
下载掌阅APP,畅读海量书库
立即打开



监督学习的主要目的是从有标签的训练数据中学习一个模型,并用该模型预测未知或未来无标签数据的标签。这里,“监督”一词指的是训练样本(输入数据)的标签(输出数据)已知。监督学习建模输入数据和标签之间的关系。因此,也可以将监督学习视为“标签学习”。
图1.2总结了一个监督学习的典型工作流程。首先,将带有标签的训练数据提供给机器学习算法,用于拟合预测模型;然后,拟合后的预测模型可以用于预测新的无标签数据的标签。
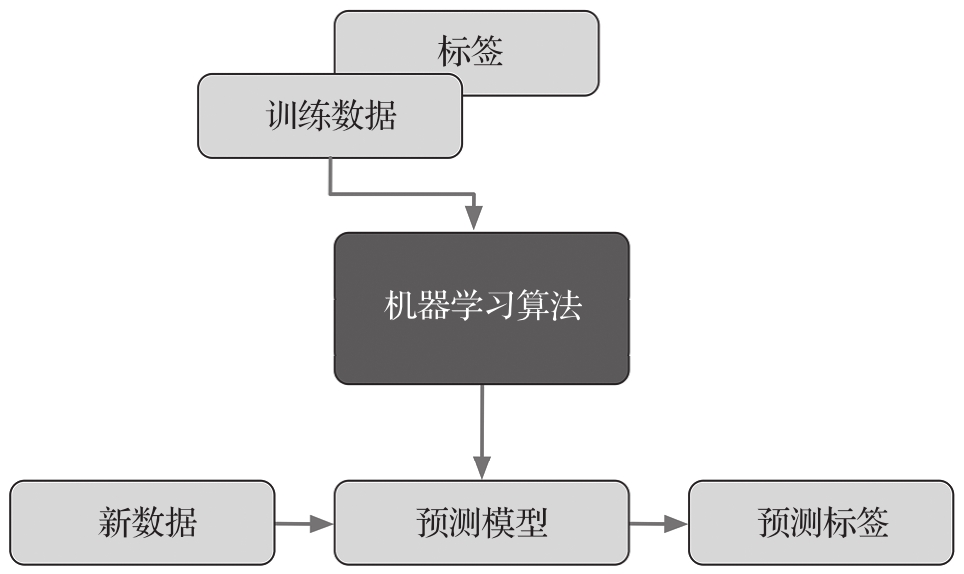
图1.2 监督学习过程
以过滤垃圾邮件为例,提供标记为垃圾邮件或非垃圾邮件的样本库
 ,可以使用监督机器学习算法训练模型,以预测新的电子邮件是否属于垃圾邮件。在监督学习中,如果标签是离散类型数据(如本小节中提到的过滤垃圾邮件任务),则该任务被称为分类任务。另一个监督学习的任务称为回归任务,其标签为连续数值。
,可以使用监督机器学习算法训练模型,以预测新的电子邮件是否属于垃圾邮件。在监督学习中,如果标签是离散类型数据(如本小节中提到的过滤垃圾邮件任务),则该任务被称为分类任务。另一个监督学习的任务称为回归任务,其标签为连续数值。
分类是监督学习的一个子任务,其目标是根据过去的观测结果来预测新样本或新数据的类别标签。这些类别标签是离散的、无序的数值,可以理解为数据的类别归属。前面提到的垃圾邮件检测就是一个典型的二分类任务,其中机器学习算法通过学习一组规则来区分两种可能的邮件类别,即垃圾邮件和非垃圾邮件。
图1.3利用30个训练样本来阐述二分类任务的概念。在30个训练样本中,15个训练样本被标记为A类,另外15个训练样本被标记为B类。该数据集为二维数据,每个样本都有两个值,即 x 1 和 x 2 。可以使用监督机器学习算法来学习一个分类规则,即决策边界(图1.3中的虚线),将两类训练数据分开。给一个新样本,决策边界可以根据新样本的 x 1 和 x 2 值将其分类到这两个类别中的一个。
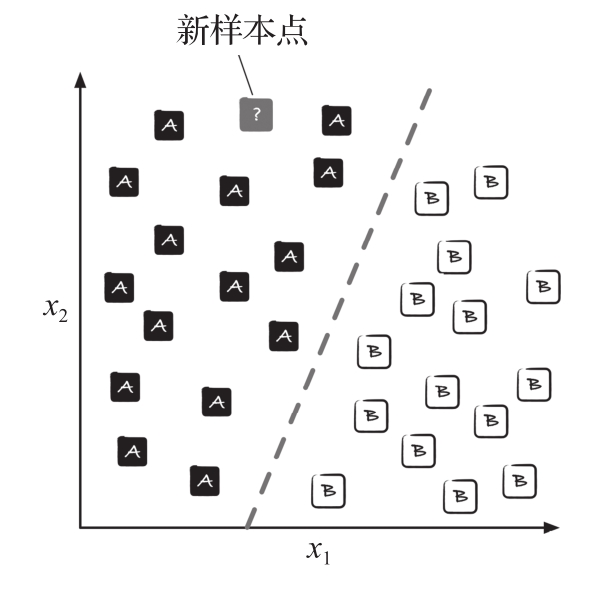
图1.3 对新样本点进行分类
并非所有问题中的类别标签都只有两个类别。监督学习算法学习到的预测模型可以将训练数据集中出现的任何类别标签分配给新的、无标签的数据或样本。
多类别分类任务的一个典型例子是手写字符识别。可以收集字母表中每个字母的多个手写图片样本,组成训练数据集。字母(“A”“B”“C”等)代表模型想要预测的无序类别标签。当用户通过输入设备提供一个新的手写字图片时,使用训练数据训练好的预测模型能够以一定的准确率预测这个手写字图片对应的字母。然而,如果给定的图片不属于训练数据集的一部分,比如0和9之间的任何数字,那么该机器学习系统将无法正确识别手写字图片的标签。
上一节介绍的分类任务是为实例分配离散的、无序的类别标签。第二种监督学习类型是预测连续数据类型的标签,也被称为回归分析(或者回归)。给定一系列预测(解释)变量和一个连续的响应变量(结果),回归分析试图找到这些变量之间的关系,从而能够预测结果。
请注意,在机器学习领域,预测变量通常被称为“特征”,响应变量通常被称为“目标变量”。本书通篇采用此命名习惯。
以预测学生的数学SAT(SAT是美国大学招生常用的标准化考试)分数为例。如果备考花费的学习时间与SAT分数之间存在关系,那么可以将学习时间和SAT分数作为训练数据,以此训练一个模型,该模型可以根据学生的学习时间来预测SAT分数。
均值回归
1886年,Francis Galton在其论文“Regression towards Mediocrity in Hereditary Stature”中首次提到回归一词。Galton描述了一种生物学现象,即种群身高的变化不会随时间的推移而增加。
他观察到父母的身高不会遗传给自己的孩子,相反,孩子的身高会回归到人群身高的均值。
图1.4展示了线性回归的概念。给定一个特征变量 x 和一个目标变量 y ,为该数据拟合一条直线,使数据点和拟合直线之间的距离(通常用均方距离,即平均平方距离)最小。
现在可以从该数据中获得直线的截距和斜率,并以此预测新数据的目标变量。