
下载掌阅APP,畅读海量书库
立即打开



插入行的语法如下:
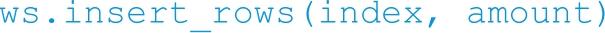
上述参数说明如下:
□ index: 插入的起始行。
□ amount: 插入的行数,如果省略amount相当于插入1行。
注 当执行插入行后,插入起始行后面的行号将会自动往下移动。
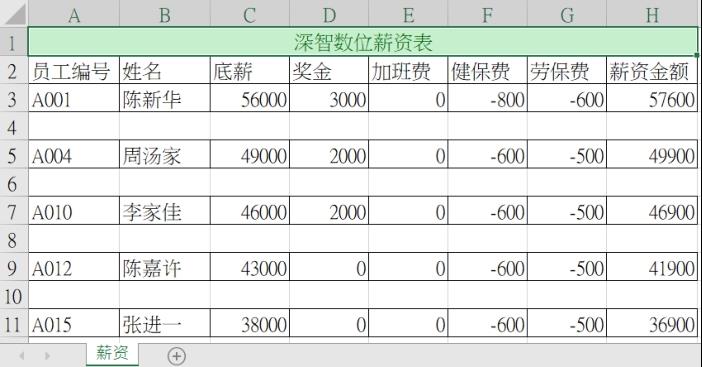
有一个 data5_1.xlsx 工作簿文件的 薪资 工作表内容如下。
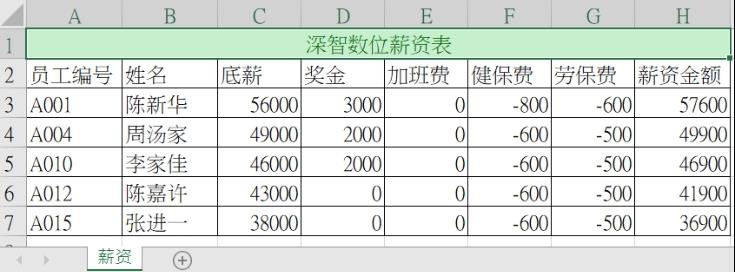
注 上述H3单元格是一个公式 =SUM(C3:G3),H4:H7概念与H3相同。
下面将从读者容易犯错的概念说起。
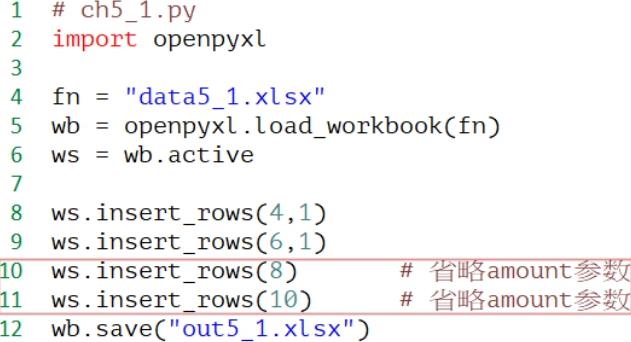
程序实例ch5_1.py: 在第4~7行上方增加1行空白行,相当于在每一个员工编号上方增加1个空白行。
执行结果 开启out5_1.xlsx可以得到如下结果。
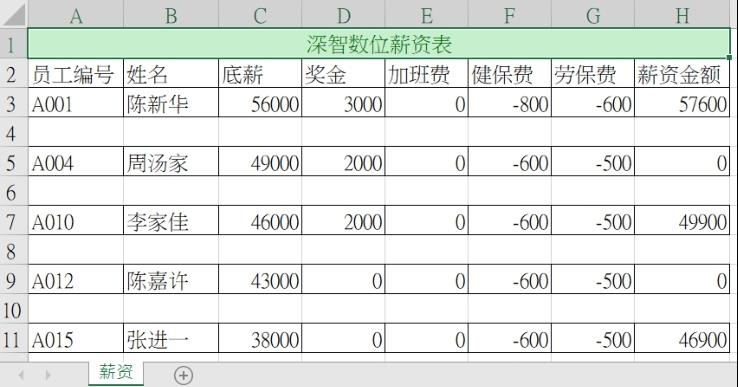
上述程序因为每插入1行空白行会造成增加1行,所以实际插入的起始行并不是连续的第4~7行。
注1 上述第10~11行省略了amount参数,表示只插入1行。
注2 从上述的H3:H11,除了H3单元格外,其余单元格的数据是错误的,因为开启文件时没有考虑H3:H7单元格是公式,程序实例ch5_2.py会做改良。
程序实例ch5_2.py: 修订ch5_1.py的错误,改良方式是在使用 load_workbook( ) 函数时增加 data_only=True 参数。

执行结果 如果开启out5_2.xlsx可以得到如下正确的结果。
从上述执行结果可以看到当插入工作表行后,会造成工作表部分框线遗失,本书将在6-3节讲解绘制框线的方法。
如果员工有100个,使用ch5_2.py不是一个很有效率的方法,这一节将使用循环方法重新设计ch5_2.py。
程序实例ch5_3.py: 使用循环的概念重新设计ch5_2.py。

执行结果 开启out5_3.xlsx可以得到和out5_2.xlsx相同的结果。
工作簿的data5_1.xlsx是财务部的薪资数据,每个月发薪资的时候,财务部需要给每位员工一份薪资条,如果只给下列数据,员工无法判断各字段的数据所代表的真实意义。

如果每个人的薪资数据上方增加明细,则可以让人一目了然。

程序实例ch5_4.py: 在薪资条上方加上薪资项目。
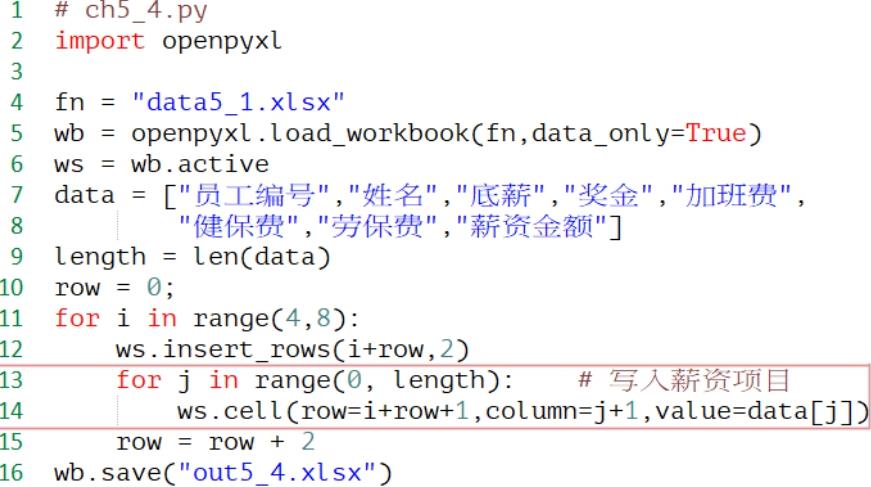
执行结果 开启out5_4.xlsx可以得到如下结果。
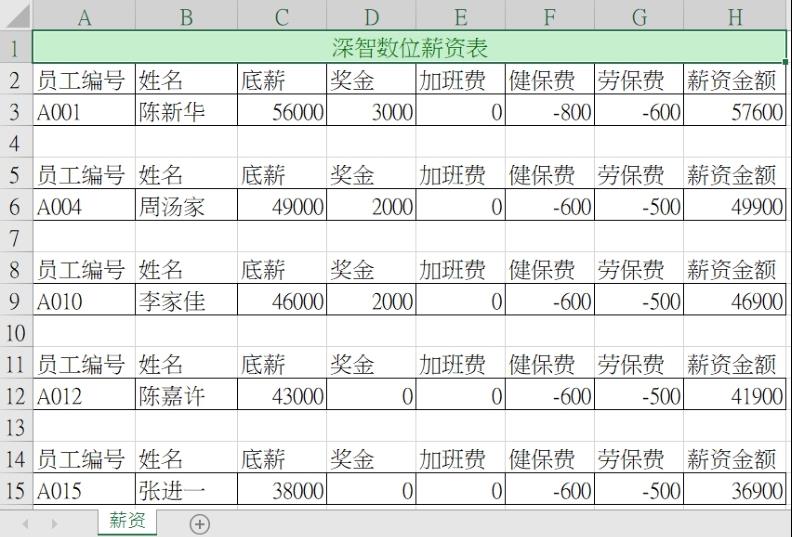
从上述可以得到每个人的薪资条上方已经有薪资项目了,其实上述程序的缺点是第7~8行,使用data重新定义了薪资项目,我们可以参考3-9-1节的概念取得薪资项目的数据,重新设计ch5_4.py程序。
程序实例ch5_4_1.py: 省略重新定义薪资项目,重新设计ch5_4.py。
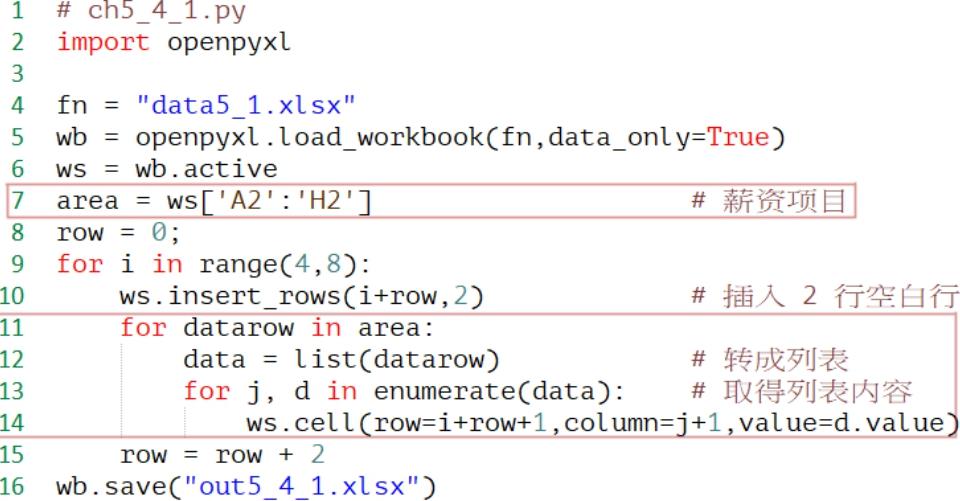
执行结果 与ch5_4.py相同。
上述程序虽然可以得到结果,但是使用了ws[‘A2’:‘H2’]获得了薪资项目,为了要解析出项目内容需使用双层for循环。其实以data5_1.xlsx工作簿而言,我们需要的只是第2行的薪资项目,可以采用3-8节的概念获得第2行数据。
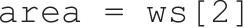
上述取得薪资项目方式可以简化整个设计,细节可以参考下列实例。
程序实例ch5_4_2.py: 使用ws[2]方式取得薪资明细,重新设计ch5_4_1.py。
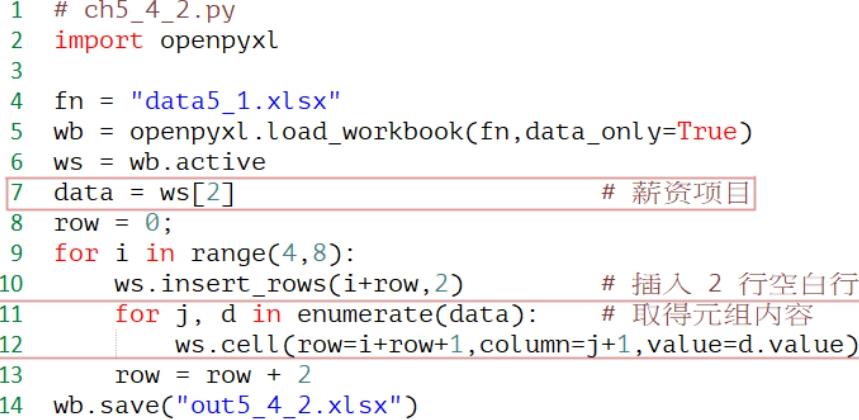
执行结果 与ch5_4_1.py相同。
程序实例ch5_4_3.py: 重新设计ch5_3.py,使用iter_row( )函数在执行插入行前和执行插入行后输出行数据,观察插入行的结果。
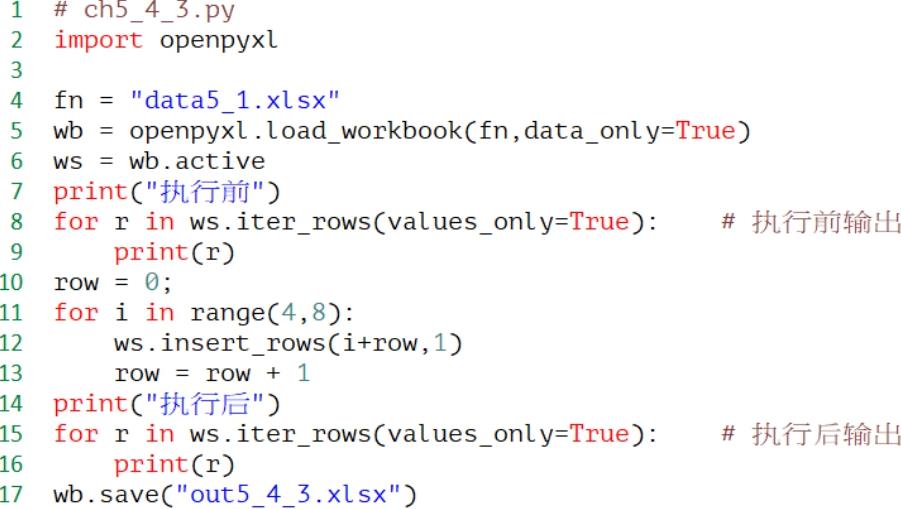
执行结果
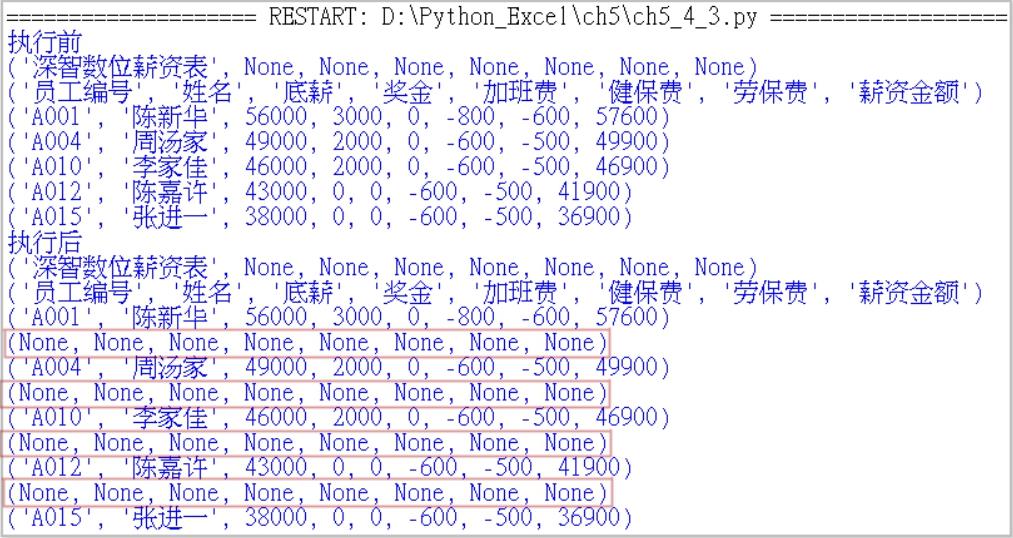
上述框起来的就是插入的行,因为尚未设定单元格内容所以得到None。如果开启out5_4_3.xlsx,可以得到和out5_3.xlsx相同的结果。