
下载掌阅APP,畅读海量书库
立即打开



关系型数据库建立在关系型数据模型的基础上,是借助于集合代数等数学概念和方法来处理数据的数据库。现实世界中的各种实体以及实体之间的各种联系均可用关系模型来表示,市场上占很大份额的Oracle、MySQL、DB2等都是面向关系模型的DBMS。
在关系型数据库中,实体以及实体间的联系均由单一的结构类型来表示,这种逻辑结构是一张二维表。前面图1.4所示的学生选课系统中,实体和实体间联系在数据库中的逻辑结构可通过如图1.5所示。
关系型数据库以行和列的形式存储数据,这一系列的行和列被称为表,一组表组成了数据库。如图1.6所示的员工信息表就是关系型数据库。
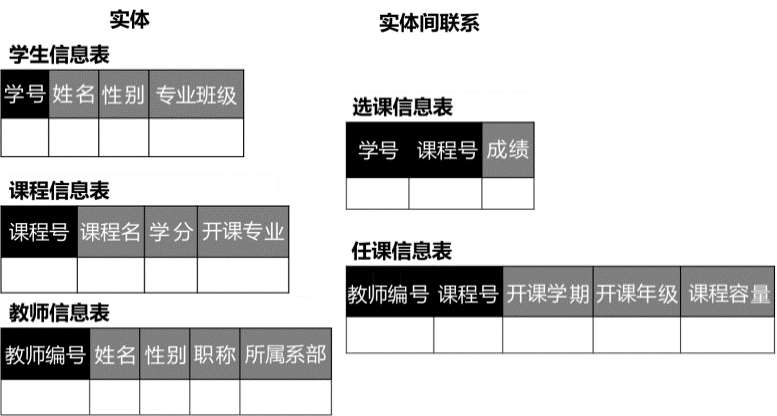
图1.5 学生选课系统数据库逻辑结构
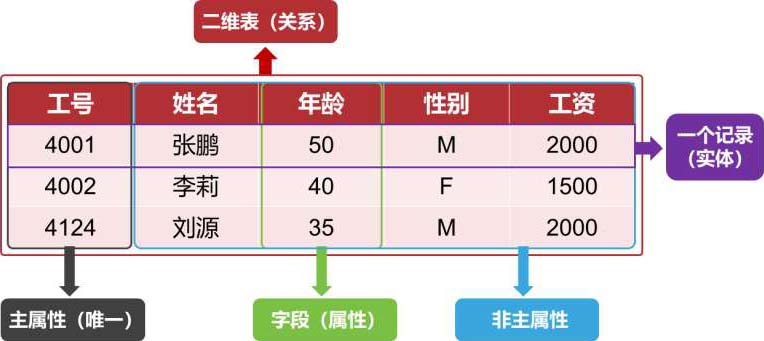
图1.6 员工信息表
(1) 二维表:也称为关系,它是一系列二维数组的集合,用来代表与存储数据对象之间的关系。它由纵向的列和横向的行组成。
(2) 行:也叫元组或记录,在表中是一条横向的数据集合,代表一个实体。
(3) 列:也叫字段或属性,在表中是一条纵行的数据集合。列也定义了表中的数据结构。
(4) 主属性:关系中的某一属性组,若它们的值唯一地标识一个记录,则称该属性组为主属性或主键。主属性可以是一个属性,也可以由多个属性共同组成。在图1-5中,学号是学生信息表的主属性,但是课程信息表中,学号和课程号共同唯一地标识了一条记录,所以学号和课程号一起组成了课程信息表的主属性。
关系型数据库的核心是其结构化的查询语言(Structured Query Language,SQL),SQL涵盖了数据的查询、操纵、定义和控制,是一个综合的、通用的且简单易懂的数据库管理语言。同时SQL又是一种高度非过程化的语言,数据库管理者只需要指出做什么,而不需要指出该怎么做即可完成对数据库的管理。SQL可以实现数据库全生命周期的所有操作,所以SQL自产生之日起就成了检验关系型数据库管理能力的“试金石”,SQL标准的每一次变更和完善都引导着关系型数据库产品的发展方向。SQL包含以下四个部分。
(1) 数据定义语言(DDL)
DDL包括CREATE、DROP、ALTER等动作。在数据库中使用CREATE来创建新表,DROP来删除表,ALTER负责数据库对象的修改。例如,创建学生信息表使用以下命令:

(2) 数据查询语言(Data Query Language,DQL)
DQL负责进行数据查询,但是不会对数据本身进行修改。DQL的语法结构如下:

(3) 数据操纵语言(Data Manipulation Language,DML)
DML负责对数据库对象运行数据访问工作的指令集,以INSERT、UPDATE、DELETE三种指令为核心,分别代表插入、更新与删除。向表中插入数据命令如下:

(4) 数据控制语言(Data Control Language,DCL)
DCL是一种可对数据访问权进行控制的指令。它可以控制特定用户账户对查看表、预存程序、用户自定义函数等数据库操作的权限,由GRANT和REVOKE两个指令组成。DCL以控制用户的访问权限为主,GRANT为授权语句,对应的REVOKE是撤销授权语句。
关系型数据库已经发展了数十年,其理论知识、相关技术和产品都趋于完善,是目前世界上应用最广泛的数据库系统。
(1) 关系型数据库的优点
● 容易理解:二维表结构非常贴近逻辑世界的概念,关系型数据模型相对层次型数据模型和网状型数据模型等其他模型来说更容易理解。
● 使用方便:通用的SQL使用户操作关系型数据库非常方便。
● 易于维护:丰富的完整性大大减少了数据冗余和数据不一致的问题。关系型数据库提供对事务的支持,能保证系统中事务的正确执行,同时提供事务的恢复、回滚、并发控制和死锁问题的解决。
(2) 关系型数据库的缺点
随着各类互联网业务的发展,关系型数据库难以满足对海量数据的处理需求,存在以下不足。
● 高并发读写能力差:网站类用户的并发性访问非常高,而一台数据库的最大连接数有限,且硬盘I/O有限,不能满足很多人同时连接。
● 对海量数据的读写效率低:若表中数据量太大,则每次的读写速率都将非常缓慢。
● 扩展性差:在一般的关系型数据库系统中,通过升级数据库服务器的硬件配置可提高数据处理的能力,即纵向扩展。但纵向扩展终会达到硬件性能的瓶颈,无法应对互联网数据爆炸式增长的需求。还有一种扩展方式是横向扩展,即采用多台计算机组成集群,共同完成对数据的存储、管理和处理。这种横向扩展的集群对数据进行分散存储和统一管理,可满足对海量数据的存储和处理的需求。但是由于关系型数据库具有数据模型、完整性约束和事务的强一致性等特点,导致其难以实现高效率的、易横向扩展的分布式架构。
NoSQL数据库最初是为了满足互联网的业务需求而诞生的。互联网数据具有大量化、多样化、快速化等特点。在信息化时代背景下,互联网数据增长迅猛,数据集合规模已实现从GB、PB到ZB的飞跃。数据不仅仅是传统的结构化数据,还包含了大量的非结构化和半结构化数据,关系型数据库无法存储此类数据。因此,很多互联网公司着手研发新型的、非关系型的数据库,这类非关系型数据库统称为NoSQL数据库,其主要特点如下。
互联网数据如网站用户信息、地理位置数据、社交图谱、用户产生的内容、机器日志数据以及传感器数据等,正在快速改变着人们的通信、购物、广告、娱乐等日常生活,没有使用这些数据的应用很快就会被用户所遗忘。开发者希望使用非常灵活的数据库,容纳新的数据类型,并且不会被第三方数据提供商的数据结构变化所影响。关系型数据库的数据模型定义严格,无法快速容纳新的数据类型。例如,若要存储客户的电话号码、姓名、地址、城市等信息,则SQL数据库需要提前知晓要存储的是什么。这对于敏捷开发模式来说十分不方便,因为每次完成新特性时,通常都需要改变数据库的模式。NoSQL数据库提供的数据模型则能很好地满足这种需求,各种应用可以通过这种灵活的数据模型存储数据而无须修改表;或者只需增加更多的列,无须进行数据的迁移。
对企业来说,关系型数据库一开始是普遍的选择。然而,在使用关系型数据库的过程中却遇到了越来越多的问题,原因在于它们是中心化的,是纵向扩展而不是横向扩展的。这使得它们不适合那些需要简单且动态可伸缩性的应用。NoSQL数据库从一开始就是分布式、横向扩展的,因此非常适合互联网应用分布式的特性。在互联网应用中,当数据库服务器无法满足数据存储和数据访问的需求时,只需要增加多台服务器,将用户请求分散到多台服务器上,即可减少单台服务器的性能瓶颈出现的可能性。
由于关系型数据库存储的是结构化的数据,所以通常采用纵向扩展,即单台服务器要持有整个数据库来确保可靠性与数据的持续可用性。这样做的代价是非常昂贵的,而且扩展也会受到限制。针对这种问题的解决方案就是横向扩展,即添加服务器而不是扩展单台服务器的处理能力。NoSQL数据库通常都支持自动分片,这意味着它们会自动地在多台服务器上分发数据,而不需要应用程序增加额外的操作。
NoSQL数据库支持自动复制。在NoSQL数据库分布式集群中,服务器会自动对数据进行备份,即将一份数据复制存储在多台服务器上。因此,当多个用户访问同一数据时,可以将用户请求分散到多台服务器中。同时,当某台服务器出现故障时,其他服务器的数据可以提供备份,即NoSQL数据库的分布式集群具有高可用性与灾备恢复的能力。