
下载掌阅APP,畅读海量书库
立即打开



在我没回去过的老家米缸,爷爷用楷书写一个满。
——歌曲《上海一九四三》
本节我们介绍文字在计算机内的二进制表示方式。
大约在公元前1200年,腓尼基人根据埃及的象形文字创立了22个腓尼基字母,这应该就是英文字母的源头了。
约公元前1000年,希腊人根据腓尼基字母创立了希腊字母表,大小写字母各24个。字母的英文单词Alphabet的词源即希腊语的alpha( α )和beta( β )。
公元前800—前500年,罗马创立了拉丁字母。这是世界上使用最为广泛的字母体系
 。
。
公元500年左右,由罗马传教士对拉丁字母进行了改造,形成英文字母表,并逐步演化发展,一直沿用到今天。
ASCII编码
我们知道,二进制可用于表示不同数值,如果事先约定每一种数值对应的文字符号,就可以用来表示文本。
1874年,法国电报服务公司的职员埃米尔·波多(Emile Baudot)创造了一种5位编码方式,又称Baudot编码。Baudot编码整个系统由32个字符组成,编码00被保留下来,字母占26个字符,剩余的5个字符是:回车、空格、换行、数字转义、字符转义,用来调整格式。
然而,5位编码明显不够,数字和符号需要依赖转义,大小写字母也无法区分。这是当时经济上的一种权衡技术。
实际上,英文大小写加上10个数字,已经达到62个字符;如果考虑标点符号,字符数量会超过64个。因此,理想的编码至少应为7位。
1967年,美国信息交换标准码(American Stardard Code for Information Interchange,ASCII)正式发布,采用7位编码,取值范围是0~127,即00h~7Fh。
可以在线查看完整的ASCII编码表。对于像Hello,World!这样的一段文本,它的ASCII码为:
48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21
字符和字节是一一对应的。00通常保留为空字符,代表一个字符串的结束。0x20代表空格。大小写字母之间的差值也为0x20。
128个码位包括大写字母26个、小写字母26个、数字10个、控制符33个、符号33个。
区位码
ASCII码只有128个码位,而常用的汉字有6000多个,这显然是不够的。
为了解决这个问题,在20世纪80年代,国际标准化组织(ISO)及国际电工委员会(IEC)联合制定了ISO/IEC 8859,简称ISO 8859。DOS时代的汉字系统和汉字输入法就建立在ISO 8859之上。
同时,为了解决汉字的计算机编码问题,我国也制定了对应的国家标准,即国标第2312号,简称GB 2312。由于该标准于1980年发布,也叫作GB 2312—1980,这个标准能编码6763个简体汉字。
GB 2312的基础,是汉字的区位码,分为94个区,每个区都保留96个码位,头尾2个码位被保留为空,剩余94个码位用于表示汉字字符。这样共有94×94=8836个可用码位,但GB 2312实际使用了其中的7445个,还有一些空区/空码。
例如,“啊”字的区位码是1601,表示第16区的第1个字符。“诚”字的区位码是1947,表示第19区的第47个字符。
区位码使用十进制表示,而GB 2312则使用十六进制表示,范围是0xA1A1~10xFEFE。这里从0xA1到0xFE正好是94个区/码,如图1-10所示。选择从0xA1(161)开始是为了与ASCII码(0~127)兼容,同时保持一定的后续扩展能力。

图1-10 GB 2312中的汉字
图1-11中的算法实现了区位码和GB 2312的相互转换。
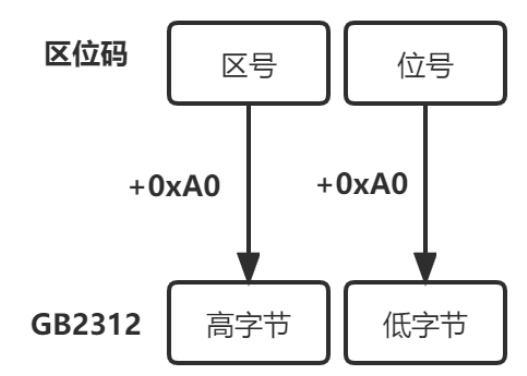
图1-11 区位码和GB 2312的相互转换
要将区位码转换成GB 2312,只需要将高、低字节分别加上0xA0,反之减去0xA0即可。

GB 2312
GB 2312编码了7445个字符、94个区,汉字在16~55区和56~87区,如图1-12所示。
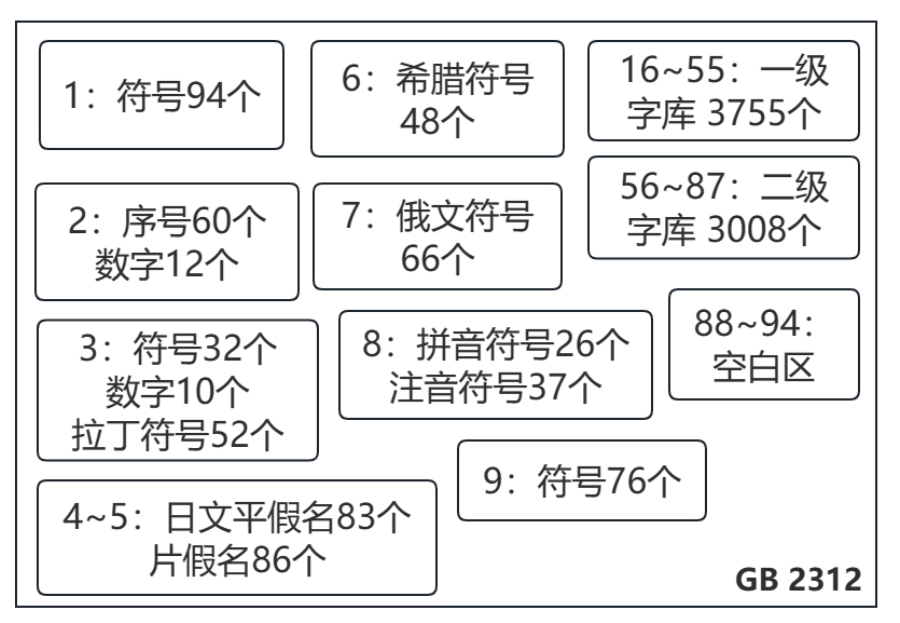
图1-12 GB 2312符号表
汉字共有6763个,其中包含一级字库3755个和二级字库3008个。非汉字符号有682个,包括符号202个、序号60个、数字22个、拉丁符号52个、日文符号169个、希腊符号48个、俄文符号66个、拼音符号26个、注音符号37个。
这个标准于1981年5月实施,是DOS时代使用的汉字编码标准。
GBK编码
随着计算机的普及,人们对各种字符的需求不断增加。因此,1995年12月,GB的扩展标准GBK得以推出。
GBK可以表示21 886个字符,分为5部分。GBK1、GBK2与GB 2312兼容,并新增717个字符。GBK3新增6080个汉字,GBK4新增8160个汉字,GBK5新增166个符号,如图1-13所示。
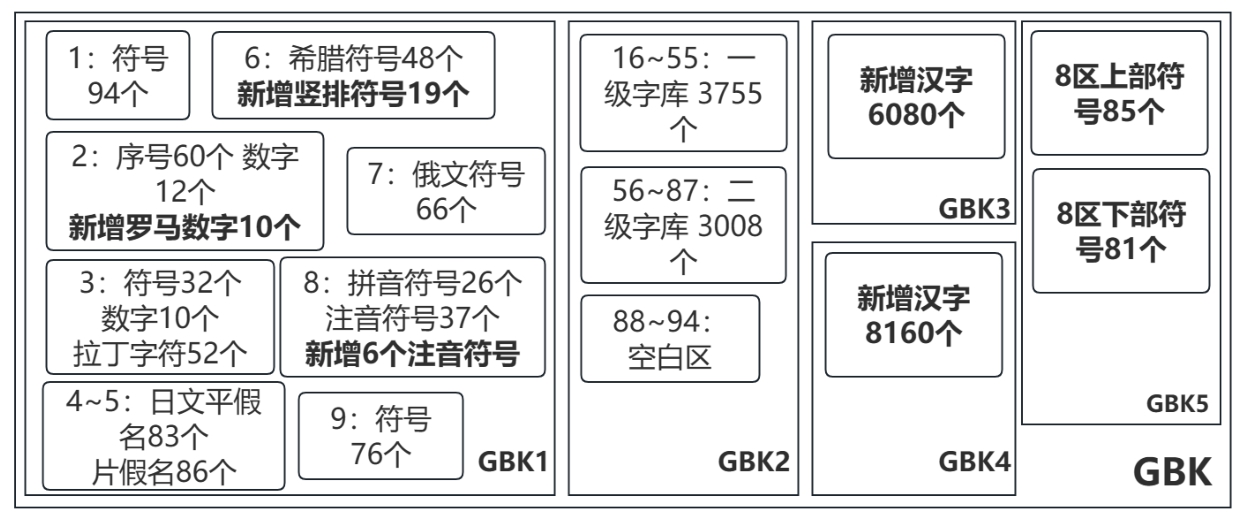
图1-13 GBK符号表
GBK编码表示一个字符,可以分为1、2、4字节。
·如果首字节在0x00~0x7F,则这段编码与ASCII编码一致。
·如果首字节为0x80或0xFF,则为无效编码。
·如果首字节在0x81~0xFE,且第二字节在0x40~0xFE,则为两字节编码。
·如果首字节在0x81~0xFE,且第二字节在0x30~0x39,则为四字节编码,其第三、四字节重复第一、二字节的模式,其余为无效字节。
根据以上规则,可以编写一个函数,用于获取一个GBK字节流中的字符数
。
GBK标准是为了使计算机能够兼容汉字而开发的。随着计算机在世界范围内的普及,国际上越来越希望有一种统一的文字编码,能够兼容全球所有的文字,这就是Unicode编码。下一节我们将详细介绍Unicode编码。
上一节介绍了GB编码,与之对应,各国也有各自的文本编码标准。图1-14显示了各种编码标准的衍生关系。为了有一种统一的编码标准,1990年,联合国经济社会文化组织(ECOSOC)开始制定Unicode编码标准。
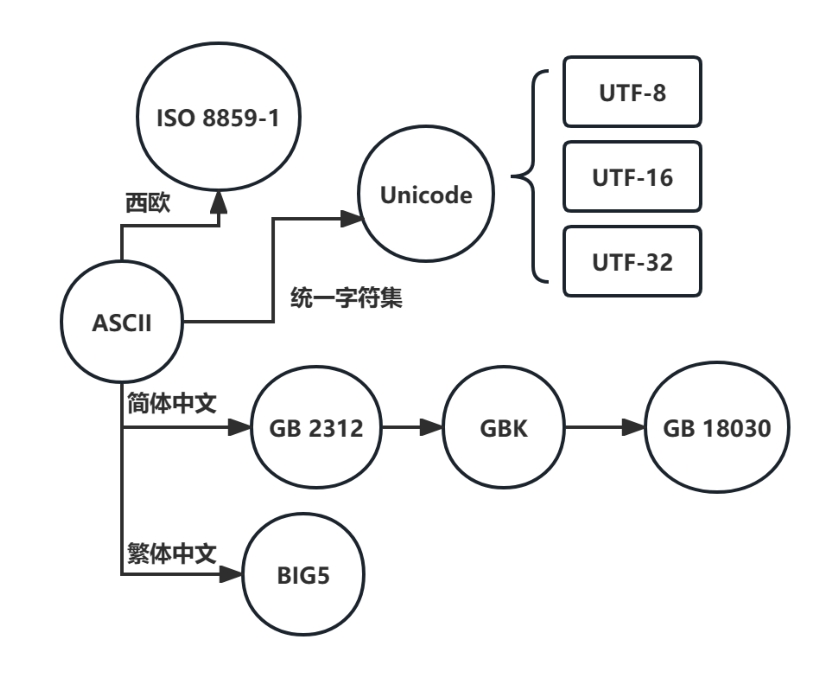
图1-14 各种编码标准的衍生关系
通过Unicode官网可以看到,截至2022年9月13日,共发布了15个版本。
Unicode有1 114 112(0x110000)个码位,分为17个字符平面,每个平面有65 536个码位。
Unicode 7.0标准共收录字符112 956个,其中汉字74 616个。
对于同一个Unicode码位,通常有3种编码方式:UTF-8、UTF-16、UTF-32。UTF-32编码总是使用4字节,相邻的编码具备连续性。UTF-16编码总是使用2字节,且在0平面与UTF-32相等。
Windows平台通常使用UTF-16编码,而macOS平台通常使用UTF-32编码。
0平面为基本位平面(Basic Multilingual Plane,BMP),码位从0x0000到0xFFFF。
Unicode为亚洲文字保留了CJK(Chinese Japanese Korean)区域,从0平面的0x4E00开始,共包含20 912个汉字。还有5个A~E的扩展区域,其中CJK A扩展区域位于0平面,从0x3400开始,扩展区域B~E位于2平面。
在0平面的0xD800和0xDC00开始的地方,各保留了1 024个码位,被称为UTF-16替代区(UTF-16 Surrogate Codec),用来转义1~16平面中的字符。这样大于2字节的字符,也能在UTF-16编码下进行表示。
1平面为补充位平面(Supplementary Multilingual Plane,SMP),码位从0x10000到0x1FFFF。
平面3~14中的很多码位都尚待分配。
最后的15、16平面为私人使用区,用户可以自行定义,被称为PUA(Private Use Area)-A、PUA-B。
在Windows平台上,可以使用如下两个API进行Unicode与GB编码之间的互转。
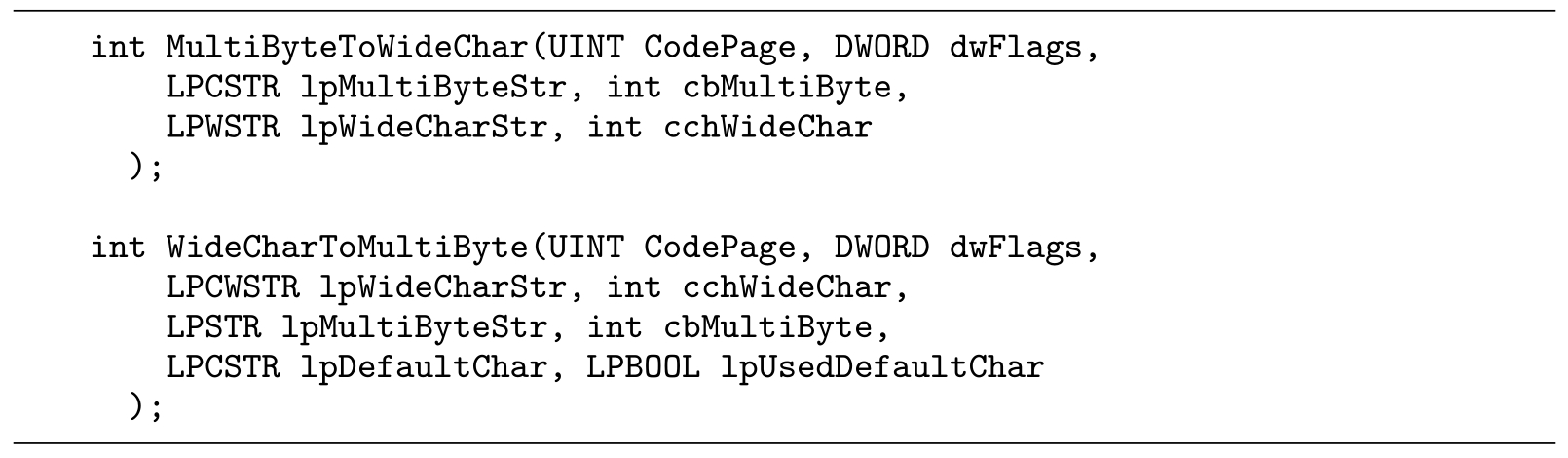
在UNIX平台上,我们通常使用libiconv开源库来完成字符集之间的转换。
UTF-8编码
Unicode用来表示全球的文本是足够的,但它的问题是,当它用来表示英文的时候,太浪费了。
英文字符只需要128个码位就足够了,于是1992年,UTF-8编码被UNIX系统的发明人Ken Thompson发明出来。
UTF-8编码使用1~6个变长字节来表示1个字符。
当使用1字节时,它与ASCII码完全一致,即0x00~0x7F,形如二进制0xxxxxxx,这里字母x代表0或1。
当使用2字节时,可以表示0x80~0x07FF的码位,形如110xxxxx 10xxxxxx可以表示8~11比特。
当使用3字节时,可以表示0x0800~0xFFFF,形如1110xxxx 10xxxxxx 10xxxxxx,可以表示12~16比特,这能表示所有2字节的编码。由于常用汉字都位于0平面的CJK和CJK A中,因此大多数汉字也能用3个UTF-8编码表示。
当使用4字节时,其位序列为11110xxx 10xxxxxx 10xxxxxx 10xxxxxx,可以表示21比特,表示范围是0x10000~0x1FFFF,这是Unicode 6.1的标准。
其余更大的UTF32字符,则使用5字节或6字节的UTF-8编码。
Unicode的文件,通常会在最前面加上3字节的BOM(Byte Order Mark)头,来表示文本的编码与字节序。
对于UTF-8编码,BOM通常为0xEF 0xBB 0xBF。为了能让C++源码跨平台显示与编译,我们的.h/.cpp文件都必须加上UTF-8的BOM头。
Windows平台上提供的字符集转换API也可以用于UTF-8编码的转换。
但由于UTF-8编码相对容易清晰,自己实现一套UTF-8与UTF-16的转换函数也是很方便的。
以下函数实现了对一个2字节字符的UTF-8编码,同时返回其需要的UTF-8字节数。

读者可以将上述代码作为参考,并实现对应UTF-32字符的编解码函数,以及对一个连续Unicode字符串的UTF-8转换
。
下一节将展示一个显示文本对应编码的工具。
TextViewer展示了任意输入文本的3种编码方式:ANSI(GBK)、Unicode、UTF-8,如图1-15所示。
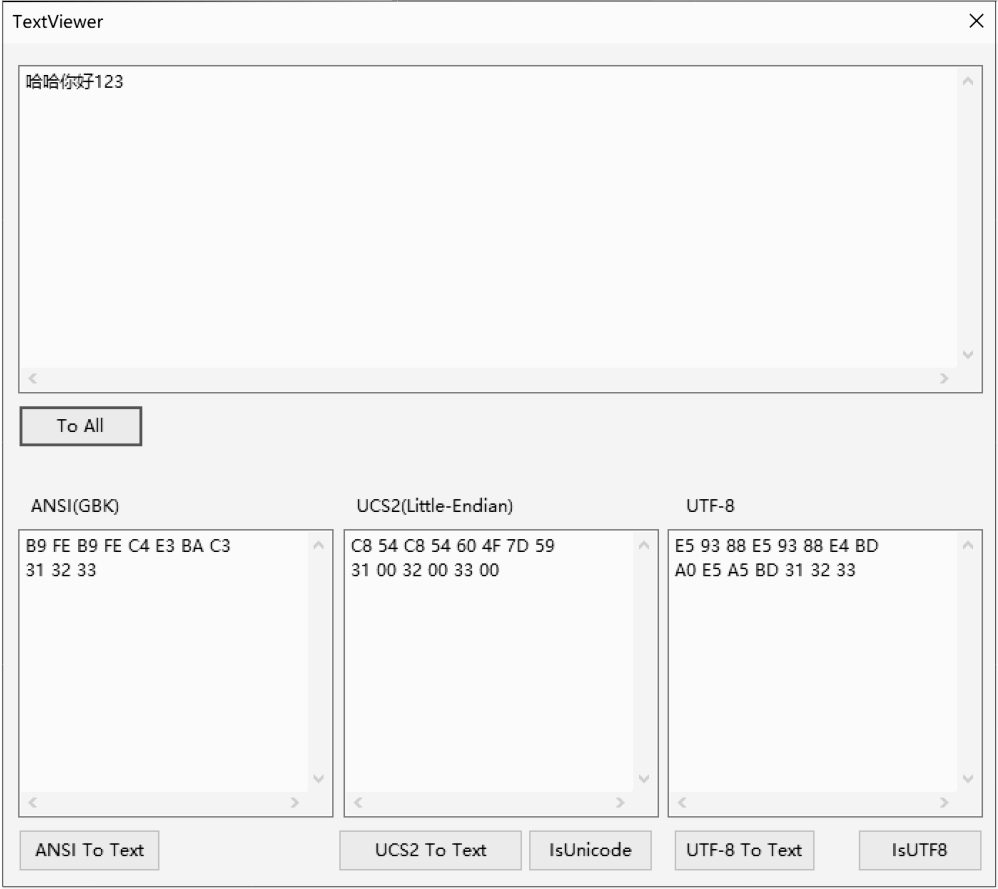
图1-15 TextViewer的界面
从Windows界面上读到的字符串都是Unicode的。在早期没有Unicode标准时,Windows系统使用ANSI字符集,在ANSI字符集下,英文采用ASCII编码,汉字采用GBK编码。为了进行ANSI与Unicode之间的转换,我们使用了C++标准库提供的wcstombs_s和mbstowcs_s,并封装到了DXP类中。

注意这里的std::wstring在不同平台下有着不同的字符宽度。Windows下wchar_t是2字节字符,macOS下wchar_t是4字节字符,它并不具备跨平台的特性。
为了进行UTF-8字符集的转换,我们封装了一个DUTF8的类,提供了一些静态方法,可以很方便地完成各类UTF-8的字符处理任务。

在RTC程序设计中,数据的传输要同时兼顾高效与跨平台的需要,因此对于文本的内容,通常会使用UTF-8编码。
有了对本节文本的深入理解,我们就可以将想要发出的信息用计算机编码表示出来。然而,要将信息传递给对方,还必须借助于网络,这将在下一节继续介绍。
英文字符的个数较少,使用一字节表示即可。汉字等亚洲文字需要使用两个或更多字节,各国大都定义了自己的字符集。为了统一全球的文字编码,Unicode标准应运而生。为了提高英文的传输效率,UTF-8编码成为非常流行的文本编码。
1.《编码的奥秘》(2000年),Charles Petzold著,伍卫国等译。此书介绍了一些相当有趣的编码历史,例如盲文的编码、ASCII码的由来。
2.《计算机字符编码——Unicode与Windows》(2016年),李建文著。书中列举了所有Windows支持的Unicode字符。
3.UTF-8编码的细节,参考RFC3629。
4.Bjoern Hoehrmann用C语言实现了UTF-8解码器,可在线查阅 Flexible and Economical UTF-8 Decoder 。
1.[5分钟](布莱叶盲文系统)路易斯·布莱叶(Louis Braille,1809—1852)于1824年创建了布莱叶盲文系统。该系统使用了64个码字,使用凸起和平面区分1和0。请问该编码表示一个字符需要多少个平凸?
2.[30分钟](ASCII输出)编写一个程序,输出每个ASCII码位及其对应的符号。
3.[30分钟](GBK字符数)编写一个函数,实现输入一个GBK字节流,输出其中包含的GBK字符数。
4.[1小时](GB 18030)2000年3月,我国推出了GB 18030—2000标准,其字符集来自Unicode 3.0,包括27 533个字符。2005年11月,GB 18030—2005成为强制执行的标准,它来自Unicode 4.1,包括76 556个字符。上网查询相关的标准内容,它们相对于GBK做了哪些改进。


