
下载掌阅APP,畅读海量书库
立即打开



undo是数据库中最关键的部分,它的效率直接影响到数据库的性能。
很多初学者对undo机制不了解,想当然地以为在变更数据时会先把数据保存在内存中,提交(commit)后再把内存中的数据写入数据文件。这种理解是错误的。
undo中存放着数据变更前的镜像,当事务执行失败或者需要回退(rollback)时,数据库就从undo中获取数据前镜像将数据恢复到原来的一致状态。
任何数据变更都是直接写数据文件(严格说起来是先写入buffer中的数据块,然后由检查点在适当的时候写入磁盘),事务回退时使用undo中数据重新恢复数据。
与commit相比,rollback操作是更耗费资源的操作。为什么在commit前就把数据写入数据文件呢?为何不把数据先写入一个缓存中,commit后再写入数据文件,rollback时原来的数据没有发生变化,就不用恢复了,这样岂不更省事?
这时直接写数据文件效率更高,因为发生rollback操作的概率远远小于commit操作,即大部分事务都会成功执行,失败的只是少数。
undo的作用除了回滚事务(rollback transaction)和实例恢复(instance recovery)之外,还有一个重要作用就是提供一致性读。下面通过一致性读的过程来了解undo的机制。一致性读分以下两种情况。
(1)事务尚未提交。
事务的隔离性不允许发生脏读(未提交的数据被其他会话读取)。因此,其他会话在查询到这些包含未提交事务的数据块时,数据库会根据保存在数据块头部的未提交事务的id去undo中获取相应的前镜像数据,然后构造出一个数据变更前的数据块,供其他会话读取。
(2)事务已经提交。
如果在数据查询过程中发生了事务提交,当查询到这些已提交的数据时,数据库仍然会根据undo信息构造包含原来信息的数据块。这样就保证了查询到的数据是查询开始时刻的一致性数据。
例如,T0时刻,会话A对表t发起查询。T1时刻,会话B对表t提交事务。T2时刻,会话A查询到表t中被会话B更改的数据块,数据库根据数据块头部的SCN判断出此时的数据块为T1时刻提交,晚于T0时刻(不一致)。这时数据库就会去undo中寻找该数据块满足T0时刻(等于或早于T0的最近时刻)的前镜像数据构造变更前的块,从而完成一致性读。如果undo中没有满足该数据块T0时刻的undo数据,达梦数据库就会报错:回滚记录版本太旧,无法获取用户记录。Oracle数据库相应的报错信息为ORA-01555(snapshot too old,快照太旧)。
找不到undo信息的原因就是undo中的数据因时间久远被覆盖,导致一致性读无法构造包含原来信息的数据块。如果报错发生频繁,可以考虑适当增大undo表空间,也可以增大参数undo_retention(undo数据保留时间,默认为90秒)。
针对不同的数据变更操作,undo会保存不同的信息。对于insert操作,undo保存新插入行记录的rowid,rollback时根据rowid即可删除掉该记录。对于update操作,undo只记录被更新的字段的前镜像(旧值),rollback时通过旧值覆盖新值即可。对于delete操作,undo则会记录整行的数据,rollback时通过反向操作即可恢复删除的记录。因此,insert产生的undo数据最少,update居中,delete最多。
在整表删除数据时,推荐用户使用truncate(截断)。truncate是DDL操作,通过直接释放表空间的方式删除数据,不产生undo数据,不能回退(rollback),redo数据也产生的非常少(系统的数据字典中会记录分配的存储空间的改变),执行效率很高,对系统的影响也非常小。因此,如果是整表数据删除,建议用户尽可能使用truncate操作,举例如下。
SQL> select count(*) from t1; 行号 COUNT(*) 1 10000000
使用常规的delete命令删除表t1中的全部数据记录:
SQL> delete from t1; 影响行数 10000000 已用时间: 00:00:29.708,执行号:604
回退操作,恢复所有数据:
SQL> rollback; 操作已执行 已用时间: 00:00:24.986,执行号:605
截断表t1:
SQL> truncate table t1; 操作已执行 已用时间: 25.892(毫秒),执行号:606 SQL> select count(*) from t1; 行号 COUNT(*) 1 0
可以看到,1000万条记录的表全表常规删除操作耗费了近30秒,而使用truncate只需约26毫秒。
undo中记录了数据变更前的值,如果误删除、修改了数据,能否用undo中的数据进行恢复呢?答案是肯定的,这就是闪回技术。
闪回技术主要是通过回滚段存储的undo记录来完成数据的还原。设置ENABLE_FLASHBACK为1后,开启闪回功能。达梦数据库会保留回滚段一段时间,回滚段保留的时间代表着可以闪回的时间长度,由UNDO_RETENTION参数决定。
开启闪回功能后,达梦数据库会在内存中记录下每个事务的起始时间和提交时间。通过用户指定的时刻,查询到该时刻的LSN,结合当前记录和回滚段中的undo记录,就可以还原出特定LSN的记录。
闪回查询功能完全依赖于回滚段管理,对于drop、truncate等没有产生undo的操作则不能恢复。测试如下。
因为达梦数据库的undo数据保留时间较短,undo_retention默认为90秒。因此,需要将保留时间设置长一些。本次测试将undo_retention设置为1200秒。
SQL> alter system set 'undo_retention'=1200 both;
此外,还需先将ENABLE_FLASHBACK设置为1:
SQL> alter system set 'enable_flashback'=1 both;
(1)闪回查询insert之前的数据。
查看当前时间:
SQL> select sysdate; 行号 SYSDATE 1 2022-10-11 20:10:18
查看表t1当前数据记录:
SQL> select * from t1; 行号 ID 1 1 2 2 3 3
向表t1插入一条记录,并提交:
SQL> insert into t1 values(4) 影响行数 1 SQL> commit;
查看表t1中当前的数据记录:
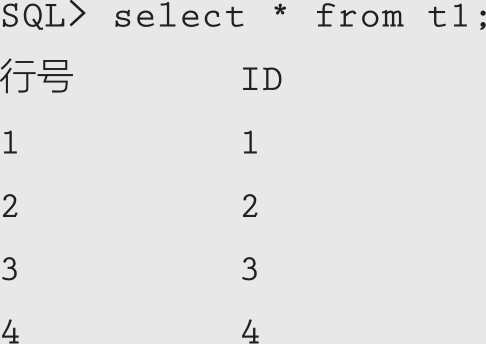
闪回查询表t1在2022-10-11 20:10:20时刻的数据:

(2)闪回查询delete的数据。
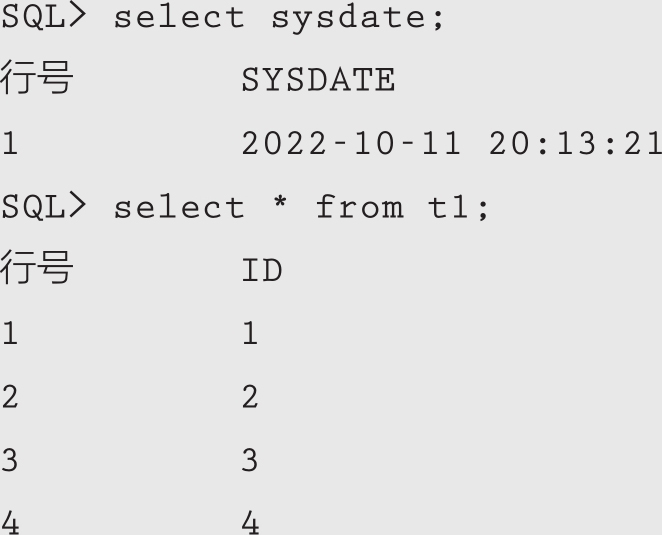
删除表t1中部分数据,并提交:
SQL> delete from t1 where id<3; 影响行数 2 SQL> commit; 操作已执行
查看表t1当前数据记录:
SQL> select * from t1; 行号 ID 1 3 2 4
闪回查询表t1在2022-10-11 20:13:22时刻的数据记录:
SQL> select * from t1 when timestamp '2022-10-11 20:13:22'; 行号 ID 1 1 2 2 3 3 4 4
(3)闪回查询update的数据。
SQL> select sysdate; 行号 SYSDATE 1 2022-10-11 20:15:40
查看表t1当前时刻的数据记录:
SQL> select * from t1; 行号 ID 1 3 2 4
更改部分数据,并提交:
SQL> update t1 set id =20 where id =3; 影响行数 1 SQL> commit;
查看表t1当前数据记录:
SQL> select * from t1; 行号 ID 1 20 2 4
闪回查询表t1在2022-10-11 20:15:41时刻的数据:
SQL> select * from t1 when timestamp '2022-10-11 20:15:41'; 行号 ID 1 3 2 4
注意 达梦数据库的闪回查询距离数据变更的时间不能超过参数undo_retention的限制,否则就无法闪回了。