
下载掌阅APP,畅读海量书库
立即打开



计算机科学基础主要是考试中所涉及的基础数学知识。本章在考纲中主要有以下内容:
● 计算机内数据的表示及运算(数的表示、非数值的表示)。
● 算术运算和逻辑运算(计算机的二进制数运算方法、逻辑代数运算)。
● 编码基础(检测与纠错、海明码、循环冗余码、哈夫曼编码)。
计算机科学基础考点如图1-1所示,用星级★标示知识点的重要程度。
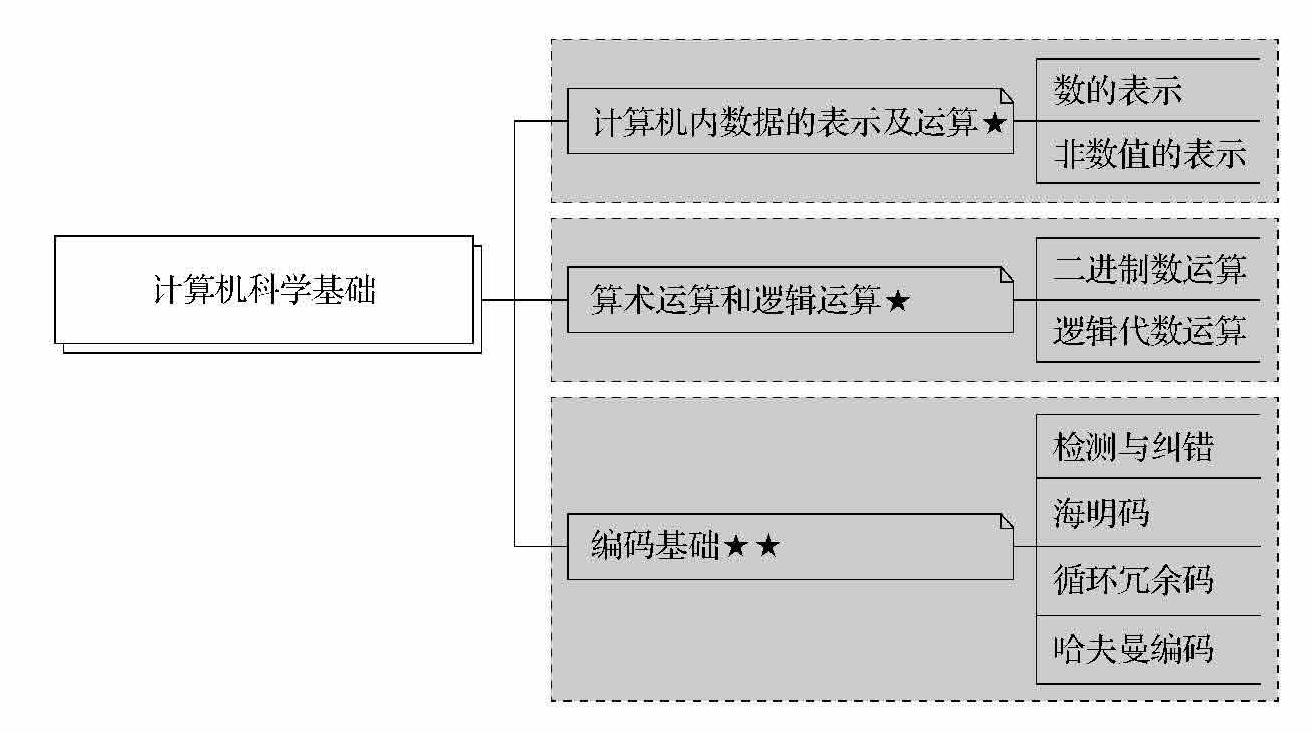
图1-1 计算机科学基础考点
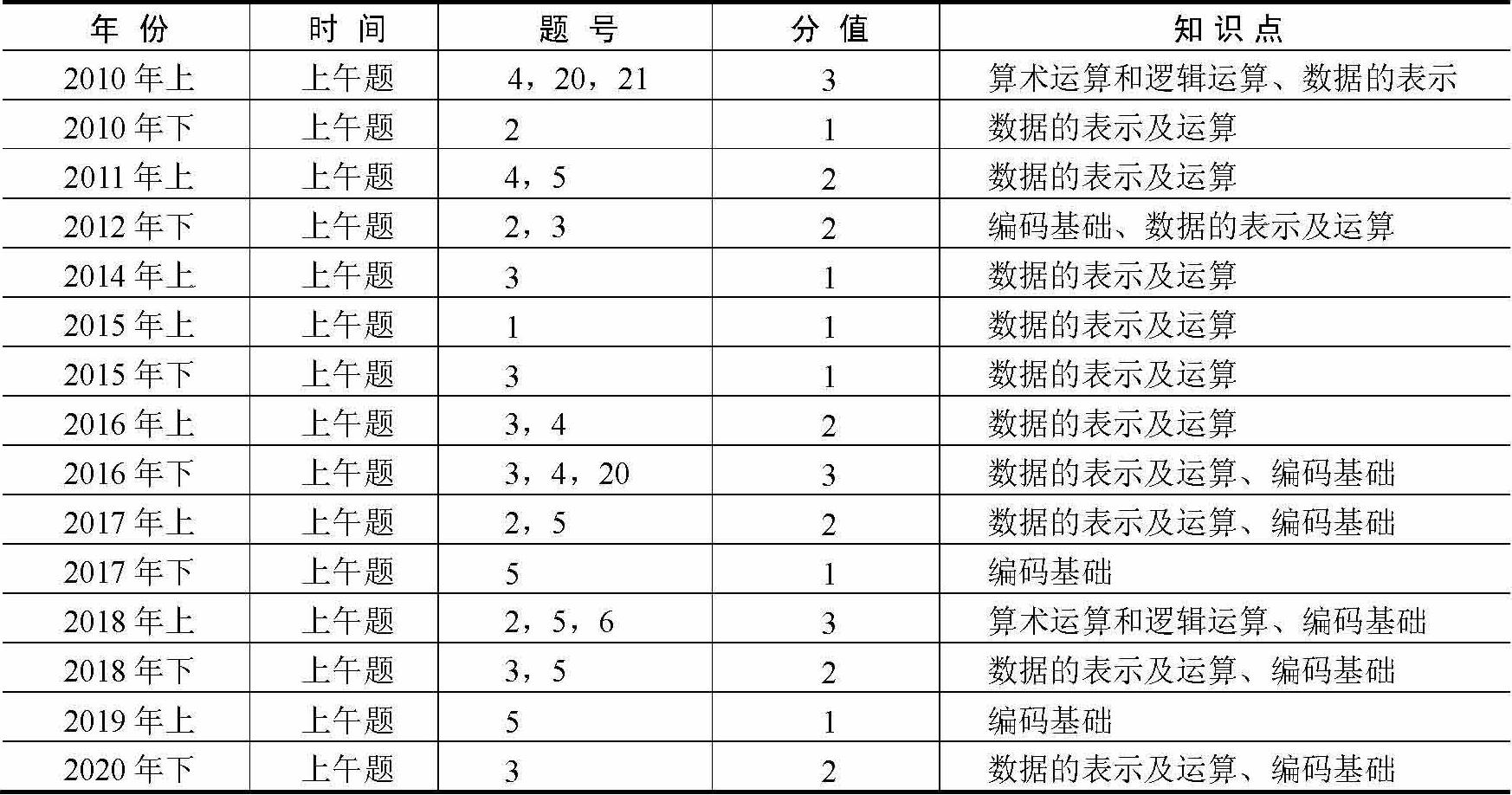
统计2010年至2020年试题真题,本章主要考点分值为1~3分。历年真题统计如表1-1所示。
表1-1 历年真题统计
1.1.3.1 数值及其转换
1.进位计数制
以十进制为例,十进制中采用0,1,2,3,4,5,6,7,8,9这10个数字来表示数据,逢十向相邻高位进一。每一位的位权都是以10为底的指数函数,由小数点向左,各数位的位权依次是10 0 ,10 1 ,10 2 ,10 3 ,…;由小数点向右,各数位的位权依次为10 -1 ,10 -2 ,10 -3 ,…。
N = a n ×10 n + a n -1 ×10 n -1 +…+ a 1 ×10 1 + a 0 ×10 0 + a -1 ×10 -1 +…+ a -m ×10 -m
数制的表示方法:为了区分不同进制的数,一般把具体数用括号括起来,在括号的右下角标上表示数制的数字。例如,(101) 2 与(101) 10 。
基数:所使用的不同基本符号的个数。
权:是基数的位序次幂。
2.十进制、二进制、十六进制、八进制的概念
● 十进制(D):由0~9组成,权为10 i ,计数时按逢十进一的规则进行,用(345.59) 10 或345.59D表示。
● 二进制(B):由0、1组成,权为2 i ,计数时按逢二进一的规则进行,用(101.11) 2 或101.11B表示。
● 十六进制(H):由0~9、A~F组成,权为16 i ,计数时按逢十六进一的规则进行,用(1A.C) 16 或1A.CH表示。
● 八进制(Q):由0~7组成,权为8 i ,计数时按逢八进一的规则进行,用(34.6) 8 或34.6Q表示。
总结:不同数制的表示方法有两种,一种是加括号及数字下标,另一种是数字后加相应的大写字母D、B、H、Q。
3.按权展开基本公式
设一个基数为 R 的数值 N , N =( d n -1 d n -2 … d 1 d 0 d -1 … d -m ),则 N 展开为 N = d n -1 × R n -1 + d n -2 × R n -2 +…+ d 1 × R 1 + d 0 × R 0 + d -1 × R -1 +…+ d -m × R -m 。
说明:( d n -1 d n -2 … d 1 d 0 d -1 … d -m )表示各位上的数字, R i 为权。
例如,十进制数2345.67展开为:2345.67=2×10 3 +3×10 2 +4×10 1 +5×10 0 +6×10 -1 +7×10 -2 。
4.二进制、八进制、十六进制转换为十进制的方法
(1)二进制转换为十进制的方法
(1011.011) 2 =(1×2 3 +0×2 2 +1×2 1 +1×2 0 +0×2 -1 +1×2 -2 +1×2 -3 ) 10 =(11.375) 10
(2)八进制转换为十进制的方法
(246) 8 =(2×8 2 +4×8 1 +6×8 0 ) 10 =(166) 10
(3)十六进制转换为十进制的方法
(2AB.C) 16 =(2×16 2 +10×16 1 +11×16 0 +12×16 -1 ) 10 =(683.75) 10
练习:①(11001) 2 =(25) 10
②(110110) 2 =(54) 10
③(165) 8 =(117) 10
④(207) 8 =(135) 10
⑤(2CF) 16 =(719) 10
⑥(59) 16 =(89) 10
总结: n 进制转换为十进制的方法是按权展开法(将 n 进制数按权展开相加即可得到相应的十进制数)。
5.十进制转换为二进制、八进制、十六进制的方法
(1)十进制转换为二进制的方法(除2取余逆排法)
例如,将十进制数236转换成二进制数的方法如下:
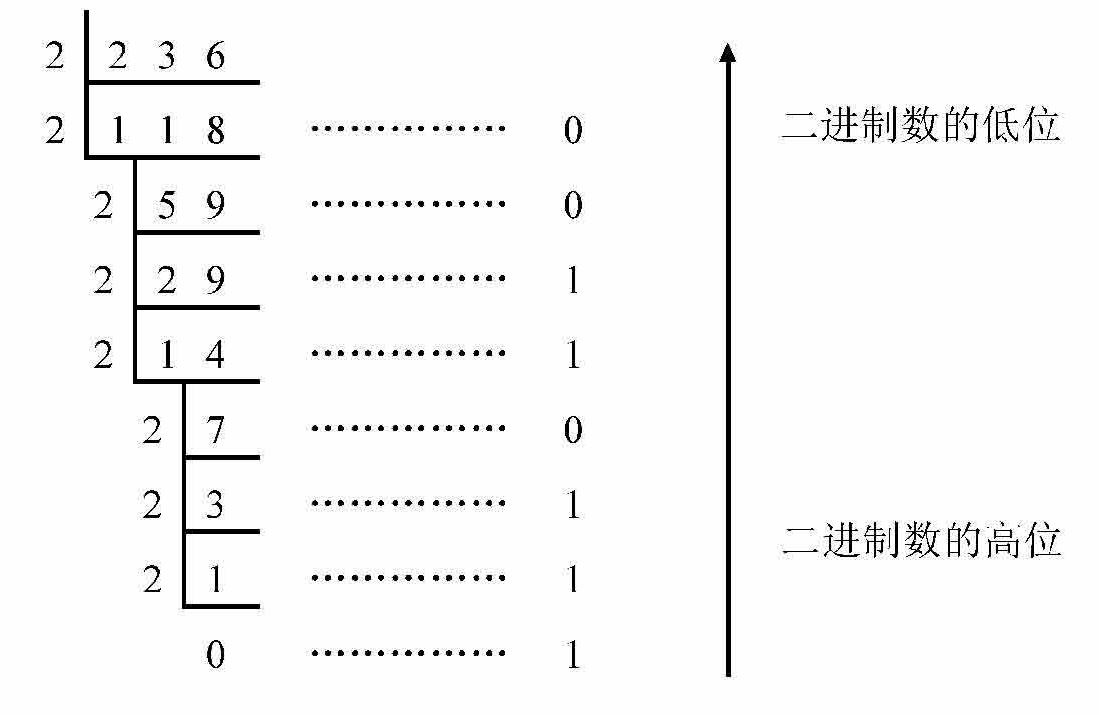
所以:(236) 10 =(11101100) 2 。
(2)十进制转换为八进制的方法(除8取余逆排法)
例如,将十进制数236转换成八进制数的方法如下:
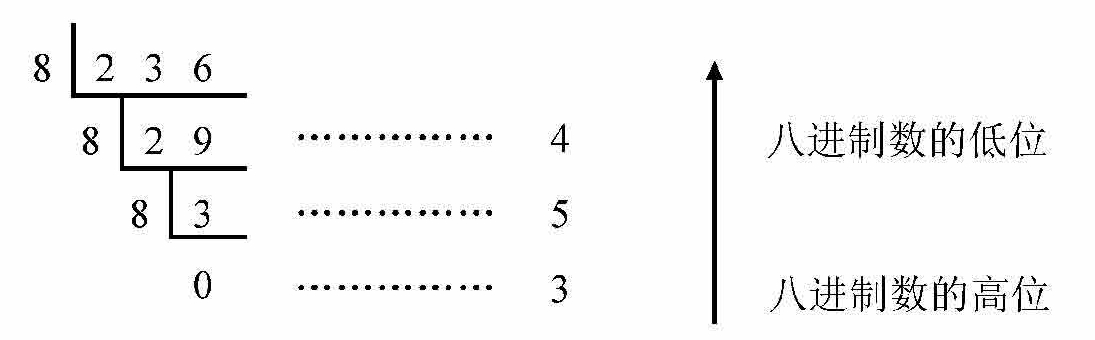
所以:(236) 10 =(354) 8 。
(3)十进制转换为十六进制的方法(除16取余逆排法)
例如,将十进制数236转换成十六进制数的方法如下:

所以:(236) 10 =(EC) 16 。
总结:十进制整数转换为 n 进制整数的方法(除 n 取余逆排法)说明如下。
将已知的十进制数的整数部分反复除以 n ( n 为进制数,取值为2、8、16,分别表示二进制、八进制和十六进制),直到商是0为止,并将每次相除之后所得到的余数按次序记下来,第一次相除所得余数 K 0 为 n 进制数的最低位,最后一次相除所得余数 K n -1 为 n 进制数的最高位。排列次序为 K n -1 K n -2 … K 1 K 0 的数就是换算后得到的 n 进制数。
6.二进制、八进制、十六进制整数之间的转换
首先,我们需要了解一个数学关系,即2 3 =8,2 4 =16,而八进制和十六进制是用这种关系衍生而来的,即用三位二进制数表示一位八进制数,用四位二进制数表示一位十六进制数。接着,记住4个数字8,4,2,1(2 3 =8,2 2 =4,2 1 =2,2 0 =1)。现在我们来练习二进制与八进制之间的转换。
(1)二进制整数转换为八进制整数
方法:取三合一法,即从二进制整数的最低位起,向左每三位取成一位,接着将这三位二进制数按权相加,得到的数就是一位八位二进制数,然后按顺序进行排列,得到的数字就是我们所求的八进制数。如果向左取三位后,取到最高位的时候无法凑足三位,可以在小数点最左边(最右边),即整数的最高位添0,凑足三位。
例1:将二进制数11001转换为八进制数。
(11001) 2 =( 011 , 001 ) 2 =(31) 8
得到结果:将二进制数11001转换为八进制数为31。
例2:将二进制数1101110转换为八进制数。
(1101110) 2 =( 001 , 101 , 110 ) 2 =(156) 8
得到结果:将二进制数1101110转换为八进制数为156。
(2)八进制数转换为二进制数
方法:取一分三法,即将一位八进制数分解成三位二进制数,用三位二进制数按权相加去凑这位八进制数,小数点位置不变。
例3:将八进制数67转换为二进制数。
(67) 8 =(6,7) 8 =(110111) 2
因此,得到结果:将八进制数67转换为二进制数为110111。计算八进制数转换为二进制数,首先将八进制数按照从左到右每位展开为三位,然后按每位展开为2 2 ,2 1 ,2 0 (即4,2,1)三位去凑数,即 a ×2 2 + b ×2 1 + c ×2 0 =该位上的数( a =1或者 a =0, b =1或者 b =0, c =1或者 c =0),将 a , b , c 排列就是该位的二进制数。接着,将每位转换成二进制数按顺序排列。最后,就得到了八进制转换成二进制的数字。
(3)二进制整数转换为十六进制整数
与二进制数转换为八进制数相似,只不过是一位(十六进制)与四位(二进制)的转换。方法:取四合一法,即从二进制的最低位起,向左每四位取成一位,接着将这四位二进制数按权相加,得到的数就是一位十六位二进制数,然后按顺序进行排列,得到的数字就是我们所求的十六进制数。
例4:将二进制数11101001转换为十六进制数。
(11101001) 2 =( 1110 , 1001 ) 2 =(E9) 16
得到结果:将二进制数11101001转换为十六进制数为E9。
例5:将二进制数101011101转换为十六进制数。
(101011101) 2 =( 0001 , 0101 , 1101 ) 2 =(15D) 16
得到结果:将二进制数101011101转换为十六进制数为15D。
(4)十六进制数转换为二进制数
方法:取一分四法,即将一位十六进制数分解成四位二进制数,用四位二进制数按权相加去凑这位十六进制数,小数点位置不变。
例6:将十六进制数6E2转换为二进制数。
(6E2) 16 =(6,E,2) 8 =( 0110 , 1110 , 0010 ) 2
得到结果:将十六进制数6E2转换为二进制数为11011100010。
(5)八进制数与十六进制数的转换
一般不能相互直接转换,而是先将八进制(或十六进制)数转换为二进制数,再将二进制数转换为十六进制(或八进制)数,小数点位置不变。相应的转换请参照前面二进制数与八进制数的转换和二进制数与十六进制数的转换。
1.1.3.2 数据的表示
1.定点数和浮点数的概念
在计算机中,数值型的数据有两种表示方法,一种叫作定点数,另一种叫作浮点数。所谓定点数,就是在计算机中所有数的小数点位置固定不变。定点数有两种:定点小数和定点整数。定点小数是将小数点固定在最高数据位的左边,因此它只能表示小于1的纯小数。定点整数是将小数点固定在最低数据位的右边,因此定点整数表示的也只是纯整数。由此可见,定点数表示数的范围较小。
为了扩大计算机中数值数据的表示范围,我们将12.34表示为0.1234×10 2 ,其中0.1234叫作尾数,10叫作基数(可以在计算机内固定下来)。2叫作阶码,若阶码的大小发生变化,则意味着实际数据小数点的移动,我们把这种数据叫作浮点数。由于基数在计算机中固定不变,因此,我们可以用两个定点数分别表示尾数和阶码,从而表示这个浮点数。其中,尾数用定点小数表示,阶码用定点整数表示。
在计算机中,无论是定点数还是浮点数,都有正负之分。在表示数据时,专门有1位或2位表示符号。对单符号位来讲,通常用“1”表示负号,用“0”表示正号;对双符号位来讲,则用“11”表示负号,“00”表示正号。通常情况下,符号位都处于数据的最高位。
2.定点数
对于定点数,在计算机中可用不同的码制来表示,常用的码制有原码、反码和补码三种。不论用什么码制来表示,数据本身的值并不发生变化,数据本身所代表的值叫作真值。下面我们就来讨论这三种码制的表示方法。
(1)原码
原码的表示方法为:如果真值是正数,则最高位为0,其他位保持不变;如果真值是负数,则最高位为1,其他位保持不变。
例7:写出13和-13的原码(取8位码长)。
解:因为13=(1101) 2 ,所以13的原码是00001101,-13的原码是10001101。
因此,原码的表示范围如下:
原码小数的表示范围:[+0] 原 =0.0000000,[-0] 原 =1.0000000。
最大值:1-2 -( n -1) 。
最小值:-(1-2 -( n -1) )。
表示数值的个数:2 n -1。
原码整数的表示范围:[+0] 原 =00000000,[-0] 原 =10000000。
最大值:2 ( n -1) -1。
最小值:-(2 ( n -1) -1)。
表示数值的个数:2 n -1。
采用原码的优点是转换非常简单,只要根据正负号将最高位置0或1即可。但原码表示在进行加减运算时很不方便,符号位不能参与运算,并且0的原码有两种表示方法:+0的原码是00000000,-0的原码是10000000。
(2)反码
反码的表示方法为:如果真值是正数,则最高位为0,其他位保持不变;如果真值是负数,则最高位为1,其他位按位求反。
例8:写出13和-13的反码(取8位码长)。
解:因为13=(1101) 2 ,所以13的反码是00001101,-13的反码是11110010。
因此,反码的表示范围如下:
n 位纯整数:-(2 n -1 -1)~2 n -1 -1。
n 位纯小数:-(1-2 -( n -1) )~1-2 -( n -1) 。
与原码相比较,反码的符号位虽然可以作为数值参与运算,但计算完后,仍需要根据符号位进行调整。另外,0的反码同样也有两种表示方法:+0的反码是00000000,-0的反码是11111111。
为了克服原码和反码的上述缺点,人们又引进了补码表示法。补码的作用在于能把减法运算化成加法运算,现代计算机中一般采用补码来表示定点数。
(3)补码
补码的表示方法为:若真值是正数,则最高位为0,其他位保持不变;若真值是负数,则最高位为1,其他位按位求反后再加1。
原码求补码:
正数:[ X ] 补 =[ X ] 原 。
负数:符号除外,按位取反,末位加1。
例9: X =-01001001
[ X ] 原 =11001001
[ X ] 补 =10110110+1=10110111
例10:写出13和-13的补码(取8位码长)。
解:因为13=(1101) 2 ,所以13的补码是00001101,-13的补码是11110011。
因此,补码的表示范围如下:
n 位纯整数:-2 n -1 ~2 n -1 -1。
n 位纯小数:-1~1-2 -( n -1) 。
在补码系统中,由于0有唯一的编码,因此 n 位二进制能表示2 n 个补码数。补码的符号可以作为数值参与运算,且计算完后,不需要根据符号位进行调整。另外,0的补码表示方法也是唯一的,即00000000。
3.浮点数
(1)浮点数表示
浮点数表示法类似于科学记数法,任意数均可通过改变其指数部分,使小数点发生移动,如数23.45可以表示为10 1 ×2.345、10 2 ×0.2345、10 3 ×0.02345等各种不同形式。浮点数的一般表示形式为 N =2 E × D ,其中, D 称为尾数, E 称为阶码。如图1-2所示为浮点数的一般形式。

图1-2 浮点数的一般形式
不同的机器对于阶码和尾数各占多少位、分别用什么码制进行表示有不同的规定。在实际应用中,浮点数的表示首先要进行规格化,即转换成一个纯小数与2 m (其中 m 为尾数位数)之积,并且小数点后的第一位是1。尾数用补码表示时,小数最高位应与浮点数 N 的符号位相反。 D 表示尾数。
正数应满足1/2≤ D <1,即0.1x…x。
负数应满足-1/2> D ≥-1,即1.0x…x。
例11:写出浮点数(-101.11101) 2 在计算机内的表示(阶码用4位原码表示,尾数用8位补码表示,阶码在尾数之前)。
解:(-101.11101) 2 =(-0.10111101) 2 ×2 3
阶码为3,用原码表示为0011。尾数为-0.10111101,用补码表示为1.01000011。因此,该数在计算机内表示为00111.01000011。
(2)浮点数的加减运算步骤
以一个例子来讲解, X =00.1011×2 3 , Y =00.1001×2 4 ,求 X + Y 。
浮点数的加减运算分为5步:
① 对阶。
把指数小的数( X )的指数(3)转化成和指数高的数( Y )的指数(4)相等,同时指数小的数( X )的尾数的符号位后面补两个数的指数之差的绝对值(1)个0。对于本例来说,就是把 X 变为00.01011×2 4 。
②尾数相加减。
尾数相加减为:
00.01011+00.1001=00.11101
这是相加,相减是把减数换成对应的补码再做相加运算。
③规格化。
当出现以下两种情况时需要进行规格化:
● 两个符号位不相同。两个符号位不同,说明运算结果溢出,此时要进行右规,即把运算结果的尾数右移一位。需要右规的只有两种情况:01×××和10×××。01×××右移一位的结果为001×××,10×××右移一位的结果为110×××。最后将阶码(指数)+1。
● 两个符号位相同,但是最高数值位与符号位相同。两个符号位相同,说明运算结果没有溢出,此时要进行左规,把尾数连续左移,直到最高数值位与符号位的数值不同为止。需要左规的有如下两种情况:111×××和000×××。111×××左移一位的结果为11×××0,000×××左移一位的结果为00×××0。最后将阶码(指数)减去移动的次数。
④舍入。
执行右规或者对阶时,有可能会在尾数低位上增加一些值,最后需要把它们移掉。比如说,原来参与运算的两个数(加数和被加数)算上符号位一共有6个数,通过上面三个操作后运算结果变成了8个数,这时需要把第7位和第8位的数去掉。如果直接去掉,会使精度受影响,通常有以下两种方法:
● 0舍1入法。
第一个例子:运算结果 X =00.11010111,假设原本加数和被加数算上符号位一共有6个数,结果 X 是10个数,那么要去掉后4个数(0111)。由于0111首位是0(即要去掉的数的最高位为0),这种情况下,直接去掉这4个数就可以。该例最后结果为 X =00.1101。
第二个例子:运算结果 Y =00.11001001,这时要去掉的数为1001四个数,由于这4个数的首位为1(即要去掉的数的最高位为1),这种情况下,直接去掉这4个数,再在去掉这4个数的新尾数的末尾加1。如果加1后又出现了溢出,继续进行右规操作。该例最后结果为 Y =00.1101。
● 置1法。这个比较简单,去掉多余的尾数,然后保证去掉这4个数的新尾数的最后一位为1(即是1不用管,是0改成1)即可。比如 Z =00.11000111,置1法之后的结果为 Z =00.11001。
⑤检查阶码是否溢出。
阶码溢出在规格化和右移的过程中都有可能发生,若阶码不溢出,则加减运算正常结束(即判断浮点数是否溢出,不需要判断尾数是否溢出,直接判断阶码是否溢出即可)。若阶码下溢,则置运算结果为机器0(通常阶码和尾数全置0)。若上溢,则置溢出标志为1。
1.1.3.3 非数值表示
非数值数据主要是指字符和汉字。
1.字符编码
字符主要是指西文字符(英文字母、数字、各种符号)。字符编码采用 ASCII(American Standard Code for Information Interchange,美国国家标准信息交换码)。ASCII采用7位二进制对常用的字符及其他符号(共128个)进行编码,其中包括可显示的大小写英文字母、阿拉伯数字及其他符号共95个,不可显示的“符号”(如回车、换行、响铃及各种控制字符)33个,数字字符、大写字母、小写字母都按各自的顺序依次排列。对应的大写字母、小写字母的ASCII码值相差20H。数字字符的ASCII码值和对应的十进制数字相差30H。例如十进制数字5、8对应的ASCII码值分别为35H、38H。
2.汉字编码
常见的汉字字符集编码说明如下:
1)GB2312编码:1981年5月1日发布的简体中文汉字编码国家标准。GB2312对汉字采用双字节编码,收录了7445个图形字符,其中包括6763个汉字。
2)BIG5编码:繁体中文标准字符集,采用双字节编码,共收录了13053个中文字,1984年实施。
3)GBK编码:1995年12月发布的汉字编码国家标准,是对 GB2312编码的扩充,对汉字采用双字节编码。GBK字符集共收录了21003个汉字,包含国家标准GB13000-1中的全部中、日、韩汉字和BIG5编码中的所有汉字。
4)GB18030编码:2000年3月17日发布的汉字编码国家标准,是对GBK编码的扩充,覆盖中文、日文、朝鲜语和中国少数民族文字,其中收录了27484个汉字。GB18030字符集采用单字节、双字节和四字节三种方式对字符编码,兼容GBK和GB2312字符集。
5)Unicode编码:国际标准字符集,它将世界各种语言的每个字符定义为一个唯一的编码,满足跨语言、跨平台的文本信息转换。Unicode采用四字节为每个字符编码。
6)UTF-8编码和UTF-16编码:Unicode编码的转换格式,可变长编码,相对于Unicode更节省空间。
1.1.3.4 算术运算和逻辑运算
1.算术运算
计算机中,常采用补码进行加减运算。补码可将减法变为加法进行运算。
补码运算的特点:符号位和数值位一同参加运算。
定点补码运算在加法运算时的基本规则如下:
[ X ] 补 +[ Y ] 补 =[ X + Y ] 补 (两个补码的和等于和的补码)
定点补码运算在减法运算时的基本规则如下:
[ X ] 补 -[ Y ] 补 =[ X ] 补 +[ -Y ] 补 =[ X-Y ] 补
例12:已知机器字长 n =8, X =44, Y =53,求 X + Y 。
解:[ X ] 原 =00101100,[ Y ] 原 =00110101。
[ X ] 补 =00101100
[ Y ] 补 =00110101
[ X ] 补 +[ Y ] 补 =00101100+00110101=01100001
X + Y =+97
例13:已知机器字长 n =8, X =-44, Y =-53,求 X + Y 。
解:[44] 补 =00101100
[53] 补 =00110101
[ X ] 补 =[-44] 补 =11010011+1=11010100
[ Y ] 补 =[-53] 补 =11001010+1=11001011
[ X + Y ] 补 [ X ] 补 +[ Y ] 补 =11010100+11001011=110011111(超出8位,舍弃模值)
X + Y =-01100001
X + Y =(-97) 10
2.逻辑运算
(1)与逻辑
当决定某一事件的所有条件都具备时,事件才能发生。 Y = A · B 真值表如表1-2所示。
表1-2 Y = A · B 真值表

(2)或逻辑
当决定某一事件的一个或多个条件满足时,事件便能发生。 Y = A + B 真值表如表1-3所示。
表1-3 Y = A + B 真值表

(3)非逻辑
条件具备时,事件不能发生;条件不具备时,事件一定发生。
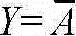 真值表如表1-4所示。
真值表如表1-4所示。
表1-4
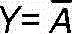 真值表
真值表

(4)移位运算
<<(左移):右边空出的位置补0,其值相当于乘以2。例如3<<2,即将数字3左移2位。计算过程是:首先把3转换为二进制数字0011,然后把该数字高位(左侧)的两个0移出,其他的数字都向左平移2位,最后在低位(右侧)的两个空位补零。得到的最终结果是1100,转换为十进制是12。
>>(右移):左边空出的位,若为正数则补0,若为负数则补0或1,取决于所用的计算机系统。按二进制形式把所有的数字向右移动对应位移位数,低位移出(舍弃),高位的空位补符号位,即正数补零,负数补1。其值相当于除以2。例如,11>>2是将数字11右移2位。计算过程是:11的二进制形式为1011,然后把低位的最后两个数字移出,因为该数字是正数,所以在高位补零。得到的最终结果是000010,转换为十进制是2。
1.1.3.5 编码基础
1.数据校验
在数据传输或者存储的过程中,会受到外界的干扰(电路故障或者噪声等),有可能导致某位或多位错误。所以校验是非常有必要的,要再添加额外的冗余码,也称校验位。
发送出来的信息就是有效信息( k 位)+校验信息( r 位)。
码距:与二进制位有关,任意两个合法编码的二进制位之间不同的位数。比如对于一套编码000000111111,第一个数(0000)和第二个数(0011)后两位的二进制位不同,所以对于前两个数来说码距是2。同理,后两个数(0011和1111)之间的码距也是2。对于第一个数(0000)和第三个数(1111),码距就是4。但是注意,码距是最小值,所以这套编码的码距就是2。
码距的检查:拿上面那套编码来说,本来编码出来是0000,但是传输过程中有一位发生错误,编码变成了0001,一看编码里面没有这种编码,所以就是无效的编码,就知道有一位错了。码距为1时无法识别一位错误,因为任何一种错误都是有效编码。
2.奇偶校验
采用增加一位校验位的方法。在添加一位校验位后,使得整个数据中1的个数呈现奇偶性。奇偶校验其实是奇校验和偶校验的合称。
(1)奇校验
就是让原有数据序列中(包括要加上的一位)1的个数为奇数,如1000110(0),因为原来有3个1,已经是奇数了,所以奇校验的位数为0,保证1的个数还是奇数。
(2)偶校验
就是让原有数据序列中(包括要加上的一位)1的个数为偶数,如1000110(1),因为原来有3个1,要想1的个数为偶数,就只能让偶校验的位数为1。
我们把传送过来的1100111000逐位相加就会得到1,应该注意的是,如果在传送中1100111000变成0000111000,通过上面的运算也将得到1,接收方就会认为传送的数据是正确的,这个判断正确与否的过程称为校验。而使用上面的方法进行的校验称为奇校验,奇校验只能判断传送数据时奇数个数据从0变为1或从1变为0的情况,对于传送时偶数个数据发生错误,它就无能为力了。
3.海明码
海明码的作用是:在编码中如果有错误,可以表达出第几位出了错。二进制的数据只有0和1,修改起来很容易,求反即可,这需要加入几个校验位。它是根据总的位置来加的,加在“2的几次幂”的位置上,这个位置不是我们通常的从右向左数位置,刚好相反,是从左到右,如图1-3所示。

图1-3 海明码位置含义
P 是校验位, D 是数据位。原始的数据是101101,校验位是插到了1,2,4,8这几个位置上。
(1)校验码的计算
步骤①:确定校验码的位数 k 。
公式: m + k +1≤2 k ( m 是数据位的位数, k 是要加的校验位的位数)。
若数据长是4位,4+ k +1≤2 k ,当 k =3时,校验码就是3位。
若数据长是5位,5+ k +1≤2 k ,当 k =4时,校验码就是4位。
因为101101的数据位是6位,所以校验位应该是4位,总位数是6+4=10位。
步骤②:确定校验码的位置。
校验位插在2的幂的位置上,如图1-4所示。4个校验位就是插到2 0 =1,2 1 =2,2 2 =4,2 3 =8的位置上。

图1-4 海明码校验位位置
步骤③:确定数据的位置。
数据的位置就按顺序写入,不要写到校验位上。
步骤④:求出校验位的值。
求图1-4中 P 1 P 2 P 3 P 4的值。因为是4位校验码,所以我们能够用 s 4 s 3 s 2 s 1来表示这个4位校验码。
M1位置十进制是1,转成4位二进制数就是0001,即M1和 s 1有关系。同理,M2位置十进制是2,转成4位二进制数就是0010,对应 s 4 s 3 s 2 s 1。 s 2的位置上是1,所以M2和 s 2有关系。

通过异或运算,求对应的4位校验码 s 1, s 2, s 3, s 4。
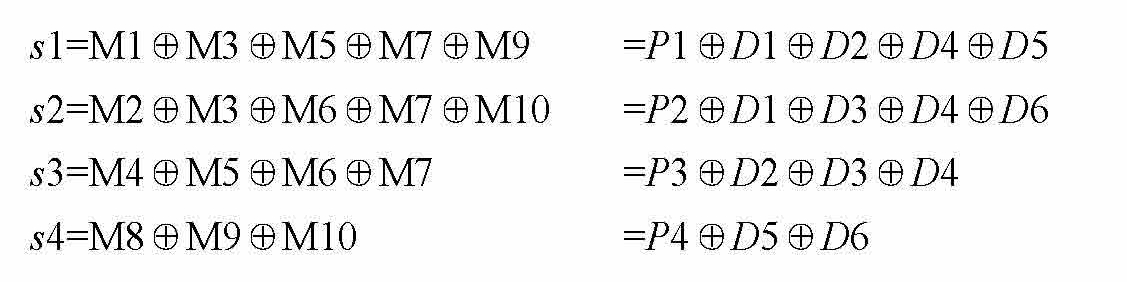
如果海明码没有错误信息, s 1、 s 2、 s 3、 s 4都为0,等式右边的值也得为0。由于是异或,因此 Pi ( i =1,2,3,…)的值与后边的式子必须一样才能使整个式子的值为零,即 Pi =后边的式子的值。
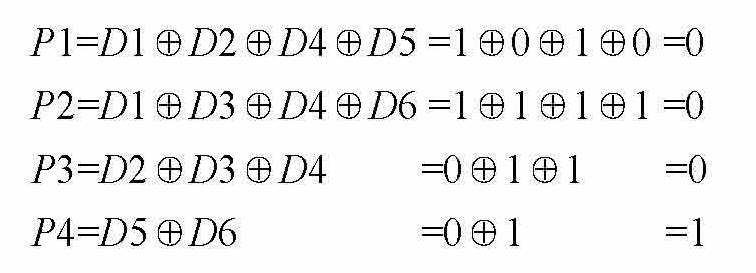
把 Pi 的值填写到图1-4中,就可以得到海明码,如图1-5所示。

图1-5 补充海明码校验码
(2)海明码校验过程
现在,假设海明码为0010111101,其中数据 D =101101。第5位错了,第5位现在的值是0,如果错了,它只能是1。对方接收到了这样的一组编码,如图1-6所示,接收方如何找出错误的位置?

图1-6 一组错误的海明码
上文已提到校验码的计算,4位校验码为 s 1, s 2, s 3, s 4。
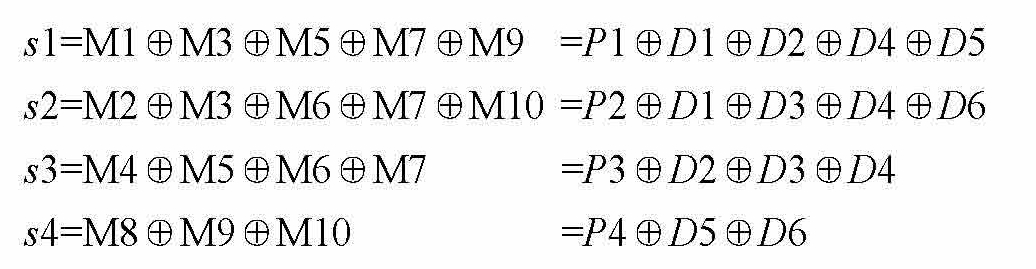
代入数据后,计算可得:
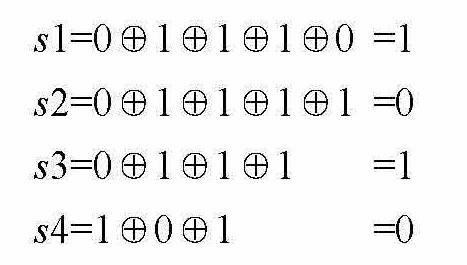
按照 s 4, s 3, s 2, s 1排列得到的二进制数为0101,对应的十进制数为5,所以是第5位出错,和之前假设的一样。
4.哈夫曼编码
哈夫曼编码(Huffman Coding)是一种编码方式,它是可变字长编码(Variable Length Coding,VLC)的一种。哈夫曼编码是Huffman于1952年提出的一种编码方法,该方法完全依据字符出现的概率来构造异字头的平均长度最短的码字,有时称为最佳编码,一般就叫作哈夫曼编码。
(1)哈夫曼编码的原理
哈夫曼编码的基本思想是:输入一个待编码的串,首先统计串中各字符出现的次数,称为频次,假设统计频次的数组为count[],则哈夫曼编码每次找出count数组中的值最小的两个分别作为左、右孩子,建立它们的父节点,循环这个操作 n -1( n 是不同的字符数)次,就把哈夫曼树建好了。
(2)哈夫曼树
字符串:agdfaghdabsb。
如表1-5所示,统计每个字符出现的次数。如图1-7所示为字符串agdfaghdabsb的哈夫曼编码的哈夫曼树。
表1-5 字符出现次数统计
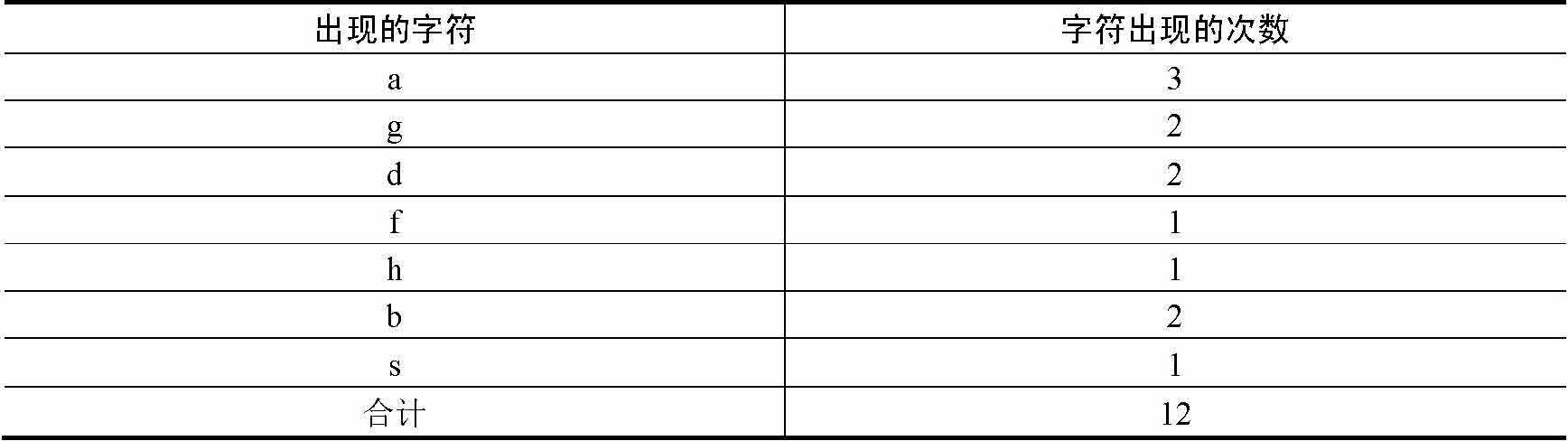
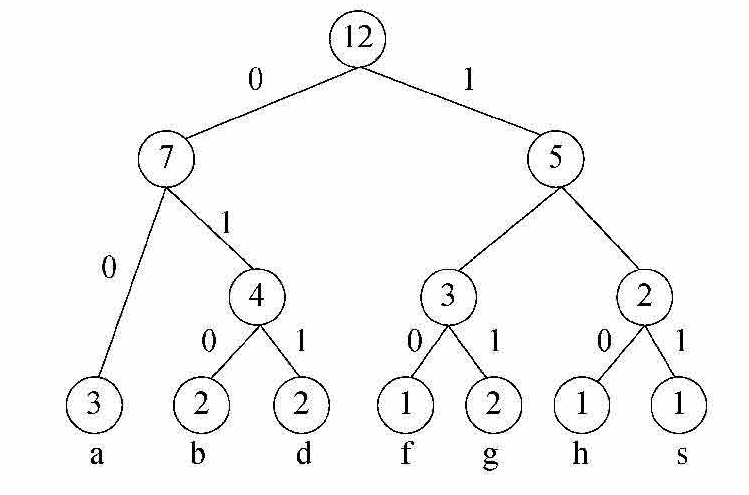
图1-7 哈夫曼树
由上面的哈夫曼树可知,各个字符的编码如下:
● a:01.
● b:010.
● d:011.
● f:100.
● g:101.
● h:110.
● s:111.
所以整个串的编码为:
011010111000110111001101010111010
5.循环冗余码
循环冗余校验(Cyclic Redundancy Check,CRC)是一种很常用的设计。一般来说,数据通信中的编码可以分为信源编码和信道编码两大类,其中,为了提高数据通信的可靠性而采取的编码称为信道编码,即抗干扰编码。在通信系统中,要求数据传输过程中的误码率足够低,而为了降低数据传输过程中的误码率,经常采用的一种方法是差错检测控制。
基本原理就是在一个 P 位二进制数据序列之后附加一个 R 位二进制检验码序列,从而构成一个总长为 N = P + R 位的二进制序列。例如, P 位二进制数据序列 D =[ d p -1 d p -2 … d 1 d 0 ], R 位二进制校验码 R =[ r r -1 r r -2 … r 1 r 0 ],那么所得到的 N 位二进制序列就是 M =[ d p -1 d p -2 … d 1 d 0 r r -1 r r -2 … r 1 r 0 ],这里附加在数据序列之后的CRC码与数据序列的内容之间存在着某种特定的关系。如果在数据传输过程中,由于噪声或传输特性不理想而使数据序列中的某一位或某些位发生错误,这种特定关系就会被破坏。可见在数据的接收端通过检查这种特定关系,可以很容易地实现对数据传输正确性的检验。
在CRC中,校验码 R 是通过对数据序列 D 进行二进制除法取余运算得到的,它被一个称为生成多项式的 r +1位二进制序列 G =[ g r g r -1 … g 1 g 0 ]来除,具体的多项式除法形式如下:
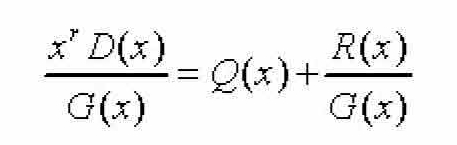
其中, x r D ( x )表示将数据序列 D 左移 r 位,即在 D 的末尾再增加 r 个0位; Q ( x )代表这一除法所得的商, R ( x )就是所需的余式。此外,这一运算关系还可以表示为:
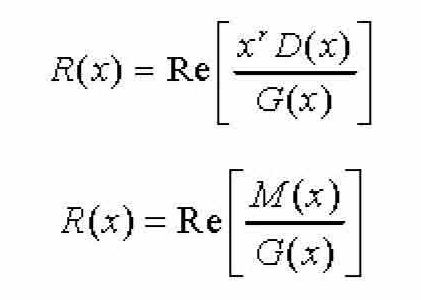
通过上面CRC基本原理的介绍,可以发现生成多项式是一个非常重要的概念,它决定了CRC的具体算法。目前,生成多项式具有以下一些通用标准,其中CRC-12、CRC-16、CRC-ITU和CRC-32是国际标准。
● CRC-4: x 4 + x +1.
● CRC-12: x 12 + x 11 + x 3 + x +1.
● CRC-16: x 16 + x 12 + x 2 +1.
● CRC-ITU: x 16 + x 12 + x 5 +1.
● CRC-32: x 32 + x 26 + x 23 +…+ x 2 + x +1.
● CRC-32c: x 32 + x 28 + x 27 +…+ x 8 + x 6 +1.
现在假设选择的CRC生成多项式为 G ( X )= X 4 + X 3 +1,要求出二进制序列10110011的CRC码,具体的计算过程如下:
步骤01 首先把生成多项式转换成二进制数,由 G ( X )= X 4 + X 3 +1可以知道,它一共是5位(总位数等于最高位的幂次加1,即4+1=5),然后根据多项式各项的含义(多项式只列出二进制值为1的位,也就是这个二进制的第4位、第3位、第0位的二进制均为1,其他位均为0)很快就可以得到它的二进制比特串为11001。
步骤02 因为生成多项式的位数为5,根据前面的介绍得知CRC码的位数为4(校验码的位数比生成多项式的位数少1位)。因为原数据帧为10110011,在它后面再加4个0,得到101100110000,然后把这个数以“模2除法”的方式除以生成多项式,得到的余数(即CRC码)为0100,如图1-8所示。
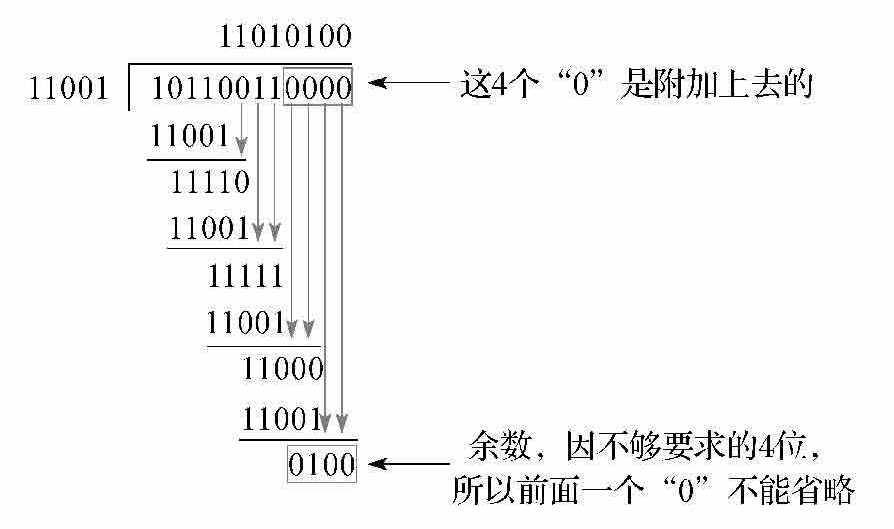
图1-8 模2除法计算过程
步骤03 用上一步计算得到的CRC码0100替换原始帧101100110000后面的4个“0”,得到新帧101100110100,再把这个新帧发送到接收端。
步骤04 当以上新帧到达接收端后,接收端会把这个新帧再用上面选定的除数11001以“模2除法”方式去除,验证余数是不是0,如果为0,则证明该帧数据在传输过程中没有出现差错,否则证明出现了差错。