
下载掌阅APP,畅读海量书库
立即打开



本节将通过构造一个简单的编译模型来介绍flex和bison工具的使用。
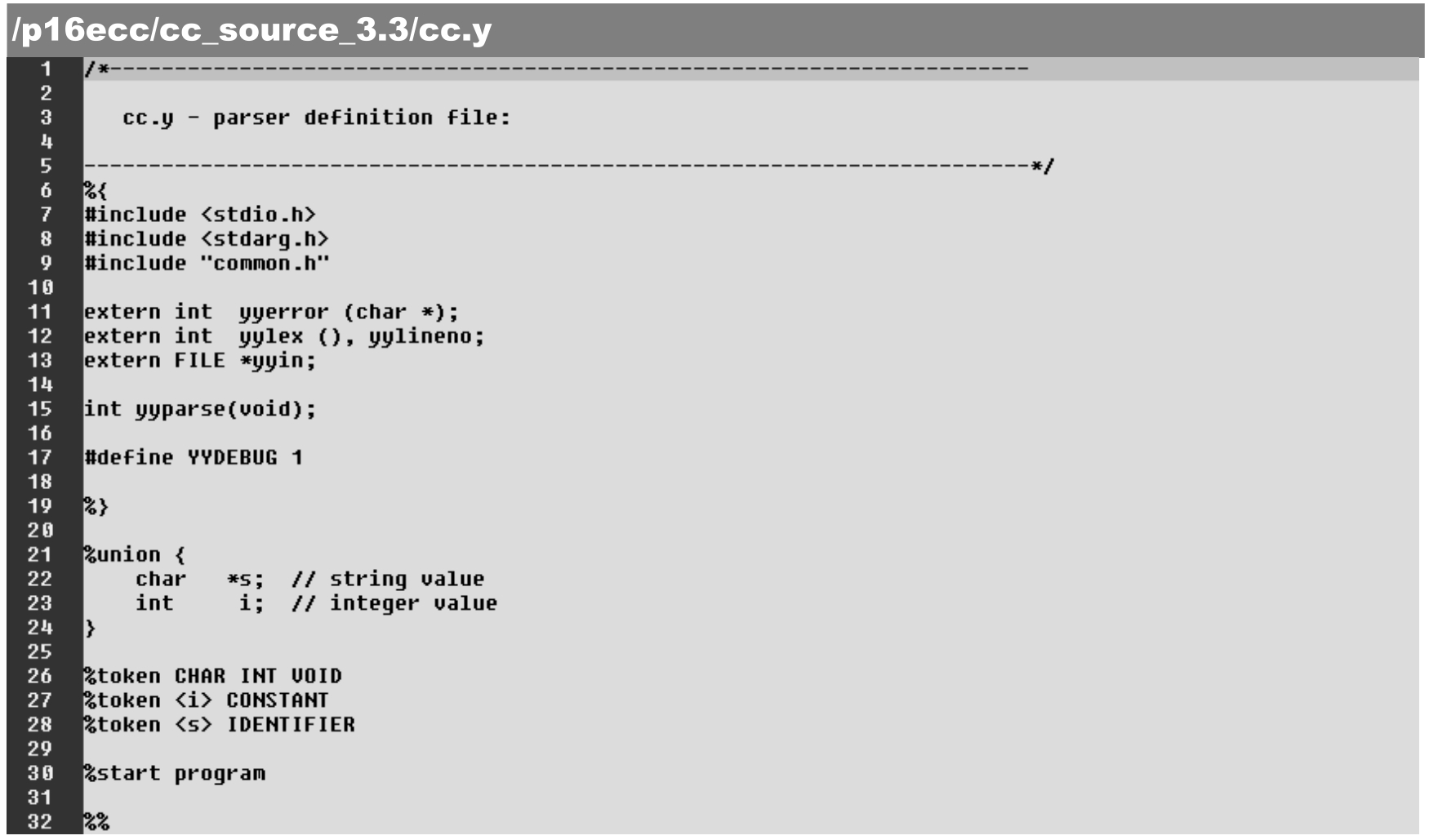
编译器的编译过程包括C语言词法解析和C语言语法解析两个环节,并且前者的输出就是后者的输入。第2章中词法解析器的设计借助了专用工具flex,而语法解析器的设计需要使用相应的专用工具bison。bison的前身是UNIX系统的yacc命令(可执行命令文件)。和flex相似,bison是用于构建语法解析器的工具。它先以语法解析设计文本为输入,生成相应的语法解析器C语言文件,再经过C语言的编译后,最终生成可运行的语法解析器。语法解析设计文本文件是用户设计提供的源程序文件,一般以“.y”为文件名后缀,经过bison命令的处理后,生成后缀为“.c”和“.h”两个C语言文件,如图3-1所示。
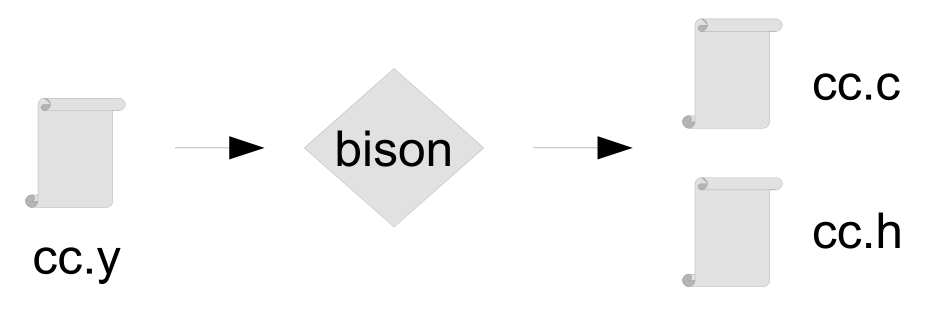
图3-1 bison运行基本过程
cc.c和cc.h这两个文件是cc.y文件经由bison生成的语法解析器的C语言程序,其形式同样是一组以“yy”或“YY”为起始字符的函数和变量。例如,yyparse()为语法解析器启动函数。
类似地,flex的运行和使用过程也是如此,如图3-2所示。
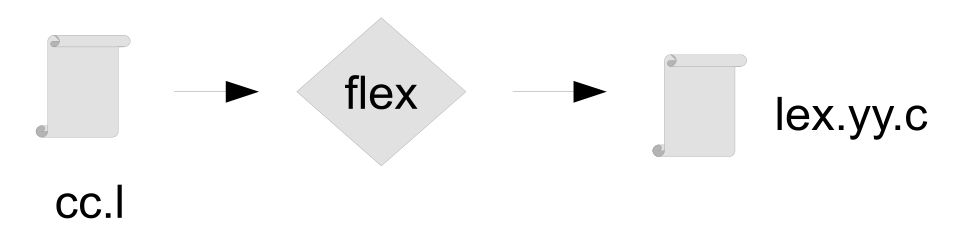
图3-2 flex运行基本过程
词法解析器的设计文本为cc.l。它经过flex的处理后生成词法解析器C语言文件lex.yy.c,成为编译器中的词法解析,提供语法解析的输入。具体说明如下。
(1)cc.l和cc.y文件均为用户设计的文本(源程序文件),而cc.c、cc.h及lex.yy.c文件是由flex和bison生成的C语言文件。
(2)flex可以单独使用,但bison对flex有依赖关系。当两者同时参与编译器设计时,通常会形成互相依赖的关系。具体来说,cc.c文件中将调用lex.yy.c文件中的yylex()函数,获取词一级的输入(token流);而cc.l文件通常要使用cc.y文件中给出的宏定义。
(3)flex和bison均有能生成C++语言输出的词法解析器和语法解析器版本。为了便于理解,本书未采用。
项目任务:作为首个实验,本程序只是用于识别部分C语言关键字(如void、int等)、标识符(如变量名、函数名等),以及十进制常量,并输出相应的提示信息,但没有进行语法解析。因此,设计中只使用了词法解析。
工程项目路径:/cc_source_3.1。
源程序文件:main.cpp、cc.l、makefile。
输出文件:cc16e.exe。
本识别器主要包含cc.l和main.cpp两个源程序文件,经编译后生成cc16e.exe可执行文件。其工程项目文件makefile如下。

其中,cc.l文件中含有主要的运行程序。
在主程序main.cpp文件中,main()函数的操作包含获取输入文件名,并对输入文件进行预处理。经过预处理的文件将成为词法解析的输入,具体如下。

·第4~6行:_main()函数是词法解析的起始,位于cc.l文件的C语言部分,属于外部函数,使用前需要预先声明。
·第10行:支持对多个源程序文件进行逐个处理。
·第15行:调用第2章介绍的预处理器cpp1.exe进行预处理(生成相应后缀为“.c_”的输出文件)。
·第17~19行:对源程序进行词法解析。
·第20行:运行结束后一般删除刚生成的后缀为“.c_”的输出文件(此处暂不做删除处理,仅用于对比源程序文件)。
本词法解析器使用正规表达式的规则识别输入源程序中C 语言关键字的一个子集,并输出显示,具体如下。
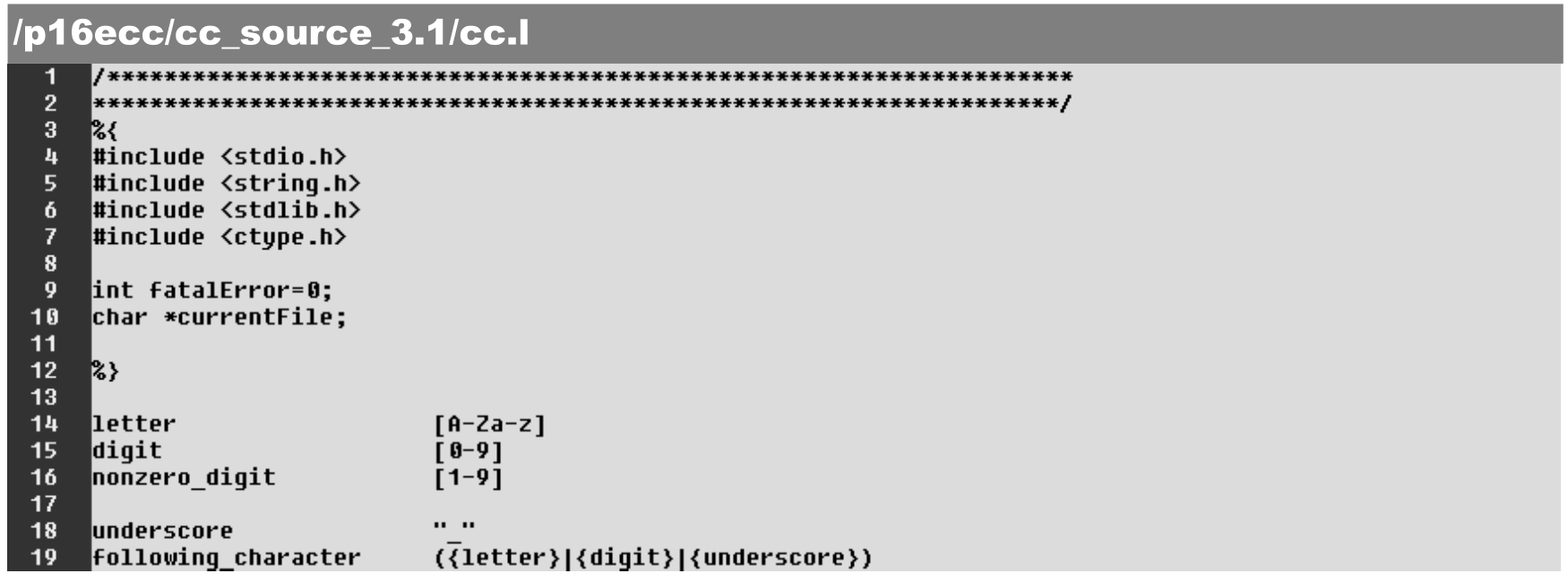
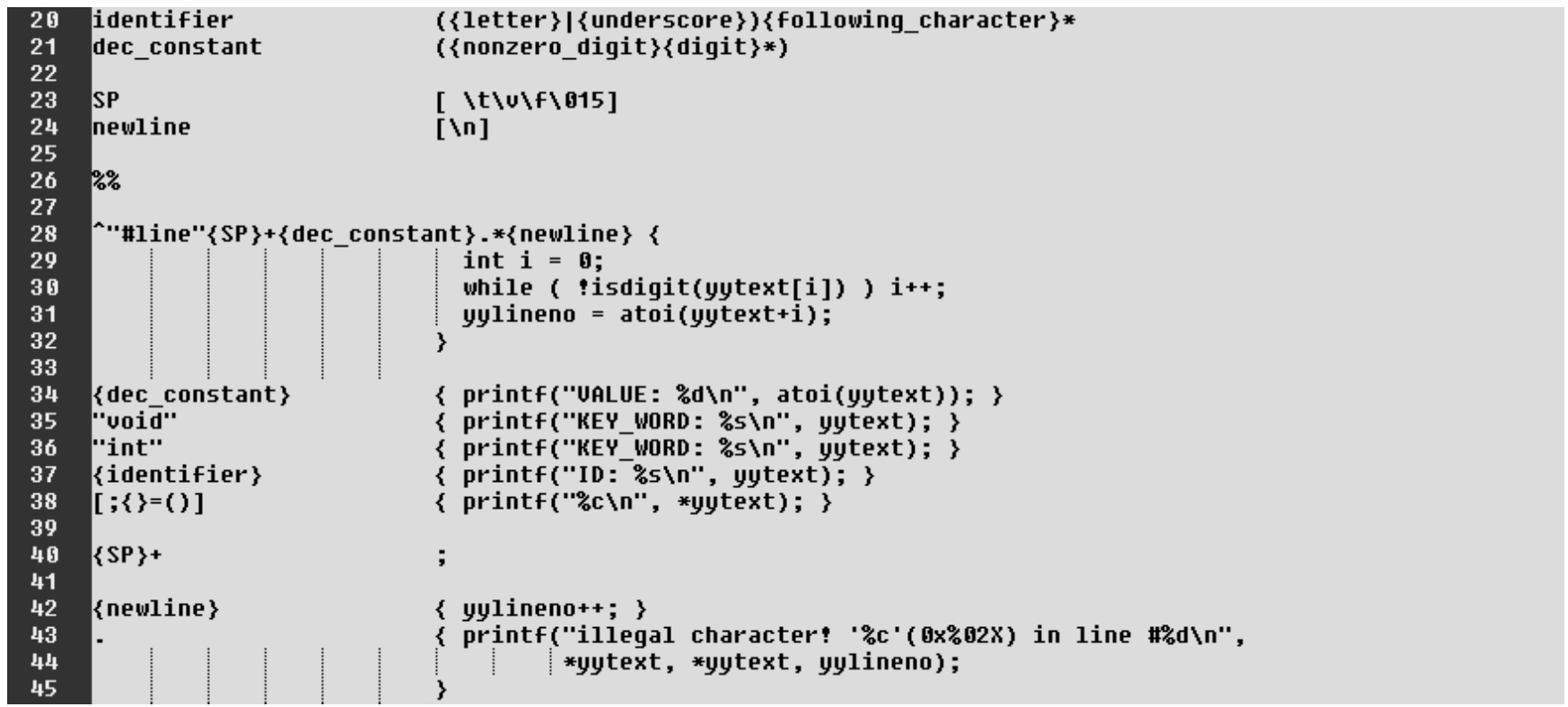
·第20行:宏定义中的标识符的识别规则。
·第21行:宏定义中的(非零)十进制常数的识别规则。
·第28~32行:源程序文件行标记的识别。
·第34行:十进制常数识别。识别后的操作为打印显示内容。
·第35~36行:对void和int这两个关键字的识别。识别后的操作为打印显示内容。
·第37行:识别标识符,并在识别后进行打印显示内容的操作。
·第38行:合法C语言字符(集)识别,并在识别后进行打印显示内容的操作。
·第40~45行:空格和换行符的识别。
很显然,增加识别规则和扩展字符识别集可以提升解析器的识别范围。
cc.l文件中的_main()函数可以打开输入文件,并启动词法解析,具体如下。
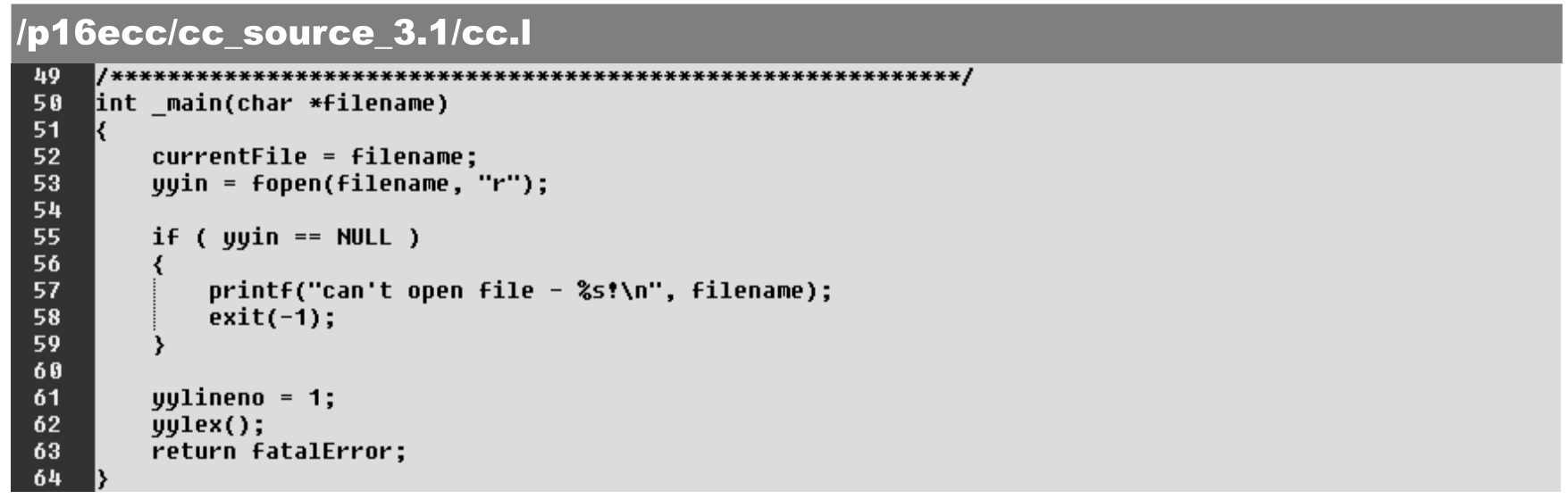
·第52~53行:打开输入文件(由yyin文件指针指定)。
·第62行:启动词法解析自动机。
本节的实验如表3-1所示。
表3-1 简单词法解析实验的运行输出

小结
(1)本节只涉及简单的C语言词法解析器(小部分关键字),旨在介绍如何设计、使用词法解析器。
(2)词法解析后只显示输出。
(3)本词法解析器无法识别数值为零(如“a=0;”语句)的常数。
3.2节在词法解析的部分引入对C语言的关键字,以及对固定常数的解析。其中需要理解的是,一旦调用了yylex()函数,程序将进入词法解析器的内部循环,并不断地从输入文件(由 yyin 文件指针指定)中读入、匹配和打印词法单元,直到遇到 return 语句或调用yyterminate()函数。
由 bison 生成的语法解析器的启动函数为 yyparse()。它将以隐含的方式调用yylex()函数,以便启动词法解析器并控制其运行。而调用yyparse()函数之前,必须先为yylex()函数的运行设定输入文件yyin。作为语法解析的前端输入,当词法解析在读入源程序文件并匹配成功后,相关的信息将通过return语句返回给yyparse()调用函数,成为语法解析的基本输入元素——终结符。
项目任务:在3.2节介绍的基础上,增加语法解析环节,对输入文件(e1.c)进行语法解析、扫描。
工程项目路径:/cc_source_3.2。
源程序文件:main.cpp、cc.l、cc.y、makefile。
输出文件:cc16e.exe。
同样地,本节项目工程文件内容如下,其中包含cc.l和cc.y这两个源程序文件。
本节基本沿用了3.2节设计的词法解析。不同的是,一旦解析匹配完成,将返回识别类型(值),具体如下。

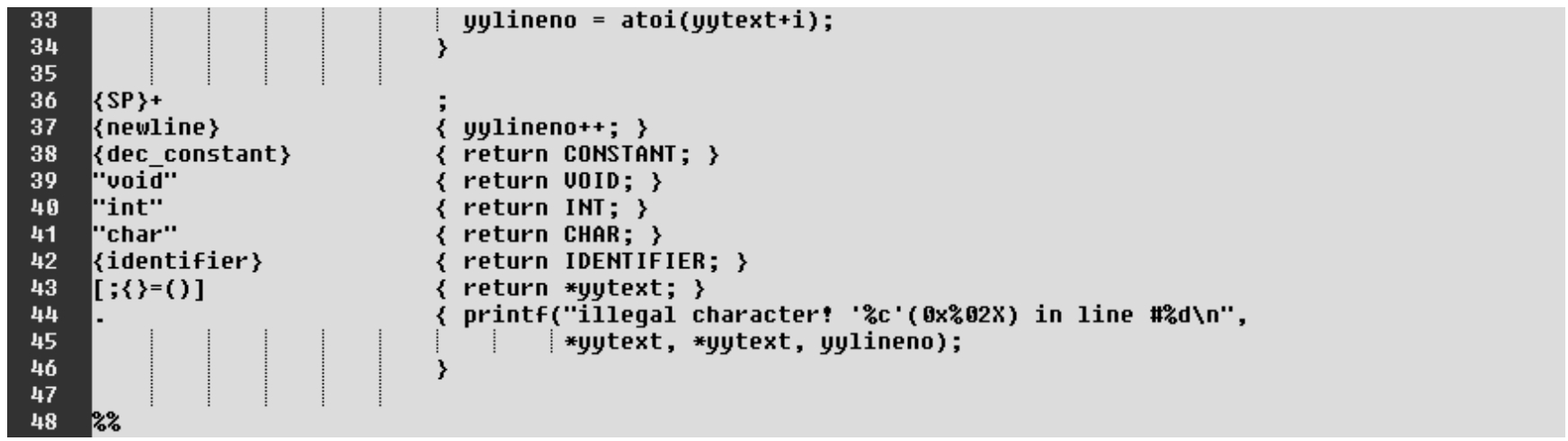
·第38~42行:(关键字)识别成功,返回其token值。注:词法解析返回值{CONSTANT,VOID,INT,CHAR,IDENTIFIER}被定义在cc.y文件中,由bison将其生成在cc.h文件中。它们的值处于≥256的范围,以便区别常规ASCII字符数值。
·第43行:C语言保留字符(集)识别,返回字符数值。
同样地,cc.l 文件中的_main()函数首先需打开输入文件,供解析输入。与之前 3.2.4 节介绍不同的是,它将调用yyparse()函数启动语法解析,具体如下。
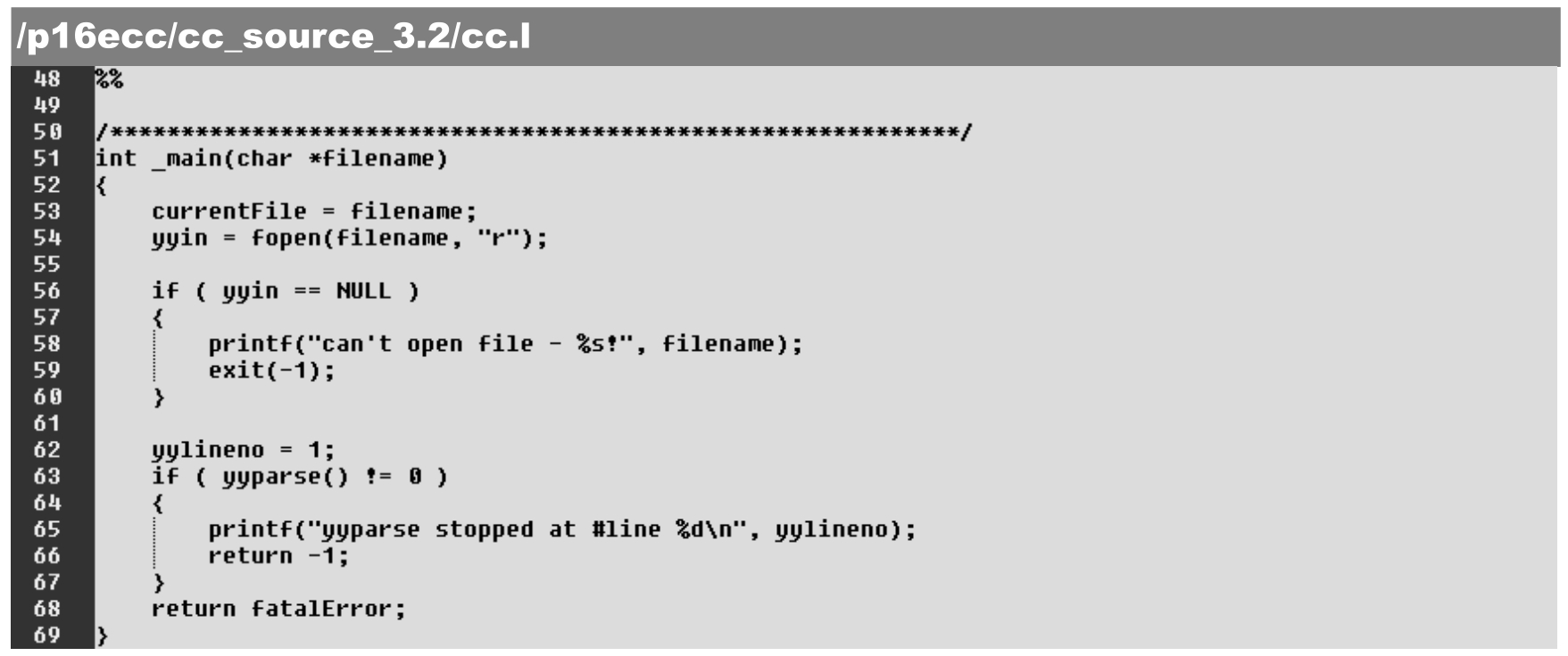
·第53~54行:打开输入源程序(filename.c_),由yyin文件指针所指示。
·第63行:启动并运行语法解析,即调用yyparse()函数。注:此时并不会直接启用词法解析器的yylex()函数。
语法解析器文本是纯ASCII文本形式的文件。与词法解析器文本格式类似,语法解析器文本格式同样从始至终以特殊的字符划分为以下3个区域。


几点说明:
(1)终节点(符):由词法解析器(通过调用yylex()函数)生成的token,即(特定)字符或类型值。
(2)中间节点:表示一组终节点/中间节点的归纳。
(3)各节点的生成规则:用来确定/定义识别法则,即解析器的目标语言语法定义。
(4)语法解析可以有两种不同的理解方式:一种是从顶向下,即从树根向树叶的解析;另一种是从下向上,即从树叶向树根的归纳。
(5)当语法解析完成后,对全部输入进行识别、匹配,其过程及结果便构成了“编译树”或“语法树”。其中,“枝干”部分对应识别规则,“树叶”对应各种token。
语法解析器文本的起始部分如下。作为编译器的雏形,“区域1”和“区域2”所含的内容很简短。
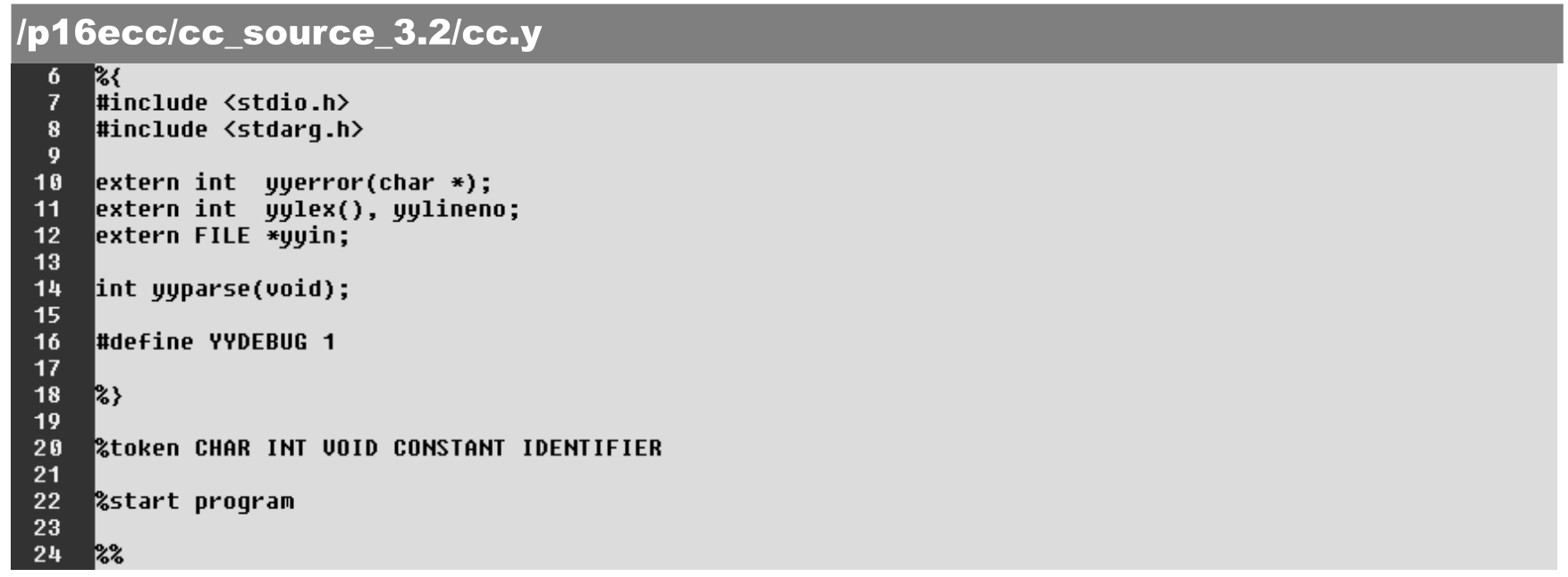
·第10~12行:将引用lex.yy.c文件中的函数与变量。
·第20行:非ASCII字符终结符(token)的命名和定义,并以enum{}的形式列入cc.h()函数。
·第22行:语法解析最终归纳的终节点——编译树根节点标记,也可以理解为语法解析的起始。
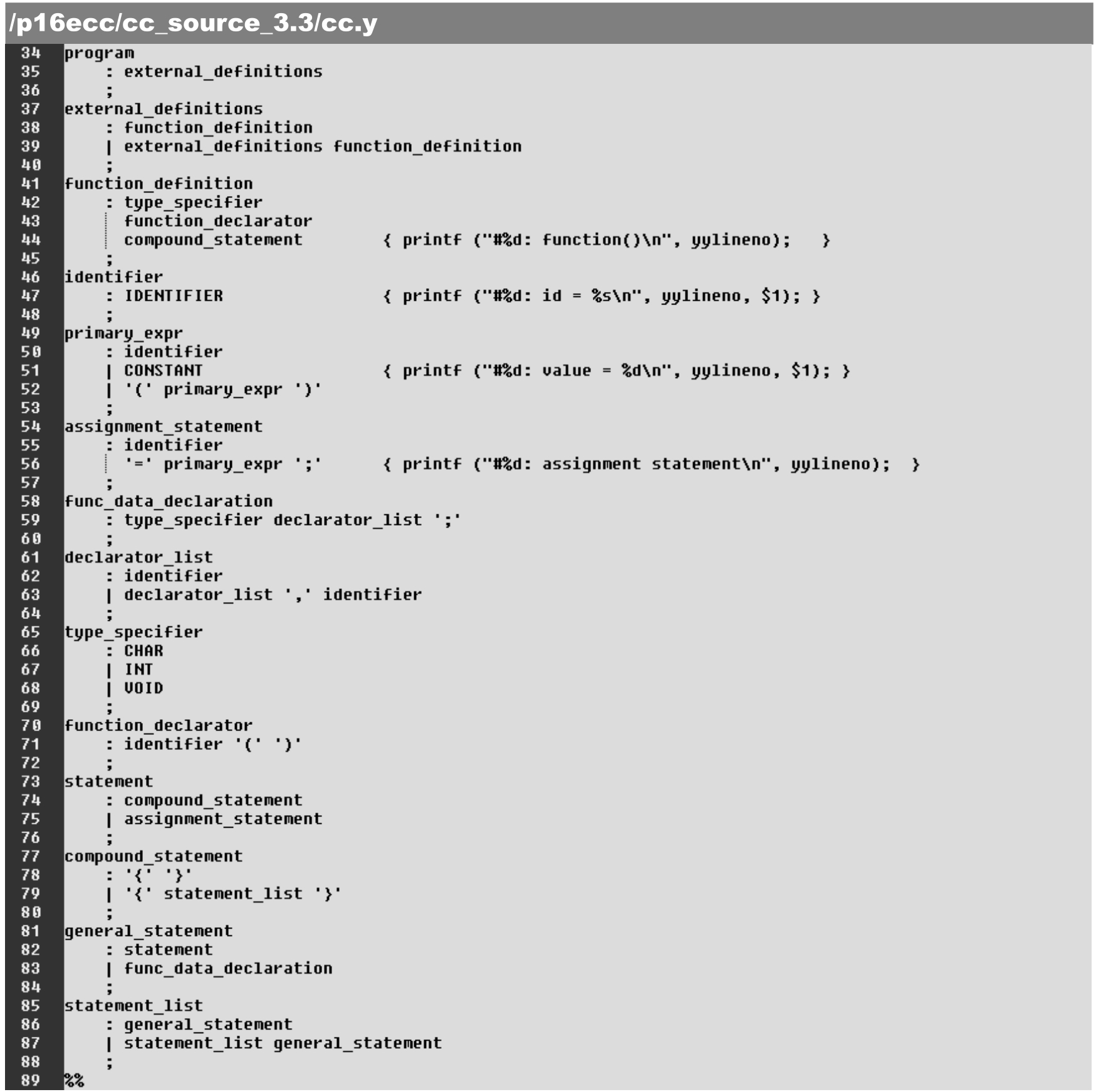
语法解析器文本“区域3”定义了语法解析规则,对应了yyparse()函数的基本内涵,具体如下。作为基础性实验,这里给出一个 C 语言子集语法解析识别/生成规则。bison 使用BNF的描述格式定义解析器需识别/定义的语法规则。使用BNF 格式描述/定义解析器的识别在语法形式上很直接,也容易理解。
BNF对语法描述的规则/格式也被称为产生式(generation),可以简单地概括为:
归纳后的节点:节点 1 节点 2 ...节点 n 。
具体如下。
(1)字符“:”和“;”用来识别规则中解析序列的起始和终结。
(2)“节点 1 节点 2 ...节点 n ”是一组由各类节点组成的序列,包括中间节点和由yylex()函数读取的终节点token,以及用户插入的C语言处理代码。
(3)“节点 1 节点 2 ...节点 n ”以$ 1 、$ 2 、…、$ n 为序列标记,而归纳后的节点以 $$为标记。这类标记将以变量的形式出现在产生式的C语言代码中(本节暂未使用)。
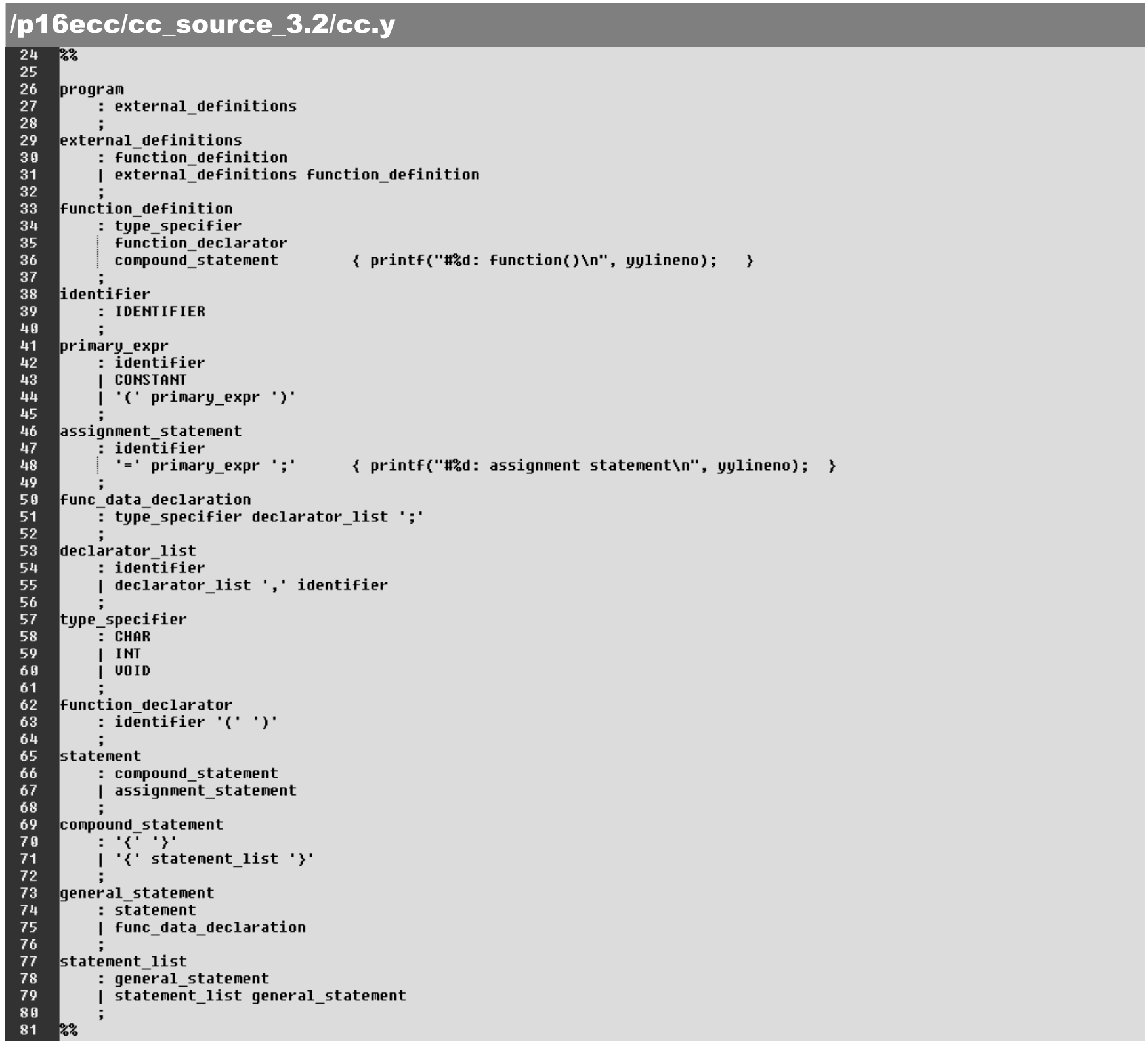
·第33~36行:函数定义的语法识别。识别后的操作为打印输出提示及对应的源程序行号。
·第46~48行:赋值语句的语法识别。识别后的操作为打印输出提示及对应的源程序行号。
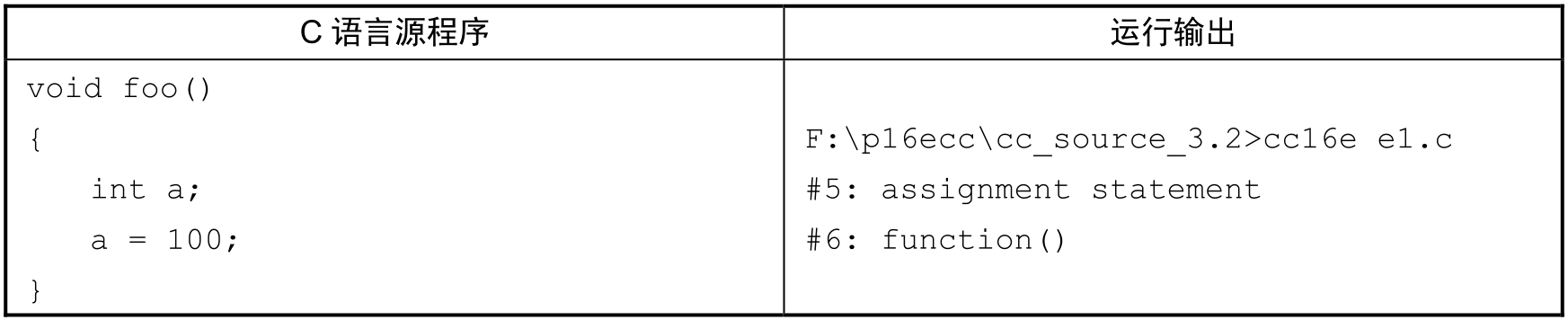
本节的实验如表3-2所示。通过运行命令:

得到运行结果。
表3-2 简单语法解析实验运行输出
其对应的编译树(或语法树),如图3-3所示。
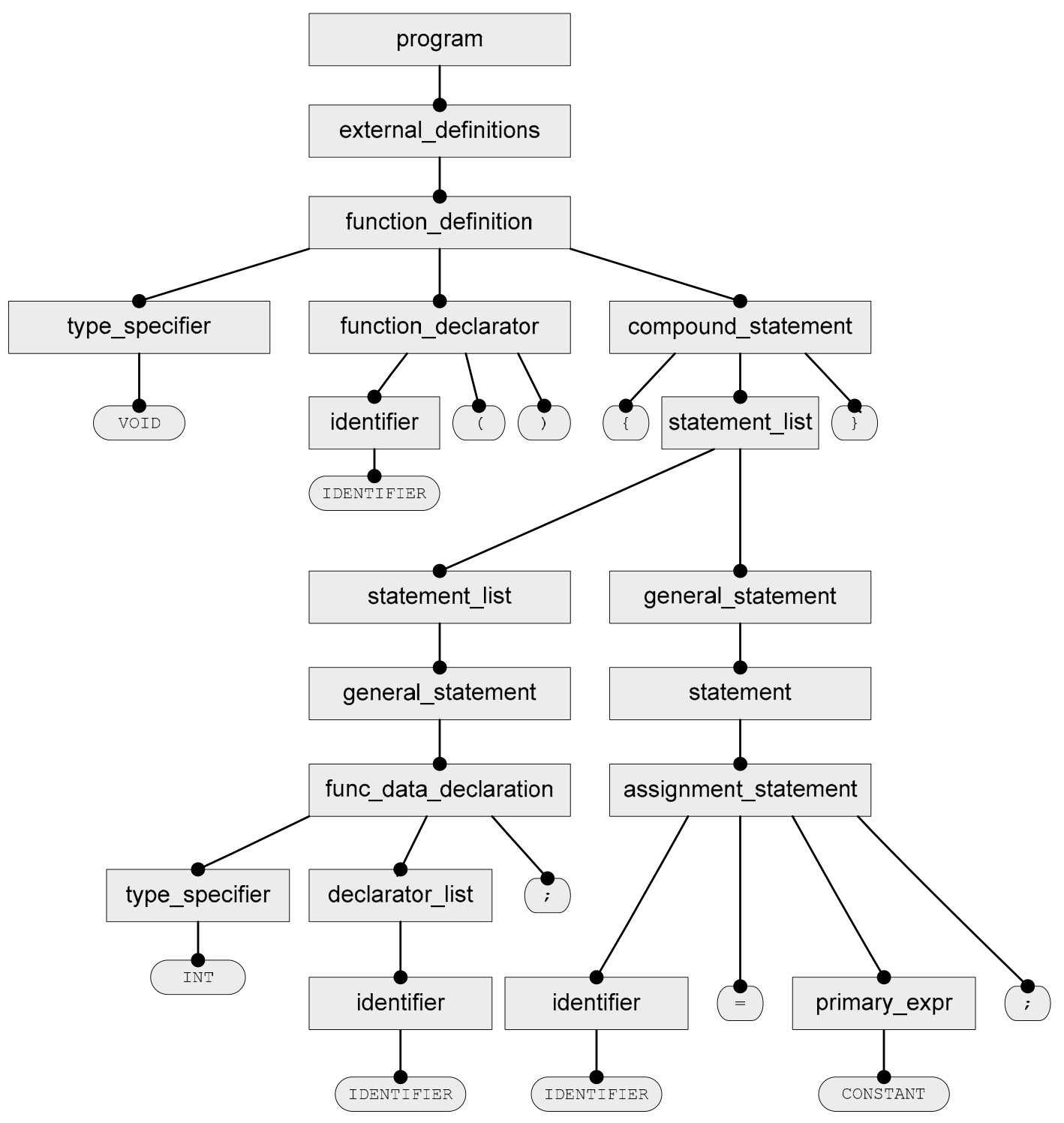
图3-3 实验对应的编译树
3.3 节介绍了语法解析,以及语法解析器与词法解析器的设计基本手段及两者在运行中的配合。但其中的词法解析对于标识符IDENTIFIER和常数CONSTANT类的节点只提供给词的类型值(或token值)而缺少其具体内涵,因此无法进行具体的编译输出。比如,标识符IDENTIFIER的具体字符串,以及常数CONSTANT的具体数值。为此,bison/flex提供了一种手段,词法解析器除了返回类型值,同时通过变量yylval,提供token的具体内涵/数值。
yylval 是bison/flex中定义的数据,用于表示和容纳各节点或 token 数据,并采用联合(union)的数据结构以涵盖各种类型的数据。而数据成员类型及命名,则由使用者自行确定。在本节中,将yylval的内部成员定义为:

理论上,最终(根)节点和所有中间节点均属于yylval的某成员数据类型。因此,语法解析/归纳的过程也是对这类数据的解析/归纳。而对yylval数据的具体使用和操作,则由用户在识别规则中插入的C语言代码完成。
工程项目路径:/cc_source_3.3。
源程序文件:main.cpp、cc.l、cc.y、makefile、common.c/common.h。
输出文件:cc16e.exe。
在3.4节的基础上,对cc.y文件进行扩充,具体如下。
·第9行:引用common.h文件,为解析过程定义并提供所需的各种数据类型和函数。
·第21~24行:对yylval的成员进行定义。注:此处语法结构与C/C++语法有所不同。
第26~28行:终节点token类型枚举,所有由“%token”定义的标识符将被列入枚举(enum语句)列表中,通过cc.h文件输出,供cc.l文件引用。其中,CONSTANT用来追加其yylval的成员类型为i(%union中的整数成员“int i;”);IDENTIFIER用来追加其yylval的成员类型为s(%union中的字符串成员“char*s;”)。
识别规则后的操作扩充如下。
其中:
·第47行:对IDENTIFIER进行识别/匹配处理,即显示字符串内容。该节点元素的数据类型为char*。
·第51行:对CONSTANT进行识别/匹配处理,即显示整数值。该节点元素的数据类型为int。
此处,$ 1 、$ 2 、…、$ n 表示语法规则中各节点元素位置序列成员(token)的yylval数据。而$$对应语法规则中的归纳结果yylval数据。
相应地,词法解析将使用yylval,具体如下。
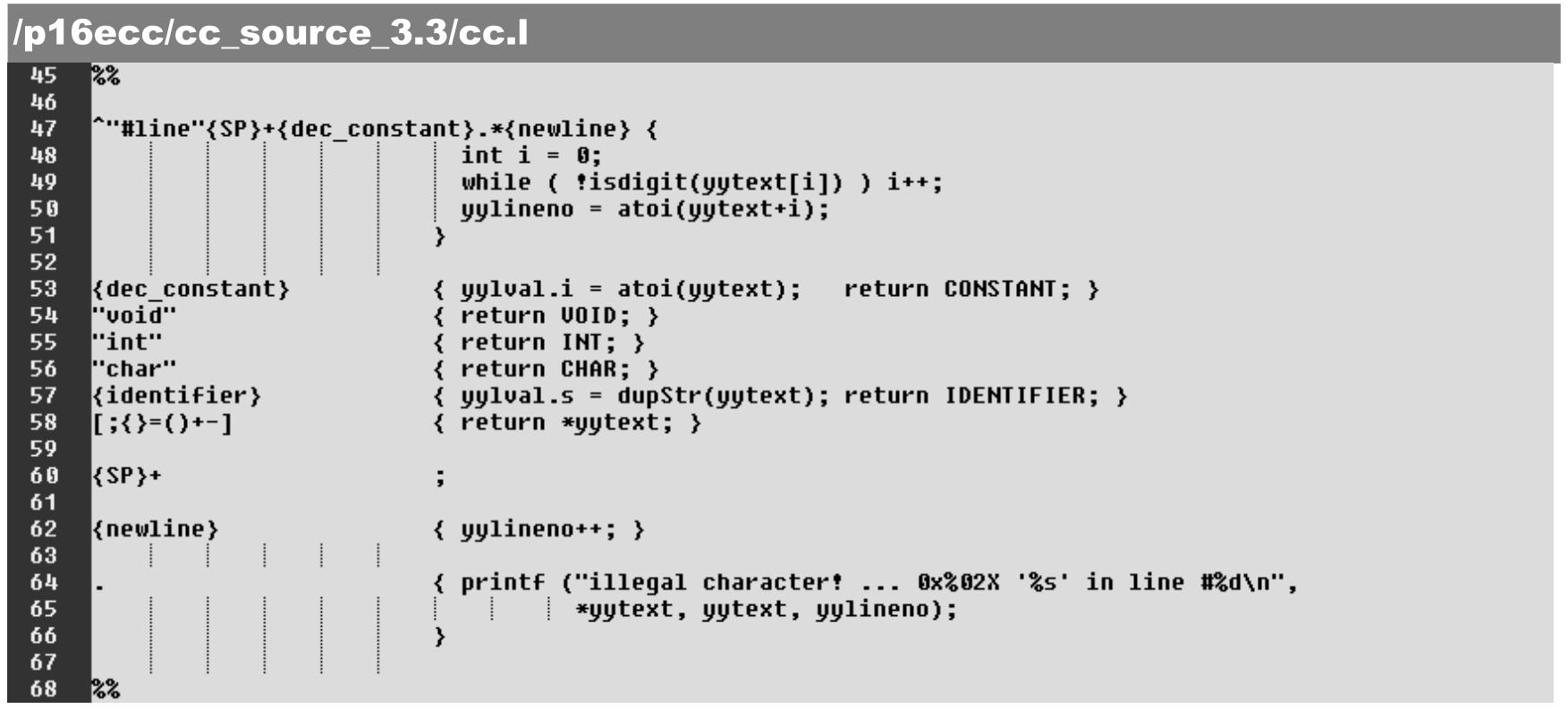
·第53行:识别整数,并获取其数值,赋予yylval.i,而后返回其token值CONSTANT。
·第57行:识别标识符,并获取其字符串,赋予 yylval.s,而后返回其 token 值IDENTIFIER。
本节的实验如表3-3所示。
表3-3 语法解析实验的运行输出

小结
(1)本节给出的语法分析只包含C语言标准的一个子集。
(2)语法解析生成式只属于实验举例,某些处理并不符合C语言语义规范。
(3)本节的实验结果不会生成最终的编译树数据实体。
为了构建一棵编译树实体,在3.4节的基础上,为所有中间节点赋予某种数据类型。通过数据之间的归纳连接,最终在根节点获得表示输入源程序的全部语义的树状数据结果。
因为解析/归纳过程中节点的数据类型差异,并使用yylval 作为类型索引,所以需要在yylval联合结构中增加相应的数据类型。

其中,node和attrib是新增的数据类型,用来表示节点和特征,其具体描述都在common.h中。事实上,node是所有节点的概括或总称,也被称为抽象节点。节点的具体类型和内涵可以分为以下5种。
(1)常数节点:表示一个常数。
(2)字符串节点:表示一个字符串。
(3)标识符节点:表示一个标识符(如变量名、函数名等)。
(4)操作运算节点:表示某一个操作(若干节点的结构关系,长度可变)。
(5)列表节点:表示一个列表(若干node的单链,长度可变)。
node是一个联合结构,可以匹配各种节点,从而使各种节点可以共享同一种表示方式,这也是本设计中常用的类型。
工程项目路径:/cc_source_3.4。
源程序文件:cc.l、cc.y、common.c/common.h。
所有的数据结构由用户根据编译器设计中的要求而设计,并在common.h文件中定义,具体如下。
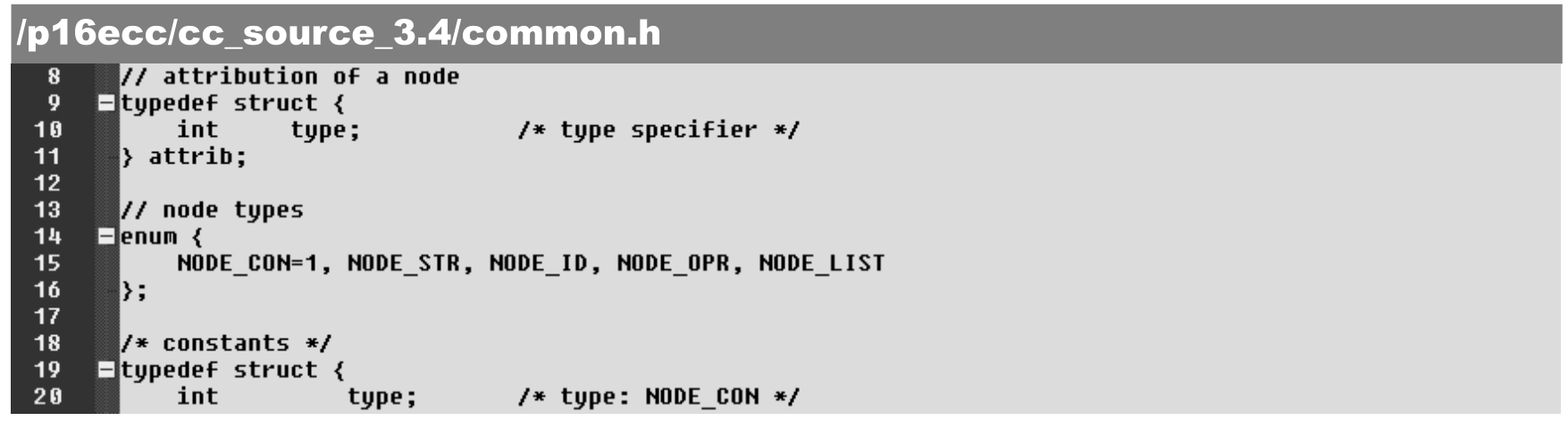
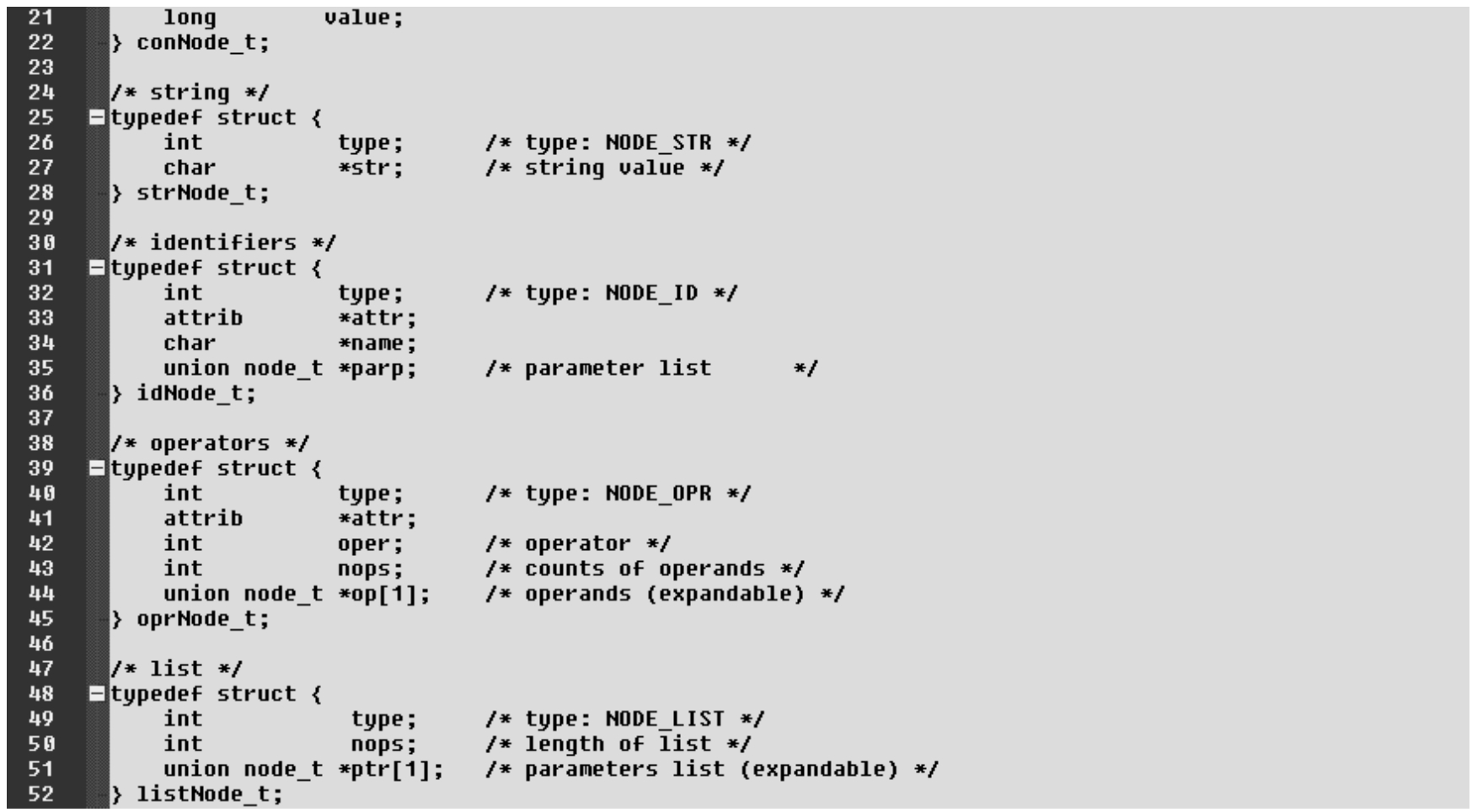
·第8~11行:特征attrib的数据定义。
·第14~16行:枚举5种节点类型名称。
·第18~52行:各种节点的具体数据结构定义。注:每一种节点结构的首端都必须为“int type;”。
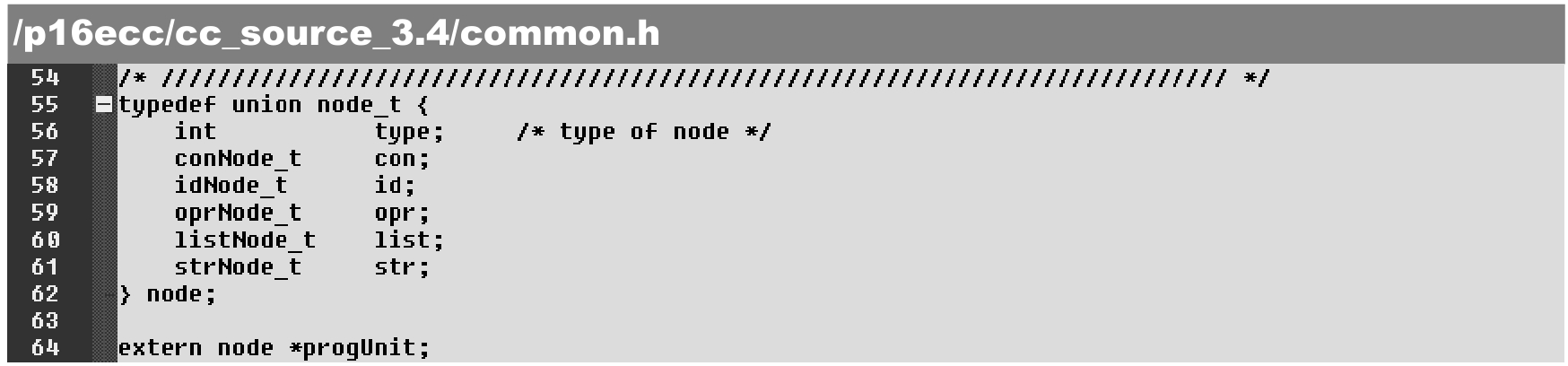
·第55~62行:node联合的结构定义可以对各种节点数据进行归纳或同质化,因此可以用node结构表示各种节点。
·第64行:解析结束/归纳后得到最终的编译树数据(指针)。
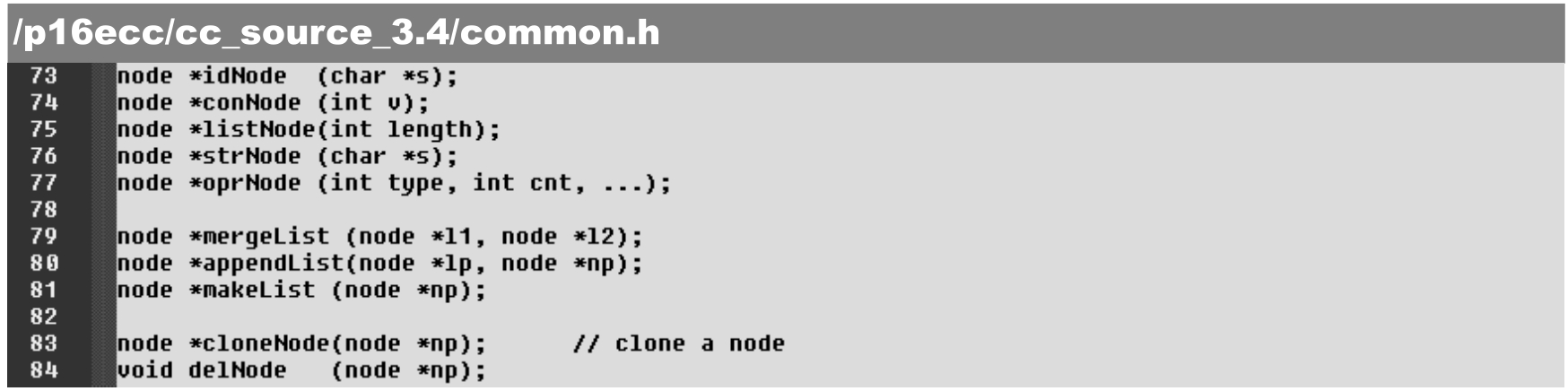
common.h文件给出了各类节点的创建、清除,以及扩展函数,具体如下。
由于引入新的数据结构,语法解析器文本cc.y中的各种节点均被赋予相应的类型,具体如下。
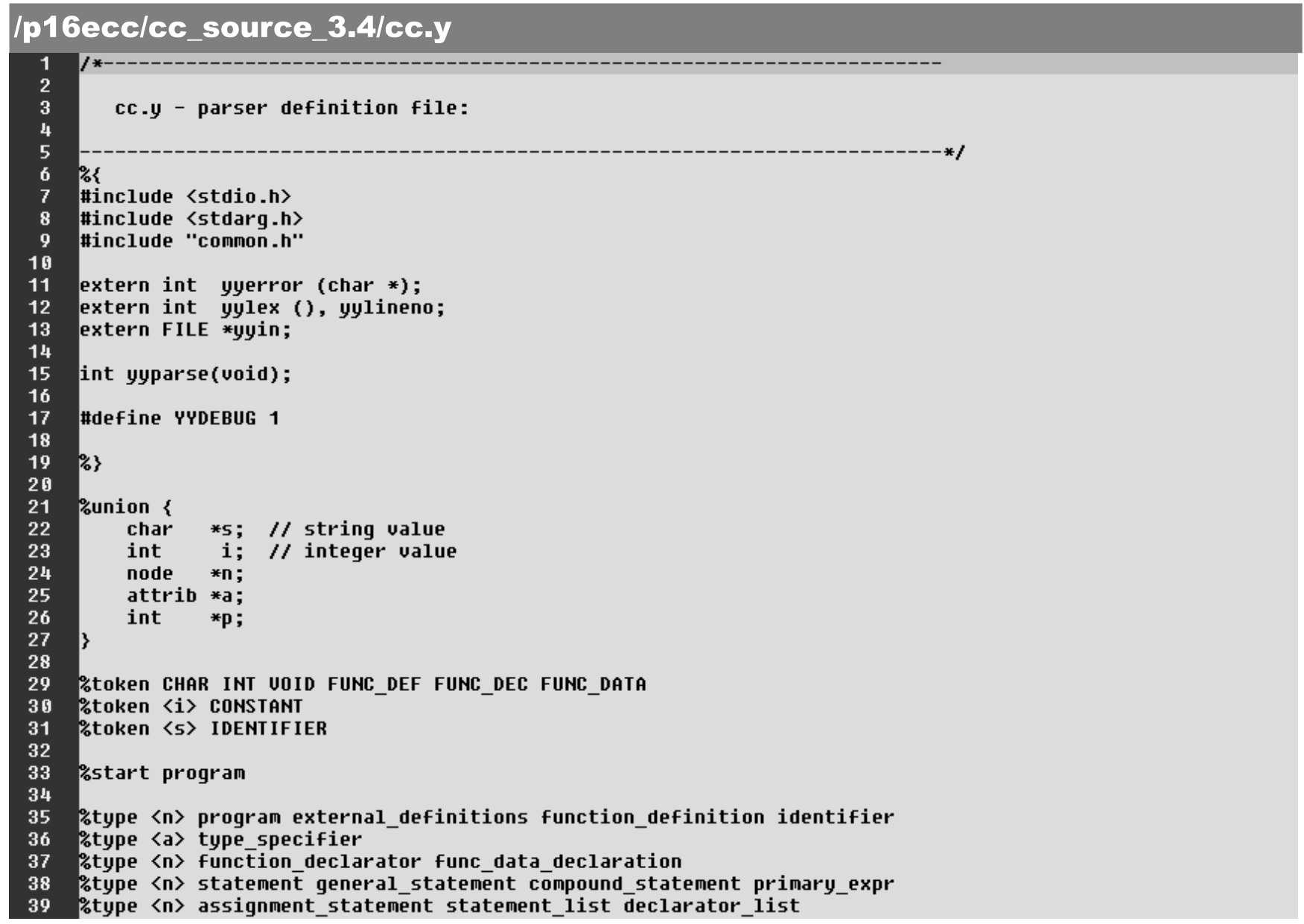
·第21~27行:增加yylval的数据类型成员。
·第29~31行:枚举(列出)所有终节点token,并确定CONSTAN和IDENTIFIER的相应数据类型。
·第35~39行:定义中间节点的数据类型。
与此同时,在产生式中增加了匹配后的处理(C 语言格式的语句代码)。将节点序列标记($1、$2、…、$$)作为运算变量,具体如下。
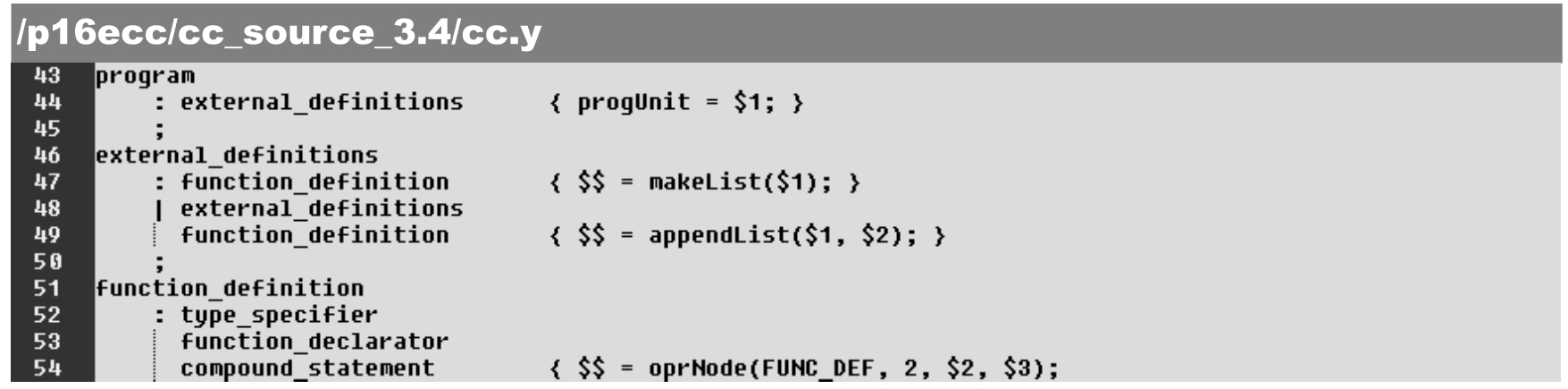

在上述各解析规则(产生式)的C 语言代码操作中大量使用中间节点的数据表示$$、$1、$2、$3等。例如,第58~60行:

其中$1是IDENTIFIER本身的yylval(类型为“char*s;”),由idNode()函数生成类型为idNode_t的数据节点,最终传递(赋予)归纳后的节点为identifier,并释放IDENTIFIER在(flex中)生成时占用的内存。
当解析成功结束后,输入源程序的全部信息被转换、归纳为编译树,并且由节点program(progUnit指针)指示、输出。
小结
(1)本节展示了在语法解析过程中生成编译树的具体手段,以及相应的语法。
(2)在最终结果中,编译树蕴含全部输入源程序的内容及其对应的语义关联信息。
(3)cc.y文件中的产生式序列(列表)和common.h文件中定义的数据结构是简化后的模型,尚不覆盖C语言的语义范畴。
(4)作为练习,读者可以在 main.cpp 文件中添加有关程序,以梯形图方式打印显示progUnit所提供的编译树输出内容。
作为一个应用程序/工具,编译器可以对用户源程序语言进行转换和输出、对用户源程序的语法和语义进行检测,也可以提供源程序中出错的准确位置,还可以将源程序中按语句嵌入到对应的输出文件中,甚至可以作为对比参照,此举具有重要意义。而完成这一嵌入操作的前提是在词法/语法的解析过程中将输入的源程序按解析内容进行截取,并随着编译器的运行逐步将这些源程序代码传递至最后的输出。由于语法本身的复杂性,加上用户源程序的代码排列格式经常带有某种随意性,使得对源程序语句片段的提取及输出嵌入的过程有一定的难度。
源程序语句片段的截取是从词法解析器(flex)中进行的,截取的片段被存入专用的缓冲区中(flex/bison并不提供此服务,需用户自行解决)。在语法解析过程中可以获取缓冲区中的内容,拼凑并嵌入到恰当的输出(编译树)位置。
需要理解的是,在大多数情况下,只需将部分(有意义的)源代码截取并嵌入编译树即可。
工程项目路径:/cc_source_3.5。
源程序文件:main.cpp、cc.l、cc.y、common.c/common.h。
输出文件:cc16e.exe。
对于源代码的截取将在词法解析的过程中进行。为此,将在词法解析器文本中设置用于源程序截取的缓冲区及标识,具体如下。

·第16~17行:定义缓冲区及其指示(emptySrc=1 表示缓冲为空)。
源代码截取发生在对词法解析成功后,即一旦某输入字符(串)满足识别规则后,该输入字符(串)的内容便被送入上述的缓冲区中,具体如下。
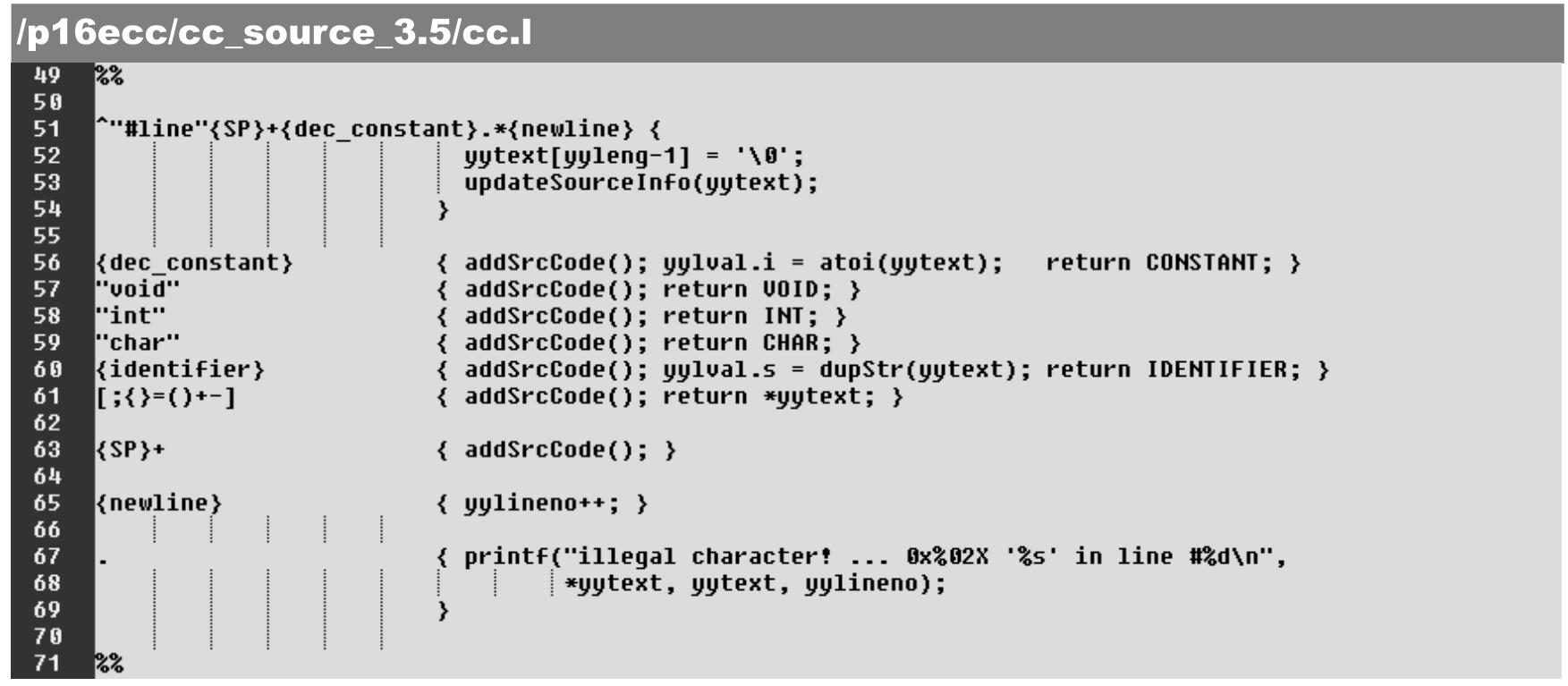
·第52行:清除缓冲区结尾的换行符。
·第56~63行:识别/匹配成功后,在返回token值之前将对应的源代码送入缓冲区中。
源代码缓冲的内容将由语法解析通过调用下述的函数读取,具体如下。

·第108~115行:getSrcCode()函数在语法解析的cc.y文件中调用,用来获取当前缓冲区内源代码片段;结束时设置emptySrc,用来清空缓冲区。
·第117~128行:通过updateSourceInfo()函数来设置/更新源代码的文件信息(如文件名、行号等)。
相应地,为了在语法解析过程中将获得的源程序片段存入编译树中,需要在 common.h文件中对各类node的数据结构进行扩充,具体如下。

·第8~12行:用于容纳源代码片段的数据结构并定义src_t。
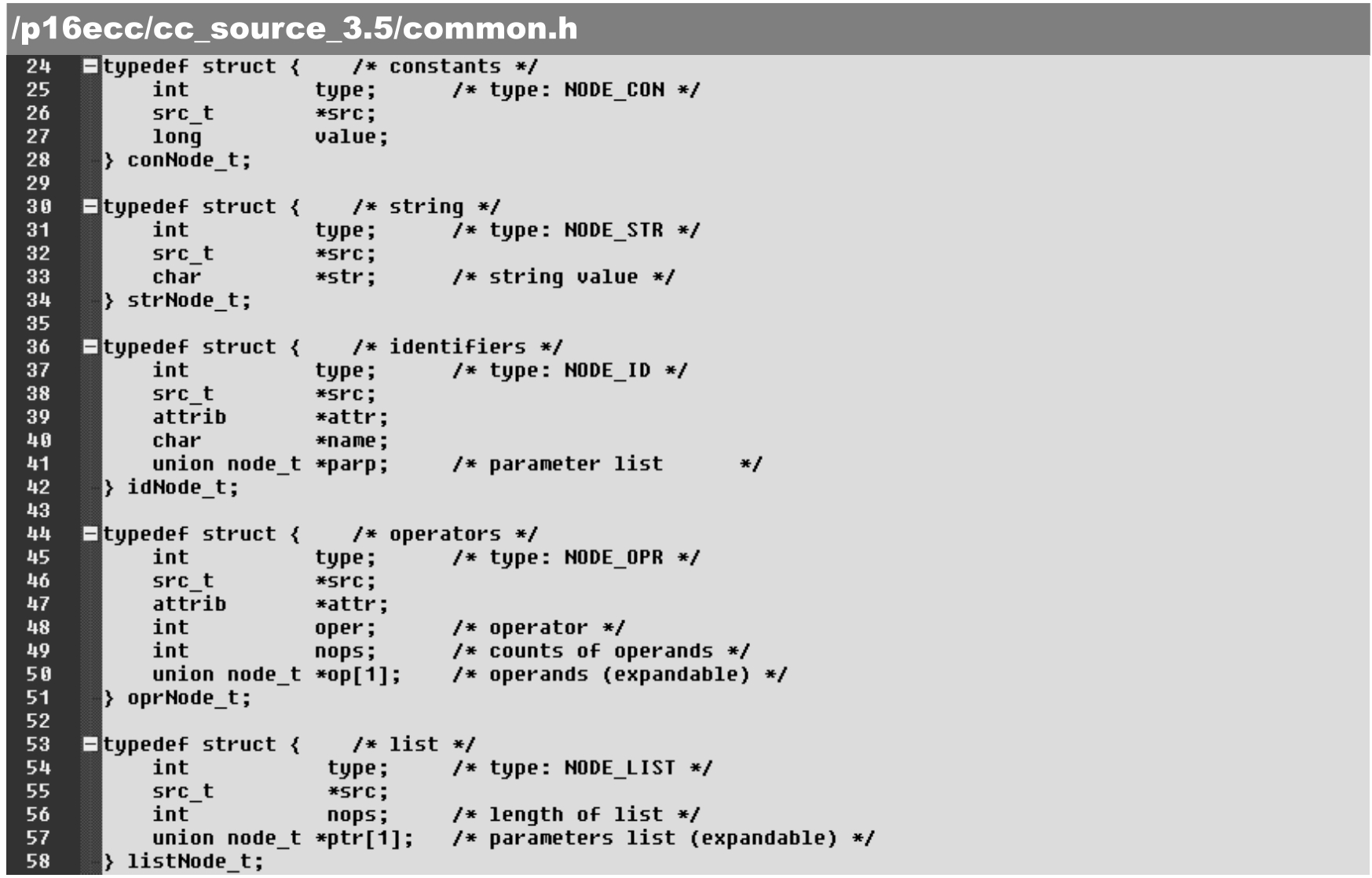
·第24~58行:在各类node数据结构的同一位置中增加src_t的*src指针。
相应地,在common.c文件中增加支持源程序片段截取后嵌入节点的函数,具体如下。
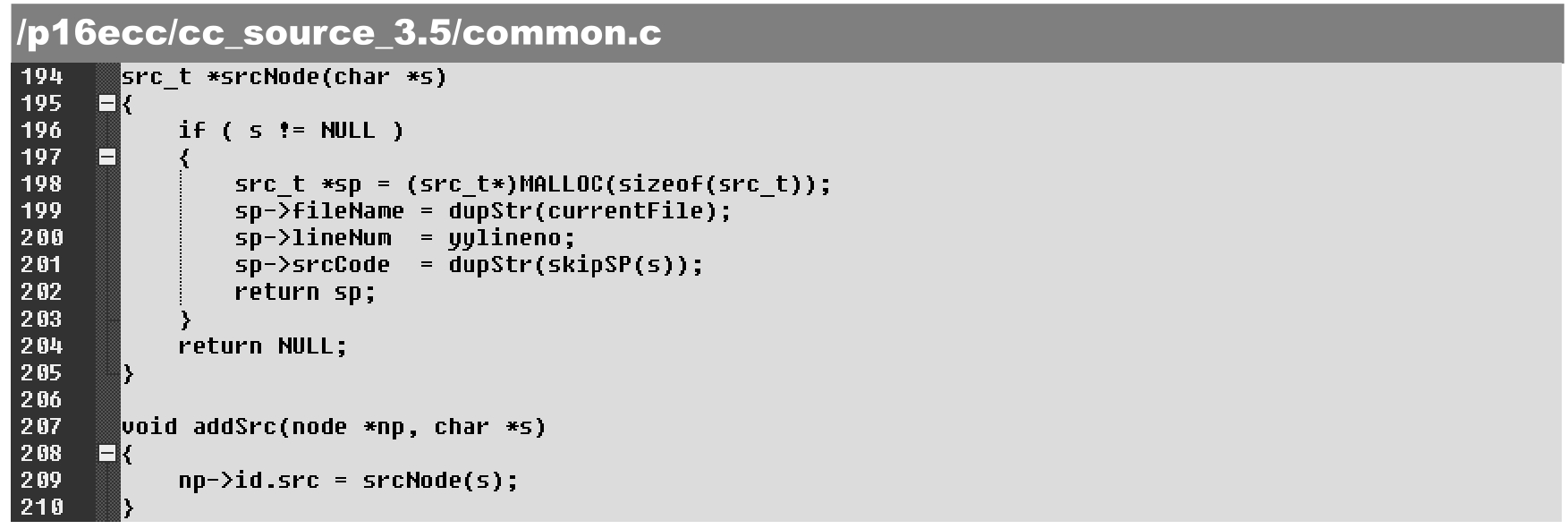
·第194~205行:通过srcNode()函数创建src_t结构,并填入当前输入文件信息,以及源代码缓冲区内容。
·第202~206行:通过addSrc()函数将创建的src_t结构链入node。
与词法解析的情景对应,在语法解析中,一旦解析匹配成功,缓冲区中的源代码片段将被读取,并嵌入语法归纳后生成的节点中,具体如下。

·第17行:宏定义,截取并嵌入某节点。
·第18行:宏定义,清空缓冲区。

·第70~72行:赋值表达式识别规则,将缓冲区内的源代码嵌入归纳后的节点(随后自动清除缓冲区)。

·第99~100行:当完成一条语句或某个函数的解析时,清空缓冲区。
在前文的基础上,增加一个对结果数据打印显示的模块——display。对编译后生成的编译树进行检验和打印显示,以此作为本章的最后一个小节。这种输出、打印不仅有助于对编译器运行的理解,还是一种调试检错的重要手段。可以预见,随着本书章节的逐步拓展、扩充,这个打印显示模块的覆盖范畴也将相应增加。
提示:这种打印显示模块是设计中的一种调试手段/工具,而在常规的编译运行中并不需要。
工程项目路径:/cc_source_3.6。
源程序文件:main.cpp、display.cpp/display.h。
输出文件:cc16e.exe。
display.h和display.cpp文件给出了用于打印输出的各种函数,其声明如下。
使用函数重载及参数默认的功能,会给编程设计提供便利。
编译树的打印输出将被安排在编译树生成之后,具体如下。

·第21行:调用显示函数display(),打印显示整棵编译树。
本节的实验如表3-4所示(其中包括源程序的截取片段)。
表3-4 语法解析实验的打印输出

续表
