
下载掌阅APP,畅读海量书库
立即打开



我们在本章中已经看到了几个单变量的图形示例,这些示例只包含有一个数据的因变量,比如图3.1中的柱状图和螺旋图,或图3.10中的气温图。然而,在实际操作中,仅有一个因变量是远远不够的,我们还需要分辨出多个甚至所有因变量之间的关系或联系。因此,我们就需要借助多元图形技术来解决这个问题。
多元数据图形主要用于显示数据集的因变量,也就是属性A。下面我们来介绍多元图形技术的几种基本类型。每种类型都有不同的绘制方案,这些方案遵循它们各自的可视化基本操作原理。我们将要讨论到:
● 基于表格的图形
● 组合双变量图形
● 基于多边形的图形
● 基于符号的图形
● 基于像素的图形
● 嵌套图形
关于时间T和空间S,以及数据元素间的关系R等自变量,我们将在本章后面几节中讨论。
我们在第2.2.1节中提到,多元数据通常会以数据表格的形式存在,其中列代表数据属性,行代表数据元组。具体由表格程序将其转换为电子表格,其中各行各列的数据值以文本形式显示。尽管电子表格非常适合精确读取和编辑数据值,但几乎没法用于理解数据的多元化关系。另外,数据值的文本内容要求每个单元格都要有一定的空间,这就限制了可以显示的数据元组的数量。
在这种情况下,我们可以用一种比较灵活的办法,就是保留电子表格,同时把数据值的文本内容换成图形。这样一来,图形比文本更容易理解,而且尺寸也比洋洋洒洒的许多字要小得多。
根据数据域的属性,我们可以使用不同的图形元素。通常情况下,表格里的单元格会用不同的颜色来表示。对于标量数据,可以将条形图插入单元格,然后根据数据值改变条形图的长度(可以理解为进度条)。也可以将长度和颜色结合使用,具体参考图3.9中的双色调图形方案。如图3.15所示就是基于双色调图形的示例。图中显示的是400辆汽车的七种车辆参数,按照每加仑
 汽油能跑的里程(MPG)来排序。
汽油能跑的里程(MPG)来排序。
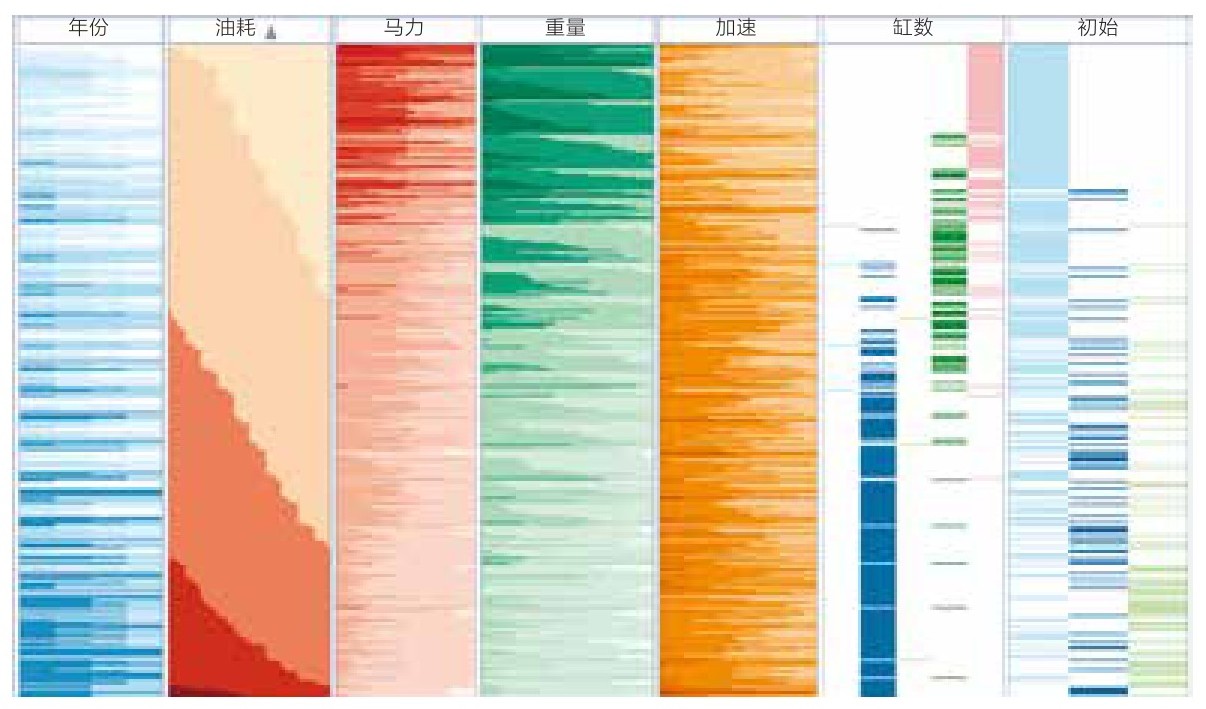
图3.15 基于双色调彩色表格的车辆数据集图形
我们可以看出,一方面,基于表格的图形能够显示出多变量数据分布的情况;而另一方面,这个图中却丢失了很多具体细节:也就是说,数据文本内容里并没有精确的数据值。所以我们使用经典的畸变图形表(焦点+背景) 20 来解决这个问题。在焦点位置的数据集,畸变会让其所在的单元格放大,然后我们再以文本形式插入精确的数值,表格的其余部分保持不变。图3.16所示是111个国家和地区的人口数据的图形,已通过鱼眼畸变来放大单元格的高度,并且在焦点和背景之间平滑过渡。
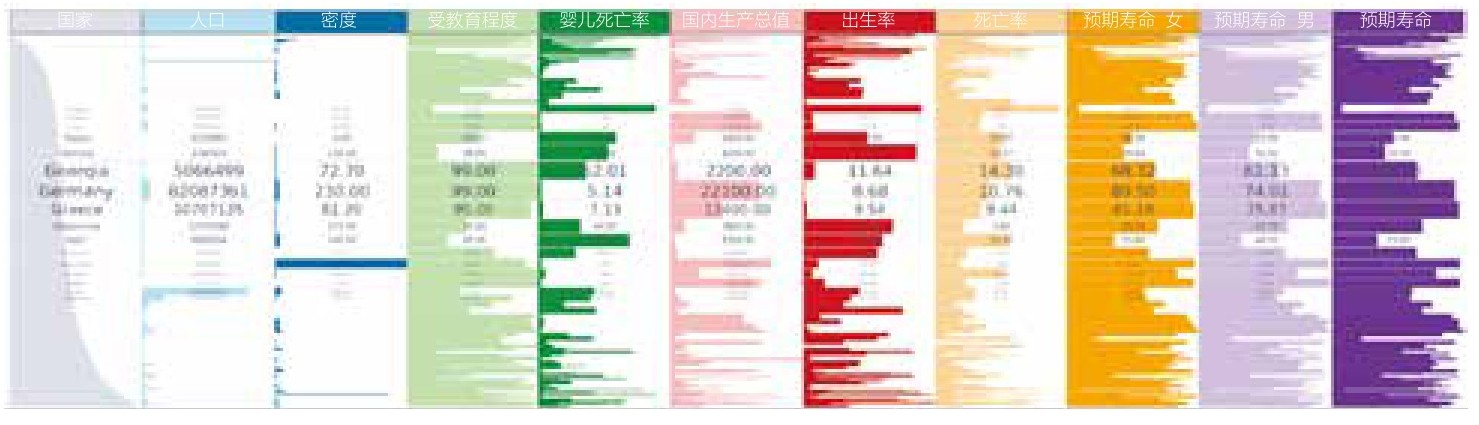
图3.16 焦点在数据组文本内容上的畸变图形表格
表格图形也和正常的电子表格操作一样,可以根据数据属性值按照行或者列来排序。表格图形虽然在研究单独数据方面很有效果,但在面对多元数据时依旧力不从心。表格里的数据需要按照列来排序,然后由用户默算结果。为了减少工作量,其实可以根据多元数据的相似程度来按照行排列。我们将在第五章中的第5.4.2节中对自动分析的部分进行详细说明。
组合双变量图形可以用来替代基于表格的图形显示多变量数据。操作方法是为所有的属性对创建双变量图形,( a i , a j ): a i , a j ∈ A , i ≠ j ,然后将这些双变量图形组合起来用以显示整个数据的全局情况。双变量图形可以按照空间排列,也可以按照图形的时间顺序排列。
空间排列。最早和最广泛使用的组合双变量图形是离散图形矩阵 21 。如图3.17所示,对于m个属性,矩阵含有m 2 -m个独立离散图形。每个属性都有m-1个与之对应的离散图。每个离散图都由平面坐标系组成,x轴和y轴分别代表两个属性,点代表两个数据属性相交的数据组。位于(i,j)的离散图显示了属性a i 和a j 。位于(j,i)的离散图显示的数据与(i,j)相同,但互换了轴。(i,i)处通常没有离散图,因为将属性a i 与自身进行对比没有任何意义。所以,空间通常用来显示a i 值的分布,或者干脆只显示数据文本的内容。
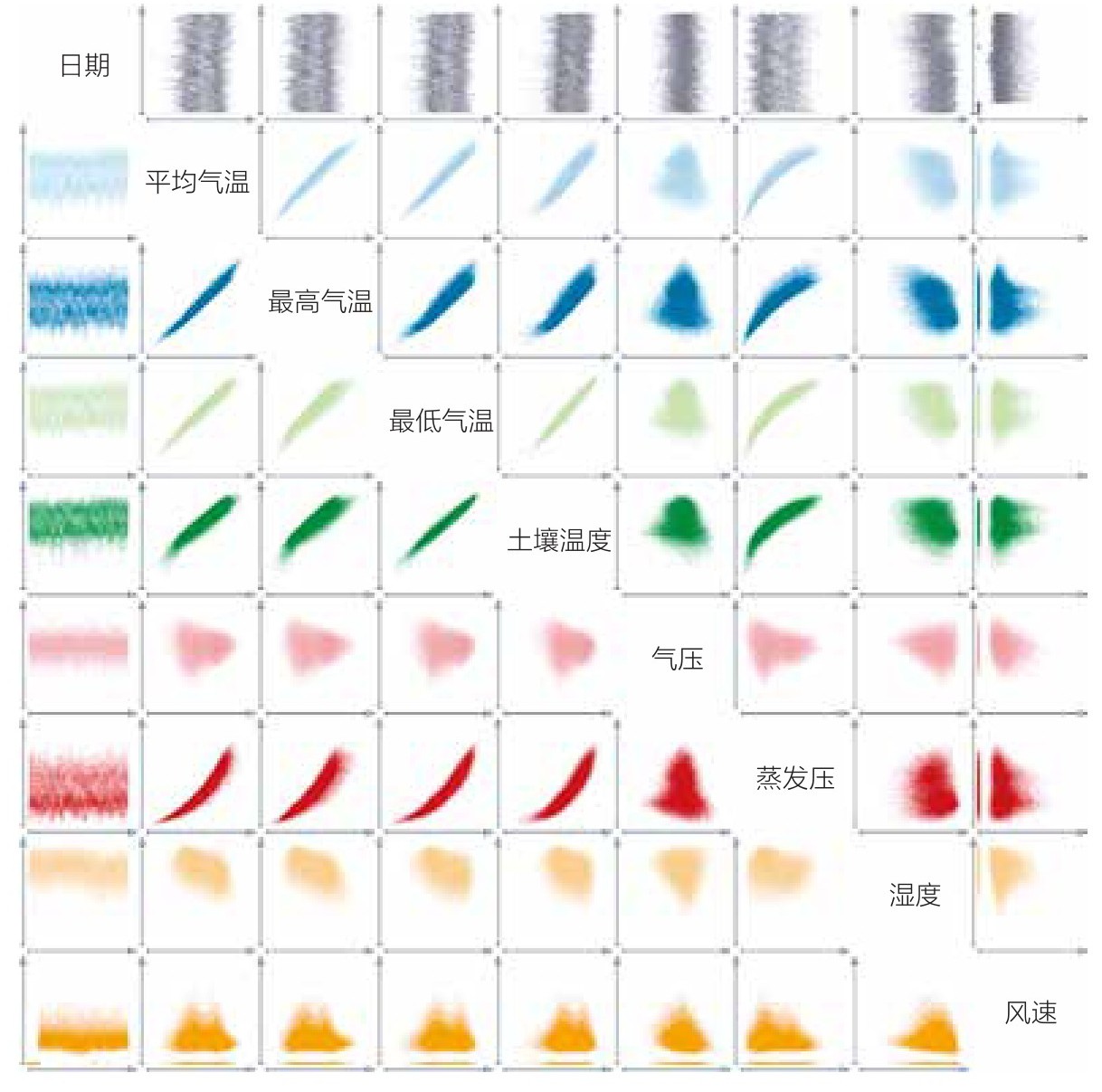
图3.17 气象数据的9×9离散图矩阵用不同的颜色简化数据变量
在实际应用中,可以根据情况重新排列离散图矩阵的行和列。比如,可以将目标属性布置在屏幕左上角,或者将它们并排显示。
时间顺序排列。 除了使用空间布局作为矩阵外,还可以将离散图设置为动画或幻灯片演示,称为“盛大旅行”(Grand Tour) 22 。本质是一帧一帧地显示每一个离散图。播放的顺序要仔细选择,这样才能准确清晰地显示出重要信息。
在使用组合双变量图形时,重点在于要意识到每个双变量图形仅能显示数据值的两个属性。因此,双变量图形中显示出的异常值或者关联性并不足以说明发现的信息是否具有多变量特征。为了让用户得出更可靠的结论,我们可以引入更多的机制来实现这一点。
其中一种机制我们称为“涂抹&连接”。用户可以在双变量图形中对点进行标记,也就是直接选择数据组。然后选择的点会在所有双变量图形中自动显示为高亮。因此,如果用户在一个图形上标记了一个异常值,并且在其他图形上随之高亮显示的点也是异常值,那么我们就可以认为确实发现了一个多变量的异常值。关于数据值的选择和图形元素高亮的内容请见第四章中的第4.4节。
组合双变量图形有一个弊端,就是用户需要靠想象来把各个图形联系起来。也就是说,当用户的视线从一个双变量图形转移到另一个双变量图形时,必须要紧紧跟随所选择的点,这样才不会丢失元素,才能完整地解读数据组。
这个问题我们可以用基于多边形的图形来解决。其中心思想是画出m个轴,每一个轴都对应一个数据属性,再画出n个多边形,每一个多边形都对应一个数据组。m个变量数据组的多边形构造请看图3.18。数据组的每个属性值则需要在相应的轴上计算出位置。最后,我们将计算出的m个位置连接起来,就形成了代表整个数据组的多边形。

图3.18 分别呈平行轴和星形轴排列的多边形图形
剩下的问题就是如何在屏幕上布置轴的位置。平行坐标图,顾名思义,就是将其坐标轴平行排列 23 。但是在雷达图中,轴并非平行排列,而是从一个中心点向周边做星形辐射。图3.18所示是相同多变量数据的平行轴和星形轴排列。除了以上两种排列以外,也可以使用三维排列的方式,在第3.3节中,我们将会看到专门用于时间数据的排列。
值得一提的是,多边形图形中轴的顺序很重要,这是因为数据中的模型可以通过相邻轴之间的区域进行解读。现在我们来看一看由多边形图形组成的一些可视化图形,具体请参照图3.19中的几种不同的平行轴图形示例。第一组轴显示出了完全相关性。第二组轴显示出了不完全相关性。第三组和第四组轴分别显示有波峰和波谷。最后,最右侧的一组轴存在局部异常。那么,如果将相同的数据转换为单个离散图时会发生什么呢?如果读者对此有兴趣,并且已经得出了结论,那么可以对照图3.20检查。

图3.19 平行轴图形
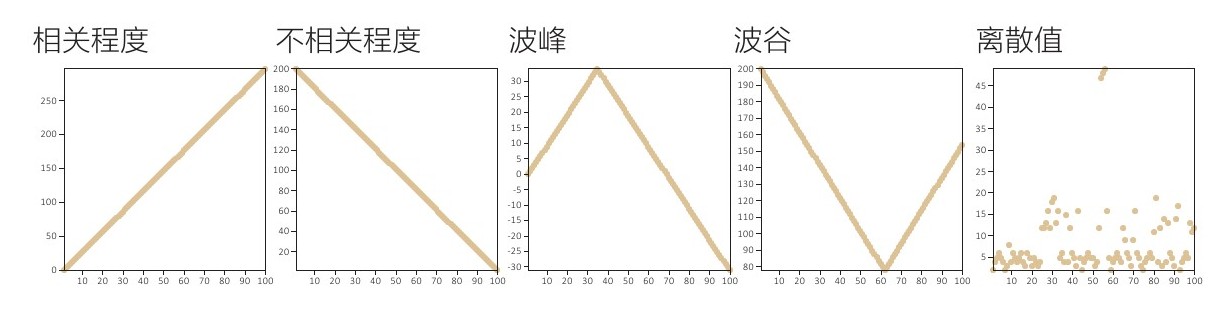
图3.20 平行轴图形的数据被转换为离散图
我们仔细研究一下离散图、离散图矩阵和平行坐标图,很明显它们都有一个隐藏的共同点:它们都位于数据点对应的轴上 24 。其实很多其他类型的图也都具备这种特征 25 。因此,基于轴的图形是一个普遍应用的概念,适用于广泛的多元数据分析。
然而它的问题在于,由于数据相同的元组会被对应到同一个位置,这就导致了图形重叠。我们通常无法直接判断一个区间(或通常所说的点或像素)能够代表多少元组。所以我们可以使用透明功能来解决这个问题,或者加入其他的视觉元素来代表数据值的重复率,比如说利用直方图。以图3.21为例,直方图可以很轻松地添加在离散图或者平行轴中。在第五章中,我们再讨论如何通过自动计算来减少图形元素的过度添加和布局混乱的问题。
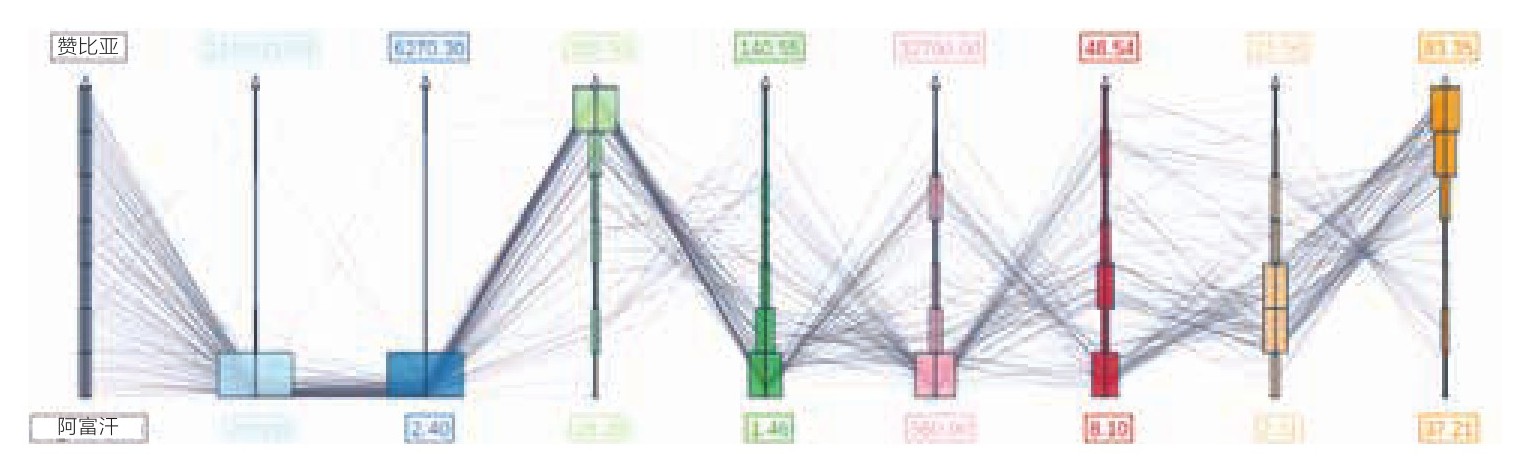
图3.21 结合使用平行坐标图与直方图来显示的人口统计数据
前文中提到,基于轴的图形主要用于强调两个属性之间的关系,那么反过来,基于符号的图形则是用于强调独立的数据元素。也就是说,当数据元素本身就被转换为一个独立的图形时,我们称为符号。每一个符号都代表一个多元数据元素,更准确地说,它代表的是与数据元素相关联的属性。设计符号需要以下三步:
1.符号的设计
2.属性与符号对应
3.符号放置
符号的设计比较复杂 26 ,主要的难点在于每个符号的空间有限,但是还要容纳好几种数据属性,这就要考验设计师的设计能力了。
我们先来看看这几个问题:符号中打算容纳几个数据属性?每个属性要显示多少数据值?采用哪些视觉变量?视觉编码如何组合?整个符号怎么安排?
在搞定这些问题之前,首先要保证设计出的符号必须完整明了,而且当好几个符号在一起出现时,要能很清晰地将它们区分开。只有这样,用户才能够将每一个符号作为单独的数据元素来解读并且与其他符号作对比。
图3.22所示是一组典型的符号设计。图3.22(a)是一组彩色方块,每一个方块代表一个数据属性。图3.22(b)是一组线条,根据不同的长度、粗细、颜色和角度来代表数据。图3.22(c)是切尔诺夫(Chernoff)笑脸,通过模仿人类表情来表达数据,比如通过嘴巴、眼睛还有鼻子的形状和大小。
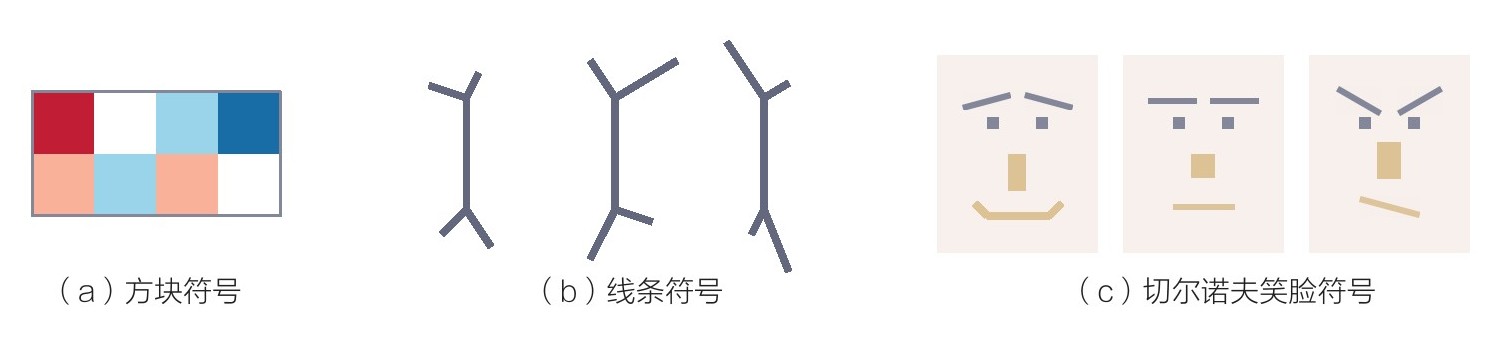
图3.22 典型的符号设计
在这一步中,我们需要仔细给符号和数据配对,也就是要决定好哪个符号指定给哪个数据的问题。我们在前文第3.1.1节中曾简单谈到过配对的问题。对符号来说,有一个方面尤其值得注意:通常,由于符号的空间极其有限,没办法容纳很多数据,所以很多时候需要减少数据值的范围。用连续性属性举例来说,可以先将它离散为几个值,然后再逐一对应到符号中。
如图3.23,我们用符号图形来表达影响玉米收获的各种因素。这个图形的核心是三幅玉米的图片,分别为:长势良好的玉米、长势一般的玉米和长势不好的玉米。这三张图片代表着三个顺序:良好、一般和不好。我们取玉米图片的中段来分别表示这几种不同的数据值。请注意,任何我们想要对应到玉米图片中的数据,首先要与符号中已有的内容相符。这一点要在数据分类时提前安排妥当。
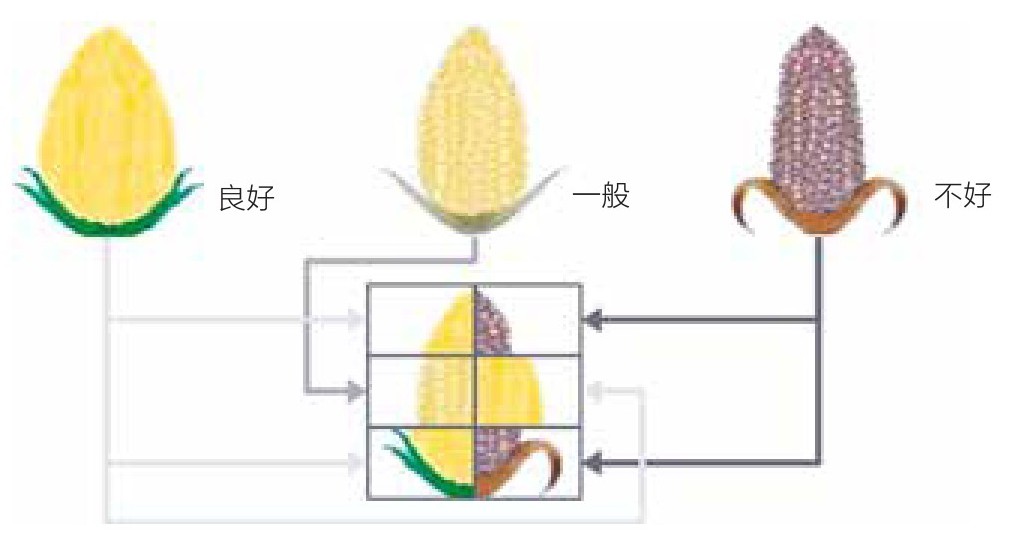
图3.23 用玉米图片表示六种顺序数据
最后,符号的放置也特别重要。通常来说,符号可以放置在方块或者网格中。图3.24(a)所示是一个关于细菌对八种抗生素所产生的耐药性的数据示例。图中网格的小方块显示黑色(存在耐药性)和白色(不存在耐药性)两种数据属性。这种图形非常适用于对数据进行总体了解,并且能看出数据的发展趋势,比如从网格中可以看出细菌对哪些药物完全不存在耐药性(全部为白色方块)或者存在一定的耐药性(含有T形黑色方块)。
在实际应用中,符号完全可以根据不同的数据自由放置。比如,可以根据数据元素的不同归类来分别放置符号。如果数据与空间有关,那么就可以利用符号来表示这些关系。图3.24(b)所示就是在地图上放置玉米符号的例子。我们在第3.4节中会深入讨论如何使用符号来表示与空间有关的数据。
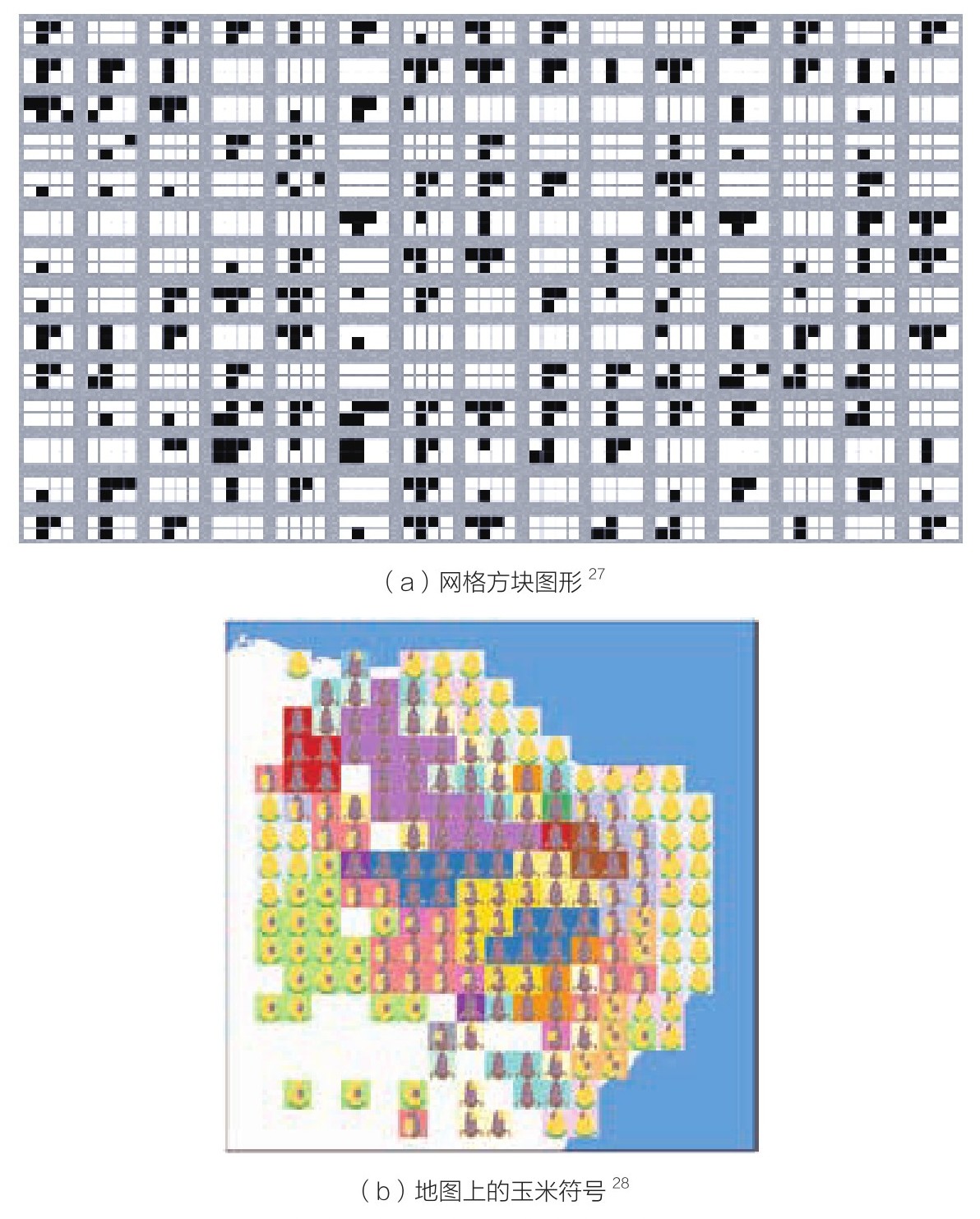
图3.24 不同的符号放置方法
与基于符号的图形比起来,基于像素的图形可谓简化到极致。具体操作非常简单,就是创建一个图形,图形中的每一个像素都代表一个数据值,不同的像素颜色也不同。虽然看起来很简单,但其中也有很多复杂情况。像素非常小,甚至远远小于网格中的方块,整个图形中的像素能够显示上百万个数据值。
在设计之前,我们要解决以下三个问题:
● 独立数据怎么对应到彩色像素?
● 多属性数据的像素放在哪儿?
● 像素怎么布置?
第一个问题尤其重要。像素是显示器上最小的显示单位,甚至小到我们连单个像素的颜色都看不出来,而能看到的都是已经连成片的像素。所以,我们所看到的像素其实都受到成片像素间对比效果的影响。从这方面可以看出,基于像素的图形应该具备清晰、可分辨的颜色。
第二个问题是表示数据属性的像素该放在哪儿。通常,我们可以在屏幕上划分区域,每一片区域都表示一种属性。图3.25所示就是显示6种天气情况的气象数据。每一种天气情况都对应一个单独的矩形区域,内部用彩色像素填充。
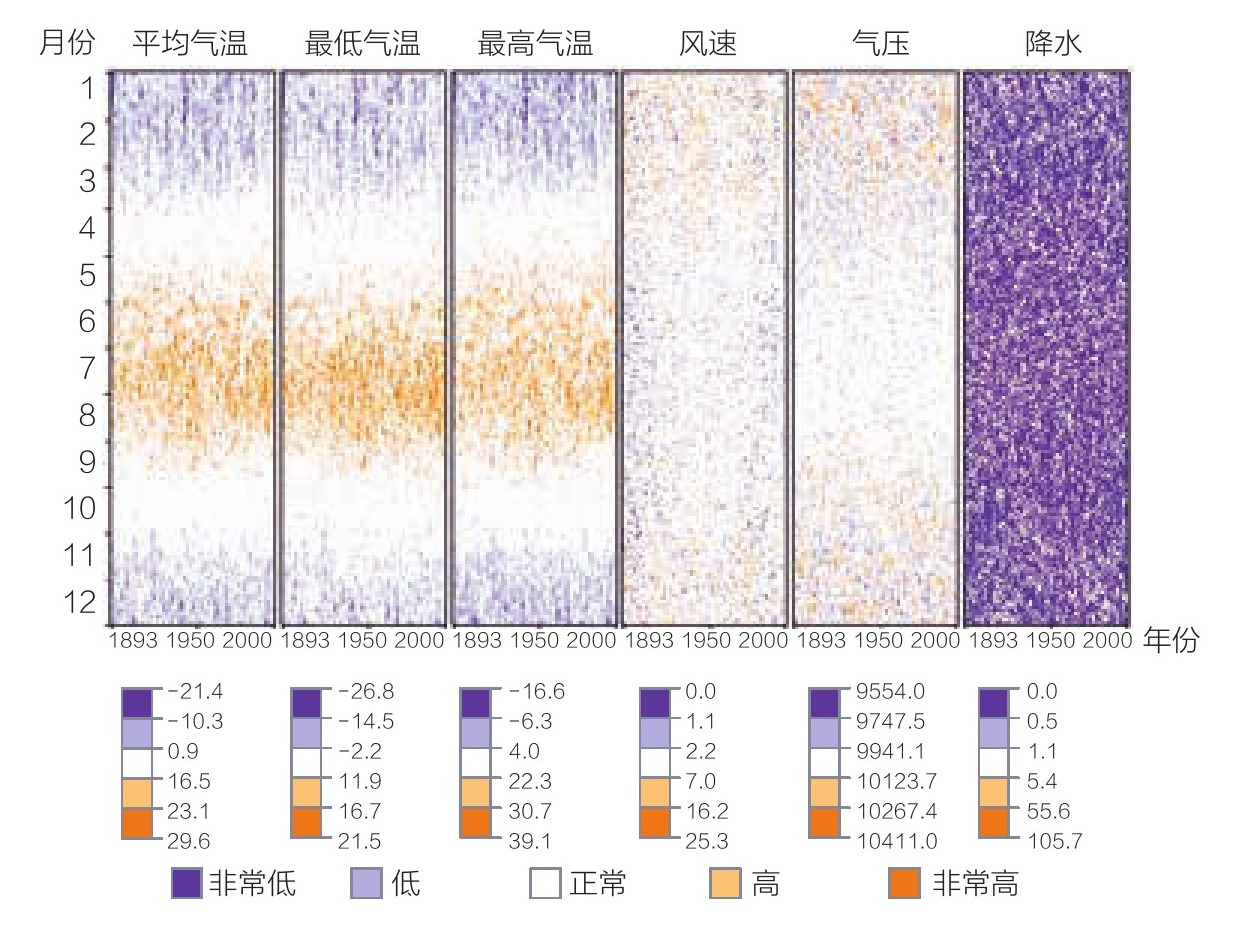
图3.25 基于像素的图形
显示了德国波茨坦市一百多年来记录的六种天气情况的每日数据
最后,第三个问题是关于像素在一个区域内如何布置。常用的有下面这些布置方式:
● 数据导向式:像素的布置方式与数据集中出现的数据组的布置方式相同。
● 预置式:像素的排列顺序根据数据集的自变量决定。比如,根据时间顺序排列像素以体现时间变量产生的影响。
● 属性导向式:像素根据特定属性的数值来布置。这种布置方式的优点在于可以显示出数据的多元性。
● 查询式:像素根据其关联的数据组与查询标准的差异来布置。这种情况下,符合(查询内容)程度高的数据值就被排列(显示)在前面。
前文中的图3.25就使用了基于时间变量的预置式方法。从中可以清晰地看出,前三种天气情况受季节变化的影响程度较强。第四、第五种天气情况也表现出了受季节变化的影响,但程度不太强。最后一种天气情况看起来则与时间无关。
显然,尽管在细节方面没那么详细,但是用像素作为信息的载体还是非常适合于概括多变量数据。对于细节问题,我们可以使用技术蓝图中广泛运用的图形分解来解决。其基本原理是将整体拆分为各个小部分,每一部分都可以放大显示,并且加入详细的注释以及复杂的细节。如图3.26所示,图形分解的概念也可以应用于基于像素的图形 29 。在这个示例中,用户选择的随时间递增而变化的像素被逐步拆分成多块。分步式的拆分过程显示了图形的一系列“爆炸”式展开,最后将紧凑而密集的像素图形转换为日历式的图形。至此,所有详细信息一览无余。
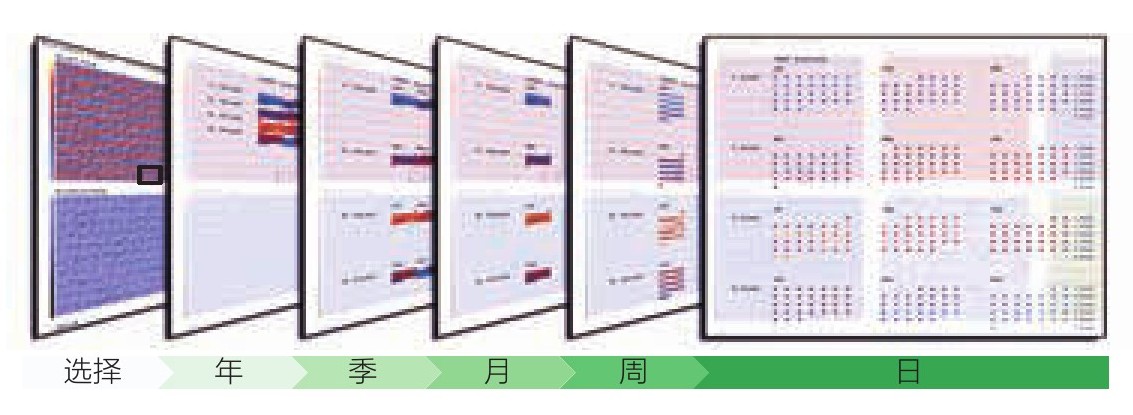
图3.26 随着时间递增而逐步拆分的基于像素的图形
在上个示例图3.26中,像素出现了一种递进嵌套式的布置,而迄今为止我们提到的可视化图形都是平面图形。嵌套式图形的基本概念是将其属性空间划分为子集合,并在图形上对子集合进行空间嵌套。操作分为如下两步:
1.归类属性子集合和确定嵌套顺序
2.在子集合中嵌套子集合
在最开始,我们要先考虑三个方面:首先,属性的数据域必须要支持嵌套。嵌套图形所需的定类数据域、顺序数据域和离散数据域必须要保证规模小,否则就会失败。
其次,必须预先指定属性子集合,而且所有的属性子集合必须规格相同。通常,每个子集合的属性不能超过三个。需要注意的是,不同的子集合会导致不同的视觉效果,而不同的视觉效果又会显示出数据的不同方面。
最后,必须预先指定子集合的嵌套顺序。换句话说,必须预先说明哪个子集合应该嵌套到哪个子集合中。因为嵌套顺序决定了哪些属性在可视化图形是主要角色,哪些是次要角色。通常,嵌套结构不会很复杂,最多不超过四层。因为嵌套得越复杂,用户就越难以解读图形信息。
当属性子集合和它们的嵌套顺序设定完毕以后,那下一个问题就是如何在显示屏上显示出嵌套的图形。通常,嵌入的方式取决于属性子集合的大小。对于不同属性量级的子集合,嵌套方案也不一样。
马赛克图适用于只有一个元素的子集合,例如(a
1
)、(a
2
)等。第一步,将显示区域沿垂直方向拆分为矩形
。矩形的数量取决于a
1
域中不同值的数量,矩形的大小表示a
1
范围内值的频率。第二步,根据a
2
的域,将每个矩形沿水平方向拆分。然后继续按照嵌套顺序中的其他属性,沿着水平和垂直两个方向拆分矩形。最后,马赛克图中的矩形就形成了数据值的分布情况。图3.27所示是泰坦尼克号事故中幸存乘客的舱室等级和性别分布统计情况。
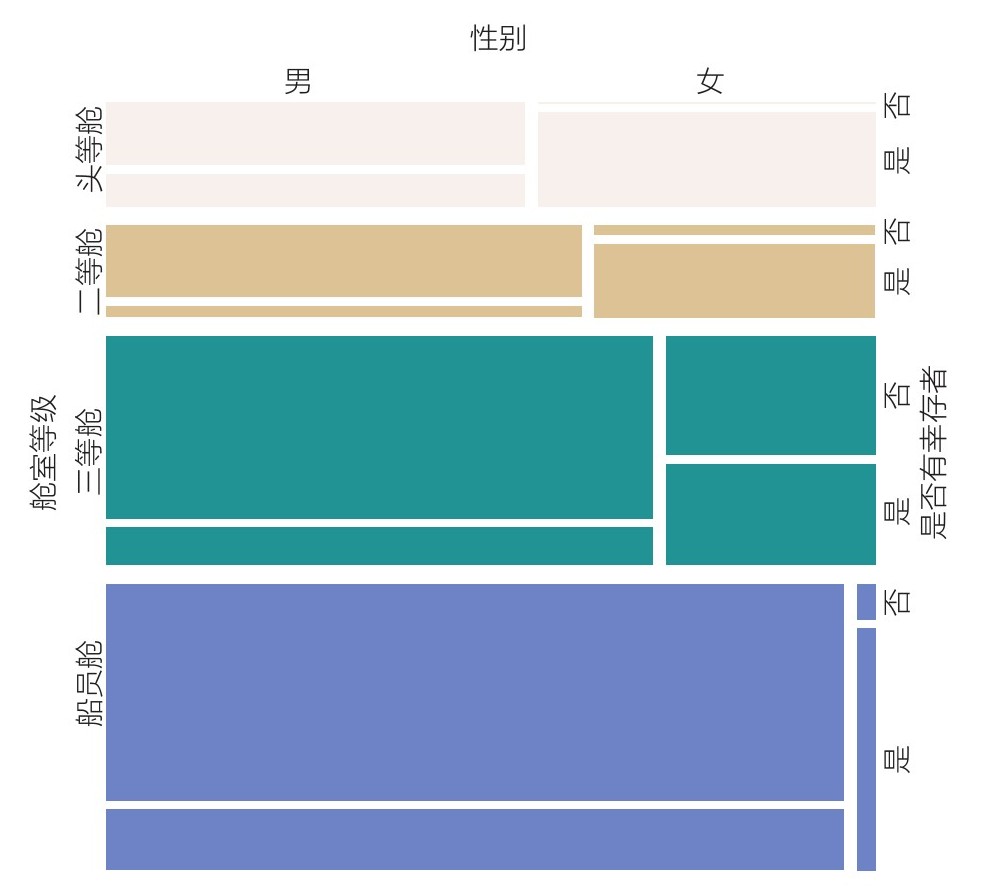
图3.27 泰坦尼克号事故幸存者的统计情况的马赛克图形
当嵌套顺序是由属性对(a 1 ,a 2 )、(a 3 ,a 4 )组成的,那么就我们可以使用维度叠加的嵌入方案30。其基本概念是在网格中嵌套网格。首先,将显示区域划分为|a 1 |×|a 2 |的单元格,所有的单元格大小一致,其中|a i |表示a i 域中不同值的数量。其次,将每个单元格细分为一个维度为|a 3 |×|a 4 |的新单元格。然后继续为所有单元格都做如此操作。我们的目的是将多变量数据转换成图形,所以还要根据每个单元格中相应的数据组的频率为单元格赋予颜色。
图3.28就是一个维度叠加的例子。图中显示的是和前文所述相同的细菌对抗生素产生耐药性的统计。数据由存在耐药性或不存在耐药性这两个维度的属性组成。从图中我们可以轻易地看出大多数单元格都是空的(即单元格中的数字为“0”),这意味着并不存在代表耐药性的数据元组,另外也能看出红色所代表的频率值组合和左上角的高频率耐药性符号,这表示细菌对这种抗生素完全没有耐药性。
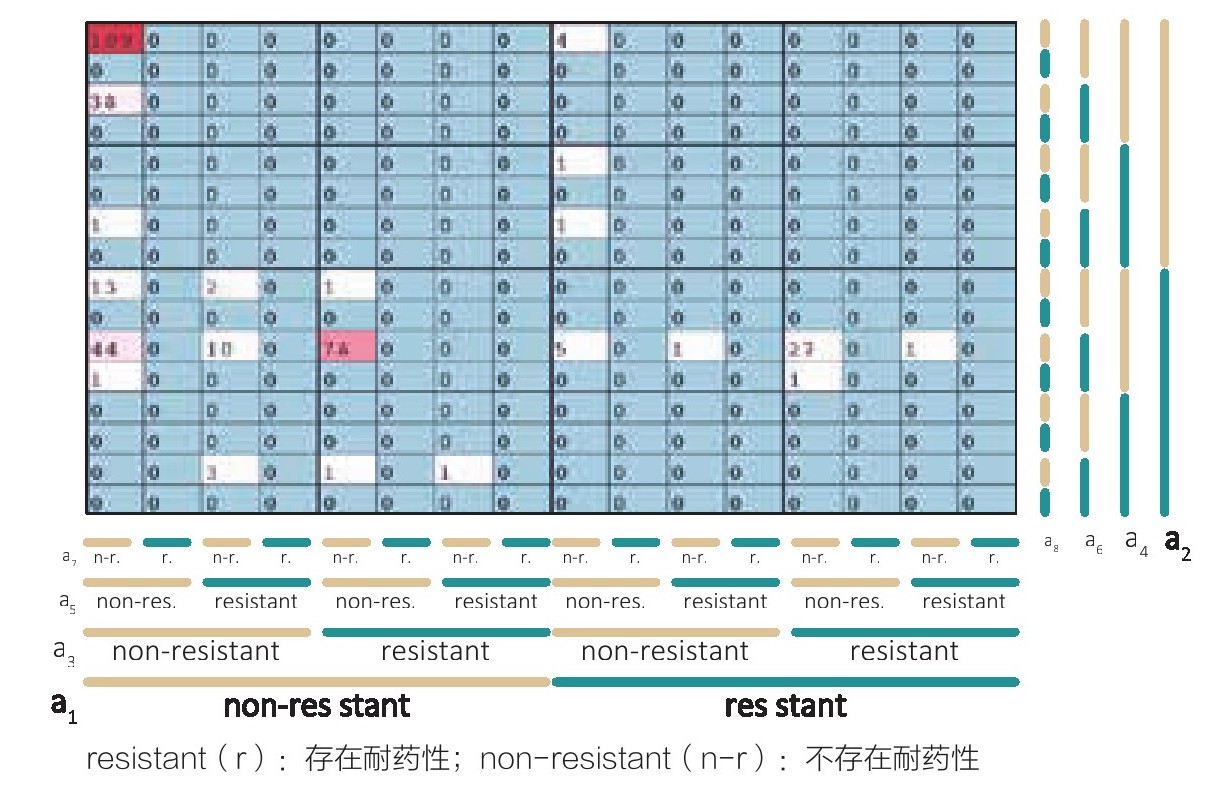
图3.28 八个二维数据属性的维度叠加 31
通过嵌套图形和维度叠加,我们分别介绍了有一种和两种属性的数据子集合的绘制方案。如果子集合中存在三个维度,那么可以使用“世界中的世界(Worlds-within-Worlds)”的方式将数据嵌入三维图形中 32 。三个维度的嵌套顺序可以如下所示:(a 1 ,a 2 ,a 3 )、(a 4 ,a 5 ,a 6 )……第一个子集合的三个属性定义了三维坐标系的三个轴。在这个三维坐标系中,由用户指定一个点,该点作为嵌入代表第二个属性子集合的新三维坐标系的原点。按照以上操作,继续将代表其余属性子集合的三维坐标系依次嵌入。
最后一个是预先指定的坐标系,该坐标系用于显示嵌套顺序中最后一组属性的实际数据值。换句话说,只有指定的属性子集合的值能够直接看到,而其余属性的值则在嵌套过程中体现。因此,“世界中的世界”只能显示坐标原点代表的数据部分。
根据前文所述,我们看到多变量数据的嵌套方法极为强大。然而可视化图形的绘制远远没有那么简单,我们还是需要一些练习才能够真正理解它。
通过对嵌套法的研究,我们对多元数据转化为图形简要总结如下:
● 基于表格的图形将普遍的电子表格转化为了图形。通过对表格的行进行排序,我们可以看出多维度数据的相关性、异常值和相似性。利用焦点+背景的方式可以分辨出单独的数据值。
● 组合双变量图形适用于表达二维度数据值的分布、双变量的关联性、相似性和离散值。它可以通过连接与涂抹功能来探索多维度关系,还可以使用视觉元素来表示数据的频率。
● 基于多边形的图形可以将数据元素显示为跨轴的多边形,主要用于探索两个相邻轴之间值的分布情况。在分析数据中所有的双变量关系时,都要重新排列轴。数据频率可以通过嵌入直方图来读取。
● 基于符号的图形可以将数据组转换为符号。其目的是仅显示数据的总体情况,而细节则可以忽略。因此,符号有助于大概估计和比较数据元素间的属性。另外,符号也适用于空间参照系中的数据转化。
● 基于像素的图形是通过单个赋予颜色的像素来对每个数据值进行转化。由于像素的尺寸非常小,所以也非常节省空间,即便是非常大的数据组也可以转化成图形。但缺点在于很难显示数据细节。关于这一点,可以整合其他的交互方法和多图形设计方案来解决。
● 嵌套图形的本质就是在显示区域内按照属性或变量逐步嵌套属性子集合,非常适合显示数据中不同值组合的频率。但是,嵌套图形解读起来并不是很容易,特别是嵌套层次较多的时候。
根据本章开头讨论的基本图形设计方案,我们可以得出以下结论。面对多维度数据时,通常情况下会使用二维平面布局。虽然前文介绍了很多三维空间布局的技术,如“世界中的世界”技术,也有生成动画图片序列的技术,如“盛大旅行”。但一般来说,二维空间布局的应用场景要比三维空间布局广泛得多。
在这一点上,我们可以进一步得出结论,就是数据的可视化需要通过完善便利的人机交互来实现充分利用视觉效果的力量。例如,人机交互可以让我们根据需要选择数据,或者通过重新布局来探索其他信息。人机互动的重要性无可比拟,我们将在第四章深入讨论。
另外,我们在前文中曾提到,某些图形转化方法只能应用于数据域中的值不是太多的情况下。我们还简单地说过,当有很多数据元素需要转化时,会面临过度绘制的问题。那么,在这种情况下,我们需要通过额外的计算来压缩数据,使其变小,然后才能够将其转换为真正可以读取的图形。关于这一点,我们将在第五章进行深入的讨论。
总而言之,这一节中关于多元数据可视化的重点是因变量,也就是属性A。在接下来的两节中,我们会深入了解自变量时间T和空间S的相关知识。