
下载掌阅APP,畅读海量书库
立即打开



由于 顺序表的存储特点是用存储下标的相邻实现了逻辑上的相邻 ,它要求用下标连续的存储单元顺序存储线性表中的各元素,因此,对顺序表进行插入、删除时需要通过移动数据元素来实现,影响了运行效率。本节介绍线性表的链式存储结构,它不需要用下标连续的存储单元来实现,因为它不要求逻辑上相邻的两个数据元素在存储位置上也相邻,它是 通过“链”来表示数据元素之间的逻辑关系,因此对线性表进行插入、删除时不需要移动数据元素。

授课视频2-2 线性表的链式存储与实现
链表是通过一组任意的存储单元来存储线性表中的数据元素。那么怎样表示数据元素之间的线性关系呢?为建立起数据元素之间的线性关系,对每个数据元素a i ,除了存放数据元素自身的信息之外,还需要存放其后继元素a i+1 所在的存储单元的地址,这两部分信息组成一个“结点”。单链表结点结构如图2-6所示,每个结点都如此。 data域称为数据域,用来存放数据元素的信息;next域称为引用域,用来存放其后继元素对象的地址信息。
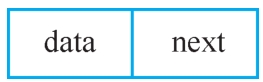
图2-6 单链表结点结构
因此,n个元素的线性表可以通过每个结点的引用域连成了一个“链”,称之为 链表 。因为每个结点中只有一个指向后继的引用,所以又称其为 单链表 。
链表是由一个个结点构成的,结点可被定义成如下的结点类。

线性表(a 1 ,a 2 ,a 3 ,a 4 ,a 5 ,a 6 ,a 7 ,a 8 )对应的链式存储结构如图2-7所示。当然,必须将第一个结点的地址160放到一个引用变量如H中,最后一个结点没有后继,其引用域必须置空,表明此表到此结束。这样就可以从第一个结点的地址开始“顺藤摸瓜”地找到每个结点。
作为线性表的一种存储结构,人们关心的是结点间的逻辑结构,而不是每个结点的实际地址,所以通常的单链表用图2-8所示的形式表示,而不用图2-7所示的形式表示。
通常,用“表头引用”来标识一个单链表。如单链表L、单链表H等,是指某链表的第一个结点的地址被记录在引用变量L、H中,当其为“NULL”时,则表示一个 空表 。
在Java语言中可以定义一个链表类LinkList,将链表中结点的存储与链表的基本运算封装在一起, 作为对抽象数据类型接口IList的实现 。
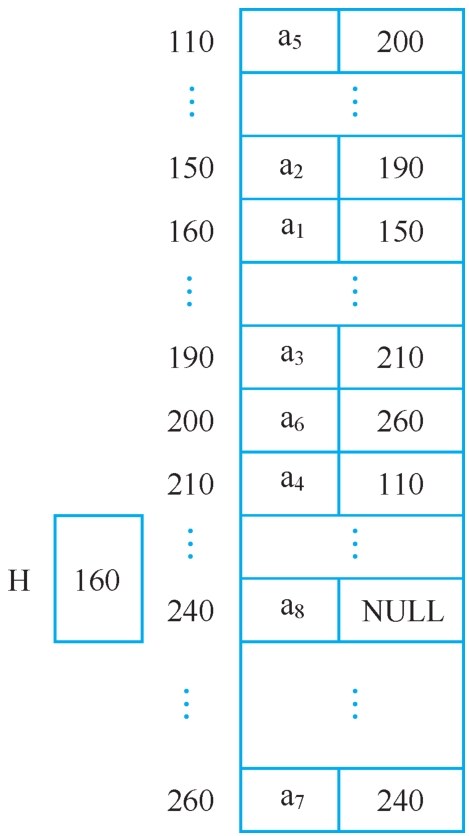
图2-7 链式存储结构

图2-8 单链表示意图

申请一个LinkNode类的实例的语句如下:
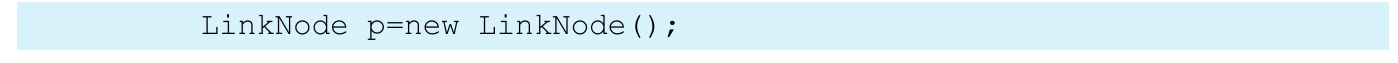

图2-9 申请一个结点
执行的结果是将一个LinkNode类的实例地址赋值给变量p,如图2-9所示。p所指的结点的数据域为p.data,引用域为p.next。
1.链表的初始化
顺序表的初始化即构造一个空表,首先动态分配存储空间,然后将表中last的值置为-1,表示表中没有数据元素。
【算法2-8】链表的初始化。

2.建立单链表
(1)在链表的头部插入结点建立单链表
链表与顺序表不同,它是一种动态的存储结构,链表中每个结点占用的存储空间不是预先分配的,而是运行时系统根据需求生成的,因此建立单链表从初始化头结点开始,每读入一个数据元素则获取一个LinkNode类的实例存放元素的值,然后将其插在链表的头结点后面。图2-10展现了线性表(25,45,18,76,29)的链表的建立过程,因为是在链表的头部插入,读入数据的顺序和线性表中的逻辑顺序是相反的。
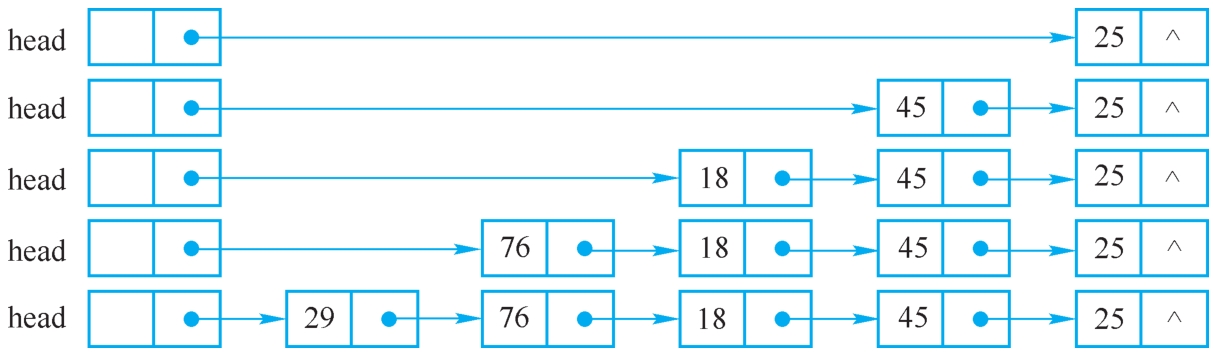
图2-10 在链表的头部插入结点建立单链表
以这种方式创建整数链表的算法如下所示。
【算法2-9】在表头插入结点,建立线性表的链式存储。

(2)在单链表的尾部插入结点建立单链表
在头部插入结点建立单链表的方法简单,但读入数据元素的顺序与生成的链表中元素的顺序是相反的,若希望次序一致,可用尾插入的方法。因为每次是将新结点插入链表的尾部,所以需加入一个引用变量r来始终指向链表的尾结点,以便能够将新结点插入链表的尾部。为简便起见,不画出引用变量H、r所占空间。图2-11展现了在链表的尾部插入结点建立单链表的过程。
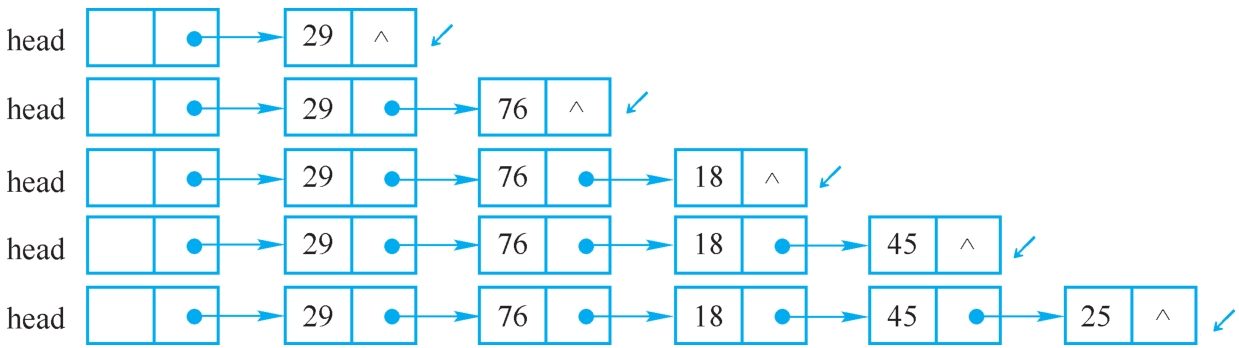
图2-11 在链表的尾部插入结点建立单链表
算法思路:初始状态时,表头引用H=NULL,表尾引用r=NULL;按线性表中元素的顺序依次读入数据元素,非结束标志时,申请结点,将新结点插入r所指结点的后面,然后r指向新结点(但第一个结点有所不同,请读者注意下面算法中的有关部分)。
以这种方式创建整数链表的算法如下所示。
【算法2-10】在表尾插入结点,建立线性表的链式存储。

通过上面两个链表初始化算法,创建的是图2-12a所示的一个作为表头的结点,最终创建的单链表如图2-12b所示,是带头结点的单链表。
还有另外一种存放单链表的方式,是头位置方式,如图2-12c所示,初始时head=NULL。在创建这种方式的单链表时,第一个结点的处理方法和其他结点是不同的。原因是第一个结点加入时链表为空,它没有直接前驱结点,它的地址就是整个链表的位置,需要放在链表的头位置变量中;而其他结点有直接前驱结点,其地址放入直接前驱结点的引用域。这种“第一个结点”的问题在很多链表操作中都会遇到,如在链表中插入结点时,将结点插在第一个位置和插在其他位置是不同的,在链表中删除结点时,删除第一个结点和其他结点的处理方法也是不同的,等等,头位置方式都需要给予单独的处理。
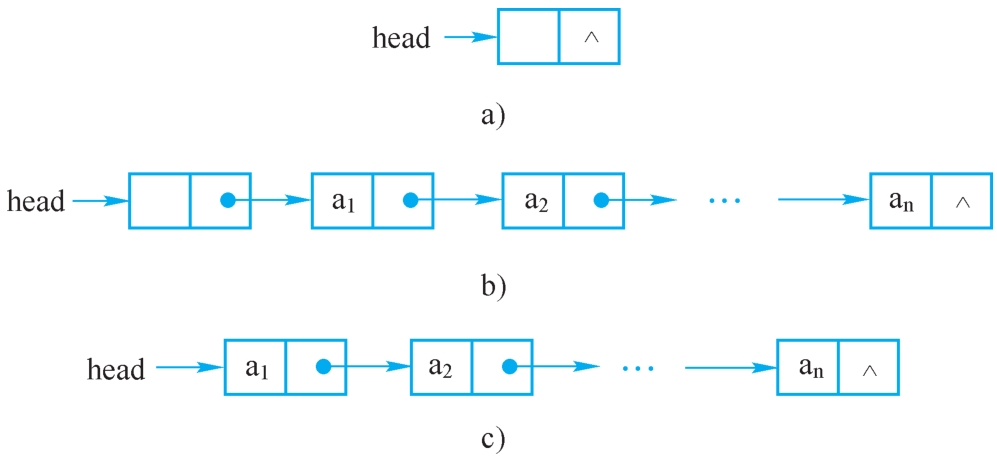
图2-12 带头结点的单链表
a)初始化链表 b)头结点方式 c)头位置方式
相比之下,采用头结点方式可方便上述操作的实现。头结点的加入使得“第一个结点”的问题不再存在,也使得“空表”和“非空表”的处理方法一致。头结点的加入完全是为了运算的方便,它的数据域无定义,引用域中存放的是第一个数据结点的地址,空表时为空。在以后的算法中如不加说明则认为单链表是带头结点的。
3.求链表的表长
算法思路:设一个指向当前结点位置的引用变量p和计数器j,初始化后,p所指结点后面若还有结点,p向后移动,计数器加1。
【算法2-11】求单链表的表长。

算法2-11的时间复杂度为 O(n) 。
4.查找操作
(1)按序号查找
算法思路:从链表的第一个结点起,判断当前结点是否是第i个。若是,则返回该结点的引用;否则,继续判断后一个,直到表结束为止。没有第i个结点时返回空。
【算法2-12a】单链表的查找运算(按序号查找)。


(2)按值查找(即定位查找)
算法思路:从链表的第一个元素结点起,判断当前结点值是否等于x。若是,返回该结点的位置;否则,继续判断后一个,直到表结束为止。找不到时返回-1。
算法如下:
【算法2-12b】单链表的查找运算(按值查找)。

需要注意的是,为符合接口定义,本算法设计成返回整序数位置,在单链表中确定元素的整序数位置和顺序表相比意义明显不大,不如按键值返回该元素的结点指针,读者可自行考虑本算法修改为返回结点指针的方法。
算法2-12a和算法2-12b的时间复杂度均为 O(n) 。
5.插入
(1)后插结点
设p指向单链表中某结点对象,s指向待插入的值为x的新结点对象,将s插入p的后面,插入过程如图2-13所示。
操作过程如下:
①s.setNext(p.getNext());
②p.setNext(s);
注意:两个操作的顺序不能颠倒。
(2)前插结点
设p指向链表中某结点对象,s指向待插入的值为x的新结点对象,将s插入p的前面,插入过程如图2-14所示。与后插结点不同的是:首先要找到p的前驱q(①),再完成在q之后插入s(②③)。算法如下:

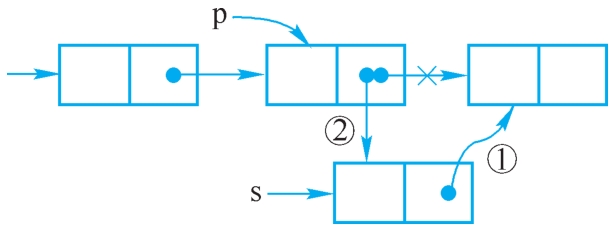
图2-13 在p之后插入s
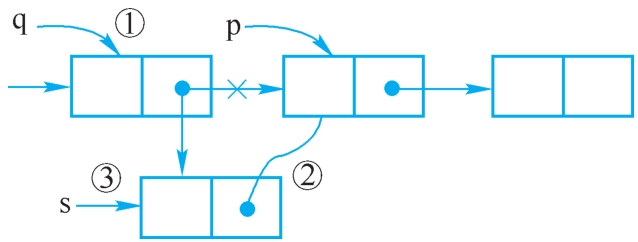
图2-14 在p之前插入s
后插结点操作的时间复杂度为O(1),前插结点操作因为要找p的前驱,所以时间复杂度为O(n)。其实人们更关心的是数据元素之间的逻辑关系,所以仍然可以将s插入p的后面,然后将p.data与s.data交换即可,这样既满足了逻辑关系,也使得时间复杂度为O(1)。
(3)插入运算
算法思路:
1)找到第i-1个结点;若存在继续2),否则结束。
2)申请、填装新结点。
3)插入新结点,结束。
【算法2-13】单链表中的插入运算。

算法2-13的时间复杂度为O(n)。
6.删除
(1)删除结点
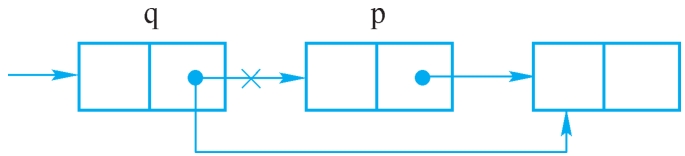
图2-15 删除p
设p指向单链表中某结点,删除结点p。操作过程如图2-15所示。
由图2-15可见,要实现对结点p的删除,首先要找到p的前驱结点q,然后通过下面的语句完成删除,将p的后继结点作为q的后继。

显然,找p前驱的时间复杂度为O(n)。
若要删除p的后继结点(若存在),可直接进行以下操作:

该操作的时间复杂度为O(1)。
(2)删除运算
算法思路:
1)找到第i-1个结点;若存在继续2),否则结束。
2)若存在第i个结点则继续3),否则结束。
3)删除第i个结点,结束。
【算法2-14】单链表的删除运算。

算法2-14的时间复杂度为O(n)。
通过上面的基本运算可知:
1)在单链表上插入、删除一个结点,必须知道其前驱结点。
2)单链表不具有按序号随机访问的特性,只能从头位置开始一个个顺序进行。
对于单链表而言,最后一个结点的引用域是空,不指向任何结点对象,如果将该链表头结点对象置入该引用域,则使得链表头尾结点相连,这就构成了单循环链表,如图2-16所示。
在单循环链表上的运算基本上与非循环链表相同,只是在判断线性表是否到达末尾时,将原来判断引用域是否为NULL变为是否是表头对象而已,没有其他较大的变化。因此,只需要将在单链表类LinkList中的链表初始化运算改为算法2-15,即可初始化一个图2-16b所示的空循环链表。

图2-16 带头结点的单循环链表
a)非空表 b)空表
【算法2-15】循环链表的初始化。

单链表只能从头结点开始遍历整个链表,而单循环链表则可以从表中任意结点开始遍历整个链表。不仅如此,对链表常做的操作是在表尾、表头进行,此时可以改变一下链表的标识方法,不用指向表头的引用而用一个指向尾结点的引用R来标识,可以提高操作效率。
例如,两个单循环链表H1、H2的连接操作,是将H2的第一个数据结点接到H1的尾结点。若用头位置标识,则需要找到第一个链表的尾结点,其时间复杂度为O(n);而若用尾位置R1、R2来标识,则时间复杂度为O(1)。算法如下:

这一过程如图2-17所示。

图2-17 两个用尾位置标识的单循环链表的连接
以上讨论的单链表的结点中只有一个指向其后继结点的引用域next,因此若已知某结点的引用为p,其后继结点的引用则为next。若找其前驱,则只能从该链表的表头开始,顺着各结点的next域进行。也就是说,找后继的时间复杂度是O(1),找前驱的时间复杂度是O(n)。如果希望找前驱的时间复杂度也为O(1),则只能付出空间的代价:每个结点再加一个指向前驱的引用域。这种结点的结构如图2-18所示。用这种结点组成的链表称为双向链表。

图2-18 双向链表结点结构
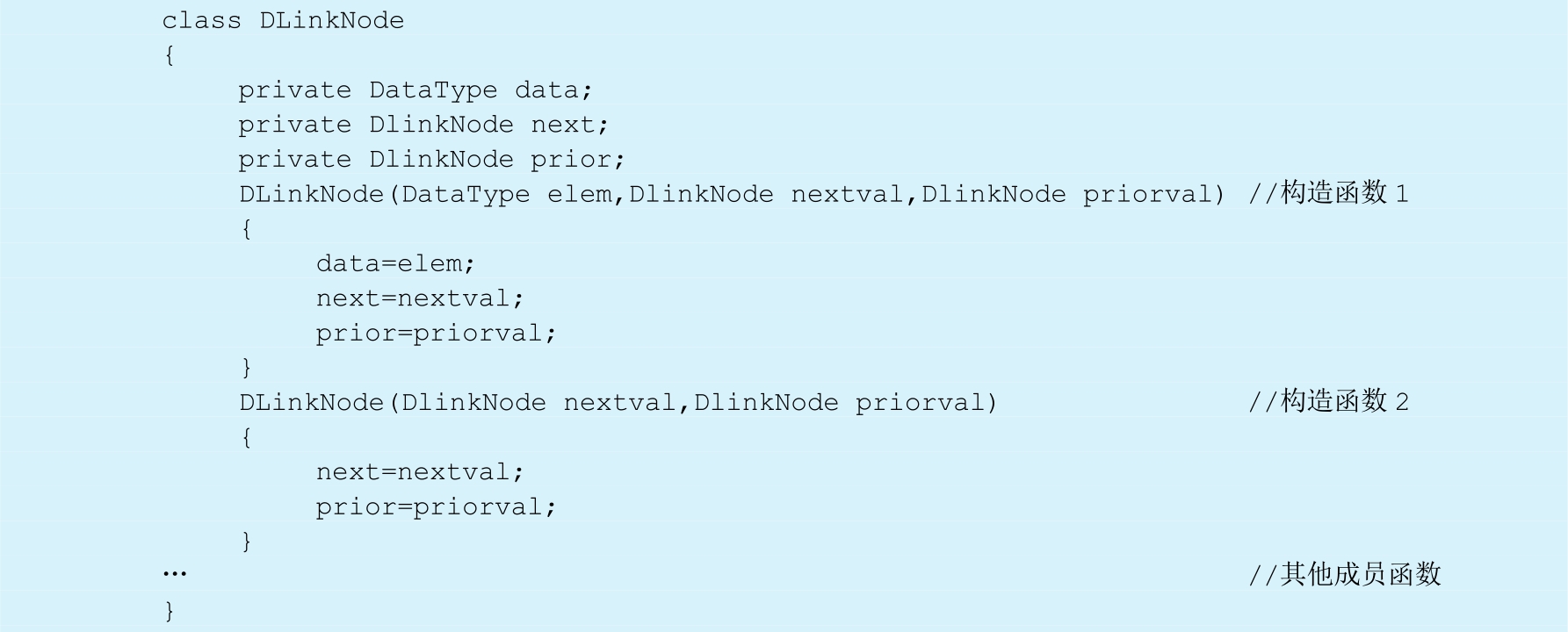
双向链表结点类的定义如下:
和单链表类似,双向链表通常也是用头位置标识,也可以带头结点做成循环结构。图2-19所示的是带头结点的双向循环链表。图2-19b所示的是空双向循环链表。双向循环链表的初始化见算法2-16。显然,通过某结点的位置p即可直接得到它的后继结点的位置next,也可以直接得到它的前驱结点的位置prior。这样,在有些运算中需要找前驱时,则无须再用循环。从下面的插入删除运算中可以看到这一点。
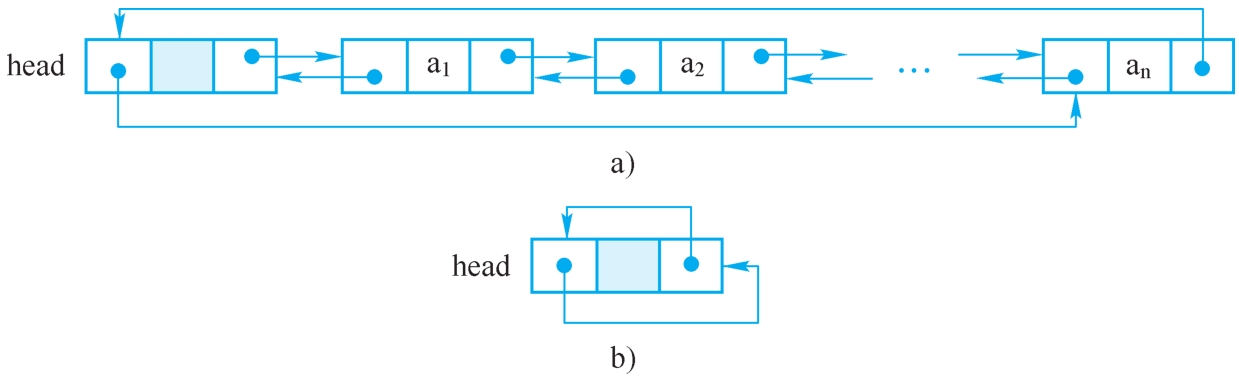
图2-19 带头结点的双循环链表
a)非空表 b)空表
【算法2-16】双向循环链表的初始化。


设p指向双向循环链表中的某一结点,即p是该结点的引用。则p的prior字段的next字段表示的是p结点的前驱结点的后继结点的位置,即与p相等;类似地,p的next字段的prior字段表示的是p结点的后继结点的前驱结点的位置,也与p相等,所以有等式。
p.getPrior().getNext()=p=p.getNext().getPrior()
(1)在双向链表中插入一个结点
设p指向双向链表中某结点,s指向待插入的值为x的新结点,将s插入p的前面,插入过程如图2-20所示。
操作如下:
①s.setPrior(p.getPrior());
②p.getPrior().setNext(s);
③s.setNext(p);
④p.setPrior(s);
上述操作的顺序不是唯一的,但也不是任意的,操作①必须要放到操作④的前面完成,否则p的前驱结点的位置就丢掉了。读者把每步操作的含义搞清楚,就不难理解了。
(2)在双向链表中删除指定结点
设p指向双向链表中某结点,删除p。操作过程如图2-21所示。
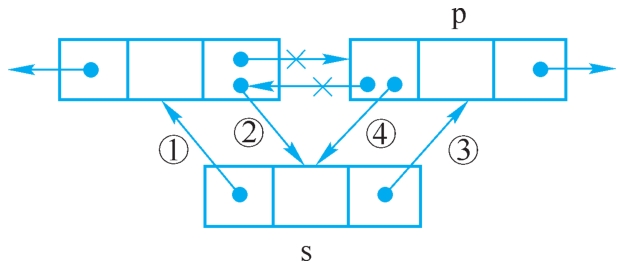
图2-20 在双向链表中插入结点
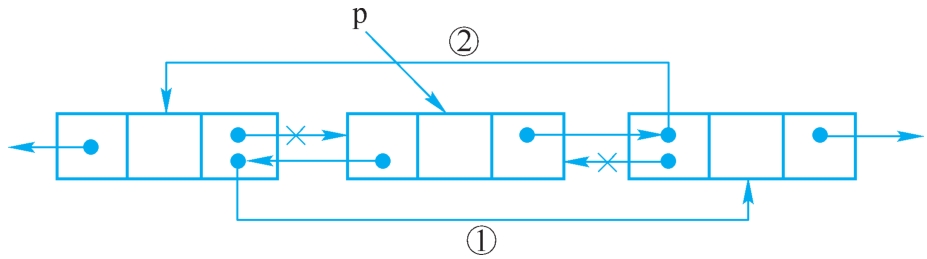
图2-21 在双向链表中删除结点
操作如下:
①p.getPrior().setNext(p.getNext());
②p.getNext().setPrior(p.getPrior());
【例2-3】已知单链表H如图2-22a所示,编写一算法将其逆置,即实现图2-22b所示的操作。
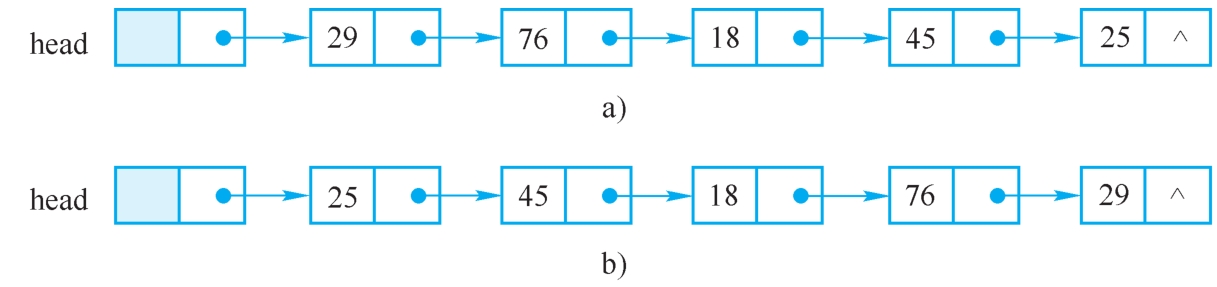
图2-22 单链表的逆置
a)原链表 b)逆置后的链表
算法思路:依次取原链表中的每个结点,将其作为第一个结点插入新链表中,引用变量p用来指向原表中当前结点。p为空时结束。
【算法2-17】单链表逆置。

该算法只是对链表顺序扫描一遍即完成了逆置,所以时间复杂度为O(n)。
【例2-4】已知单链表L如图2-23a所示,编写一算法,删除其重复结点,即实现图2-23b所示的操作。
算法思路:将引用变量p指向第一个数据结点,从它的后继结点开始到表结束,找与其值相同的结点并删除之,p指向最后结点时算法结束。
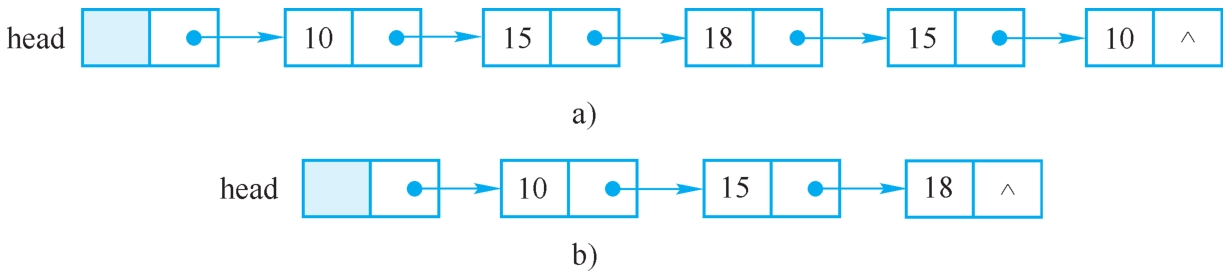
图2-23 删除重复结点
a)原链表 b)删除后的链表
【算法2-18】在单链表中删除重复结点。

该算法的时间复杂度为O(n 2 )。
【例2-5】设有两个单链表A、B,其中元素递增有序,编写算法将单链表A、B合并成一个按元素值递减(允许有相同值)有序的链表C。要求用单链表A、B中的原结点形成,不能重新申请结点。
算法思路:利用单链表A、B有序的特点,依次进行比较,将当前值较小者摘下,插入C表的头部,得到的C表则为递减有序的。
【算法2-19】单链表的合并。

该算法的时间复杂度为 O(m+n) 。
【例2-6】设计算法将采用单循环链表L存储的线性表,转换为用双向循环链表H存储。单循环链表L和双向循环链表H分别如图2-24a和图2-24b所示。
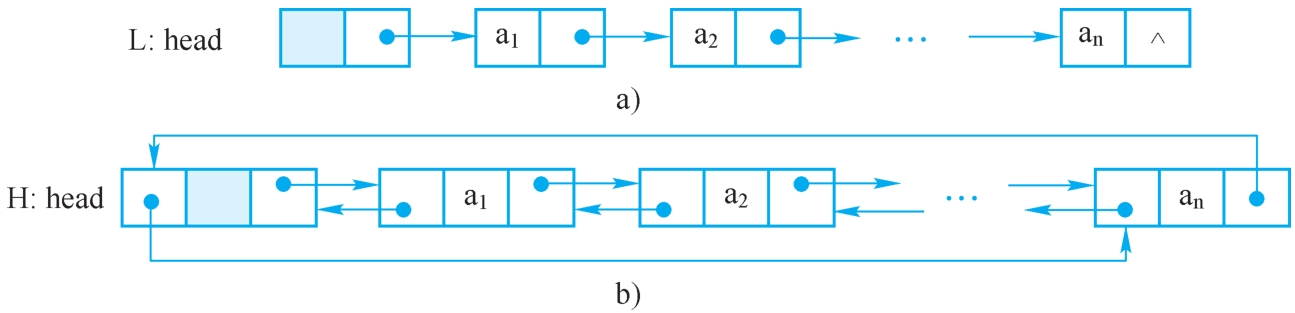
图2-24 单循环链表和双向循环链表
a)单循环链表 b)双向循环链表
算法思路:首先建立空的双向循环链表H,然后从单循环链表L的第一个结点开始,逐个读取数据元素,生成双向链表的结点s,再将s插入双向循环链表H中。
【算法2-20】将单循环链表转换为双向循环链表。


该算法的时间复杂度为O(n)。