
下载掌阅APP,畅读海量书库
立即打开



联邦学习的出现为机器学习的发展带来了新的机遇,使得分散存储、彼此绝缘的小规模数据可以联合起来参与计算,在提升计算结果表现的同时满足人们对隐私保护的需求。在具体介绍联邦学习算法之前,让我们首先了解联邦学习是什么,以及联邦学习是如何保护客户端本地数据的。
深度学习的成功均是建立在大规模、高质量的数据基础之上的。一般而言,计算者可以向数据提供者收集数据,并将其全部传输至高性能服务器上进行模型训练。然而现实的情况是,大部分数据以“孤岛”的形式存在。形成“数据孤岛”的原因主要有以下3个方面。
(1)数据汇聚至服务器需要较高的传输成本。在集中式计算场景中,客户端的数据需要先传输至服务器,然后由服务器统一调配并进行计算。然而,由于客户端的数据量较大,以及数据传输距离较长,数据传输这一过程会产生较高的传输成本,阻碍了数据提供者和隐私服务者之间的数据共享。
(2)数据中蕴含巨大的商业价值。一般情况下,计算者难以获得高质量、大规模的数据。在构建数据集的过程中,计算者通常需要付出大量的人力和时间成本来标注数据。基于这些数据,计算者可以提供满足结果使用者多种需求的服务。因此,高质量、大规模的数据已经成为计算者保证自身核心竞争力的重要因素之一,这使得计算者之间不愿意共享数据,阻碍了数据价值的流动和提升。
(3)数据中包含大量的隐私信息。对于应答者而言,数据中往往包含着诸多隐私信息。基于对隐私泄露和数据滥用等风险的考虑,应答者往往不愿意分享这些数据。对于管护者而言,则需要在满足法律法规要求的前提下与他人共享从应答者处采集的数据,而不能简单粗暴地直接共享数据。
如何在保护数据主体隐私的情况下获得高质量模型,是现阶段亟待解决的关键问题。最简单的方法是客户端利用自己的本地数据训练模型。然而,由于有限的数据量和计算资源,客户端通常无法获得高准确率的模型。还有一种方法是:首先,服务器利用自身采集的数据训练一个模型;然后客户端下载该模型,并利用本地数据对模型进行微调。然而,现实的情况是,服务器难以获得高质量、大规模的数据,并且客户端微调后的模型无法学习其他客户端的数据特征。
为了解决上述两种方法的局限性,联邦学习应运而生。作为一种分布式机器学习范式,联邦学习的多个客户端在服务器的协调下协作解决机器学习问题。在联邦学习中,各个客户端的数据始终存储在本地,并且各个客户端和服务器之间仅交换客户端本地训练生成的模型更新。
与传统的分布式学习不同,联邦学习的服务器对各个客户端的数据没有操作的权限,只负责协调不同客户端之间的计算。此外,联邦学习的各个客户端只有访问自身数据的权限,没有任何权限能够操作其他客户端的数据。
此外,与将所有数据集中在一起训练的集中式学习相比,联邦学习的模型性能会有所损失[Yang et al.,2019]。令 v fed 表示联邦学习模型的性能, v sum 表示集中式学习模型的性能,并设 δ 为一个非负实数,当满足如下条件时,联邦学习模型具有 δ 性能损失:

然而,在模型性能相差较小的情况下,由于联邦学习能够提供额外的隐私保护能力,因此在实际应用中更具有价值。
联邦学习应用于实际场景中所需的工作流程可依次划分为需求确认、模型开发和模型部署这3个阶段。
需求确认阶段用于明确是否开展联邦学习。通常在以下两种情况下可以开展联邦学习:第一,对于计算任务来说,客户端本地数据比服务器代理数据更加相关;第二,客户端本地数据包含的敏感信息或数据量过大。如果确定使用联邦学习,服务器需要根据客户端的计算能力、通信能力及与服务器连接的稳定性等特点,选择合适的联邦学习算法。
模型开发阶段包含模型仿真、模型训练和模型评估3个环节。由于联邦学习分布式的特点,联邦学习的超参数与集中式学习相比有所增加,例如需要考虑客户端本地训练的次数、每轮参与聚合的客户端数量等。服务器可以在实际训练开始之前,使用代理数据(proxy data)模拟仿真训练过程以选择合适的模型结构和超参数,指导真实的模型训练。在实际训练过程中,联邦学习可以使用不同的模型结构和超参数获得多个备选的全局模型。典型的联邦学习模型训练通常包含以下6个步骤,各个客户端需要在服务器的协调下重复执行这些步骤,直至完成训练过程。典型的联邦学习模型训练过程如图3.1所示。
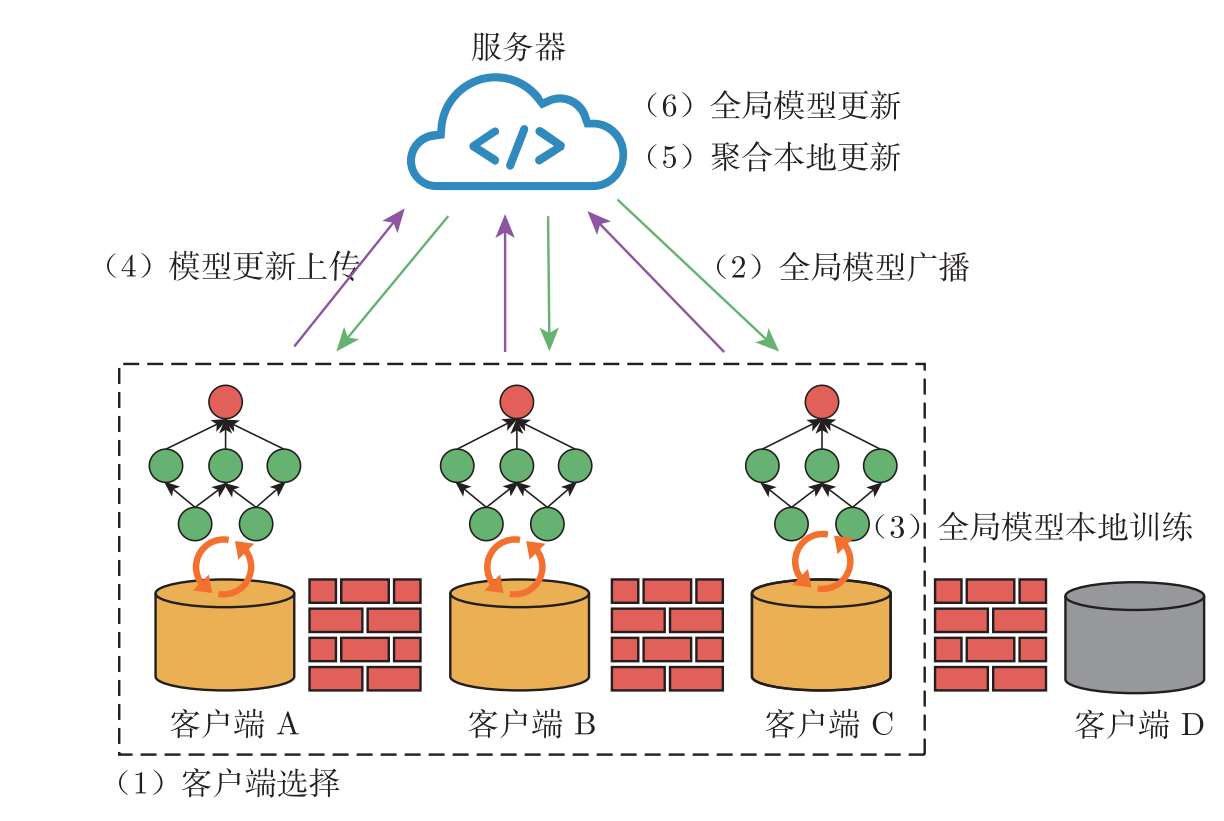
图3.1 典型的联邦学习模型训练过程
(1)客户端选择:服务器随机选择部分客户端参与模型更新过程。
(2)全局模型广播:服务器将全局模型广播给被选中的客户端。
(3)全局模型本地训练:各个客户端基于本地数据,对接收到的全局模型进行训练更新。
(4)模型更新上传:各个客户端将本地模型更新上传至服务器。
(5)聚合本地更新:服务器对接收到的本地模型更新进行聚合。
(6)全局模型更新:服务器基于聚合后的模型更新对全局模型进行更新。
在评估过程中,服务器可使用联邦分析的方式对多个备选模型进行性能评估:各个客户端计算备选模型在本地数据验证集上的指标,并将这些指标上传至服务器;服务器对指标进行统计分析后选出合适的全局模型。
模型部署是将筛选后的全局模型部署到参与或未参与联邦学习的客户端本地。与集中式训练模式一样,最优的全局模型将通过A/B测试和灰度发布(staged rollout)等标准的应用发布方式[Kairouz et al.,2021]部署在实际应用环境中。
在实际应用中,联邦学习具有两种不同的设定,即 跨设备联邦学习 (cross-device FL)和 跨筒仓联邦学习 (cross-silo FL)。前者联合大量的移动设备进行协同学习,而后者联合多个大型组织机构进行协同学习。二者的差异主要体现在客户端数量、客户端的稳定性、计算和通信的限制,以及与服务器连接的状态等方面,如表3.1所示。
表3.1 跨设备联邦学习和跨筒仓联邦学习的特点对比

在客户端数量方面,跨设备联邦学习中的客户端数量基本是百万级以上,远大于跨筒仓联邦学习。跨筒仓联邦学习中的客户端一般情况下仅有几十个,甚至有些情况下只有两个客户端。此外,跨设备联邦学习中每个客户端的本地数据量比跨筒仓联邦学习少很多,这导致了跨设备联邦学习的数据异构性问题。
在不同客户端的数据分布方面,参与联邦学习的各个客户端的数据分布呈现非独立同分布(Non-independent Identically Distributed,Non-IID)的特点。联邦学习中的数据非独立同分布主要有特征分布倾斜、标签分布倾斜、不同客户端相同标签的数据具有不同的特征、不同客户端相同特征的数据具有不同的标签和不同客户端的数据量存在较大差异等多种情况[Kairouz et al.,2021]。参与联邦学习的客户端的数据分布可能同时存在着上述多种不同类型的非独立同分布。
在客户端可用性方面,跨筒仓联邦学习的客户端可用性要比跨设备联邦学习高。跨筒仓联邦学习的客户端数据通常托管在大型数据中心,这意味着这些客户端能够稳定地参与每一轮的模型更新过程,并且不会主动退出训练过程。跨设备联邦学习的客户端则存在间歇性可用的困扰:受限于网络信号强弱和电源续航能力,客户端在计算时存在随时掉线的可能性。
在客户端计算和通信限制方面,跨设备联邦学习的客户端受限程度要比跨筒仓联邦学习高。由于跨设备联邦学习的客户端主要是小型移动设备,其计算和通信能力有限,难以对大量数据进行计算和传输。同时,不同客户端之间的计算和通信能力也有着明显差异。跨筒仓联邦学习的客户端则可以通过部署计算加速器和高带宽通信链路来提升数据计算和传输能力。
在客户端计算状态方面,跨设备联邦学习通常假设客户端没有标示符,并且在整个训练过程中可能仅参与一次模型更新,服务器不会为客户端建立唯一索引。因此,跨设备联邦学习通常需要无客户端计算状态的算法。跨筒仓联邦学习中的每个客户端通常会参加绝大多数轮次的模型更新,因此,有客户端计算状态的算法更加适用于跨筒仓联邦学习。
根据客户端本地数据重叠方式的不同,联邦学习可以划分为 横向联邦学习 (Horizontal Federated Learning,HFL)、 纵向联邦学习 (Vertical Federated Learning,VFL)和 联邦迁移学习 (Federated Transfer Learning,FTL)。一般情况下,跨设备联邦学习主要采用横向联邦学习的形式,而跨筒仓联邦学习支持以上3种类型。如图3.2所示,我们分别使用红色和绿色表示两个客户端,分别使用 x 、 y 和 F 表示数据样本的标识、标签和特征。在横向联邦学习中,各个客户端的数据样本重叠较少、数据特征重叠较多,如图3.2(a)所示。横向联邦学习根据特征空间的重合特征进行对齐,取出客户端数据中特征相同而样本不相同的数据进行协同训练。与横向联邦学习不同,纵向联邦学习中各个客户端的数据样本重叠较多、数据特征重叠较少,如图3.2(b)所示。纵向联邦学习根据样本进行匹配,利用各个客户端数据中样本相同而特征不完全相同的数据进行协同训练。在联邦迁移学习中,各个客户端的数据样本和数据特征均重叠较少(几乎不重叠),如图3.2(c)所示。典型的联邦迁移学习的目标是利用客户端A和客户端B特征之间的共同表示,以及客户端B的数据标签学习模型,使模型能够对客户端A的数据进行正确的分类。
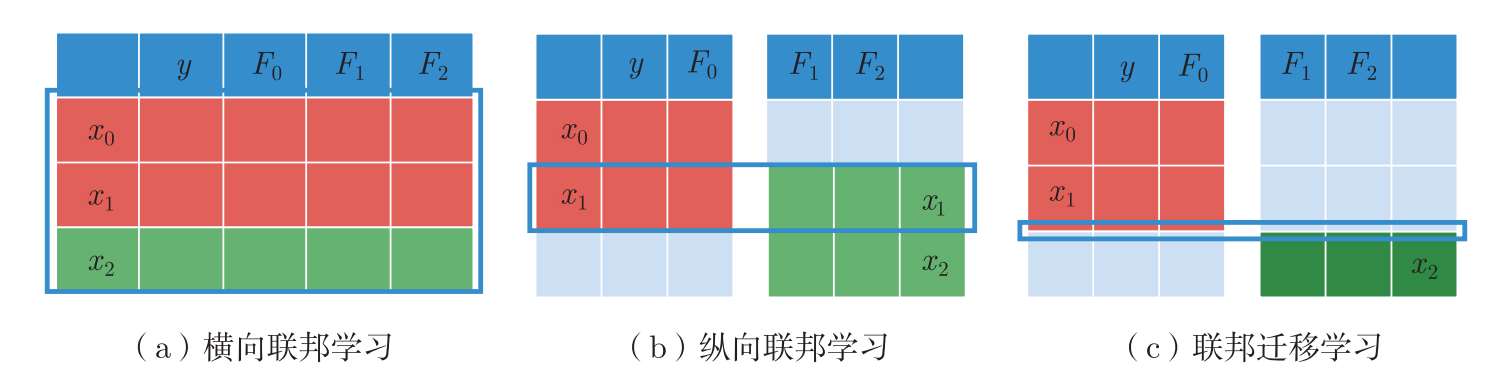
图3.2 不同联邦学习中数据特征空间和数据样本空间的重叠方式
根据联邦学习拓扑结构的不同,联邦学习可以分为 中心化联邦学习 (centralized FL)、 去中心化联邦学习 (decentralized FL)及 层次化联邦学习 (hierarchical FL)。图3.3展示了3种不同拓扑结构的联邦学习。在中心化联邦学习中,服务器协调模型训练的整个过程,负责聚合各个客户端的本地模型并更新全局模型。与中心化联邦学习不同,去中心化联邦学习不需要服务器,而是用客户端之间的对等通信取代了客户端与服务器之间的通信。去中心化联邦学习降低了中心化联邦学习中的服务器出现故障后模型无法继续训练的风险,但是存在通信开销较大、通信滞后的问题。层次化联邦学习是中心化联邦学习和去中心化联邦学习的折中方案,兼具二者的优点。层次化联邦学习设置有多个子中心节点,客户端与各自对应的子中心节点进行通信,然后由子中心节点与服务器进行通信,协作完成整个联邦学习训练过程。层次化联邦学习避免了大量的客户端与单一的服务器之间的频繁交互,并且能够有效地提升实际场景下模型训练的效率。
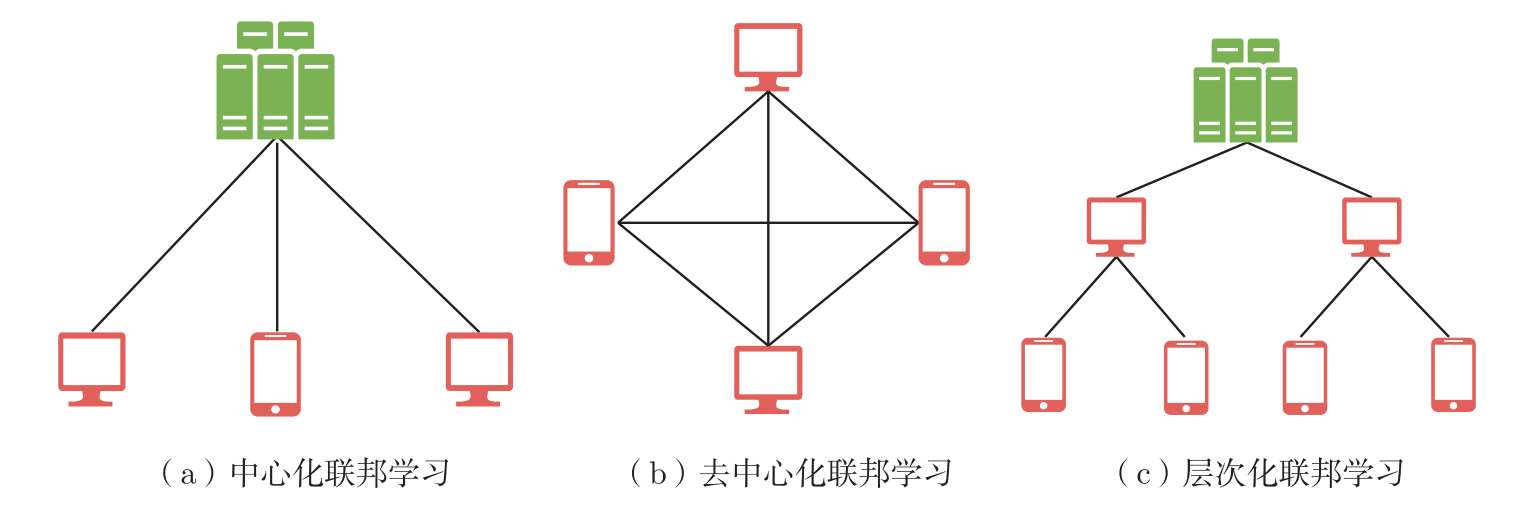
图3.3 3种不同拓扑结构的联邦学习示意图
在实际应用中,联邦学习提供的隐私保证立足于数据最小化和结果匿名化两大原则。
联邦学习的实现机制满足数据最小化原则,主要通过服务器仅收集实现特定计算所需的必要数据、即时聚合、短暂存储中间结果,以及仅发布最终结果的方式实现。在集中式学习模式下,服务器将各个客户端的数据进行汇聚以备计算使用。在这一过程中,服务器倾向存储更多的数据,即使某些数据并不会在其业务实现中使用。然而,收集的数据越多,隐私泄露的风险也就越大。为了保护各个客户端的数据隐私,联邦学习在数据不离开客户端且服务器无权访问客户端数据的情况下,仅将从数据中提炼出的中间结果发送至服务器,不会上传任何有关客户端及其数据的额外信息。这些从数据中提炼出的中间结果可以是模型更新或分析统计结果,也可以是对数据编码或添加噪声之后的信息。
联邦学习在服务器接收到客户端上传的计算中间结果后立即执行聚合操作,操作完成后将客户端发送的本地计算结果和聚合结果删除,不会对其进行持续存储。在计算完成后,联邦学习仅对模型需求方发布最终的计算结果,不会发布计算过程中的任何中间信息。
尽管联邦学习因隐私而生,但其防护水平远远不够。值得注意的是,满足数据最小化原则需要一个完全可信的第三方。然而,不仅诚实但好奇的服务器可以通过一定方式推理出客户端的数据信息,甚至诚实但好奇的客户端也可以通过一定方式推理出其他客户端的数据信息。因此,联邦学习依然存在着隐私威胁,并不能提供完全的隐私保护,需要与其他的隐私保护技术联合使用,以进一步保证数据最小化原则。
联邦学习的数据最小化强调如何处理数据和执行计算,而结果匿名化则强调如何对外发布计算结果。为了保证攻击者无法从聚合结果中推断出客户端的隐私信息,我们可以将联邦学习与差分隐私结合使用,以确保发布结果的匿名性。