下载掌阅APP,畅读海量书库
立即打开



在平台虚拟化技术中,核心的技术是实现CPU、内存和I/O设备的虚拟化,下面分别从CPU虚拟化、内存虚拟化和I/O设备虚拟化三个方面对虚拟化技术进行介绍。
CPU虚拟化的实质是,多个虚拟CPU分时复用物理CPU,任意时刻一个物理CPU只能被一个虚拟CPU使用。VMM的工作就是为各个虚拟CPU合理分配时间片,并维护所有虚拟CPU的状态,当一个虚拟CPU的时间片用完需要切换时,要保存当前虚拟CPU的状态,将下一个将被调度的虚拟CPU的状态载入物理CPU。因此,CPU虚拟化主要解决的两个问题:(1)虚拟CPU的正常运行;(2)虚拟CPU的调度。
在介绍虚拟CPU的运行机制前,先来看一下在没有虚拟化的情况下CPU的运行机制。CPU作为计算机系统中的核心部件,主要是运行各种指令。在计算机系统中,存在这样一部分指令,如清内存、设置时钟、分配系统资源、修改虚拟内存的段表和页表、修改用户的访问权限等,这些指令如果使用不当,则会导致整个计算机系统的崩溃。因此,为了保证系统的稳定性和安全性,这部分指令被定义为特权指令,其他的指令被定义为非特权指令。同时,将CPU的运行状态也相应地定义为用户态和核心态。操作系统或其他系统软件运行在核心态,可以执行所有的指令,包括特权指令和非特权指令;而用户的应用程序则运行在用户态,只能运行非特权指令。
x86架构的CPU被细分为Ring 0~3四种执行状态,其中Ring 0优先级最高、Ring 3优先级最低,如图3-3所示。目前,操作系统运行在Ring 0层,应用程序运行在Ring 3层,Ring 1和Ring 2一般处于空闲状态。
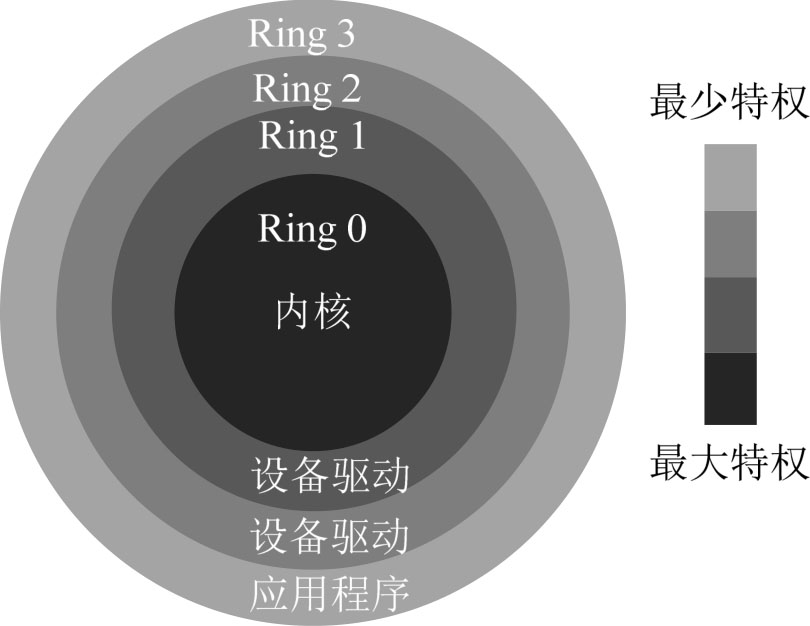
图3-3 CPU的执行状态
(1)Ring 0核心态(Kernel Mode)。
Ring 0核心态是操作系统内核的执行状态(运行模式),运行在核心态的代码可以无限制地调用特权指令对系统内存、设备驱动程序、网卡、显卡等外部设备进行访问。
显然,只有操作系统能够无限制地访问内存、磁盘、鼠标、键盘等外围硬件设备的数据,因为操作系统就是作为计算机硬件资源管理器而存在的,操作系统就是为了让多个普通应用程序可以更简单、安全地运行在同一台计算机上而存在的“特殊的应用程序”。
(2)Ring 3用户态(User Mode)。
运行在用户态的程序代码需要受到CPU的检查,用户态程序代码只能访问内存页表项中规定能被用户态程序代码访问的页面虚拟地址(受限的内存访问)和I/O端口,不能直接访问外围硬件设备,不能抢占CPU,即只能执行非特权指令,不能执行特权指令。
应用程序的代码运行在Ring 3上,不能执行特权指令。如果需要执行特权指令,如访问磁盘、写文件等,则需要通过执行系统调用(或函数)来实现。在执行系统调用时,CPU的运行级别则会从Ring 3切换到Ring 0,并跳转到系统调用对应的内核代码位置执行,这样内核(操作系统)就为应用程序完成了设备的访问。在设备访问完成之后,CPU的运行级别则从Ring 0返回Ring 3。
用户态转换为内核态的核心机制是中断或异常机制,即当应用程序执行特权指令时,就会发生中断或异常请求,系统捕获到这种中断或异常,就会进行状态切换,由操作系统直接调用物理资源来完成相应的特权指令。
在没有虚拟化的环境中,操作系统运行在Ring 0层,拥有对所有硬件的全部特权;而在虚拟化环境中,操作系统作为客户操作系统运行在VMM之上,其所使用的是虚拟的资源而非物理硬件,如何保证原来操作系统中的特权指令被正确执行,是CPU虚拟化需要解决的核心问题。
CPU虚拟化技术可以分为三类:全虚拟化、半虚拟化和硬件辅助虚拟化。
(1)全虚拟化。
CPU全虚拟化的实现架构如图3-4所示,客户操作系统运行在Ring 1层,VMM运行在Ring 0层,用户的应用程序仍然运行在Ring 3层。那么在这种虚拟化模式下需要解决两个问题:一是原来运行在Ring 0层的客户操作系统变成运行在Ring 1层,这就意味着操作系统丧失了运行特权指令的特权,那么此时操作系统应该如何运行特权指令呢?二是在保证虚拟机中客户操作系统的特权指令被正确执行的情况下,如何保证其他虚拟机的安全性?
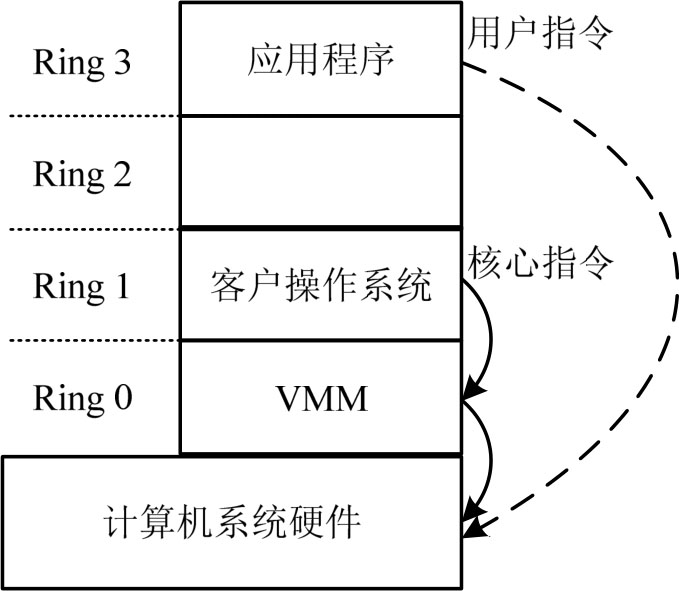
图3-4 CPU全虚拟化的实现架构
为了解决上述问题,CPU全虚拟化的实现技术主要有两种:模拟仿真技术和二进制翻译技术。
① 模拟仿真技术。
最早实现CPU全虚拟化的技术是陷入—模拟(Trap-and-Emulate)技术,其将客户操作系统的特权解除,即将操作系统的执行状态由原来的Ring 0层降低至Ring 1层,此时客户操作系统就丧失了执行特权指令的特权。于是当客户操作系统执行特权指令时,就会发生中断或异常,也称为陷入(Trap),此时运行在Ring 0层的VMM就可以捕获到这种陷入,然后由VMM完成特权指令的执行,并将结果返回给客户操作系统。
在虚拟化的模式下,除了特权指令,还定义了敏感指令。
◆ 特权指令:系统中有一些操作和管理关键系统资源的指令,这些指令只有在最高特权级上能够正确运行。如果在非最高特权级上运行,那么特权指令就会引发一个异常,处理器会陷入最高特权级,交由系统软件处理。
◆ 敏感指令:操作特权资源的指令,包括修改虚拟机的运行模式或下面物理机的状态;读写时钟、中断寄存器等;访问存储保护系统、地址重定位系统及所有的I/O指令。
在CPU虚拟化中,不仅特权指令需要被捕获,所有的敏感指令也需要被捕获。对于一般的RISC架构处理器构成的大型机、小型机,敏感指令全部是特权指令,但是对于x86架构处理器来说,敏感指令并不全是特权指令,如图3-5所示。在执行这些非特权指令的敏感指令时
 ,就不会自动Trap被VMM捕获,所以这种模拟仿真技术不适合x86架构的CPU虚拟化。
,就不会自动Trap被VMM捕获,所以这种模拟仿真技术不适合x86架构的CPU虚拟化。
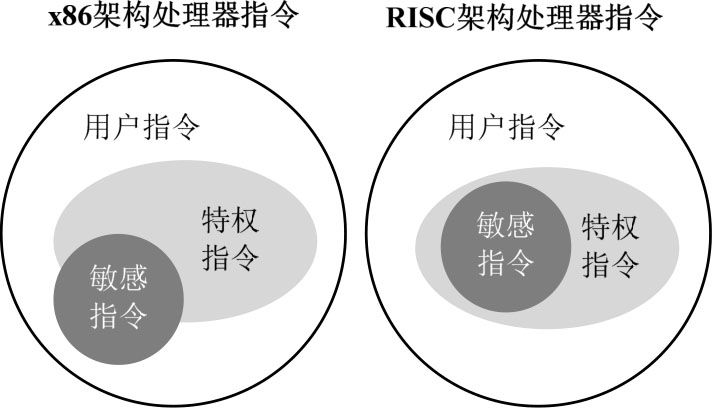
图3-5 x86架构处理器指令与RISC架构处理器指令
② 二进制翻译技术。
针对模拟仿真技术不能有效地实现x86架构处理器的虚拟化,VMware在1999年提出基于二进制翻译技术来实现x86架构处理器的虚拟化,解决了x86架构处理器不适合虚拟化的难题。
二进制翻译技术(Binary Translation,BT),是将一种处理器上的二进制程序翻译到另外一种处理器上执行的技术,即将机器代码从源机器平台映射(翻译)至目标机器平台,包括指令语义与硬件资源的映射,使源机器平台上的代码“适应”目标平台。在虚拟化场景中,就是将客户操作系统的指令翻译成宿主机操作系统的指令进行执行。
在全虚拟化中,客户操作系统运行在Ring 1层,VMM运行在Ring 0层,当客户操作系统的内核代码被执行时,VMM就会进行截断,然后利用二进制翻译技术将客户操作系统中的代码翻译成VMM的指令运行,实现了CPU的虚拟化。
虽然二进制翻译技术解决了x86架构的CPU虚拟化问题,但是翻译的过程造成了较大的性能损失。
(2)半虚拟化。
半虚拟化是2003年Xen虚拟化平台采用的虚拟化技术,其核心是基于超级调用(Hypercall)技术来实现的。通过对客户操作系统的内核代码进行修改,将客户操作系统中的敏感指令操作转换为调用VMM的超级调用,然后由VMM来完成相应的操作,如图3-6所示。
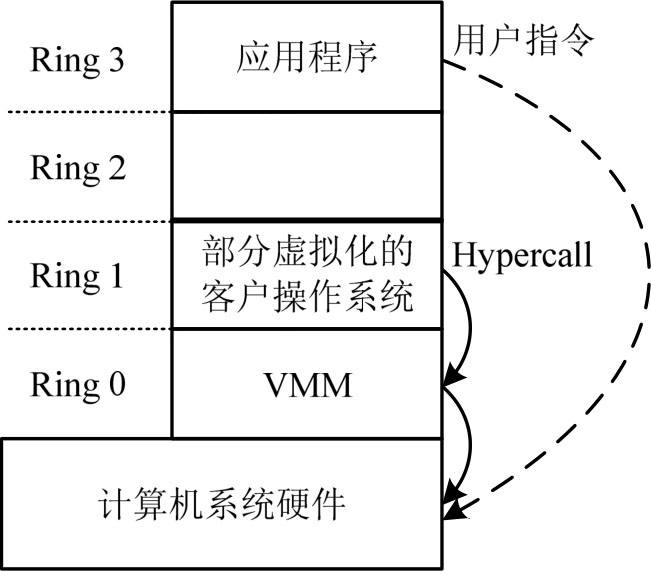
图3-6 CPU半虚拟化
与CPU全虚拟化不同,在CPU半虚拟化中,客户操作系统是主动调用VMM的超级调用,即在全虚拟化中,客户操作系统不知道自己运行在虚拟机中,其敏感操作是由VMM截获的,是被动的,而在半虚拟化中,客户操作系统知道自己运行在虚拟机中,主动调用VMM的超级调用。CPU半虚拟化的优点是提高了性能,通过超级调用技术,能够达到近似物理机的速度,其缺点是需要修改客户操作系统的内核,因此只适合Linux操作系统,不适合Windows操作系统
。
(3)硬件辅助虚拟化。
硬件辅助虚拟化的核心思想是通过引入新的指令和运行模式,使VMM和客户操作系统分别运行在不同模式下,即ROOT模式和非ROOT模式。在非ROOT模式下,客户操作系统运行在Ring 0层。通常情况下,客户操作系统的核心指令可以直接下达到计算机系统硬件执行,而不需要经过VMM。当客户操作系统执行到特殊指令时,系统会切换到VMM,让VMM来处理特殊指令,如图3-7所示。
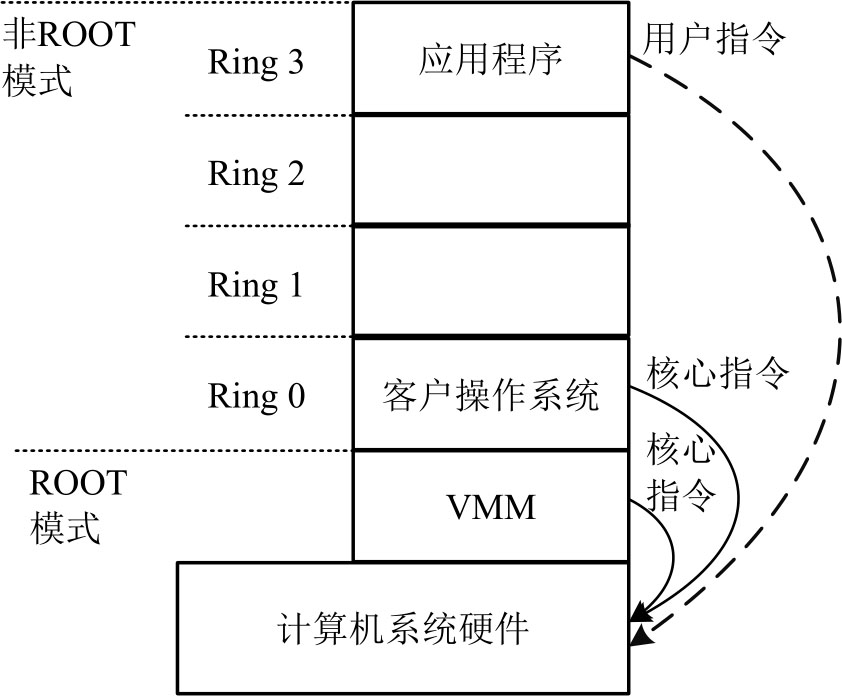
图3-7 CPU硬件辅助虚拟化
支持硬件辅助虚拟化的硬件技术有Intel-VT和AMD-V,典型的虚拟化平台代表是KVM。硬件辅助虚拟化是新的发展趋势,一方面有硬件的支持,性能得以提高;另一方面,不需要修改客户操作系统,适应性强。随着硬件技术的发展,目前硬件对虚拟化的支持已不是问题。
VMM通常采用分块共享的思想来虚拟计算机的物理内存,即VMM需要将机器的内存分配给各个虚拟机,并维护机器内存和虚拟机所见到的“物理内存”的映射关系,使得这些虚拟机看来是一段从地址0开始的、连续的“物理”地址空间。为此,在操作系统原来的机器地址和虚拟地址之间新增加了一个内有虚拟化层,用来表示这一段连续的“物理”地址空间,如图3-8所示。内存地址的层次由两层向三层的转变使得原来的内存管理单元(Memory Management Unit,MMU)失去了作用,因为普通的MMU只能完成一次虚拟地址到物理地址的映射,但在虚拟环境下,经过MMU转换所得到的“物理地址”已不是真正硬件的机器地址。如果需要得到真正的物理地址,则必须由VMM介入,经过再一次映射才能得到总线上使用的机器地址。
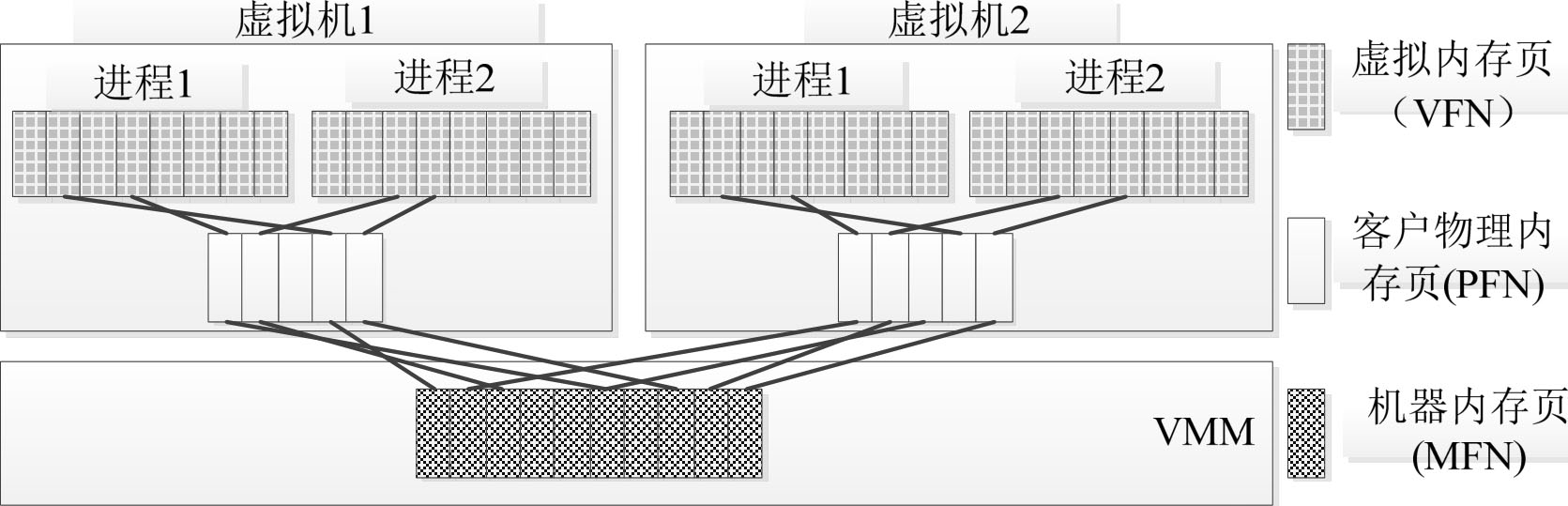
图3-8 内存虚拟化的三层模型
如何利用现有的MMU机制实现虚拟地址到机器地址的高效转换,是VMM在内存虚拟化方面面临的基本问题,目前实现内存地址转换的技术主要包括三类:页表写入法、影子页表法和硬件辅助内存虚拟化。
(1)页表写入法。
页表写入法,是在VMM的帮助下,使客户操作系统能够利用物理MMU一次完成由虚拟地址到机器地址的三层转换的技术。当客户操作系统创建一个新的页表(客户机页表)时,同时向VMM注册该页表,VMM则维护一个转换表,其中保存了客户操作系统的虚拟地址VA、客户机物理地址GPA和机器地址MA的对应关系,如图3-9所示。
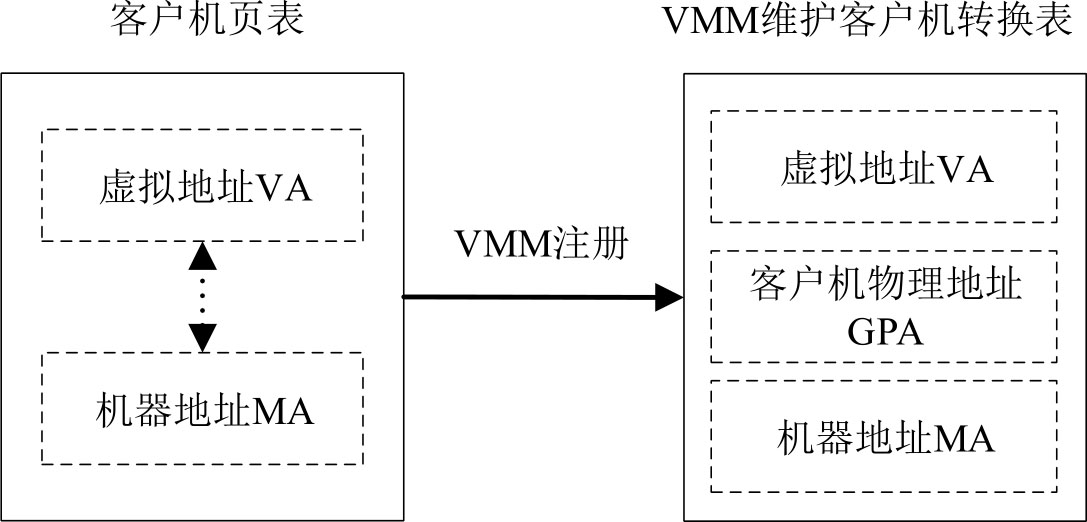
图3-9 页表写入法
客户操作系统在运行的过程中,VMM根据自身维护的客户机转换表对客户机页表进行不断的改进,即经过VMM改写后,客户页表中的地址不再是客户机物理地址GPA,而是机器地址MA,因此MMU能够像在原来操作系统中一样直接完成由虚拟地址VA到机器地址MA的转换工作,如图3-10所示。
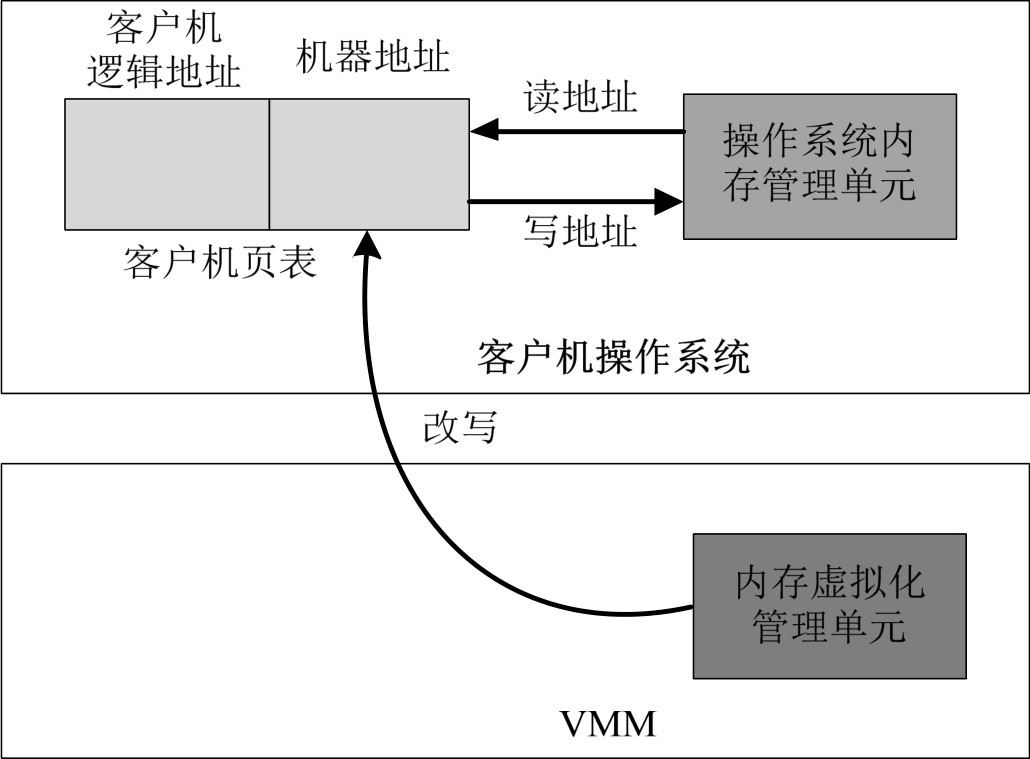
图3-10 页表写入法的页表转换机制
在页表写入法中,客户操作系统每次创建页表都要主动向VMM进行注册,也就是说,客户操作系统是知道自己运行在虚拟化环境中的,因此,页表写入法也称为内存半虚拟化技术。
(2)影子页表(Shadow Page Table)法。
VMM为每个客户操作系统维护一个影子页表,影子页表保存了虚拟地址VA到机器地址MA的映射关系。客户机页表保存了虚拟地址VA到客户机物理地址GPA的映射关系。当客户机页表发生修改时,VMM就会捕获到并查找保存了客户机物理地址GPA到机器地址MA的P2M页表,从其中找到修改的GPA对应的MA。然后,VMM将查找到的机器地址MA填充到寄存器上的影子页表中,从而生成了虚拟地址VA到机器地址MA的映射关系,如图3-11所示。
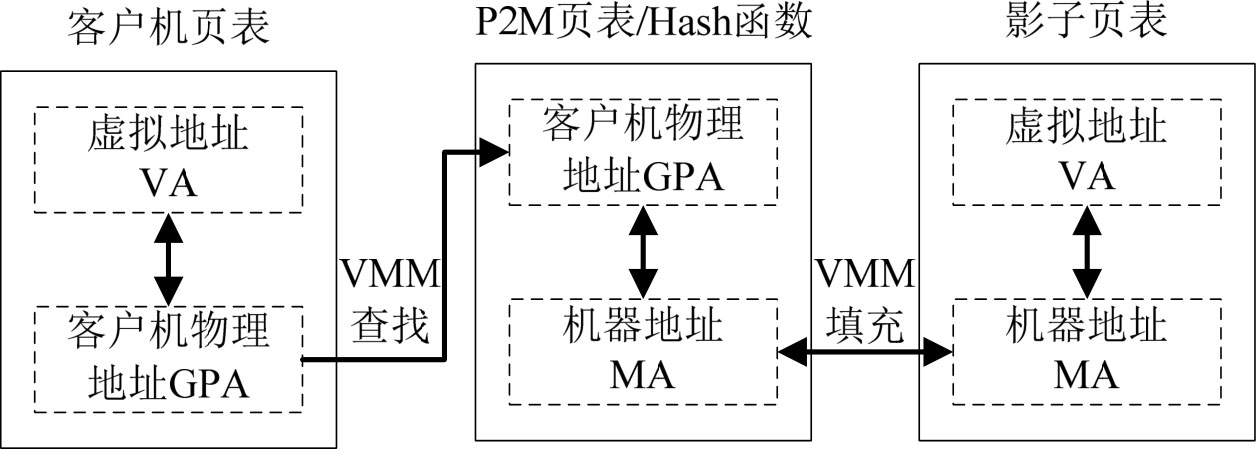
图3-11 影子页表
VMM通过影子页表给不同的虚拟机分配机器的内存页,就像操作系统的虚拟内存一样,VMM能将虚拟机内存换页到磁盘,因此,虚拟机申请的内存可以超过机器的物理内存。VMM也可以根据每个虚拟机的要求,动态地分配相应的内存。
在影子页表技术中,客户操作系统的客户机页表无须变动,即客户操作系统不知道自己运行在虚拟化的环境中,因此,影子页表技术是一种内存全虚拟化技术。
(3)硬件辅助内存虚拟化。
硬件辅助内存虚拟化技术是通过扩展页表(Extended Page Table,EPT)实现内存虚拟化的,即通过硬件技术,在原来的页表基础上,增加一个扩展页表,用于记录客户机物理地址GPA到机器地址MA的映射关系。VMM预先把扩展页表设置到CPU中,如图3-12所示。
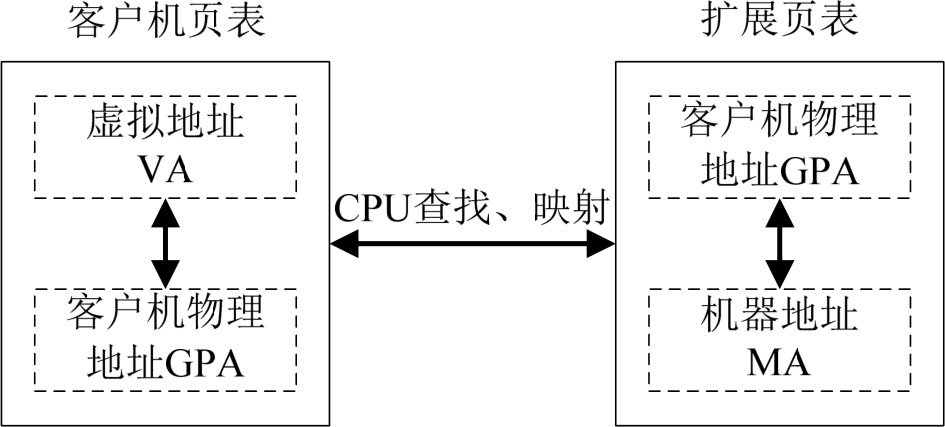
图3-12 硬件辅助内存虚拟化
客户操作系统在运行过程中,直接修改客户机页表,无须VMM干预。地址转换时,CPU自动查找两张页表并完成虚拟地址VA到机器地址MA的转换,从而降低整个内存虚拟化所需的开销。
在没有虚拟化下的情况下,I/O设备
的调用流程可以描述如下:当某个应用程序或进程发出I/O请求时,事实上是通过系统调用等方式进入内核,然后通过调用相对应的驱动程序,获得I/O设备进行相关操作,最后操作完成后,将运行结果返回给调用者。
I/O设备虚拟化的实质就是实现I/O设备在多个虚拟机之间的分时共享,由于I/O设备的异构性强、内部状态不易控制等特点,I/O设备虚拟化一直是虚拟化技术的难点所在。目前I/O设备虚拟化模式分为四类:全虚拟化、半虚拟化、直通访问和单根虚拟化,如图3-13所示。
(1)I/O设备全虚拟化。
I/O设备全虚拟化主要是通过采用全软件的方法来模拟I/O设备实现的,即客户操作系统的I/O操作会被VMM捕获,并转交给宿主操作系统的一个用户态进程,该进程通过对宿主操作系统的系统调用,模拟设备的行为,如图3-14所示。
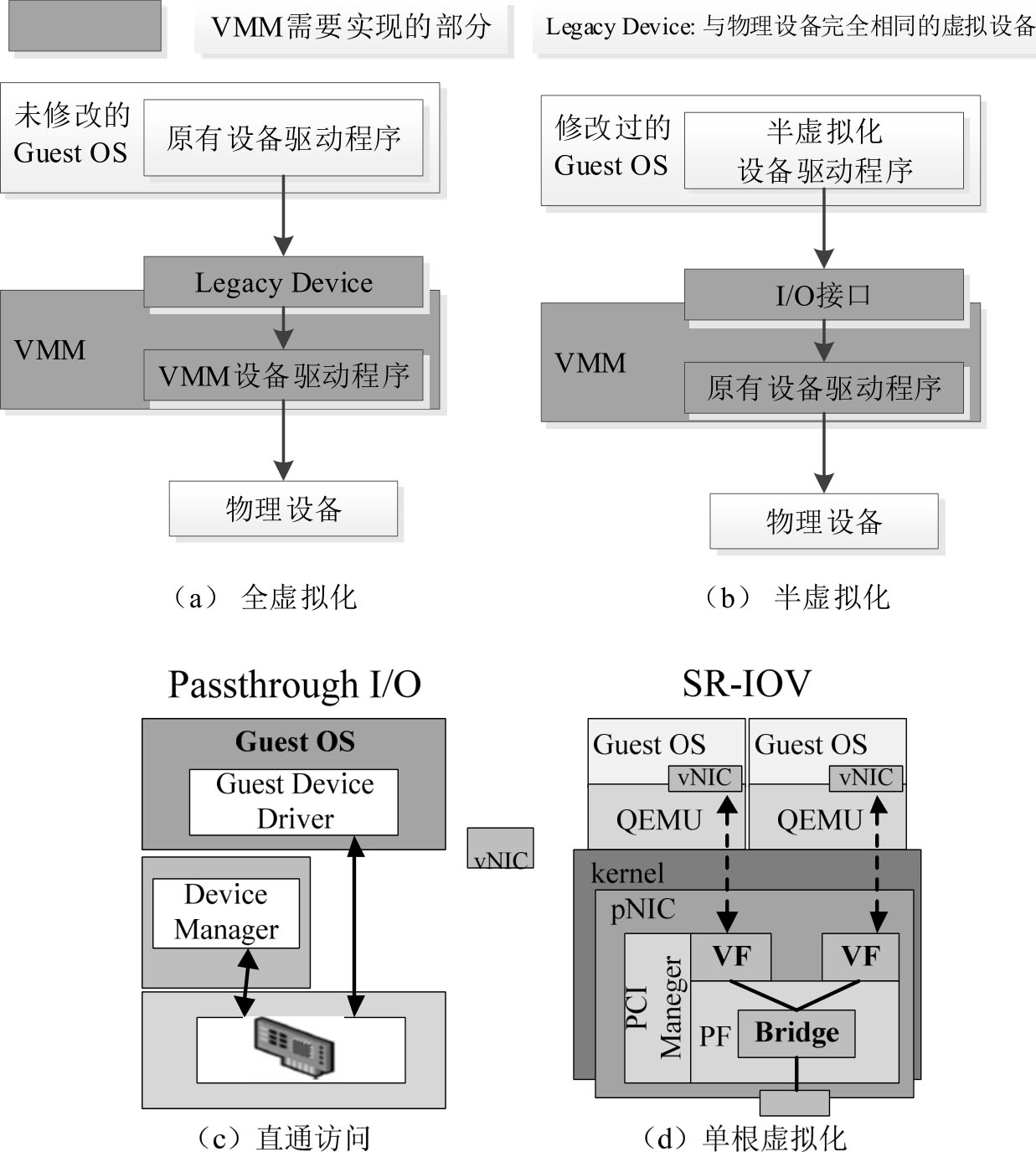
图3-13 I/O设备虚拟化模式
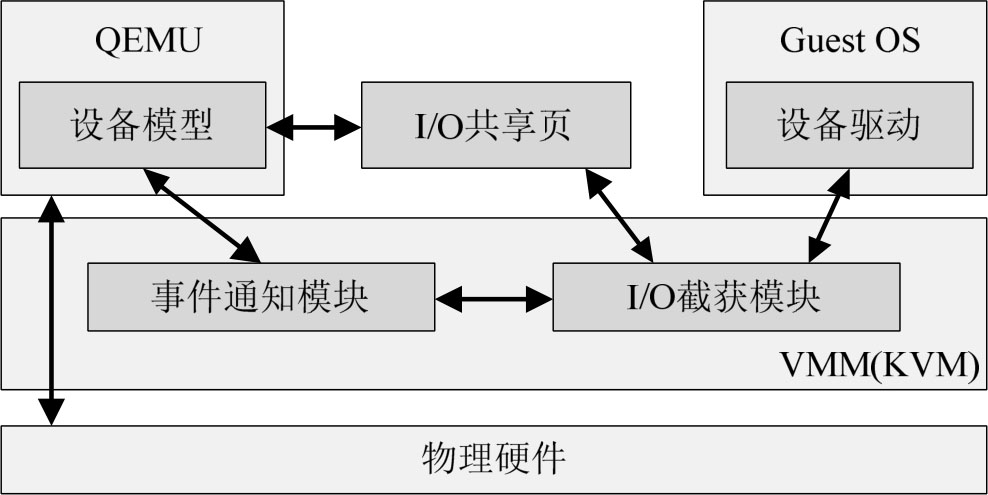
图3-14 I/O设备全虚拟化
I/O设备全虚拟化的运行流程如下:
① 客户操作系统的设备驱动程序发起I/O操作请求;
② VMM(如KVM)模块中的I/O截获模块拦截发起的I/O请求;
③ VMM对I/O请求进行处理后将相关信息放到I/O共享页(sharing page),并通过事件通知模块通知用户空间的设备模型(如QEMU);
④ QEMU获得I/O操作的具体信息之后,交由硬件模拟代码来模拟出本次I/O操作;
⑤ 完成之后,QEMU将结果放回I/O共享页,并通知KVM模块中的I/O截获模块;
⑥ KVM模块的I/O截获模块读取I/O共享页中的操作结果,并把结果返回客户操作系统。
其中,当客户机通过DMA(Direct Memory Access,直接内存访问)访问大块I/O时,QEMU将不会把结果放进I/O共享页中,而是通过内存映射的方式将结果直接写到客户机的内存中,然后通知KVM模块客户机DMA操作已经完成。
全虚拟化技术的优点是可以模拟出各种各样的硬件设备,对客户操作系统完全透明,采用全虚拟化技术的虚拟化平台有QEMU、VMware WorkStation、VirtualBox等。其缺点是每次I/O操作的路径比较长,需要进行多次上下文切换,同时还需要进行多次数据复制,整体来说,性能较差。
(2)I/O设备半虚拟化。
I/O设备半虚拟化,最早由Citrix的Xen虚拟化平台提出,为了促进半虚拟化技术的应用,提出Linux上的设备驱动标准框架virtio,提供了一种宿主机与客户机交互的I/O框架。在半虚拟化模型中,物理硬件资源统一由VMM管理,由VMM提供资源调用接口。虚拟主机通过特定的调用接口与VMM通信,然后完成I/O资源控制操作。除了Xen平台,KVM/QEMU都实现了基于virtio的半虚拟化技术。
virtio的实现主要包括两部分:在客户操作系统内核中安装前端驱动(Front-end driver)和在特权域(Xen虚拟化平台)或QEMU中实现后端驱动(Back-end driver)。前、后端驱动通过virtio-ring直接通信,从而绕过了经过KVM内核模块的过程,达到提高I/O性能的目的,Xen虚拟化平台的半虚拟化架构如图3-15所示。
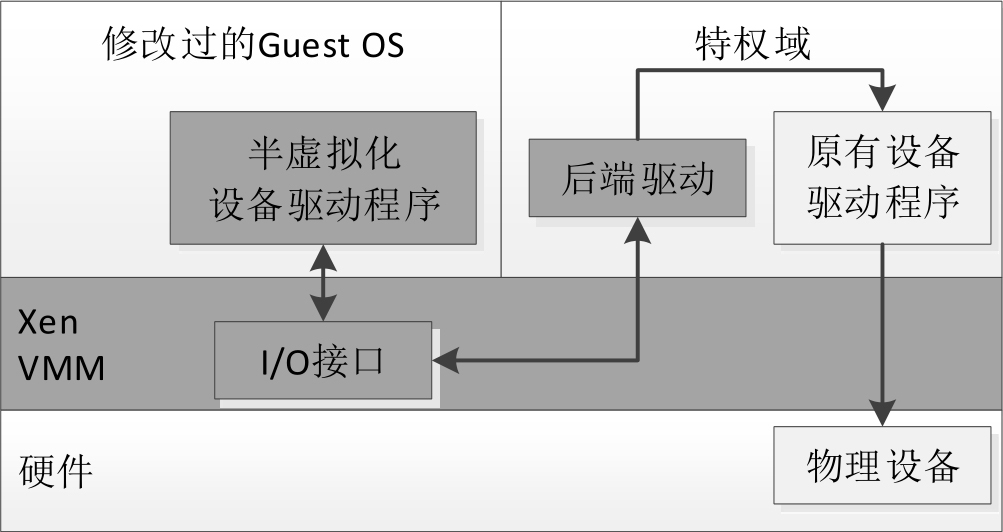
图3-15 Xen虚拟化平台的半虚拟化架构
◆ 前端驱动:客户操作系统中安装的驱动程序模块,负责将客户操作系统的I/O请求转发给后端驱动。
◆ 后端驱动:在QEMU或特权域中的实现,接收客户操作系统的I/O请求,并检查请求的有效性,然后调用主机的物理设备进行相应的操作。
◆ virtio层:虚拟队列接口,从概念上连接前端驱动和后端驱动。驱动可以根据需要使用不同数目的队列。比如实现网卡虚拟化的virtio-net使用两个队列,实现块存储虚拟化的virtio-block只使用一个队列。该队列是虚拟的,实际上是使用virtio-ring来实现的。
◆ virtio-ring:实现虚拟队列的环形缓冲区,Xen中的virtio-ring如图3-16所示。
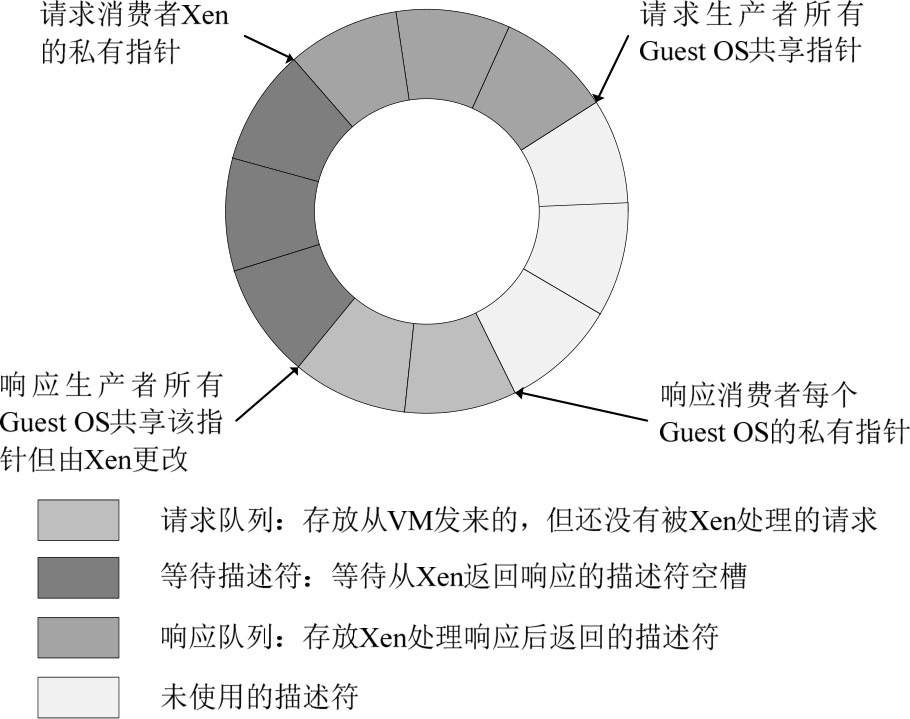
图3-16 Xen的环状队列示意
前端驱动实际上就是请求的生产者和响应的消费者,相反,后端驱动则是请求的消费者和响应的生产者。请求队列用于存储从虚拟机发送的I/O请求,所有的客户操作系统共享该队列;响应队列存储Xen对虚拟机的请求处理结果。该环状队列实际上是客户操作系统和特权域的一块共享内存。
为了实现大量DMA数据在客户操作系统和特权域之间的高效传递,Xen采用“授权表”机制,通过直接替换页面映射关系来避免不必要的内存拷贝(如图3-17所示)。授权表实现了一种安全的虚拟机之间共享内存机制。每个虚拟机都有一个授权表,指明了它的哪些页面可以被哪些虚拟机访问。同时,Xen自身存在一个活动授权表,用来缓存各个虚拟机授权表的活动表项。
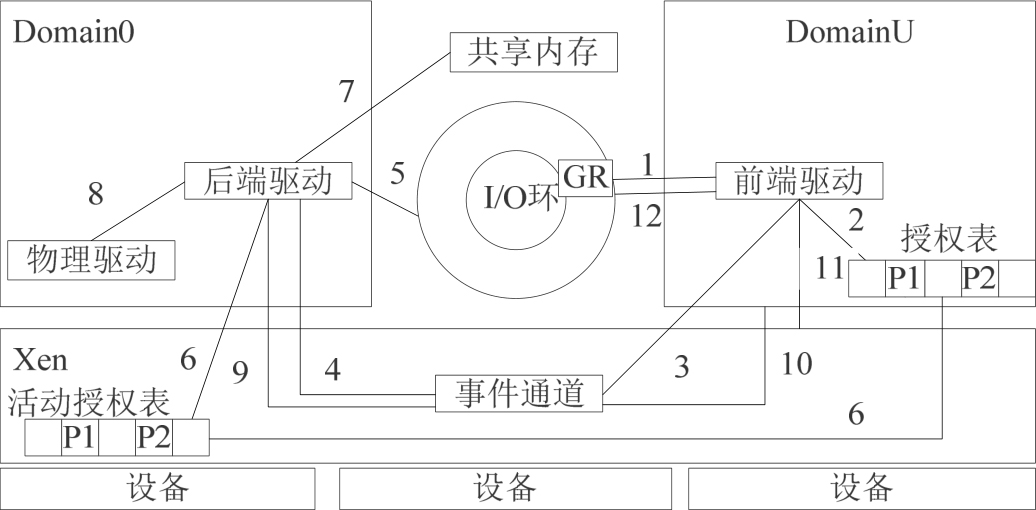
图3-17 Xen的授权表机制的一个授权处理流程
① DomainU的应用程序访问虚拟I/O设备,DomainU内核调用对应前端驱动。前端驱动生成I/O请求,该请求描述了要写入数据的地址和长度等信息。
② 前端驱动为对应的数据页面生成一个授权描述(见图3-17中的GR),用来为Domain0授予访问的权限,并把授权描述和请求一起放入I/O环中。
③ 前端驱动通过事件通道通知Domain0。
④ Xen调度Domain0运行时,检查事件,发现有新的I/O请求,则调用后端驱动进行处理。
⑤ 后端驱动从I/O环中读取I/O请求和授权描述,向Xen请求锁住该页面,以避免DMA过程中该页面被其他客户操作系统替换,同时分析I/O请求(分析DomainU想要Domain0做什么,如通过网卡发送网络数据)。
⑥ Xen接收到锁定页面的请求后,就在活动授权表或客户操作系统的授权表中确认是否已授权特权域访问该页面,并确保没有其他虚拟机能够控制这个页面。如果通过检查,则表明这个页面能够安全地进行DMA操作。
⑦ 后端驱动通过共享内存取得DomainU要写入的数据(即要发送的数据内容)。
⑧ 后端驱动将I/O请求预处理后调用真实的设备驱动执行请求的操作。
⑨ I/O请求完成后,后端驱动产生I/O响应,将其放入I/O环,并通过事件通道通知DomainU。
⑩ Xen调度DomainU运行时,检查事件,发现有新的I/O响应,则为DomainU产生模拟中断。
⑪ 中断处理函数检查事件通道,并根据具体的事件调用对应前端驱动的响应处理函数。
⑫ 前端驱动从I/O环中读出I/O响应,处理I/O响应。
在整个DMA操作过程中,没有任何页面副本,而且授权表机制很好地保证了虚拟机间的隔离性和安全性。
采用半虚拟化的VMM不需要直接控制I/O设备,大大简化了VMM的设计。同时,由于半虚拟化的I/O设备驱动在一个较高的抽象层次上将I/O操作直接传递给VMM,因此性能较高。此外,半虚拟化还允许VMM重新调度和合并I/O操作,甚至在某些情况下还能够对设备的访问进行加速。不过,半虚拟化的缺点是需要在客户操作系统上安装前端驱动程序,甚至要修改其代码。
(3)I/O设备直通访问。
I/O设备直通访问需要硬件的支持,即通过硬件的辅助实现将宿主机中的物理I/O设备直接分配给客户操作系统使用,此时客户操作系统以独占的方式访问I/O设备,如图3-18所示。
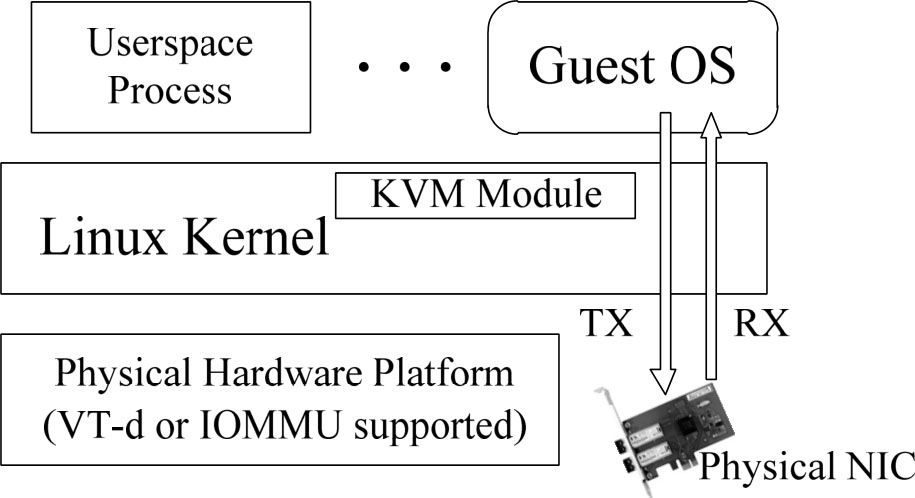
图3-18 I/O设备直通访问
I/O设备直通访问的最大优点是客户操作系统可以直接与分配给它的物理设备进行通信,性能高。I/O设备直通访问的缺点是设备只能被一个客户操作系统占用,所有虚拟机所能得到的虚拟设备总数不可能多于真实的物理设备数量,从而丧失了虚拟化技术的优势。此外,配置也比较复杂,需要在VMM层手动地对I/O设备进行指定或分配,客户操作系统识别到设备后再安装相应的驱动来使用。
(4)单根虚拟化。
单根虚拟化(Single Root I/O Virtualization,SR-IOV)是针对I/O设备直通访问只能将一个物理I/O设备分配给一个客户操作系统的问题,定义了一个标准化的机制,从而实现多个客户操作系统共享一个设备。
具有SR-IOV功能的I/O设备是基于PCIe规范的,每个I/O设备具有一个或多个物理功能(Physical Function,PF),每个PF可以管理或创建多个虚拟功能(Virtual Function,VF),如图3-19所示。
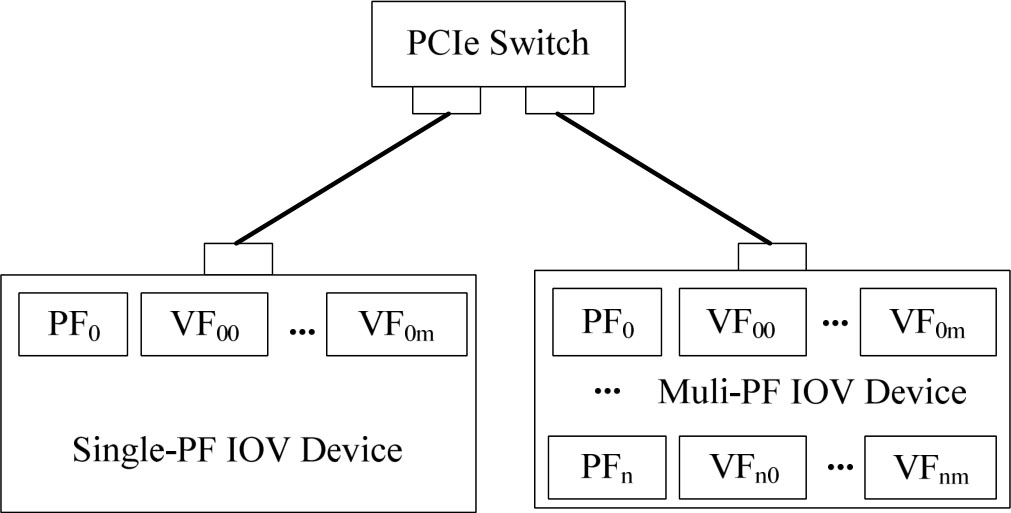
图3-19 具有SR-IOV功能的I/O设备
PF是标准的PCIe功能,如一个以太网端口,其可以像普通设备一样被发现、管理和配置;VF只负责处理I/O设备,在设备初始化时,无法进行初始化和配置,每个PF可以虚拟出的VF数目是一定的。
在一个具体的时刻,VF与虚拟机之间的关系是多对一的,即一个VF只能被分配给一个虚拟机,一个虚拟机可以拥有多个VF。从客户操作系统的角度,一个VF的I/O设备和一个普通I/O设备是没有区别的,SR-IOV驱动是在内核中实现的。
SR-IOV的实现模型包括VF驱动、PF驱动和IOVM(SR-IOV管理器)。VF驱动是运行在客户操作系统上的普通设备驱动,PF驱动部署在宿主机上对VF进行管理,同时IOVM也部署在宿主机上,用于管理PCIe拓扑的控制点及表示每个VF的配置空间,如图3-20所示。
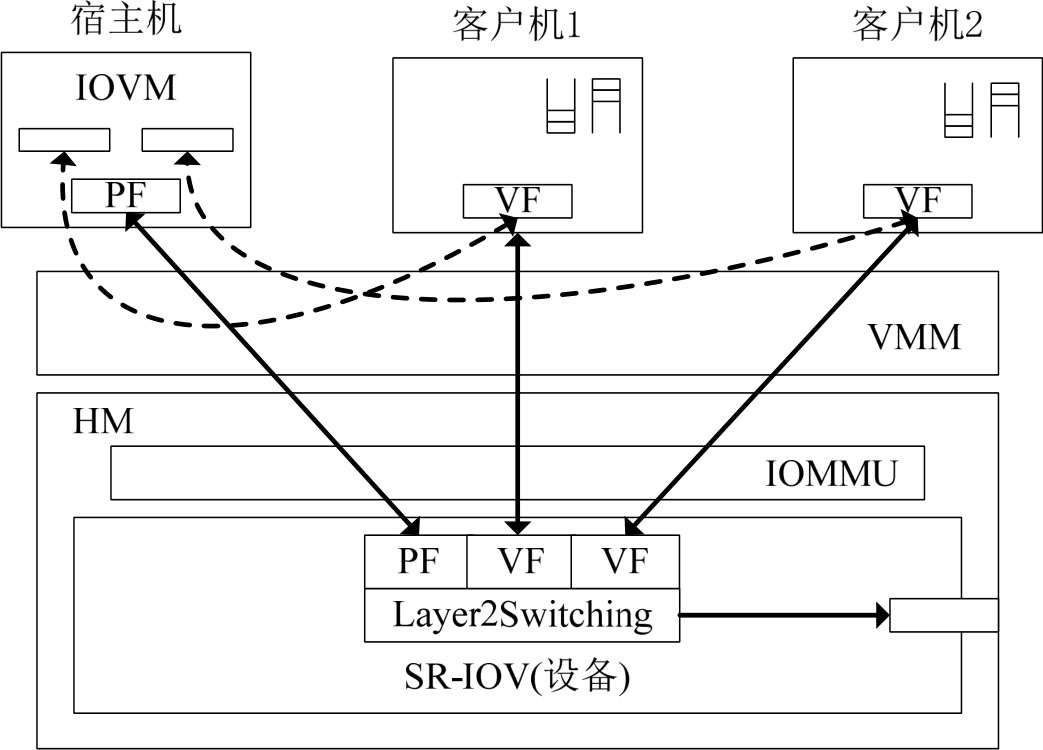
图3-20 SR-IOV的总体架构
◆ PF驱动,直接访问PF的所有资源,并负责配置和管理所有VF。它可以设置VF的数量,全局地启动或停止VF,还可以进行设备相关的配置。PF驱动同样负责配置2层分发,以确保从PF或VF进入的数据可以正确地路由。
◆ VF驱动,像普通的PCIe设备驱动一样运行在客户操作系统上,直接访问特定的VF设备完成数据的传输,所有工作不需要VMM的参与。从硬件成本角度来看,VF只需要模拟临界资源(如DMA等),而对性能要求不高的资源则可以通过IOVM和PF驱动进行模拟。
◆ IOVM,为每个VF分配了完整的虚拟配置空间,客户操作系统能够像普通设备一样模仿和配置VF。当宿主机初始化SR-IOV设备时,无法通过简单的扫描PCIe功能(通过PCIM实现)的供应商lD和设备ID列举出所有的VF。因为VF只是修改过的“轻量级”功能,不包含完整的PCIe配置空间。该模型可以使用Linux PCI热插拔API动态地为宿主机增加VF,然后将VF分配给客户机。
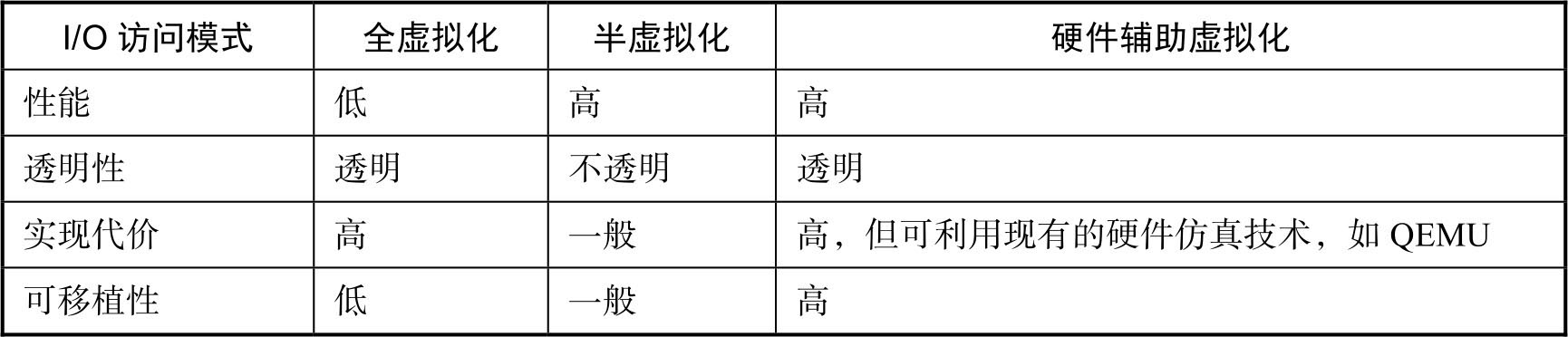
(5)三种I/O访问模式的比较。
如表3-2所示,从性能、透明性、实现代价和可移植性4个方面对全虚拟化、半虚拟化和硬件辅助虚拟化(I/O设备直通访问、单根虚拟化)进行了对比。在一个现实系统里,通常采用几种虚拟化技术相结合的方式实现整个I/O设备的虚拟化,从而做到优势互补。
表3-2 三种I/O访问模式的比较