
下载掌阅APP,畅读海量书库
立即打开




授课视频2-1 线性表的顺序存储与实现
线性表中基本运算的具体实现依赖于所采用的对数据的存储方式。本节将详细讨论线性表的顺序存储与其基本运算的实现。
线性表的顺序存储是指在内存中用地址连续的一块存储空间顺序存放线性表的各元素,采用这种存储形式的线性表称为顺序表 。因为内存中的地址空间是线性的,故而用物理上的相邻实现数据元素之间的逻辑相邻关系,既简单又自然。线性表的顺序存储如图2-1所示。
设a 1 的存储地址为Loc(a 1 ),每个数据元素占d个存储单元,则第i个数据元素的地址为
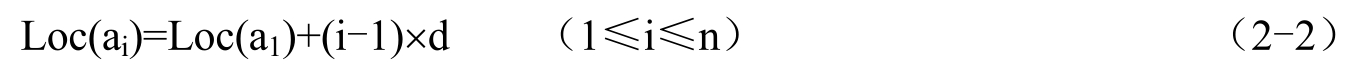

图2-1 线性表的顺序存储
这就是说,只要知道顺序表的首地址和每个数据元素所占地址单元的个数就可求出第i个数据元素的地址,即 顺序表具有按数据元素的序号存取的特点 。
在程序设计语言中,一维数组在内存中占用的存储空间就是一组连续的存储区域,因此,用一维数组来表示顺序表的数据存储区域是再合适不过的。考虑到线性表的运算有插入、删除等,即表长是可变的,因此,数组的容量需设计得足够大。设用data[MAXSIZE]来表示数组,其中MAXSIZE是一个根据实际问题定义的足够大的整数,线性表中的数据从data[0]开始依次存放,但当前线性表中的实际元素个数可能未达到MAXSIZE个,因此需用一个变量last来记录当前线性表中最后一个元素在数组中的位置,即last起一个指示作用,始终指向线性表中最后一个元素的位置,因此,表空时last=-1。这种存储思想的具体描述可以是多样的。例如,可以是

这样表示的顺序表如图2-1所示。表长为last+1,第1个到第n个数据元素分别存放在data[0]到data[last]中。这样使用简单方便,但有时不便管理,信息的隐蔽性不好。在Java语言中可以定义一个顺序表类SeqList,将数据存储区data、位置last与顺序表中的基本运算封装在一起,作为对抽象数据类型接口IList的实现。

在图2-2所示的顺序表中,L是一个 引用类型 的变量,是顺序表类SeqList的一个实例,通过“SeqListL=newSeqList();”操作来获得顺序表的存储空间,L代表着一个具体的顺序表。

图2-2 顺序表的存储表示方式
线性表的表长表示为L.last+1。
线性表中数据元素顺序存储的基址为L.data。
线性表中数据元素的存储或表示为L.data[0]~L.data[L.last]。
1.顺序表的初始化
顺序表的初始化即构造一个空表,首先动态分配存储空间,然后将last置为-1,表示表中没有数据元素。
【算法2-1】顺序表的初始化。

2.求顺序表的长度
由于在顺序表类的定义中last代表顺序表中最后一个元素的存储下标,而Java语言数组的下标是从0开始,因此顺序表中的元素个数为last+1。
【算法2-2】求顺序表的长度。

3.插入运算
线性表的插入是指在表的第i个位置上插入一个值为x的新元素,插入后使原表长n变为n+1。
插入前:(a 1 ,a 2 ,…,a i-1 ,a i ,a i+1 ,…,a n) 。
插入后:(a 1 ,a 2 ,…,a i-1 ,x,a i ,a i+1 ,…,a n ),其中1≤i≤n+1。
插入过程如图2-3所示。
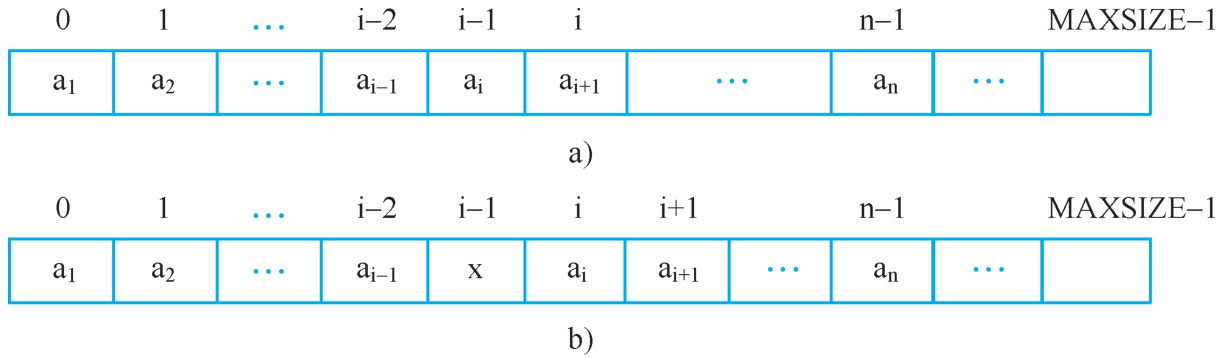
图2-3 顺序表中的插入过程
a)插入前 b)插入后
顺序表上完成这一运算需通过以下步骤进行。
1)将a i ~a n 顺序向后移动,为新元素让出位置。
2)将x置入空出的第i个位置。
3)修改last的位置(相当于修改表长),使之仍指向最后一个元素。
【算法2-3】顺序表的插入运算。

性能分析:顺序表的插入运算,时间主要消耗在数据的移动上,在第i个位置上插入x,从a i ~a n 都要向后移动一个位置,共需要移动n-i+1个元素,i的取值范围为1≤i≤n+1,即有n+1个位置可以插入。设在第i个位置上做插入的概率为p i ,则平均移动数据元素的次数为

设
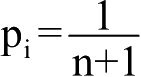 ,即为等概率的情况下,则
,即为等概率的情况下,则
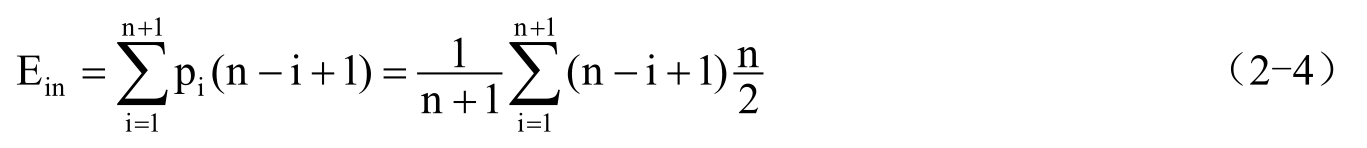
这说明顺序表的插入运算需移动表中一半的数据元素,算法的时间复杂度为O(n)。
本算法 注意以下问题 。
1)顺序表中数据区域有MAXSIZE个存储单元,所以在向顺序表中做插入时先检查表空间是否满了,在表满的情况下不能再做插入,否则产生溢出错误。
2)要检验插入位置的有效性,这里i的有效范围是1≤i≤n+1,其中n为原表长。
3)注意数据的移动方向。
4.删除运算
线性表的删除运算是指将表中第i个元素从线性表中去掉,删除后使原表长n变为n-1。
删除前:(a 1 ,a 2 ,…,a i-1 ,a i ,a i+1 ,…,a n )。
删除后:(a 1 ,a 2 ,…,a i-1 ,a i+1 ,…,a n ),其中1≤i≤n。
删除过程如图2-4所示。
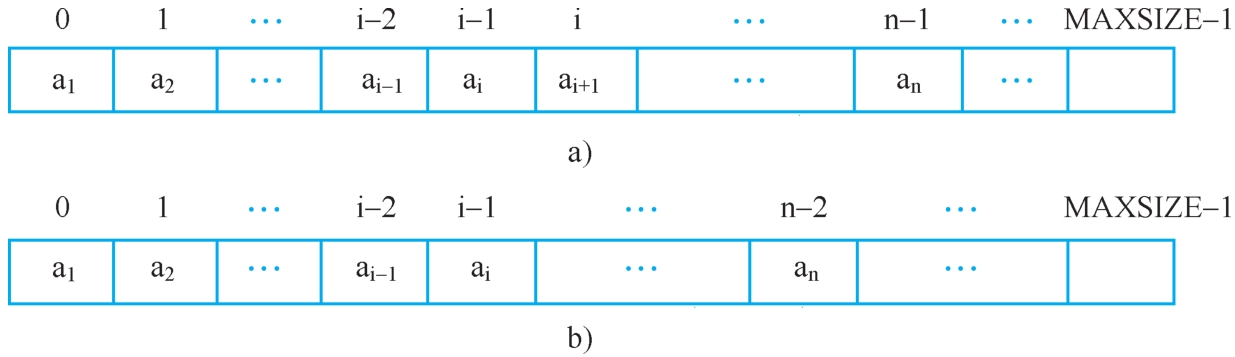
图2-4 顺序表的删除过程
a)删除前 b)删除后
顺序表的删除运算需要通过以下步骤。
1)将a i+1 ~a n 顺序向前移动。
2)修改last的位置(相当于修改表长),使之仍指向最后一个元素。
【算法2-4】顺序表的删除运算。

性能分析:与插入运算相同,删除运算的时间主要消耗在移动表中元素上,删除第i个元素时,其后的元素a i+1 ~a n 都要向前移动一个位置,共移动了n-i个元素,所以平均移动数据元素的次数为

在等概率情况下,
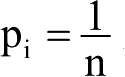 ,则
,则
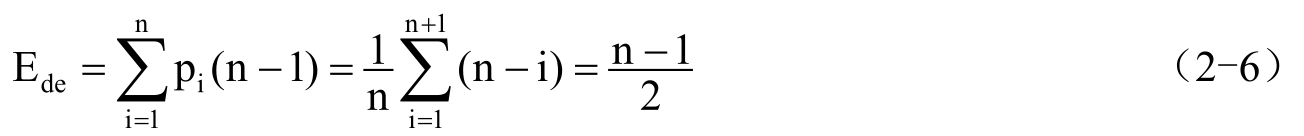
这说明在顺序表上做删除运算时大约需要移动表中一半的元素,显然该算法的时间复杂度为O(n)。
删除算法中需 注意以下问题 。
1)删除第i个元素,i的取值为1≤i≤n,否则第i个元素不存在,因此,要 检查删除位置的有效性 。
2) 当表空时不能做删除运算 ,因表空时last的值为-1,条件(i<<1||i>last+1)也包括了对表空的检查。
3)删除a i 之后,该数据就不存在了, 如果需要此数据,先取出a i ,再做删除运算。
5.按值查找
线性表中的按值查找是指在线性表中查找与给定值x相等的数据元素。在顺序表中完成该运算最简单的方法是:从第一个元素a 1 起依次和x做比较,直到找到一个与x相等的数据元素,返回它在顺序表中的存储下标或序号(二者差1,即序号=下标+1);若查遍整个表都没有找到与x相等的元素,则返回-1。
【算法2-5】顺序表的查找运算。

查找算法主要是给定值x与表中元素做比较。显然比较的次数与x在表中的位置有关,也与表长有关。当a 1 =x时,比较一次即成功;当a n =x时,比较n次才成功。等概率情况下,查找成功的平均比较次数为

在查找失败的情况下,需要比较n次。显然,按值查找算法的时间性复杂度为O(n)。
【例2-1】将顺序表(a 1 ,a 2 ,…,a n )重新排列为以a 1 为界的两部分:a 1 前面的值均比a 1 小,a 1 后面的值都比a 1 大(这里假设数据元素的类型具有可比性,不妨设为整型)。操作前后如图2-5所示。这一操作称为划分,a 1 称为基准。
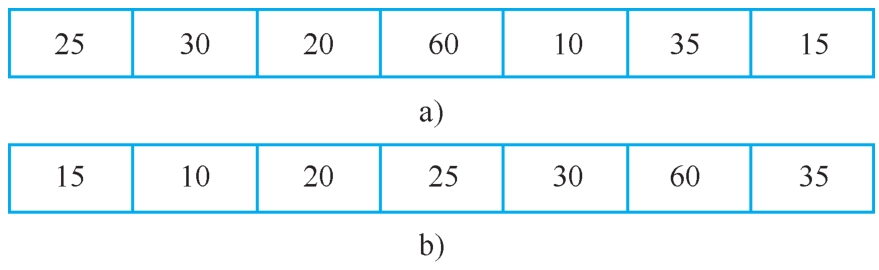
图2-5 顺序表的划分
a)划分前 b)划分后
划分的方法有多种,下面介绍的划分算法思路简单,但性能较差。
基本思路:从第二个元素开始到最后一个元素逐一向后扫描。
1)当前数据元素a i 比a 1 大时,表明它已经在a 1 的后面,不必改变它与a 1 之间的位置,继续比较下一个。
2)若前数据元素比a 1 小,说明它应该在a 1 的前面,此时将它上面的元素都依次向后移动一个位置,然后将它置入最前方。
【算法2-6】划分算法。

本算法中有两重循环,外循环执行n-1次,内循环中移动元素的次数与当前数据的大小有关,当第i个元素小于a 1 时,要移动它前面的i-1个元素,再加上当前结点的保存及置入,所以移动i-1+2次。在最坏情况下,a 1 后面的结点都小于a 1 ,故总的移动次数为
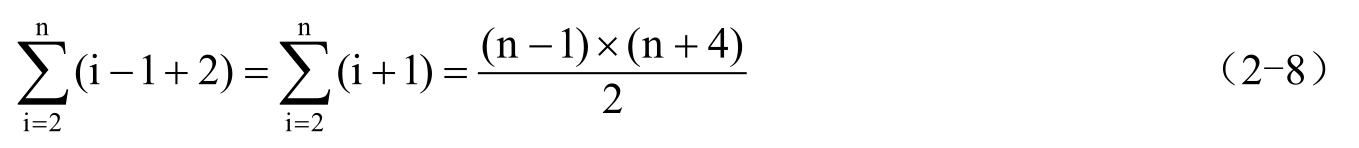
也就是说,最坏情况下移动数据的时间复杂度为O(n 2 )。
这个算法简单但效率低,在第7章的快速排序中将介绍另一种划分算法,它的时间复杂度为O(n 2 )。
【例2-2】有顺序表A和B,其元素均按从小到大的升序排列,编写一个算法将它们合并成一个新的顺序表C,要求C的元素也是从小到大升序排列。
算法思路:依次扫描顺序表A和B的元素,比较当前元素的值,将较小值的元素赋给C,如此直到一个线性表扫描完毕,然后将未扫描完的那个顺序表中的余下部分赋给C即可。C的大小要能够容纳A、B两个线性表相加的长度。
【算法2-7】顺序表的合并。

该算法的时间复杂度是O(m+n),其中m是A的表长,n是B的表长。