
下载掌阅APP,畅读海量书库
立即打开



序列(Series)是工作文件中最重要的对象,序列存储了变量的观测值,是数据存储的基本单元。
本章的主要内容包括:
· 什么是序列?
· 创建序列。
· 序列窗口的工具栏。
· 数值代码与Valmap。
序列是单个变量的观测值的集合。序列只能存储数值,不能存储文本。数值既包括定量变量的观测值,也包括定性变量的数值代码。
如果定性变量的观测值是文本,Eviews会将其识别为文本序列;如果定性变量的观测值是数值代码,Eviews才会将其识别为序列。例如,性别的值为“男”和“女”,Eviews会将性别识别成文本序列;如果性别的值为“0”和“1”,Eviews才会将性别识别成序列。
文本序列和序列是两种完全不同的对象类型。文本序列主要用于标识观测单元,以及进行字符串运算,能参与的数值分析有限;只有序列才能参与数值分析。因此,将外部数据导入Eviews时,要特别注意外部数据中的定性变量的表现形式,如果定性变量是文本形式的,建议先将其转换为数值代码,再将其导入Eviews。
创建序列有3种常用方法,一是通过导入外部数据创建序列,二是通过新建对象创建序列,三是通过对序列进行数学变换创建序列。
本节将以数据文件“students 210.xlsx”为例,介绍上述操作方法的实现。
如图6.1所示,将数据文件“students 210.xlsx”导入Eviews,数值形式的变量都被转换成了工作文件中的序列,序列的图标是一小段折线图。
“name”存储的名字是文本字符串,转换为工作文件中的文本序列后,其图标是“abc”。
创建工作文件后,如图6.1中箭头所示,单击主菜单“Object/New object...”,或者单击工作文件窗口工具栏中的“Object”按钮,打开新建对象的对话框,选择对象类型为“Series”,即可创建序列。
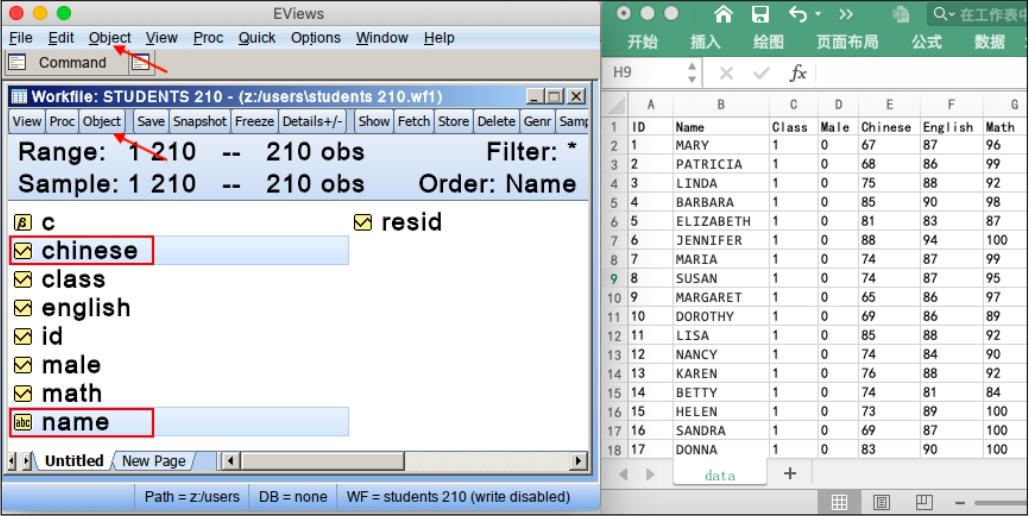
图6.1 通过导入外部数据创建序列
注意: 序列是存储在工作文件中的。要创建序列,需要先创建工作文件。如果Eviews中没有打开的工作文件,单击主菜单“Object”,将无法选择“New Object...”,如图6.2所示。
依次单击主菜单“Quick/Generate Series...”,或者单击工作文件窗口工具栏中的“Genr”按钮,打开图6.3所示的对话框,在“Enter equation”文本框中输入形如“series_name = formula”的表达式,“series_name”是新序列的名称,“formula”是数学表达式。
图6.2 新建对象
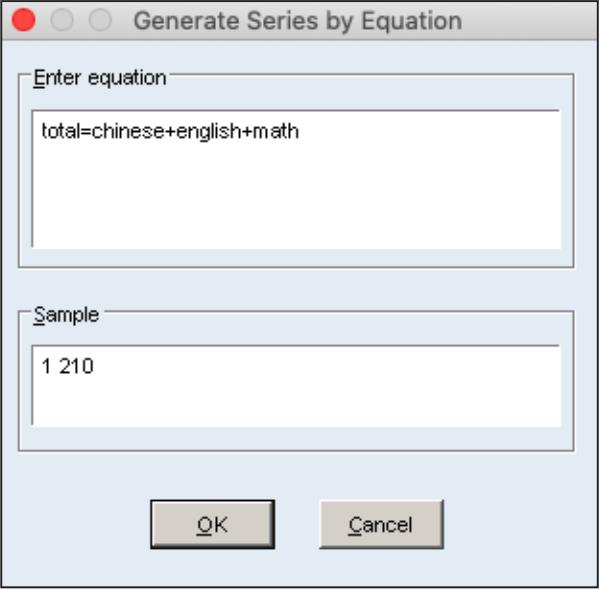
图6.3 输入数学表达式创建序列
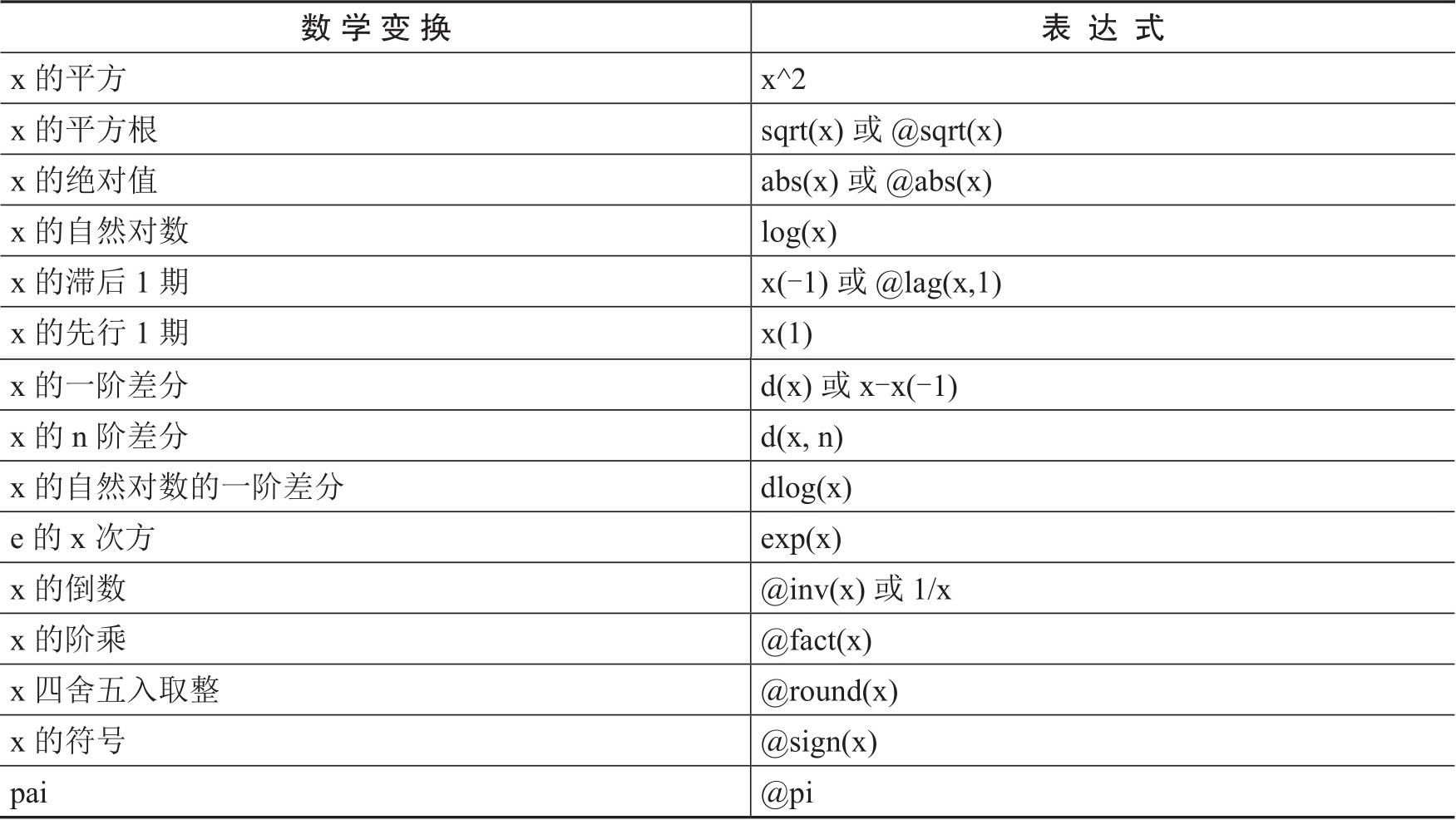
以“x”序列为例,表6.1列示了对序列进行数学变换的表达式。
表6.1 序列的数学变换
本节介绍序列窗口工具栏中的工具,包括视图(View)、程序(Proc)、对象(Object)、属性(Properties)、打印(Print)、命名(Name)、冻结(Freeze)、排序(Sort)、切换编辑模式(Edit+/-)、切换样本(Smpl+/-)、切换调整模式(Adjust+/–)、切换标签显示(Label+/-)、切换宽窄显示(Wide+/-)、标题(Title)、样本(Sample)、创建新序列(Genr)和实时统计量(Live Statistics)。
序列窗口的工具栏是一系列工具按钮,排列在序列窗口标题栏的下方,如图6.4所示。工具栏中集合了16个工具,下面将一一对其进行介绍。
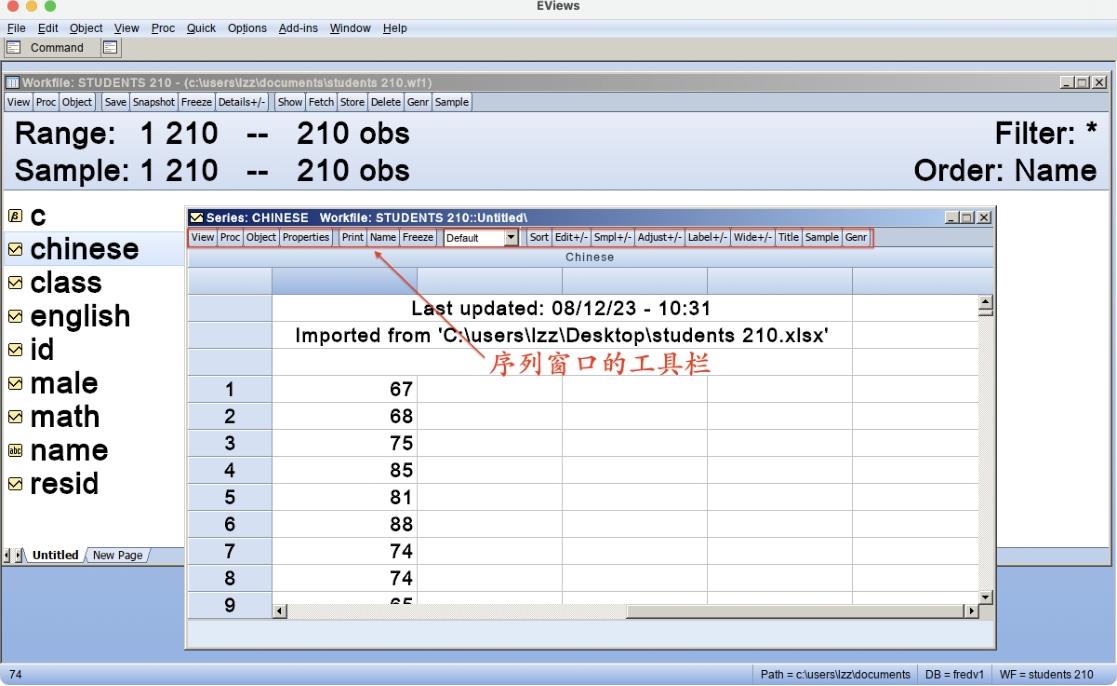
图6.4 序列窗口的工具栏
本节以数据文件“students 210.xlsx”为例,其数据结构如图6.5所示。该文件是210名同学的资料,包括学生编号(ID)、姓名(Name)、班级(Class,Class的值为数字代码1、2、3、4,分别代表4个班级)、性别(Male,1代表男生,0代表女生),以及语文、数学、外语3门课程的成绩。
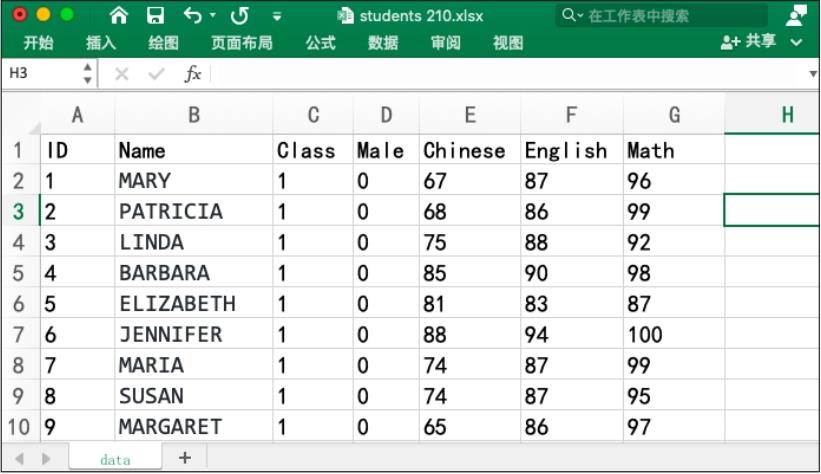
图6.5 “students 210.xlsx”的数据结构
将“students 210.xlsx”导入Eviews,创建工作文件,单击“Chinese”序列,打开图6.4所示的窗口。
1)视图工具
单击序列窗口工具栏中的“View”按钮,下拉菜单罗列了序列的视图工具(见图6.6),分为4栏,每一栏的主要功能如下。
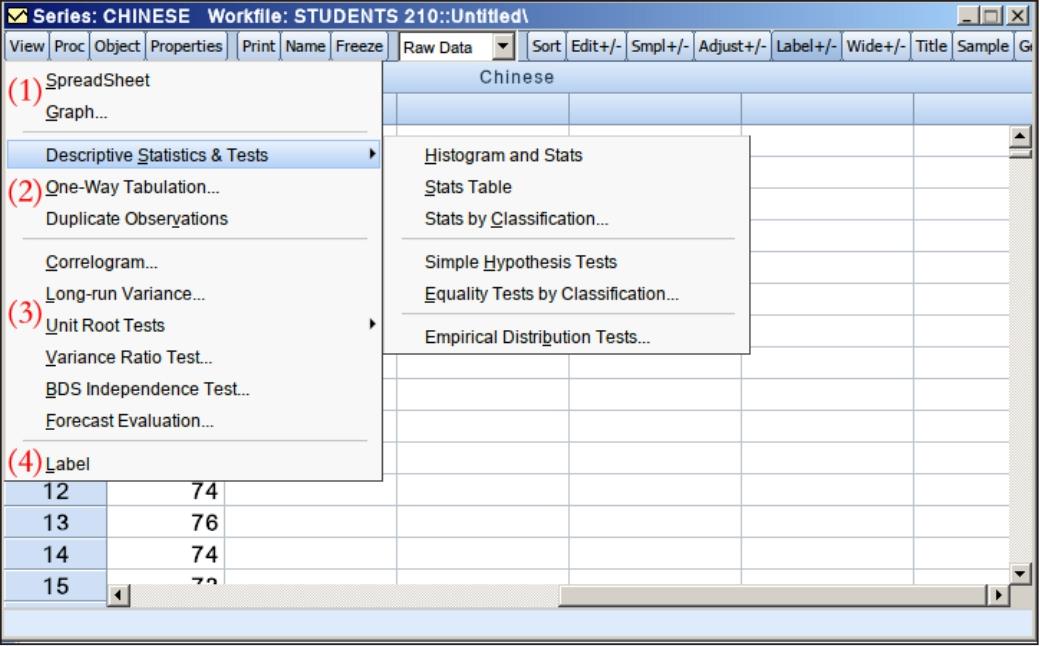
图6.6 序列的视图工具
(1)表单和图形
单击“SpreadSheet”,序列中的数据将以表单形式呈现,这也是Eviews默认的打开序列后的呈现形式。
单击“Graph...”,打开新建图形的对话框,可以对序列绘制线图、直方图、点图等。
(2)截面数据的描述性统计分析和检验
第二栏的工具主要适用于截面数据,包括直方图和描述性统计量(Histogram and Stats)、统计量表格(Stats Table)、分组统计量(Stats by Classification...)、单个总体参数的假设检验(Simple Hypothesis Tests)、多个总体参数是否相等的假设检验(Equality Tests by Classification...)、检验序列是否服从某种分布(Empirical Distribution Tests...)、频数分布表(One-Way Tabulation...)、重复观测值的检测(Duplicate Observations)。
关于上述工具的具体使用方法,详见第11章。此处主要是让读者快速了解Eviews对序列的视图工具设计了哪些功能。
(3)时间序列的检验和预测
第三栏的工具主要适用于时间数据,包括序列相关检验(Correlgoram...)、长期方差(Longrun Variance...)、单位根检验(Unit Root Tests...)、方差比检验(Variance Ratio Test...)、BDS独立性检验(BDS Independency Test...)、预测评估(Forecast Evaluation...)。
关于上述工具的具体使用方法,详见第21章。
(4)标签
单击“Label”,序列窗口显示如图6.7所示。“Name”是工作文件中序列对象的名称,“Display Name”是显示名称。显示名称(Display Name)主要用于图形和表格中的标题。序列的名称(Name)中不能有空格等特殊字符,但是显示名称则不受上述限制,能使图标标题更加完整。如图6.7所示,对“Chinese”序列设置显示名称后,绘制其直方图。
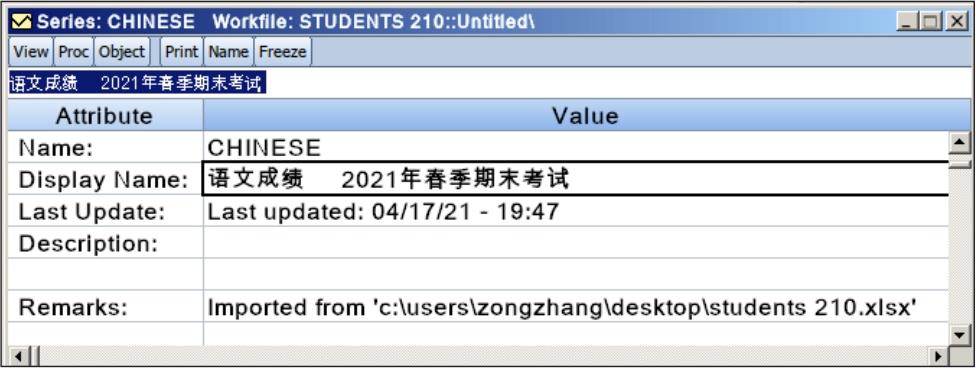
图6.7 序列的标签视图
图6.8(a)是“Chinese”序列的直方图,图形的标题是“Chinese”序列的显示名称,图6.8(b)是“Math”序列的直方图。因为没有对“Math”序列设置显示名称,所以直方图的标题就是序列的名称。
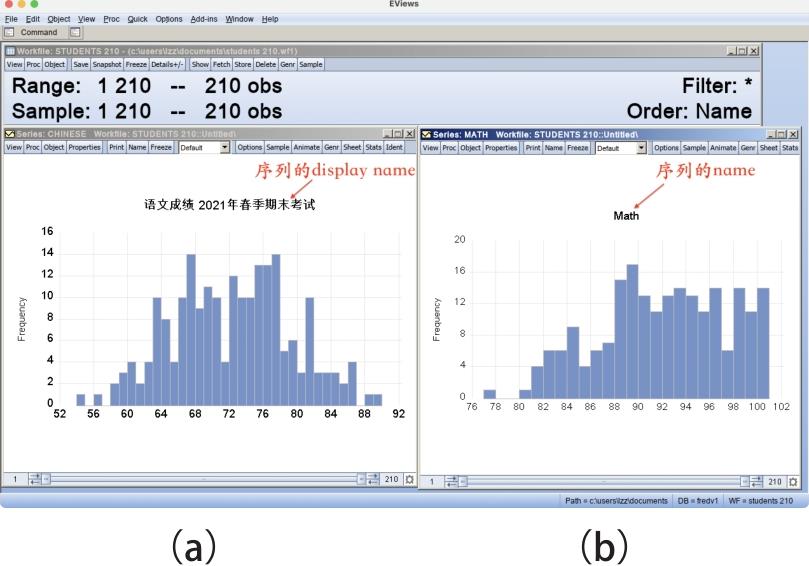
图6.8 序列的直方图
2)程序工具
单击序列窗口工具栏中的“Proc”按钮,下拉菜单列示中工具分为3栏,第一栏是创建序列的工具,包括通过方程创建(Generate by Equation)、通过分组创建序列(Generate by Classification)、再抽样(Resample...)和插值(Interpolate...)。第二栏是关于时间序列的分析模块。第三栏是可调用的插件。
本部分将介绍通过分组创建序列(Generate by Classification)功能,该功能可以将数值型的定量变量转换为顺序型的定性变量(见图6.9)。在研究中引入定性变量,能够进行更多元化的分析。
图6.9 序列的程序工具
打开“Chinese”序列,单击“Proc/Generate by Classification”按钮,打开“Series Classify”对话框,如图6.10所示。“Method”下拉列表框中有4种方法,即设置组距(Step Size)、组数(Number of Bins)、划分成几个等分组(Quantile Values)、各组分界点(Limit Values)。
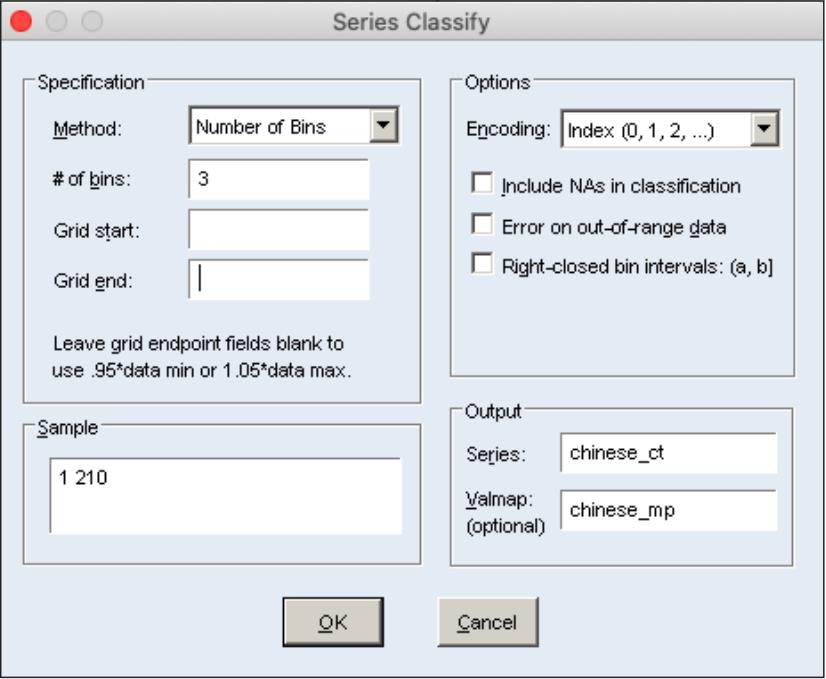
图6.10 “Series Classify”对话框
如图6.10所示,在“Method”下拉列表框中选择“Number of Bins”,设置组数(# of bins)为3,在“Encoding”下拉列表框中选择“Index (0,1,2,...)”,单击“OK”按钮。注意,“Output”组合框中相关参数的设置,表明将生成一个序列对象,名为“chinese_ct”,生成一个Valmap对象,名为“chinese_mp”。
图6.11所示的窗口并列显示了3个对象,左边是“Chinese”序列,中间是“chinese_ct”序列,右边是“chinese_mp”Valmap。Valmap反映了“chinese”序列和“chinese_ct”序列的对应关系。若某位同学的语文成绩落在最低的那个区间,那么该同学的“chinese_ct”值为1;若其语文成绩落在中间区间,则对应的“chinese_ct”值为2;若其语文成绩落在最大区间,则对应的“chinese_ct”值为3。语文成绩原本是一个定量变量,通过分组转换为一个顺序型的定性变量。
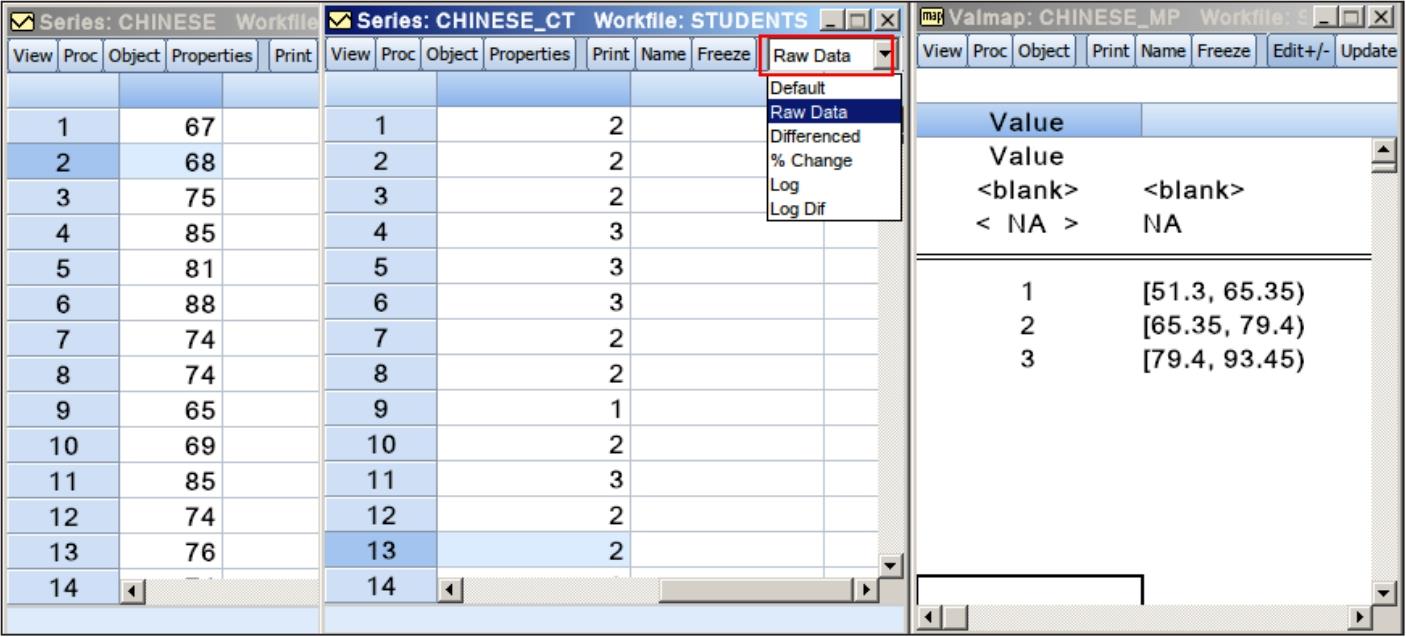
图6.11 序列窗口对象
注意,“chinese_ct”序列窗口中有一个下拉按钮,控制值的显示方式。若设置控制值的显示方式为“Raw Data”,则“chinese_ct”序列的值就会显示成1、2或3;若设置控制值的显示方式为“Default”,则“chinese_ct”序列的值会显示成该界面单元所在组的区间,即[51,3, 65.35]这种形式。
3)对象工具
单击“Object”按钮,可以对对象进行复制、删除、重命名等操作。
4)属性工具
单击“Properties”按钮,打开“Properties”对话框,如图6.12所示。在“Properties”对话框中选择“Display”选项卡,这里显示3个选项组,分别是序列的数值显示(Numeric display)、列宽(Column width)和对齐方式(Justification)。
在“Numerical display”选项组中单击“Data displayed as:”下拉按钮,打开的下拉列表中有水平(Level)、百分比变化(% change)、自然对数(Logarithm)3个选项,选择“Logarithm”,单击下方的下拉按钮,在打开的下拉列表中选择“Fixed decimal”,在“Decimal places”文本框中输入“3”,单击“OK”按钮,打开图6.13所示的窗口。此时,“Chinese”序列窗口显示的是其取自然对数后的值,保留3位小数。
“Properties”对话框中的“Value Map”选项卡可以用于给数值型代码添加文本标签,关于“Value Map”选项卡的介绍详见6.4节。
“Properties”对话框中的其他选项卡还可以设置字体颜色、单元格颜色,设置界面简洁明了,在此不一一赘述。
5)打印工具
单击“Print”按钮,打开“Print”对话框,如图6.14所示,可以设置打印机输出或者输出为RTF文件。
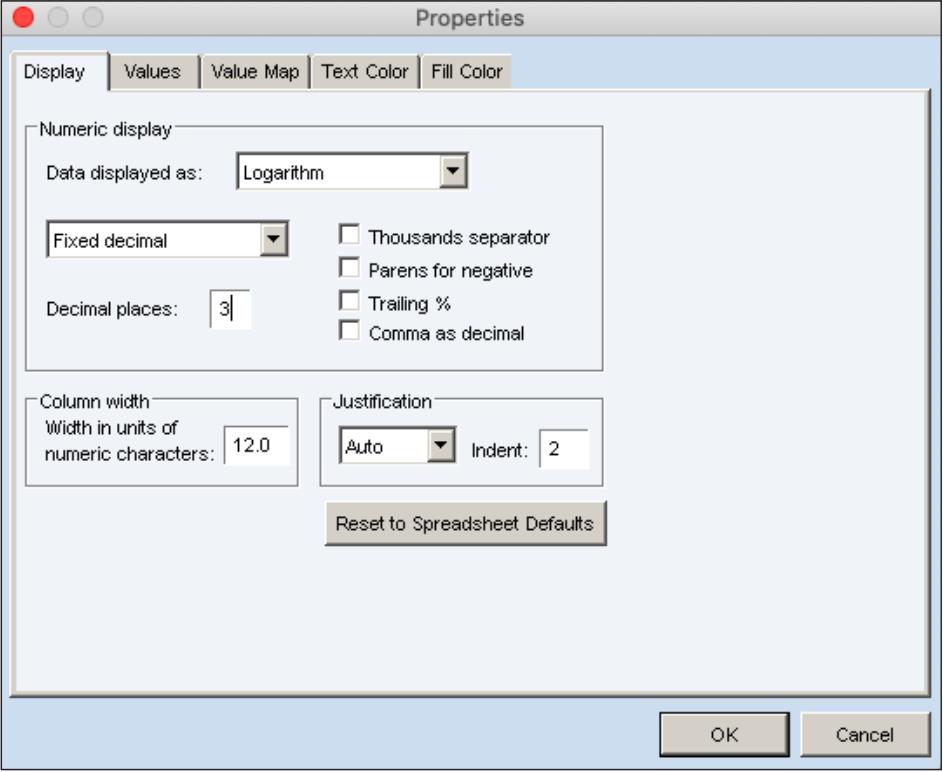
图6.12 “Properties”对话框
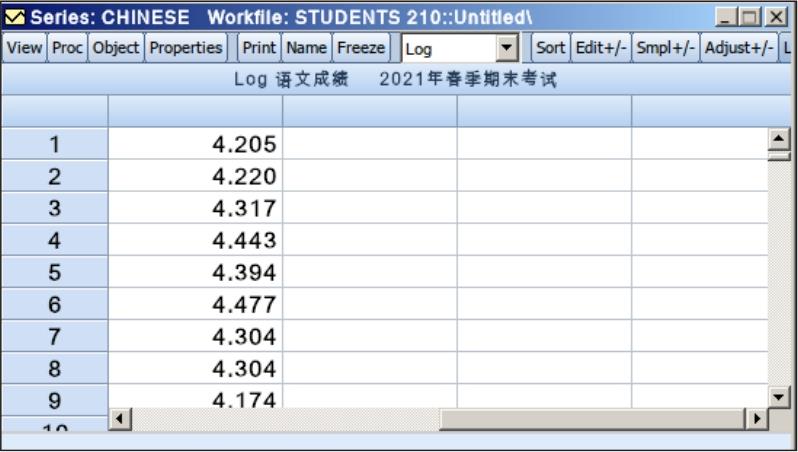
图6.13 “Chinese”序列窗口
图6.14 “Print”对话框
6)命名工具
单击“Name”按钮,可以对对象进行命名或重命名。
7)冻结工具
单击“Freeze”按钮,可以把对象的视图保存为表格或图形。关于冻结工具的功能,详见5.4节。
8)排序工具
单击“Sort”按钮,打开“Sort Order”对话框,可以对对象进行排序设置,可以设置排序字段、升序或降序,默认按观测单元的编号(Observation Order)升序排列,也可以按序列的数值大小排序,如图6.15所示。
9)切换编辑模式工具
单击“Edit+/-”按钮,可以切换到编辑模式,修改序列中的数值。
10)切换样本工具
单击“Smpl+/-”按钮,序列窗口中的数据将在子样本和全样本之间切换。
如图6.16所示,在工作文件窗口将“Sample”设置为4班的同学,序列窗口将只显示4班的54位同学的语文成绩。单击序列窗口的“Smpl+/-”按钮,序列窗口将显示工作文件中210位同学的语文成绩,再次单击“Smpl+/-”按钮,序列窗口又将切换到54位同学的语文成绩。
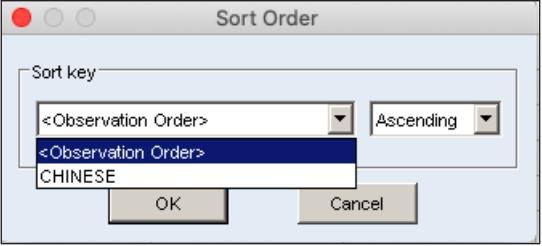
图6.15 “Sort Order”对话框
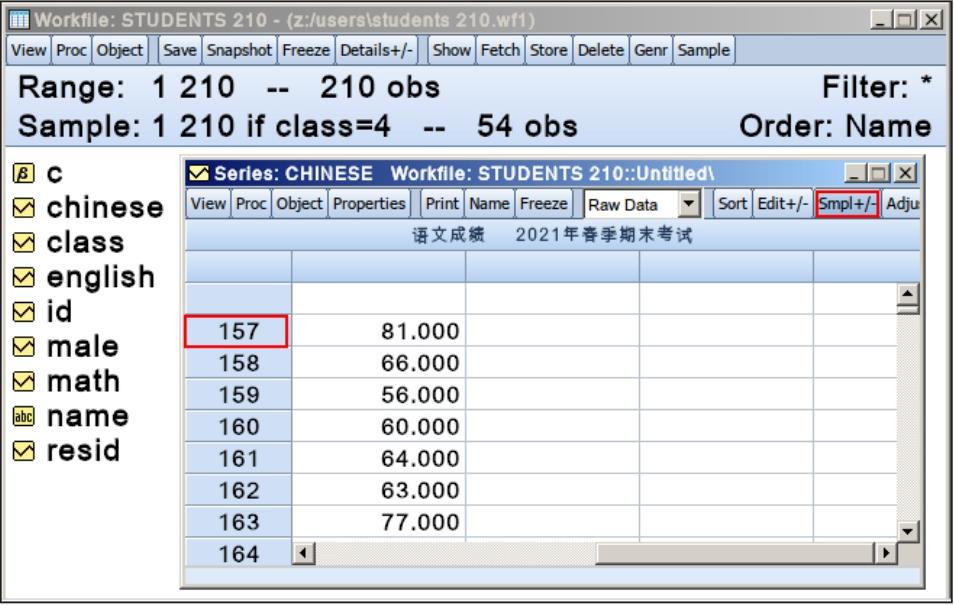
图6.16 序列窗口
11)切换调整模式工具
单击“Adjust+/-”按钮,序列窗口进入调整模式,可以对序列中的监测值进行调整。
(1)单个调整。如图6.17所示,单击“CHINESE”下方第5行单元格,输入“90”,“Delta”显示的是调整后的值与未调整的值(Unadjusted)的差,“Delta%”显示的是调整的百分比。未经调整的值是白色底色,调整过的值以红色显示。
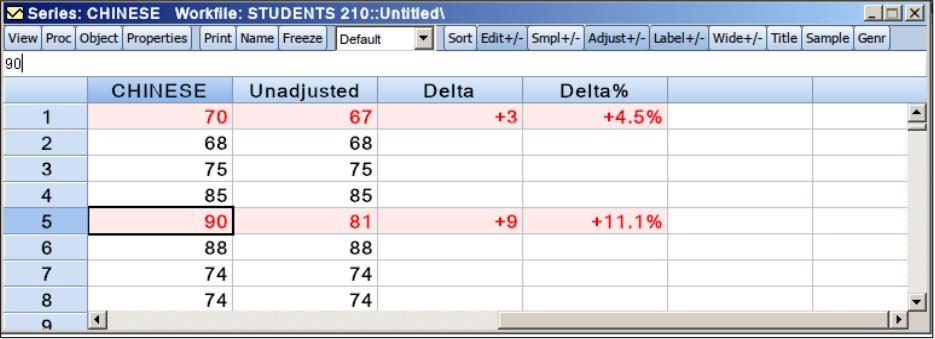
图6.17 单个调整
在“Delta”或“Delta%”下方输入调整幅度,或者调整百分比,序列中的值也随之变换。
(2)批量调整。如图6.18所示,单击列标题“Delta”,选中“Delta”整列,然后在输入栏中输入“=5”,则所有同学的语文成绩都将加5。若选中“Delta%”整列,然后在输入栏中输入“=10”,则所有同学的语文成绩都将提高10%。
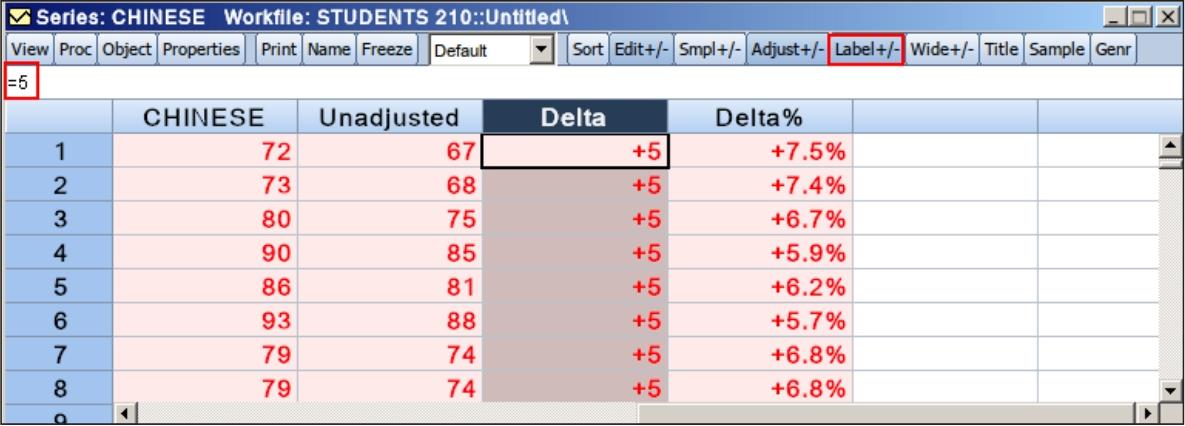
图6.18 批量调整
再次单击“Adjust+/按钮”按钮,将退出调整模式,此时会打开信息提示对话框,提示“序列已经被修改,是否保存修改?”。若选择保存,则调整的数据将被保存到序列中。
切换调整模式工具提供了一个可视化的窗口,可以设置调整的幅度或百分比,实现对观测值的逐个或批量调整。
12)切换标签显示工具
单击“Label+/-”按钮,可控制序列窗口是否显示标签信息。如图6.19所示,上方窗口显示了“English”序列的标签信息,下方窗口没有显示“Math”序列的标签信息。
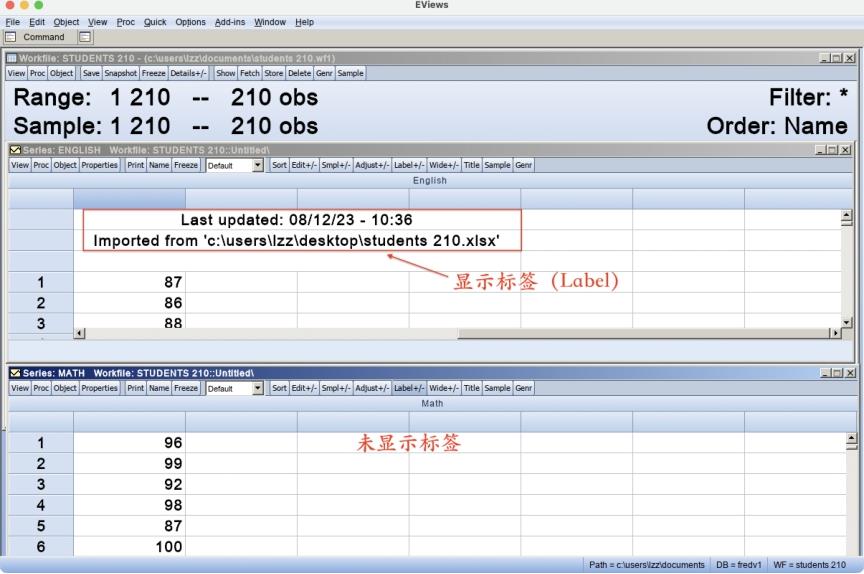
图6.19 序列窗口
13)切换宽窄显示工具
单击“Wide+/-”按钮,序列窗口在宽窄两种方式之间切换。如图6.20所示,在上方窗口中,序列显示在1列中,即窄型显示,这是序列在表单中默认的显示形式;在下方窗口中,序列显示在5列中,即宽型显示。当数据容量较大时,采用宽型形式显示数据,能快速浏览数据全貌。
14)标题工具
单击“Title”按钮,打开“Table Title”对话框,输入标题,单击“OK”按钮,则序列窗口工具栏的下面将显示设置的表格标题,如图6.21所示。
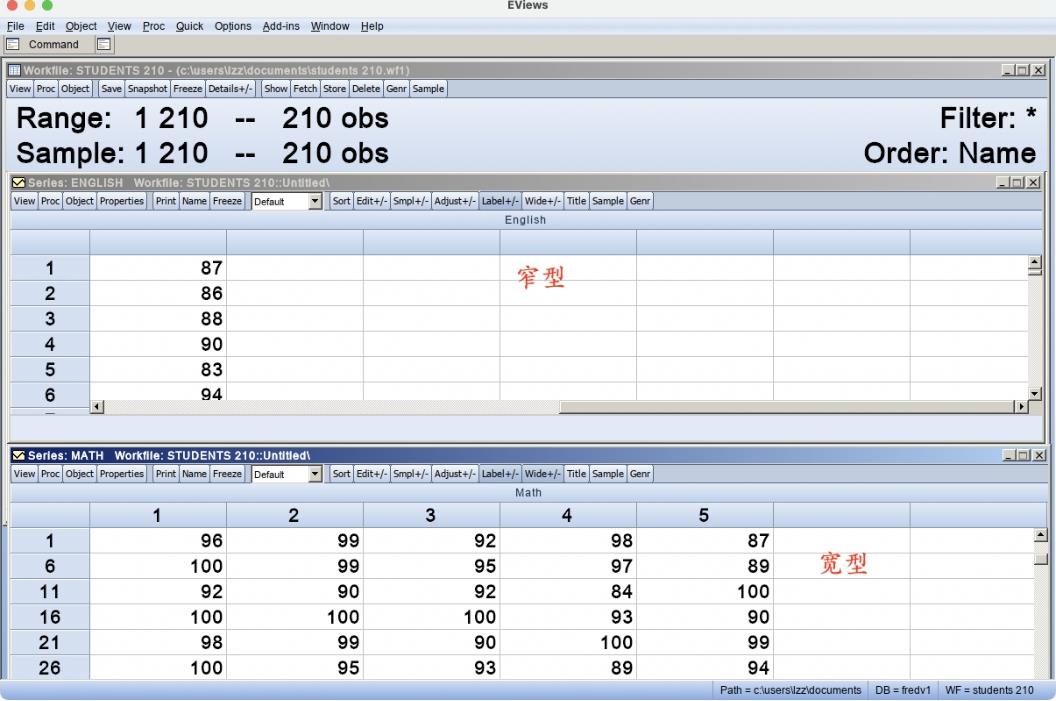
图6.20 序列窗口的显示形式
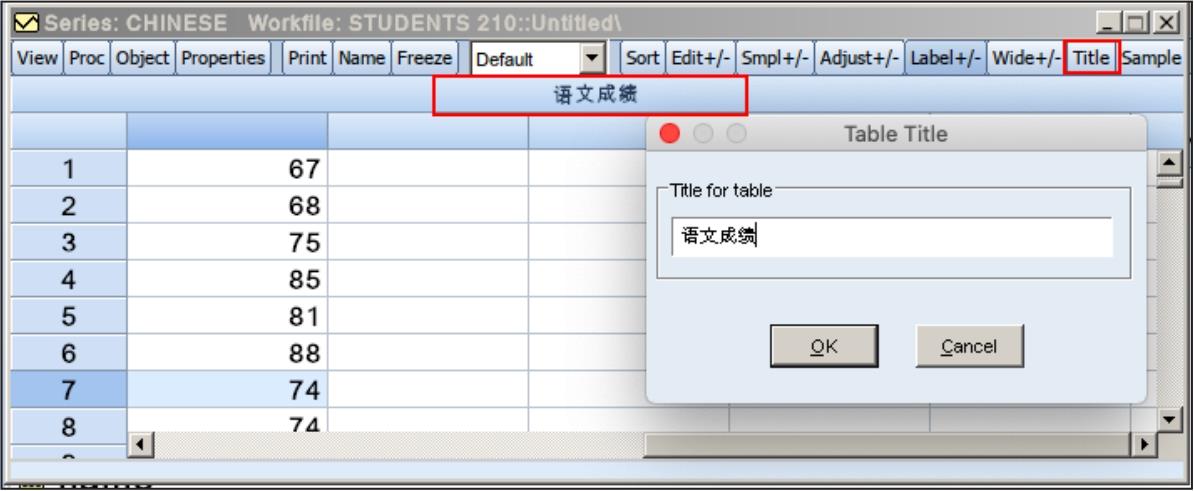
图6.21 设置表格标题
15)样本工具
单击“Sample”按钮,可以设置样本的筛选条件。关于样本筛选条件的设置方法,详见8.1节。
16)创建新序列工具
单击“Genr”按钮,可以在打开的对话框中输入数学表达式以创建新序列,详见6.2节,这里不再赘述。
双击序列窗口的底部,打开“Series Info”对话框,勾选需要显示的统计量(最多选6项),然后单击“OK”按钮,如图6.22所示。
如图6.23所示,在序列窗口中,单击观测值所在的列标题栏,选中整列,此时序列窗口下方的状态栏显示该列观测值的均值、中位数、最大值、最小值、标准差和观测值的个数。如果只选中5个单元,那状态栏将显示这5个观测值的上述统计量的结果。
实时统计量工具虽然没有设置在工具栏中,但是其使用简便,且能实时报告观测值的描述性统计量的信息,是非常有用的工具。
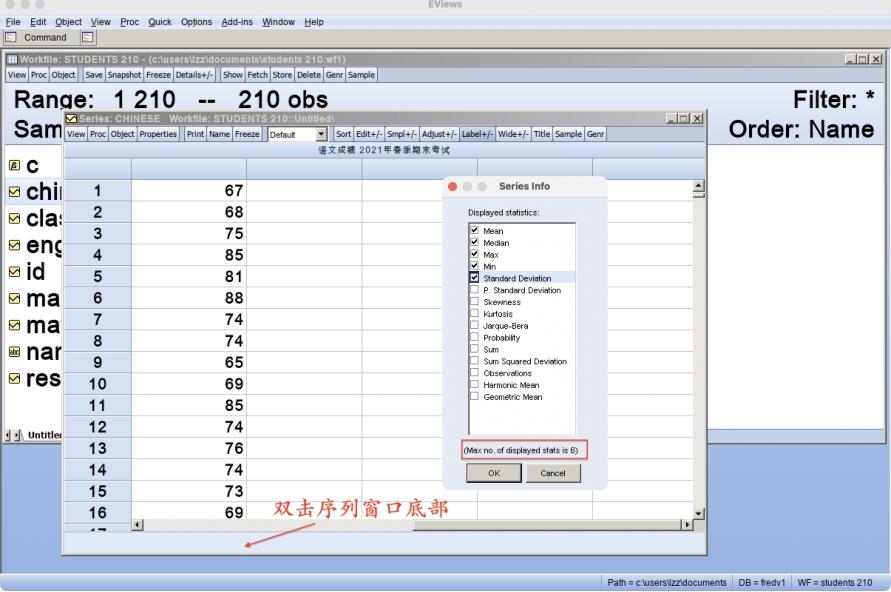
图6.22 选择实时统计量
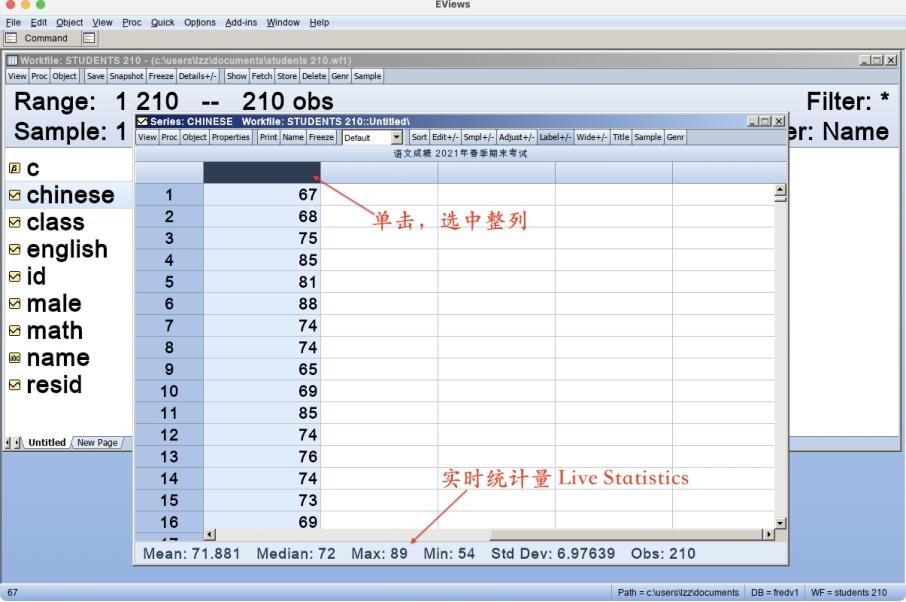
图6.23 实时统计量
此外,单击Eviews主菜单“Options/General Options...”,打开图6.24所示“General Options”对话框,选择“Live statistics”,然后勾选需要显示的统计量,单击“OK”按钮。该设置对工作文件中的所有序列都有效。打开任何一个序列,其窗口的状态栏都会显示勾选的统计量的值。
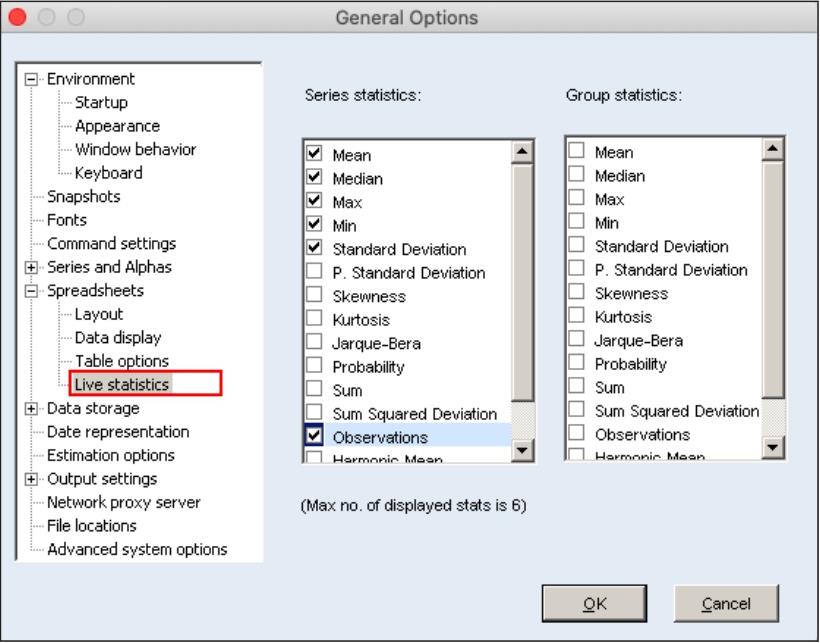
图6.24 “General Options”对话框
Valmap存储的是数值代码与数值的映射关系。在6.3节中,利用“Proc/Generated by Classification...”将数值型定量变量转换为顺序型定性变量这一过程中就生成了Valmap。
本节将介绍如何为数值代码创建Valmap,让数值代码所代表的信息能在分析结果中显示出来。
沿用6.3节中的例子,将数据文件“students 210.xlsx”导入Eviews,创建工作文件。性别(Male)序列中的观测值是数值代码,1代表男生,0代表女生。
打开“Male”序列,单击“View/One-way Table...”,打开图6.25所示的窗口,表中是“Male”序列的频数分布表,“Value”一列是“Male”序列的数值代码0和1。若“Value”一列能显示数值代码的含义“女生”和“男生”,则表格信息会更加直观。
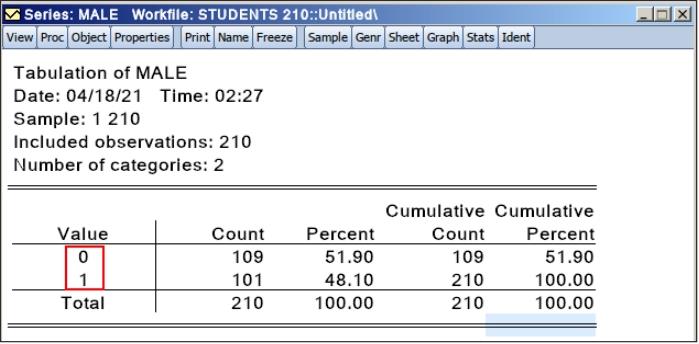
图6.25 “Male”序列的频数分布表
图6.26是按“Male”序列分组后绘制的“Math”序列的箱线图。分类轴显示的是“Male”的数值代码,若要让分类轴显示成“女生”和“男生”,需要创建Valmap,建立数值代码与代码标签的映射关系。
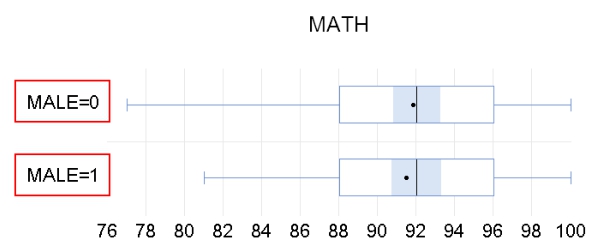
图6.26 “Math”序列的箱线图
单击主菜单“Object/New object...”,选择序列类型为“Valmap”,打开图6.27所示的窗口,在箭头所指处输入数值代码和代码标签,单击“Name”按钮,将其命名为“Male_map”,最后单击“Update”按钮,使映射关系生效。
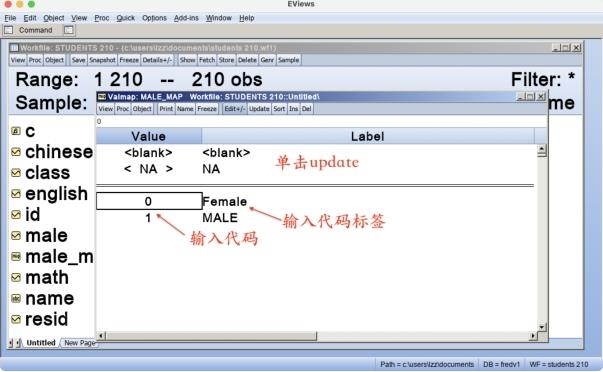
图6.27 建立映射关系
然后打开“Male”序列,单击“Properties”按钮,打开“Properties”对话框,如图6.28所示。选择“Value Map”选项卡,在“ValMap name”文本框中输入“male_map”,单击“OK”按钮。
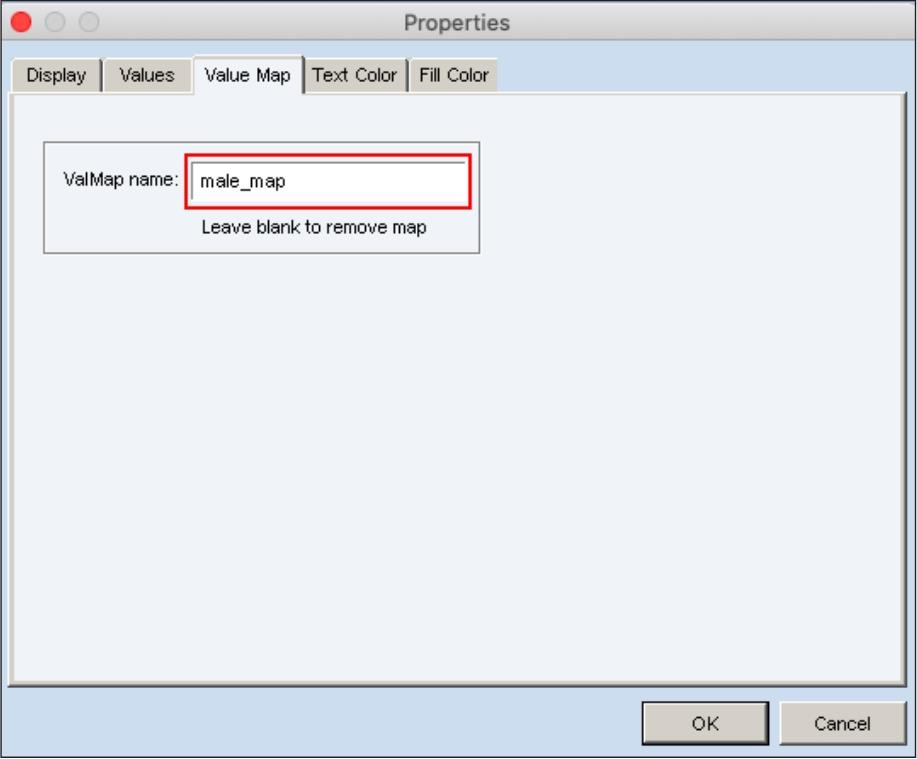
图6.28 “Properties”对话框
重新查看“Male”序列的频数分布表,表中“Value”一列显示的是“FEMALE”和“MALE”,如图6.29所示。
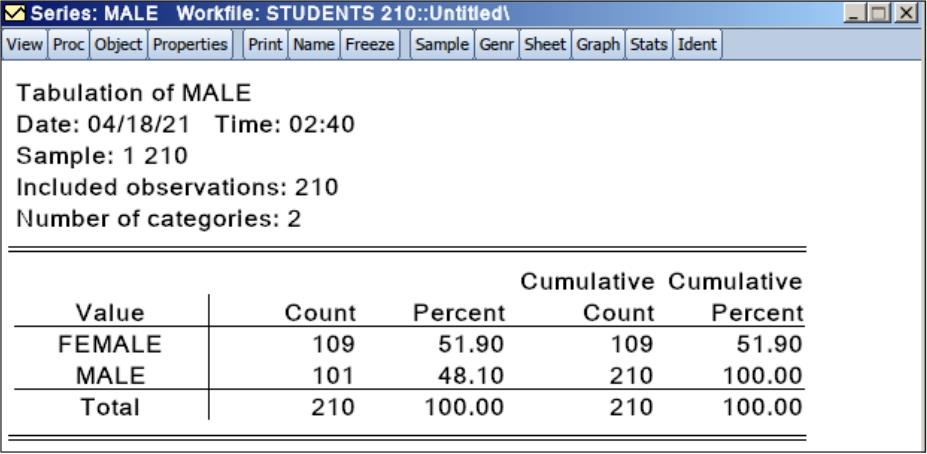
图6.29 “Male”序列的频数分布表
绘制根据“MALE”序列分组的“Math”序列的箱线图,分类轴也显示为“FEMALE”和“MALE”,达到了显示代码含义的效果,如图6.30所示。
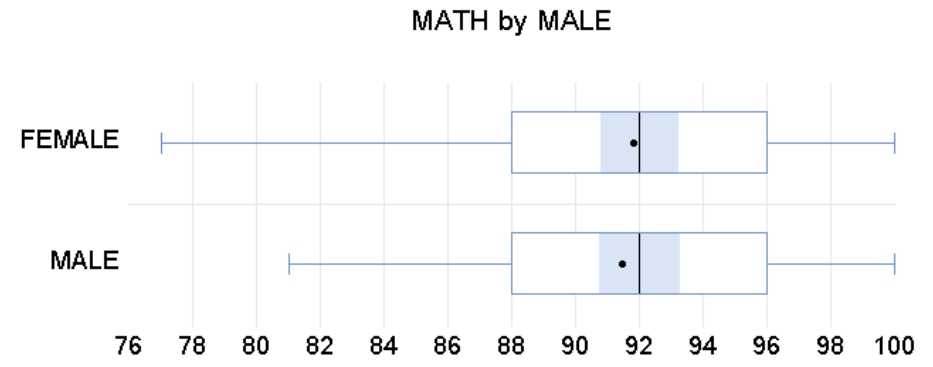
图6.30 “Male”序列的箱线图
本章介绍的关于序列操作的工具看似繁杂,或许会让初学者感到眼花缭乱,甚至产生怀疑:这么多工具,我能学会吗?初学者大可打消此类顾虑。初学者不需要立即掌握每一个关于序列操作的工具。本章的介绍可让初学者管中窥豹,了解Eviews以对象为导向的开发理念,领略Eviews的强大功能,感受Eviews的简洁设计。用户通过单击按钮或者菜单,就能实现想做的分析。
用户可以在实践中慢慢去体验和熟悉这些工具。当打开一个序列后,用户可多单击工具栏中的按钮,尝试不同的设置,在实践中积累经验,逐渐达到熟练。
序列是Eviews工作软件中最重要的对象类型。学习了序列窗口的工具,其他类型的对象(如组、表格、图形窗口的工具)也有相通之处,用户可以举一反三,触类旁通。
· 序列窗口下的“View”工具集成了对单个序列作图、报告描述性统计量、参数检验、时间序列的平稳性检验、自相关诊断等一系列功能。
· 双击序列窗口的底部,打开“Series Info”对话框,勾选需要显示的统计量(通过主菜单“Options/General Options...”下也可实现此设置),则序列窗口下方的状态栏会实时显示序列的描述性统计量。
· 单击序列窗口的“Proc/Generate by Classification”,可将定量变量转换为顺序型的定性变量。在研究中引入定性变量后,可以使用更丰富的研究工具。
· 创建Valmap,在数值代码与代码标签之间建立映射关系,单击“Update”按钮,该映射关系才生效。