
下载掌阅APP,畅读海量书库
立即打开



在构建标准工况试验过程中产生的循环工况数据库与实际道路试验过程的数据库,为新车型的开发设计提供丰富而又更接近实际的工况数据,使仿真的条件与实际情况更符合。尤其是电池开发工程师对工况的使用较为频繁,经常需要调用各类工况对动力蓄电池的耐久性能与放电容量性能进行匹配分析。
基于工况数据库的随机工况构建法适用于在车辆测试验证阶段的精度分析,同时适用于获取不同用户的随机仿真工况,从而进行定制化动力总成匹配设计。汪春洪在《随机日工况的构建及仿真分析》中使用了随机方法,但其随机数据获取并未采用数据库方式,选择的工况片段较为简单。
本节提出了一种基于大数据的工况数据库构建方法,选择临时随机抽样法替代标准的工况片段法。首先,在数据收集阶段,对于标准工况,采用底盘测功机实测数据作为数据源;对于实际道路工况,采用用户实际道路行驶数据作为数据源。然后,根据车速起停周期编号存档,建立工况数据库。接着,在仿真设计阶段,采用从数据库中随机抽样的方法生成工况,并持续计算行驶里程与主要统计特征。最后,分析了随机工况构建法与标准工况构建法的优缺点。随机工况构建法可以对仿真与试验结果的可信度与离散性进行分析,仿真结果可以更合理地与实测结果相匹配。
1.标准工况底盘测功机实测数据分析
CLTC提供的标准工况在实际台架测试中,因驾驶员控制稳定性,会引入一定的误差量。胡杰在《个性化驾驶员模型及其在驾驶行为评估中的应用》中采用将驾驶员模型引入随机干扰的方式模拟驾驶误差。本节采用基于实际测试历史数据的随机获取工况循环的方式消除驾驶员误差,该方法将与实测结果更接近,且适用于实际道路工况数据库的类比构建。
(1)试验工况数据获取
在底盘测功机上将实测CLTC中国工况的数据进行提取,由于驾驶员的误差,部分误差较大的循环不能加入数据库中。例如,最后一个循环跟不上线,是不完整的工况循环,需要将其辨识并剔除,如图2-17所示。
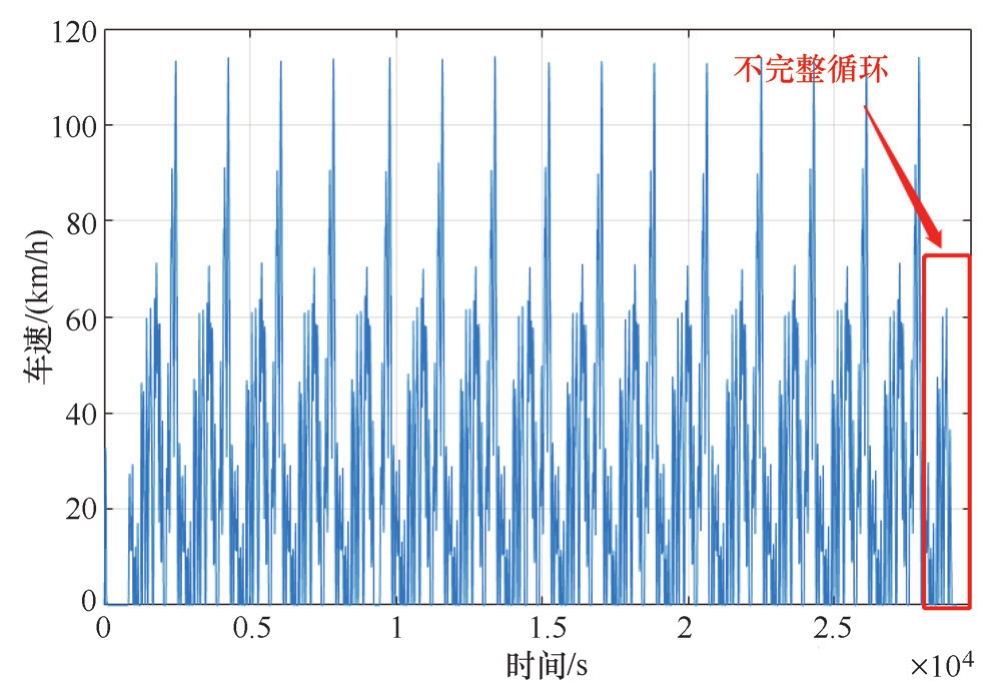
图2-17 底盘测功机实测CLTC中国工况循环
基于12次CLTC中国工况试验结果进行汇总示例,每次试验中国工况循环数约为4个到30个循环不等,总共109个循环样本。在实际操作中,样本量越大越好。
(2)标准工况数据库构建
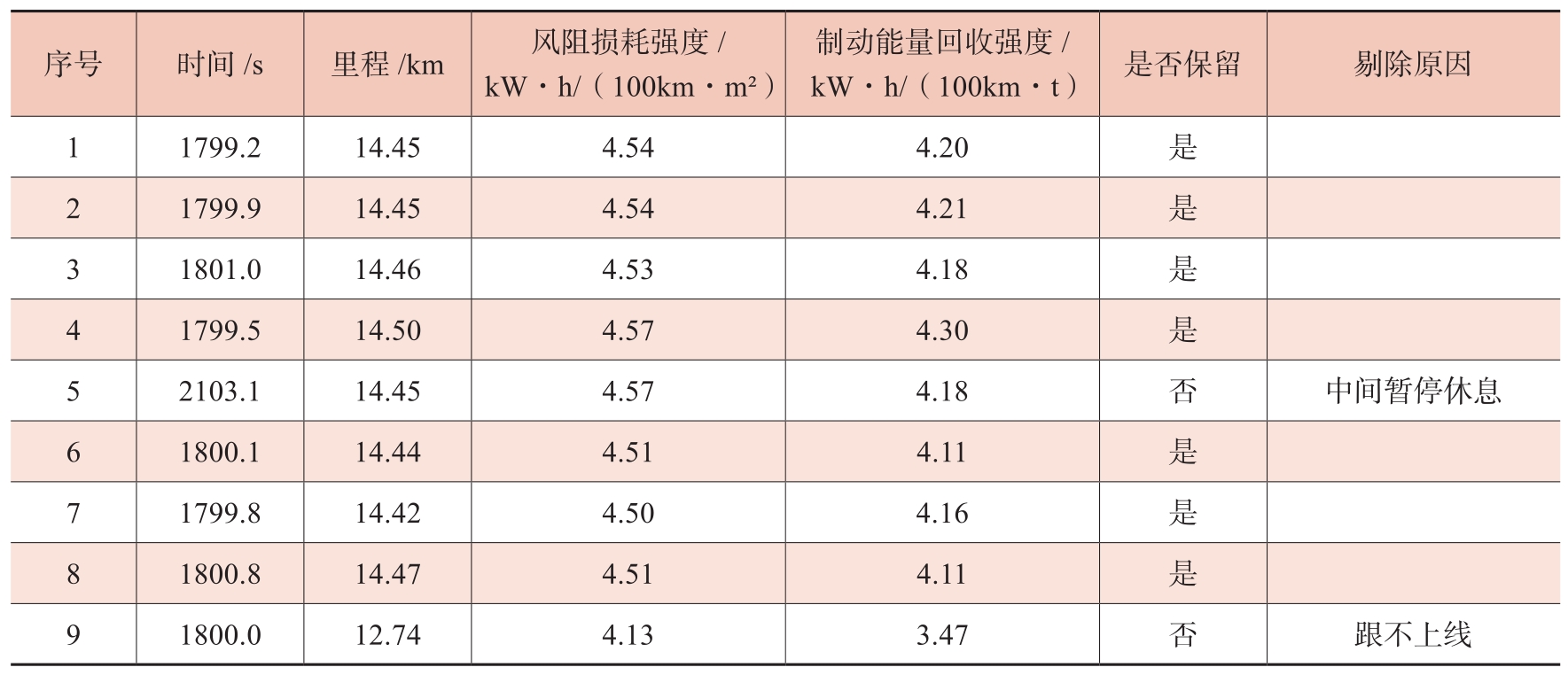
由于驾驶员误差,不能将所有循环皆收录数据库中,在109个循环样本中,需要进一步提取较为规范的循环。对循环筛选的重要指标是时间、里程、风阻损耗强度、制动能量回收强度等参数,见表2-13。
表2-13 CLTC中国工况循环收录数据库示例
将符合要求的循环收录数据库中,将各循环绘图对比,如图2-18所示。
(3)工况能耗相关特性分析
工况的风阻损耗强度、制动能量回收强度两个特征参数与能耗直接相关,因驾驶员偏差导致的测试误差亦可在这两个参数中体现。将循环符合要求的风阻损耗强度与制动能量回收强度分布进行分析,如图2-19和图2-20所示。
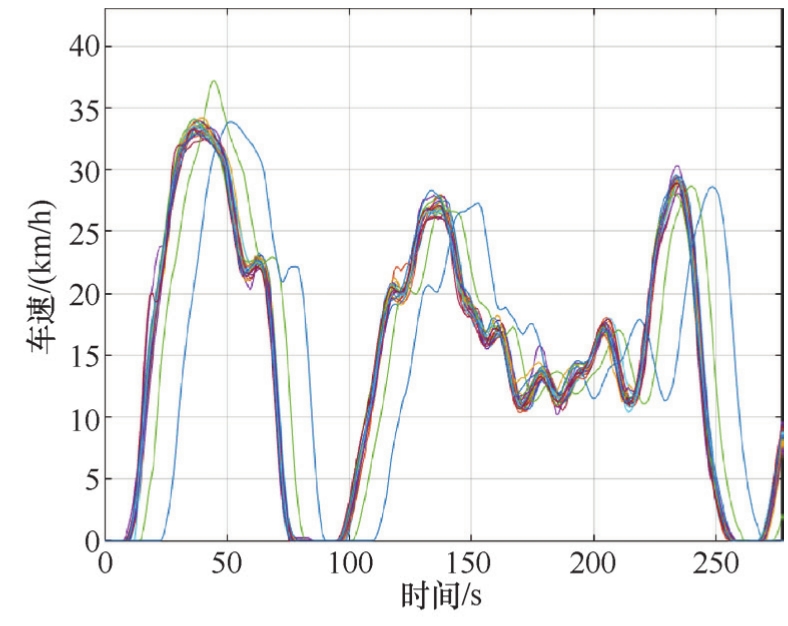
图2-18 符合要求的CLTC中国工况循环
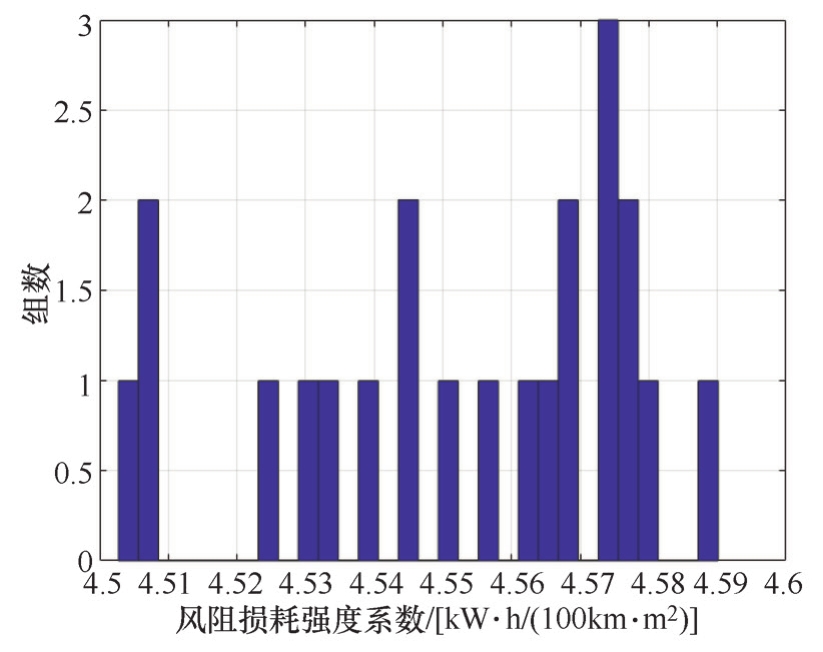
图2-19 实测的CLTC中国工况风阻损耗强度分布
CLTC中国工况风阻强度的设计值是4.62kW·h/(100km·m 2 ),制动能量回收强度的设计值是4.70kW·h/(100km·t),而实测的风阻强度均值是4.56kW·h/(100km·m 2 ),实测的制动能量回收强度均值是4.19kW·h/(100km·t)。由图2-19和图2-20可知,实测值分布离散度在±0.05kW·h/(100km·m 2 )和±0.1kW·h/(100km·t)以内,为保证试验精度,应当测试2个循环以上。
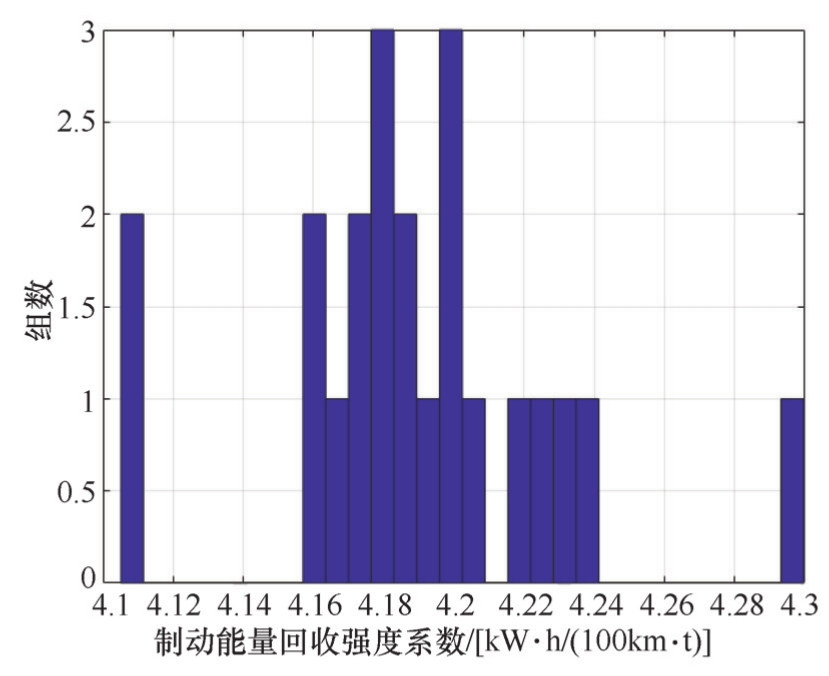
图2-20 实测的CLTC中国工况制动能量回收强度分布
2.实际道路工况数据分析
用相同的方法可以获得实际道路测试的工况数据,但是与底盘测功机标准工况数据库构建不同的是,实际道路工况以一个起停周期作为数据存储片段,其筛选规则不再是根据特定的时间区间或里程区间,原则上任何起停循环均有效。
(1)实际道路工况数据获取
车辆的行驶车速可通过Tbox上传至云平台,可以直接通过云平台获得用户实际道路的工况数据。工况数据可针对不同地区不同路况进行定义,以试验车辆在黑河做冬季试验的样本为例,图2-21所示为某试验车一天的行驶工况数据。
图2-21 某试验车一天的行驶工况数据
(2)实际道路工况数据库构建
将车辆的起停周期作为一个循环片段,如图2-22所示,总共获得465个起停周期。实际最短的为0.4s、实际最长的为3138s、里程最短的为0.27m、里程最长的为72.8km。
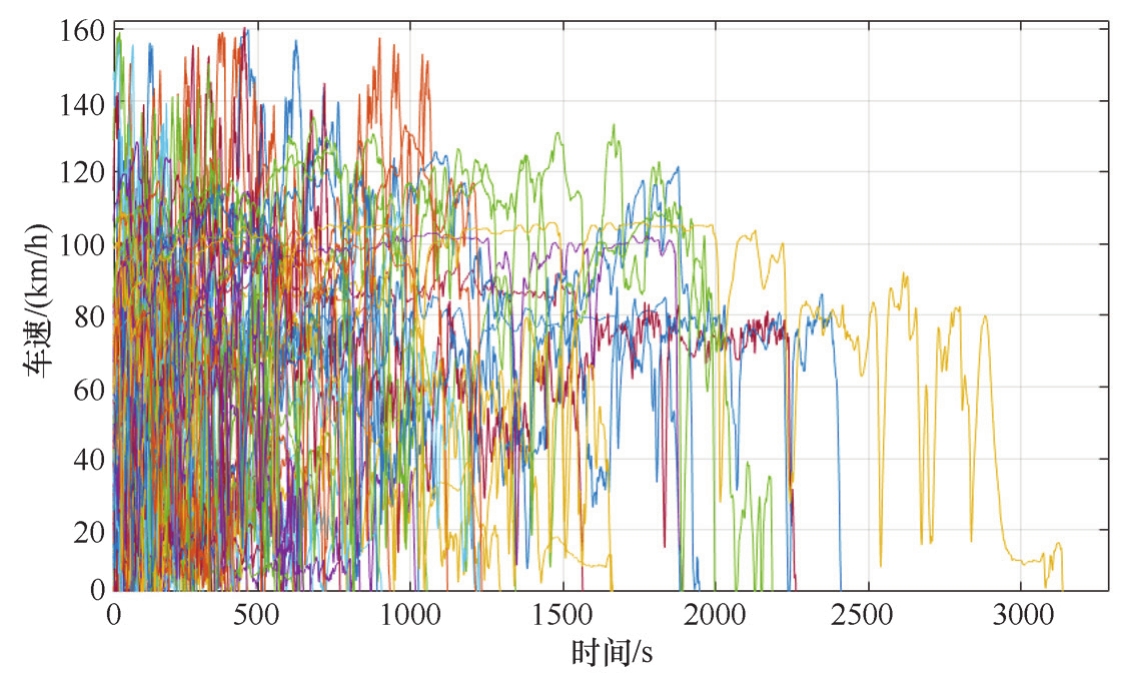
图2-22 实际道路行驶工况片段
行驶时间和距离较短的工况可能是由于路况较拥堵时起停引起的。将行驶时间少于2s、行驶距离小于1m的数据剔除,则可列入起停数据库中。将怠速数据做分布分析可知,停车最长时间为14000s,停车时间少于1s的数据样本有114次。怠速时间过长很可能是中间休息或做静态测试项目的数据,为了保证台架仿真有效性,提取怠速时长为1~300s的数据记录入数据库中,其分布如图2-23所示。
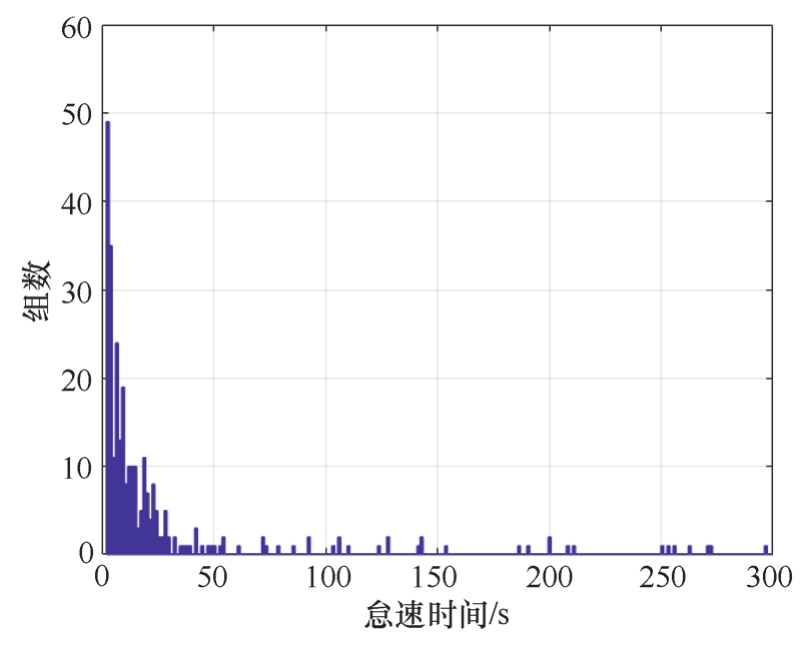
图2-23 怠速时间分布
(3)实际道路工况数据能耗相关特性分析
与标准工况循环相比,实际道路测试获得的工况片段能耗相关特性参数分布离散性更大,如图2-24和图2-25所示。
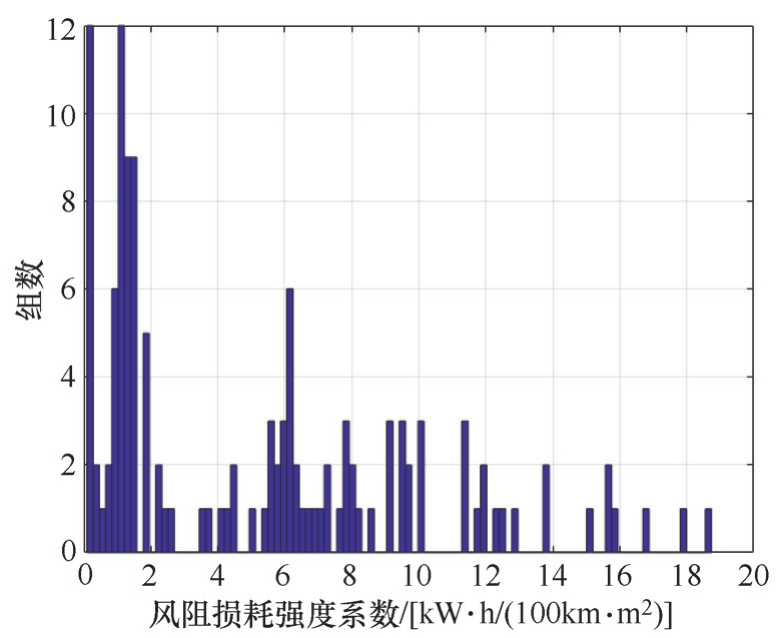
图2-24 实际道路工况风阻损耗强度分布
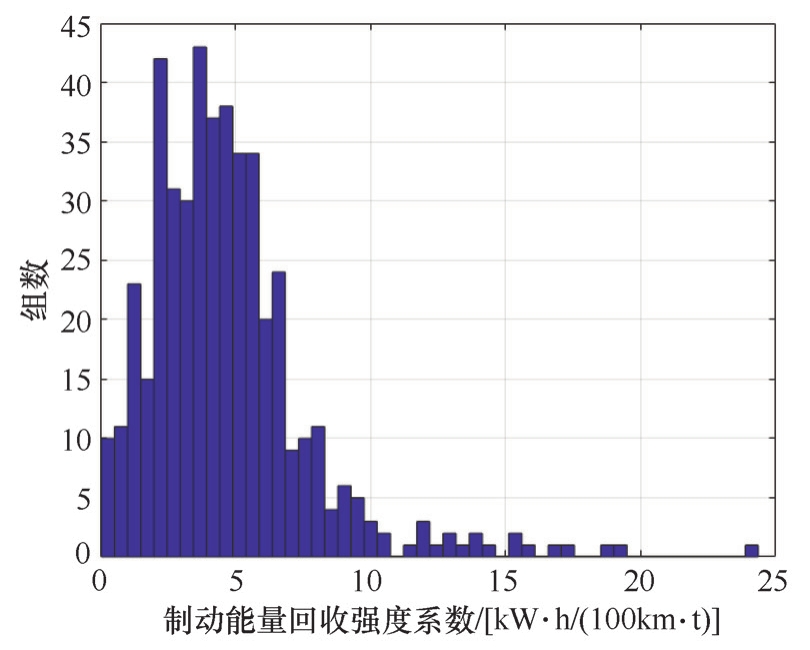
图2-25 实际道路工况制动能量回收强度分布
所有样本的风阻损耗强度均值的计算公式为

式中
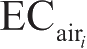 ——第
i
个样本的风阻损耗强度[kW·h/(100km·m
2
)];
——第
i
个样本的风阻损耗强度[kW·h/(100km·m
2
)];
s i ——第 i 个样本的行驶里程(km);
EC air ——平均风阻损耗强度[kW·h/(100km·m 2 )]。
计算平均制动能量回收强度的方法相同,公式不再陈述。
计算所得,风阻损耗强度均值为9.12kW·h/(100km·m 2 ),制动能量回收强度均值为4.72kW·h/(100km·t)。
3.随机工况生成与统计特征分析
工况数据库构建的最终目的是获得可用于仿真或试验分析的工况,标准工况与实际道路工况的构建方法略有差别。
(1)标准工况循环的生成
在底盘测功机上测试获得的工况数据库中,以单位循环为样本,随机抽取若干循环组成仿真工况,则可以将驾驶员的误差考虑在仿真模型中,令仿真结果与实测结果更接近。例如,随机生成5个实际测试标准工况循环,其工况图如图2-26所示。将各次试验工况插值到电机效率MAP中,获得电机效率差异如图2-27所示。
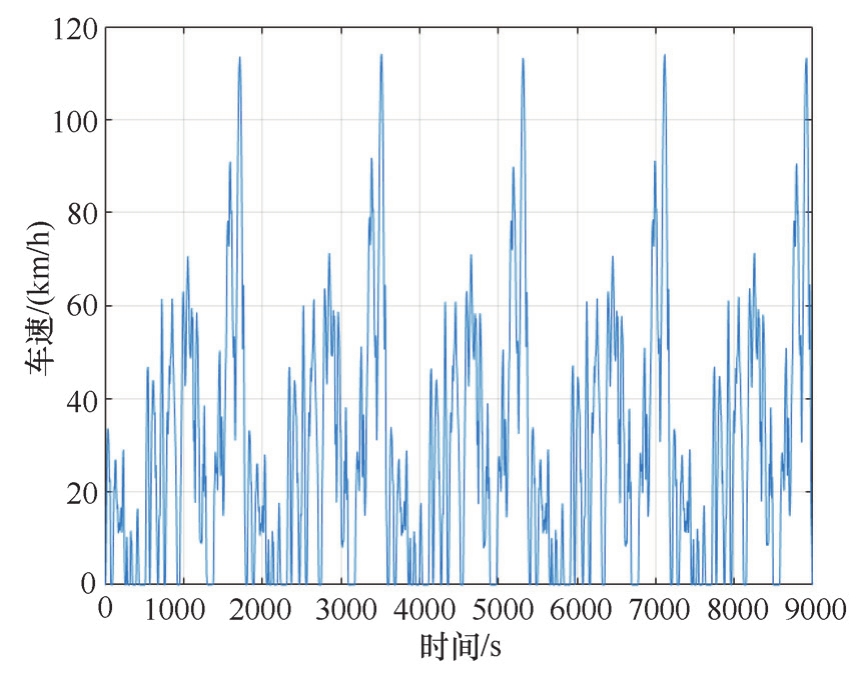
图2-26 随机抽取5个CLTC中国工况循环
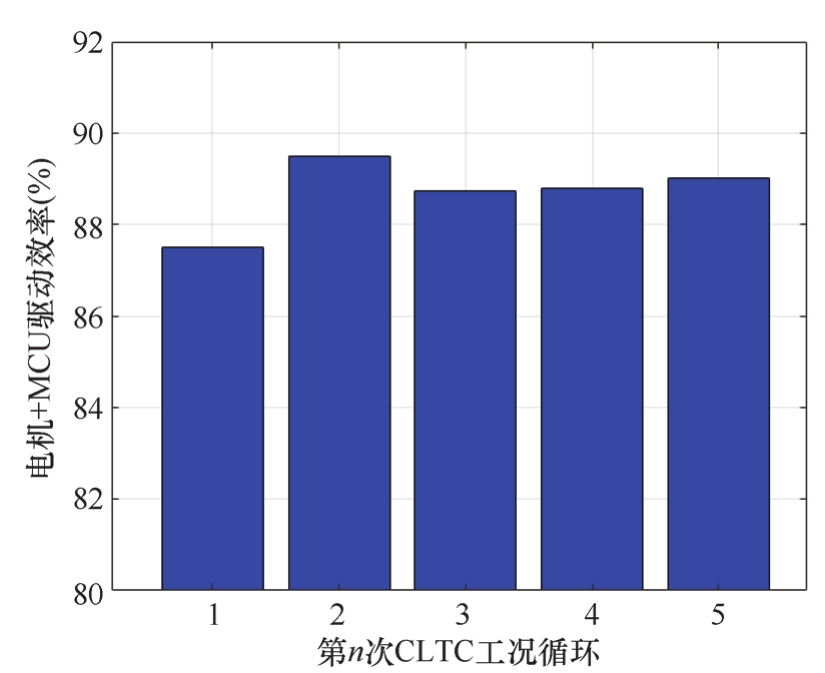
图2-27 插值获得各循环电机效率
(2)实际道路工况的生成
实际道路工况的生成亦采用随机方式,但需要考虑各循环的风阻损耗强度与制动回收强度的统计值,且生成的结果不是按照循环数,而是按照里程来判断生成的工况长度。例如,随机生成300km的工况曲线,并对其能耗相关统计特性进行分析,如图2-28和图2-29所示。
由图2-29可知,该自动生成工况的风阻损耗强度系数为8.63kW·h/(100km·m 2 ),制动能量回收强度为4.40kW·h/(100km·t),与全数据库的能耗相关特征均值接近。这两条曲线都随里程的增加趋于稳定,即里程越长生成的工况越稳定。
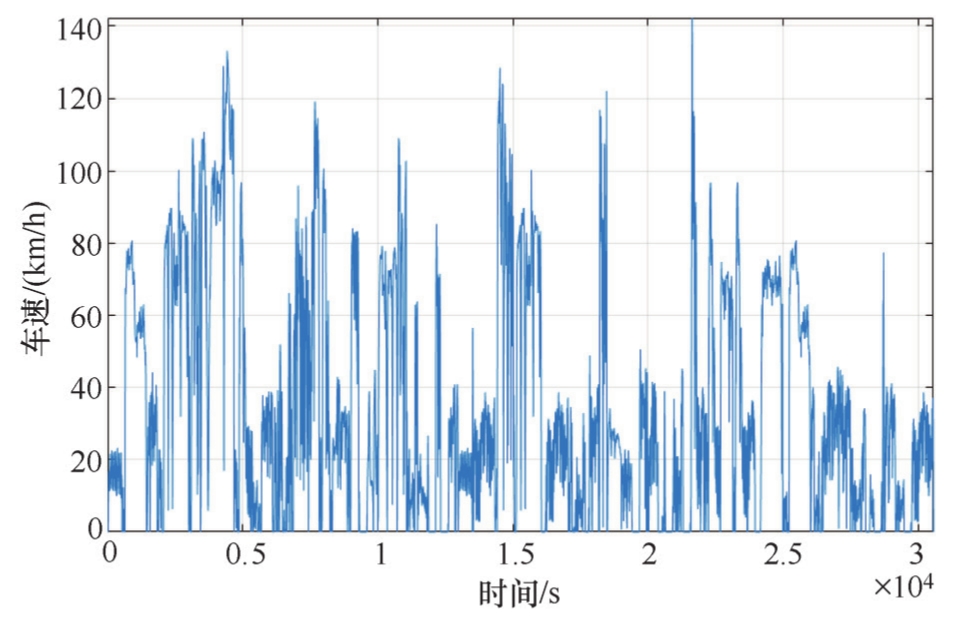
图2-28 随机生成实际道路工况
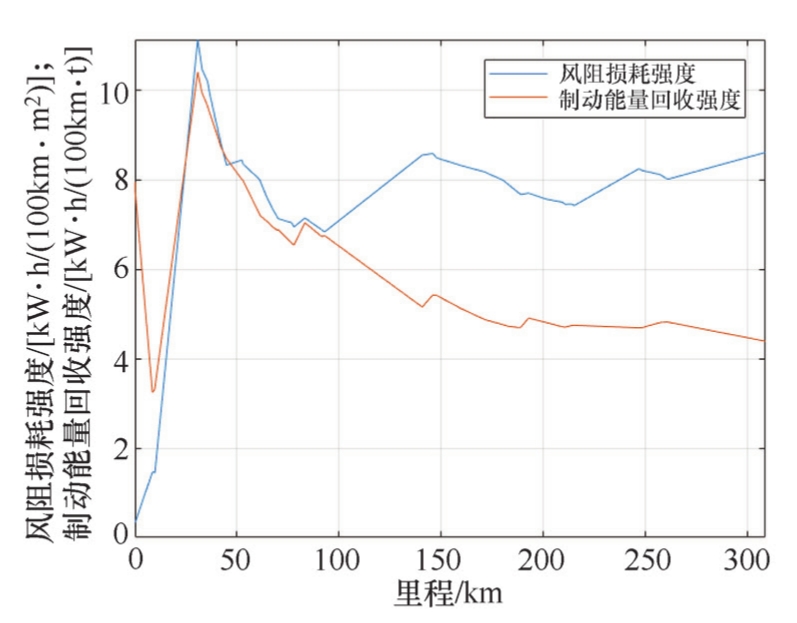
图2-29 随机生成工况的风阻损耗强度与制动能量回收强度
4.随机工况在仿真与试验分析中的应用
以NEDC工况为例,将标准工况导入到仿真模型中,得出的整车能耗仿真结果与实测结果之间会约有±4%的偏差。从大样本中选择一个与均值较为接近的样本可以消除驾驶员偏差,但不能反映驾驶员导致的测试循环误差。因此,从已执行的实测工况循环中,随机抽样方式可令试验结果跟仿真结果更吻合,且可以反映仿真和实测结果的稳定性以及接受误差区间。
在实际道路能量消耗量与续驶里程测试中,受到天气及路况影响,试验的可重复性较差,多次测量获得的结果较为离散。采用仿真路况对实际道路测试结果进行分析,可以反映实际道路测试结果受随机路况影响的程度,为修正评价与接受测试结果提供判定依据。
实际道路测试与用户使用结果更为吻合,可为定制化设计与用户相匹配的动力总成方案、减速器速比、回收策略、剩余里程估计策略提供设计依据。工况相关自学习程序可在仿真阶段得到验证,例如自学习剩余里程估算、自学习制动能量回收策略等。
5.随机工况与标准工况优缺点分析
标准工况是根据某一地域大量行驶数据,采用特定的统计提取方法获得的工况片段,不同企业可以依据国家规定的工况做续驶里程和能量消耗量估算。随着大数据技术的发展,各企业也可以采用相似的统计方法获得企业的工况,以进行适应特定用户使用场景的动力系统匹配开发。而随机工况主要应用于测试评价领域,其稳定性相对较差,但更接近实际用户的实测结果。
各工况稳定性、台架测试结果符合性、用户实测结果符合性的比较见表2-14。各工况适用的阶段分析见表2-15。在车辆前期开发阶段选择标准工况较为合适;在测试与验证阶段则应切换为随机工况。
表2-14 各工况评价指标对比

表2-15 各工况适用开发阶段

综上分析,汽车定制化设计将是未来发展方向,工况数据库的收集与应用将起到关键作用。随机工况主要应用于开发中后期与产品迭代优化,可较好地反映用户的实际使用情况。在动力总成匹配、减速器速比匹配、制动能量回收策略优化、剩余里程估算等领域有重要的应用价值。