
下载掌阅APP,畅读海量书库
立即打开



3.2节介绍了KVM的架构以及KVM API,并通过调用KVM API的示例展现了一台虚拟机在用户态VMM中的生命周期。那么,这些KVM API在内核KVM中是如何实现的呢?KVM是如何支持CPU、内存以及设备虚拟化的呢?
首先,我们来看一下KVM/arch_x86在Linux内核代码中的目录结构,如图3-2所示。
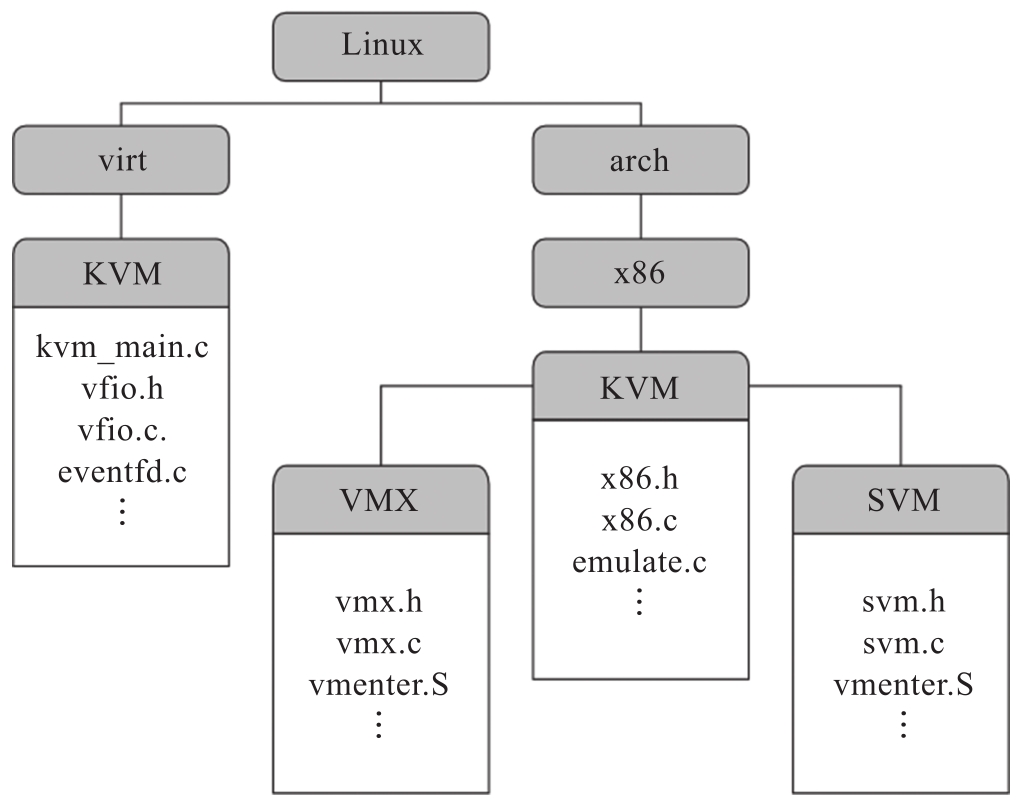
图3-2 KVM/arch_x86在Linux内核代码中的目录结构
其中,Linux的virt/kvm目录下是通用KVM内核模块的代码,用于提供与平台无关的虚拟化框架,对应内核模块kvm.ko。arch/x86/kvm目录下则是x86平台相关的KVM实现,包括Intel和AMD公用的代码,如对x86指令的解码与模拟、型号特有寄存器(Model-Specific Register,MSR)及控制寄存器(Control Register,CR)的模拟、中断控制器的模拟等。此外,由于Intel和AMD平台的硬件虚拟化技术不同,其对应的虚拟化支持分别在arch/x86/kvm下的vmx和svm子目录中有各自的实现,例如Intel VT-x中对VMCS的管理、VMX Root和VMX Non-Root模式间的切换等特有的代码则位于vmx子目录中,编译后为kvm-intel.ko。kvm-intel.ko、kvm-amd.ko等平台相关的模块依赖于通用KVM内核模块(kvm.ko)为其提供虚拟化基础设施的服务,同时为通用KVM内核模块提供具体的硬件虚拟化实现。
在接下来的章节中,我们基于Linux 5.10版本大致描述KVM在Intel虚拟化平台上(即基于Intel VT技术)的具体实现。
KVM的初始化包括平台相关部分与通用部分的初始化,在kvm-intel.ko模块加载时发起,其主要调用关系如图3-3所示。
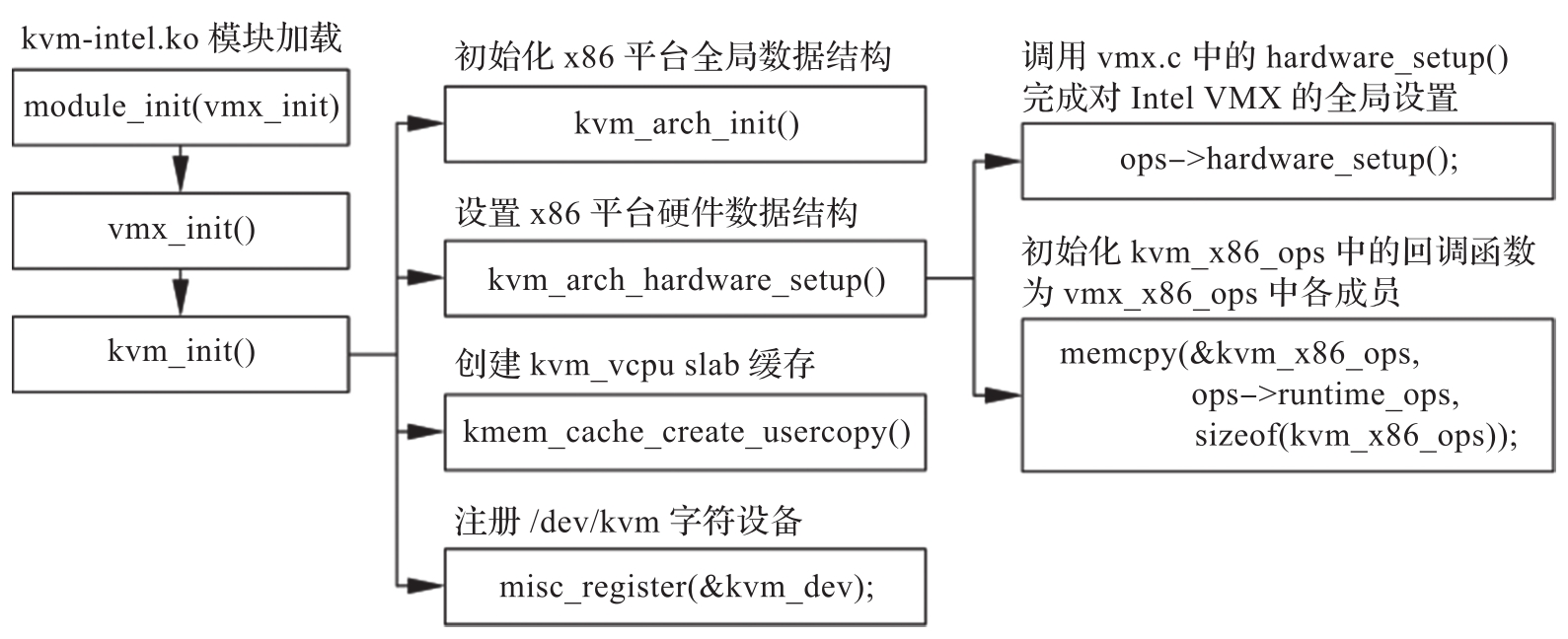
图3-3 KVM的初始化调用栈
由图3-3可以看出,kvm-intel.ko模块的入口函数为vmx_init(),其主要内容如下:

在调用kvm.ko提供的kvm_init()函数来发起初始化时,vmx_init()为其提供了一个重要的数据,即vmx_init_ops。该变量中有两个重要的成员:一个是名为hardware_setup的函数指针,用于完成初始化阶段平台相关的设置;另一个是runtime_ops,为KVM提供运行时平台相关的一组回调函数。在Intel平台上,这两个成员分别被设为hardware_setup和&vmx_x86_ops,后者则会在初始化阶段将内容复制给kvm_x86_ops。
简化后的kvm_init()函数内容如下:

首先,kvm_init()调用kvm_arch_init()函数,检查处理器是否支持Intel VMX以及BIOS是否开启了该特性,并在检查通过后为x86平台相关的数据结构分配内存并初始化部分全局设置。然后,kvm_init()会调用kvm_arch_hardware_setup(),该函数通过调用vmx.c中的hardware_setup()完成针对Intel VMX的全局设置,并且将kvm_x86_ops的内容初始化为vmx_x86_ops中提供的各个回调函数。接下来,kvm_init()创建一个名为“kvm_vcpu”的slab缓存,该缓存的每个对象大小为sizeof(struct vcpu_vmx),用于存放vCPU的结构体。最后,kvm_init()创建字符设备“/dev/kvm”,该设备提供的IOCTL接口即3.2.2节中所描述的系统全局接口,用户态VMM可以通过该接口完成整个KVM模块的配置以及创建虚拟机的操作。
需要特别指出的是vmx.c中的hardware_setup()函数。我们知道,Intel处理器对于VMX的支持是通过CPUID指令体现的,而每代架构的CPU VMX中又有着各种各样的子特性,对于各个子特性的支持有一个演进过程。处理器是否支持某个子特性需要查看特定的MSR,例如IA32_VMX_PROCBASED_CTLS2寄存器的第33位为1,代表当前处理器上的VMX可以使用EPT;IA32_VMX_EPT_VPID_CAP寄存器的第21位为1,代表EPT中的页表项(Page Table Entry,PTE)可以支持“既访”(Accessed)和“脏”(Dirty)标识。这些MSR统称为VMX能力MSR(VMX Capability MSR)。KVM在初始化阶段通过vmx.c中的hardware_setup()对VMX能力MSR进行一一遍历,并将检测结果保存在vmcs_config、vmx_capability等全局变量中,在后面创建vCPU时,就可以依据这些全局变量决定该vCPU对应VMCS中具体字段的设置,而不需要再次查询硬件MSR
 。
。
除了初始化Intel VMX的全局设置之外,hardware_setup()还会通过调用alloc_kvm_area()函数为每个pCPU分配缓存,该缓存的物理地址将作为VMXON指令的参数,即VMXON区域(VMXON Region)。处理器只有执行VMXON指令之后,才能进入VMX模式,但是VMXON指令的执行并不是发生在KVM的初始化阶段,而是在创建第一台虚拟机的时候。
3.3.1节讲到KVM在初始化阶段会创建字符设备“/dev/kvm”。通过对该设备的ioctl(KVM_CREATE_VM)操作,用户态VMM可以创建虚拟机。KVM中对于此类IOCTL的处理是函数kvm_dev_ioctl(),并调用kvm_dev_ioctl_create_vm()完成虚拟机的创建。函数kvm_dev_ioctl_create_vm()的主要内容如下:
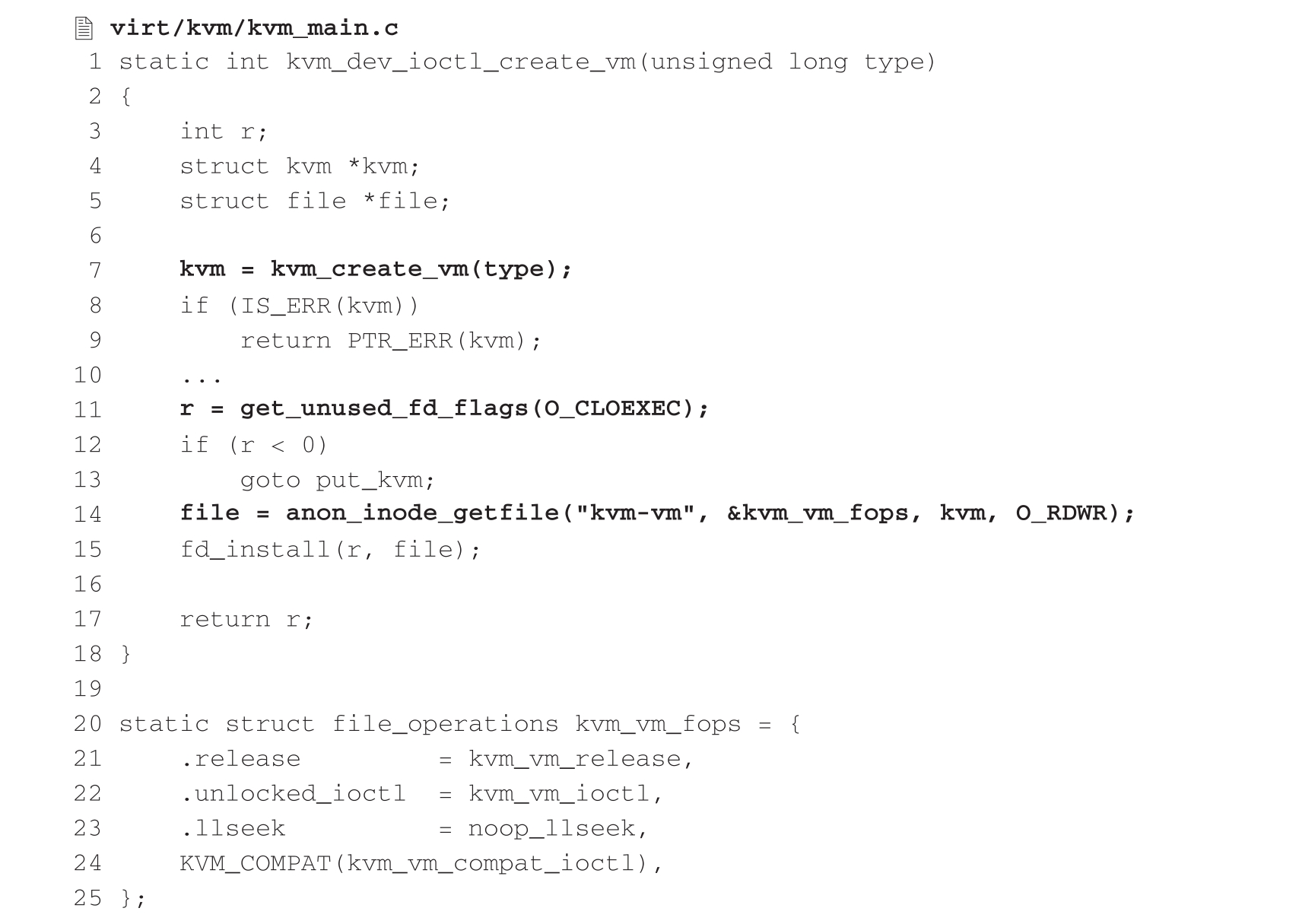
kvm_dev_ioctl_create_vm()的主要任务是通过调用kvm_create_vm()创建一个虚拟机实例。每个虚拟机实例用一个struct kvm结构来描述,其核心作用就是描述客户虚拟机中的资源,包括CPU虚拟化的vCPU信息、内存虚拟化相关的内存槽信息等。此外,如果kvm_create_vm()要判断当前系统是否有正在运行的虚拟机,还会通过hardware_enable_all()在每个pCPU上执行VMXON指令,从而进入VMX根模式。接下来kvm_dev_ioctl_create_vm()通过anon_inode_getfile()来创建一个匿名文件,并将该文件的文件操作集设置为kvm_vm_fops,最后将文件描述符fd返回给用户态VMM。此后,用户态VMM就可以通过对该fd执行IOCTL操作来调用虚拟机相关接口了。KVM收到此类IOCTL后,通过kvm_vm_fops中注册的kvm_vm_ioctl()对相关请求进行处理。需要强调的是,每个VMM都会对应一个fd,有多个VMM,就会在多个进程中分别调用kvm_create_vm来返回对应的虚拟机fd。
本节将讨论如何创建并运行KVM虚拟CPU,KVM还为虚拟CPU实现了多处理器(Multiple Processor,MP)系统中的调度机制,限于篇幅,在此不再赘述,感兴趣的读者可以阅读相关资料。
1.KVM虚拟CPU的创建
在创建KVM虚拟机之后,接下来的关键任务就是创建虚拟CPU。在3.2.2节的示例代码中,没有将虚拟CPU放在单独的线程中管理,但在实际应用中,用户态VMM往往会为虚拟CPU创建一个线程,在该线程中通过对vm_fd执行ioctl(KVM_CREATE_VCPU)操作创建虚拟CPU。KVM中对于此类IOCTL的处理函数是kvm_vm_ioctl(),并调用kvm_vm_ioctl_create_vcpu()完成虚拟CPU的创建。函数kvm_vm_ioctl_create_vcpu()的主要内容如下:


kvm_vm_ioctl_create_vcpu()的主要任务是通过调用kvm_arch_vcpu_create()创建一个虚拟CPU实例。每个虚拟CPU实例用一个kvm_vcpu结构体来描述,该结构体的主要成员定义如下:

这里的kvm指针指向创建该虚拟CPU的虚拟机,vcpu_id存储用户态VMM创建时指定的虚拟CPU标识符,其他成员还包括模式、状态位等,arch结构体变量则包含不同架构下一系列平台相关的变量,如寄存器、内存管理单元等,这里重点介绍run指针。
变量run是一个指向kvm_run结构体的指针,该结构体的典型成员定义如下:


该结构体是用于KVM和用户态VMM之间通信的数据结构,KVM会为该结构指针分配整页大小的内存空间,并由用户态VMM通过内存映射的方式共享访问。其中的输入变量和输出变量是相对于KVM而言的,在两者传输数据的过程中,用户态VMM向KVM传递数据时写入输入变量,用户态VMM从KVM接收数据时读取输出变量,其中有些变量既用作输入又用作输出。不难理解,数据的传输是在根模式和非根模式之间切换时发生的,当发生VM Exit时,CPU从非根模式切换为根模式,这时KVM会将VM Exit的原因记录于该结构体的exit_reason变量中,如果某些VM Exit还需要继续交由用户态VMM来处理的话,用户态VMM仍将通过读取作为输出变量的exit_reason来获取VM Exit原因,再进一步读取该结构后半部分的共用体中的相应变量进行处理。
现已介绍完kvm_vcpu结构,那么虚拟CPU究竟是如何被创建出来的呢?让我们回到之前提到的函数kvm_arch_vcpu_create()。

该函数完成的绝大部分任务是对kvm_vcpu的arch结构变量中平台相关的各成员进行初始化,如内存管理单元的创建及初始化等。既然是平台相关的结构变量,kvm_arch_vcpu_create()函数自然就会在不同平台上进行不同的实现,在此仅以x86平台实现为例进行简要介绍。在x86平台上最为关键的任务是调用static_call(kvm_x86_vcpu_create)宏,该宏最终会调用vmx_create_vcpu()函数创建x86平台虚拟CPU,其关键代码如下:

在3.3.1节曾谈到,vmx_init()会在调用kvm_init()函数时将vcpu_vmx结构体的大小传给参数vcpu_size,vcpu_vmx是x86平台相关的数据结构,该结构包含一个平台无关的kvm_vcpu结构体变量,以及平台相关的其他内容。前面阐述的内容大部分是虚拟CPU与平台无关的初始化,所访问的是kvm_vcpu的变量。现在进入平台相关的部分,首先调用to_vmx()将kvm_vcpu的指针转换成vcpu_vmx的指针类型,以便扩大指针访问范围对x86平台相关的其余变量继续进行初始化。以下是vcpu_vmx结构体的主要成员:

我们看到,该结构体中的第一个变量vcpu正是平台无关的kvm_vcpu结构变量,不难理解,该变量的首地址与整个vcpu_vmx结构体变量的地址相同,故此在指针类型强制转换时地址不变,范围扩大。平台相关的其余变量主要包括虚拟CPU退出执行条件、VMCS地址、CPU切换为根模式时VM Exit原因等。
vmx_create_vcpu()函数后面继续执行加载虚拟CPU、初始化VMCS等任务,然后返回kvm_arch_vcpu_create()调用处继续后续的内存管理单元初始化,最后返回kvm_vm_ioctl_create_vcpu()继续完成剩余平台无关的初始化收尾任务,如为虚拟CPU分配文件描述符、计算虚拟CPU数组索引并追加虚拟CPU数组元素等,这样就完成了对虚拟CPU的全部初始化任务,用户态VMM对ioctl(KVM_CREATE_VCPU)的调用将得以返回并获得该虚拟CPU文件描述符。
2.KVM虚拟CPU的运行
在创建KVM虚拟CPU之后,通过对虚拟CPU文件描述符执行ioctl(KVM_RUN)操作,用户态VMM进而可以将虚拟CPU运行起来。KVM中对于此类IOCTL的处理函数是kvm_vcpu_ioctl(),调用kvm_arch_vcpu_ioctl_run()运行虚拟CPU,其主要调用关系如图3-4所示。
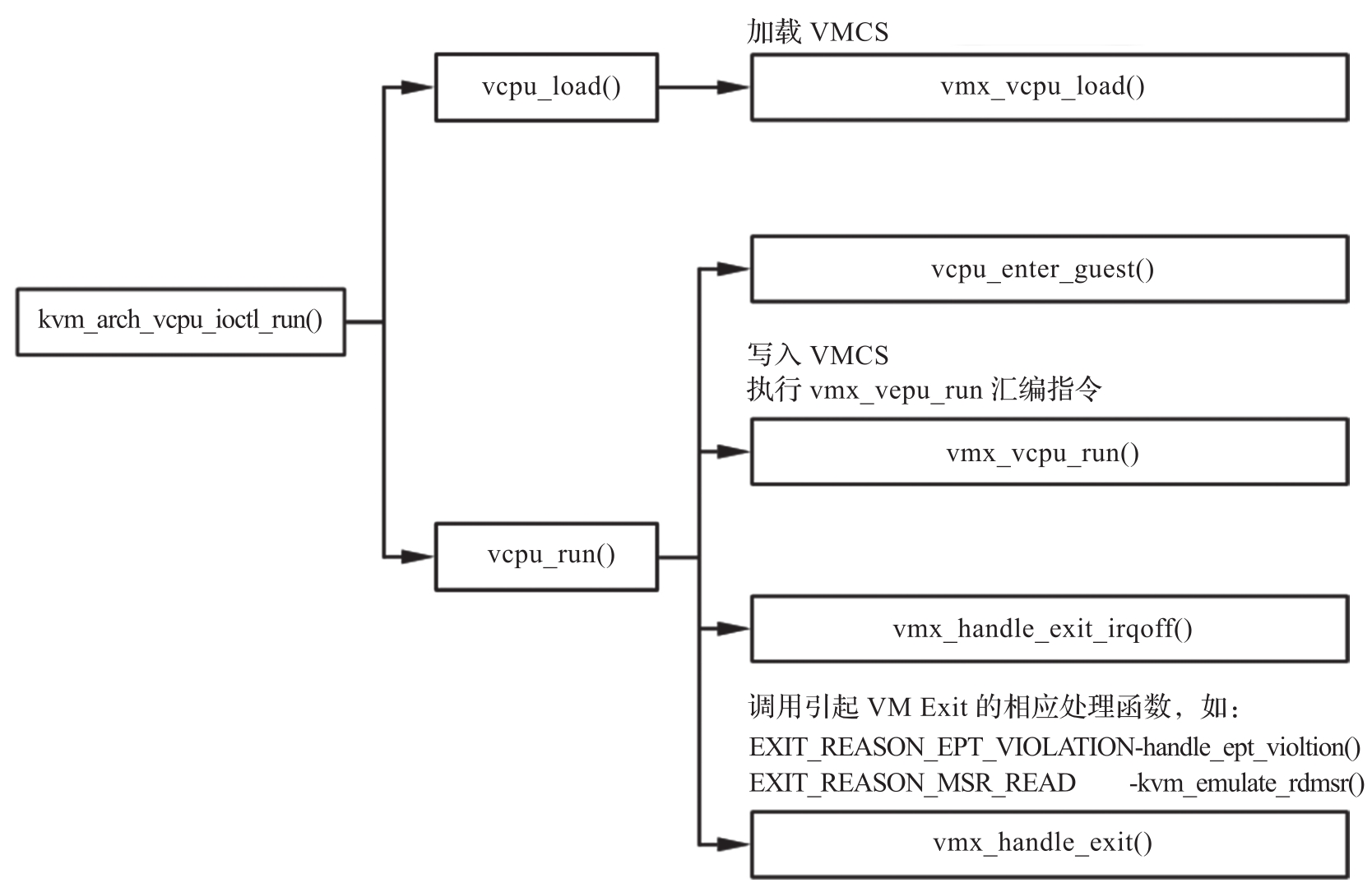
图3-4 KVM虚拟CPU的运行调用栈
函数kvm_arch_vcpu_ioctl_run()的主要内容如下:

vcpu_load()首先调用平台相关的函数kvm_arch_vcpu_load(),再通过宏static_call(kvm_x86_vcpu_load)调到x86平台的vmx_vcpu_load(),其主要任务就是通过vmx_vcpu_load_vmcs()调用vmcs_load()函数,最终执行VMPTRLD指令加载虚拟CPU的VMCS。指令VMPTRLD用于加载指向VMCS的指针,该指令的参数是一个VMCS的地址。执行指令后,该VMCS在逻辑处理器上既处于活动状态又处于当前状态,指令调用代码如下:

vcpu_run()函数的实现主要由一重循环构成,当虚拟CPU需要进入运行客户机状态时调用vcpu_enter_guest(),该函数又由一重循环构成,通过宏static_call(kvm_x86_run)循环调用x86平台的vmx_vcpu_run(),再由vmx_vcpu_enter_exit()调用__vmx_vcpu_run()执行VMLAUNCH或VMRESUME指令进入客户机运行所处的模式,即非根模式,相应的VMCS也是在这时配置并加载完成的,主要代码如下:


由上述代码可以看出,vcpu_enter_guest()所实现的内层循环运行于虚拟CPU的IN_GUEST_MODE状态,在执行VMLAUNCH/VMRESUME指令后切换至非根模式,CPU转而运行客户机操作系统指令。那么,VMLAUNCH/VMRESUME在进入VMX非根模式的区别又是什么呢?VMLAUNCH指令是当VMCS尚未在物理CPU上运行的情况下执行的,而VMRESUME指令是当VMCS已经在该物理CPU上运行且状态已经保存的情况下执行的,比较常见的就是虚拟CPU的VMCS在该物理CPU上反执行,用VMRESUME比VMLAUNCH会有着更小的延迟进入客户机系统。
无论是运行于KVM还是用户态VMM中,CPU所处的VMX操作模式均为根模式,只有当运行于客户机操作系统时,CPU才处于非根模式。从以上代码不难看出,此时的客户机是在用户态VMM的根模式下调用ioctl(KVM_RUN)进入KVM内核态根模式再执行VMX指令切至非根模式这样的调用栈上运行的,宿主机上运行的KVM虚拟CPU线程此时阻塞在VMX指令调用处直到VM Exit发生后切回根模式才继续执行,内层循环退出后,vcpu_run()所实现的外层循环将运行于虚拟CPU的OUTSIDE_GUEST_MODE状态,如果外层循环再退出,vcpu_run()将返回至起初的kvm_arch_vcpu_ioctl_run()函数,用户态VMM对ioctl(KVM_RUN)的调用将得以返回并退出到用户空间继续运行。在3.2.2节的示例中,用户态VMM中还有一重循环不断调用ioctl(KVM_RUN)来促使虚拟CPU执行客户机的指令。这三重循环周而复始、协同配合完成了KVM的CPU虚拟化运行过程。表3-1大致归纳了这三重循环层层深入的递进关系。
表3-1 KVM的CPU虚拟化运行过程

本节将详述KVM内存虚拟化的原理及其演进。
KVM内存虚拟化的主要任务是向客户机操作系统提供符合其假定和认知的虚拟内存,让其如同正常访问物理内存一样,同时能够在访问用户态VMM所创建的虚拟机内存时将其正确转换为物理机的内存地址。
在阐述原理时,我们首先引入内存虚拟化中的一个重要概念——内存槽。这一重要机制搭建起虚拟机地址空间通往物理机地址空间的桥梁,是客户机物理地址向宿主机物理地址转换过程中的关键一环,它不仅为KVM内存虚拟化的实现提供了可行性,而且贯穿KVM内存虚拟化演进的整个过程,发挥着举足轻重的作用。本节后面将详细阐述KVM内存虚拟化的演进过程,从软件完全虚拟化的影子页表机制到硬件辅助虚拟化的EPT机制,让读者不仅能够了解KVM的代码现状,还能够从中领略KVM内存虚拟化的发展历程。
1.KVM内存虚拟化原理
在3.2.1节中,我们提到虚拟机的内存同时也是用户态VMM进程的内存,这里再详细阐述一下。每个虚拟机作为用户态VMM的一个进程,虚拟机所虚拟出来的内存,其地址空间是由用户态VMM从该进程空间中申请并分配给客户机使用的,既然内存的申请发生在用户态VMM,那么客户机物理地址空间自然会落在用户态VMM的进程地址空间内。我们知道,任何进程都运行于自己的虚拟地址空间,这样虚拟出来的用以“欺骗”客户机操作系统的物理地址显然不能被直接发送到系统总线上,否则破坏的就是宿主机物理地址(HPA)空间,换言之,这样的物理地址是瞒不过宿主机操作系统的。
因此KVM引入了内存槽(Memory Slot)机制来解决客户机物理地址到宿主机虚拟地址的转换问题,图3-5描述了客户机和宿主机操作系统中四种地址的转换关系。
我们清楚地看到,客户机和宿主机的虚拟地址到物理地址的转换是由各自系统页表负责完成的,内存槽在这里充当连接客户机地址空间和宿主机地址空间的桥梁。那么究竟什么是内存槽?它又是如何进行地址转换的呢?
内存槽是被KVM引入用来建立从GPA到H VA映射关系的数据结构,该数据结构主要记录对应此映射区间的GPA起始页帧号、当前槽所包含的页面数目以及起始宿主机虚拟地址。内存槽所映射的内存以页面为单位对起始地址进行存储,无论是GPA还是HVA都是按页对齐的,映射区间的内存大小也是页面大小的整数倍。一个虚拟机的物理内存由多个内存槽组成,每个内存槽都有各自的一段映射区间,不同内存槽的映射区间互不重叠,一个虚拟机的所有内存槽构成了完整的GPA空间,因此,从客户机的角度来看,“不重不漏、分段映射”是内存槽的显著特征。在2.1.2节中谈到,对于宿主机来说,客户机的物理内存实际上是不连续的,不同内存槽在映射前后的地址位置关系是不确定的,其具体位置完全取决于KVM的内存分配算法。最明显地,即便是在GPA空间相邻的两个内存槽,经映射后的HVA空间也不一定是相邻的。
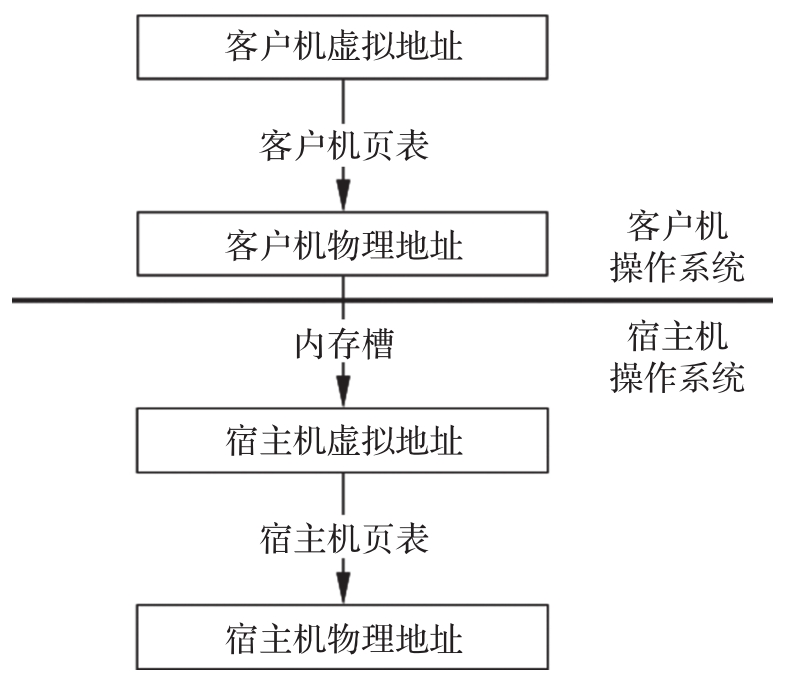
图3-5 客户机和宿主机操作系统中四种地址的转换关系
前面谈到客户机物理内存的申请发生在用户态VMM中,用户态VMM会将GPA和申请得到的用户空间地址通过系统调用传递并注册到内核空间的KVM中,然后由KVM通过内存槽来保存并管理GPA到HVA的映射关系。2.1.2节已经指出,这里的管理任务主要涉及两个方面——维护和转换。维护是指当用户空间内存区域发生变化时,KVM会根据待更新的内存槽信息,包括起始客户机页帧号(Guest Frame Number,GFN)、页面数目、起始HVA、内存属性等,处理同现有内存槽之间的空间位置重叠关系及属性变化,使之仍然满足前述特征,以便重新构造一个有效的GPA到HVA的映射关系。地址转换的过程是依照GPA遍历所有内存槽找到所属的映射区间,然后根据GPA在此映射区间内的偏移量计算得到相应的HVA。
KVM中的内存槽用kvm_memory_slot结构体来描述,该结构体的定义如下:


这里的base_gfn是GPA对应的起始页帧号,其类型gfn_t定义为64位无符号整型,npages是当前内存槽所包含的页面数目,userspace_addr则用来存储起始HVA,其他成员还包括脏页标识位图、架构相关的变量、标志位及标识符等。
kvm_memory_slot结构体表示一段映射区间,KVM以动态数组形式存储一个虚拟机的所有内存槽信息,用以覆盖全部GPA空间,这里用kvm_memslots结构体来对kvm_memory_slot进行封装,该结构体的定义如下:

我们看到,该结构体的最后一个变量memslots的类型是kvm_memory_slot结构的动态数组,其数组空间会在分配kvm_memslots结构空间的同时进行动态分配。至此,KVM就得以完整存储GPA到HVA的映射关系了。下面具体介绍KVM所提供的用以构建内存槽数组的系统调用接口。
在3.2.2节的示例中,用户态VMM通过mmap()系统调用(一种内存映射文件的方法)在进程的虚拟地址空间映射了一段连续内存作为虚拟机的物理内存,在经过内存布局之后,用户态VMM通过对vm_fd执行ioctl(KVM_SET_USER_MEMORY_REGION)操作将内存区域信息传递给KVM。不难看出,ioctl(KVM_SET_USER_MEMORY_REGION)正是KVM提供给用户态VMM的这一系统调用接口,而内存区域信息则是该调用的参数。内存区域用kvm_userspace_memory_region结构体来描述,它包含GPA到HVA中的一段映射关系以及相关属性的信息,该结构体定义如下:

这里的slot用来存储内存槽编号,flags为标志位,guest_phys_addr即GPA,memory_size是以字节为单位的内存大小,userspace_addr就是从用户态VMM进程地址空间中映射文件得到的内存起始地址,即HVA。
上述信息传入KVM后,KVM会根据这些信息构造一个内存槽并进行安装,安装过程需要计算与当前内存槽数组元素之间的空间位置关系及标志位变化,从而进行相应的创建、删除或修改内存槽等操作,最终在KVM中保存一份完整的GPA到HVA的映射关系。
综上所述,内存虚拟化的关键在于维护客户机物理地址(GPA)到宿主机虚拟地址(HVA)的映射关系。如果说客户机物理地址空间是在“欺骗”客户机操作系统的话,那么内存槽机制就是反过来为宿主机操作系统“圆谎”的,“欺”上“瞒”下并要做到天衣无缝是内存虚拟化最为形象的写照。
2.KVM内存虚拟化的演进
有了内存槽,就从技术可行性的角度解决了GPA到HVA的转换问题,但当客户机操作系统真正运行时,客户机的进程每次要访问物理内存时需要经过从GVA到GPA到HVA再到HPA的层层转换,如果都用最原始的方式转换,正确性是没有问题的,但会发生大量VM Exit,其效率非常低下。为此KVM设计了一套软件框架,并利用该框架实现了软件完全虚拟化的解决方案。下面就从这一解决方案的原理出发,逐步探究KVM内存虚拟化的演进。
(1)影子页表
在客户机进程第一次访问某个GVA时,KVM通过上述方式得到HPA后,就将该GVA到HPA的映射记录下来,这样下次再访问该地址时直接将之前记录的映射结果返回,既不必重新进行转换计算也不会发生VM Exit。这就是KVM解决地址转换效率问题的基本思路。
随着对GPA空间访问的逐渐增加,最终会在KVM中形成一张完整记录GVA到HPA的页表,该页表可以快速完成一个进程的GVA到HPA的转换而不会发生VM Exit,从而使运行效率大大提高。这张逐渐形成的完整页表就是2.1.3节中提到的影子页表。影子页表是完成GVA到HPA转换的映射机制,如图3-6所示。
这里用到了KVM内存管理中一种至关重要的数据结构——KVM MMU页面,KVM通过该结构来管理影子页表,它本身是由struct kvm结构中arch变量所管理的链表的节点,但它管理的影子页表在页表项地址关系上呈现树形结构。KVM中用kvm_mmu_page结构体来描述,该结构体的定义如下:
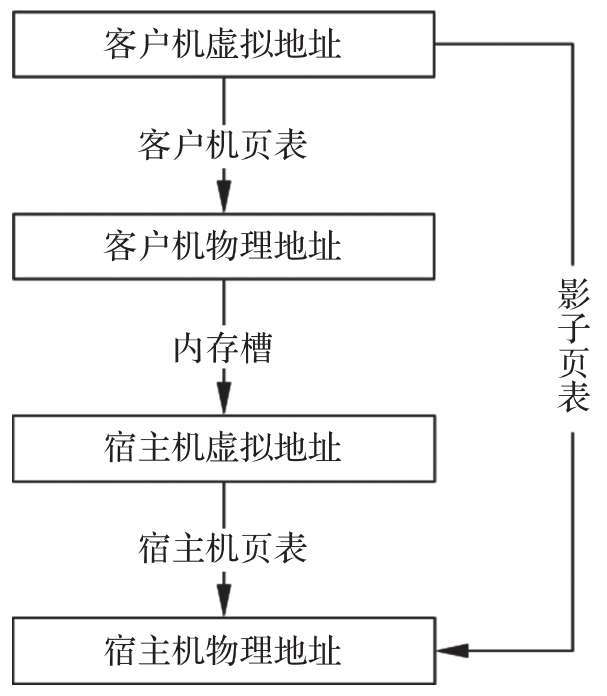
图3-6 影子页表的作用

这里的link指针用于将生成的KVM MMU页面插入活动链表中;spt指针指向一块页面大小的内存空间,该页面被称为影子页面(Shadow Page),用来存储影子页表项(Shadow Page Table Entry,SPTE),即对客户机页表项GPA翻译后的HPA,每个SPTE占用8个字节,故一整页的SPTE共有512个,它们可以是叶子和非叶子页表项的混合;role共用体占用32位的内存空间,各成员用以标明该页面的属性,其中level属性变量表示所管理的影子页面在影子页表中的层级。
下面简要描述影子页表是如何构建的。客户机进程在首次访问某个GVA时,KVM会通过GVA着手建立影子页表,既然KVM在内核态根模式运行,那么一定已经发生VM-Exit了,客户机和宿主机分别处于两个不同的世界,彼此互不相知,那么KVM是如何得知客户机某进程GVA的呢?这要从CPU虚拟化说起。3.3.3节讲过,虚拟CPU是用户态VMM在一个线程中通过KVM创建的,而VMCS保存了虚拟CPU的相关状态,既然创建发生在KVM中,那么KVM完全可以通过查询虚拟CPU的VMCS来获取数据。事实上,在退出非根模式之前,虚拟CPU会将控制寄存器CR2的值保存到VMCS的字段中,而CR2存储的正是GVA。这样在VM Exit之后,KVM就轻而易举地获得了客户机进程的GVA。有了GVA之后,KVM就会运用3.3.3节引入的概念想方设法地将其转换为HPA,从而建立影子页表。但此时问题又来了,如前所述,从GVA到GPA的转换是由客户机页表负责完成的,而这时客户机已经退出,何谈页表呢?读者或许已经猜出,线索还得从VMCS中发掘。我们知道,CR3是页目录基址寄存器(Page Directory Base Register,PDBR)保存当前进程页表的物理地址,它在整个地址转换过程中发挥着举足轻重的作用。KVM获得客户机CR3的值之后,当仁不让地实现了对客户机页表的遍历,最终计算出GPA。后面通过内存槽计算HVA,再通过宿主机页表转换为HPA。
通常,操作系统是通过页表将虚拟地址转换为物理地址的,现在面临着持有虚拟地址和物理地址,如何反推页表的问题。这里的虚拟地址是GVA,物理地址则是HPA,页表就是影子页表。如果能在客户机构造页表时,同步在KVM中构造一张拓扑结构与客户机页表完全一样的页表,然后用GVA不同位段索引各级页表内偏移,选取HPA反填至最后一级页表项中,把在KVM中分配的各级页表起始HPA反填至上一级页表项中,最后再用这张页表移花接木,被KVM真正载入物理内存管理单元(Memory Management Unit,MMU)模块中,取代原有的客户机页表,使客户机得以高效运行,这样就完成了影子页表的任务。图3-7展示了影子页表的工作流程,从HPA沿虚线箭头所指方向逆向溯源不难推导影子页表的构造过程。
上面谈到KVM实现了通过硬件寄存器遍历客户机页表,上面所说的是最为常见的用户进程页表,这时CPU处于保护模式(Protected Mode)。实际上,CPU支持多种操作模式,不仅不同的操作系统运行于不同的CPU操作模式,而且即使在同一操作系统运行过程中该模式也会发生变化。众所周知,现代操作系统在刚开机时首先运行在实模式下,然后再切换到保护模式下运行。在不同的CPU操作模式下,内存寻址方式也大相径庭,表3-2大致描述了不同CPU操作模式下的内存寻址方式。
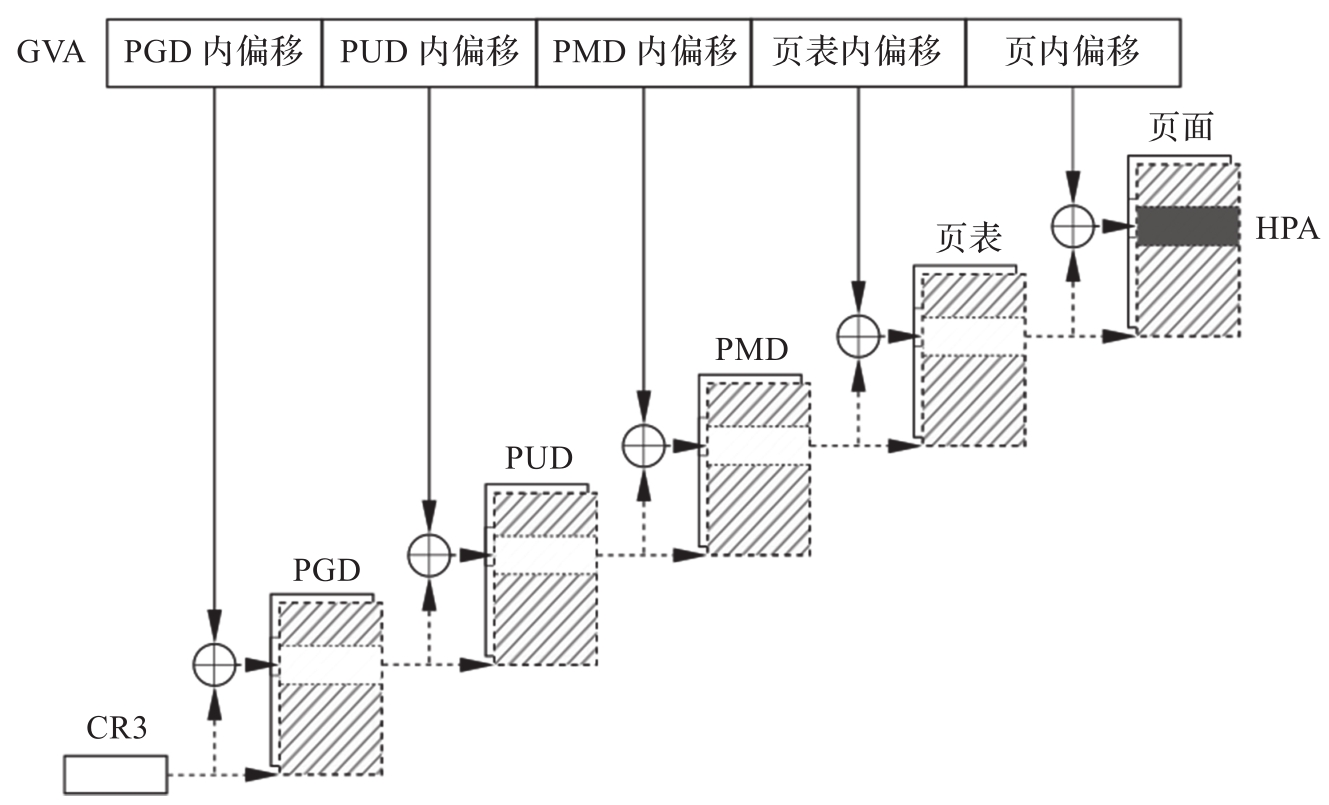
图3-7 影子页表的工作流程
表3-2 不同CPU操作模式下的内存寻址方式
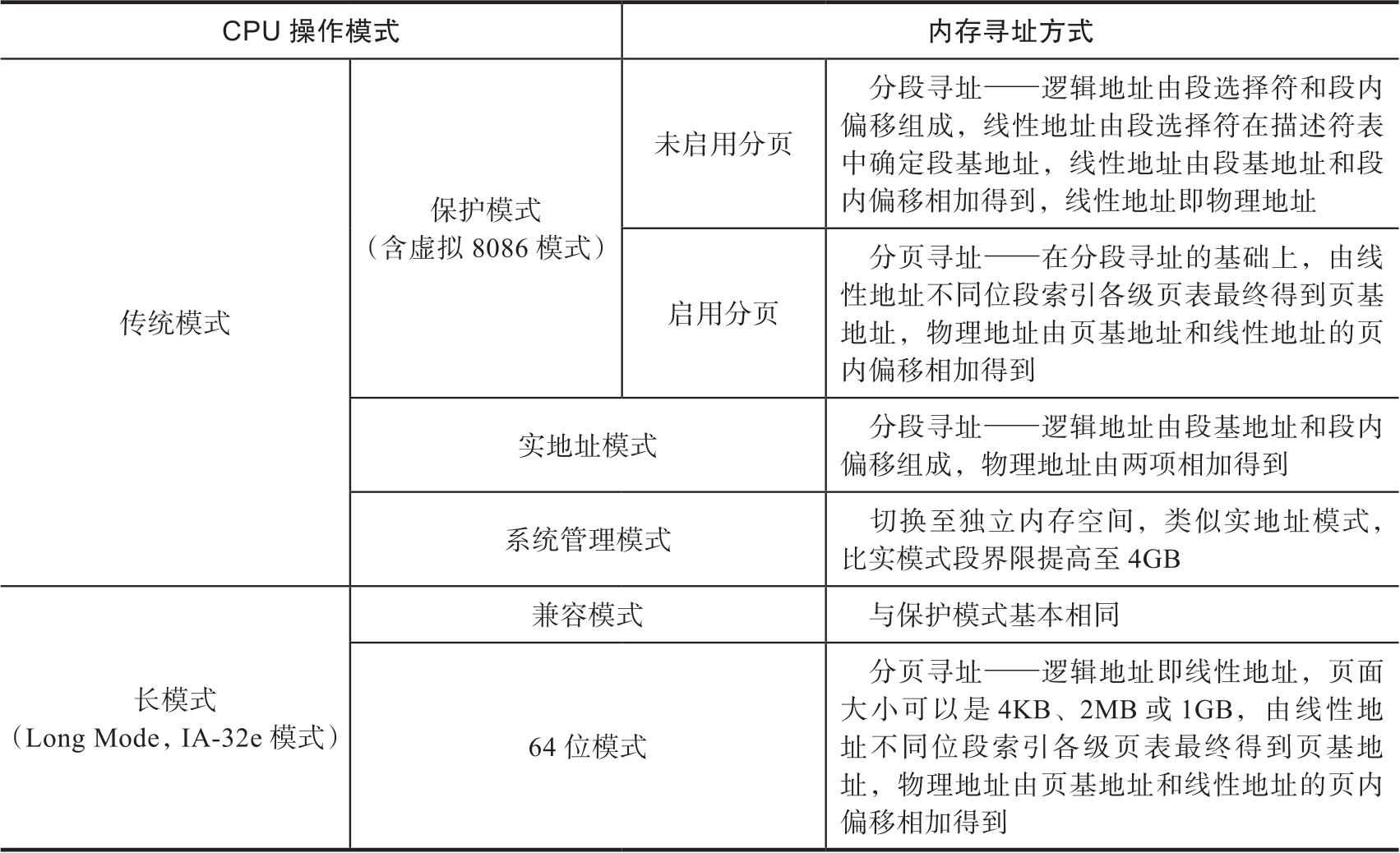
从表3-2可以看出,每种操作模式均有其相应的内存寻址方式,这势必导致KVM需要采用不同的算法才能正确遍历客户机页表。因此,在通过GVA计算GPA的过程中,不仅需要获取CR3的值,还需要根据虚拟CPU所处的操作模式按照正确的内存寻址方式对客户机页表进行遍历。KVM为此设计了一套机制涵盖所有内存寻址方式以便进行遍历。在3.3.3节中提到,在虚拟CPU结构体kvm_vcpu的成员中有一个arch结构体变量,它包含内存管理单元相关变量,其中mmu指针是一个指向kvm_mmu结构体的指针,该结构体的主要成员定义如下:

我们看到,该结构体中包含一系列函数指针变量,KVM在实现MMU机制时根据内存寻址方式的不同划分出不同的分页模式,这些函数指针是对不同分页模式下的关键操作进行的抽象,实际上是为各个模式提供回调函数接口层,由各个模式分别实现每个回调函数的处理逻辑,然后在运行时根据虚拟CPU的当前模式对相应系列处理函数进行回调,进而完成GVA到GPA的计算翻译。
在实现各模式下的回调函数时,KVM发现其中有大部分函数在不同模式下的实现逻辑流程大体相同,只有部分常量、类型以及汇编指令等在字面上不同,如gva_to_gpa()、sync_page()等,如果对各个模式逐一定义实现,势必造成代码重复冗余。于是,KVM对这类函数进行归纳,为相同功能的函数定义了通用的模板,将函数名以及函数体中分页模式相关的常量、类型、汇编指令等用宏替代,然后在编译阶段对每种模式进行相应的宏展开,为函数名加上前缀得以区分,这样就用一段代码为不同模式定义多套函数,最终生成的函数诸如paging64_gva_to_gpa()、paging32_sync_page()等。通用模板相关的宏定义代码如下:
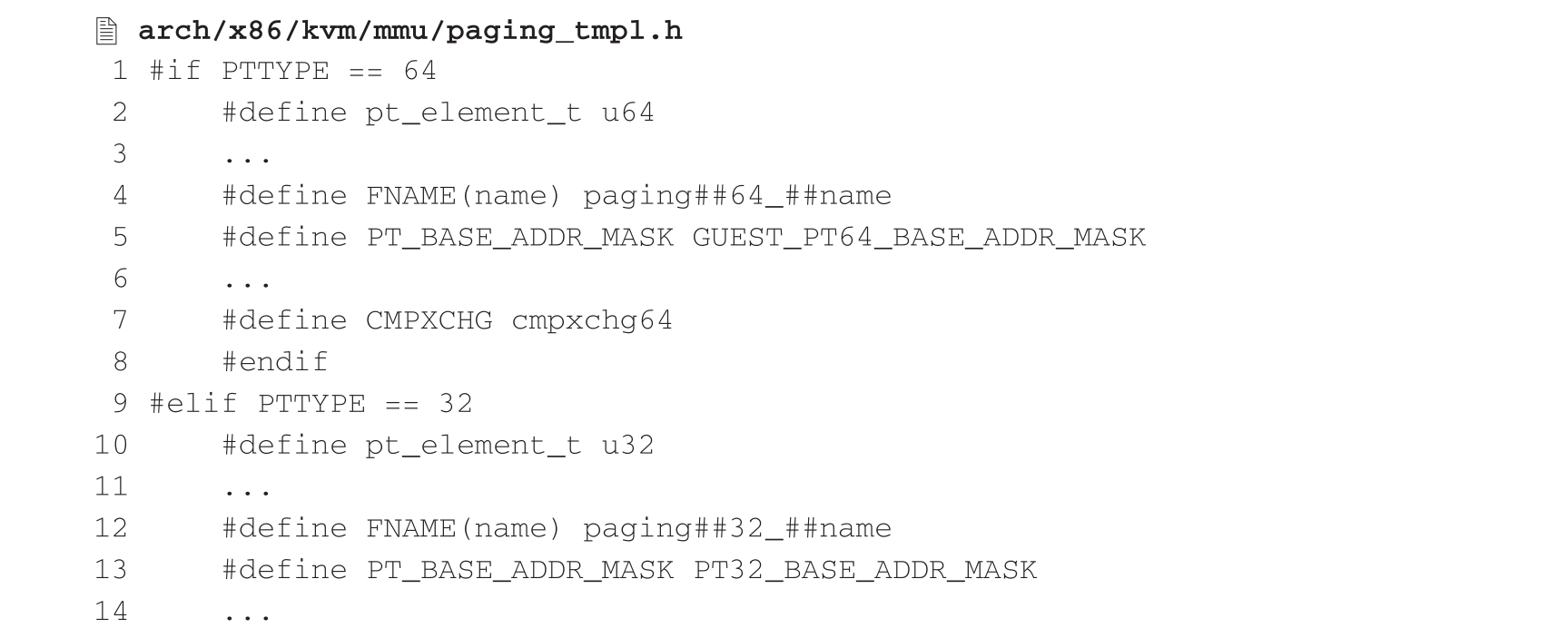

在为各个模式实现回调函数之后,KVM会在初始化阶段将mmu指针指向的一系列回调函数与所实现或生成的回调函数相关联。3.3.3节曾提到在kvm_arch_vcpu_create()中会调用kvm_init_mmu(),就是为了对这部分逻辑进行初始化,该函数会按照如图3-8所示的流程完成各分页模式的初始化任务。
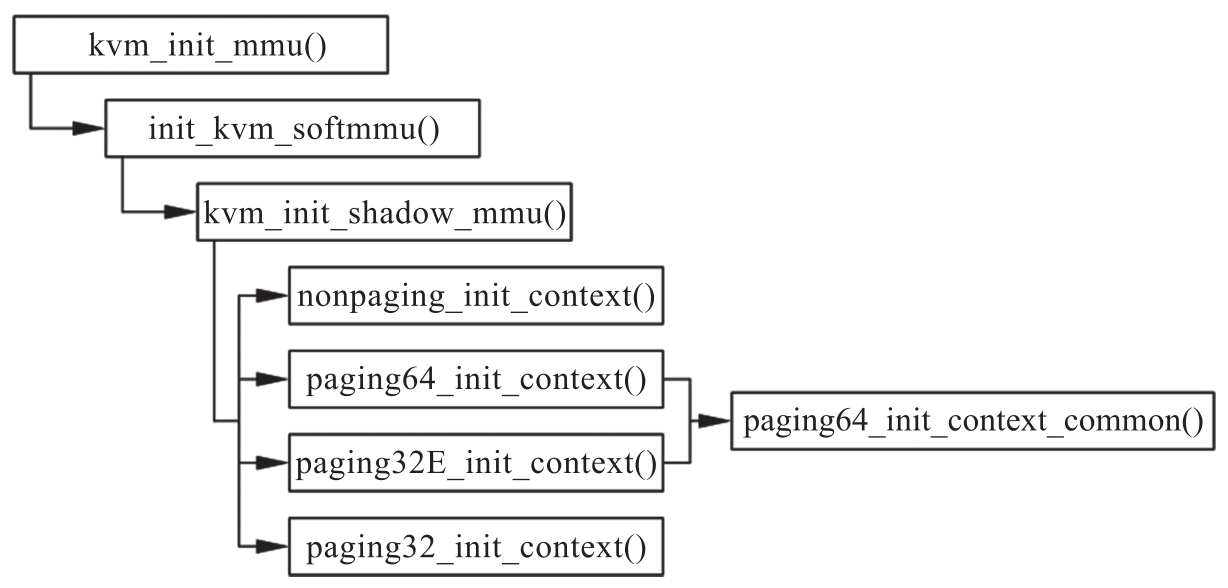
图3-8 软件完全虚拟化下的内存管理单元初始化流程
如果说为各个模式实现回调函数是编译时多态,即所谓静态多态,那么根据当前模式调用回调函数则是运行时多态,即所谓动态多态。从中我们体会到,多态是一种编程思想,它并不局限于面向对象语言,反而面向对象语言是从大量编程实践中不断汇集先进思想并最终应运而生的。
(2)EPT
读者不禁会问,客户机操作系统会运行多个进程,如果按照上述方案解决GVA到HPA映射的话,那么是不是意味着要为每个进程建立这样一张影子页表呢?结果不出所料。影子页表正是通过利用空间换取时间的方式,在宿主机的内核空间存储了大量客户机进程的影子页表,并在客户机进程切换时对相应影子页表进行切换的,当客户机进程数量逐渐增多时,其影子页表所占据的内存空间也会逐渐增大,并且切换管理所带来的开销也同样逐渐增大。
历史经验告诉我们,当在软件层面难以解决某类问题时,人们就自然想到从硬件层面去寻求解决途径。在这一领域,英特尔是走在技术前沿的厂商之一,于是EPT技术应运而生。2.1.2节中提到过,Intel VT-x的EPT技术,直接在硬件上支持GVA→GPA→HPA的两次地址转换,大大降低了内存虚拟化的难度,显著提高了内存虚拟化的性能。此外,为了充分发挥旁路转址缓冲区(Translation Lookaside Buffer,TLB)
的使用效率,VT-x还引入了虚拟处理器标识符(Virtual Processor ID,VPID)功能,进一步增强内存虚拟化的性能。
EPT的原理
图3-9描述了EPT的基本原理。在原有的CR3页表地址映射的基础上,EPT引入了EPT页表来实现另一次映射。这样,GVA→GPA→HPA两次地址转换都由CPU硬件自动完成。
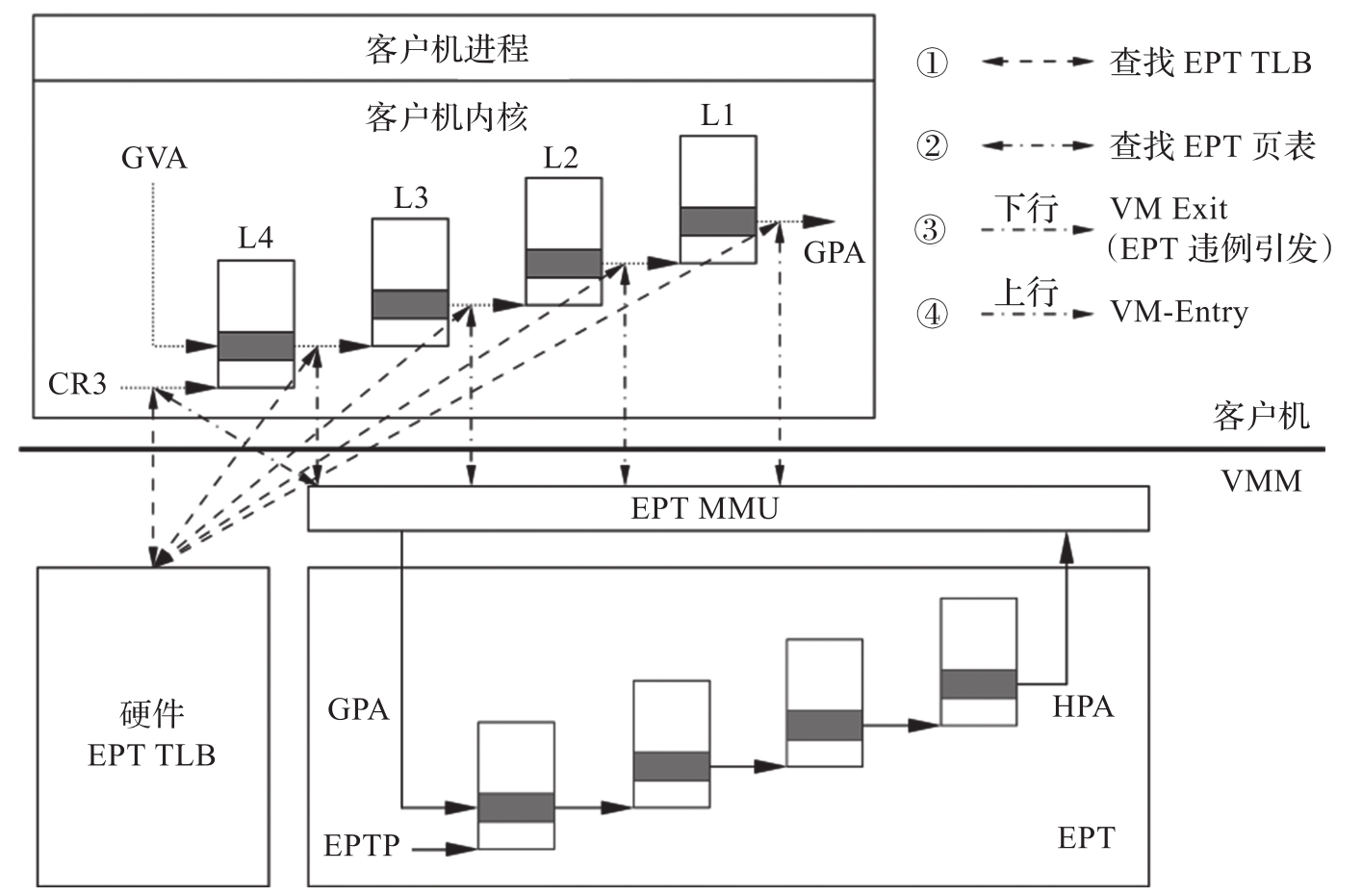
图3-9 EPT的基本原理
这里假设客户机页表和EPT页表都是四级页表,CPU完成一次地址转换的基本过程如下。
CPU首先会查找客户机CR3指向的L4页表。由于客户机CR3给出的是GPA,因此CPU需要通过EPT页表来实现客户机CR3的GPA到HPA的转换。CPU首先会查看硬件的EPT TLB,如果没有对应的转换,CPU会进一步查找EPT页表,如果还没有,则CPU抛出EPT违例(EPT Violation)异常交由VMM来处理。
获得L4页表地址后,CPU根据GVA和L4页表项的内容来获取L3页表项的GPA。如果L4页表中GVA对应的表项显示为“缺页”,那么CPU产生页面错误(Page Fault,PF),直接交由客户机内核处理。注意,这里不会产生VM Exit。获得L3页表项的GPA后,CPU同样要通过查询EPT页表来实现L3的GPA到HPA的转换,过程和上面一样。
同样地,CPU会依次查找L2、L1页表,最后获得GVA对应的GPA,然后通过查询EPT页表获得HPA。从上述过程可以看出,CPU需要查询EPT页表5次,每次查询都需要4次内存访问,因此最坏情况下总共需要20次内存访问。EPT硬件通过增大EPT TLB来尽量减少内存访问次数。
EPT的硬件支持
为了支持EPT,VT-x规范在VMCS的VM执行控制域(VM-Execution Control Field)中提供了启用EPT(Enable EPT)字段。如果在VM-Entry的时候该字段被置位,EPT功能就会被启用,CPU会使用EPT功能进行两次转换。
EPT页表的基地址是由VMCS的VM执行控制域的扩展页表指针(Extended Page Table Pointer,EPTP)字段来指定的,它包含了EPT页表的宿主机物理地址。
EPT是一张多级页表,每级页表的表项格式是相同的,如表3-3所示。
表3-3 EPT页表的表项格式

EPT页表转换过程和CR3页表转换是类似的。图3-10展现了CPU使用EPT页表进行地址转换的过程。
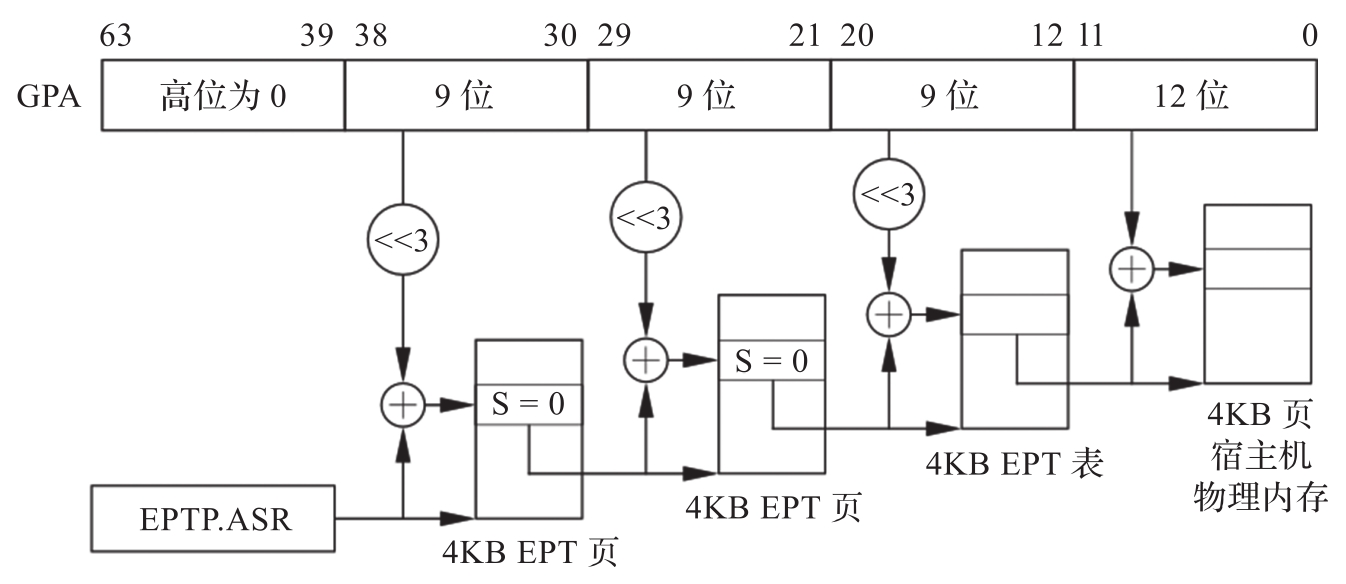
图3-10 CPU使用EPT页表进行地址转换的过程
EPT通过EPT页表中的SP字段支持大小为2MB或者1GB的超级页。图3-11给出了2MB超级页的地址转换过程。与图3-10的不同点在于,当CPU发现SP字段为1时,就停止继续向下遍历页表,而是直接转换。
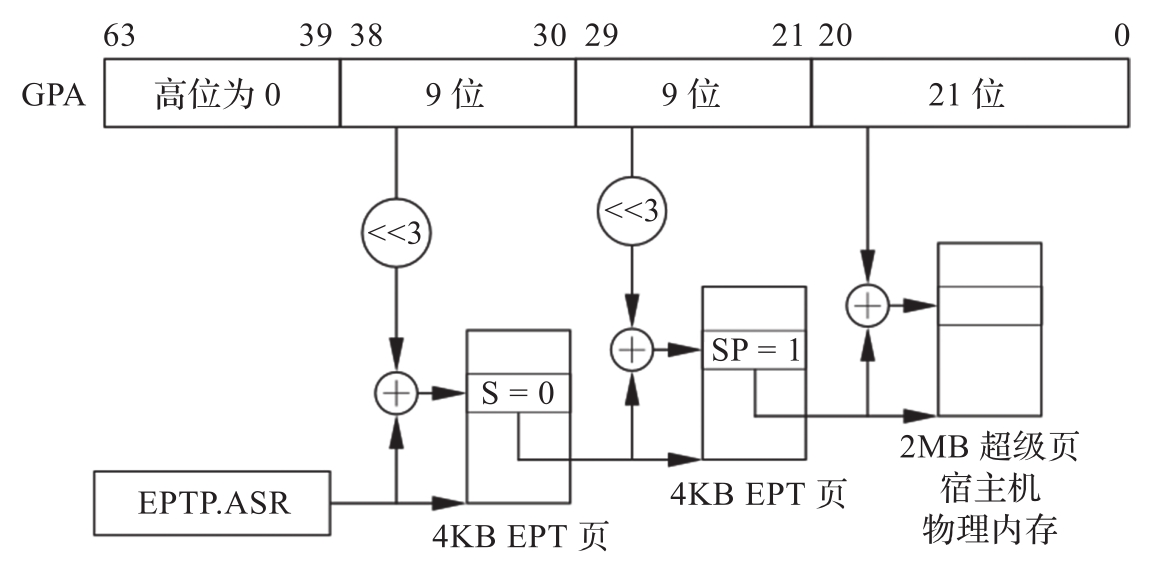
图3-11 EPT页表转换——超级页
EPT同样会使用TLB缓存来加速页表的查找过程。因此,VT-x还提供了一条新的指令INVEPT,可以使EPT的TLB项失效。这样,当EPT页表有更新时,CPU可以执行INVEPT使旧的TLB失效,让CPU使用新的EPT表项。
与CR3页表会导致页面错误一样,使用EPT之后,当CPU在遍历EPT页表进行GPA→HPA转换时,也会发生异常。
●GPA的地址位数大于客户机地址宽度(Guest Address Width,GAW)。
●客户机试图读一个不可读的页(R=0)。
●客户机试图写一个不可写的页(W=0)。
●客户机试图执行一个不可执行的页(X=0)。
发生异常时,CPU会产生VM Exit,退出原因为EPT违例。VMCS的VM Exit信息域(VM Exit Information Field)还包括如下信息。
●VM Exit物理地址信息(VM Exit Physical Address Information):引起EPT违例的GPA。
●VM Exit线性地址信息(VM Exit Linear Address Information):引起EPT违例的GVA。
●触发条件(Qualification):引起EPT违例的原因,如由读写引起等。
EPT的软件使用
要使用EPT,VMM需要做如下事情。
首先需要在VMCS中将EPT功能打开,只需要写VMCS相应字段即可。
其次需要设置好EPT的页表。EPT页表反映了GPA到HPA的映射关系。由于是VMM负责给虚拟机分配物理内存,因此,VMM拥有足够的信息来建立EPT页表。此外,如果VMM给虚拟机分配的物理内存足够连续,VMM可以在EPT页表中尽量使用超级页,这样有利于提高TLB的性能。
当CPU开始使用EPT时,VMM还需要处理EPT违例。EPT违例的来源通常有如下几种。
●客户机访问MMIO地址。这种情况下,VMM需要将请求转给I/O虚拟化模块。
●EPT页表的动态创建。有些VMM采用惰性方法,一开始EPT页表为空,当第一次使用发生EPT违例的时候再建立映射。
下面重点看一下KVM的EPT内存管理单元的初始化实现,这里EPT所采用的模式被称为两级页映射(Two-Dimensional Paging,TDP)模式。在介绍影子页表的内存管理单元初始化流程时,我们提到了kvm_init_mmu()函数,当时调用了init_kvm_softmmu()函数来进行初始化,与之对应的EPT的初始化是init_kvm_tdp_mmu(),其代码如下:


在调用上述函数之前,KVM会首先通过hardware_setup()函数调用setup_vmcs_config()(arch/x86/kvm/vmx/vmx.c)将Enable EPT字段置位,该字段位于基于处理器的虚拟机运行辅助控制域(Secondary Processor-Based VM-Execution Control)的第1位;当然,辅助控制域有效的前提是基于处理器的虚拟机运行基础控制域(Primary Processor-Based VM-Execution Control)的第31位被置位,它也是在setup_vmcs_config()函数中预先设置生效的。
在init_kvm_tdp_mmu()中,KVM通过设置kvm_tdp_page_fault()回调函数来处理EPT违例,并在处理过程中逐渐形成EPT页表。该回调函数主要通过调用direct_page_fault()来完成缺页处理,direct_page_fault()进而调用函数__direct_map()来建立EPT页表结构,而每个EPT页表项所使用的数据结构正是前面讲述影子页表时特别强调过的kvm_mmu_page。因此,EPT的实现是在影子页表的代码框架基础上完成的。有关direct_page_fault()的处理流程将后面进行详细描述。
然后,KVM通过kvm_mmu_get_tdp_level()函数获取EPT页表的级数,该级数最终是通过读取VMX能力MSR中的IA32_VMX_EPT_VPID_CAP获得的,一般系统默认为4级。最后在不同的模式下,我们再次看到了似曾相识的回调函数,如paging64_gva_to_gpa()等。的确如此,EPT正是沿用了前面深入讨论的各个模式下回调函数通用模板来完成GVA到GPA的转换的。
由此可以看出,相对于传统的“影子页表”方法,EPT的实现大幅简化。而且,由于客户机内部的页面错误不会发生VM Exit,因此大大减少了VM Exit的次数,提高了性能。此外,EPT只需要维护一张EPT页表,不像“影子页表”机制那样需要为每个客户机进程的页表维护一张影子页表,也减少了内存的开销。
至此,我们通过以上两个章节清晰地再现了KVM内存虚拟化从影子页表到EPT的演进历程。虽然目前EPT技术已经成熟,但尚有一些应用场景依然使用影子页表的方案,因此KVM保留着两种不同的方式,展现了软件完全虚拟化和硬件辅助虚拟化两种截然不同的实现方案,在运行时会通过环境检测优先选择后者,并提供编译选项由用户指定转换方式。
如果说内存槽是穿梭于宿主机与客户机两岸间的江上扁舟,那么影子页表就是通过这些船只运送材料架设而成的跨江大桥,而EPT则是桥上风驰电掣的高速动车。这让我们不禁感慨于虚拟化技术在征服虚拟机到物理机之间的“天堑”的过程中日新月异的发展。
3.KVM页面错误的处理流程
在客户机运行过程中,当需要访问的GPA在对应的页表中不存在时,则会产生页面错误从而发生VM Exit。这时CPU切换至根模式,由KVM负责建立GPA到HPA之间的映射关系。
从本节前面的内容得知,KVM的内存虚拟化实现有两种模式,即EPT和影子页表,相应地,KVM页面错误也分为两种:EPT违例和影子页表的页面错误(#PF)异常。当KVM运行于EPT所采用的TDP模式时,KVM首先会在kvm_init_mmu()中调用init_kvm_tdp_mmu()函数来初始化内存管理单元(Memory Management Unit,MMU),然后指定页面错误的回调处理函数为kvm_tdp_page_fault(),由该函数处理EPT违例引发的VM Exit;当KVM运行于影子页表的软件映射模式时,KVM则会调用init_kvm_softmmu()来初始化MMU,然后根据CPU操作模式指定诸如nonpaging_page_fault()、paging32_page_fault()或paging64_page_fault()等回调函数处理页面错误,此类函数有些正是由前面提到的通用模板所生成。
下面重点介绍第一种情况,即TDP模式下页面错误的处理流程。当发生EPT违例时,KVM首先根据VM Exit的触发条件计算引发EPT违例的原因,再通过VMCS获取引发EPT违例的GPA,然后触发回调函数kvm_tdp_page_fault(),其调用的direct_page_fault()函数将为虚拟机准备EPT页表,该函数主要流程如下。
1)先通过GPA计算出客户机页帧号(Guest Frame Number,GFN),然后调用try_async_pf()函数获取与GFN对应的宿主机物理页帧号(Physical Frame Number,PFN)及HVA,这两个数值是该函数调用__gfn_to_pfn_memslot()来获取的。顾名思义,这个函数的功能通过内存槽将GFN转换为PFN,主要分为两个步骤:一是通过__gfn_to_hva_many()函数调用__gfn_to_hva_memslot()遍历内存槽数组得到GFN对应的HVA,在前面的KVM内存虚拟化原理中,我们提到过内存槽,它是在虚拟机建立内存布局的过程中,用户态VMM通过调用kvm_vm_ioctl(KVM_SET_USER_MEMORY_REGION)来设置GPA到HVA之间的映射关系并存放在内存槽数组中的;二是将获得的HVA通过hva_to_pfn()函数转换为与之对应的宿主机PFN,该函数按不同情况下获取PFN的执行效率高低设计了三条路径,优先尝试高效路径是否可行,如果通过某条路径能够成功获得结果就不再执行后续方案,各路径最终均会调用get_user_pages()或其等价函数来获取HVA对应的内存页面,并调用page_to_pfn()函数返回宿主机PFN。
2)调用__direct_map()或者kvm_tdp_mmu_map()函数,根据GPA和HPA准备好客户机系统要使用的EPT页表。两个函数都是用于TDP模式下MMU建立EPT页表结构从而完成GPA→HPA映射的,其核心算法都是根据GPA遍历当前的EPT页表,当遍历至中间层级的页表项时,将下一级页表起始HPA填入,如果遍历至叶子页表项则填入GPA所对应的HPA。不同的是,两个函数分别隶属于两套不同的TDP模式MMU引擎。前者是基于影子页表机制框架衍生而来的实现方案,虽然影子页表与EPT机制相去甚远,但在KVM中建立GPA→HPA转换页表的过程却十分相似,因此该方案的实现沿用了影子页表的数据结构和主要函数,仅在建立转换页表时利用了EPT机制才产生分化;后者则是针对TDP模式MMU进行的优化,实现该方案是为了满足超大型虚拟机能够并行处理页面错误。与前者相比,后者具有更高的并行性和可扩展性,该方案能够得以实施的先决条件之一得益于Linux内核中的一个同步机制:读取-复制更新(Read-Copy Update,RCU
)。借助该机制,诸多MMU相关函数被重新实现,进一步满足了具有数百个虚拟CPU和十几TB内存的虚拟机实现热迁移的性能需求,在最新的KVM版本中已经取代前者成为默认的TDP模式MMU引擎。
3)在EPT页表准备完成后会再次进入客户机系统,并重新执行导致EPT违例的指令。由于此时KVM已经为其准备好从GPA到HPA的映射关系,从而保证客户机系统可以正常运行。
中断是指当紧急事件发生时CPU收到信号,立即中止当前指令流,转入相应的处理程序执行其他指令,处理完成后再回到之前的指令流继续执行。当有多个外部中断源时,它们将共享中断资源,由此会引发共享带来的一系列问题,如多个中断源如何与CPU的INTR输入端连接、如何区别中断向量、如何判定各个中断源的优先级等,我们把上述管理和判定等操作都交由专门的模块——中断控制器来完成。中断控制器是设备中断请求的管理者,它可以帮助CPU处理可能同时发生的来自多个不同中断源的中断请求。
x86架构所采用的中断控制器被称为高级可编程中断控制器(Advanced Programmable Interrupt Controller,APIC)。APIC中有两个组件,即本地APIC(Local APIC,LAPIC)和输入/输出APIC(Input/Output APIC,I/O APIC)。系统中的每个CPU有一个LAPIC。LAPIC具有传统中断控制器的功能及相关寄存器,如中断请求寄存器(Interrupt Request Register,IRR)、中断在服寄存器(In-Service Register)和中断屏蔽寄存器(Interrupt Mask Register,IMR)。外部I/O APIC是英特尔系统芯片组的一部分,它的主要功能是从系统及其关联的I/O设备接收外部中断事件,并将它们作为中断消息中继到LAPIC。系统中的每个外设总线通常都有一个I/O APIC,所有的CPU共用该I/O APIC,用于统一接收来自外部I/O设备的中断。下面着重介绍LAPIC。
LAPIC主要为处理器完成以下两个功能。
●从处理器的中断引脚、内部源和外部I/O APIC(或其他外部中断控制器)接收中断,将这些中断发送到处理器内核进行处理。
●在多处理器系统中,向系统总线上的其他逻辑处理器发送处理器间中断(Inter-Processor Interrupt,IPI)消息并接收其他逻辑处理器的IPI消息。IPI消息可用于在系统中的处理器之间分配中断或执行系统范围的功能,如启动处理器或在一组处理器之间分配工作。
LAPIC的中断来源可以分为以下几类。
●外部连接的I/O设备
●处理器间中断
●APIC定时器产生的中断
●性能监测计数器中断
●温度传感器中断
●APIC内部错误中断
英特尔起初为了支持多核处理器,第一代LAPIC采用了APIC架构,通过专门的APIC总线与I/O APIC进行通信以及完成处理器间中断;之后便出现了xAPIC,xAPIC架构是APIC架构的扩展,在xAPIC架构中,LAPIC和I/O APIC通过系统总线进行通信,此外,xAPIC架构还扩展和修改了部分APIC功能;继xAPIC之后,又出现了x2APIC,x2APIC架构是对xAPIC架构的再次扩展,主要是为了提高处理器的寻址能力,从而能够实现超过256核的CPU之间的通信。x2APIC架构提供对xAPIC架构的向后兼容性及对未来英特尔平台的向前扩展性。由此形成了对中断控制器的两种操作模式:xAPIC模式和x2APIC模式。在xAPIC模式下,通过对内存映射输入/输出(Memory-Mapped I/O,MMIO)的访问方式来访问LAPIC上的寄存器;在x2APIC模式下,则通过对MSR的访问方式来对LAPIC上的寄存器进行访问。
在介绍了APIC的基本概念之后,下面简要阐述中断虚拟化的基本原理。
在虚拟化技术中,虚拟CPU要么共享物理CPU的真实硬件,附加必要的隔离保护措施,要么使用虚拟硬件。对于APIC部分,因为其硬件逻辑复杂,所以使用虚拟APIC来进行中断虚拟化。由于虚拟机并不具备真实的硬件单元,因此客户机对中断控制器的读写访问只能由VMM拦截后做特殊处理,并且,虚拟的中断控制器与物理CPU之间没有任何线路连接。这样问题也就随之而来,客户机APIC的处理逻辑可以由软件来模拟,但如何将中断传递给客户机CPU?虚拟CPU在没有运行时中断事件暂时记录在哪里?外部中断到来时是由宿主机处理还是由客户机处理?
首先,客户机操作系统在对中断控制器进行读写访问时,VMM会对这些访问操作进行拦截,发生VM Exit,之后再由VMM将对应的信息写入虚拟中断控制器,进而判断如何响应虚拟设备的中断。其次,英特尔x86架构处理器在EFLAGS寄存器中的虚拟中断标志位(Virtual Interrupt Flag,VIF)和虚拟中断待决标志位(Virtual Interrupt Pending,VIP)共同提供了对虚拟中断的支持,VIP置位时表示有中断待处理,复位时表示没有待处理的中断,这些标志位的结合使用可以解决虚拟CPU未运行时记录中断事件的问题。另外,英特尔在VT-x中引入的VMCS为支持中断虚拟化提供了相应的控制域,外部中断退出(External-Interrupt Exiting)控制域用于确定外部中断由谁来处理,如果该控制位为1,则外部中断会导致VM Exit,然后由宿主机操作系统进行处理;否则,外部中断将通过客户机的中断描述符表(Interrupt Descriptor Table,IDT)直接传递给客户机操作系统进行处理。
当虚拟设备完成相应的操作后,VMM需要给客户机的CPU注入中断,要通知客户机系统进行后续的操作。VM-Entry中断信息域(VM-Entry Interruption-Information Field)为事件注入(Event Injection)机制提供了可控性保障。如果VMCS中置位了中断标志,VMM执行VMRESUME指令后客户机不会继续执行先前任务而是立即处理中断;如果对应的虚拟CPU正在另外的物理CPU上运行,仍先将中断写入VMCS中,然后向物理CPU发送IPI中断,这时物理CPU会从非根模式切换至根模式,接着通过检测IPI信息得知是虚拟CPU的中断,再通过VMM执行VMRESUME指令重新触发VM-Entry,这样利用事件注入机制将中断传递给虚拟CPU。
这里仅通过以上几个典型的场景简要介绍中断虚拟化的基本原理,限于篇幅,在此不做详细阐述。
在VMM中以软件方式实现APIC虚拟化势必造成VM Exit次数过多,客户机运行性能较差,硬件辅助中断虚拟化因此应运而生。APICv是英特尔目前所提供的硬件辅助中断虚拟化技术,旨在减少客户机运行时的中断开销。APICv主要完成如下功能。
●APIC寄存器虚拟化(APIC Register Virtualization):启用VMCS中的这个控制位,大部分客户机APIC寄存器会被映射至内存,当客户机操作系统对该内存中的地址空间进行读取时,APICv会在硬件层面将虚拟APIC页面的相应内容返回,从而减少了读取过程中的VM Exit次数。APIC访问页面也会被映射至内存,当客户机对该内存地址进行写入时,APICv同样会将写入操作定向至虚拟APIC页面,但由于对LAPIC的写操作会触发一些硬件的操作,比如ICI写操作,此时就会产生VM Exit,进而往其他虚拟CPU注入虚拟的IPI中断。这里的APIC访问页面和虚拟APIC页面的地址在VMCS中均有相应域进行记录,由于VMCS是与虚拟CPU相关联的,因此确保每个虚拟CPU可以访问到各自虚拟APIC地址上的数据。此类操作在中断虚拟化过程中非常频繁,有了APICv的硬件支持可以减少VM Exit的次数,很大程度上提升了客户机运行的性能。
●虚拟化x2APIC模式(Virtualize x2APIC Mode):在上述功能完成后,xAPIC模式下的大部分APIC寄存器被虚拟化;再启用这个控制位,则x2APIC模式下的APIC寄存器都将被虚拟化,而该模式是基于MSR访问APIC的。
●虚拟中断递送(Virtual-Interrupt Delivery):启用该控制位并配置客户机状态区(Guest-State Area)的客户机中断状态(Guest Interrupt Status)控制域,完成对新中断注入的流程。
●处理已发布的中断(Process Posted Interrupt):该控制位允许软件发布虚拟中断并向另一个虚拟CPU发送通知;目标虚拟CPU收到通知后,将虚拟中断复制到虚拟APIC页面,然后对已发布的中断(Posted Interrupt)进行处理。借助APICv的支持,不需要目标虚拟CPU发生VM Exit就可以向其注入中断。另外,Posted Interrupt提供了一个机制,允许外部的PCI MSI中断直接注入虚拟机,而不会导致目标虚拟CPU产生VM Exit。
下面就KVM中断虚拟化的实现进行扼要分析。在KVM中有一个专有名词——中断请求芯片(Interrupt Request Chip,IRQ Chip),该模块相关的接口有KVM_CREATE_IRQCHIP和KVM_IRQ_LINE等。
KVM_CREATE_IRQCHIP用于虚拟机在初始化阶段创建中断请求芯片,其主要任务如下:


当KVM接收到虚拟机相关联的IOCTL调用时,会由函数kvm_vm_ioctl()(virt/kvm/kvm_main.c)进行处理进而调用上面的kvm_arch_vm_ioctl()函数。从代码中不难看出,该函数在处理KVM_CREATE_IRQCHIP请求时主要完成了初始化PIC(8259芯片)和I/O APIC控制器模块、配置中断请求默认路由等任务。其中kvm_setup_default_irq_routing()(arch/x86/kvm/irq_comm.c)会以默认中断请求路由入口表作为参数依次调用函数kvm_set_irq_routing()(virt/kvm/irqchip.c)和setup_routing_entry(),最终调用下面的函数来完成路由配置,其核心操作是将各个类型控制器中断置位函数与该类型控制器路由入口进行绑定,以备后续发生中断请求时调用。

KVM_IRQ_LINE用于虚拟机向VMM的虚拟APIC发送中断请求,再由VMM将中断交付虚拟CPU处理,当kvm_vm_ioctl()函数被调用并处理KVM_IRQ_LINE请求时会调用kvm_vm_ioctl_irq_line()(arch/x86/kvm/x86.c),该函数调用下面的函数来完成中断注入,其核心任务正是根据控制器类型调用之前所绑定的中断置位函数。这些中断置位函数最终会将中断请求写入虚拟CPU的VMCS中。
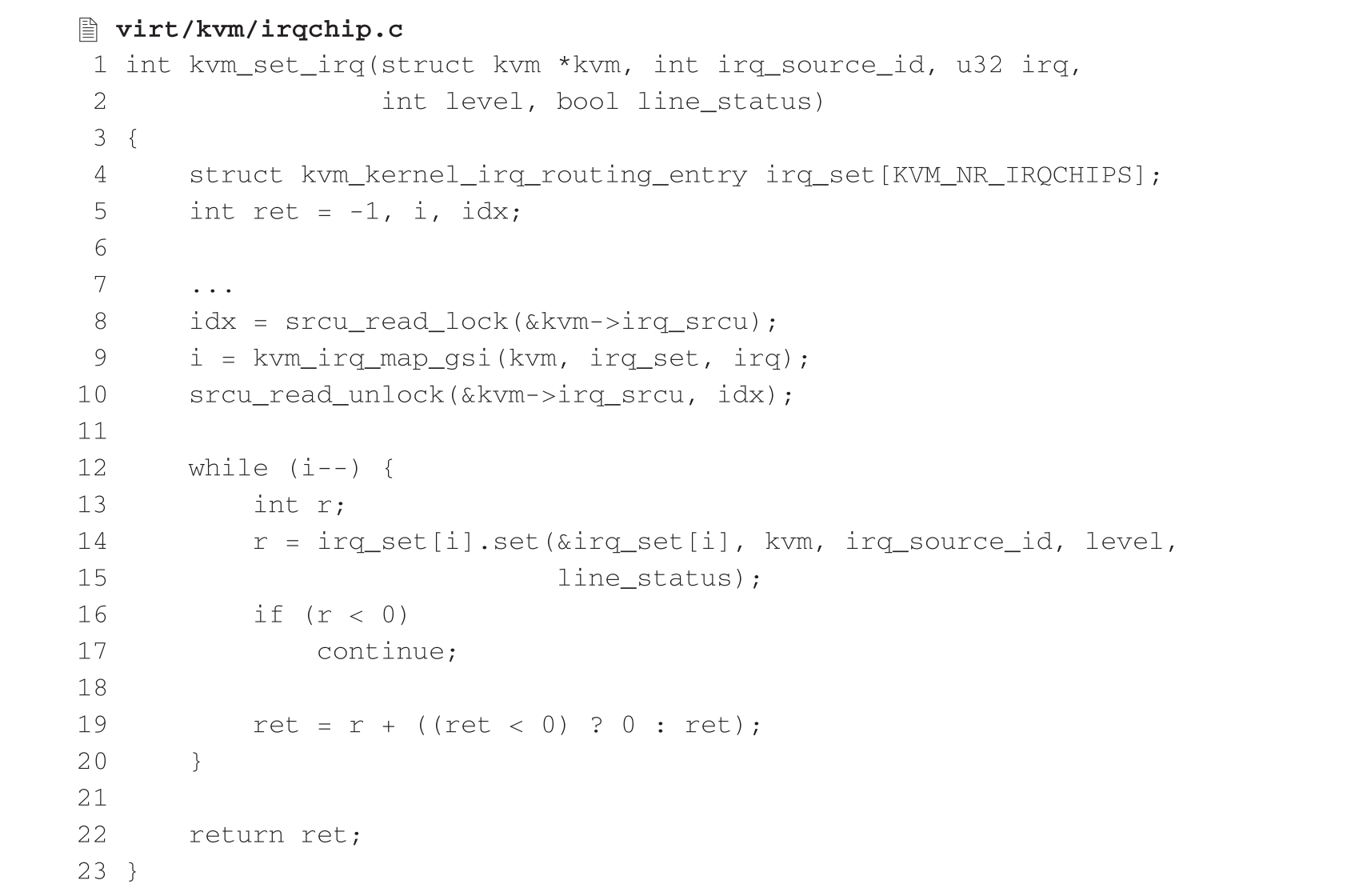
这里之所以循环遍历设置而不直接调用相应的执行函数,是因为KVM无法检测客户机所使用的是PIC还是I/O APIC,将两者进行置位操作,客户机届时会自行忽略无效的中断注入。
当需要注入的中断为MSI类型时,则kvm_vm_ioctl()会处理KVM_SIGNAL_MSI类型的请求。kvm_send_userspace_msi()函数会根据传入的MSI消息类型,判断向哪个虚拟CPU发送对应的虚拟中断。具体的实现细节在kvm_set_msi()函数中。