
下载掌阅APP,畅读海量书库
立即打开



一般来说,机器学习开发流程(Machine Learning Workflow)有多种建议的模型,例如数据挖掘(Data Mining)流程,包括CRISP-DM (cross-industry standard process for data mining)、Google Cloud建议的流程 [4] 等,个人偏好的流程如下。
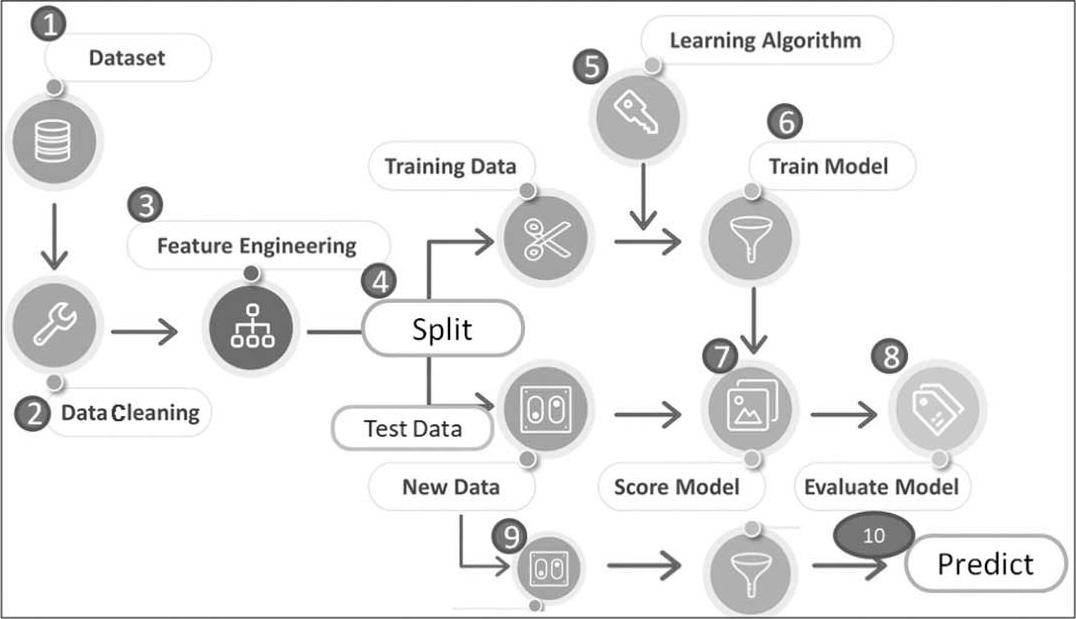
图1.6 机器学习开发流程(Machine Learning Workflow)
流程大概分为10个步骤(不含较高层次的企业需求了解,只包括实际开发的步骤):
(1)搜集数据,汇总为数据集(Dataset)。
(2)数据清理(Data Cleaning)、数据探索与分析(Exploratory Data Analysis, EDA):EDA通常通过描述统计量及统计图来观察数据的分布,了解数据的特性、极端值(Outlier)、变量之间的关联性。
(3)特征工程(Feature Engineering):原始搜集的数据未必是影响预测目标的关键因素,有时候需要进行数据转换,才得以找到关键的影响变量。
(4)数据切割(Data Split):将数据切割为训练数据(Training Data)及测试数据(Test Data),一份数据供模型训练之用,另一份数据则用在衡量模型效能,例如准确度,切割的主要原因是确保测试数据不会参与训练,以维持其公正性,即Out-of-Sample Test。
(5)选择学习算法(Learning Algorithms):依据问题的类型选择适合的算法。
(6)模型训练(Model Training):以算法及训练数据,进行训练产出模型。
(7)模型计分(Score Model):计算准确度等效能指标,评估模型的准确性。
(8)模型评估(Evaluate Model):比较多个参数组合、多个算法的准确度,找出最佳参数与算法。
(9)部署(Deploy):复制最佳模型至正式环境(Production Environment),制作使用界面或提供API,通常以网页服务(Web Services)方式开发。
(10)预测(Predict):正式开始服务用户,用户传入新数据或文件后,输入至模型进行预测,并回传预测结果。
机器学习开发流程与一般应用系统开发流程有何差异?最大的差别如下:
(1)一般应用系统利用输入数据与转换逻辑产生输出,例如撰写报表,根据转换规则将输入字段转换为输出字段,但机器学习先产生模型,再根据模型进行预测,故而重用性(Reuse)高。
(2)机器学习不只使用输入数据,还会搜集大量的历史数据或从因特网中爬取出一堆数据,作为“饲料”。
(3)新产生的数据可再返回模型,重新训练,自我学习,使模型更聪明。
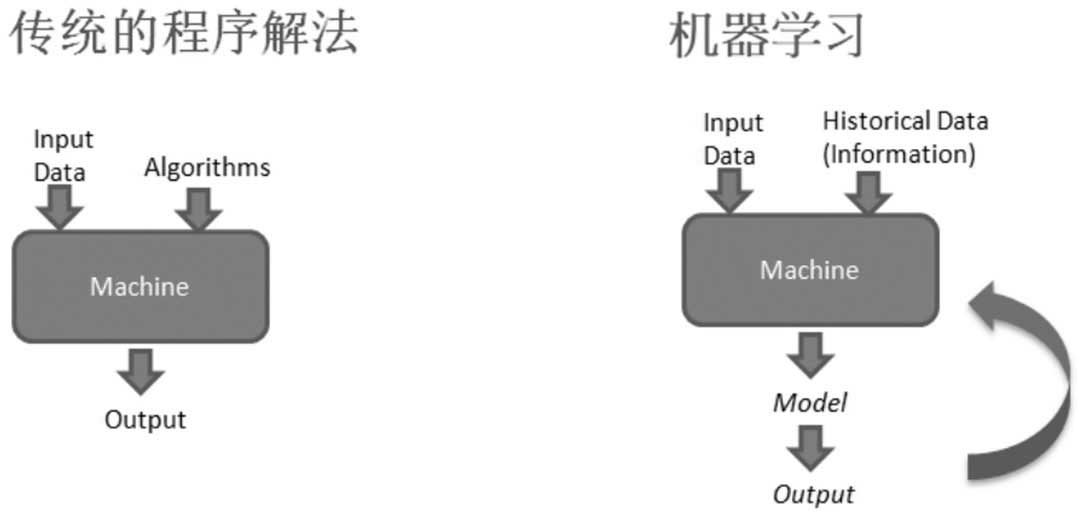
图1.7 机器学习与一般应用系统开发流程的差异