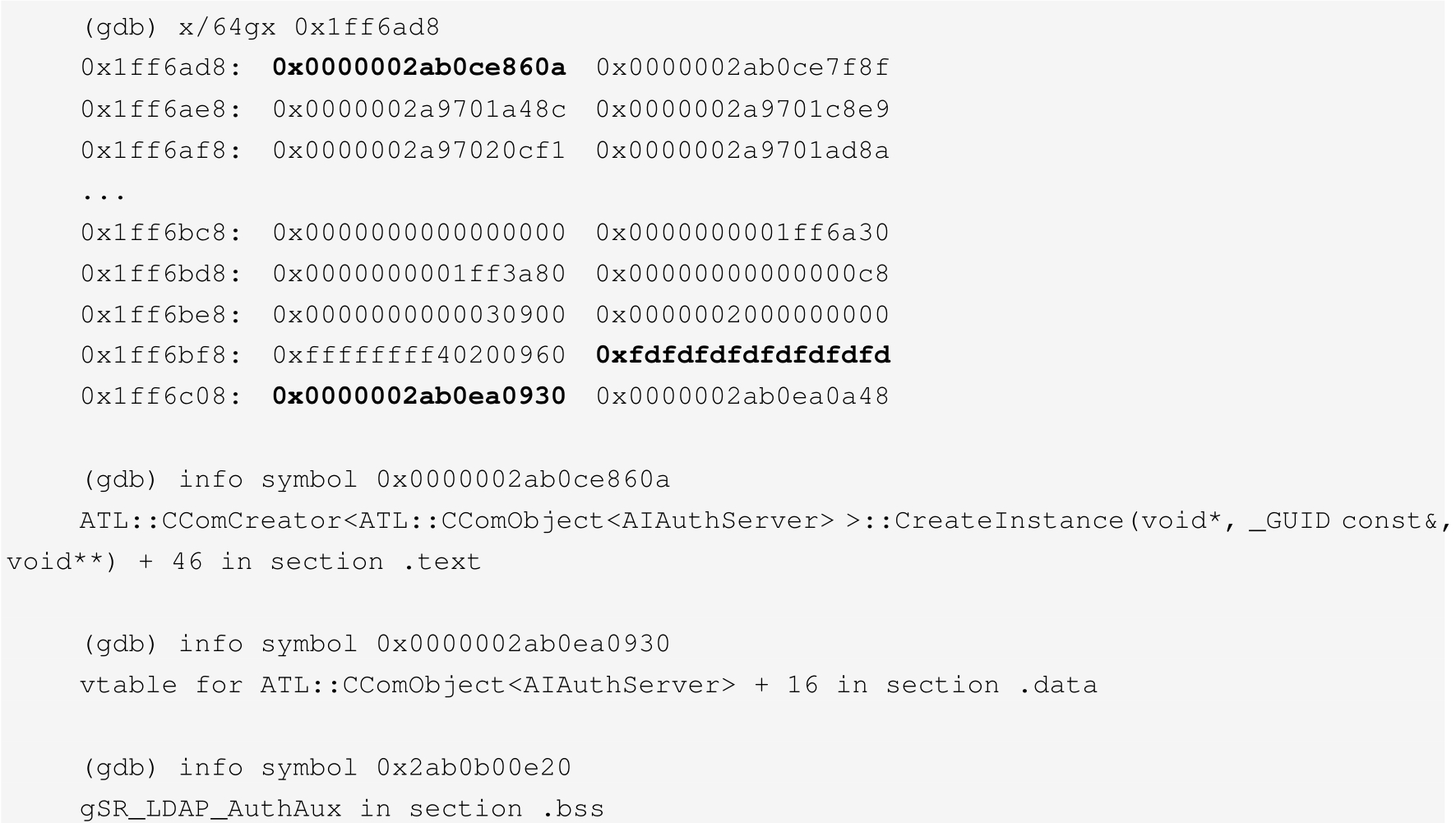
示例2:全局对象包括函数或者变量,具有类似下面内存区域的关联调试符号。我们感兴趣的内存区域的前8个字符看起来像一个指针。通过询问调试器指针指向的内存是否与已知符号相关(GDB命令是info symbol),可以确定它是CreateInstance方法的指令。第二个指针指向位于库的.data段中的对象的虚表。第三个地址属于库的.bss或者未初始化数据段中全局对象。需要注意的是,在地址0x1ff6c00处的字节模式0xfdfdfdfdfdfdfdfd,这是内部工具的数据结构签名,用来跟踪内存的使用情况。
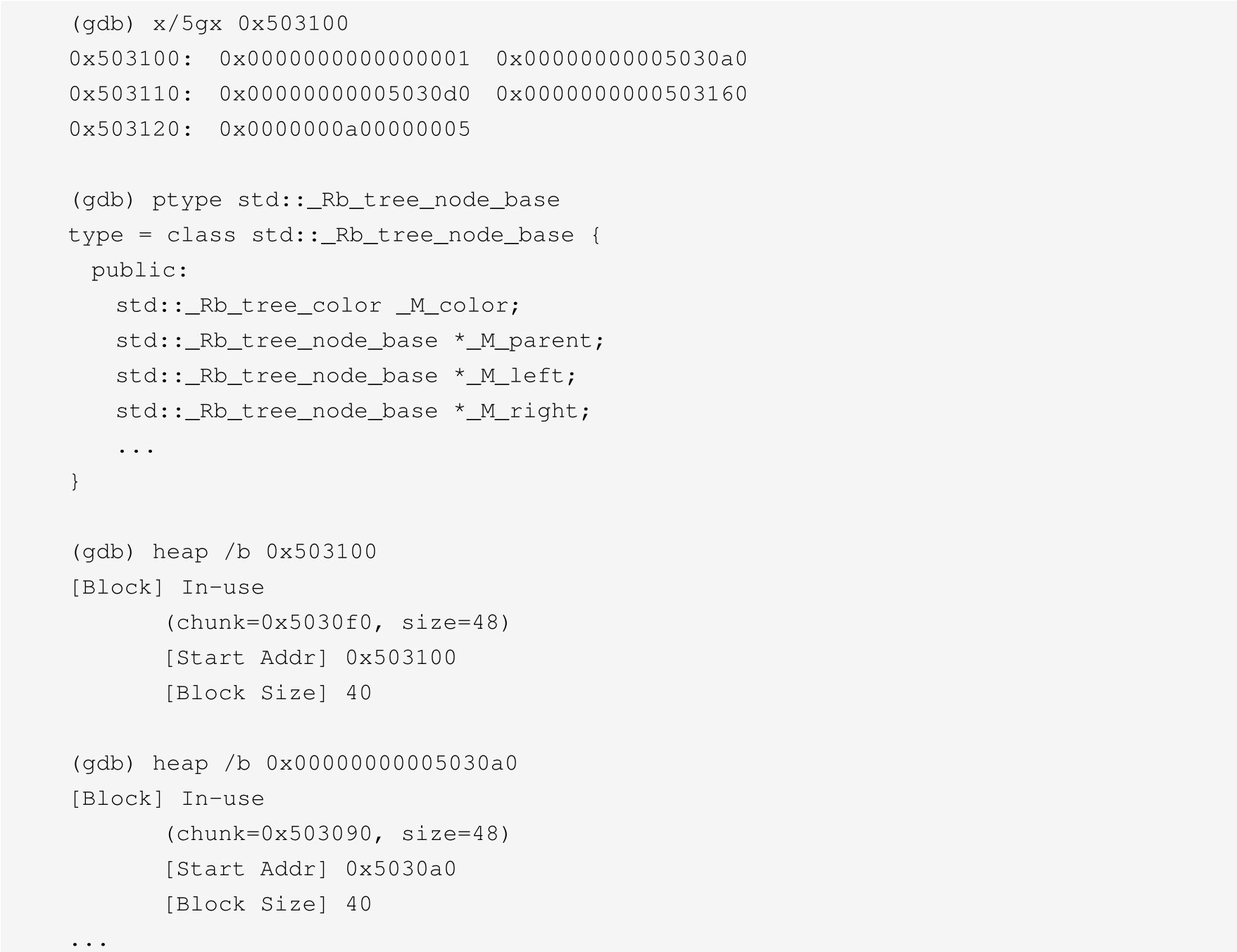
示例3:下面的代码列表展示了另外一种模式。从表面上看,这个40字节的内存块似乎由1个整数、3个指针和另外2个整数组成。其中两个指针指向的内存块也具有同样的构成。因为程序使用了很多的STL数据结构,所以猜测这是一个类std::map<int, int>的树节点并不困难。g++编译器实现的STL map使用了红黑树。树节点声明为std::_Rb_tree_node_base,隐式地跟随std::pair<key,value>(在本例中,键值都是整数类型)。这正是我们在列出的内容中观察到的。通过查询内存管理器,了解指针地址指向的内存块的大小和状态,可以进一步确认我们的猜测。
当把所有这些串联在一起,我们可以更好地理解内存是怎样被访问的。第10章将介绍一个强大的工具——Core Analyzer,它有一个用来自动分析内存模式的函数,可以更好地辅助我们调试。
如果一块内存以看似随机的方式被损坏,并且在审阅代码以后无法使用设计逻辑来解释,那么我们应该将调查拓展到与受感染变量相邻的内存块。由于内存溢出比内存下溢更常见,因此应该优先检查挨着感染内存区域的上一个内存块(地址较低的内存块)。可以通过找到拥有怀疑内存块的变量,并查看相关的代码来确定是否存在这种可能性。
如果感染的变量来自堆中,并且进程存在多个堆,则要找出这个数据对象属于哪个堆。为什么要关心这个呢?因为很多调试过程都是从大量的可能性集合缩小范围,最终定位bug的(分而治之的策略)。
如果涉及堆内存,则完整的堆分析可能会有所帮助。最简单的分析可能是遍历堆并验证所有堆数据结构和内存块的一致性和有效性。如果有任何堆数据结构被损坏的方式,那么这可能是问题的标志,有必要进一步调查。
如果同一类环境出现多个故障实例,我们应该努力找到它们之间的共性。如果所有的故障都发生在同一个地方,有相同的调用栈,那就显而易见了。如果所涉及的数据对象是相同类型的,那么即使它们是为堆动态分配的因而最终表现不一样,但其相似性也是不可忽视的。这些失败模式的知识可以很好地指导下一步调试,也许会涉及内存检查工具或者改造代码(Instrument Code,后续章节会简单介绍)。
完成以上步骤后,我们可以根据收集到的信息构建出程序会失败的一个或多个假设。如果没有足够多的证据表明任何理论,我们应该重复前面的步骤,或者深入挖掘以前可能忽视的地方,或者用不一样的方法运行更多的测试来暴露问题,希望得到更多相关的线索。
以上步骤可以让我们在面对复杂问题时具有下手的地方和思考的方向。对于实际项目的代码,通常有很多的变量和信息要浏览,这需要更多的耐心和坚持,但是当我们最终确定bug时,回报也是巨大的。
如果初始调查没有结论(很多时候是这样的),我们应该怎么继续调查呢?
一个常见的方式是根据搜集到的信息在受控的环境中重现问题。如果问题是可重现的,那么我们可以更近距离地观察问题并用各种方式引导程序。通过透彻地审阅代码,可能得到内存损坏的新理论,就可以在调试器下重新运行程序,在内存块即将被损坏的地方设置数据断点。因为每次程序运行时被损坏的内存块的地址可能会不一样,这种方法可能不可靠。
如果重现问题的时机非常关键,那么调试可能会有所谓的海森堡效应,即调试器带来的失真会改变程序的行为并防止问题重现(后续章节会介绍真实工作中遇到的例子)。另外,为避免内存损坏传播得更远,我们也可以通过各种特制工具尽可能早地检测内存损坏。在后续章节中,我们将会看到这样一些工具和它们的实现。
数据对象是从堆上分配还是在栈上分配对于内存损坏的情况下有着显著差异。
堆对象由内存管理器在运行时分配,它的地址取决于很多因素:
· 具体内存管理器实现的分配策略。
· 内存分配与释放请求的历史,例如它们的大小分布和顺序会影响内存管理器缓存哪些空闲内存块,以及是从缓存中选择新内存块还是从全新的段分配。
· 多线程多处理器环境下的并发内存请求等。
由于其动态特性,堆对象通常在同一程序的各个实例中具有不同的地址。每次分配时,其相邻的数据对象也可能不同。
另一方面,栈变量是由编译器静态分配的。它相对于函数栈帧的地址是固定的,并且相邻变量是已知且不变的。因为内存损坏与罪魁祸首和受害者的相对位置有很大关系(它们通常在地址空间中是相邻的),所以堆内存损坏通常呈现出更多的随机性,而栈内存损坏可能是一致的。
静态分析工具可有效防止多种类型的栈内存损坏。事实上,所有的编译器都已经内置了很多分析功能。例如,如果启用了一定级别的警告,它们能够报告使用未初始化变量的错误。其他专门的工具,如PC-Lint,有更全面的检查列表来发现潜在的问题,如无限字符串复制等。
如果静态分析无法检测到栈内存损坏,那么我们可以尝试在调试器下运行程序。由于损坏的栈对象通常是一致的,我们可以使用数据监测点来捕获罪魁祸首代码。如果每次重现问题时,创建的包含可疑变量的栈帧的位置是变化的,或者调用函数时并不总是发生损坏,则此方法可能不可行。
调试栈内存损坏的另一种方法是通过添加检查与跟踪代码,或在可疑变量周围添加填充字节来检测变量,以吸收错误的覆写。这需要重新编译程序,因此有时可能不太方便。
调试堆内存损坏有大量工具可供选择,从免费的开源工具到昂贵的商业产品,从轻量级插件到具有丰富功能的重型程序。令一些工程师惊喜的是,许多内存管理器已经嵌入了强大的调试功能,只需调用API、设置环境变量或者注册表即可启用这些功能。
无论这些工具看起来如何不同,底层算法实际上非常相似。内存调试工具基本上有3种类型。第一种也是最常用的类型是在分配的用户空间周围,即在每个内存块的末尾或开始处添加额外的填充。额外字节(填充)具有固定的字节模式。设计正确的应用程序不应触及这些填充字节。但有缺陷的代码可能会超越分配的内存块的上下边界,从而修改填充字节,并很可能改变其字节模式。调试工具会在特定位置检查这些填充字节,通常是在内存分配API的入口处,例如函数malloc和free中。如果填充的固定字节模式更改后被调试工具检测到,那么该工具会通过在控制台上打印一条消息、在报告文件中记录错误或该工具支持的任何通信渠道通知用户内存损坏。
第二种内存调试工具使用系统保护页。思路是在怀疑被越界的内存块之前或之后放置一个不可访问的系统页面。为了检测代码是否对已释放的内存进行无效访问,刚释放的内存块会暂时保留一段时间,即使它能够很好地满足新的内存请求,也不会立即重新使用。我们还可以进一步将已释放的用户空间设置为不可访问。当缺陷代码试图非法访问受保护的内存时,系统都会通过硬件检测到该操作并在内存访问指令处停止程序。此方法会在发生无效内存访问时立即将其捕获,因此,可以非常有效地找到根本原因。然而,频繁分配系统页面并将它们设置为保护模式的开销在时间和空间方面都是巨大的,如果影响大到足以改变程序的行为,我们可能根本无法重现故障。
第三种内存调试工具称为动态二进制分析。广受欢迎的基于Valgrind的工具就是这种类型的主要示例。Valgrind是一个动态二进制检测框架,它将客户端程序转换为平台中立的中间表示,然后在其控制下运行。Valgrind会发送程序运行中的一系列事件,比如内存访问、系统调用等。许多工具作为该框架的插件开发,它们通过接收特定的事件来诊断程序的错误。Memcheck就是这样一个常用的插件工具,旨在检测各种内存错误,包括无效访问和内存泄漏。客户端程序的每次内存访问都由Valgrind执行,并且每次发生时都会通知Memcheck。Memcheck在内部使用影子内存来跟踪程序的内存使用情况。换句话说,被调试程序内存的每个字节都被Memcheck中的另一个专用内存投影。影子内存记录了被监控内存的信息,是否正在使用或空闲、是否初始化等。程序代码的每一次内存访问都伴随着影子内存的更新。当发生错误时,例如内存溢出与下溢、访问已释放的内存、重复释放同一内存、使用未初始化的数据等,Memcheck可以通过查询其影子内存立即发现错误。它还可以检测到位的内存错误,并且涵盖所有内存段,包括栈变量。这种方法的缺点是由于细粒度和软件模式检查而导致性能下降太多。据统计,使用Memcheck会使程序速度降低约原来的1/22。然而,这个工具无须重新编译程序的特性以及强大的功能使其成为调试内存损坏的一个重要选择。
在许多情况下,初步调查可以为下一步调试步骤提供指导。选择正确的工具并明智地使用它可以在通宵工作(这对许多程序员来说并不陌生)和与家人一起共度时光之间产生很大的不同。也许这有点夸张,但读者应该明白笔者的意思。我们将在第10章详细讨论内存调试工具。