
下载掌阅APP,畅读海量书库
立即打开



机器学习算法往往无法直接使用原始数据。即使使用原始数据,机器学习算法也很少能达到其最佳性能。因此,数据的预处理是任何机器学习应用过程中最关键的步骤之一。
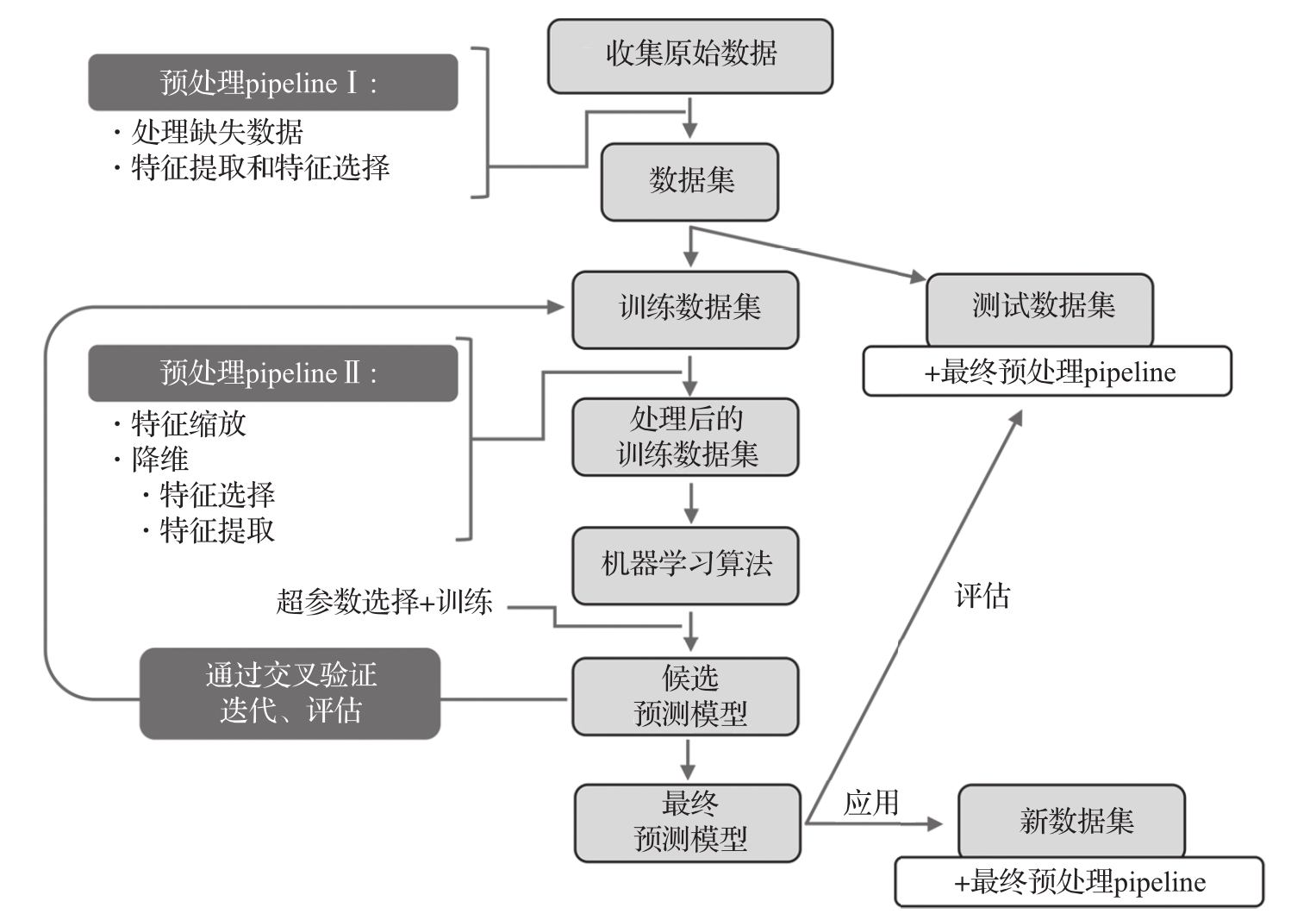
图1.9 模型预测工作流程
以上一节中的鸢尾花数据集为例,可以将原始数据视为一系列花的图像,希望能从这些图像中提取关于花的有意义或有用的特征,如花的颜色、高度、长度、宽度等。
许多机器学习算法为了达到其最佳性能,一般要求所选的特征具有相同的数值范围。通常做法是通过特征转换将特征的值变换到[0,1]范围内;另一种方法是将特征的均值变为0、方差变为1。这些将在后续章节中继续讨论。
某些特征之间可能高度相关,因此这些特征在一定程度上是冗余的。在这种情况下,数据降维可以将特征压缩到低维子空间中。降低特征空间维数的一个好处是可以减小存储数据所需要的空间,提高机器学习算法的运行速度。在某些情况下,如果数据集包含大量与预测任务不相关的特征(或噪声),换言之数据具有低的信噪比,那么数据降维还可以提高模型的预测性能。
为了确定机器学习算法不仅在训练数据集上表现良好,而且能够在新的数据上也表现很好(或者说泛化能力强),一般将数据集随机划分为训练数据集和测试数据集。使用训练数据集训练和优化机器学习模型,然后使用测试数据集评估最终模型的性能。