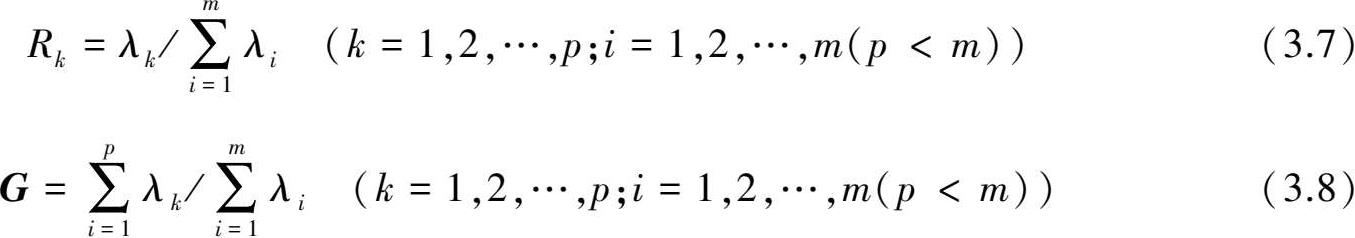下载掌阅APP,畅读海量书库
立即打开



逐步回归分析的基本方法是在所选的全部预报因子集 X 中,按其对预报量 Y 作用显著程度的大小,由大到小逐个地引入回归方程。在变量引入过程中,那些对 Y 作用不显著的自变量 X 从回归方程中逐步剔除,使方程中各个变量都是显著的,最后得到“最优”的回归方程。
我们知道,逐步回归方法在选入或剔除预报因子时,都是基于统计检验( F 检验),所以从理论上并不能以任何概率保证所挑选的自变量的“显著性”。这样,挑选出的预报子集就有可能只是一个局部最优子集,而不是全局的最优 [2] 。因而就不可能充分体现模型特征,对预报工作的准确性产生一定的影响。而最优子集方法正是针对上述问题提出的。该方法是对模型的所有子集进行筛选,即对所有因子进行各种组合,从中选出最优的方程。
选择最优子集就是要确定哪一个子集回归效果最好。在一般情况下,用回归方法建立预报方程时,入选的因子个数越多,方程的复相关系数会越高,方程的拟合效果也会越好,但是仅凭这一点无法作为选择方程的准则。因此,要在众多的因子组合中筛选出最优子集,就需要采用统一标准的准则来衡量各个子集的优劣程度,常用的准则有修正相关系数
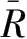 、平均剩余平方和
σ
2
和平均预报均方差
S
p
等,其中修正相关系数着眼于建模,后两个准则着眼于预测,它们对自变量个数的增加进行了较严厉的惩罚,其表达式如下:
、平均剩余平方和
σ
2
和平均预报均方差
S
p
等,其中修正相关系数着眼于建模,后两个准则着眼于预测,它们对自变量个数的增加进行了较严厉的惩罚,其表达式如下:
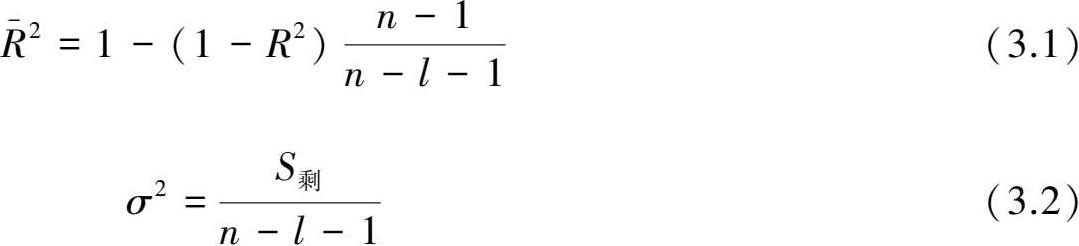
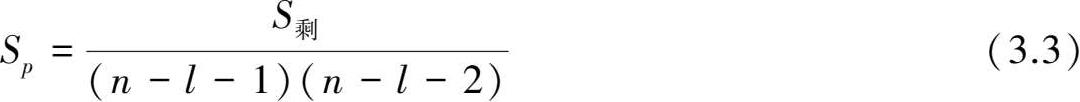
其中
S
剩
为剩余平方和,
n
为样本长度,
l
为选取因子的个数。这样,满足
σ
2
、
S
p
最小,
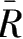 最大的回归模型子集即为最优子集
[2]
。
最大的回归模型子集即为最优子集
[2]
。
但是最优子集回归方法计算工作量相当大,当有 P 个可供挑选的预报变量时,所有可能的回归模型就有2 p -1个,这样当 P 相当大时需检验的样本组合数就会大得惊人,这显然是要付出运算代价。针对此问题,本章首先对预报因子进行逐步回归筛选,筛选出 m 个变量( m ≤15),然后计算 m 个变量与预报变量的全部可能回归找出最优子集,但应注意,如果所得的最优子集恰是逐步回归筛选出来的 m 个变量,这时应放宽逐步回归筛选的变量数,使其大于最优回归所找出的最优子集的变量数。这是因为当最优子集的变量和逐步回归所筛选的变量相等时,表示逐步回归筛选的局部最优子集可能作为最优子集,但逐步回归方法不一定能保证所筛选的子集达到全局最优。
经验正交分解(Empirical Orthogonal Function, EOF)作为一种系统降维和特征提取方法在气象预报和气候分析中已有广泛的应用。其主要优点可归结为:①能用相对少得综合变量因子描述复杂的场资料变化;②当变量值相关密切时,展开收敛速度快,很容易将变量场的信息集中在几个主要模态上;③分解出来的特征向量互相正交,时间系数也互相正交;④能过滤变量序列的随机干扰。
对一个要素场 X 进行EOF分解,可将其分解成时间函数 Z 和空间函数(特征向量) V 两部分,其数学表达式为:

设气象要素场 X 有 m 个空间点,样本长度为 n ,对其作EOF分解时,计算过程可简单概括为:

式中 A 为 m × m 阶实对称方阵, X T 为 X 的转置矩阵。
其中 Λ 矩阵中对角线上的元素 λ 1 , λ 2 ,…, λ m 为 A 的特征值; V 由对应的特征向量 v 1 , v 2 ,…, v n 组成,为列向量矩阵。

其中 V T 为 V 的转置矩阵。