
下载掌阅APP,畅读海量书库
立即打开



在第一章中,我们将实验研究定义为“基于一定的假设,通过某种实验处理,来观察所导致的结果,最终对实验处理与实验结果之间的因果关系进行探讨的量化研究方法”。因此,实验处理和实验结果是我们开展实验研究的基本抓手。“变量”(variable)则是我们用来描述、讨论实验处理和实验结果的基本概念。也就是说,我们用不同的变量来代表实验处理和实验结果。相应地,在实验研究中,我们探究实验处理与实验结果之间的关系,正是通过考察代表实验处理的变量和代表实验结果的变量之间的关系来实现的。本节我们首先介绍变量的定义,其次举例说明它的各种类型,最后探讨它的数量化表达。
“变量”,顾名思义,就是在数值上“可变”的“量”。它对应的英文术语是variable,在《柯林斯高阶英语学习词典》(第九版)[ Collins COBUILD Advanced Learner's Dictionary (9th Edition)]里的解释是“a variable is a quantity that can have any one of a set of values”(HarperCollins 2018:1675)。因此,变量包括两个属性:第一,它是某种“量”(a quantity)的存在;第二,它在取值上有变化的范围(a set of values)。例如,一个学生某次考试的成绩就是一种“量”,而且有取值范围,如0分到100分。再如,时间也是一种“量”,也有取值范围,但它的取值范围很大,可以从0秒到正无穷秒。或许,世界上的万物都是某种“量”的存在。从理论上讲,我们完全可以把所有事物都看作变量,继而研究变量之间的关系,即研究事物之间的关系。
但是,我们需要特别明确的是,变量的取值问题实际上是人为规定的。人们为了方便描述某个事物,并把它和其他事物进行比较,人为地规定了变量的取值方式,有时也规定了变量的取值范围。就像前面提到的例子,学生考试的成绩作为一个变量,是我们人为地规定了使用分数作为取值方式,并以0到100作为取值范围。换言之,我们同样可以人为规定使用档次作为取值方式,并以A、B、C、D作为取值范围。时间的取值方式也是如此,我们人为规定了时、分、秒——这些概念并不是从来就有的。只是时间的取值范围很难人为规定,不像考试成绩较为容易规定。总之,根据不同的需要,人们对变量的取值方式完全可以有不同的规定。例如,在衡量温度变量的时候,就有摄氏、华氏等不同的方式。“变量”是人们为了生产、生活的便利,人为规定了取值方式(在某些情况下还包括取值范围)的事物。
无论开展实验研究还是阅读实验研究论文,我们首先需要明确所要研究的事物是什么,即都包括了哪些变量。我们往往从实验研究论文的题目中就能识别出这些研究所要考察的变量。例如:
(1)《不同语言经验对儿童语音意识发展的影响:维吾尔族与汉族儿童的对比研究》(韦晓保、王文斌2018)
(2)《大学英语语音音段和超音段的教学先后顺序——一项基于大学生语音学习实践的实证研究》(梁波2010)
(3)《情景反应类型、年龄和语言水平对补缺作用的影响——一项关于补缺假设的实验研究》(徐浩、林立2007)
例(1)包括了两个变量,第一个是语言经验,第二个是儿童语音意识发展,通过题目的表述我们就能了解到,研究者是在考察第一个变量对第二个变量的影响。例(2)则只包括了一个变量,即大学英语语音音段和超音段的教学先后顺序,而通过题目我们无法判定研究者在考察这种顺序对什么变量有影响。例(3)包括了四个变量:情境反应类型、年龄、语言水平和补缺作用,且可以看出研究者旨在考察前三个变量对最后一个变量的影响。
至于变量的取值方式和取值范围问题,往往需要研究者在实施实验研究前就作好系统的设计。我们将在2.2节(“因素和水平”)中作详细介绍。
变量代表我们所研究的事物,而实验研究的根本目的是揭示事物之间的关系,即变量之间的关系。因此,在实验研究中,一个变量属于哪种类型并不取决于它自身的性质和特点,而是取决于它与其他变量的关系。也就是说,我们一旦说某一个变量是哪个类型的,就同时界定了另外至少一个变量的类型。下面我们就根据变量之间可能构成的不同关系来介绍变量的类型。
首先是自变量(independent variable)和因变量(dependent variable)。自变量是引发因变量变化的原因,因变量是自变量变化所引发的结果。简单地说,自变量是原因,因变量是结果。因此,自变量和因变量之间存在因果关系。我们应当都学习过一次函数,它的表达式为y=kx+b(k、b是常数,k≠0)。假设这个表达式中,k=2,b=5,那么表达式就变成了y=2x+5。x就是自变量,y就是因变量。当x=1时,y就有了对应的取值7;x=2时,y的取值就变成了9;x=3,则y=11;以此类推。可见,自变量x的取值变化是引发因变量y变化的原因,而因变量y的不同取值是自变量x变化所引发的结果。
自变量和因变量的因果关系可能是单向的,即自变量单纯地是原因,因变量单纯地是结果。它们之间的因果关系也可能是双向的,即两个变量互为因果。例如,身心疾病/心身疾病就是典型的互为因果的情形。身心疾病,就是身体上发生病变,出现躯体症状,进而影响心理,导致精神不佳;心身疾病,则是心理上出现障碍,发生精神异常,进而影响身体,导致躯体有恙。身心也好,心身也罢,往往相互影响,密不可分。然而,在互为因果的情形中,通常都是由其中一个变量首先引发各种变化,如身心疾病中的“身”、心身疾病中的“心”。我们可以把这个变量称为诱发变量(trigger variable)。诱发变量本质上是一个初始自变量,因此通常具有更高的研究价值。
在某些实验研究中,还可能存在多个自变量和多个因变量。例如,我们研究学生的外语写作能力,就有可能将语言因素(如词汇知识)、认知因素(如构思能力)和社会因素(如同伴反馈)作为待考察的自变量,也可能将评价写作过程(如写作速度)和写作结果(如语法错误)的各个指标视为因变量。然而,在众多待考察的自变量中,往往是一个或少数几个起了主导作用。我们把这种变量称为主导变量(lead variable)。
有些变量并不直接引发其他变量的变化,但却能调节其他变量之间的关系。例如,学生的外语听力能力决定他们在某一项听力任务中的表现,即听力能力可视为自变量,任务表现可视为因变量。而焦虑程度作为一个变量,并不直接决定任务表现,或者说焦虑程度并不是决定任务表现的主导变量。但焦虑程度却能够调节听力能力与任务表现之间因果关系的强度:当焦虑程度较低时,听力能力往往能更显著地决定任务表现;但当焦虑程度较高时,听力能力对任务表现的影响力或许就会降低。因此,焦虑程度调节了其他变量(自变量和因变量)之间关系的强度。这样的变量称为调节变量(moderator variable)。调节变量可能调节其他变量之间关系的强度,还可能调节它们之间关系的方向。假设在某项口语任务中,学生在产出中出现的语言错误的数量和他们的焦虑程度之间存在因果关系,即错误数量(自变量)越多,焦虑程度(因变量)越高。此时就可能存在一个调节变量——学生对语言错误的敏感程度。当学生的敏感程度较高时,错误数量和焦虑程度之间的关系应当是成正比的;而当学生的敏感程度较低时,情况可能很不一样,错误数量的多少或许并不显著影响焦虑程度的高低。错误数量可能导致焦虑,也可能不导致焦虑,即自变量与因变量之间存在不同性质的关系(有影响或无影响),而敏感程度恰恰调节了自变量和因变量关系的性质。也就是说,敏感程度作为一个调节变量,调节了错误数量和焦虑程度之间关系的方向。总之,调节变量能够调节其他变量之间关系的强度或方向。
调节变量调节其他变量之间关系的强度或方向,而中介变量(mediator variable)则是其他变量之间的直接因果联结。生活常识告诉我们,饭前不洗手容易导致肠道疾病——显然,饭前不洗手是自变量,肠道疾病是因变量,二者之间存在因果关系。但二者之间的因果关系并非直接因果关系,在它们之间存在一个联结,即病菌的侵入。饭前不洗手直接导致病菌侵入,而病菌侵入直接导致肠道疾病。因此,病菌侵入是饭前不洗手和肠道疾病之间的直接因果联结,属于中介变量。中介变量作为直接因果联结,实质上和它所联结的两个变量都构成了因果关系,在其中一种因果关系中充当因变量,在另一种因果关系中充当自变量。也就是说,中介变量实质上联结了两种因果关系。在实验研究中,我们经常需要在已知的自变量和因变量之间寻找某个中介变量,以便更深入地解释自变量和因变量之间何以构成因果关系。一项好的研究,要么发现并验证了已知因果关系中的中介变量,要么对可能存在的中介变量提出了合理的假设以供后续研究进一步验证。
一般来说,能够影响一个变量的因素非常多。换言之,一个因变量可能拥有众多自变量,而我们并不总是希望同时研究所有的自变量。如果在一项实验研究中,因变量Y有X 1 、X 2 、X 3 三个自变量,而我们只希望考察自变量X 1 对因变量Y的影响,那么我们就需要通过某些实验方法和技术排除或消除X 2 和X 3 的干扰,即控制它们潜在的影响。这样的被采取了实验控制措施的变量称为控制变量(control variable)。控制变量本质上是自变量或潜在的自变量,只是我们在某一次特定的观察中需要对它进行屏蔽而已。这种有意识的屏蔽在生活中也非常常见。我们在测量血压前通常会保持一段时间的平静状态,因为影响血压的因素除了身体本身的器质性因素外,还包括人的运动状态。而我们测量血压是为了考察那些器质性因素,以检测健康状态,因此需要排除或消除运动状态这一控制变量带来的潜在影响。
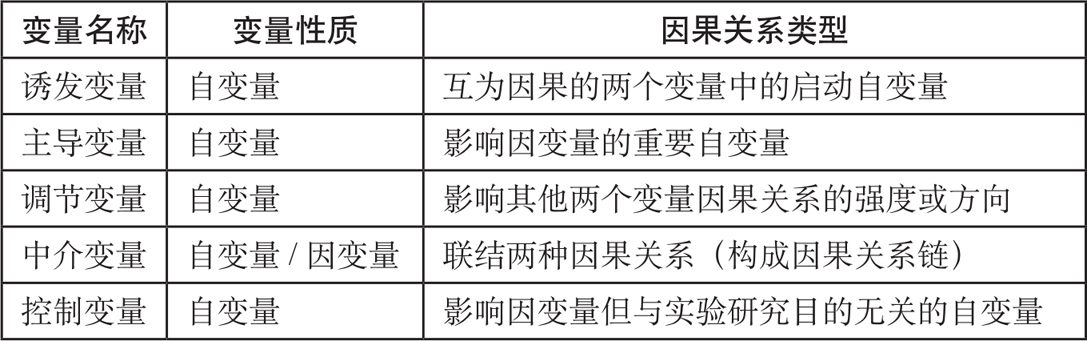
综上所述,我们通过变量之间的关系界定变量的类型。在实验研究中,最基本的关系就是因果关系,因果关系也恰恰是实验研究最希望揭示的关系。在因果关系中,自变量是原因,因变量是结果。而基于此,又衍生出各种具体的因果关系,构成了各种具体的变量类型,如诱发变量、主导变量、调节变量、中介变量、控制变量等。下表为这些变量的性质及因果关系类型。
表2.1 不同变量的因果关系类型
不论变量属于哪种类型,它们都是以数据(data)的形式进行数量化表达的。数据大致分为四种类型:称名数据(nominal data)、等级数据(ordinal data)、等距数据(interval data)和比率数据(ratio data)。
“称名数据”用名称来给变量进行赋值。例如,性别是一个变量,因为它在取“值”上可以有变化,而男、女则是为性别变量赋“值”的数据,且它们是以名称的形式出现的数据。因此严格地讲,称名数据算不上是变量的数量化表达;更贴切地讲,称名数据是变量的名称化表达。
“等级数据”则使用某种具有等级关系的序列来给变量进行赋值。例如,考试之后的排名就是等级数据。排名是具有等级关系的序列,从第一、第二、第三,一直到末位。序列中任何两个数据之间都具有明确的等级关系,但一个数据和与它相邻的两个数据之间的差距未必相等。例如,第三名显然低于第二名,但第三名与第二名的差距,未必等同于第四名与第三名的差距。因此,等级数据之间可以从等级关系的角度比较大小(谁大谁小),但无法确定大小关系在数量上的差异(无法确定大多少或小多少)。
“等距数据”则使用具有相同间距的序列来给变量进行赋值。也就是说,和等级数据相比,等距数据之间可以计算数量上的差异。例如,百分制考试的分数就属于等距数据。从0分到100分,这是一个序列,且这个序列中任何两个相邻的数据之间的数量差异都是相等的——90分和91分之间相差1分,91分和92分之间也相差1分,间距是相等的1分。等距数据不仅可以像等级数据那样比较大小,还可以计算大小关系在数量上的差异。我们完全可以说70分和80分的差距与80分和90分的差距相等。需要特别注意的是,等距数据之间可以进行加减运算,但不能进行乘除运算。讨论等距数据之间的倍数关系时应当尤为谨慎。等距数据通常只是用来表示变量在某个区间或区段的状况,等距数据的序列往往不能覆盖这个变量的全部状况。还以百分制的考试分数为例,得0分通常并不意味着没有任何学习收获。考试本身就是对所学内容进行抽样检查,分数只能反映此次抽查的情况,并不能完全反映学习的全貌。因此,等距数据一般是没有绝对零点的——序列中的0只是序列的起点而已,并不是什么都没有或不存在的意思。
“比率数据”则是具有绝对零点的等距数据,也就是说,它除了具有等距数据的全部特征外,还可以为变量赋予0这个数值,因此它的数据之间既可以进行加减运算,也可以进行乘除运算。例如,反应时(reaction time)就是典型的用比率数据进行表达的变量。反应时指从受试接受某种刺激到对刺激进行反应之间的时间差。因此,反应时理论上可能是0,是一个有绝对零点的数据。
总之,数据是对变量进行数量化表达的基本方式,不同类型的数据以不同方式为变量赋值。称名数据没有大小关系;等级数据有大小关系,但没有相等间距;等距数据有大小关系、相等间距,但没有绝对零点;只有比率数据既有大小关系、相等间距,也有绝对零点。