
下载掌阅APP,畅读海量书库
立即打开



谈到大数据处理引擎,不能不提Spark。Apache Spark是一个通用大规模数据分析引擎。它提出的内存计算概念让人们耳目一新,让程序员得以从Hadoop繁重的MapReduce程序中解脱出来,可以说是划时代的大数据处理框架。除了计算速度快、可扩展性强,Spark还为批处理(Spark SQL)、流处理(Spark Streaming)、机器学习(Spark MLlib)、图计算(Spark GraphX)提供了统一的分布式数据处理平台,整个生态经过多年的蓬勃发展已经非常完善。
然而,正在人们认为Spark已经“如日中天”、即将“一统天下”之际,Flink如一颗新星“异军突起”,使得大数据处理的“江湖”再起风云。很多读者在最初接触大数据处理时都会有这样的疑问:想学习一个大数据处理框架,到底应该选择Spark,还是Flink呢?
这就需要了解两者的主要区别,理解它们在不同领域的优势。
我们已经知道,数据处理的基本方式可以分为批处理和流处理两种。
批处理针对的是有界数据集,非常适合必须访问海量的全部数据才能完成的计算工作,一般用于离线统计。
流处理主要针对的是数据流,特点是无界、实时,对系统传输的每个数据依次执行操作,一般用于实时统计。
从根本上来说,Spark和Flink采用了完全不同的数据处理方式。
Spark以批处理为根本,并尝试在批处理之上支持流计算;在Spark的世界中,“万物皆批次”,离线数据是一个大批次,而实时数据则是由无限个小批次组成的。因此,对流处理框架Spark Streaming而言,其实并不是真正意义上的流处理,而是“微批次”(micro-batching)处理,如图1-12所示。

图1-12 Spark Streaming流处理示意图
Flink则认为流处理才是最基本的操作,批处理也可以统一为流处理。在Flink的世界中,“万物皆流”,实时数据是标准的、没有界限的流,而离线数据则是有界限的流。图1-13就是所谓的无界数据流和有界数据流。
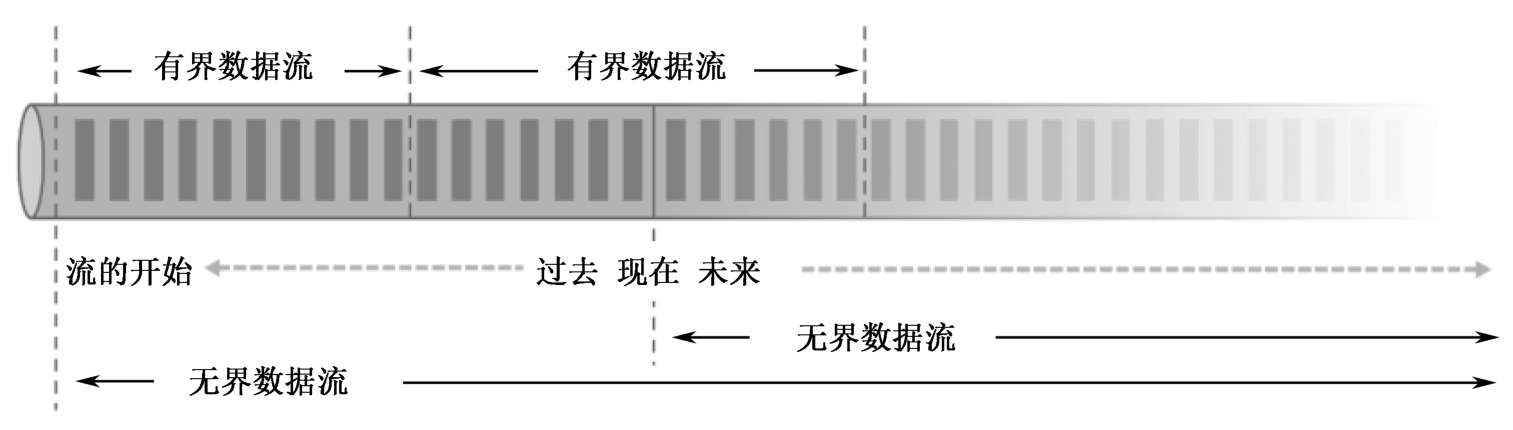
图1-13 无界数据流和有界数据流
1.无界数据流
无界数据流有头没尾,数据的生成和传递会开始,但永远不会结束。我们无法等待所有数据都到达,因为输入是无界的,数据没有“都到达”的时候。因此,对于无界数据流,必须连续处理,即必须在获取数据后立即处理。在处理无界数据流时,为了保证结果的正确性,必须做到按照顺序处理数据。
2.有界数据流
相应地,有界数据流有明确定义的开始和结束,因此,我们可以通过获取所有数据来处理有界数据流。处理有界数据流就不需要严格保证数据的顺序了,因为总可以对有界数据集进行排序。有界数据流的处理也就是批处理。
正因为这种架构上的不同,Spark和Flink在不同应用领域中的表现会有差别。一般来说,Spark基于微批处理的方式做同步,总有一个攒批的过程,所以会有额外开销,故无法在流处理的低延迟上做到极致。在低延迟流处理场景,Flink已经有明显的优势;而在海量数据的批处理领域,Spark能够处理的吞吐量更高,加上其完善的生态和成熟易用的API,目前同样优势比较明显。
Spark和Flink在底层实现上最主要的差别在于数据模型不同。
Spark底层数据模型是弹性分布式数据集(RDD),Spark Streaming进行微批次处理的底层接口DStream实际上处理的也是一组一组的小批数据RDD的集合。可以看出,Spark在设计上本身就是以批量的数据集作为基准的,更加适合批处理的场景。
Flink的基本数据模型是数据流(DataFlow)和事件(Event)序列。Flink基本上是完全按照Google的DataFlow模型实现的,因此,从底层数据模型上看,Flink是以处理流式数据作为设计目标的,更加适合流处理的场景。
数据模型不同,对应在运行处理的流程上,自然也会有不同的架构。Spark进行批计算,需要将任务对应的DAG划分阶段(Stage),一个阶段完成后,经过shuffle再进行下一阶段的计算;而Flink是标准的流式执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。
通过前面的分析可以看出,Spark和Flink目前各有所长,在批处理领域,Spark具有优势;而在流处理方面,Flink当仁不让。具体到项目应用中,不仅要看是流处理还是批处理,还需要在延迟、吞吐量、可靠性,以及开发容易度等多个方面进行权衡。
如果在工作中需要从Spark和Flink这两个主流框架中选择一个进行实时流处理,我们更加推荐使用Flink,主要原因如下。
· Flink的延迟是毫秒级别的,而Spark Streaming的延迟是秒级的。
· Flink提供了严格的精确一次(exactly-once)性语义保证。
· Flink的窗口API更加灵活、语义更丰富。
· Flink提供事件时间语义,可以正确处理延迟数据。
· Flink提供了更加灵活的对状态编程的API。
基于以上特点,使用Flink可以解放程序员,提高编程效率,把本来需要程序员费时费力手动完成的工作交给框架去完成。
当然,在海量数据的批处理方面,Spark还是具有明显的优势的,而且Spark的生态更加成熟,也会使其在应用中更为方便。相信随着Flink的快速发展和完善,这方面的差距会越来越小。
另外,Spark 2.0之后新增的Structured Streaming流处理引擎借鉴DataFlow进行了大量优化,同样做到了低延迟、时间正确性及精确一次性语义保证;Spark 2.3以后引入的连续处理(Continuous Processing)模式更是可以在至少一次语义保证下做到1ms的延迟。Flink自1.9版本合并Blink以来,在SQL的表达和批处理的能力上同样有了长足的进步。
那如果现在要学习一门框架的话,优先选择Spark还是Flink呢?其实可以看到,不同的框架各有利弊,它们也在互相借鉴、取长补短、不断发展,至于未来是Spark还是Flink,甚至是其他新崛起的处理引擎“一统江湖”,都是有可能的。作为技术人员,我们应该对不同的架构和思想都有所了解,只有跳出某个框架的限制,才能看到更广阔的世界。