
下载掌阅APP,畅读海量书库
立即打开



变量分箱是一种数据预处理手段,主要是对数值型变量进行离散化操作。若要进行分箱的是离散型变量,则可先用变量不同取值对应的Badrate将离散型变量转换为数值型变量,再执行分箱操作。变量的分箱方法主要包括有监督分箱和无监督分箱,有监督分箱需要结合目标字段一起进行,分箱速度较慢;无监督分箱不需要目标字段就能进行,分箱速度较快。常见的有监督分箱方法有卡方分箱、决策树分箱、Best-KS分箱等,常见的无监督分箱方法有等频分箱和等宽分箱等。虽然上述分箱方法都比较成熟,但都不是适用于单维度策略测算场景的最优分箱方法。
本节介绍一种基于业务经验设计的适用于单维度策略测算场景的最优分箱方法,该分箱方法属于无监督分箱范畴。在大多数情况下,单维度规则的最终结果形态往往是变量取值在某个切分点之上或之下,且单条规则的拒绝率一般不超过5%(用单个模型分变量设计的单维度规则拒绝率可能会超过5%,但一般不超过20%),因此,在评估单变量规则效果的时候,我们往往更看重头部或尾部的分箱对坏样本是否有区分度,若有区分度(如头部或尾部的分箱对应的样本占比大于1%、小于3%且分箱对应的Lift>3),则会从头部或尾部的样本中找出变量最优的切分点,然后对规则进行泛化,若泛化效果仍较好,则会上线该规则进行风险决策。基于业务经验设计的最优分箱方法只适用于数值型变量,若要分析的变量为分类型变量,则需要先用每个分类对应的Badrate将变量转换为数值型变量,再进行分析。接下来结合虚构的数据样例展示最优分箱方法的实现步骤。
(1)将变量非缺失样本按照取值从小到大排序,并计算每个取值对应的样本量和占比
表2-3为虚构的数据样例,表中变量非缺失值取值个数为8,对变量值从小到大排序,并计算各个取值对应的样本占比。
表2-3 变量排序后取值样例

(2)基于步骤(1)的结果,首先切分出头部和尾部 N %的样本,然后对 N %的样本进行再次切分,每个分箱的样本占比不高于 K %
上述过程包括两个小步骤,一是对步骤(1)的结果进行第一次分箱,切分出头部和尾部 N %的样本,二是对头部和尾部 N %的样本进行精细化分箱,每个分箱的样本占比不超过 K %。之所以要对头部和尾部 N %的样本进行再次分箱,就是为了在这些样本中找出最优切分点,作为单维度规则的切分点。
基于表2-3中的结果,首先切分出头部和尾部前 N %的样本,此处假设 N =5,然后对5%的样本进行精细化分箱,每个分箱的样本占比不超过 K %,此处假设 K =2。表2-4展示了对变量头部和尾部 N% 样本切分及再对 N% 样本二次切分的过程。
表2-4 对变量头部和尾部 N %样本切分及再对 N %样本二次切分的过程

(续)
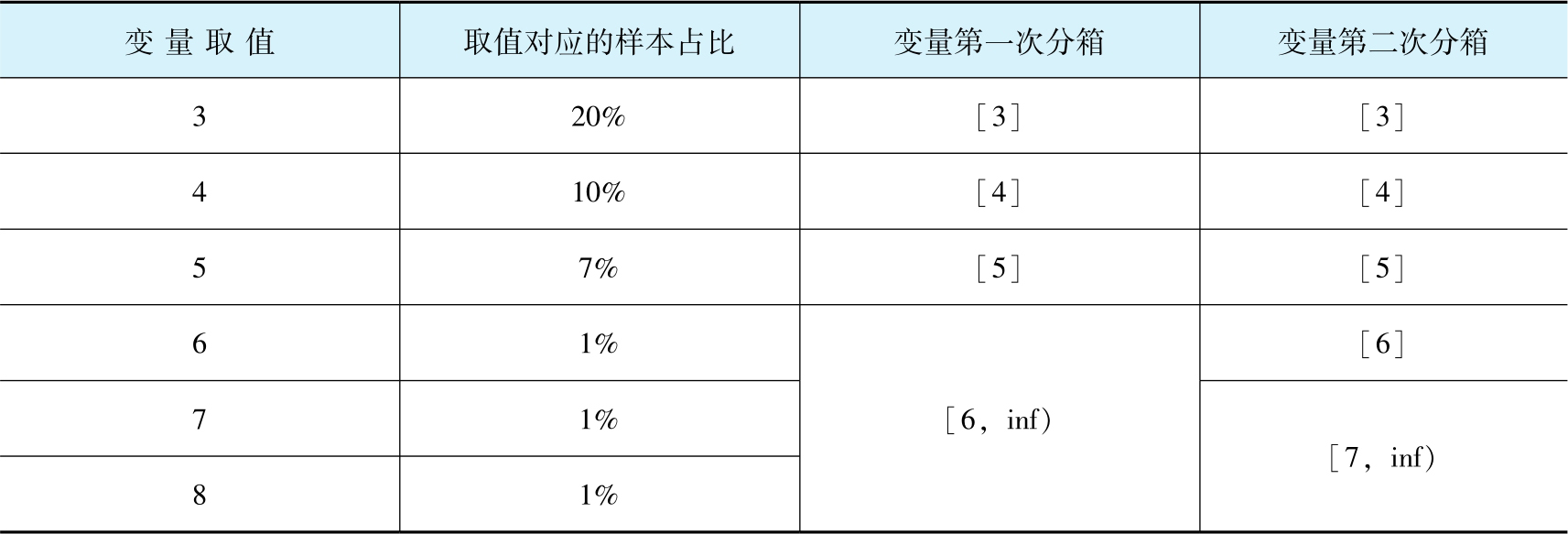
基于表2-3,首先要对变量进行第一次分箱,将头部和尾部的5%的样本归入一箱。头部样本取值为1时,样本占比为35%,已经超过5%,故无须进行样本切分,尾部的最后4个样本取值分别为8、7、6、5,对应的样本占比分别为1%、1%、1%、7%,若对8、7、6进行合并,则样本占比为3%,小于5%,若对8、7、6、5进行合并,则样本占比为10%,大于5%,不满足分箱条件,分箱终止,故只需要对8、7、6对应的分箱进行合并。变量第一次分箱结果见表2-4中“变量第一次分箱”列。
基于表2-4中“变量第一次分箱”列对变量进行第二次分箱,只需要对取值为“[6,inf)”的分箱进行细分箱,每个细分箱的样本占比不超过2%,故细分成了两个分箱“[7,inf)”和“[6]”,该步骤的最终分箱结果见表2-4的“变量第二次分箱”列。
(3)基于变量分箱数量,对中间的(1-2 N %)样本对应的分箱结果进行合并,增强分箱结果的可读性
在进行单变量分箱的时候,我们往往不是很关注中间样本的分箱情况,而且,如果变量取值很多,那么分出来的箱会非常多,可读性较差。为了解决这种问题,我们需要对不是很关注的中间样本的分箱进行合并。对于中间样本的分箱,即使有些分箱对应的Lift取值很高,我们通常也不会将它用来设计规则。例如,单维度规则的形式为:“A卡模型分取值属于[500,600],授信审批拒绝”,这样的规则很难给出合理的业务解释,在实际生产中,没有业务解释性的单维度规则基本上不会使用。
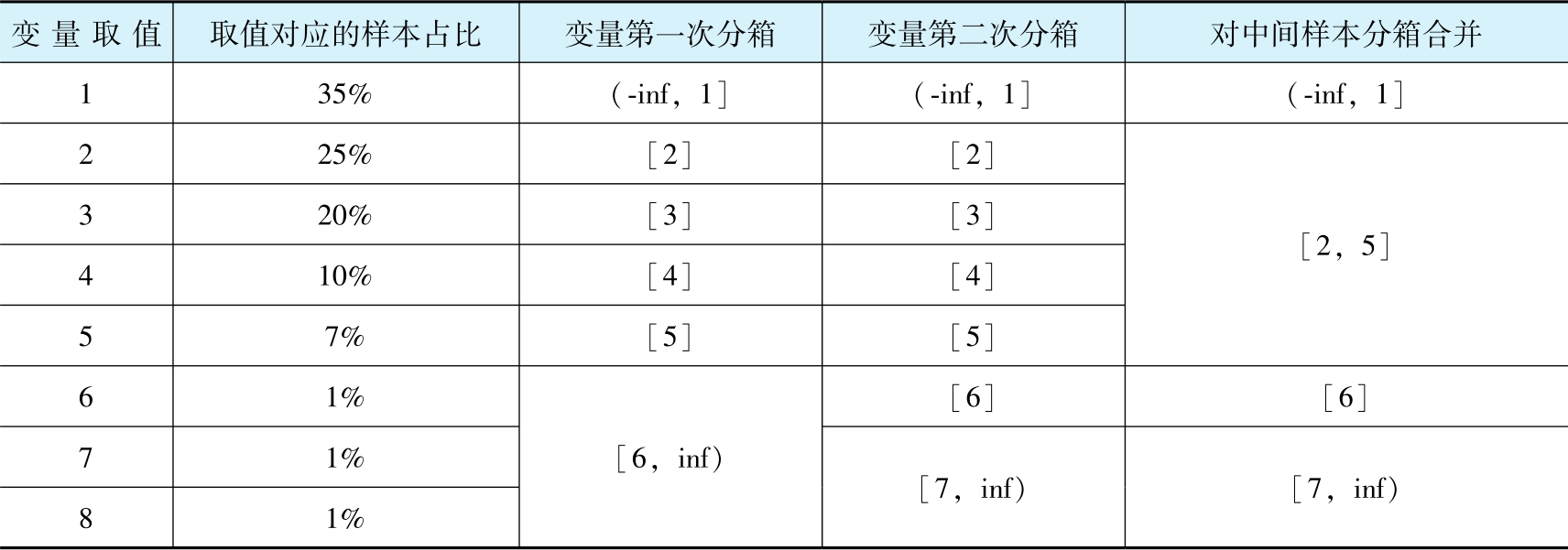
在完成步骤(2)后,若表2-4中“变量第二次分箱”列对应的分箱数太多(如大于16箱),则不利于分箱结果的展示,可对中间的(1-2 N %)样本对应的分箱进行合并;若表2-4中“变量第二次分箱”列对应的分箱数不是很多(如小于或等于16箱),则不需要进行分箱合并。假设需要对表2-4中“变量第二次分箱”列的分箱结果进行合并,则基于合并逻辑合并后的结果见表2-5的“对中间样本分箱合并”列。
表2-5 中间的(1-2 N %)样本分箱合并过程
(4)若变量存在缺失值,则缺失值单独分一箱
若变量存在缺失值,则缺失值通常需要作为单独的一箱并与表2-5中“对中间样本分箱合并”列的分箱结果合并,形成最终的分箱结果。在最终分箱结果中,缺失值处于最后一箱。至此,变量的分箱结果就确定了,接下来就需要计算不同分箱对应的相关统计指标了。
(5)结合目标字段和分箱结果计算不同分箱对应的各种统计指标
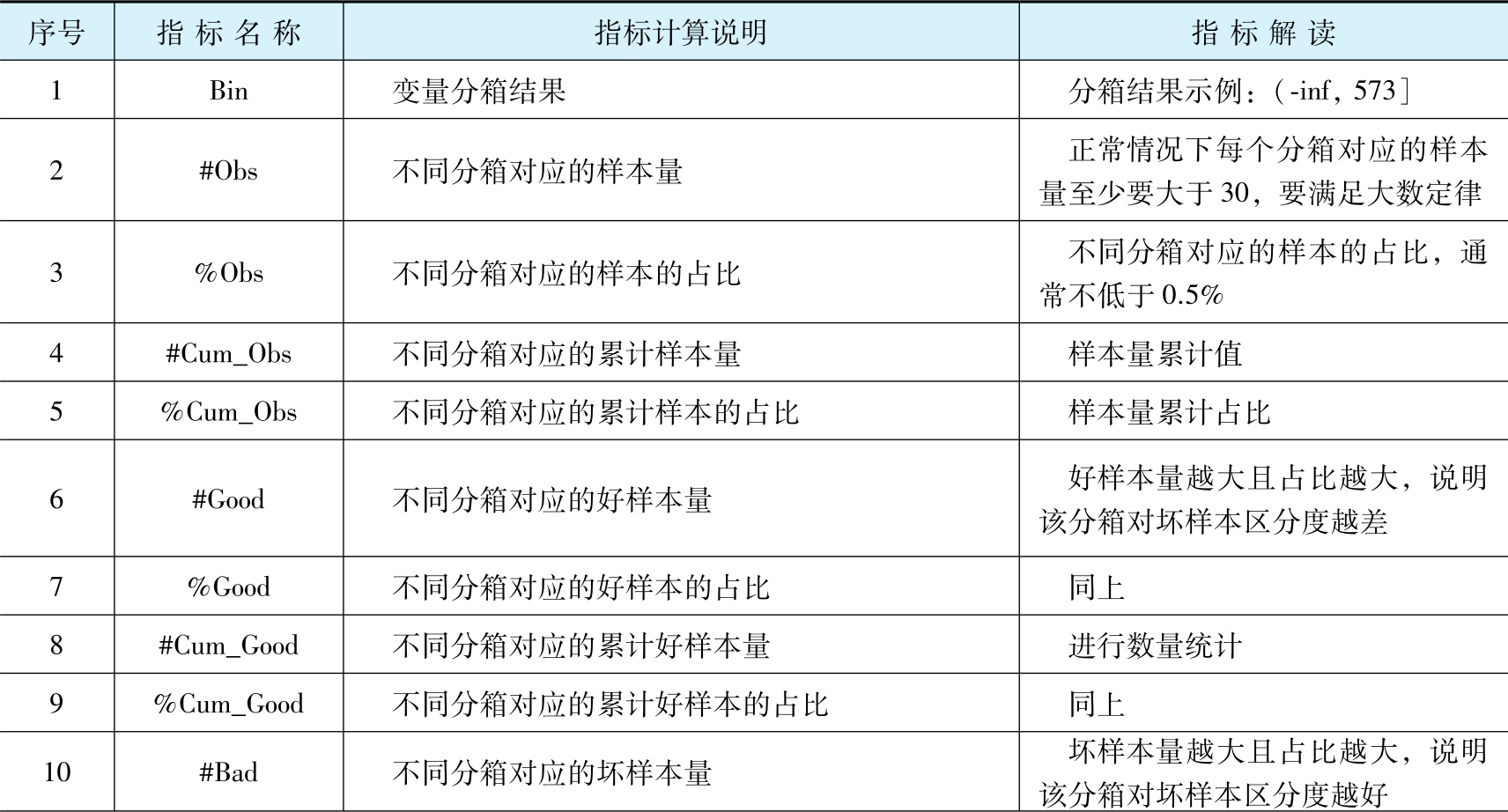
结合目标字段和分箱结果计算的主要指标见表2-6。2.2.7节中的案例实践代码部分计算的指标的名称和表2-6中“指标名称”列是一一对应的。
表2-6 变量分箱对应的主要统计指标
(续)
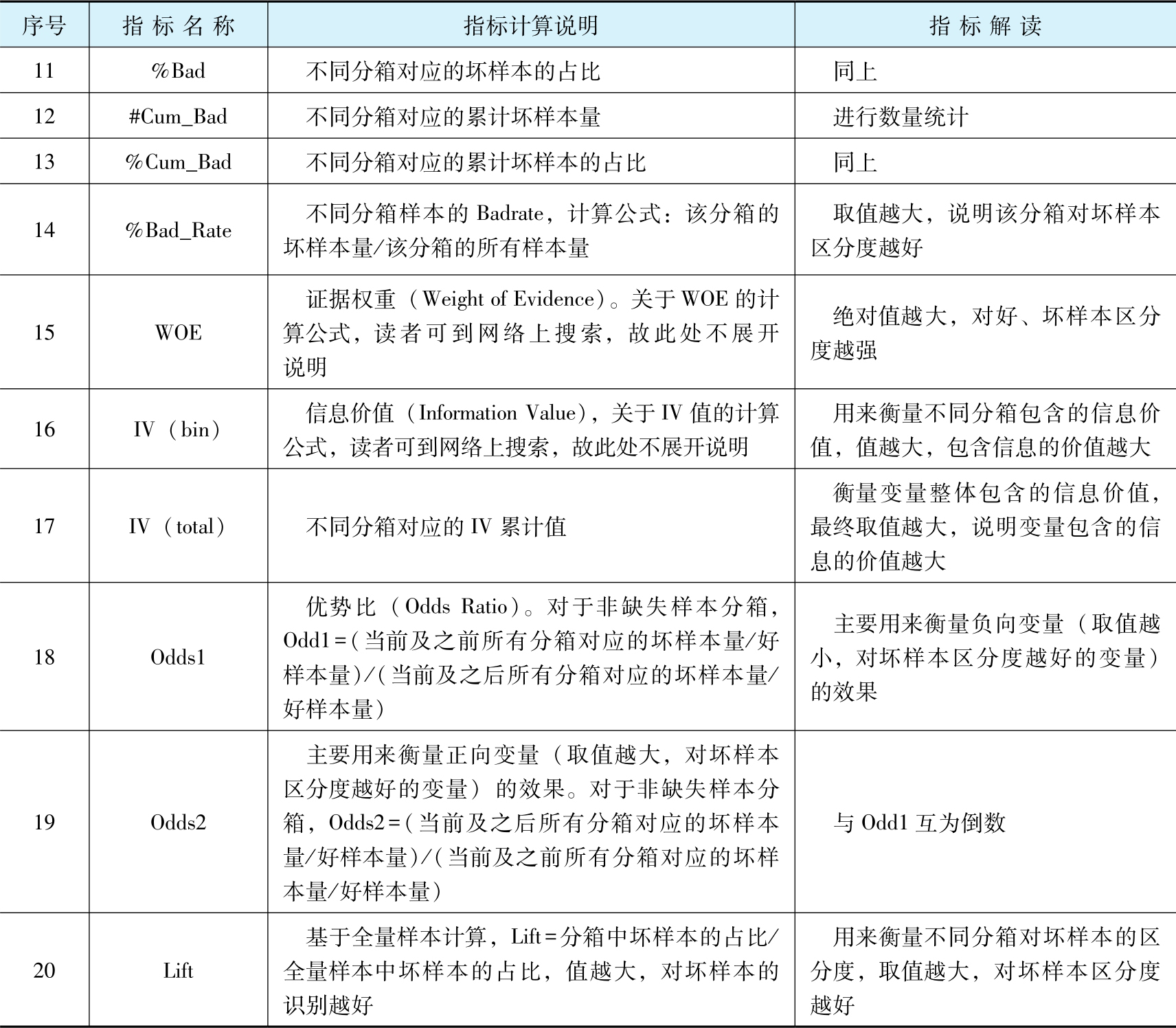
图2-3是变量最终分箱结果示例图,在变量分箱过程中,虽然计算了数十个统计指标,但是比较重要的6个统计指标分别为Bin、#Obs、%Obs、#Bad、%Bad_Rate、Lift,因为基于上述6个重要的统计指标基本上就能够确定变量头部或尾部的分箱对坏样本的区分度了。
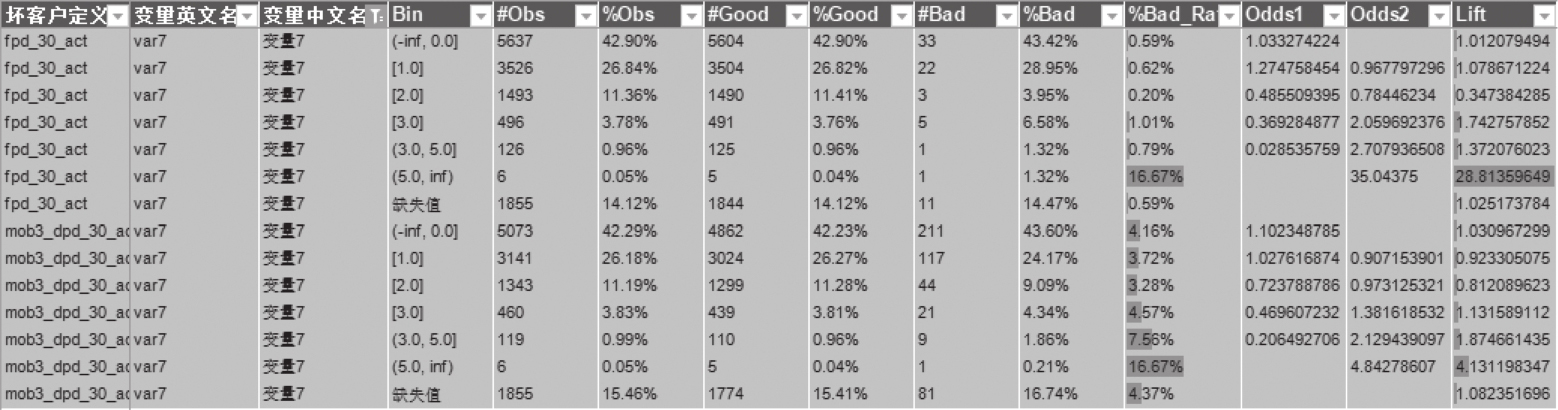
图2-3 变量最终分箱部分结果