
下载掌阅APP,畅读海量书库
立即打开



收集到的问卷资料还要整理、分类及统计运算,把庞大的、复杂的、零散的资料集中简化,使资料变得易于理解和解释。简言之,资料整理就是将问卷资料转变成数据结果,以便于研究者了解、揭示其中的含义。

资料采集后,所有资料都要汇总,以便统计处理。为避免信息损失,评价访问员的工作成绩,负责人要对资料进行登记分类,如按地区、访问员等分类,分别记录各地区、各访问员交回的问卷数量、交付时间、实发问卷数量、丢失问卷数等情况。
编码是把原始资料转化为符号或数字的资料简化过程。通过编码,资料输入计算机进行统计就简单多了。所以,编码通常是不可忽略的程序,合理、正确的编码将极大方便统计计算和结果解释。编码包括下列方面的工作。
(一)规定变量名称
市场调查问卷通常包含若干问题(变量),为方便统计处理,数据输入计算机前必须先给每个问题或变量起一个变量名称。变量名称一般是英文字母与阿拉伯数字的组合,如S、Age、X 1 、Y 2 ,等等。
定义变量名要把个人基本情况与其他问题区分开,受调查者的个人基本情况如年龄、性别、文化程度、职业等,这些变量通常可以直接用英文单词、英文的第一个字母或前几个字母来命名。例如,性别可规定为“ Sex”,年龄规定为“Age”,文化程度定义为“Edu”等,也可以用汉语拼音字母等方法来命名,命名由研究者或编码者决定。
其他问题的题目数量通常比较多,常用“X 1 、X 2 ……X n ”或“Y 1 、Y 2 ……Y n ”等字母与数字系列组合方式来表示,也可以按问题的含义来定义。
(二)规定各量表值
量表值依据数据的类型可以用字符串表示,也可以用数字表示,一般用数字来表示比较方便。
问题:您的性别
答案:A.男 B.女
可把“男”规定为 1,“女”规定为“0”或“2”。
问题:您对芳草牙膏的喜欢程度
答案:A.非常喜欢 B.比较不喜欢 C.难以确定 D.比较喜欢 E.非常喜欢
这个量表中,可以直接依答案顺序分别规定为 1、2、3、4、5,最好按递增程度排序,若颠倒过来排序对结果的理解而言,增加了难度。
定义量表值时,还应当注意有些受调查者不按问卷设计要求作答,如多选或漏选,如果是个人基本项目出现这种情况,那么该问卷就是无效问卷,不纳入统计处理。如果是个别其他问题出现多选或漏选现象,则要另加一个或两个量表值,把它们归为一类或两类,以例 2 来说,可将“漏选”和“多选”分别规定为“7”或“0”。
在规定变量名称和量表值时,还要注意以下几种情况。
1.非问卷题目的有关问题
大规模调查中,通常包含许多地区,统计时需要分析不同调查地区的差别,地区本身就是一个变量,命名规定量表值时要考虑它。例如,分别在北京、上海、广州和成都四个地区开展调查,可以将该变量命名为“Seg”,将北京规定为“1”、上海为“2”、广州为“3”、成都为“4”,没有注明或不知为哪个地区的规定为“9”。
2.多选题
对于单选题来说,每个问题就是一个变量,一个问题有n个答案,就有n + 1个量表值。而对于多选题来说,情况就复杂一些,下面我们用一个例子来说明。
例:您是通过哪些渠道知道× ×品牌的?
A.电视广告 B.报纸广告 C.杂志广告
D.广播广告 E.户外广告 F.听别人介绍
G.在商店看到 H.其他____
对于这样一个问题的编码,就要将 8 个答案变成 8 个变量,然后依照顺序分别命名,如分别规定为“X 9a 、X 9b 、X 9c 、X 9d 、X 9e 、X 9f 、X 9g 和X 9h ”。而每个变量的量表值则根据是否被选择作规定,如选择规定“1”,没选择规定为“2 或 0”。如果研究者还需要了解作答者选择答案数量的分布情况,还需要增加一个变量,如命名为“X 9 ”,量表值则根据作答者的答案选择数量作规定,如选择 1 个答案规定为“1”,2 个答案为“2”,……
3.开放性问题
有些开放性问题在统计处理时只想了解究竟有多少人作答,这时的编码就比较简单,只要给每一个题目相应地起一个名称,然后用“1”表示“作答”,用“0”表示“未作答”即可。但是如果要对答案进行量化分析,那么编码工作就比较复杂一点。编码员首先要将多数作答者的答案浏览一遍,列出各种可能答案,根据答案是单选或多选,规定变量名称和量表值,然后将每一位作答者的答案进行分类。例如对于“您为什么喜欢瓶装植物油而不喜欢散装植物油?”这样一个开放题,答案可以分类为:卫生、质量、购买方便……,变量名称为:X h1 、X h2 、X h3 ……,每一个变量的量表值为“1”时表示答案“涉及”该方面内容,“0”表示答案“未涉及”该方面内容。
当所有变量和量表值都规定清楚之后,编码人员要编写一本编码簿,说明各英文字母、数码的意思。因为在市场调查研究中,通常都有大量变量和数据资料。这些资料一旦输入电脑时,只有编码人员知道各变量名称以及数码的意义。不制作手册,很可能遗忘,其他人也不得而知。
编写一本编码簿,用以说明各种符号、数码的意义,具有三种功能:
(1)录入人员可根据编码簿说明来录入数据。
(2)研究者人员或电脑程序员根据编码簿编拟统计分析程序。
(3)研究者阅读统计分析结果时,不清楚各种代码的意义时,可以从编码簿中查询。
在大多数较为复杂的市场调研中,编写编码簿是一项必要的程序。但是在编写编码簿时,各项说明要尽量详尽。
编码簿通常包含有六个主要项目,即变量序号、变量含义、相应问卷题号、变量名称、是否跳答、数据宽度、数据说明。
变量序号是给各变量的数码,表示各变量在数据库中的输入顺序;变量含义,即问卷中问题意思的概括,使研究者或程序设计师很快得知这一变量的意思;相应问卷题号指变量属于问卷中的第几题,便于查寻原来的题意;变量名称是变量的代号,代号便于计算机识别和统计操作,列入编码簿可使研究者便于从代号查寻其含义;数据宽度包括该变量的数据最多是几位数及小数点之后有几位数;数据说明是对各数码代表受访者的何种反应的说明。
有了编码簿,储存于计算机中的资料,其含义就一清二楚。录入之后的问卷材料就可以束之高阁。在目前常用的SPSS统计软件中,编码簿的主要内容可以输入文件之中,以便直接在统计结果中体现出来。
为了深入研究总体的特征,揭示总体中的矛盾,要进行统计分组,根据广告研究的目的,按照一定的标志,将统计总体区分为若干个组成部分。这些若干部分中的每一个部分就叫作一个“分组”。例如,研究某一地区人口状况对广告效果的影响时,可按年龄这一标志将人口区分为不同年龄组,各组的年龄不同,每个组中人口所表现的年龄特征相同。统计分组的根本任务就是区分事物之间存在着的质的差异,通过分组,把总体中各个不同性质的单位区分开,把性质相同的单位归在一个组内。这样才能从数量方面剖析该变量对广告的影响,揭示变量内部的联系,深入研究总体的特征,认识变量的本质及规律性。
统计分组是基本统计方法之一,经常使用。广告调查方案必须对统计分组做出具体规定,才能搜集到能够满足分组需要的资料。资料整理的任务是使零散资料系统化,但怎样使资料系统化,本着什么去归类,这就取决于统计分组。因此,在取得完整、正确的统计资料前提下,统计分组决定整个广告研究成败的关键,直接关系广告分析的质量。
目前,统计工作中常用的分组如按生产资料所有制性质分组、按国民经济行业分组、按单位隶属关系分组、按地区分组、三次产业划分、企业按大中小型划分、职业分类等,其中重要的分组都有全国统一的分类标准。
统计分组根据分组标志的性质,分为按品质标志分组和按数量标志分组。品质标志说明事物的性质或属性特征,反映总体单位在性质上的差异,不能用数值来表现;数量标志直接反映事物的数量特征,反映事物在数量上的差异,如人口的年龄、企业的产值等。统计分组方法就是指这两种标志的具体分组方法。
(一)按品质标志分组
品质标志分组一般较简单,分组标志一旦确定,组数、组名、组与组之间的界限也就确定。有些复杂的品质标志分组可根据统一规定的划分标准和分类目录进行。
(二)按数量标志分组
按数量标志分组的目的并不是单纯确定各组在数量上的差别,而是要通过数量上的变化来区分各组的不同类型和性质。数量标志分组方法从以下几个方面来说明。
1.单项式分组和组距式分组
对离散变量,如果变量值的变动幅度小,就可以一个变量值对应一组,称单项式分组。如居民家庭按儿童数或人口数分组,均可采用单项式分组。
离散变量如果变量值的变动幅度很大,变量值的个数很多,则把整个变量值依次划分为几个区间,各个变量值则按其大小确定所归并的区间,区间的距离称为组距,这样的分组称为组距式分组。一般组距式分组组数以 5—7 组为宜,最多不超过 10 组,组间距最好为整数。
也就是说,离散变量根据情况既可用单项式分组,也可用组距式分组。在组距式分组中,相邻组既可以有确定的上下限,也可将相邻组的组限重叠。
连续变量由于不能一一列举其变量值,只能采用组距式的分组方式,且相邻的组限必须重叠。如以总产值、商品销售额、劳动生产率、工资等为标志进行分组,就只能是相邻组限重叠的组距式分组。
在相邻组组限重叠的组距式分组中,若某单位的标志值正好等于相邻两组的上下限的数值时,一般把此值归并到作为下限的那一组(适用于连续变量和离散变量)。
组距式分组会损害资料的真实性。组距式分组的假定条件是:变量在各组内的分布都是均匀的(即各组标志值呈线性变化)。
通过组距式分组,抽象出各组内部各单位的次要差异,突出各组之间的主要差异,这样各组分配的规律就容易把握。根据这个道理,如组距太小、分组过细,容易将属于同类的单位划分到不同的组,因而显示不出现象类型的特点;但如果组距太大,组数太少,会把不同性质的单位归并到同一组中,失去区分事物的界限,达不到正确反映客观事实的目的。因此,组距的大小、组数的确定应根据研究对象的经济内容和标志值的分散程度等因素,不可强求一致。
2.等距分组和不等距分组
等距分组是各组保持相等的组距,也就是说各组标志值的变动都限于相同的范围。不等距分组即各组组距不相等的分组。
统计分组时采用等距分组还是不等距分组,取决于研究对象的性质特点。在标志值变动比较均匀的情况下宜采用等距分组。等距分组便于各组单位数和标志值直接比较,也便于计算各项综合指标。在标志值变动很不均匀的情况下宜采用不等距分组。不等距分组有时更能说明现象的本质特征。
3.组限和组中值
组距两端的数值称组限。其中,每组的起点数值称为下限,每组的终点数值称为上限。上限和下限的差称组距,表示各组标志值变动的范围。
组中值是上下限之间的中点数值,以代表各组标志值的一般水平。组中值并不是各组标志值的平均数,各组标志数的平均数在统计分组后很难计算出来,就常以组中值近似代替。组中值仅存在于组距式分组数列中,单项式分组中不存在组中值。
组中值的计算是有假定条件的,即假定各组标志值的变化是均匀的(与组距式分组的假定条件相同)。一般情况下,组中值= (上限+下限)÷ 2。
对于第一组是“多少以下”,最后一组是“多少以上”的开口组,组中值的计算可参照邻组的组距来决定。即:缺下限开口组组中值=上限-1 /2 邻组组距,缺上限开口组组中值=下限+ 1 /2 邻组组距。
4.分类变量、连续变量和离散变量
分类变量的变量值是定性的,表现为互不相容的类别或属性。分类变量可分为无序变量和有序变量两类。
(1)无序分类变量指所分类别或属性之间无程度和顺序的差别。它又可分为:二项分类,如性别(男、女),广告反应(正面、负面)等;多项分类,如职业(教师、公务员、商人、学生、农民),品牌选择(飘柔、海飞丝、潘婷、百年润发)等。
对于无序分类变量的分析,应先按类别分组,清点各组的观察单位数,编制分类变量的频数表,所得资料为无序分类资料,亦称计数资料。
(2)有序分类变量。各类别之间有程度的差别。如喜欢程度按非常喜欢、比较喜欢、难以确定、比较不喜欢、非常不喜欢分类。对于有序分类变量,应先按等级顺序分组,清点各组的观察单位个数,编制有序变量(各等级)的频数表,所得资料称为等级资料。
变量取值只能取离散型的自然数,就是离散变量,比如,一次掷 20 个硬币,k个硬币正面朝上,k是随机变量,k的取值只能是自然数 0、1、2……20,而不能取小数 3.5、无理数
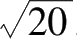 ,因而k是离散变量。
,因而k是离散变量。
如果变量可以在某个区间内取任一实数,即变量的取值可以是连续的,这随机变量就称为连续变量。比如,公共汽车每 15 分钟一班,某人在站台等车时间x是个随机变量,x的取值范围是[0,15),它是一个区间,从理论上说在这个区间内可取任一实数 3.5、
等,因而称这随机变量是连续型随机变量。连续变量的数值是连续不断的,相邻两值之间可作无限分割,即可取无限数值。例如,人的身高、体重、粮食亩产、零件误差的大小等,它们的计量单位可以取小数点以后的任意一个位数,而且必须用测量或计量的方法取得其值。
变量类型不是一成不变的,根据研究目的的需要,各类变量之间可以进行转化。
(三)SPSS中实现过程
选择“Transform”菜单的Compute项,打开如图所示的“Compute Variable” (计算变量)对话框,如图 2-2 所示。
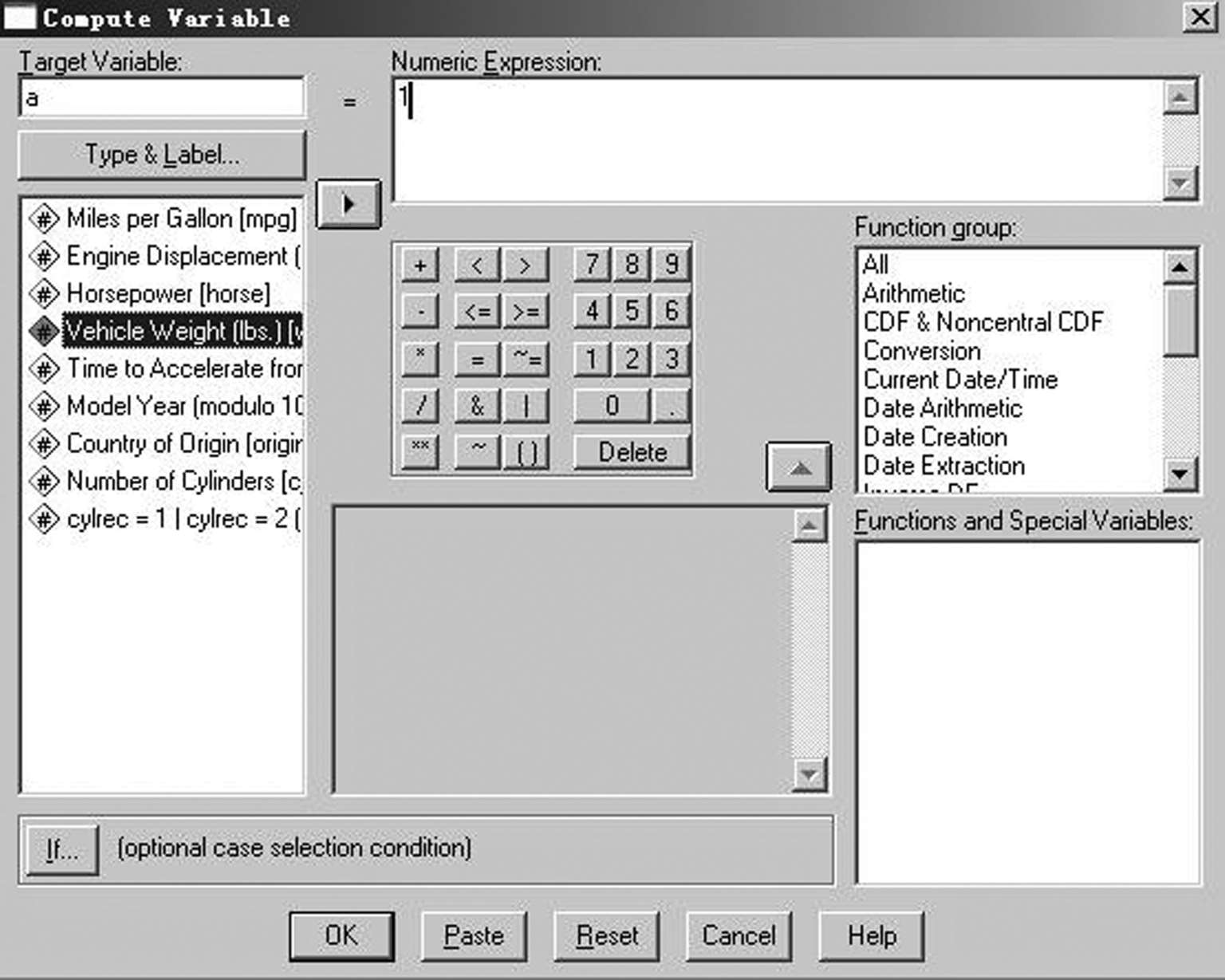
图2-2 “Compute Variable”(计算变量)对话框
在该对话框中的“Target Variable”(目标变量)框中输入符合变量命名规则的变量名,如a。目标变量可以是现存变量或新变量。
“Numeric Expression”(数值表达式)框用于输入计算目标变量值的表达式。分组时,第一次操作输入“1”,表明a = 1,计算器板下面有个“If”按钮,单击该按钮打开条件表达式对话框,如图 2-3 所示。在条件表达式对话框中指定一个逻辑表达式。在该图中,只对满足“[weight > 0]&[weight < = 2000]”(汽车重量在 0 和2000 之间,不包括 0 但包括 2000)条件的样本进行计算,符合该条件的赋值为a =1,依次类推该操作根据需要进行分组,最后新产生的变量a为分类变量。
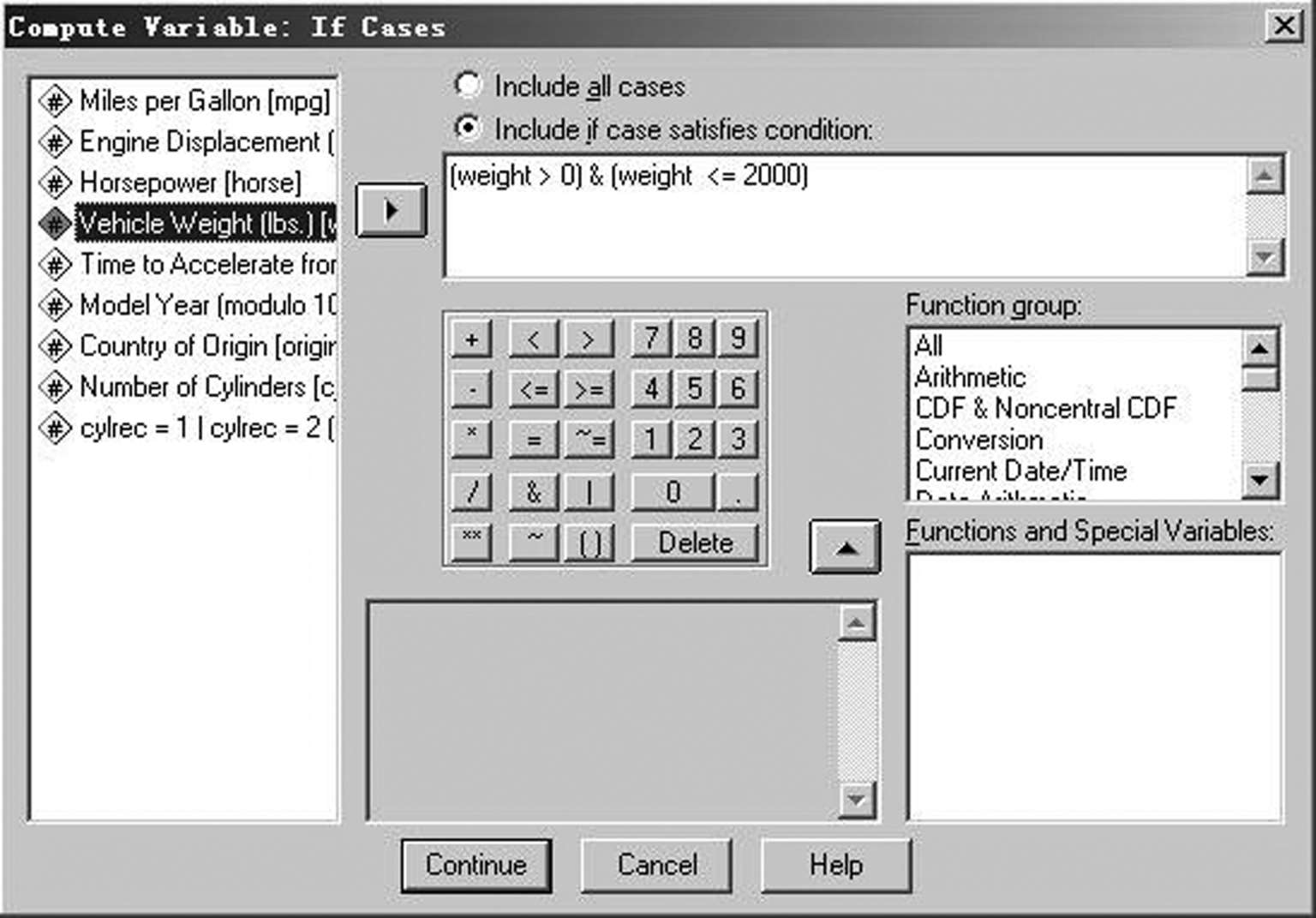
图2-3 条件表达式对话框