
下载掌阅APP,畅读海量书库
立即打开



手写阿拉伯数字辨识,问题定义如下。
(1)读取手写阿拉伯数字的影像,将影像中的每个像素当作一个特征。数据源为MNIST机构收集的60000笔训练数据,另含10000笔测试数据,每笔数据是一个阿拉伯数字,宽高为(28, 28)的位图形。
(2)建立神经网络模型,利用梯度下降法,求解模型的参数值,一般称为权重(Weight)。
(3)依照模型推算每一个影像是0~9的概率,再以概率最大的影像为预测结果。
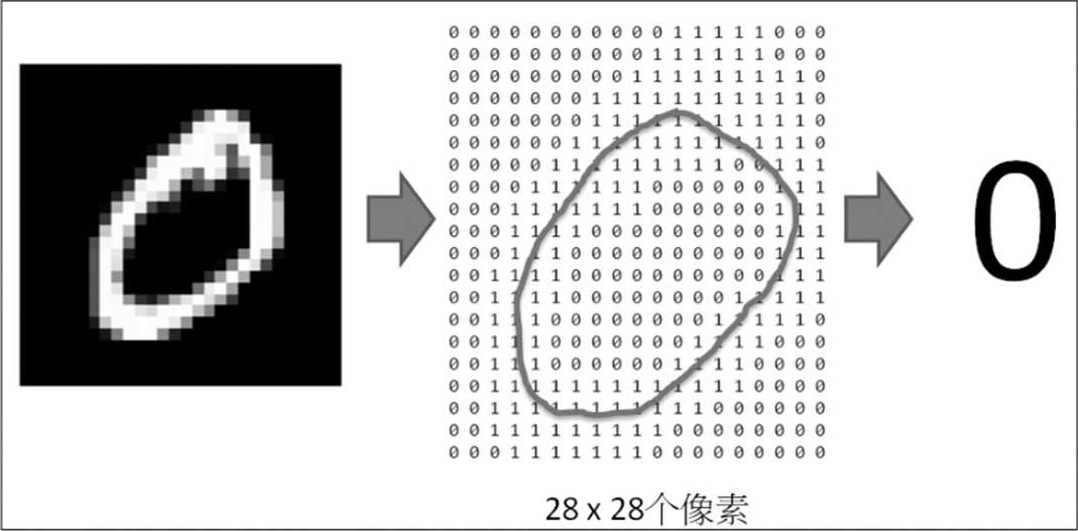
图4.1 手写阿拉伯数字辨识,左图为输入的图形,中间为图形的像素,右图为预测结果
TensorFlow v1.x版使用会话(Session)及运算图(Computational Graph)的概念来编写,只是将两个张量相加就需写一大段程序,这被对手Facebook PyTorch嘲讽得体无完肤,于是TensorFlow v2.x为了回击对手,官网直接出大招,在文件首页展示一个超短程序,示范如何撰写“手写阿拉伯数字辨识”代码,这充分证明了改版后的TensorFlow确实超好用,现在我们就来看看这个程序。
范例1.TensorFlow官网的手写阿拉伯数字辨识 [4] 。
下列程序代码请参考【04_01_手写阿拉伯数字辨识.ipynb】。

执行结果如下。
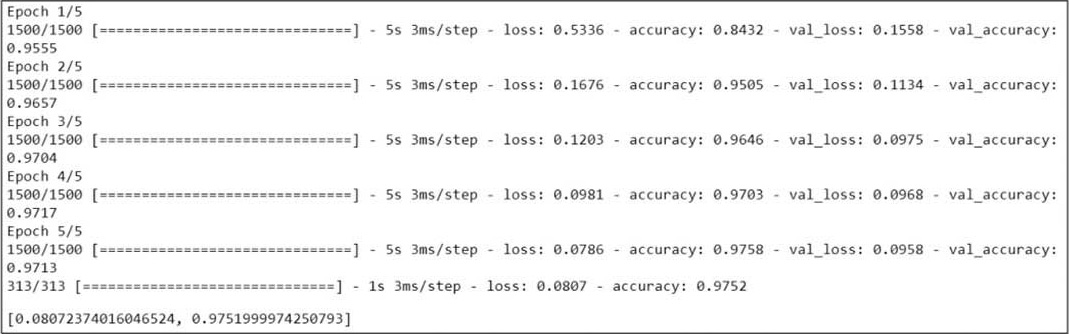
上述程序扣除批注仅10多行,但辨识的准确率竟高达97%~98%,TensorFlow借此成功扳回一城。PyTorch随后也开发出Lightning套件模仿TensorFlow/Keras,训练也直接使用model.fit,取代梯度重置、权重更新循环,双方攻防精彩万分。
范例2.以PyTorch Lightning撰写“手写阿拉伯数字辨识”的代码,须先安装套件,指令如下:
pip install pytorch-lightning
官网首页的程序复制如【04_02_手写阿拉伯数字辨识_Lightning.ipynb】,程序不够简洁,笔者到官网教学范例中复制了一段更简洁的程序如下。
下列程序代码请参考【04_03_手写阿拉伯数字辨识_Lightning_short.ipynb】。
(1)设定相关参数。

(2)建立模型:指定另一种损失函数交叉熵(Cross Entropy)及Adam优化器,写法与TensorFlow/Keras专家模式相似。

(3)训练模型。
下载MNIST训练数据。
建立模型对象。
建立DataLoader:DataLoader是一种Python Generator,一次只加载一批训练数据至内存,可节省内存的使用。
模型训练:与TensorFlow/Keras一样使用fit。
范例3.“手写阿拉伯数字辨识”完整范例请参阅【04_04_手写阿拉伯数字辨识_Lightning_accuracy.ipynb】,内含准确率的计算。由于我们的重点并不在这个范例上,所以这里就不再逐行说明了。
上一节的范例“手写阿拉伯数字辨识”是官网为了炫技刻意缩短了程序,本节将会按照机器学习流程的10大步骤(如图4.2),撰写此范例的完整程序,并对每个步骤仔细解析,大家务必理解每一行程序代表的意义。
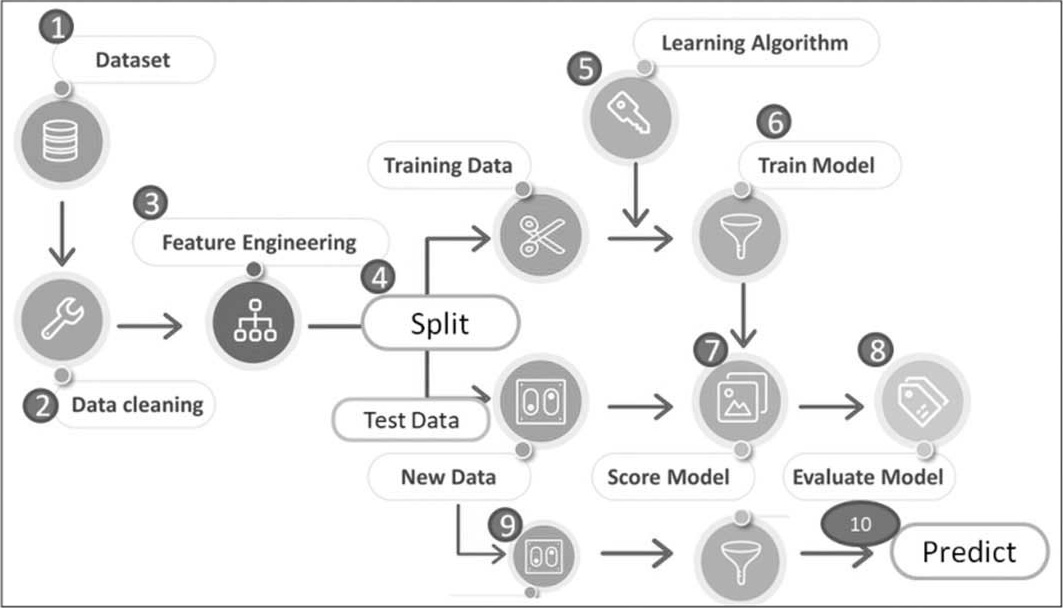
图4.2 机器学习流程10大步骤
范例4.依据图4.2所示的10大步骤撰写手写阿拉伯数字辨识程序。训练数据集采用MNIST数据库,它的数据源是美国高中生及人口普查局员工手写的阿拉伯数字0~9,如图4.3所示。

图4.3 手写阿拉伯数字
下列程序代码请参考【04_05_手写阿拉伯数字辨识_完整版.ipynb】。
(1)载入框架。
(2)设定参数,包括GPU的侦测,并决定是否使用GPU。
PATH_DATASETS:数据集下载存放的路径,空字符串表示程序目前的文件夹。

(3)加载MNIST手写阿拉伯数字数据集。

train=True为训练数据;train=False为测试数据。
执行结果:取得60000笔训练数据,10000笔测试数据,每笔数据是一个阿拉伯数字,宽高各为(28, 28)的位图形,要注意数据的维度及大小,必须与模型的输入规格契合。
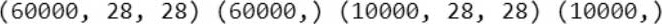
(4)对数据集进行探索与分析(EDA),首先观察训练数据的目标值(y),即影像的真实结果。

执行结果如下,每笔数据是一个阿拉伯数字。
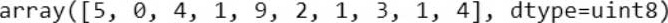
(5)显示第一笔训练数据的像素。

执行结果如下,像素的值介于(0, 255)为灰度图,0为白色,255为最深的黑色, 注意,这与RGB色码刚好相反(RGB黑色为0,白色为255) 。

(6)为了看清楚图片上手写的数字,将非0的数值转为1,变为黑白两色的图片。

执行结果如下,笔者以笔描绘1的范围,隐约可以看出是5。

(7)显示第一笔训练数据图像,确认是5。

执行结果如下。

(8)使用TensorFlow进行特征工程,将特征缩放成(0, 1)之间,可提高模型准确度,并且可以加快收敛速度。但是,PyTorch却会造成优化求解无法收敛,要特别注意,PyTorch特征缩放是在训练时DataLoader加载数据才会进行,与TensorFlow不同,要设定特征缩放可在下载MNIST指令内设定,如下,请参阅 【04_07_手写阿拉伯数字辨识_Normalize.ipynb】 。

第3行指定标准化,平均数为0.1307,标准偏差为0.3081,这两个数字是官网范例建议的值,函数用法请参阅官网介绍 [2] 。
第8行套用特征缩放的转换(transform=transform)。
(9)数据分割为训练及测试数据,此步骤无须进行,因为加载MNIST数据时,已经切割好了。
(10)建立模型结构,如图4.4所示。
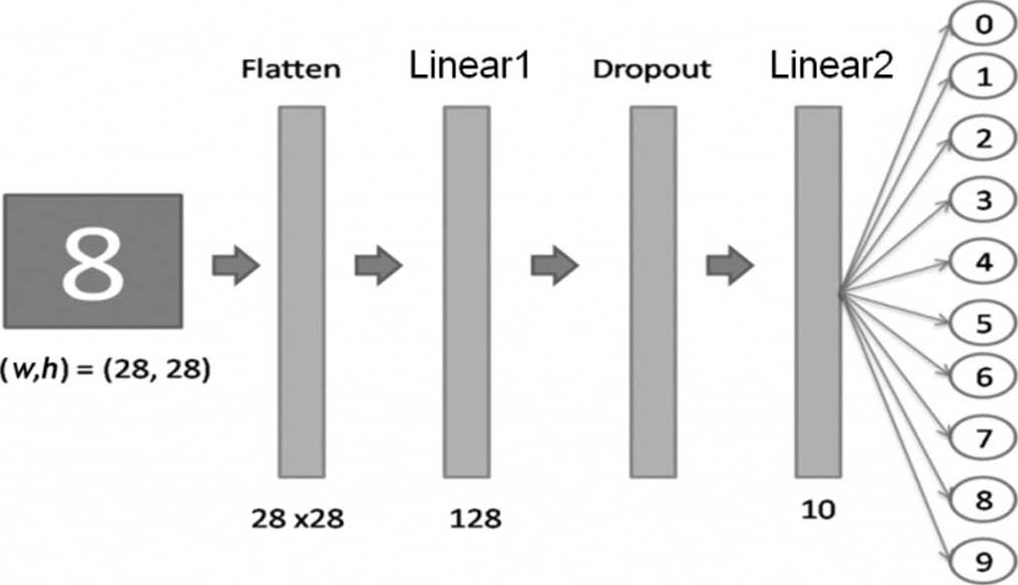
图4.4 手写阿拉伯数字辨识的模型结构
PyTorch与TensorFlow/Keras一样提供两类模型,即顺序型模型(Sequential Model)和Functional API模型,顺序型模型使用torch.nn.Sequential函数包覆各项神经层,适用于简单的结构,执行时神经层一层接一层地执行,另一种类型为Functional API,使用torch.nn.functional函数,可以设计成较复杂的模型结构,包括多个输入层或多个输出层,也允许分叉,后续使用到时再详细说明。这里使用简单的顺序型模型,内含各种神经层。

· 扁平层(Flatten Layer):将宽高各28个像素的图压扁成一维数组(28×28=784个特征)。
· 完全连接层(Linear Layer):第一个参数为输入的神经元个数,通常是上一层的输出,TensorFlow/Keras不用设定,但PyTorch需要设定,比较麻烦;第二个参数为输出的神经元个数,设定为256个神经元,即256条回归线,每一条回归线有784个特征。输出通常设定为4的倍数,并无建议值,可经由试验调校取得较佳的参数值。
· Dropout Layer:类似正则化(Regularization),希望避免过度拟合,在每一个训练周期随机丢弃一定比例(0.2)的神经元,一方面可以估计较少的参数,另一方面能够取得多个模型的均值,避免受极端值影响,借以校正过度拟合的现象。通常会在每一层完全连接层(Linear)后面加一个Dropout,比例也无建议值,如图4.5所示。
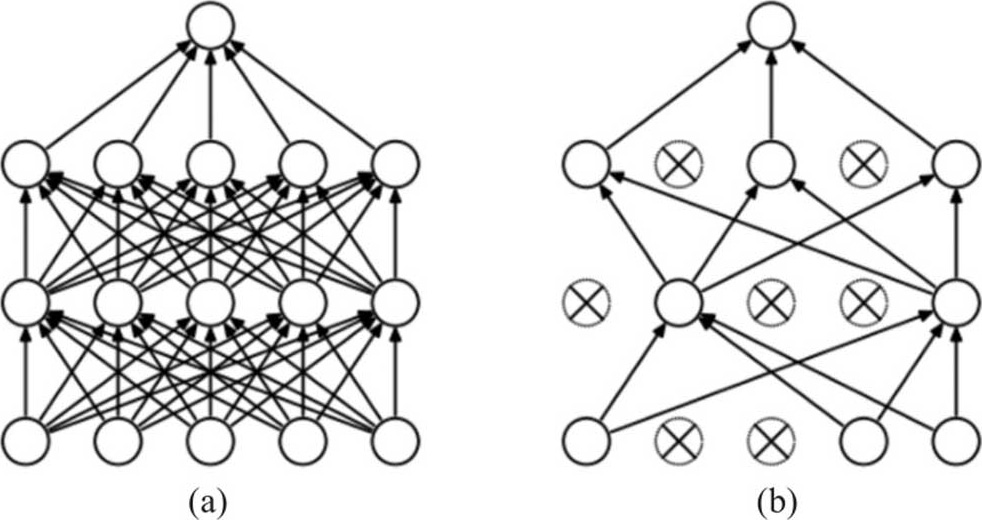
图4.5 (a)标准的神经网络,(b) Dropout Layer形成的神经网络
· 第二个完全连接层(Linear):输出层,因为要辨识0~9十个数字,故输出要设成10,一般通过Softmax Activation Function,可以将输出转为概率形式,即预测0~9的个别概率,再从中选择最大概率者为预测值,不过,若使用交叉熵(nn.CrossEntropyLoss),因PyTorch已内含Softmax处理,不需额外再加Softmax层,否则计算的损失会有误,这与TensorFlow/Keras不同,要特别注意,详情请参阅PyTorch官网CrossEntropyLoss的说明 [3] 或《交叉熵损失,softmax函数和torch.nn.CrossEntropyLoss()中文》 [4] 。
· 最后一行to(device): 要记得输入数据与模型必须一致,一律使用GPU或 CPU,不可混用 。
(11)结合训练数据及模型,进行模型训练。
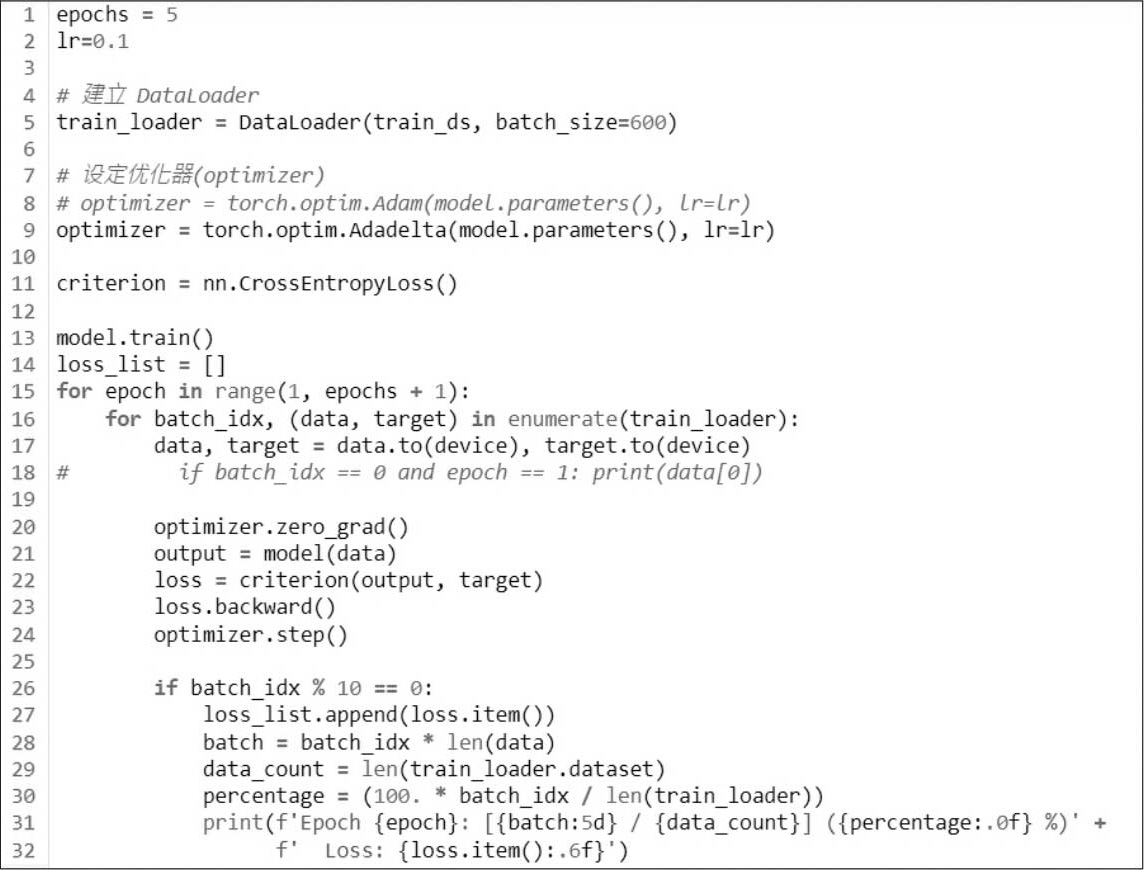
第1行设定执行周期。
第2行设定学习率。
第5行设定DataLoader,可一次取一批数据训练,节省内存。
第8~9行设定优化器(Optimizer):PyTorch提供多种优化器,各有优点,后续会介绍,本例使用哪一种优化器均可。
第11行设定损失函数为交叉熵(CrossEntropyLoss),PyTorch提供多种损失函数,后续会详细介绍。
第13行设定模型进入训练阶段,各神经层均会被执行,有别于评估阶段。
第14~32行进行模型训练,并显示训练过程与损失值,损失值多少不重要,需观察损失值是否随着训练逐渐收敛(显著减少)。
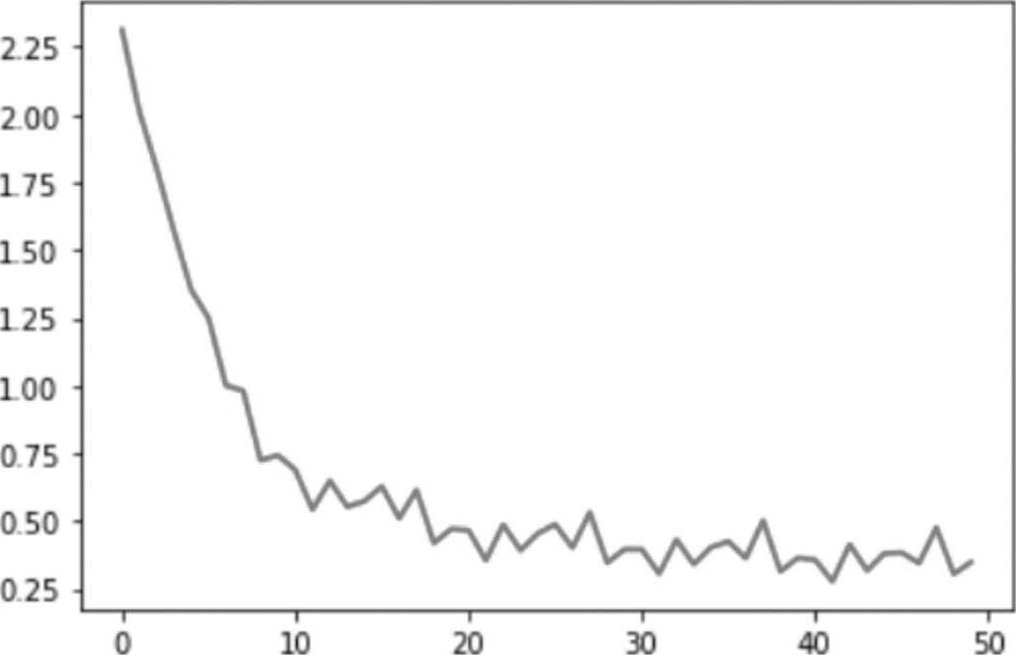
(12)对训练过程的损失绘图。

执行结果:随着执行周期(epoch)次数的增加,损失越来越低。
(13)评分(Score Model):输入测试数据,计算出损失及准确率。
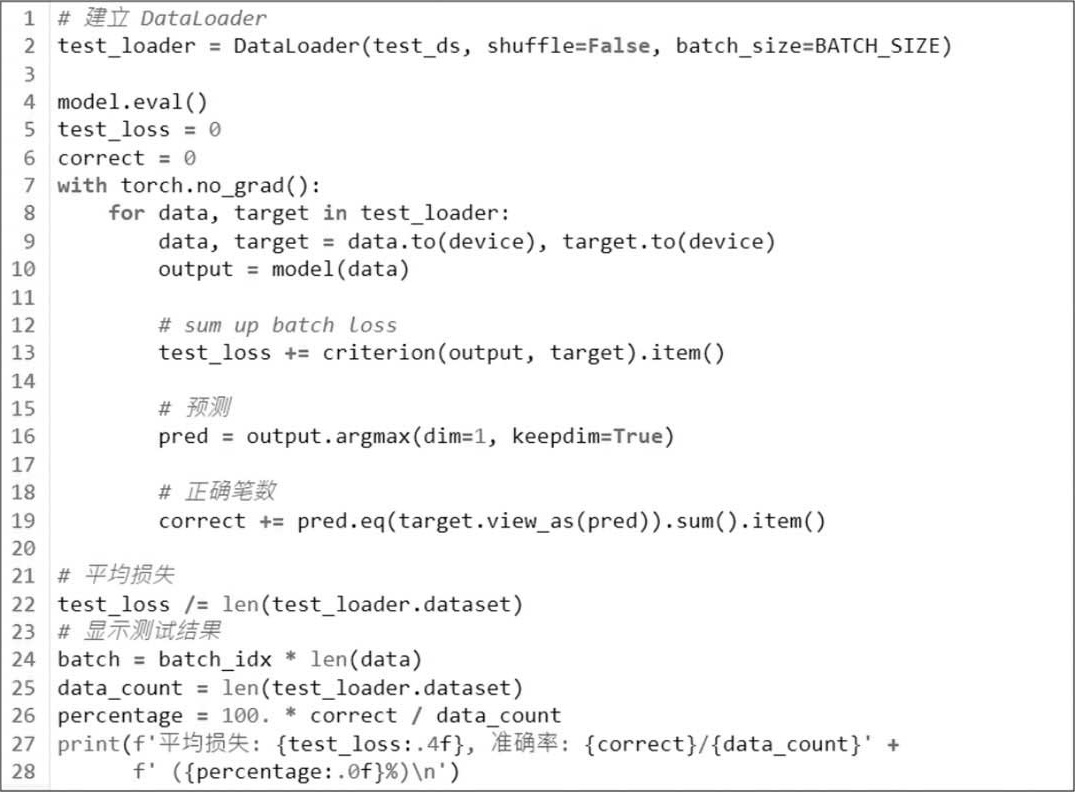
执行结果:平均损失为0.3345;准确率为9057/10000 (91%)。
第4行设定模型进入评估阶段,Dropout神经层不会被执行,因它抑制过度拟合,只用于训练阶段,这一行非常重要,否则预测会失准。
第7~19行预测所有测试数据,必须要包在with torch.no_grad()内,声明内嵌的程序代码不作梯度下降,否则程序会出现错误。
第13行是计算损失并累加。
第16行是预测并找最高概率的类别索引值,参数keepdim=True表示不修改output变量的维度。
第19行是计算准确笔数并累加。
(14)实际比对测试数据的前20笔。

执行结果如下,第9笔数据错误,其余全部正确。

(15)显示第9笔数据的概率。

执行结果:发现6的概率高很多。

(16)显示第9张图像。

第9张图像如下,像5又像6。

(17)暂不进行效能评估,之后可调校相关超参数(Hyperparameter)及模型结构,寻找最佳模型和参数。超参数是指在模型训练前可以调整的参数,例如学习率、执行周期、权重初始值、训练批量等,但不含模型求算的参数如权重(Weight)或偏差项(Bias)。
(18)模型部署,将最佳模型存盘,再开发用户接口或提供API,连同模型文件一并部署到上线环境(Production Environment)。

扩展名通常以.pt或.pth存储,建议使用.pt。
上述指令会将模型结构与权重一并存盘,如果只要存储权重,可执行以下指令,这部分概念与TensorFlow相同,但TensorFlow是存储至目录,而PyTorch是存储至文件,扩展名建议使用.pth,与上述模型结构与权重一并存盘有所区别。

model.parameters()只含学习到的参数(learnable parameters),例如权重与偏差,model.state_dict()会使用字典数据结构对照每一层神经层及其参数。
可显示每一层的state_dict维度。

更详细的用法可参照PyTorch官网Saving and Loading Models [8] 。
(19)系统上线,提供新数据预测,之前都是使用MNIST内建数据测试,但严格来说并不可靠,因为这些都是出自同一机构所收集的数据,所以建议读者利用绘图软件亲自撰写测试。我们准备了一些图片文件,放在myDigits目录内,读者可自行修改,再利用下列程序代码测试。注意, 从图片文件读入后要反转颜色 ,颜色0为白色,与RGB色码不同,它的0为黑色。另外,使用skimage读取图片文件,像素会自动缩放至[0,1]区间,不需再进行转换。
(20)显示模型的汇总信息。

执行结果:包括每一神经层的名称及输出入参数的个数。

也可以使用下列指令:

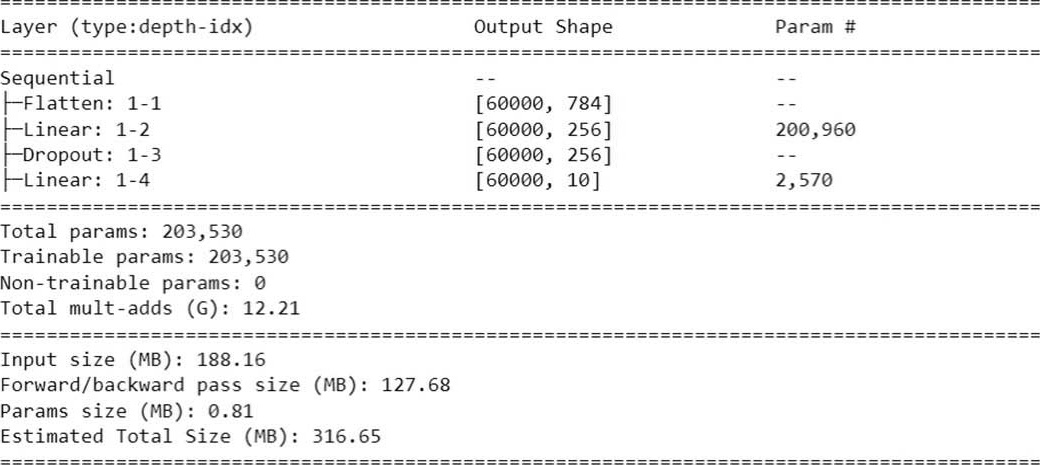
(21)也可以安装torchinfo或torch-summary显示较美观的汇总信息。
以下列指令安装:
pip install torchinfo
以下列指令显示汇总信息,summary第2个参数为输入数据的维度,含笔数。

执行结果。
(22)PyTorch无法像TensorFlow一样绘制如图4.6所示的模型图。
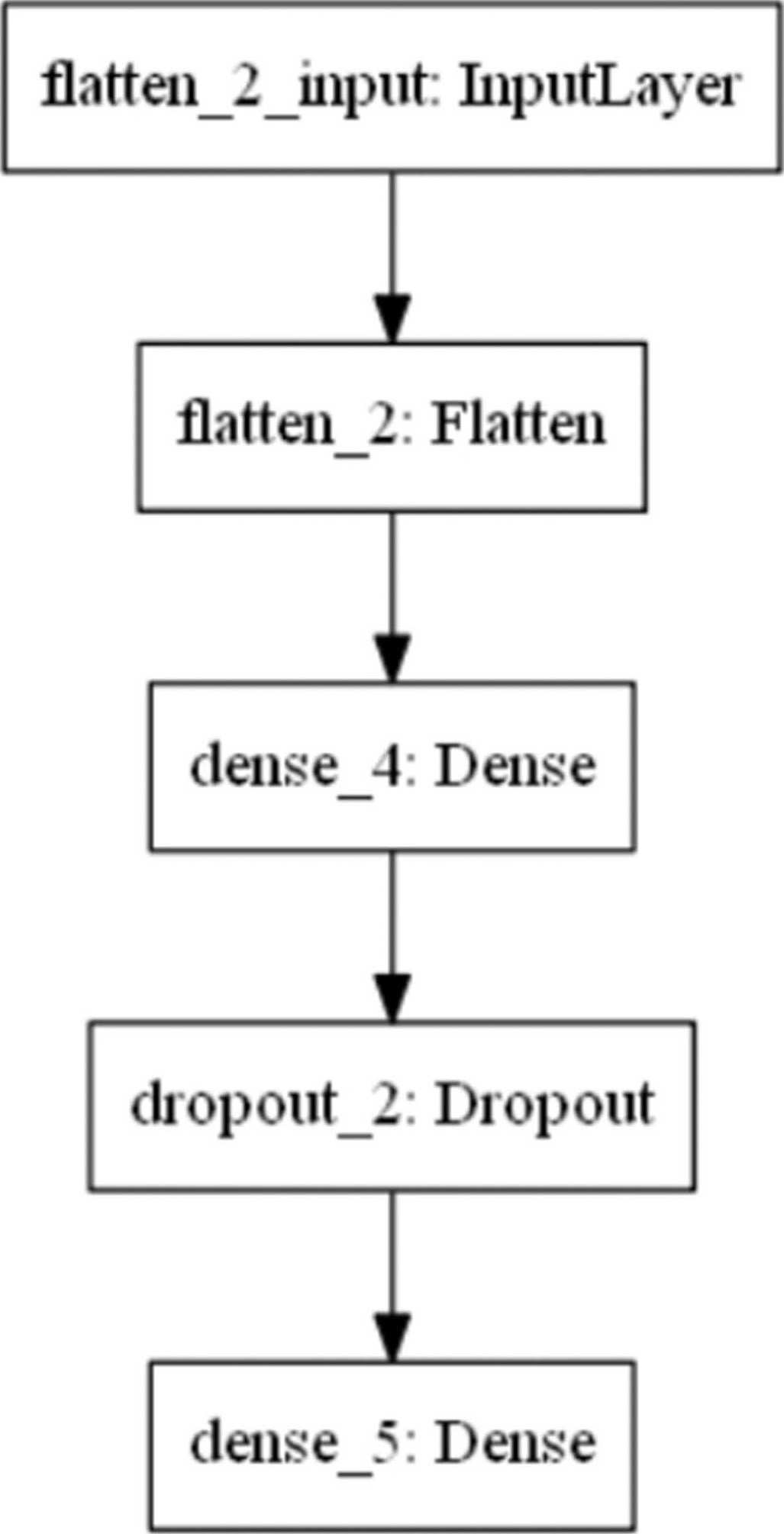
图4.6 模型图
以上按机器学习流程的10大步骤撰写了一个完整的程序,之后的任何模型或应用都可遵循相同的流程完成。因此,熟悉流程的每个步骤非常重要。下一节我们会做些试验来说明建构模型的考虑。
前一节我们完成了第一个神经网络程序,也见识到它的威力,扣除变量的检查,短短几行程序就能够辨识手写阿拉伯数字,且准确率达到90%左右,或许读者会心生一些疑问。
(1)模型结构为什么要设计成两层完全连接层(Linear)?更多层的准确率会提高吗?
(2)第一层完全连接层(Linear)输出为什么要设为256?设为其他值会有何影响?
(3)Activation Function也可以抑制过度拟合,将Dropout改为Activation Function ReLu准确率有何不同?
(4)优化器(optimizer)、损失函数(loss)、效能衡量指标(metrics)有哪些选择?设为其他值会有何影响?
(5)Dropout比例为0.2,设为其他值会更好吗?
(6)影像为单色灰度,若是彩色可以辨识吗?如何修改?
(7)执行周期(epoch)设为5,设为其他值会更好吗?
(8)准确率可以达到100%吗?
(9)如果要辨识其他对象,程序要修改哪些地方?
(10)如果要辨识多个数字,例如输入4位数,要如何辨识?
以上问题是这几年授课时学员常提出的疑惑,我们就来逐一试验,试着寻找答案。
问题1.模型结构为什么要设计成两层完全连接层(Linear)?更多层的准确率会提高吗?
解答:
前面曾经说过,神经网络是多条回归线的组合,而且每一条回归线可能还会包在Activation Function内,变成非线性的函数,因此,要单纯以数学求解几乎不可能,只能以优化方法求得近似解,但是,只有凸集合的数据集,才能保证有全局最佳解(Global Minimization),以MNIST为例,总共有28×28=784个像素,每个像素视为一个特征,即784度空间,它是否为凸集合,是否存在最佳解?我们无从得知,因此严格地讲,到目前为止,神经网络依然是一个黑箱(Black Box)科学,我们只知道它威力强大,但如何达到较佳的准确率,仍旧需要经验与反复的试验。因此,模型结构并没有明确规定要设计成几层,要随着不同的问题及数据集进行试验,一次次地进行效能调校,找寻较佳的参数值。
理论上,越多层架构,回归线就越多条,预测越准确,像是后面介绍的ResNet模型就高达150层,然而,经过试验证实,一旦超过某一界限后,准确率就会下降,这跟训练数据量有关,如果只有少量的数据,要估算过多的参数( w 、 b ),准确率自然不高。
我们就来小小试验一下,多一层完全连接层(Linear),准确率是否会提高?请参阅程序 【04_05_手写阿拉伯数字辨识_试验2.ipynb】 。
修改模型结构如下,加一对完全连接层(Linear)/Dropout,其余代码不变。

执行结果:平均损失为0.0003,准确率为9069/10000 (91%),准确率稍微提升,不显著。
问题2.第一层完全连接层(Linear)输出为什么要设为256?设为其他值会有何影响?
解答:
输出的神经元个数可以任意设定,一般来讲,会使用4的倍数,以下我们修改为512,请参阅程序 【04_05_手写阿拉伯数字辨识_试验3.ipynb】 。
执行结果:平均损失为0.0003,准确率为9076/10000 (91%),准确率稍微提升,不显著。
同问题1,照理来说,神经元个数越多,回归线就越多,特征也就越多,预测就会越准确,但经过验证,准确率并未显著提高。依据 Deep Learning with TensorFlow 2 and Keras [6] 一书测试,结果如图4.7,也是有一个极限,超过就会不升反降。
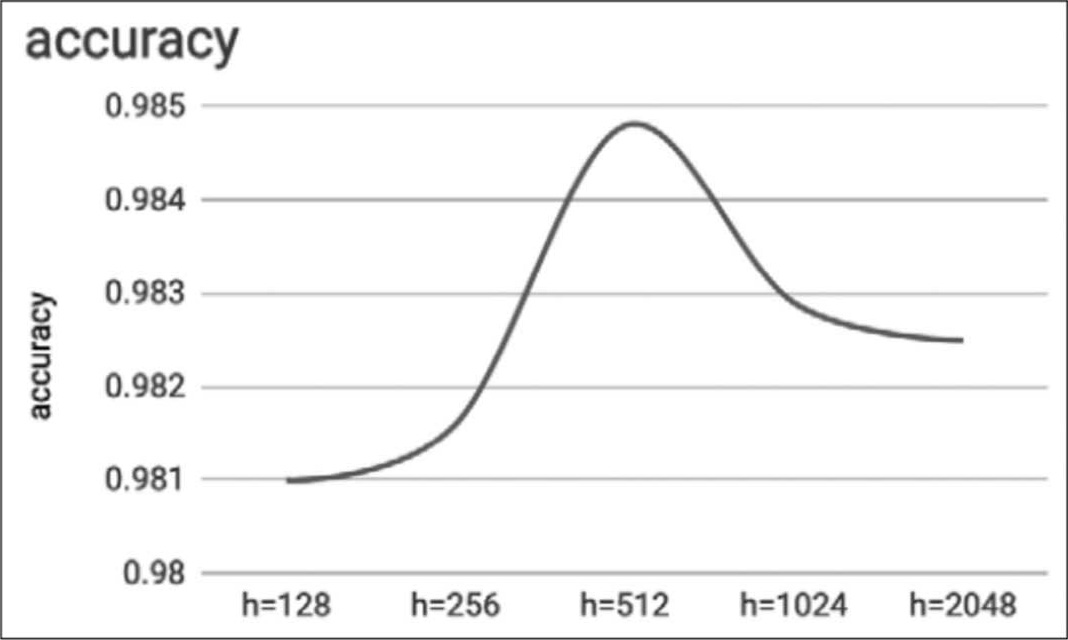
图4.7 测试结果
神经元个数越多,训练时间就越长,如图4.8所示。
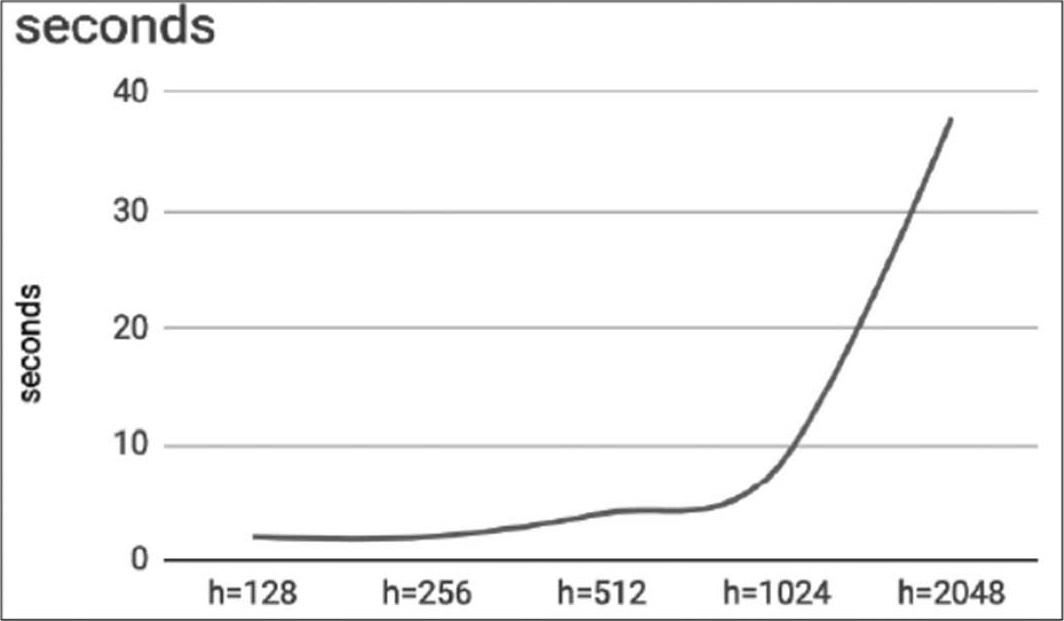
图4.8 执行结果
问题3.Activation Function也可以抑制过度拟合,将Dropout改为Activation Function ReLu,准确率有何不同?请参阅程序 【04_05_手写阿拉伯数字辨识_试验4.ipynb】 。
解答:
Activation Function有很多种,后面会有详尽介绍,可先参阅维基百科 [7] ,部分表格截取如下,包括函数的名称、概率分配图形、公式及一阶导数,如图4.9所示。

图4.9 Activation Function的种类
早期隐藏层大都使用Sigmoid函数,近几年发现ReLU准确率更高。
将Dropout改为ReLU,如下所示。

执行结果:平均损失为0.0003,准确率为9109/10000 (91%),准确率稍微提升,不显著。
新数据预测是否比较精准?答案是并不理想。
一般而言,神经网络使用Dropout比正则化(Regularizer)更理想。
问题4.优化器(Optimizer)、损失函数(Loss)、效能衡量指标(Metrics)有哪些选择?设为其他值会有何影响?
解答:
优化器有很多种,如最简单的固定值的学习率(SGD)、复杂的动态改变的学习率以及能够自定义优化器,详情请参考PyTorch官网 [8] 。优化器的选择,主要会影响收敛的速度,大多数状况下,Adam优化器都有不错的表现,不过,在下一节介绍的CNN模型搭配Adam优化器却发生无法收敛的状况,而TensorFlow则不会,可见一个同名的优化器在不同套件上,开发的细节仍有所差异。
损失函数种类繁多,包括常见的MSE、Cross Entropy,其他更多的信息请参考PyTorch官网 [9] 。损失函数的选择影响着收敛的速度,另外,某些自定义损失函数有特殊功能,例如风格转换(Style Transfer),它能够制作影像合成的效果,生成对抗网络(GAN)更是发扬光大,后面章节会有详细的介绍。
效能衡量指标(metrics):除了准确率(Accuracy),还可以计算精确率(Precision)、召回率(Recall)、F1等,尤其是面对不平衡的样本时。
问题5.Dropout比例为0.2,设为其他值会更好吗?
解答:
将Dropout比例改为0.5,测试看看,请参阅程序 【04_05_手写阿拉伯数字辨识_试验5.ipynb】 。
执行结果:平均损失为0.0003,准确率为9034/10000 (90%),准确率略为降低。
抛弃比例过高时,准确率会陡降。
新数据预测是否比较准?结果并不理想,如图4.10所示。
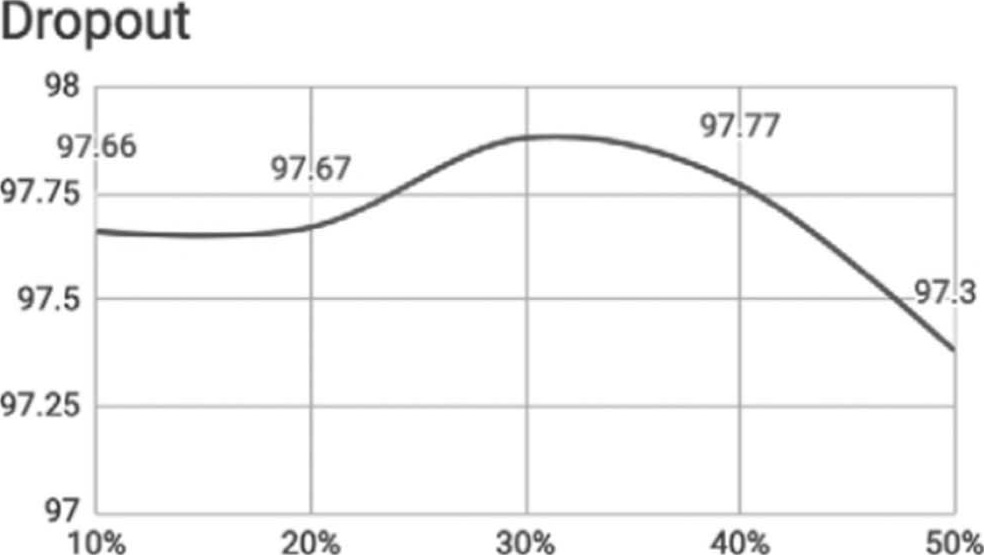
图4.10 执行结果
问题6.目前MNIST影像为单色灰度,若是彩色可以辨识吗?如何修改?
解答:可以,若颜色有助于辨识,可以将RGB三通道分别输入辨识,后面我们讲到卷积神经网络(Convolutional Neural Networks,CNN)时会有范例说明。
问题7.执行周期(epoch)设为5,设为其他值会更好吗?
解答:将执行周期(epoch)改为10,请参阅程序 【04_05_手写阿拉伯数字辨识_试验6.ipynb】 。

执行结果:平均损失为0.0003,准确率为9165/10000 (92%),准确率略为提高。
但损失率到后来已降不下去了,如图4.11所示。
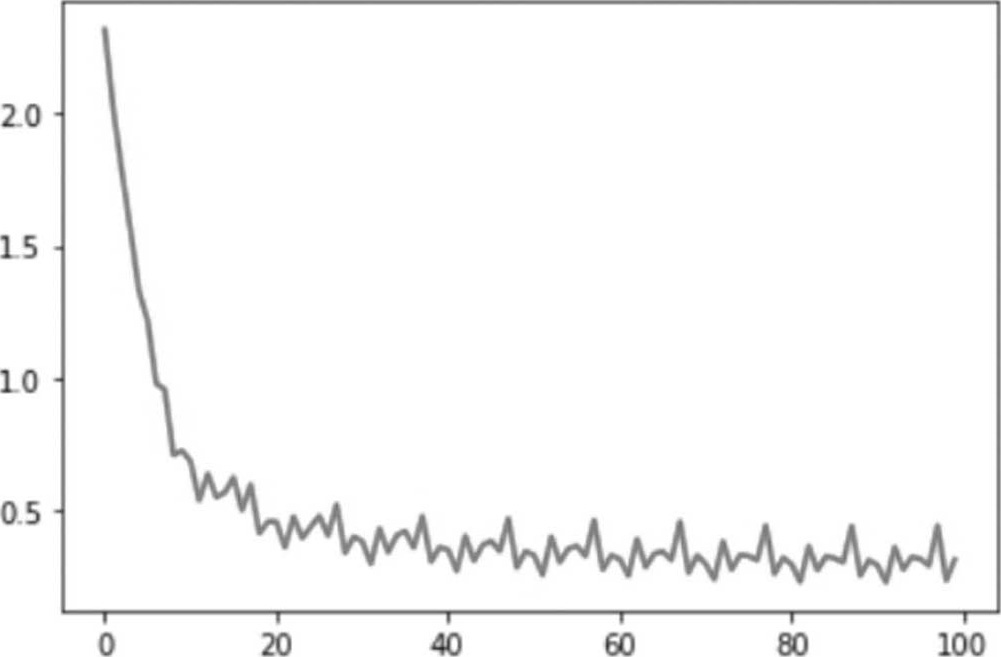
理论上,训练周期越多,准确率越高,然而,过多的训练周期会造成过度拟合(Overfitting),反而会使准确率降低,如图4.12所示。
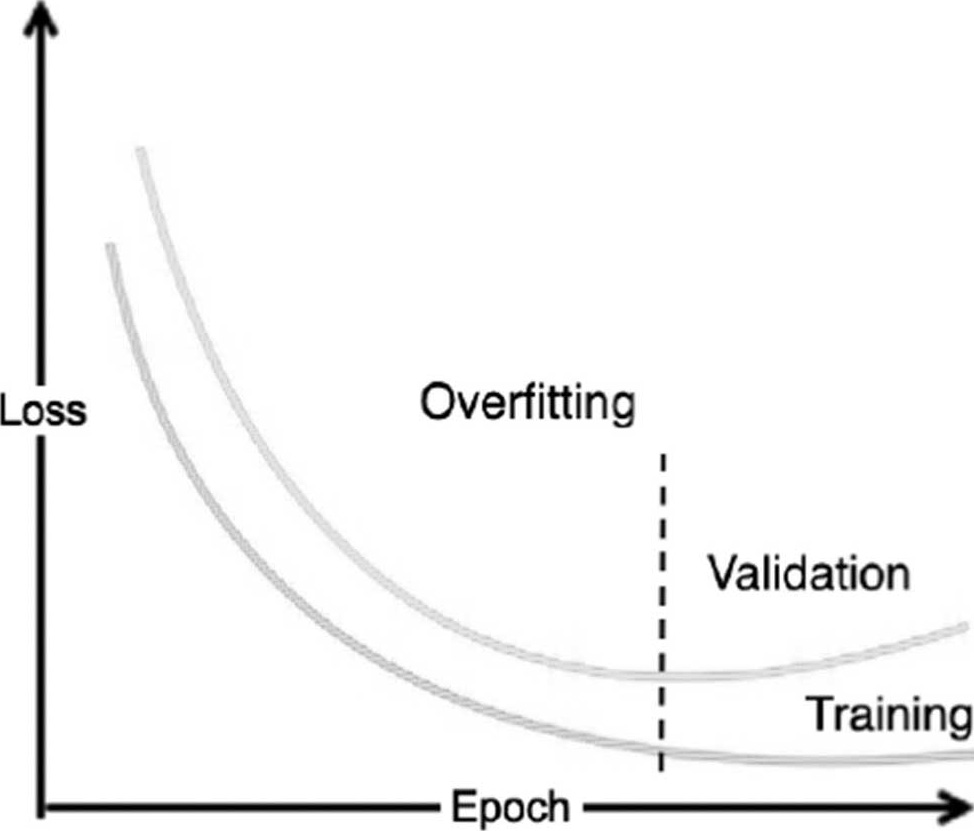
问题8.准确率可以达到100%吗?
解答:很少的模型准确率能够达到100%,除非是用数学推导出来的模型,优化只是求近似解而已,另外,由于神经网络是从训练数据中学习知识,而测试或预测数据并不参与训练,若与训练数据分布有所差异,甚至来自不同的概率分配,准确率很难能达到100%。
问题9.如果要辨识其他对象,程序要修改哪些地方?
解答:只需修改很少的程序代码,就可以辨识其他对象,例如,Zalando公司提供另一个类似的数据集FashionMNIST,请参阅 【04_06_FashionMNIST辨识_完整版.ipynb】 ,除了加载数据的指令不同外,其他的程序代码几乎不变。这也说明了一点, 神经网络并不是真的认识0~9,它只是从像素数据中推估出的模型,即所谓的从数据中学习到知识(Knowledge Discovery from Data, KDD) ,以MNIST而言,模型只是统计0~9这10个数字像素大部分分布在哪些位置而已。FashionMNIST数据集下载指令如下。

问题10.如果要辨识多个数字,例如输入4位数,要如何辨识?
解答:可以使用图像处理分割数字,再分别依次输入模型预测即可。或者更简单的方法,直接将视觉接口(UI)设计成4格,规定使用者只能在每个格子内各输入一个数字。
以上的试验大多只针对单一参数做比较,假如要同时比较多个变量,就必须跑遍所有参数组合,这样程序就会很复杂,别担心,有一些工具可以帮忙,包括Keras Tuner、hyperopt、Ray Tune、Ax等,在后续“超参数调校”一节有较详细的介绍。
由于MNIST的模型辨识率很高,要观察超参数调整对模型的影响,并不容易,建议找一些辨识率较低的模型进行相关试验,例如FashionMNIST、CiFar数据集,才能有比较显著的效果,FashionMNIST的准确率只有81%左右,试验比较能观察出差异。