
下载掌阅APP,畅读海量书库
立即打开



对数据处理系统的架构来说,其最简单的实现方式当然就是单节点。当数据量增大、处理计算更加复杂时,我们可以考虑增加CPU数量、加大内存,也就是让这一台机器变得性能更强大,从而提高吞吐量——这就是所谓的SMP(Symmetrical Multi-Processing,对称多处理)架构。但是这样做的问题非常明显:所有CPU都是完全平等、共享内存和总线资源的,这就势必造成资源竞争;而且随着CPU核心数量的增加,机器的成本会呈指数级增长,所以SMP的可扩展性是比较差的,无法应对海量数据的处理场景。
于是人们提出了“不共享任何东西”(share-nothing)的分布式架构。从以Greenplum为代表的MPP(Massively Parallel Processing,大规模并行处理)架构,到以Hadoop、Spark为代表的批处理架构,再到以Storm、Flink为代表的流处理架构,都是以分布式作为系统架构的基本形态的。
我们已经知道,Flink就是一个分布式的并行流处理系统。简单来说,它由多个进程构成,这些进程一般会分布运行在不同的机器上。
正如一个团队,人多了就会难以管理;对一个分布式系统来说,也需要面对很多棘手的问题。其中的核心问题有:集群中资源的分配和管理、进程协调调度、持久化和高可用的数据存储,以及故障恢复。
对这些分布式系统的经典问题,业内已有比较成熟的解决方案和服务,所以Flink并不会自己去处理所有的问题,而是利用现有的集群架构和服务,这样它就可以把精力集中在核心工作——分布式数据流处理上了。Flink可以配置为独立(Standalone)集群运行,也可以方便地跟一些集群资源管理工具集成使用,如YARN、Kubernetes和Mesos。Flink也不会自己去提供持久化的分布式存储,而是直接利用已有的分布式文件系统(如HDFS)或对象存储(如S3)。对于高可用的配置,Flink是依靠Apache ZooKeeper来完成的。
我们要重点了解的,就是在Flink中有哪些组件、是怎样具体实现一个分布式流处理系统的。如果大家对Spark或Storm比较熟悉,那么稍后就会发现,Flink其实有类似的概念和架构。
在Flink的运行时架构中,最重要的就是两大组件:作业管理器和任务管理器。对于一个提交执行的作业,JobManager是真正意义上的“管理者”,负责管理调度,所以在不考虑高可用的情况下只能有一个;而TaskManager是“工作者”(Worker、Slave),负责执行任务处理数据,所以可以有一个或多个。Flink的作业提交和任务处理时的系统如图4-1所示。
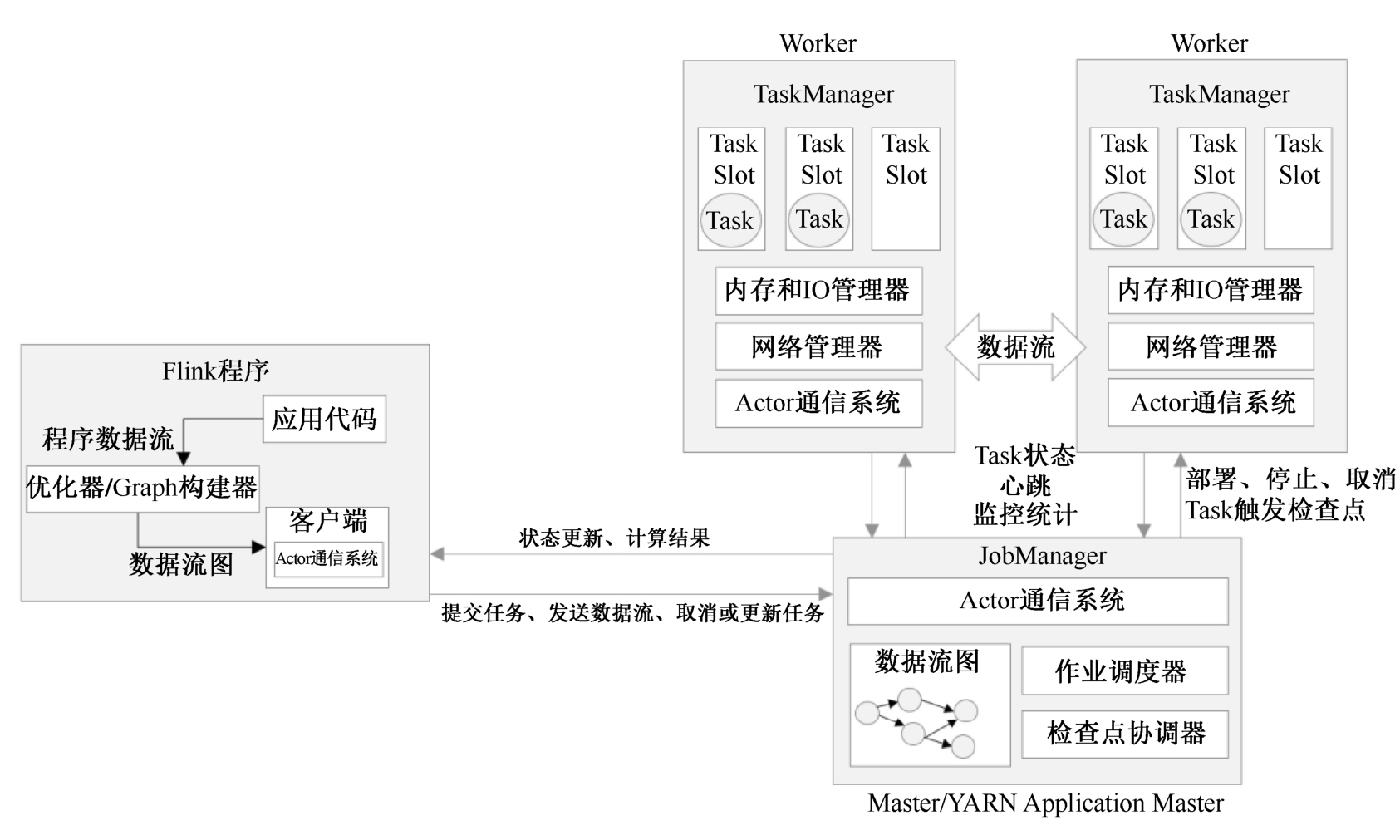
图4-1 Flink的作业提交和任务处理时的系统
这里首先要说明一下“客户端”。其实客户端并不是处理系统的一部分,它只负责作业的提交。具体来说,就是调用程序的main方法,将代码转换成“数据流图”(Dataflow Graph),并最终生成作业图(JobGraph),一并发送给JobManager。提交之后,任务的执行其实就跟客户端没有关系了;我们可以在客户端选择断开与JobManager的连接,也可以继续保持连接。之前我们在命令提交作业时,加上的-d参数,就是表示分离模式(detached mode),也就是断开连接。
当然,客户端可以随时连接到JobManager,获取当前作业的状态和执行结果,也可以发送请求取消作业。我们在上一章中不论通过Web UI还是命令行执行“flink run”的相关操作,都是通过客户端实现的。
JobManager和TaskManager可以以不同的方式启动。
· 作为独立集群的进程,直接在机器上启动。
· 在容器中启动。
· 由资源管理平台调度启动,如YARN、K8s。
这其实就对应着不同的部署方式。
TaskManager启动之后,JobManager会与它建立连接,并将作业图转换成可执行的“执行图”(ExecutionGraph)分发给可用的TaskManager,然后就由TaskManager具体执行任务。接下来,我们就具体介绍一下JobManger和TaskManager在整个过程中扮演的角色。
JobManager是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。也就是说,每个应用都应该被唯一的JobManager控制执行。当然,在高可用(HA)的场景下,可能会出现多个JobManager,这时只有一个是正在运行的领导节点,其他都是备用节点。
JobManger又包含3个不同的组件,下面我们一一讲解。
1.JobMaster
JobMaster是JobManager中最核心的组件,负责处理单独的作业(job)。这里我们把对数据进行处理的操作统称为“任务”(task),多个任务按照一定的先后顺序连接起来,就构成了“作业”(job)。所以JobMaster和具体的job是一一对应的,多个job可以同时运行在一个Flink集群中,每个job都有一个自己的JobMaster。需要注意,在早期版本的Flink中,没有JobMaster的概念;而JobManager的概念范围较小,实际指的就是现在所说的JobMaster。
在作业提交时,JobMaster会先接收到要执行的应用。这里所说的“应用”一般是客户端提交来的,包括:jar包、数据流图(dataflow graph)和作业图。
JobMaster会把JobGraph转换成一个物理层面的数据流图,这个图被叫作“执行图”,它包含了所有可以并发执行的任务。JobMaster会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。
在运行过程中,JobMaster会负责所有需要中央协调的操作,如检查点的协调。
2.资源管理器
ResourceManager主要负责资源的分配和管理,在Flink集群中只有一个。所谓“资源”,主要是指TaskManager的任务槽(task slots)。任务槽就是Flink集群中的资源调配单元,包含了机器用来执行计算的一组CPU和内存资源。每个任务都需要分配到一个slot上执行。
这里注意要把Flink内置的ResourceManager和其他资源管理平台(如YARN)的ResourceManager区分开。
Flink的ResourceManager针对不同的环境和资源管理平台(如Standalone部署,或者YARN),有不同的具体实现。在Standalone部署时,因为TaskManager是单独启动的(没有Per-Job模式),所以ResourceManager只能分发可用TaskManager的任务槽,不能单独启动新TaskManager。
而在有资源管理平台时,就不受此限制。当新的作业申请资源时,ResourceManager会将有空闲槽位的TaskManager分配给JobMaster。如果ResourceManager没有足够的任务槽,它还可以向资源提供平台发起会话,请求提供启动TaskManager进程的容器。另外,ResourceManager还负责停掉空闲的TaskManager,释放计算资源。
3.分发器
Dispatcher主要负责提供一个REST接口,用来提交作业,并且负责为每个新提交的作业都启动一个新的JobMaster组件。Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中并不是必需的,在不同的部署模式下可能会被忽略。
TaskManager是Flink中的工作进程,数据流的具体计算任务就是它来做的,所以也被称为“Worker”。Flink集群中必须至少有一个TaskManager;当然由于分布式计算的考虑,通常会有多个TaskManager运行,每个TaskManager都包含了一定数量的任务槽。slot是资源调度的最小单位,slots的数量限制了TaskManager能够并行处理的任务数量。
启动之后,TaskManager会向资源管理器注册它的slots;收到资源管理器的指令后,TaskManager就会将一个或多个槽位提供给JobMaster调用,JobMaster就可以分配任务来执行了。
在执行过程中,TaskManager可以缓冲数据,还可以跟其他运行同一应用的TaskManager交换数据。