
下载掌阅APP,畅读海量书库
立即打开



在第2章中,我们在集成开发环境里编写了Flink代码,然后运行测试。细心的读者应该会发现:对于读取文本流的流处理程序,运行之后其实并不会去直接执行代码中定义好的操作,因为这时还没有数据;只有在输入数据之后,才会触发分词转换、分组统计的一系列处理操作。可明明我们的代码是顺序执行的,会调用flatMap、keyBy和sum等一系列处理方法,这是怎么回事呢?
这涉及Flink作业提交运行的原理。我们编写的代码,对应着在Flink集群上执行的一个作业;所以我们在本地执行代码,其实是先模拟启动一个Flink集群,然后将作业提交到集群上,创建好要执行的任务等待数据输入。
这里需要提到Flink中的几个关键组件:客户端(Client)、作业管理器(JobManager)和任务管理器(TaskManager)。我们的代码实际上是由客户端获取并做转换,之后提交给JobManger的。所以JobManager就是Flink集群里的“领导者”,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的TaskManager。这里的TaskManager,就是真正“干活的人”,数据的处理操作都是它们来做的,如图3-1所示。
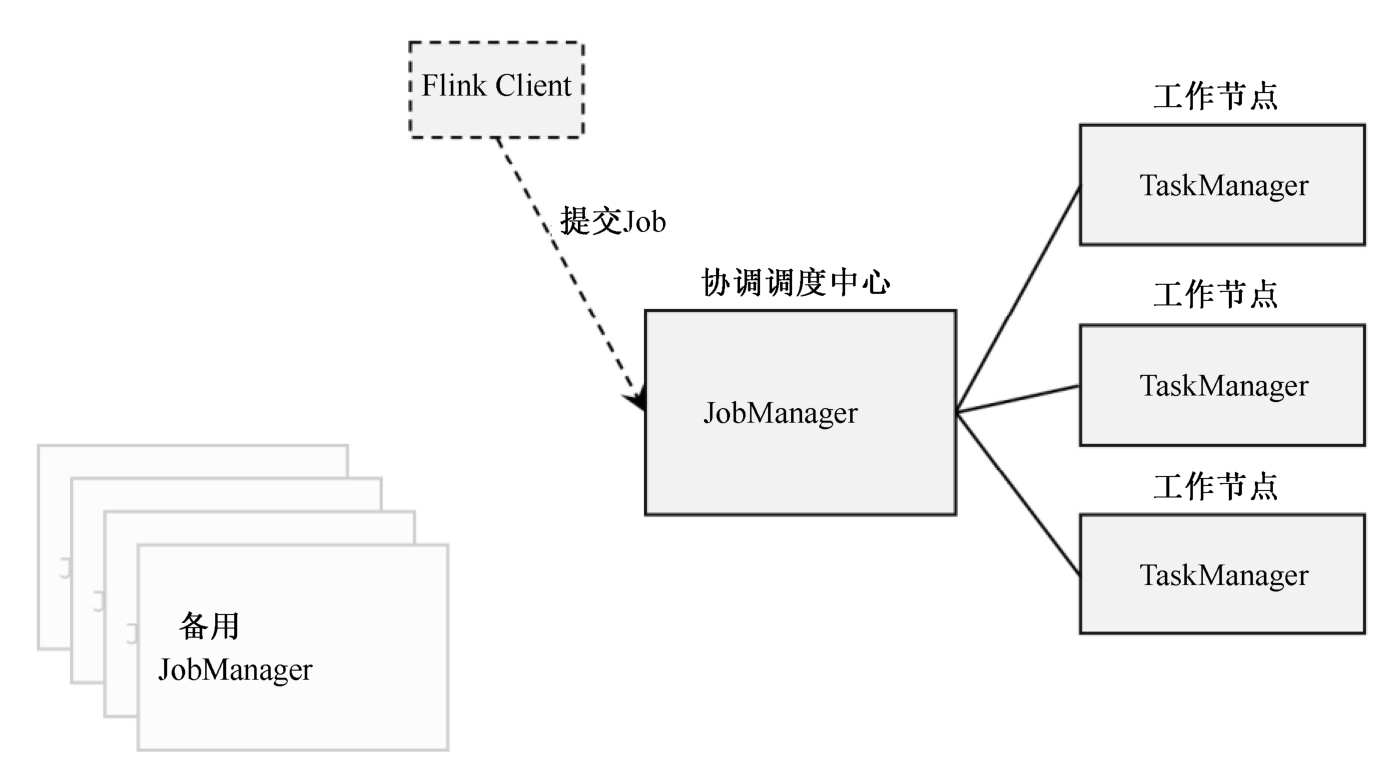
图3-1 Flink集群中的主要组件
关于Flink中各组件的作用和作业提交及运行时的架构,我们会在下一章详细展开讲解。
在实际项目应用中,我们当然不能使用开发环境的模拟集群,而是需要将Flink部署在生产集群环境中,然后再将作业提交到集群上运行。本章我们就来介绍Flink的部署及作业提交的流程。
Flink是一个非常灵活的处理框架,它支持多种不同的部署场景,还可以和不同的资源管理平台方便地集成。接下来,我们会先做一个简单的介绍,让大家对Flink部署有一个初步的认识,之后再展开讲述不同情形下的Flink部署。