
下载掌阅APP,畅读海量书库
立即打开



如果将隐私保护计算比作一棵树,那么理论和技术就是它的根茎和枝叶。在了解隐私保护计算的模型之后,是时候将目光上移,一同欣赏这棵树上结出的硕果。本节从隐私保护计算的历史出发,对本书涉及的核心技术进行介绍。
隐私保护计算的发展并非一蹴而就,而是历经了半个多世纪的岁月,涉及密码学、统计学、人工智能和计算机体系结构等多个领域。通常,隐私保护计算的历史可以分为 萌芽期(1936—1977年)、探索期(1978—2015年) 与 应用期(2016年至今) 3个阶段,如图2.7所示。
在萌芽期中,隐私保护计算相关理论取得了里程碑式的突破。1936年,Turing等[1936]给出了一种抽象计算模型——图灵机,奠定了电子计算机的理论基础。1948年,Shannon[1948]提出了信息熵的概念及信息的基本单位——比特,标志着信息论的诞生。1949年,Shannon[1949]开创了用信息理论研究密码的新途径,被视为现代密码学的开端。1960年,Baran[1960]证明了分布式中继节点架构的可生存性,成为计算机网络思想的起源。1965年,Warner[1965]构建了最早的差分隐私(Diferential Privacy,DP)机制——随机应答。1971年,IBM提出了Lucifer加密密码,它是体现了Feistel思想的分组密码算法。1976年,Difie等[2019]提出了公钥密码体制。基于此,多种公钥密码算法相继诞生。1977年,统计披露的语义概念首次形成,揭示了不可能在保证统计效用的同时根除披露的规律。
在探索期中,隐私保护计算技术相继出现,并逐渐从学术界走向工业界。1978年,Rivest等[1978]首次提出了同态加密(Homomorphic Encrgption,HE)和全同态加密的概念,并证明了RSA(Rivest-Shamir-Adelman)公钥密加算法具有乘法同态性。1979年,Shamir[1979]和Blakley[1979]分别提出了最早的秘密共享(Secret Sharing)方案。1981年,Rabin[2005]首次提出了不经意传输(Oblivious Transfer,OT),引起了密码学研究人员的广泛关注。1982年,百万富翁问题为现代密码学引入了新的分支——安全多方计算(Secure Multiparty Computation,SMC)。1985年,零知识证明(Zero-Knowledge Proof,ZKP)的概念被提出,同时在NP问题的证明系统中引入“交互”和“随机性”,构造了交互式证明系统。同年,最早的基于离散对数困难问题的同态加密机制ElGamal被提出,该算法具有乘法同态性质。1986年,第一个基于混淆电路(Garbled Circuit,GC)构造的安全两方计算协议——混淆电路协议(又称姚氏协议)诞生。同年,Meadows[1986]首次提出了基于Difie-Hellmann密钥协商协议的隐私集合求交(Private Set Intersection,PSI)协议。1988年,基于公共参考串模型的非交互式零知识证明系统首次被构造出来。1994年,NickSzabo提出了智能合约(Smart Contract,SC)的概念,但是因为缺乏可信的运行平台,智能合约当时没有得到广泛的关注。1996年,李嘉图合约出现在大众视野,它实现了合约数字化,并从法律角度为智能合约提供了合规的合约模版。1999年,著名的部分同态加密体制Paillier诞生,该算法基于判定合数剩余类问题构建,是目前应用非常广泛的同态加密算法。

图2.7 隐私保护计算的发展史
2004年,安全多方计算平台Fairplay发布,标志着安全多方计算研究从理论优化转向实用框架。2005年,第一个同时支持任意多次加法同态和一次乘法同态的机制BGN被提出,它是距离全同态加密方案最近的一项工作。2006年,差分隐私的定义正式诞生,基于查询敏感度(而非输出维度)的加噪方法成为标配。2008年,中本聪将比特币带入了公众的视野。2009年,Gentry基于理想格设计了第一代全同态加密方案,并创造性地提出了Bootstraping的想法。同年,开放移动终端平台组织(Open Mobile Terminal Platform,OMTP)在[OMTP,2009]中首次定义了可信执行环境(Trusted Execution Environment,TEE)。2012年,基于带误差学习(Learning with Error,LWE)困难问题构建的BGV算法被提出,这是目前主流的全同态加密方案中效率最高的方案,标志着第二代全同态加密的开始。同年,Bitansky等[2012]首次提出了著名的zk-SNARK,该方案是零知识证明中最经典的加密算法体系,目前被广泛应用于区块链领域。2013年,Intel推出了SGX技术,该技术对云计算安全保护的意义重大。同年,Vitalik Buterin发表了以太坊初版白皮书,以太坊由此诞生。Gentry等[2013]在这一年提出了基于近似特征向量构建的GSW算法,标志着全同态加密的研究进入了第三阶段。2015年,Konečnỳ等[2015]提出了联邦优化,让节点共同训练全局模型,同时保持训练数据在节点本地。同年,中心化预言机Oraclize首次被提出。通过将学习算法转换为求和形式,Cao等[2015]提出了一种通用的遗忘算法,这是实现机器学习场景下某些数据被快速遗忘的首次尝试。
在应用期中,隐私保护计算产品如雨后春笋,层出不穷。2016年,苹果在iOS 10 和macOS Sierra系统中部署(本地)差分隐私机制,掀起了差分隐私应用的浪潮。2018年,谷歌将联邦学习(Federated Learning,FL)应用于Gboard虚拟键盘,并在输入预测和新词发现等一系列任务中表现出众。同年,Ben-Sasson等[2018]首次实现了zk-STARK,实现了不需要可信设置、可扩展的零知识证明协议。2019年,WeBank开源全球首个工业级联邦学习框架FATE。同年,微软发布同态加密开源库SEAL,其支持BFV和CKKS方案。Ginart等[2019]第一次形式化定义了机器学习中的数据删除(机器遗忘),并研究了实现高效机器遗忘的算法原则。2020年,规模最大且用途最广的差分隐私开源平台OpenDP正式发布。同年,美国人口普查局在第24次美国人口普查中启用差分隐私保护;Hu等[2020]首次提出智能合约工程(Smart Contract Engineering,SCE),实现了智能合约的设计开发、合约维护和执行过程的系统性、模块化和规范性。
图2.8展示了隐私保护计算的主要技术与三大隐私保证的对应关系。其中,部分技术可以同时满足输入隐私和策略执行的要求,斜体字表示本书未涉及的技术。
联邦学习 是保护输入隐私的分布式计算范式,可以实现各个客户端数据不共享的条件下的协同计算。具体来说,服务器与各个客户端通过中间结果的多轮交互来获得计算结果,在整个计算过程中,客户端的数据始终存储在本地,同时其他客户端和服务器对该客户端的数据没有任何访问权限。在客户端知情并且同意隐私政策的前提下,联邦学习满足数据最小化原则。在每轮迭代过程中,客户端仅为特定的计算任务传输必要的更新,同时,服务器仅短暂存储中间结果以即时完成聚合,并仅发布最终的计算结果。然而,现有工作表明,攻击者可以依据中间结果获得原始数据的一些信息,因此,联邦学习还需结合安全多方计算或同态加密等来增强计算过程的保密性,并结合差分隐私来增强结果发布的匿名性。目前,谷歌、微众银行、达摩院及百度等机构发布了联邦学习开源框架,并且联邦学习已经在政务、金融和医疗等场景中得到应用。
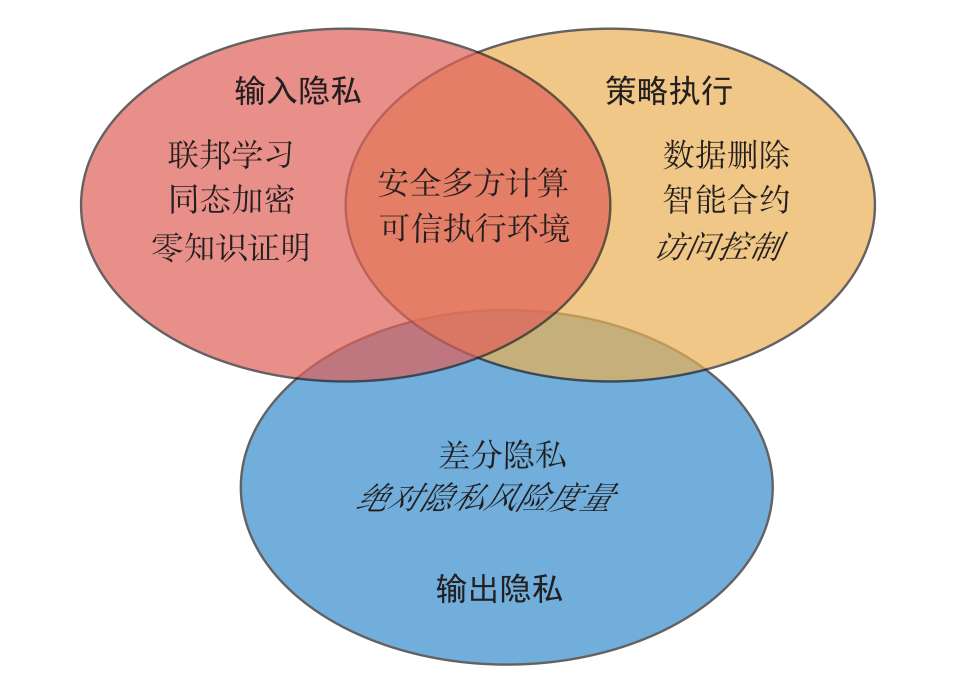
图2.8 隐私保护计算的主要技术与三大隐私保证的对应关系
同态加密 允许隐私数据以密态形式参与运算,并得到与明文运算一致的结果,为输入隐私提供了强有力的保证。具体来说,同态加密算法都是基于数论难题构造的,攻击者无法在多项式时间内破解密钥,也就无从获取加密数据的真实值。对于管护者来说,数据在外包计算的全周期都处于加密状态,计算过程中产生的中间值和统计值也处于密态,这些统计值与密文之间仅存在链式推断关系。因此,管护者始终无法从中推断真实数据。此外,即使非法访问的用户成功获取管护者服务器中其他用户的密文数据,同样无法得到数据明文。
零知识证明 通过构造证明协议使得证明者在不透露命题相关数据的情况下向验证者证明该命题,从而保护证明者在协议交互过程中的输入隐私。具体来说,证明协议的实现让证明者在不提供目标命题的具体内容时也能向验证者证明该命题的正确性。其中,“零知识”就是指验证者除了对论断判断的结果之外,无法获取任何额外信息。现有的研究通常将零知识证明的思想应用于设计隐私保护计算协议来解决许多实际场景下的隐私数据证明问题。
安全多方计算 借助密码学技术构造多方计算协议,在不泄露隐私数据的前提下,可实现一组互不信任的应答者之间的协同计算。具体来说,应答者先利用混淆电路、秘密共享等技术将原始数据转换成管护者不可识别的密态数据,再交由管护者执行计算,从而为应答者的输入数据提供隐私保护。由于计算的过程通常以协议的形式体现,在半诚实模型下,应答者和管护者会严格遵循协议执行预设的步骤完成计算任务。恶意模型下,虽然恶意的应答者或管护者存在篡改、中止协议等行为,但可以通过引入一些特殊的机制(如切分选择)来阻止该现象发生,最终实现隐私数据的可用、可控、可共享。因此,安全多方计算也能为策略执行目标提供隐私保证。
可信执行环境 依靠芯片等硬件和软件协同对数据进行保护,同时保留与系统运行环境之间的算力共享,可用于处理敏感数据、部署计算逻辑,进而执行隐私保护计算。从输入隐私角度来看,可信执行环境通过时分复用CPU或划分部分内存地址作为安全空间来建立隔离执行环境,以保证外部环境不能获取甚至篡改其内部的信息。因此,用户可以将自己的隐私数据上传到可信执行环境中,而无须担心自己的数据被其他恶意用户窃取。从策略执行的角度来看,可信执行环境能够通过安装或更新其代码来管理内部隐私内容、控制隐私保护计算过程,还可以通过定义机制来安全地向第三方证明其可信度。与本书介绍的其他技术相比,可信执行环境注重在特定场景下通过不同技术的融合来解决问题,加强技术之间的协同,为隐私保护计算发展注入了新思路。
差分隐私 是输出隐私的一种信息论度量,它通过隐私预算这一参数量化并限制统计发布造成的个人信息泄露。具体来说,差分隐私算法能够将任意相邻数据集(仅相差一条记录的两个数据集)映射到相近的概率分布,从而使攻击者无法通过输出结果辨别真实的输入(某条记录的存在或缺失)。与传统的统计披露限制方法(如 k -匿名)不同,差分隐私能够抵御具有任意背景知识和计算能力的攻击,并最大限度地延缓因多次发布而造成的隐私泄露风险。此外,差分隐私不依赖算法和参数的保密性,且任何计算都无法弱化已有的隐私保证。由于严格的数学保证和良好的隐私性质,差分隐私已被谷歌、苹果、微软、脸书、领英及美国人口普查局等机构采纳,并在生产系统中用于保护参与者的隐私。
数据删除 指在隐私保护计算过程中,管护者能通过某些方法满足应答者的个人数据删除请求,从而保障应答者对个人隐私数据的被遗忘权。具体来说,管护者在接收到应答者的删除数据请求时,不仅要删除请求的原始数据,还要删除可能推理出原始数据的相关内容,并保证删除后的状态与该请求数据从未出现过的状态一致。上述过程满足隐私保护计算目标中的策略执行,即应答者可以通过发送删除请求来控制其数据是否被管护者使用,也可以控制与之相关的计算结果是否被发布给结果使用者。
智能合约 作为自动执行合约内容的计算机化交易协议,在区块链技术支持下,一经部署则难以被篡改,且交易内容可查询、可验证,从而保证智能合约能够严格按照预定义的策略自动执行。具体来说,区块链的赋能使智能合约具有了防篡改、可追溯等特性,保证了调用智能合约的交易记录具有完整性和可审计性。当交易符合合约预设条件时,即可在区块链分布式系统中自动执行,无须第三方验证,避免了对传统方法的依赖。在策略执行方面,当策略决策点将处理规则变成机器语言后,策略实施点保证规则得到遵守,这分别对应了智能合约的生成和在区块链上的执行过程。由于合约生成过程可根据预设策略进行编写和验证,合约执行过程可保证严格按照合约逻辑强制自动执行,因此应答者对隐私保护计算过程的控制得以实现。